
Abstract
The regions obtained by image segmentation need to satisfy both the requirements of uniformity and connectivity. Image segmentation is the process of dividing an image into several specific regions. The result of image segmentation is a set of combinations covering the main feature areas of the whole image. The pixels in an area are similar to some or calculated characteristics, but there are obvious differences between adjacent areas. In this paper, a gray image segmentation algorithm based on fuzzy C-means combined with bee colony algorithm is proposed, which has strong optimization ability for multi-objective problems. By using the fuzzy membership function of the fuzzy C-means algorithm, the optimal clustering centers in the artificial bee colony optimization algorithm can be quickly calculated. It makes image segmentation faster and more accurate. The bee colony search algorithm is optimized and an effective local search algorithm is designed, it makes the bee colony converge to the optimal solution efficiently. Finally, the improved fuzzy C-means and artificial bee colony optimization algorithm are used to improve and optimize the seed region growth method. The multi-criteria are taken as the multi-objective optimization problem, and the segmentation results are finally obtained. Benefiting from our local search program and feature extraction in multi-color space, it makes the stability; efficiency and accuracy of image segmentation are higher.
Introduction
Image segmentation is one of the fundamental issues in image processing and machine vision. Its main goal is to decompose the image into a collection of non-overlapping regions. Image segmentation is very versatile and involves a variety of image formats. Image segmentation is the process of dividing a digital image into multiple sub-regions. The goal is to change or simplify the implementation of the image to make the image easier to understand and molecular [1]. Many image segmentation methods have been proposed in the application research process, in which the threshold method is widely used due to its simple and effective characteristics. Due to the importance of image segmentation, there are many research and improvement methods for image segmentation, which can be divided into three types. The edge detection based method first checks the edge points of the image. Then form a contour according to a certain strategy. The difficulty lies mainly in the contradiction between noise immunity and detection accuracy of edge detection [2]. The region-based segmentation divides the pixels into different regions according to the feature space of the image data [3]. The third type is the segmentation method of dividing edges and regions. Combining the advantages of both, the accuracy of the contour is improved by the constraint of edge points [4]. This kind of research has its own advantages and disadvantages, but it has an important problem. The important performance of this algorithm is not balanced.
The clustering method can be divided into spectrum clustering, objective function clustering, hierarchical clustering, graph theory clustering and other methods. Among them, the objective function clustering is the most commonly used method, which transforms the clustering problem into the optimal solution problem of solving the objective function, which greatly simplifies the solving process and becomes one of the research hotspots. C-means clustering algorithm is a classical algorithm for clustering problem research and is often used for image segmentation [5]. However, the clustering results of the C-means clustering algorithm often depend on the choice of initial values, and the image segmentation quality is low [6]. In view of the shortcomings of the C-means clustering algorithm, many researchers use evolutionary techniques to optimize the C-means clustering algorithm. The threshold segmentation algorithm is simple, fast and effective, and is one of the basic techniques of image segmentation [7–9].
After a single threshold segmentation algorithm divides the image into two categories, the targets in the two classes are no longer distinguished. If you continue to use threshold segmentation in both classes, you can split the target more accurately. Therefore, the single threshold algorithm is generalized to multiple thresholds. The multi-threshold segmentation algorithm has an Otsu multi-threshold fast segmentation algorithm [10, 11]. When dividing a multi-threshold image, the amount of calculation is large, and there is redundant background information that does not require segmentation. If multi-threshold segmentation can be directly performed on an image similar to the target information, the operation speed and accuracy of the target can be improved.
In this paper, a gray image segmentation algorithm based on fuzzy C-means and artificial bee colony optimization is proposed. Using the fuzzy membership function in the fuzzy C-means algorithm, the optimal clustering center in the artificial bee colony optimization algorithm is quickly calculated to make the image segmentation faster. The improved bee colony algorithm is used to improve and optimize the seed region growth method, specify the optimal position of the seed, determine the optimal threshold for each seed point consistency criterion, and use multiple criteria as the multi-objective optimization problem. The bee colony optimized the search for the Pareto optimal solution and finally obtained the segmentation result. The experimental results show that the time efficiency, consistency error and intra-class scattering of the segmentation algorithm have good practical value. Medical images that are synthesized, classical, and noise-added are selected and segmented and compared using a variety of segmentation algorithms that perform better in terms of convergence, temporal complexity, robustness, and segmentation accuracy.
Related work
The fuzzy theory was originally proposed in the 1970 s to deal with some problems that are difficult to solve in traditional collection theory. Fuzzy theory provides a new method to solve the problem of ambiguity and uncertainty. As one of the basic theories of artificial intelligence, its thought draws on many follow-up algorithms and becomes an important theory to simulate human brain thought [12, 13]. In the classic collection theory, collectibles have very important attributes. The certainty of the elements in the set, each element can only belong to a unique set, thus the conclusion that the feature function can only be 0 or 1. In fuzzy set theory, the concept of eigenfunction has been generalized from a set of two points to a region and becomes a membership function [14–16]. Clustering algorithm is an important algorithm in image segmentation and has been widely used in various fields. The clustering algorithm is an unsupervised algorithm. It does not require prior knowledge. The algorithm classifies all samples and classifies samples with the same characteristics into one class. Samples in the same class have as many features as possible. Among all clustering methods, hard C clustering is one of the most primitive and classical clustering algorithms. Each pixel in the algorithm belongs to a class, and there is no pixel overlap in the class [17]. Although this classification method is more effective, it does not reflect the affiliation of each pixel well. Because each point is strictly attributed to a class, the fuzzy properties of the image itself are not reflected.
Panda S et al calculated the variance of the gray values in each neighborhood. Filter parameters were determined to balance local noise detection and introduced the concept of approximation strategy and cluster density [18]. An improved performance algorithm for optical CDMA networks based on random artificial bee colony optimization is proposed. According to the clustering density, the computational complexity of the algorithm can be greatly reduced, and the quality of the segmentation graph can be improved. Some researchers have proposed an FCM-based artificial bee colony (ABC) image segmentation method. The fast FCM algorithm mainly reduces the number of iterations of the algorithm, thereby reducing the algorithm calculation and running time. Geng X et al. proposed a classification of moving image EEG based on artificial bee colony optimization Gaussian process, which greatly improved the segmentation quality of noise images. First, the sample points with the same characteristics are weighted, and then the weighted data is clustered [19]. Liang Y et al. proposed an improved artificial bee colony algorithm to solve the constrained optimization problem, mainly using the look-up table method to replace the complex operation in the FCM algorithm, thus reducing the computational complexity [20]. The cluster analysis of gray level directly reduces the amount of calculation, and the clustering effect does not change. Wang G et al. proposed the parameter identification of piezoelectric hysteresis model based on improved artificial bee colony algorithm [21]. The fuzzy clustering function is used to search the initial cluster center, and the optimization is performed by the ABC algorithm, which has no direct relationship with the initialization value of the cluster center. It performs well in terms of image segmentation speed and quality.
Proposed method
Cluster analysis
When people recognize things, they abstract certain features of things and generalize them into concepts. Some concepts are very clear and can be defined with a clear scope. This clear concept is used to distinguish attributes such as “gender.” In the field of mathematics, some problems have similar fuzzy attributes. For example, similar problems arise in the field of images, decision algorithms, signal processing, and the like. To solve these problems, a fuzzy theory has been developed and divided into multiple branches. In systems engineering theory, fuzzy theory combined with many classical algorithms yields very good results. Especially in image processing and pattern recognition [22], many signals have ambiguity, and fuzzy theory can effectively solve these problems. Fuzzy theory is also widely used in single-objective and multi-objective optimization algorithms. Fuzzy theory is a very effective means of measuring the similarity of certain uncertain elements. In the field of neural networks and artificial intelligence, fuzzy logic has well simulated the thinking mode of the human brain, making it shine in the field of artificial intelligence, and has become one of the key technologies of artificial intelligence. Clustering is the process of distinguishing and classifying things according to specific rules and requirements. In this process, there is no prior knowledge about the categories, but rather the similarity between things as the criterion for class division, so the samples in each class are similar, and the differences between the samples in the same class Bigger. Cluster analysis, also known as unsupervised learning, is the study of how to classify unlabeled samples into subclasses without prior knowledge. However, in the real world, the boundaries between most things are not strict. Fuzzy clustering analysis can reflect the uncertainty of the sample into the category through the fuzzy method, which is consistent with the “this is not the same” feature between things. The following mathematical model can be used to describe cluster analysis. Let a given argument X ={ x1, x2, ⋯ , x
n
}, if each sample X on x
k
(k = 1, 2, ⋯ , n) is characterized by m parameters, namely x
k
={ xk1, xk2, ⋯ x
km
}. Which on x
ki
in x
k
is the value on the i feature. If the theory is used to segment the image, then X represents the set of all pixels in the image and x
k
represents the kth pixel in the image. Cluster analysis is the measurement of the distance between samples, that is, the similarity. According to the X division principle, it will be divided into c non-overlapping feature subsets X1, X2, ⋯ , X
c
. And the following formula is satisfied.
Feature selection is the basis of clustering. It is mainly to preprocess the data samples to obtain sample features with strong anti-noise and high recognition rate, so as to better cluster in the later stage. The similarity measure is a description of the distance between samples. The suitability of the choice is important to the clustering process and usually depends on the specific application. The choice of clustering algorithm is the key to the clustering process. The data objects are classified according to the similarity measure selected in the previous stage. The evaluation of the clustering results is mainly to evaluate the ideal degree of clustering results, in order to finally get better results. There are feedback links in the clustering process, and each process interacts and depends on each other. In order to obtain better clustering results, repeated experiments are usually required, which requires a repetitive process.
The standard FCM algorithm was proposed by Dunn based on the hard C-means algorithm in 1974. In the same year, Bezedek established the FCM algorithm theory based on the Dunn FCM algorithm and converges in a few years. Practice has proved that the FCM algorithm is also applicable to the field of image segmentation. The basic idea of the FCM algorithm is to first set some class centers and membership degrees of each sample for each class, and then adjust the membership degree to convergence by iteration. The fuzzy C-means algorithm is an improved hard clustering algorithm and is a flexible fuzzy partition [23]. The FCM algorithm basically performs clustering of the target image by finding the minimum weighted distance between the pixel and the cluster center. This weighted distance is called the objective function of the FCM algorithm, and its expression is as shown in formula (2).
The physical meaning of the objective function J represents the sum of the squares of the weighted distances of each pixel in the target image to each cluster center. When the Euclidean distance weighting value of each pixel point in the target image to a cluster center is the smallest, the Euclidean distance from other cluster centers is as large as possible, so the basic principle of the FCM algorithm is to find a suitable cluster center. And the membership matrix causes the objective function J to take the minimum value min (J).
Get u
ij
= (i = 1, 2, ⋯ , C) by finding the minimum value of the objective function. Finally, each pixel is divided into different classes, and the formula for dividing the j pixel into the kth class is as shown in the following formula (3).
Since the membership degree has a constraint
If d ij is 0, the membership value of this class is 1, and the membership value of other classes is 0. When the objective function obtains the minimum value, the membership degree at this time is retained, and each pixel of the target image is classified according to the division formula (4), thereby obtaining the segmentation results of the image. In the iterative process, the appropriate iteration termination condition should be selected. It is impossible to stop iteration according to the difference between the two iterations before and after the objective function. The algorithm is easy to fall into the local part if the initial cluster center is close to the local extremum. Optimal, the results cannot be accurately segmented. The standard FCM algorithm generally adopts the difference between the membership degrees of the pixels before and after the two iterations is less than a certain threshold to stop the iteration, because the membership degree update is related to the cluster center and the algorithm is easy when the initial cluster center is improperly selected. Fall into local optimum. You can also set a maximum number of iterations and stop iterating as soon as you reach the number of iterations.
Compared with genetic algorithm, particle swarm optimization and other bionic intelligent algorithms, artificial bee colony algorithm has the advantages of less control parameters, faster convergence, avoiding local optimization and robustness. Biologists have found that after the bees return to the nest, they dance on the right lap and the left lap of the hive to convey information about the honey source. This information includes the angle of the honey source from the sun and the distance from the hive. This way of information exchange between bees allows the entire bee colony to work together to collect nectar. In this self-organizing collaborative model of bees, the honey source represents a possible solution within the solution space. Bees use the 8-word swing dance to share honey source information with other bees to recruit beekeepers, and some become lead bees.
The information sharing synergy mechanism of the bee colony ensures the efficiency of collecting nectar under complex environmental conditions. In the initial stage of optimizing the honey collecting process, all bees have no experience value of honey source, and they are used as scout bees to conduct random search for honey sources. When the scouting bee searches for the honey source, the scouting bee turns into a bee and exchanges information with other bees around it to sort the profit of each honey source. The highly profitable bees dance in the dance area to recruit more beekeepers to become the lead bee to the honey source or to search for honey in the field, the middle-of-the-money continues to collect honey, the less profitable bee is the scout bee or Waiting bee. After returning to the hive, the bee colony again evaluates the profitability of the honey source, selects the bee and scout bee with the highest profitability from each group, and re-selects the top N bee with the highest profitability as the lead bee to continue collecting honey. In the process of searching for the optimal solution by the artificial bee colony algorithm, the lead bee has the function of maintaining an excellent solution. Followers who lead the bee recruitment have the effect of increasing the convergence speed of the algorithm. Scouting bees have the effect of avoiding local optimal solutions. According to the basic principle of the artificial bee colony algorithm, the bee colony size NS is assumed. Among them, the bee is NE. Follow the bee size to NU. Where S = RD is the individual search space. Among them, S
NE
is the space for collecting bee population. Use X (0) to indicate the initial bee population. X (N) represents the N generation of bee populations. Randomly NS feasible solutions (X1, X2, ⋯ , X
NS
) under given boundary constraints, the specific way is (5).
Calculate the value of the profit function of each feasible solution separately. The formula for calculating the profitability is as follows (6):
Where fit
i
is the function value of the i feasible solution. Sort the initial feasible solution yields and use the solution of the top NE as the initial bee population X (0). For the bee X
i
(n) of the n-th step, search for the new position in the field near the current position by the formula (5), and the search formula is:
Each follower bee selects a bee according to the size of the bee. And search for new locations in its field. The probability of selection for an individual in the bee population is:
Parameter settings
The image segmentation experiment is based on artificial population optimization of fuzzy C-means and gray image segmentation numbers. The experimental test image size is 240×160, and the general control parameters are set as follows: the maximum calculation frequency of the fitness function is 100, the minimum area size is 1000, and the ratio of unmarked pixels is 0.25. In this paper, the number of members of the initial population is set to 20, the number of regions is selected as 4 values 2, 3, 4, 5, and the upper limit of the Pareto solution is 0, 5, 10, 15, 20. In order to obtain better performance parameters (estimated number of regions and upper limit solution), 20 sets of (4 x 5) pretreatment experiments were first performed. The optimal value of the total consistency error is 0.091328, the number of regions is 4, and the upper limit is 5. The sub-optimal value S_Dbw value is 0.067871, the number of regions is 3, and the upper limit is 5. Since the region value is selected too high or too low, convergence Slower. Therefore, predicting the number of regions by a small number of pre-treatment experiments is a more robust solution. In this article, the number of regions is set to a larger value. Table 1 shows the prediction parameters for 5096 and the other 3 images.
Prediction parameters of five images obtained from pretreatment experiments
Prediction parameters of five images obtained from pretreatment experiments
In order to verify the effect of the algorithm, Matlab was used as a simulation tool to simulate the algorithm. The specific parameters of the computer used in the experiment are: Intel Core i5 processor, the main frequency is 3.2 GHz, and the memory is 4 G. The algorithm parameters are set to the number of bee colonies N p = 20, the fuzzy factor f e = 2, and the maximum number of cycles maxCycle = 250. The algorithm and the traditional algorithm are applied to three different test charts for image segmentation and contrast experiments. The ABC-FFCM algorithm is based on the artificial bee colony FFCM algorithm. The three different test charts are Rice, Cameraman, and Lena, each with a size of 256×256.
Discussion
In order to test the performance of the proposed algorithm, the composite image, grayscale image and medical image are segmented, and the obtained results are compared with the traditional algorithm. The experimental image selects the gray image, the gray level is L = 256, the format is JPEG format, the running environment is Matlab, the algorithm parameter selects the bee group size N p = 20, the fuzzy index f e = 2, the maximum iteration number L i = 10. The cluster number n is selected as 3, 4, 5. The segmentation algorithm is used for segmentation, and the results are shown in Fig. 1. It can be seen from the segmentation results that the segmentation effect of the proposed algorithm is robust and relatively good.

Comparison of composite image segmentation results.
The grayscale image Lena is selected for segmentation, and the result is shown in Fig. 2. It can be seen that compared with the traditional segmentation algorithm, the fuzzy C-means and artificial bee colony-optimized gray image segmentation not only successfully extracts the main target object from the image, but also displays the detailed information of the image, and the image segmentation effect is more obvious.

Comparison of Lena image segmentation results.
In order to further verify the superiority of the algorithm in this study, three commonly used validity indices were used to measure the quality of the segmentation experiment results. The validity index experiments were performed on the Lena diagram and the noisy graph. When n = 3, 4, 5, the results of the algorithm of this study are shown in Table 2.
Effectiveness index for Lena diagram
According to the definition of X B , the clustering effect based on fuzzy C-means and artificial bee colony optimization gray image segmentation algorithm is better. When n = 4, although the X B of the research algorithm is larger than the traditional algorithm, the values are very close. The grayscale image Pepper is selected for segmentation, and the result is shown in Fig. 3. It can also be seen from Fig. 3 that compared with the traditional segmentation algorithm, the fuzzy C-means and the artificial bee colony optimized gray image segmentation can correctly segment the main information. Especially the image edge information, the image boundaries are continuous and clear.

Comparison of Pepper image segmentation results.
Although the effects of noise can be reduced to some extent, they are still sensitive to heavy noise, and the classification error of some pixels is still very serious. In this paper, the gray image segmentation algorithm based on fuzzy C-means and artificial bee colony optimization uses negative logarithm values that are insensitive to noise and outliers to characterize dissimilarity metrics, so that the relationship between pixels and clusters can be more accurately described. At the same time, based on fuzzy C-means and artificial bee colony optimization, the gray image segmentation algorithm introduces the label field to reflect the global spatial information of the image, and establishes the correlation between adjacent pixel regions of the observation field, which can improve the algorithm. Traditional algorithms also have local spatial information, but the algorithm itself does not consider global information. In the face of some regional noise, this simple algorithm using neighborhoods seems to be powerless, so traditionally it is not possible to make full use of the effective information of the image, and the strong gender is also limited. The two-dimensional histogram in Fig. 3 is projected onto the gray level to generate a one-dimensional gray histogram, and the three algorithms are compared from time complexity. The result is shown in Fig. 4.
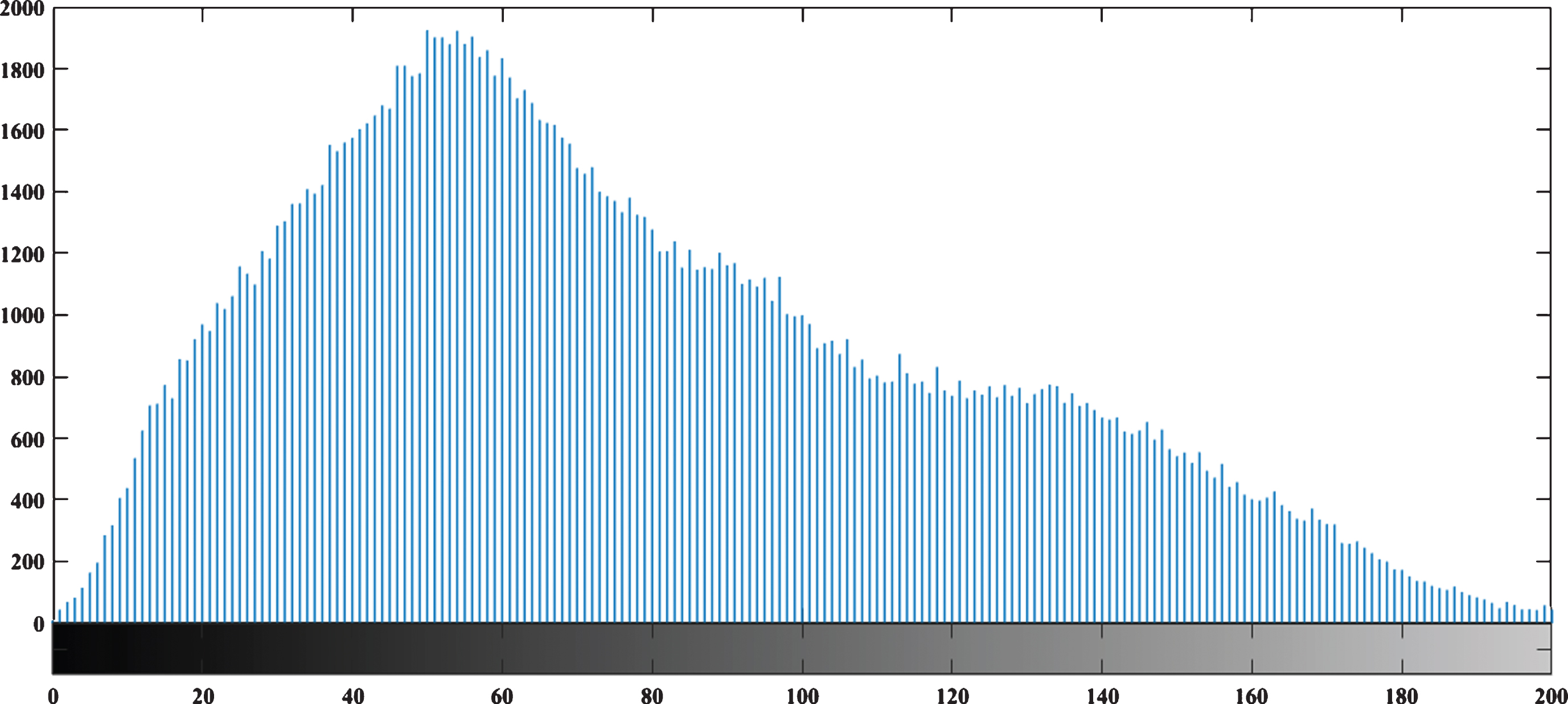
One-dimensional histogram after projection.
Compared with the gray histogram in Fig. 4. It can be seen that the peaks and valleys in the above projected grayscale gradient histogram are easier to distinguish. Therefore, the number of peak points can be obtained because the number of clusters of the fuzzy clustering algorithm and the pixel points corresponding to the peak points in the histogram can be used as the initial clustering center of the fuzzy clustering algorithm. When n = 3, 4, 5, the number of cycles and time-consuming results in Fig. 4 of this study also indicate that the segmentation algorithm proposed in this study is superior to the traditional algorithm.
Image segmentation plays an important role in image engineering. It is also an integral part of the transition from image processing to image analysis. It has been widely used in various fields. However, due to the uncertainty and ambiguity of the image itself, the traditional segmentation method usually can not obtain a good segmentation effect, so it has a certain impact on the final result analysis. In this paper, gray image segmentation based on fuzzy C-means and artificial bee colony optimization is studied. The main purpose is that the algorithm is sensitive to the initial clustering center. Analyze and propose corresponding improvement measures to optimize the segmentation performance of the algorithm. The main work of this paper is as follows:
(1) Using artificial bee colony to optimize the kernel fuzzy C-means clustering algorithm. The improved artificial bee colony algorithm is used to optimize the optimal clustering center, and the kernel fuzzy C-means clustering algorithm is used to guide the clustering. In this paper, the clustering accuracy and running time of kernel fuzzy C-means clustering algorithm based on improved artificial bee colony optimization are adopted. It proves that the algorithm takes less time and can achieve higher precision.
(2) Based on the previous studies, a gray image segmentation algorithm based on fuzzy C-means and artificial bee colony optimization is proposed. The algorithm can overcome the defect that the standard FCM algorithm has higher requirements on the initial clustering center to some extent. And overcome the premature problem of genetic algorithm in traditional algorithms. The convergence speed has also been improved.
(3) Although the algorithm can segment images well, the algorithm still has certain performance limitations on image segmentation in complex backgrounds. Therefore, it is urgent to improve and optimize future work.
Footnotes
Acknowledgments
The authors would like to express their sincere thanks to the responsible editor and the anonymous referees for their valuable comments and suggestions, which have greatly improved the earlier version of our paper.