
Abstract
The reasonable ranking of web pages is an important step in the realization of search engine technology, and plays a key role in improving the information quality of high retrieval and presentation web pages. In this paper, the authors analyze the application of deep learning and BP neural network sorting algorithm in financial news network communication. According to the historical data of users in the process of searching and browsing, we can extract the potential connection between the information of the page itself and the user’s behavior habits, so as to mine the user’s potential preference page. Finally, we use a variety of technologies to mix recommendation and sorting. By observing the effect of multiple training, it is found that the convergence speed of the network model is fast, the training time is short and the training effect is good. We need to fully understand the characteristics of financial news communication in the new media era, and then fully grasp people’s financial news reading habits on this basis, and then put forward the innovative mode of financial news communication in the new media era on the basis of these two points.
Introduction
With the rapid development of electronic information technology in modern society, we have gradually entered a new media era [1]. Under the influence of this new media era, the communication mode of financial news and the audience’s acceptance mode of financial news have undergone profound changes [2, 3]. Therefore, we need to analyze the characteristics of the financial news communication mode in the new media era, and then explore the financial news communication mode in line with the characteristics of the new media era, in order to promote the efficient and high-quality communication of financial news [4].
With the country gradually stepping into a learning society, the demand and attention of the country and Society for knowledge and talents are gradually increasing. As an elite group receiving higher education, the learning situation of financial news directly affects the depth and breadth of the learning society, so it is more and more practical to study the learning situation of financial news [5]. To evaluate the learning of financial news, we should not only measure the breadth and quantity of knowledge, but also examine whether financial news is good at connecting new ideas with the original knowledge structure, and ultimately obtain the ability to solve problems, that is, deep learning ability [6, 7]. The rapid development of global information technology has changed the learning mode of financial news. A large number of financial news are in shallow learning for a long time, which will greatly limit the school’s ability to solve problems and innovate [8]. By analyzing and predicting the mode of financial news communication, this paper can help financial news adjust their learning state in time, and also provide scientific guidance for the media education reform.
BP neural network is a kind of artificial intelligence algorithm, which has strong nonlinear mapping ability, self-organization and adaptive ability [9, 10]. Therefore, based on the statistics of NSSE China, this paper constructs a mathematical model to evaluate the in-depth learning level of financial and economic news, so as to provide some reference value for the research of financial and economic news communication mode.
In the era of new media, news reflects a strong timeliness, which is one of the main characteristics of news in today’s era. In the traditional era of news communication, the main way for people to get news is newspapers and television, which can not guarantee the timely report of news [11]. Under the function of network technology, people can release relevant news information in real time with the help of network media, and have a real-time understanding of the development process of news facts, thus enhancing the timeliness of news [12, 13]. At the same time, the interaction of news has been enhanced. Readers can discuss news events and interact in a relatively open network environment [14]. For example, using simple voting to understand the public’s attitude towards news events is conducive to the dissemination of correct views and further promoting the stable development of society. With the widespread application of network technology, a large number of self media have emerged, which has injected vitality into the development of media field. The combination of self media and news report is determined by the interaction of news communication and the diversity of communication subjects in the current era, which is the inevitable trend of news development.
Related work
The concept of deep learning was first proposed by scholars as ference Marton and Roger saljo in 1976. Through an experiment, they summed up two different learning strategies of financial news learning, that is, shallow learning strategy and deep learning strategy [15, 16]. They think that shallow learning refers to remembering the principles or facts mentioned in the book without thinking, and focusing on the contents mentioned in the book encountered in the test; while deep learning refers to understanding the whole book The focus of attention is how to apply the knowledge of books in real life [17].
After a long-term in-depth study of deep learning, the domestic scholar he Ling has made a more accurate definition of deep learning [18–20]. The so-called deep learning means that on the basis of understanding learning, learners can critically learn new ideas and facts, and integrate them into the original cognitive structure, be able to connect with many ideas, and be able to transfer existing knowledge to new situations, make decisions and solve problems [21].
Deep learning can be generalized and summarized according to Bloom’s taxonomy of educational goals. In the field of cognitive learning, bloom et al. Classified the educational goals into six categories, from the lower level to the higher level, they are memorization, understanding, application, analysis, synthesis and evaluation [22]. The cognitive level of shallow learning stays at the first and second levels, while the cognitive level of deep learning corresponds to the following four levels. Therefore, this paper argues that deep learning refers to the critical acceptance of new knowledge, through the integration of the original knowledge, build their own knowledge system, and obtain the ability to solve problems.
The focus of this paper is the financial news group. Compared with the financial news group, the financial news group has more independent learning time and more abundant extracurricular activities, and the content and access to teaching resources are more extensive and convenient [23]. Therefore, the learning mode of financial news is more independent learning mode, which is also an important difference between the financial news group and the Chinese financial news group First, financial news has really become the main body of learning activities [24]. At the same time, because financial news is about to leave the campus and enter the society, the particularity of this role determines that university education should pay more attention to the cultivation of financial news innovation and problem-solving ability, that is, deep learning ability. However, the current research finds that a large number of financial news is in a shallow learning state for a long time, which will be detrimental to social progress in the long run, so the cultivation of financial news deep learning ability has greater research value.
Theoretical analysis
Similarity-based link prediction method
The problem of link prediction in social networks was firstly modeled by the Markov chain, which is a guide for the study of link prediction. The methods based on node similarity indicators include indicators based path, indicators based on common neighbor information, and indicators based on random walks.
1. Indicator based path
The probability of a link between nodes in a network can be calculated using the length of the path between nodes.
1) Shortest path algorithm
The smaller the path length between two nodes, the greater the similarity of nodes. The formula for calculating the similarity of nodes is as follows:
2) Katz algorithm
Compared with the shortest path algorithm, the Katz algorithm takes more comprehensive consideration of the path information of the node in the network and more network topology information. Moreover, the algorithm weights all paths between two nodes in the network. The Katz algorithm exponentially decays path calculations of different lengths, and the node similarity score is calculated as follows:
Among them, |paths (x, y, 1) | represents a set of all paths of length 1 between nodes x and y. β (0 ≤ β ≤ 1) is a parameter that controls the influence of the path length on the node similarity.
3) LHN2 algorithm
The HN2 algorithm is the Leicht-Holme-Newman Index algorithm, which is a variation of the Katz algorithm. The idea of the algorithm is whether the two nodes are similar and whether they are closely related to their neighbor nodes. The algorithm uses the idea of recursion, and the similarity calculation formula of nodes is shown in Equation (3):
4) Local path similarity algorithm
The local path similarity algorithm is abbreviated as LPA, and the algorithm idea is very simple, that is, the node of the target node path length 1 and the node of the target node path length 2 are counted. The similarity calculation formula of the node is shown in the formula (4):
In the formula, A is a path matrix describing the network, and ɛ is a parameter ranging from –1 to 1. The different exponential forms of A represent the number of different paths whose length is an exponent. The local path algorithm is a local algorithm and its time complexity is low.
2. Indicators based on common neighbor information
1) Common neighbor algorithm
The co-neighbor is the pair of nodes x, y. The remaining nodes in the network are sorted in descending order according to the number of their co-neighbors. The more the number of common neighbors, the greater the probability of having edges between the two nodes. τ (x) , τ (y) are used to indicate the degrees of nodes x and y, respectively. The similarity is calculated according to the following formula:
2) Jaccard algorithm
The main idea of the Jaccard algorithm is to use the ratio of the intersection and union of neighbor nodes between nodes x and y. This ratio is a score for the similarity between two nodes. The calculation formula of the similarity score of the algorithm node is as follows:
3) Adamic-Adar algorithm
The Adamic-Adar algorithm is mainly to calculate the similarity between two web pages. When calculating the similarity of web pages, the algorithm first finds all the public keywords in the two web pages, then sums the importance of all the keywords, and calculates the weight value of the public keywords. The word frequency of the keyword is F, and the importance of the keyword is W, then W is inversely proportional to 1/ -F. The common neighbor of the node is C, and the degree of the node is D. According to the algorithm, the formula for calculating the similarity score is obtained:
4) Resource Allocation algorithm
The formula for calculating the similarity score in the RA algorithm is as follows:
Formula (8) is extended, and after considering more information, the improved formula is:
3. Indicator based random walk
The Random Walk algorithm is based on random walks to define similarity. Its basic assumptions are: The similarity between the starting node and the target node is determined by the average number of steps from the starting node to the target node.
The link prediction algorithm based on random walk has methods such as Average Commute Time, Random Walk with Restart, Local Random Walk and SimRank algorithm.
1) Average Commute Time Algorithm
Assuming that m (x, y) is the average number of steps a walker needs to go from node x to node y, the ACTs of nodes x and y are defined as:
2) Random Walk with Restart Algorithm
The basic idea of the random walk algorithm with restart algorithm is to assume that when the random rambler takes a step, he returns to the initial position with a certain probability. The formula for calculating the similarity score between nodes is as follows:
3) Local Random Walk Algorithm
Local random walk algorithm LRW only considers random walks with finite steps. In the algorithm, a walker starts to walk from node x at time t. Assuming that the probability that the walker just reaches node y at time t + 1 is π xy (t), then the probability formula for the model to stabilize is: π x (t + 1) = p T π x (t) , t ≥ 0. The formula for calculating the similarity score is as follows:
Path Sorting Algorithm PRA is an algorithm for random walks on graphs proposed by Lao and Cohen. The algorithm is mainly applied to knowledge reasoning and link prediction in the knowledge base, and it is also applicable to the problem of link prediction in the small knowledge base of the student online learning system. The PRA algorithm is similar to the remote monitoring method. The set of entities connected by path relationship p, and the PRA performs a random walk on the graph, starting from all source nodes. The path to the target node is successful, and the quality of these paths can be determined by measuring their support and precision as in the association rule mining. The path predicted by the PRA algorithm link can be treated as a rule. Because multiple rules or paths may be applicable to any given pair of entities, experiments can fuse these multiple rules through a binary classifier (logically implemented). In the PRA algorithm, the eigenvalues are the probability values of these different paths from the source node to the target node.
The PRA algorithm sorts the Node y associated with the query node x. PRA The algorithm begins with a list of path types that enumerate a large number of length limit markers, which are considered “expert” rankings. Each of the random walks on the graph is performed according to the type constraint of the edge type, and the result nodes y are sorted according to the weight values in the result distribution. Finally, the PRA algorithm combines these “experts” with logistic regression. Markov chain as shows in Fig. 1.

Markov chain.
The path sorting algorithm PRA is specifically described as: the relationship path p is defined as a sequence of relationships (R1, R2, …, R i )
Moreover, in order to highlight the type of each step, p can also be described as:
Among them, T
i
is defined as
Nodes can be connected to each other through different types of relationships, which can be represented by paths:
For any one of the relationship paths p = (R1, R2, …, R i ), one seed node s ∈ domain (p) is selected. A random walk of a path constraint is recursively defined as a distribution h s , p. If p is an empty path, then
If p = R1, R2, … R i is non-null, then
p′ = R1, R2, …, Ri-1, h s , p is defined as follows:
Among them,
θ i in the above formula is the path weight value. Moreover, the node e related to the query node s is sorted according to the following scoring function.
p1 in the above formula is a relation path set whose length is less than or equal to 1.
The algorithm uses the gradient descent method to calculate the path weight parameter θ, and it gives a set R and a set of node pairs {(s i , t i )}. At the same time, the experiment can construct a training data set D ={ (x i , r i ) }. Among them, x i is a path eigenvalues vector of all node pairs (s i , t i ), the j-th component of x i is R (s i , t i ), r i indicates whether it is a true parameter, and θ is estimated using the maximized value of the regularized objective function below:
The λ1 control L1 regularization in Equation (17) and help structure selection and λ2 controls L2 regularization, which prevents overfitting. w i is the importance weight value for each instance, and O i (θ) is the objective function of each instance, which is defined as follows:
Among them, p i is the predicted correlation value and is defined as follows:
This paper uses the data collected by NSSE China questionnaire to build a prediction model of financial news deep learning level. It is found that artificial neural network is a very effective method to build prediction model. BP neural network is one of the most widely used artificial neural network, which has strong nonlinear mapping ability, self-organization and self-adaptive ability. Therefore, this paper chooses to use BP neural network to build the prediction model of financial news deep learning level.
The Neural network model is also an algorithm that can be used for link prediction, and the method used to build the a priori model is to treat the link prediction problem as a matrix complete. The algorithm treats the link prediction problem as a very large sparse three-dimensional matrix S × P × E. G and E are the number of entities, and P is the number of link relationship. If there is a link relationship P from source node S to destination node O, then G (s, p, o), otherwise G (s, p, o) = 0.
Potential low-dimensional vectors are associated with each entity and link relationship, after which a low rank decomposition is performed on this vector and its inner product is computed.
σ (x) = 1/ -(1 + e-x) in the above equation is a nonlinear action function of the neuron, and K is approximately equal to 30, which is the dimension of the hidden layer. u s , w p , v o a is a K-dimensional vector that inserts discrete markers into the low-dimensional semantic space.
The probability value calculation model of formula (20) can continue to be improved by associating different vectors with each link relationship. The specific calculation formula is as follows:
f (x) a is a nonlinear activation function of the hidden layer of the neural network, which is similar to the tanh function. It is known from Equation (21) that this model requires O (K × E + K × K × M × P) number of parameters, and the amount of calculation is very large. It is also necessary to continue to improve this algorithm, and each link relationship P is associated with a vector, as in Equation (20). However, a standard multilayer perceptron (MLP) is used to capture the interaction conditions. A more accurate model can be expressed by Equation (22):
A in Equation (22) is a L × 3K, which represents the weight matrix of the first layer. β is a vector of column L, which represents the weight vector of the second layer. This calculation method only requires O (L + LK + KE + KP) number of parameters, and the calculation amount is much reduced, but the same effect as the formula (21) can be achieved.
Compared to the path sorting algorithm, r i indicates whether R (s i , t i ) is true or not. If there is a link between nodes s i and t i then r i = 1, otherwise r i = 0. In the improved algorithm MPRA, the calculation formula for r i is:
Therefore, the algorithm pseudo-code of the improved algorithm based on path sorting algorithm MPRA is as follows: A path set {P1, P2, … P
n
} is given, the set of nodes {e1, e2, … e
m
} in the test set is given, and the target node is a node o.
Because there are 5 comparable indexes among media involved in the questionnaire, the number of neurons in the input layer is set as n = 5. Among them, X1 indicates the news challenge, which includes the meaning of financial news individual and media organization — it not only reflects the learning behavior of financial news and the investment of time and energy in news, but also indirectly demands, standards and supports for news through the behavior performance and self-report of financial news The degree of holding is evaluated to reflect the education quality of the media. Purchase; x2 refers to the level of active cooperative learning of media, which evaluates the cooperative learning ability of financial news and the ability to discuss with multiple groups. X3 refers to the interaction between students and teachers. It evaluates the frequency, initiative and quality of the interaction between financial news and teachers. X4 indicates the richness of news experience and evaluates the effectiveness of news practice, including organizational validity, illustrative examples and effective feedback. X5 indicates the support of news environment.
This paper is mainly to evaluate the in-depth learning of financial news. The ultimate goal is to get an objective and accurate quantitative value that reflects the level of in-depth learning of financial news. Therefore, this paper takes the quantitative value of financial news deep learning level as the output vector of BP neural network, that is, the number of neurons in the output layer is determined as M = 1.
In order to eliminate the order of magnitude difference among the dimensional data and avoid the large prediction error caused by the large order of magnitude difference between the input and output data, the neural network will generally normalize the data. In this paper, the function of formula
The selection of transfer function is related to the value range of input data and output data. After many experiments and observing the training effect of the network, the transfer function parameters of the first hidden layer are determined as S-type tangent function, the transfer function parameters of the second hidden layer are determined as S-type pair function, and the transfer function of the output layer is determined as linear function.
The overall process diagram for this experiment is shown in Fig. 2:
News recommendation.
By observing the effect of multiple training, it is found that the convergence speed of the network model is fast, the training time is short and the training effect is good. The default value of BP neural network toolbox is selected for other function parameters.
The training parameters of the network are set according to the performance of the network. Among them, setting the maximum training times of the network to 100 times means that the network does not converge and the training stops if the network still does not converge beyond this time; setting the maximum confirmation failure times of the network to 15 times, that is, the verification error of the network does not decrease for 15 times in a row, which means that the training effect of the network is not good and the training stops; setting the training goal of the network to 0.003, when the network’s When the target error reaches the target value, the training stops. The experimental design is composed of three parts as a whole: (1) The preprocessing process of the source data; (2) Generating the graph according to the knowledge network model of online education; (3) Calculating the result and outputting it by using the algorithm selected by the paper and the improved algorithm.
It can be seen from Table 1 and Fig. 3 that among the several algorithms studied in this paper, the random walk with restart algorithm RWR has the least running time. This is because the RWR algorithm is a local algorithm, and the network constructed using the data set of this paper has the least structural information, its running time is slightly less. However, the running time of the algorithm SWR is much more than other algorithms. The comparison chart shows that the running time of the PRA and MPRA algorithms is an order of magnitude, there is no big difference between the two, and the MPRA algorithm runs a little longer. The reason is that the improved algorithm adds an operation of calculating the probability of a link between two nodes based on the PRA algorithm. Therefore, its running time is lengthened.
Results table of running time
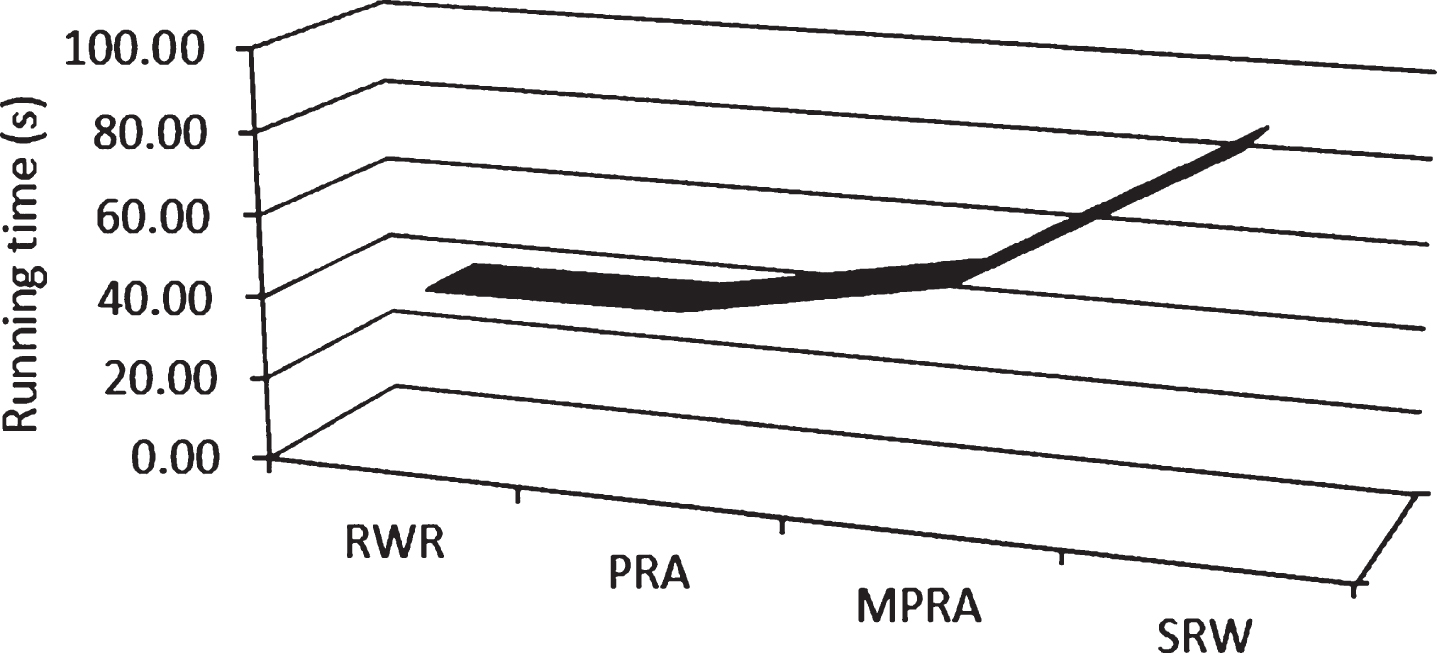
Statistics chart of running time.
The accuracy of the algorithm is measured by two indicators, Precision and F1. In this paper, only the indexes of the algorithm used in the online high school mathematics learning system network are calculated, and the Precision and F1 values of the five algorithms are obtained respectively. The specific results are shown in Table 2 and Fig. 4 below.
Statistics table of Precision and F1 values of the link prediction algorithm
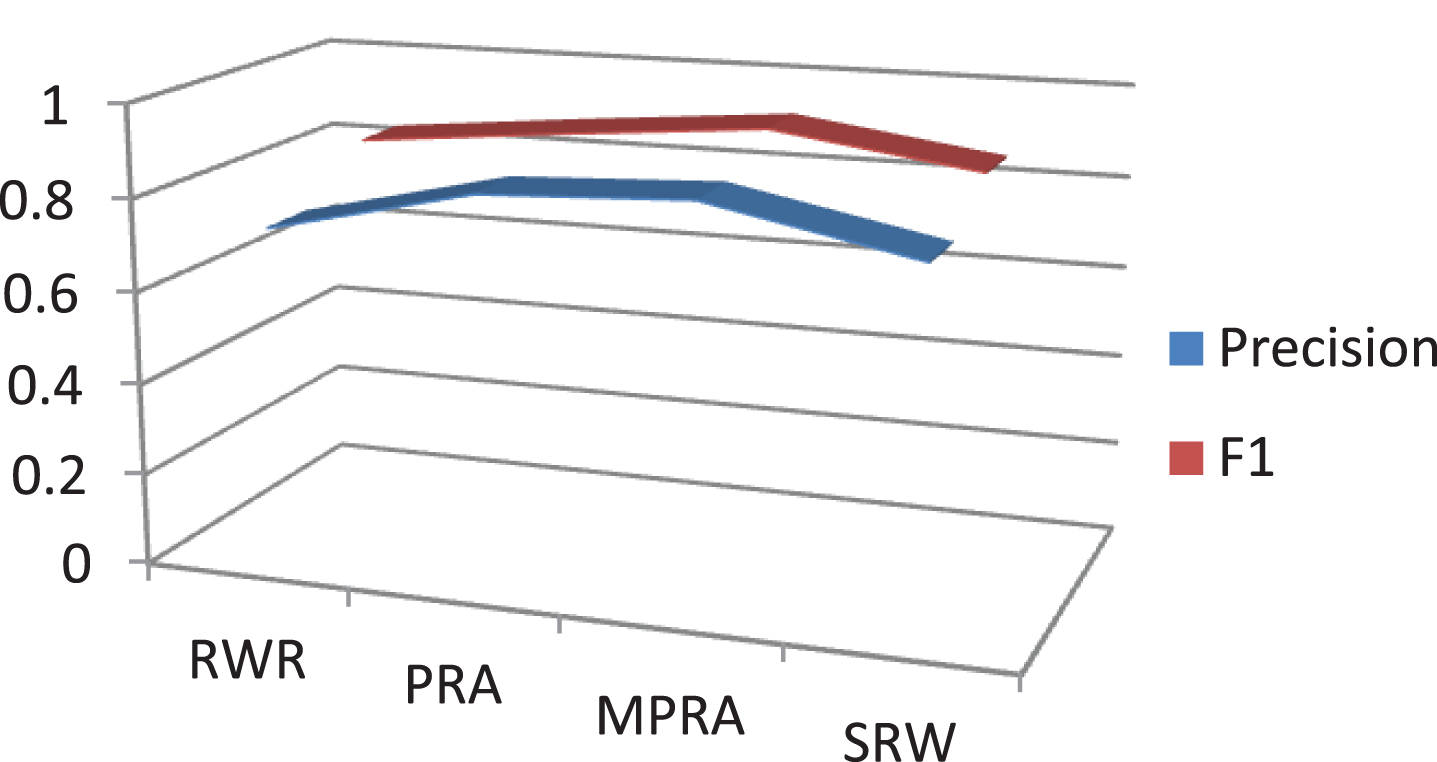
Statistics chart of Precision and F1 values of the link prediction algorithm.
The improved algorithm MPRA has significantly improved the prediction accuracy. This shows that the improved algorithm is better than the original path sorting algorithm. Moreover, it also shows that the weight value of the path has an important influence in the experiment, and the accuracy of the link prediction of the algorithm is improved. However, in a network with a large average number of paths, the accuracy of link prediction is relatively lower, which indicates that the applicability of the weight value of the path has certain limitations.
The experimental results of different algorithms are analyzed and compared by using the accuracy evaluation indexes of Precision and F1 algorithms. It is found that the link prediction accuracy of the improved algorithm MPRA algorithm is relatively high, and its value is 0.916. According to the characteristics of the graph generated in the experimental knowledge network model, we know that the average number of paths is relatively small, and the MPRA algorithm is more suitable for networks with smaller average paths. The experimental results show that the MPRA algorithm comprehensively considers the weight values of all paths from the source node to the target node in the network and improves the link prediction accuracy of the path sorting algorithm PRA.
The MAE comparison between the traditional PRA algorithm and the MPRA algorithm in number of different nearest neighbors is shown in Table 3 and Fig. 5. It can be seen from the figure that the improved algorithm has a smaller MAE value, indicating that the improved MRWR algorithm effectively solves the problem that the user project evaluation matrix cannot measure the similarity between users and projects through the traditional similarity algorithm under extreme sparse conditions. In the calculation of similarity, the algorithm uses valid information by calculating the union rather than the intersection, and predicts the score, and then calculates the similarity. This algorithm improves the accuracy of calculating the similarity of the project, thus effectively improving the recommendation quality of the recommendation algorithm.
Statistical table of MAE comparison of two algorithms

Comparison chart of MAE values of two algorithms.
The MAE values of the three algorithms in different numbers of nearest neighbors, as shown in Table 4 and Fig. 6.
Comparison table of MAE values of three recommended algorithms

Comparison chart of MAE values of the three recommended algorithms.
It can be seen from the figure that in the case of the same number of neighbors, the MAE values of the RWR and SRW algorithms are almost the same, but the MRWR algorithm is smaller than both, indicating that the algorithm has better recommendation quality. The hybrid collaborative filtering algorithm predicts the user’s unrated project scores by similar items, and fills in the sparse user project evaluation matrix, which better solves the problem of data sparseness. At the same time, the similarity between projects can be calculated offline, reducing the computational overhead and improving the efficiency of real-time recommendation. Experiments show that the hybrid collaborative filtering algorithm can achieve the purpose of improving the recommendation quality.
Timeliness of financial news
The timeliness of financial news is one of the main characteristics of financial news in the new media era. In the era of traditional media communication, people get financial news through newspapers and TV financial news. Newspapers are usually daily newspapers. The financial news that people see is often what happened one day ago. It is also possible that when people finally see financial news, the facts in financial news have been solved and dealt with, or the situation in financial news has been dealt with To the new development, television financial news is the same, timeliness is poor. However, in the era of new media, people can easily access the Internet through a variety of mobile terminal devices, so as to obtain a variety of real-time published information. Even when some financial news facts just happen, people can see relevant reports. In this way, the gap between the development of financial news and financial news facts obtained by people will be infinitely narrowed, and financial news will be improved The timeliness of. The advantage of improving the timeliness of financial news lies in that people can pay attention to the development of the situation at the same time, make relevant decisions according to financial news in time, improve the value of financial news and improve the correctness of decision-making.
Increase the interaction of financial news
The interactive enhancement of financial news is an important feature of financial news communication in the new media era. In the traditional era of media communication, financial news is one-way communication. The consumers of financial news are only the audiences of financial news. They can’t express relevant opinions on financial news, let alone influence the formulation of some policies by influencing the authorities, which seriously affects the exertion of public rights and is not conducive to the formation of a strong social state. In the new media era, the interaction of financial news has been greatly enhanced. Behind many financial news, there are simple votes to test readers’ attitudes towards the facts in financial news, and there are corresponding comment areas for readers to freely express their opinions and interact with editors, readers and readers. Through such interaction, the society can form a relatively consistent opinion on the facts in the financial news in a relatively wide range, promote the dissemination of correct views and the harmonious and stable development of the whole society, rather than find no vent to encourage the whole society’s grumpiness.
Media wide news dissemination
The whole media of financial news communication is a distinctive feature of financial news communication in the new media era. In the traditional financial news communication, the main media of financial news communication is newspaper and TV, and the main way of communication is text, picture and voice. In the new media era, the financial news communication gradually develops to the whole media, mainly including two aspects: first, the whole media of financial news communication form. The main performance is that the financial news communication has changed from traditional words and pictures to all-round presentation of words, pictures, animations, sounds and images. This has formed a variety of sensory stimulation for people, increased the interest of financial news and people’s attention to financial news, and promoted the in-depth dissemination of news. The second is the full media of financial news media. With the development of modern electronic information technology, mobile phones, computers, tablets and mobile reading devices have become the media of financial news communication. Financial news communication, together with traditional TV and newspapers, not only conforms to modern people’s reading habits, but also enriches people’s reading forms of financial news, widens people’s access to financial news, so that people can get it anytime and anywhere Take various forms of financial news.
Timeliness of news communication
The full-time nature of financial news communication is the prominent feature of financial news communication in the new media era. In the era of traditional media, financial news communication has a certain frequency, which is usually one day or half a day, and can not get all kinds of financial news information anytime and anywhere. In the era of new media, financial news communication shows the characteristics of full-time. Financial news from any place will be transmitted to the network by people. People can learn the latest financial news from all over the world anytime and anywhere, and can keep pace with the world. No matter in the late night or in the early morning, as long as there is financial news reading equipment and access to the Internet, we can know all kinds of financial news information anytime and anywhere, making up for the past long time interval of financial news release and the lag of financial news acquisition.
Conclusion
Under the influence of new media, the content of financial news shows the phenomenon of homogeneity. In order to stimulate the readers, some financial news organizations begin to use some financial news which are grandiose, exaggerated, extreme and seriously distorted. This has seriously affected the healthy development of news. Therefore, in the era of new media, if we want to innovate the mode of news communication, we must do the opposite, insist on reporting the financial news with depth and value, so as to enable readers to think independently, rather than only be stimulated by some extreme remarks. First of all, journalists and editors should have the ability to discover valuable financial news, insist on reporting financial news that has a real impact on people’s lives, has practical significance for social development and has a certain role in national development, and avoid blindly stimulating the audience’s good surprise through all kinds of anecdotes and anecdotes. Secondly, reporters should have a deep coverage of financial news. The depth of financial news is that the mining of financial news can inspire people to think, influence people’s actual behavior, and make people feel the real society. Therefore, journalists should insist on in-depth reporting of financial news, and in the process of reporting financial news, they should report financial news facts, understand the reasons behind the occurrence of financial news facts, supervise and report the handling of financial news facts, and promote the improvement of relevant laws, regulations and policies. Only in this way can financial news fulfill its mission and journalists become the real uncrowned king.
In the era of new media, the financial news communication presents new characteristics, which also affect people’s reading habits of financial news all the time. Therefore, we need to fully understand the characteristics of financial news communication in the new media era, and then fully grasp people’s financial news reading habits on this basis, and then put forward the innovative mode of financial news communication in the new media era on the basis of these two points. We believe that only by deeply grasping the characteristics of financial news communication mode in the new media era and constantly understanding people’s reading habits of financial news, can we put forward innovative financial news communication mode and greatly improve the efficiency of financial news communication.
Footnotes
Acknowledgment
2018 Anhui University of Finance and Economics Teaching and Research Project: “Construction and Reconstruction of Communication Courses under the Vision of New Management”, No.: accjyyb2018064.