
Abstract
Translation has been one of the oldest problems in natural language processing. Despite its age, it is still one where there is a tremendous scope for improvement and creativity; the quantity and quality of research in it is testament to that fact. The subfield of primarily using deep neural networks for translation has recently started to gain traction. Many techniques have been developed using deep encoder-decoder networks for bilingual translation using both parallel as well as non-parallel corpora. There is a lot of potential in applying concepts such as bilingual embeddings to create generic translation architecture, which doesn’t need huge parallel corpora to train. These ideas are particularly pertinent in the case of Indic languages, where it is generally difficult to obtain such corpus. In this paper, we try to adapt some of newest techniques in autoencoder networks and bilingual embeddings to the task of translating between English and Hindi. The models considerably outperform state of the art translating systems for these languages.
Introduction
Recent developments in autoencoders and attention mechanisms for the same have been adapted to model sentences into various types of latent spaces. Models of neural machine translation are often from a discriminative family of encoder-decoders that learn a conditional distribution of a target sentence given a source sentence [4]. A lot of the work done in translating systems today focuses on datasets that the workshop on statistical machine translation (WMT) provides for its various subtasks. However, the tasks so far have not considered translation of English and Indic languages such as Hindi. Hindi is the fourth most spoken language in the world, with over 551 million total speakers [7]. Many other languages of the Gangetic plains are highly related with Hindi. A large section of the subcontinent does not speak English with only around 125 million English speakers, and with the dawn of the digital era which is primarily based in English, this makes such translation efforts immensely relevant and important.
Motivation
One of the ways of looking at translation can be to think of it as a combination of the three subtasks, word imputation i.e. inserting appropriate words in blanks in a given sentence, sentence reconstruction and similar sentence searches; where from the perspective of one language, the other languages are fuzzy inputs which need to be reconstructed. The goal of this paper is to develop an autoencoding technique that is able to map and learn the latent space distributions of sentences in English and Hindi, and create a bilingual map between the two spaces, subsequently allowing for translation. In this paper, we use Bilingual Embeddings to form the basis of a fuzzy match between the inputs for the two languages. We then use a shared encoder which relies on the bilingual embeddings to codify the main themes and ideas of the input for both the languages, with separate decoders for the final translation.
Contributions
The present work is one of the first state of the art neural machine translation system for translation between Hindi and English that performs much better than the reference translation scores mentioned in the IIT Bombay English-Hindi Parallel Corpus [14].
The proposed embedding mapping scheme combines different ideas proposed in recent literature such as a new similarity metric (CSLS) and CCA. The resulting bilingual embedding performance that outperforms other mapping schemes in the word translation task.
The model has similar runtimes to current state of the art neural machine translation libraries. Thus the additional improvement in translation scores does not come at the cost of computational efficiency.
Finally, it is important to note that the approach can be used for semi-supervised translation, where the supervision is in the form of word translation dictionaries used for the task of training the embeddings, by using a backtranslation step instead of a translation step as explained in section 4.3.
Related research
Many neural machine translation approaches fundamentally rely on using an encoder-decoder model to maximize the conditional probability of a target sentence y given a source sentence x i.e. argmax y p (y ∣ x). The simplest approach works reasonably well for short sentences but the performance degrades for longer sentences [20].
Sutveker et al. [25] proposed a sequence to sequence encoder-decoder model using Long Short Term Memory (LSTM) networks where they showed performance improvements to the LSTM network by reversing the source sentences. Cho et al. [9] used the encoder-decoder framework to score phrase pairs in their Statistical Machine Translation (SMT) model. Bahdanau et al. [4] proposed a modification to the encoder-decoder model with a self-aligning attention mechanism, which allowed them to model long term dependencies of different words in the target sentence to the corresponding parts of the source sentence.
Recent successes of variational neural models [12] and their corresponding use to generate sentences sampled on a latent space [6] have led to the development of variational neural machine translating models. Zhang et al. [6] built a variational neural machine translation (VNMT) system using a similar encoder to Bahdanau et al. [4] but with variational inference for the decoder.
A lot of recent research has been focused on building completely unsupervised models for neural machine translation. Artetxe et al. [3] and Lample et al. [15] proposed novel approaches which utilized principles of improving translation performance using monolingual data [23] as well as concepts such as bilingual embeddings [22] to initialize a word translation lexicon [15] or to use for a shared encoding space [3]. This is built on previous research by Conneau et al. [10] and Artetxe et al. [2] on completely unsupervised bilingual mappings to learn shared embedding spaces for the two languages.
Bilingual embeddings
Word embeddings have become a well-studied field of NLP, with some popular methods being Word2vec [17] and GLoVe [19]. The idea of a good embedding is to map words into a dense n-dimensional space such that fundamental semantic relationships between the words correspond to their locations in the space. For example, words with similar meaning should lie close to each other, and also, basic vector operations should make sense, i.e. as an example, the difference between ’boy’ and ’girl’ should be similar to that of ’man’ and ’woman’. Cross-lingual embeddings are those that map similar meaning (semantically) words in nearby regions of space, irrespective of the language they come from.
There are fundamentally 3 schemes used for creating such maps: bilingual mapping, monolingual adaptation, and bilingual training [22].
In the paper, we adapt techniques used for Bilingual Mapping based methods. Further, given that word and corpus data for Hindi is now starting to become available [14], we use a dictionary of parallel words to learn the mapping between the spaces.
Simple supervised case
One of the first models for producing a bilingual mapping was developed by [18]. For this purpose, they use a known dictionary of n = 5000 pairs of words {x
i
, y
i
} i∈{1,n}, and learn a linear mapping W between the source and the target space such that
The solution of the above optimization problem is given by the Moore-Penrose pseudoinverse X+ = (X T X) -1X T with W = X+Y.
Monolingual invariance is needed to preserve the dot products after mapping, avoiding performance degradation in monolingual tasks. What this means is that if the matrix W was not orthogonal, it could have the potential to skew the monolingual word embedding matrix, adding potentially noisy correlation between the different embedding vectors [1]. Thus, we need to enforce an orthogonality constraint on the transformation matrix W. The equation (1) then boils down to the Procrustes problem, which advantageously offers a closed form solution obtained from the singular value decomposition (SVD) of YX
T
:
In order to improve embedding performance, we can use CSLS (Cross-Domain Similarity Local Scaling) similarity measures while training and validating. The idea is based on the following goal: we want to improve the comparison metric such that the nearest neighbor of a source word, in the target language, is more likely to have as a nearest neighbor this particular source word. The reason behind this is that nearest neighbours is not a symmetric relation. This is because for any vector y which has x as one of its k nearest neighbours, it is not necessary that y itself belongs to the k nearest neighbours of x. For embedding vectors, this leads the the famous "hubness" problem, where some vectors tend to become the center of relatively dense clusters [21]. We use the nearest neighbour information to "boost" cosine similarities for isolated vectors, thus re-balancing the density in the word vector space.
We can use this similarity metric to implement a refinement procedure. Using the W★ obtained, we create a synthetic dictionary where we use high frequency words and their corresponding neighbours obtained using the CSLS similarity metric in the other language. We then apply the Procrustes solution with this new generated dictionary. By iteratively applying this procedure we can potentially create more and more accurate dictionaries [10].
Consider a bipartite neighbourhood graph, where each vertex denotes a word connected to its K nearest neighbors in the other language. We denote by
We see that the CSLS similarity for two word vector pairs is now also dependent on the relative density of the word vectors, and thus, by using CSLS as the metric instead of simple cosine similarity, we can avoid the hubness issue.
The idea of Canonical Correlation Analysis is to find a linear mapping of two vectors such that the resultant two vectors have maximum correlation. Intuitively, if we have two words with similar meanings in two different languages, then if they are to be mapped to the same embedding space, the correlation of their embeddings should be maximum [11]. This intuition is borne out of the fact that words with similar meanings tend to appear in similar contexts irrespective of the language.
Let
In the case that we constrain ourself to orthogonal transformations (so as to preserve Monolingual Invariance), we only need one map Σ*, while the other map Ω* can be taken as identity.
While CCA can be used to create a projection map from scratch, it can also instead be used to optimize the embeddings obtained from the Proscutes solution.
Based on experimental results, mapping the Hindi Embeddings to English tended to result in considerably better bilingual spaces. The findings can be attributed to the following two reasons The size of the Hindi Vocabulary was much smaller than the English one (almost 25% smaller). This meant that the relation ended up being less symmetric, which directly leads to poorer results in word translation. Hindi words tended to have a many-one map with English words i.e. many English words mapped to one Hindi word in the parallel dictionary. By mapping English embeddings to Hindi, the "hubness" problem would tend to make word translation results worse.
Word embedding experiments
The word translation task is used to evaluate the embedding performance. The task itself is simple, given a test dictionary of word pairs, the goal is the use the embedding information and nearest neighbours of the embedding in the shared vector space in order to come up with a translated word. This is done for different values of k, the number of nearest neighbours checked in order to determine if there is a match. Thus, the results are obtained as values of precision@k, i.e. the precision of getting a correct translation within the first k nearest neighbours.
The monolingual word embeddings used for the problem were FastText embeddings [5] provided by Facebook trained using Wikipedia corpus of the corresponding language. The embeddings of both Hindi and English are 300 dimensions. 200,000 English words and their embeddings were taken, while for Hindi 158,016 word-embedding pairs were used. A training dictionary of 5000 word pairs was used to seed the Procrustes solution. The word translation task was finally performed on a test set of 1500 unique words in English with the entire vocabulary of Hindi words as possible translations.
The resulting precision scores are reported for different values of precision@ k for k = 1, 5, 10 using the aforementioned Supervised case algorithm with the corresponding improvements. Note that the monolingual target word similarity score for the embeddings was 65.11%. All experiments were performed on an Amazon EC2 instance running an Nvidia V100 GPU chip. The runtime for mapping the embeddings using the proposed technique increases almost linearly with the refinement iterations seen in Fig. 2, with the initial iteration not taking significantly greater runtime than Artetxe et al. [1], which took 34.7s.
The results shown in Table 1 are not far away from expectations considering the differences between Hindi and English. To iterate the point, these scores are similar to those obtained under similar conditions by Lampele et al. [15] for the English-Chinese word translation pairs. The improvement in the word embedding performance using the various techniques is extremely relevant; as in the upstream translation task, the nearest neighbours matching is a closer representation of the proximity of similar meaning words.
Precision scores obtained for different values of precision@k
Precision scores obtained for different values of precision@k
In Fig. 1, some examples of word translation are listed. The cosine similarity of the closest matches ranges from 0.55 to 0.8.
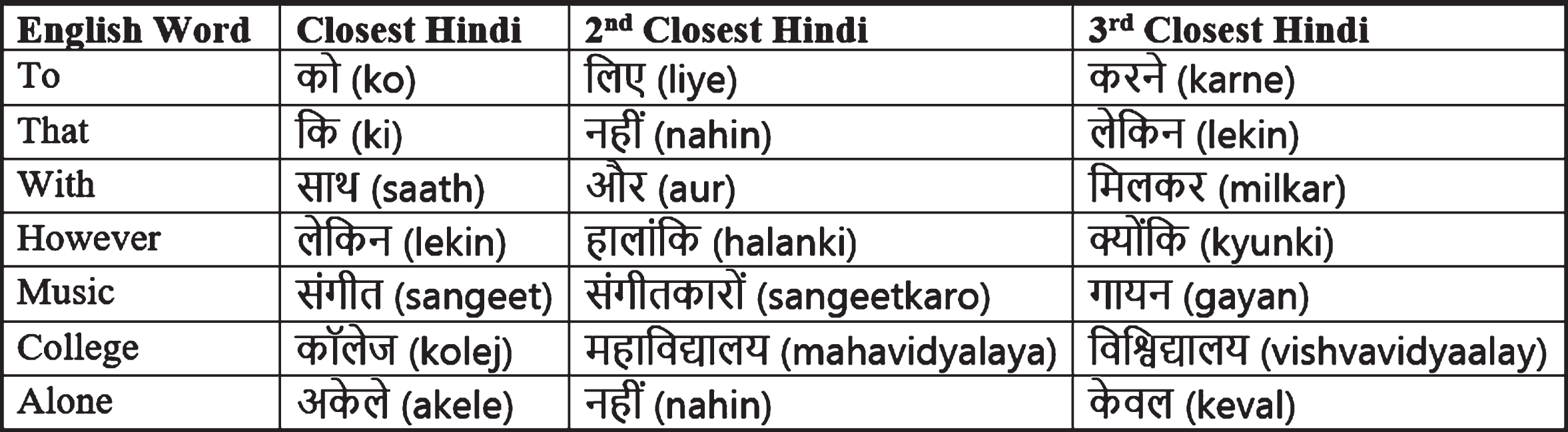
Some sample English words and their translations using the embeddings.
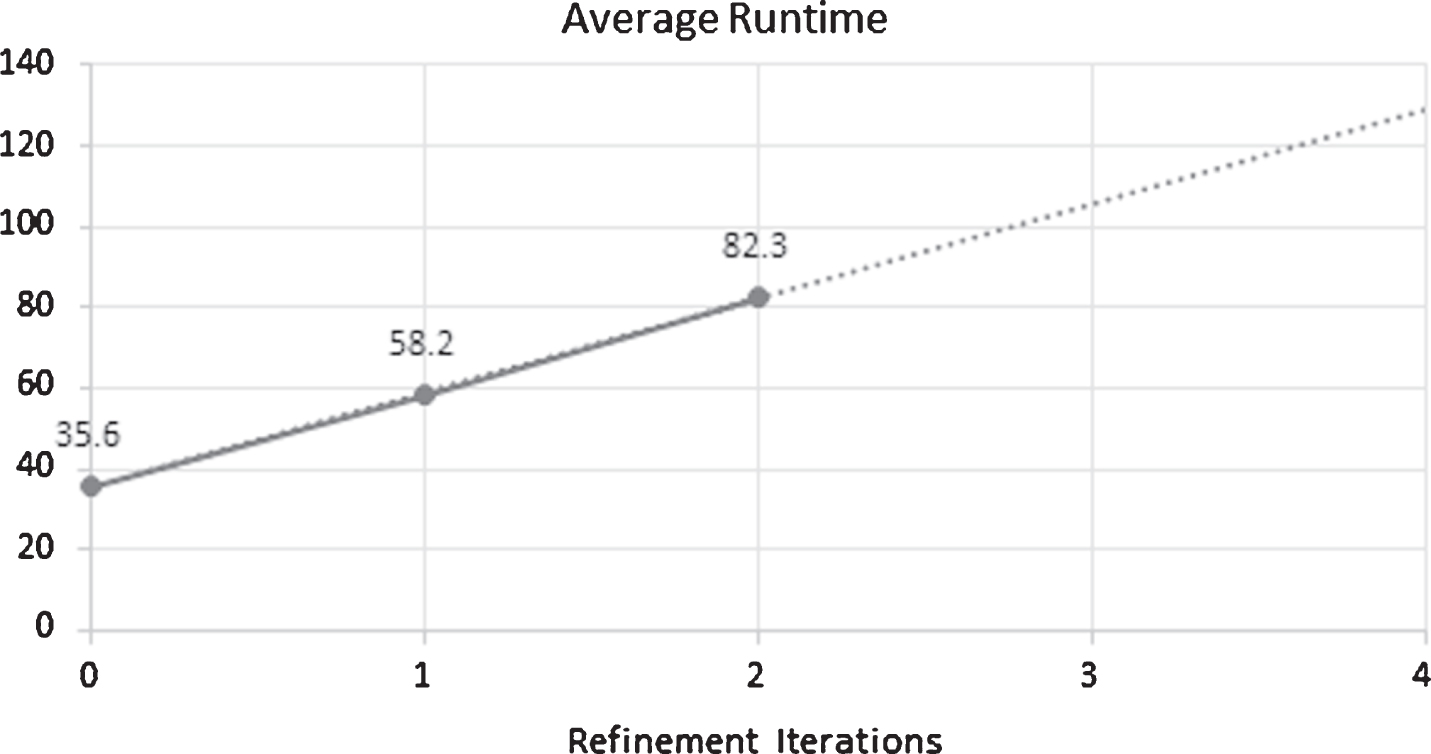
Average runtime for mapping Hindi to English
The basic translation architecture for the problem is as shown in Fig. 3. The attention based encoder and decoder architecture is similar to that proposed by Bahdanau et al. [4] and Sutskever et al. [25], where the LSTM is used for the RNN cells. Thus, both the encoder and decoder are two-layer LSTMs which sequentially read the sentence tokens. The usage of a shared encoder follows from using fixed pre-trained bilingual embeddings. This allows for two advantages, the first being that the number of variables to learn is significantly reduced as compared to standard systems which also have the learn the embedding values for the entire vocabulary, and the second is that the encoder learns to better codify the underlying semantics of the sentence in either language, thus creating a more general encoding scheme. It is important to note that the denoising steps ensure that the model learns to encode structural information about the input sentence for either language as well. Given that Hindi is not an extremely resource rich language i.e. while certain languages have tens of millions of parallel sentences, Hindi and English only have a known curated dataset of upto 1.5 million parallel sentences [14], and many other Indic languages are even more resource poor, the ability of the model to train on lesser amount of data makes it very useful.
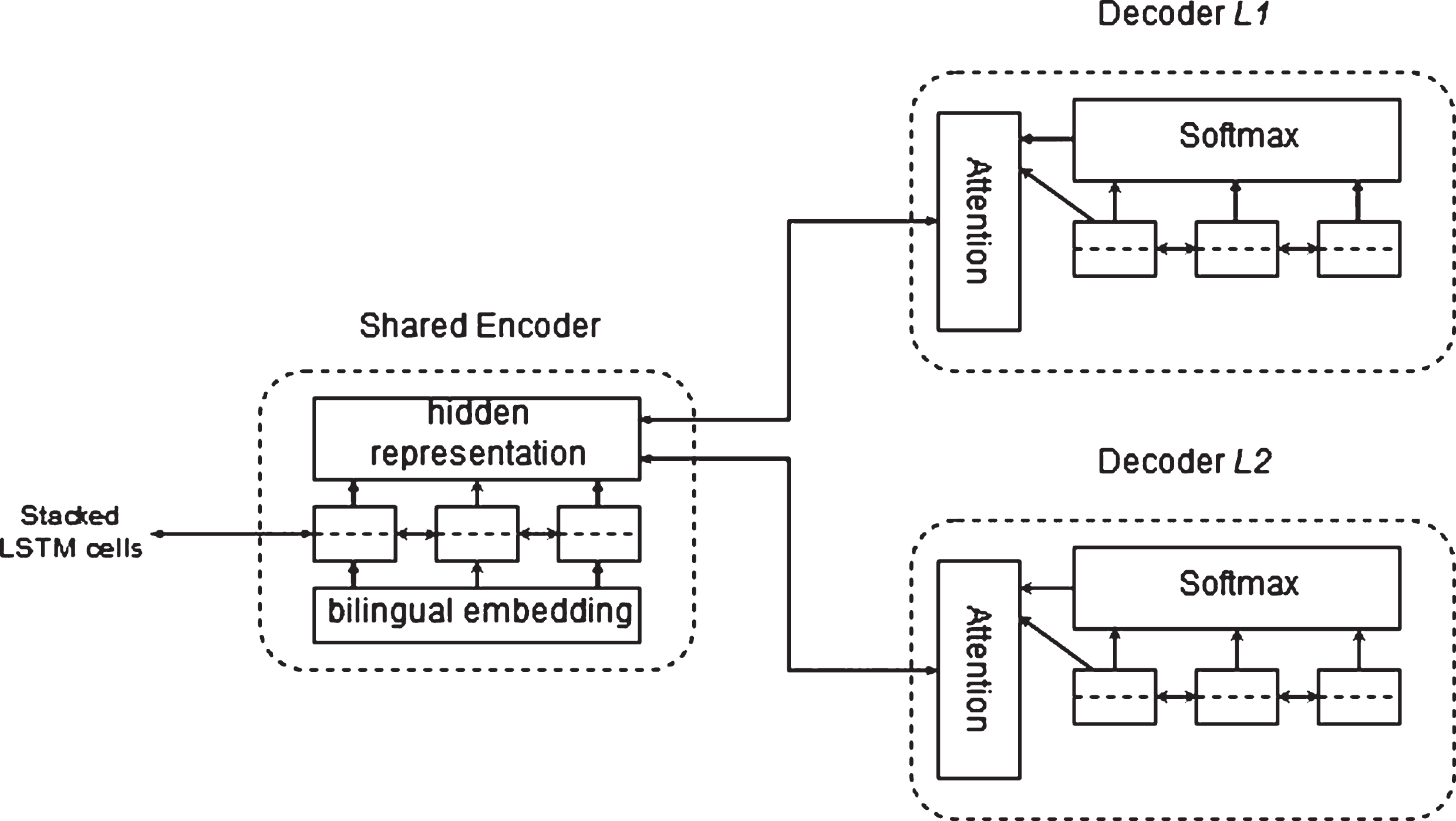
The proposed architecture [3]
An Encoder is a fundamentally a function ψ enc that takes an input and returns an output, generally of lower dimension to the input. In the domain of text modeling, a sentence is represented as a sequence of words. Hence, an encoder of a sentence would transform this sequence into a different space. This space is generally referred to as the code of the sentence. The sequence encoder used is a bidirectional two layer, stacked RNN using LSTM cells largely similar to the ones used by Sutskever et al. [25]. Based on experimental results by Sutskever et al. [25], the input sentence is fed in reverse order to the encoder. This improves the codification of sentence structures and gramatical features.
Decoder
A Decoder can be thought of as an inverse function to that of an encoder. Decoders work on probability, with the output being decided by the goal of maximizing the probability given the input code i.e. probabilistic decoder model
The decoder is an two layer sequential LSTM with a global attention mechanism inspired from Bahdanau et al. [4] and Luong et al. [16]. A simple non attention based decoder works on optimizing the probability of the current output word y
i
in the sequence based on the previous words generated using a softmax transformed output of the hidden state of that cell.
In order to generate the final sentence conditioned on the input sentence, a beam search decoding scheme is used based on the technique stated in Sutskever et al. [25]. A beam size of 10 was used with a normalization with respect to the length of the sentence for the log-probability maximization of the beam, in order to prevent the favouring of short sentences as shown by Cho et al. [8].
Training
We use the architecture as shown in Fig. 2; for each sentence in language L1, the system is trained alternating two steps: denoising, which optimizes the probability of encoding a noised version of the sentence with the shared encoder and reconstructing it with the L1 decoder. Noise is added by means of removing structural words and/or swapping tokens. This step allows training system to work better at reconstructing or generating sentences of the same language. translation, which translates the sentence in inference mode (encoding it with the shared encoder and decoding it with the L2 decoder) and then optimizes the translation probability of these parallel sentences.
Additionally, in the translation step, we can add a backtranslation step, which maximizes the probability that the shared encoder can encode the translated sentence and recover the original sentence with the L1 decoder. The above suggestion allows for a semi supervised model which can additionally use monolingual corpus with the backtranslation as a form of reinforcement learning.
Dataset
We used The IIT Bombay English-Hindi Parallel Corpus [14] for training and testing the proposed model. The dataset contains around 1.49 million parallel sentence pairs, composed from a variety of distinct sources. They also provide performance (BLEU and METEOR scores) estimates of some modern open source implementations of Statistical Machine Translation and Neural Machine Translation on their dataset, which form the baseline target to beat.
Experimentation and results of translation performance
Two different neural network models were used to provide baseline translation performance. The first was trained using complete supervision using a standard NMT architecture from Sutskever et al. [25]. The second model was trained using the architecture and algorithm proposed in section 4. The results are captured at various stages of training the respective models.
The size of the embeddings (i.e. vocabulary) was limited to 50,000 for both languages. This was actually 1/4th of the total size of the English embeddings and 1/3rd of the total size of the Hindi embedding space. This reduction in space was necessary to train the models within reasonable hardware limitations of GPU memory. The reason for the same is that the memory requirement scales superlinearly with the vocabulary size. The vocabulary itself was chosen randomly; thus there is a clear area to target for improved performance. The words not in vocabulary are listed with an out of vocabulary token.
The test set used for calculating the final BLEU scores was provided by [14] and consisted of 2000 parallel sentences taken from an unspecifed set of sources. A verification set of 1000 parallel sentences was also provided and was used to optimize model performance. The proposed model as well as the seq2seq model were run for a total of 300,000 iterations. All experiments were performed on an Amazon EC2 instance running an Nvidia V100 GPU chip. Performing the experiments on the proposed model with the limited vocabulary of 50,000 utilized 8GB of GPU memory on average for training, and 4GB of GPU memory for translation. Increasing vocabulary size had the greatest impact on memory usage. The runtime is shown in Table 4.
The BLEU scores in Table 2 and Table 3 by Artetxe et al. [3] and Lample et al. [15] while translating English to latin derived languages such as French. This actually implies that the model performs rather well, given the disparity of Hindi with English in comparison to that of French. This is corroborated by the results obtained by Kunchukuttan et al. [14] in their preliminary analysis, where the BLEU scores obtained by the baseline models was considerably lesser than those of the proposed model. The OpenNMT [13] project which is a state of the art library incorporating various recent research also obtained BLEU scores few points lesser than our best model. In terms of runtime, the proposed model is not significantly slower than the OpenNMT project library, which is a comparatively better optimized toolkit. From the translations themselves, the following qualitative analysis can me made of the output sentences. Some example translations are listed in Fig 4. The model is able to produce mostly gramatically correct Hindi. This is one of the advantages of an NMT based model, as the decoder learns semantic and syntactic structures using the corpus. By further training the model to reconstruct the language using monolingual corpus, this aspect can be further improved. The key action verbs and subjects are identified correctly, though in some cases the relation between the subject and object is misinterpreted, especially when involving negations. The major theme of the sentences are generally understood by the model, as the translated sentences talk about the same general idea introduced in the source. <OOV> tags imply that either there is a further requirement of increasing the embedding dictionary size, or a need to impute proper nouns straight from the original sentence. Additionally, further training will allow the model to learn better representations, which could avoid < OOV> tags.
BLEU scores for different systems translating English to Hindi
BLEU scores for different systems translating English to Hindi
BLEU scores for different systems translating Hindi to English
Average runtime for different systems translating English to Hindi

Some sample English sentences and their Hindi translations produced using the proposed translation architecture
In this paper, we present a modern deep learning for the task of translating between Hindi and English. Using recent developments in cross-lingual embeddings [1, 18] and natural language autoencoders [3, 25], we incorporate key ideas and designs to build the shared encoder and attentional decoder model.
The experimental results back the expected performance of the proposed model, with clear improvements shown over baseline and standard translation systems [14]. The qualitative analysis of the translated sentences show that the system is capable of producing grammatically correct sentences while keeping the key meaning of the sentence intact.
Gains in computational efficiency could allow the model to train on a greater number of parameters and on much larger vocabulary set. Variational autoencoding techniques are a promising avenue of future research in translation. Gains made for sentence reconstruction and generation [6, 24] have shown promising results in tasks such as word imputation, sentence reconstruction and similar sentence searches. Good performance in these tasks should correlate well with the requirements of a model for translation.