
Abstract
In today’s society, many decision-making problems cannot be merely solved based on quantitative data. Even though some issues are able to be addressed by quantitative data, researchers may face the difficulty of obtaining accurate and sufficient numbers. Some qualitative evaluations given by experts or decision makers are usually linguistic expressions. Therefore, fuzzy linguistic research has been broadly studied to address the above issues. This research has also been attracting increasing attention from researchers and decision makers in the world. It is believed that analyzing the status quo and emerging trends in this research area is of great necessity, especially for the beginners who are interested in fuzzy linguistic research. To do so, this paper provides the mapping knowledge domain of fuzzy linguistic research based on 648 papers on Web of Science from 1975 to 2018 by using CiteSpace which is an effective tool for scientometric studies. The visualization analyses of cited reference clusters, collaborations networks, author co-citation networks, burst detection and time zone view are presented in this study to show the research streams and the papers that made significant theoretical contributions. Also, the active counties, institutions, journals and authors in this research area are analyzed in detail. Besides, the specific hot spots and emerging trends can be known. There are two contributions in this study. Firstly, we give a comprehensive investigation about the status quo and emerging trends of fuzzy linguistic research in the recent 43 years. Secondly, we make the development of fuzzy linguistic research easier and direct to learn for beginners.
Introduction
Being different from other accurate values, fuzzy logic is used to describe any real number between 0 and 1. It is also introduced to deal with the concept of partial truth, where the truth may at the range between absolute true and absolute false (Vilém et al., 1999). The term fuzzy logic was proposed by Zadeh [77]. However, it had been studied since the 1920 s as the concept of infinite-valued logic, which was investigated by Łukasiewicz and Tarski [50]. Since its establishment, fuzzy logic has been broadly applied in different research fields. Lee [38] analyzed fuzzy logic in control system. Also, Sugeno and Yasukawa [55] presented a general method to qualitative modeling on the foundation of fuzzy logic. Obviously, there are various problem need to be solved in fuzzy environment.
Zadeh [78] introduced a linguistic variable concept which is different from numerical values. Linguistic variables tend to be words or sentences such as absolutely true, true, not true enough, untrue, and etc. Without actual numbers, linguistic variables can be also considered as the concept of fuzzy logic, providing the foundation for human reasoning to solve realistic problems. Specifically, Zadeh pointed out that linguistic approach can be applied to the research fields of artificial intelligence, human decision process, psychology, information retrieval, and etc. By combing the fuzzy logic and the linguistic approach, there has been an increasing number of explorations proposed to further extend the existing models and improve the problem solving, especially for qualitative issues in fuzzy environment. For instance, Gou et al. [19] presented hesitant fuzzy linguistic Bonferroni mean operator and the weighted hesitant fuzzy linguistic Bonferroni mean operator to deal with multicriteria decision making problems. Garg & Kumar (2018) developed many aggregation operators based on linguistic connection number (LCN). Furthermore, Liao et al. [41] compared the methods and measures of hesitant fuzzy linguistic term sets (HFLTSs), and summarized the various extensions. There are also numerous cases using fuzzy theory and linguistic approaches into practical problem solving. Yager and Petry [73] utilized fuzzy logic and computational intelligence to analyze users’ subjective comments. Similarly, Altintop et al. [2] attempted to use fuzzy linguistic summarization to explore some information from operational and financial healthcare data.
With the growing number of fuzzy linguistic research, it is necessary to know the status quo and emerging trends in this field. This paper focuses on mapping knowledge domain which involves the processes of charting, mining, analyzing, sorting and displaying knowledge [53] to investigate fuzzy linguistic research. There are various domain visualization tools such as CiteSpace, UCINET and VOS viewer. Among these visualization tools, CiteSpace is one of the most popular methods to clearly and interpretably produce co-citation networks on the basis of article citations and reveal the structure of a particular research field (Chen et al., 2006). CiteSpace was developed by Chen [11] and has been broadly applied to investigate the researches of astrobiology [58] and linguistic decision making [74]. There are some bibliometric analysis about the fuzzy journals such as such as: “A bibliometric analysis and visualization of medical big data research” [39], “Ten years of Sustainability (2009 to 2018): A bibliometric overview” [56], “A bibliometric overview and visualization of the International Journal of Fuzzy Systems between 2007 and 2017” [57] and “Bibliometric analysis for highly cited papers in operations research and management science based on Essential Science Indicators” [40]. It can be found that the above studies utilize diverse bibliometric methods such as VOS viewer and GraphPad Prism 5. The comprehensive analyses are given through combining the results obtained by the multiple analytic tools. It should be pointed out that Liao et al. [40] not only use VOS viewer to present the general knowledge domain of the highly cited papers in Operations Research and Management Science, they also apply SPSS to make correlation analysis. Compared with the above studies, this paper mainly utilizes CiteSpace to analyze the current status and the emerging trends of fuzzy linguistic research field. Both of the methods in this paper and the above studies present the co-citation analysis, the highly cited articles and the influential actors in different levels such as authors, journals, institutions and countries. However, the article burst detection and the time zone view of keywords are shown in this paper to further analyze the emerging trends and hot topics of fuzzy linguistic research area. Besides, the above studies mainly use the H-index as the selection criteria. However, the G-index which was initially proposed by Leo Egghe [16] is utilized in CiteSpace. The developer of CiteSpace then improved the G-index by applying a scaling factor that shapes the overall size of the resultant network to meet researchers’ certain needs [80].
There are also many papers research on fuzzy research by utilizing CiteSpace. For instance, Yu and Liao [74] provided a scientometric review about intuitionistic fuzzy studies to analyze the frequently cited articles, the active authors and journals in this research field. Besides, the similar bibliometric analyses related to fuzzy research are also proposed by some scholars using different methods. Merigo et al. [48] gave a general landscape of fuzzy sciences by applying bibliometric indicators. Also, Blanco-Mesa et al. [5] and Liu and Liao [45] investigated the research area of fuzzy decision through using the scientometric analysis software VOS viewer and Vantage Point, respectively. Being similar with papers, this study also presents the general overview of fuzzy linguistic research by analyzing the status quo from the perspectives of highly cited articles, active authors, journals, institutions and countries.
However, there are also some significant differences between our investigation and the prior research. Firstly, the scope of this investigation is specific, which focuses on fuzzy linguistic area. Moreover, the connections among articles and authors are illustrated by the cluster analysis and author collaboration network. Besides, the article burst detection is given to clearly show the papers that received strong citation bursts in different time intervals. Last, we analyze the hot topics in different time periods through time zone view of keywords which helps researchers especially the beginners know more about the dynamic changes in fuzzy linguist concepts and practical applications. As a result, this study is aimed at providing an objective and more comprehensive overview of research on fuzzy linguistic approach by introducing a scientometric analysis based on CiteSpace. After analyzing 648 published literatures in fuzzy linguistic research, which are retrieved from Web of Science (WoS) between 1975 and 2018, this paper is guided by the following goals: (1) to analyze the authors who significantly impact on this field; (2) to illustrate the countries/regions, journals, institutions and authors with lots of contributions; (3) to identify the emerging topics and hot spots of fuzzy linguistic research. The remainder of this paper is organized as follows. The number of publications on fuzzy linguistic research and the citation analysis are demonstrated in Section 2. The countries/regions, institutions and authors with a large amount of publications about fuzzy linguistic research are illustrated and analyzed in Section3. Section 4 presents the emerging trends and hot topics of this research area by utilizing burst detection and keyword analysis. Lastly, the key findings are concluded in Section 5. The limitation of this study and the suggestions for the future research directions are also discussed in this section.
Number of publications and co-citation analysis
In order to know the development process and theoretical basis of fuzzy linguistic research, the number of publications in recent years and their co-citation analysis are discussed in this section to show a general picture of the development in this research field.
Co-citation analysis
(1) Data collection for using CiteSpace
Firstly, WoS is selected as the data source for bibliometric analysis because it is a huge platform that provides an access for readers to know specific information about the articles published in roughly 12,000 leading journals worldwide, which includes the Science Citation Index Expanded (SCI-EXPANDED), the Social Sciences Citation Index (SSCI), and the Arts & Humanities Citation Index (AHCI) databases [61]. Then, by searching the titles “fuzzy” and “linguistic”, 1114 publications related to fuzzy linguistic research are found. In order to eliminate “noise” that may affect the accuracy of research results, the papers published in some databases such as Conference Proceedings Citation Index-Science, Emerging Sources Citation Index and Book Citation Index– Science are filtered out. Ultimately, there are 648 papers about fuzzy linguistic research which were published between 1975 and 2018. The period (1975–2018) is chosen for three major reasons: (1) based on the records on WoS, the literatures published before 1975 were limited. (2) the papers published in the recent 43 years which are related to fuzzy linguistic research reflect the development of this field. (3) the data were retrieved on October 1st, 2018. In this study, the latest papers on WoS were also taken into consideration.
(2) Cluster network and the most cited articles
Co-citation can be explained as the frequency of two earlier literatures being cited together by the later literature [54]. In order to better understand the mechanism of specialty development, co-citation analysis is introduced as a useful tool which identifies prominent journals, articles and authors. The co-citation analysis of fuzzy linguistic research can be obtained by utilizing CiteSpace, which can be seen from Fig. 2. The articles with co-citations are divided into several clusters to make it easier for readers to know the main research areas. Detailed results about the main clusters and the most cited articles with co-citation frequency are shown in Tables 1 and 2, respectively.
Summary of the largest 6 clusters
Summary of the largest 6 clusters
Top 10 most cited articles with co-citation frequency
Figure 2 shows the co-citation network based on the 648 references between 1975 and 2018. The corresponding data can be seen from Table 1 which lists top 6 clusters of this research area. In Table 1, the size means the number of publications in the cluster. The LLR (Log-Likelihood Ratio) is an algorithm to calculate each label and it is also the core concept that summarizes each cluster. Moreover, the silhouette score is used to test the homogeneity of clusters. Basically, if a silhouette is greater than 0.5, then the corresponding result is reliable. The largest value of a silhouette is 1, so if the silhouette of a cluster is near to 1, the result is considered to be more reliable. According to Table 1, all of the silhouette scores are above 0.8, which suggests a reliable quality of each cluster. The largest and the latest cluster is #0 cycle tour with 49 member references. Besides, most of the clusters’ mean years are before 2010, #6 is relatively older than other ones.
By knowing the top 6 clusters in fuzzy linguistic research area, the top 10 cited articles with co-citation frequency of over 40 times and their clusters are demonstrated in Table 2. According to Chen et al. [13], the most cited papers have significant contributions to certain research area. Therefore, it can be seen from Table 2 that the most cited article is from #0 with both 137 citations. This article is “Hesitant fuzzy linguistic term sets for decision making” [51] which is mentioned in section 2.1 as the most cited paper in Phase Three. Hesitant fuzzy linguistic information can be flexibly utilized to deal with experts’ uncertain evaluation and rich expressions in decision making.
Also, it is clear to see that the most cited articles are almost from #0, except for the fifth paper which is from #1. Therefore, multi-hesitant fuzzy linguistic information dose made great contributions in fuzzy linguistic research area. When talking about hesitant fuzzy sets, the second paper in Table 2 is of great necessity to be discussed. Torra [60] proposed hesitant fuzzy sets and introduced some basic operations. Numerous decision-making and evaluation methods therefore can be further developed. Moreover, Rodriguez et al. [52] and Zhu and Xu [79] proposed new models by utilizing comparative linguistic expressions and considering about preference relations. Liao et al. [42] and Liu and Rodríguez [44] investigated hesitant fuzzy linguistic terms sets and their applications to multi-criteria decision making. Xia and Xu [67], Wei et al. [65] and Beg and Rashid. (2013) analyzed and compared different information aggregations, then proposed aggregation methods which can be introduced in real-life decision making. Being different from the scholars above, Martinez and Herrera (2012) focused on the 2-tuple linguistic model and its extended forms, applications and challenges in decision making, which has also significantly impacted fuzzy linguistic research area.
The number of publications about fuzzy linguistic directly reflects the development process of this research field. Besides, it is also the obvious evidence to demonstrate whether this research topic is gaining increasing attention of scholars around the world. In this study, the articles on WoS that investigate fuzzy linguistic research between 1975 and 2018 are analyzed in detail, including the number of articles and the most cited articles in different development stages.
Figure 1 illustrates the number of publications from 1975 to 2018. It is obvious that the literatures about fuzzy linguistic research are increasing in the recent 43 years. In order to analyze the change of publication amount, this paper divides the whole period into four phases. Phase One (1975–1994). As shown in Fig. 1, there was a small number of publications related to fuzzy linguistic in the early stage. According to the records on WoS, the average number of papers published in each year between 1975 and 1994 was just 2.3. However, many papers published in this phase have significantly impacted the further research, especially the paper entitled “Experiment in linguistic synthesis with a fuzzy logic controller”, which was written by Mamdani and Assilian [46]. This was an attempt to explore the possibility of human interaction with a learning controller. Besides, other papers related to fuzzy linguistic research mainly focus on investigating decision making (Tong and Bonissone, 1980) [36] and fuzzy linguistic quantifiers [33, 36]. In this phase, Mamdani and Kacprzyk made great contributions for the development of fuzzy linguistic research. Phase Two (1995–2005). It is clear that the papers published in this phase are obviously more than which in Phase One. Compared with the number of publications, the number of citations grew more stably in these two phases. In 2000, Herrera and Martinez developed the 2-tuple representation model and a computational technique to deal with the loss of information [21]. With the development of fuzzy linguistic research, it has been increasingly applied to the research areas of computer science, engineering and mathematics. Specifically, many researchers utilized fuzzy linguistic approaches to make evaluations and decisions [14, 64]. Also, the synthesis models between fuzzy logic and linguistics have been designed and improved in this phase. Phase Three (2006–2012). Although the publication and citation numbers face some fluctuations in this phase, they are still in the growing trend compared with the prior stages, especially for the citations. It can be seen from Fig. 1 that there was a sharp decrease of publications from 2007 to 2008. A small downward trend can be also shown from 2010 to 2012. In this phase, the most cited article is “Hesitant fuzzy linguistic term sets for decision making”, which was written by Rodriguez et al. [51]. The authors proposed a new decision-making model by introducing a hesitant fuzzy linguistic term set to enrich experts’ linguistic expressions. This model can be flexibly utilized to deal with some qualitative decision-making problems. Besides, some fuzzy linguistic methods were proposed to address the issue of unbalanced linguistic context [10, 20]. Phase Four (2013–2018). Linguistic fuzzy research has been attracting increasing attention of scholars in recent 5 years, especially from 2013 to 2014. The publication number increased rapidly in these two years, then it climbed stably until 2018. In this stage, there are frequent investigations research on hesitant fuzzy linguistic term sets to deal with comparative linguistic expressions [52], solve multi-criteria decision-making problems [42] (Liu et al., 2014) and reflect decision makers’ preference relations in decision making [79]. As a result, hesitant fuzzy linguistic term sets have been broadly applied in fuzzy linguistic research area due to their flexibility and practicability.
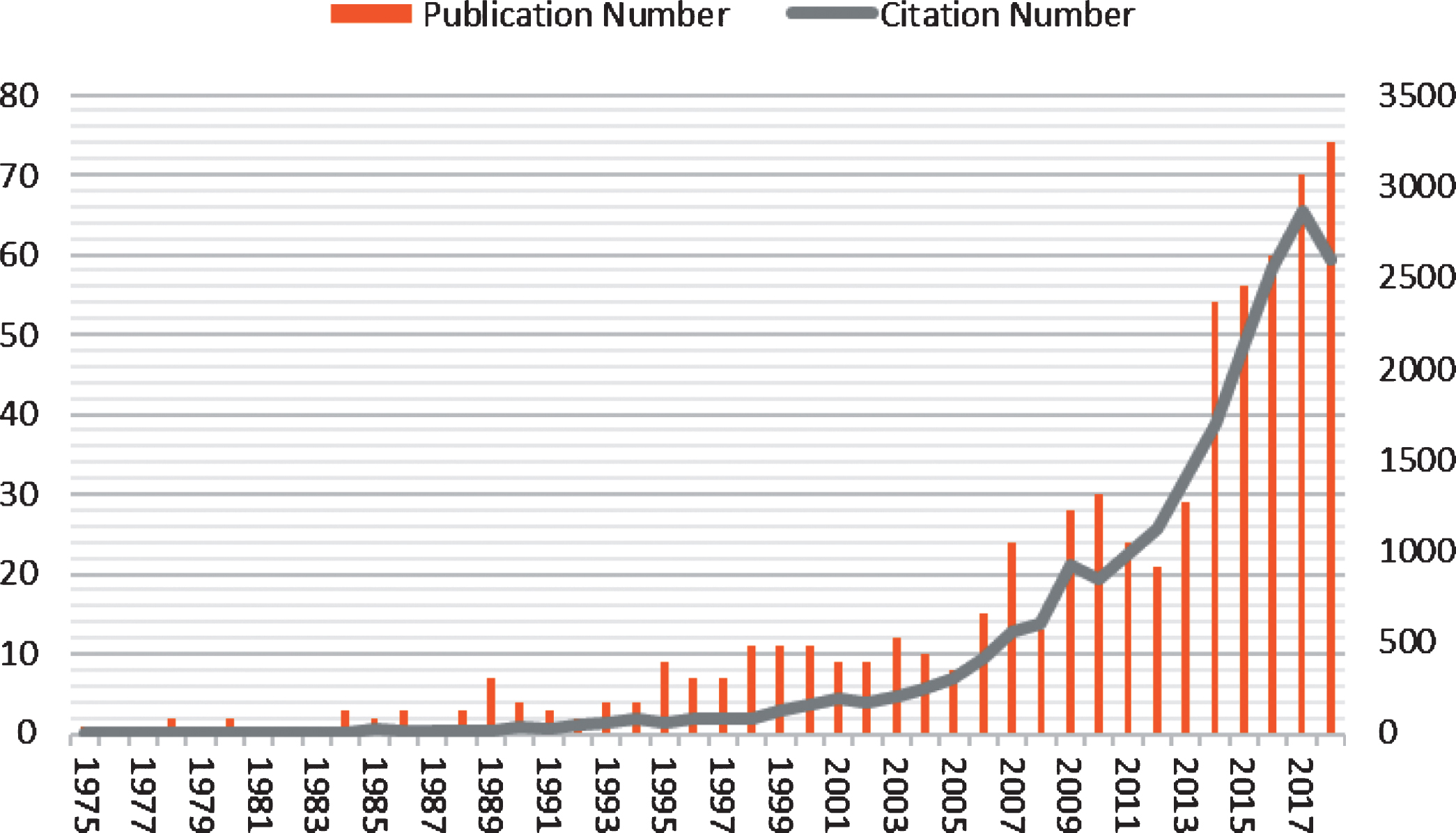
The number of publications about fuzzy linguistic research from1990–2017.

Cluster network of fuzzy linguistic research.
It is obvious that the more research outputs which were published by a country/region, journal, institution and author, the more contributions they made in this research area. As aforementioned, the number of publications can directly indicate the development of certain research area, it is also able to clearly show the academic contributions made by a country and even by an author. More importantly, the results tell that the most productive counties/regions are at their prosperous stages of fuzzy linguistic research as well, and the most productive institutions are mainly from those countries/regions. Besides, the papers written by the prolific authors are of great influence in fuzzy linguistic research.
Productive countries and institutions
The most productive countries are identified by using the records of WoS, which makes the results more accurate and objective. Additionally, the most cited authors and collaboration network among institutions are analyzed by CiteSpace. Based on the results given by WoS and CiteSpace, further discussion can be seen below.
The top 10 countries with most of literatures about fuzzy linguistic research are listed in Table 3. It is obvious that China is the largest contributor with 310 publications, followed by Spain, the USA and India. The publications of these countries account for more than 70% of all the publications related to fuzzy linguistic research in the world. Although the rest of countries’ published papers are relatively less, they also made big contributions in this research area.
Top 10 productive countries in fuzzy linguistic research field
Top 10 productive countries in fuzzy linguistic research field
Figure 3 shows the country collaboration network in fuzzy linguistic research. Combining with Table 3, the node size in Fig. 3 indicates the publication number of each country. Besides, the links among these countries construct a geographic collaboration network. It can be found that the prolific countries in fuzzy linguistic research field have more collaboration with other countries. However, the thinness of the links implies a low level of cooperation.

A visualization of the country collaboration network.
Moreover, the number of publications about fuzzy linguistic research in each country/region is also related to the amount of institutions and research funding. The top 10 institutions which made great contributions to fuzzy linguistic research are listed in Table 4. There are 507 institutions published literatures about fuzzy linguistic research. Among these institutions, The University of Granada occupies a prominent position of this research field with 83 publications. Universidad de Jaén also has significant contributions to fuzzy linguistic research with 33 publications, and both of these two institutions are from Spain. The rest of the institutions are mainly from China. As aforementioned, China is the most productive country in fuzzy linguistic research. However, there are over 17% of articles related to fuzzy linguistic research are published by the first two institutions in Table 4, and both of them are in Spain. While among the 10 prolific institutions, 5 of them are from China which published about 16% of the total amount of papers in this research area. The rest of the institutions are from Poland, Saudi Arabia and the USA, respectively. As a result, the most prolific institutions are from the most prolific countries. There are lots of institutions in China investigating on fuzzy linguistic research, so that China can be the most productive country in this research area. Nevertheless, although the institutions in Spain are less than which in China, The University of Granada and Universidad de Jaén have a large amount of research outputs, leading Spain to become one of the greatest contributors in this area.
Top 10 productive institutions in fuzzy linguistic research field
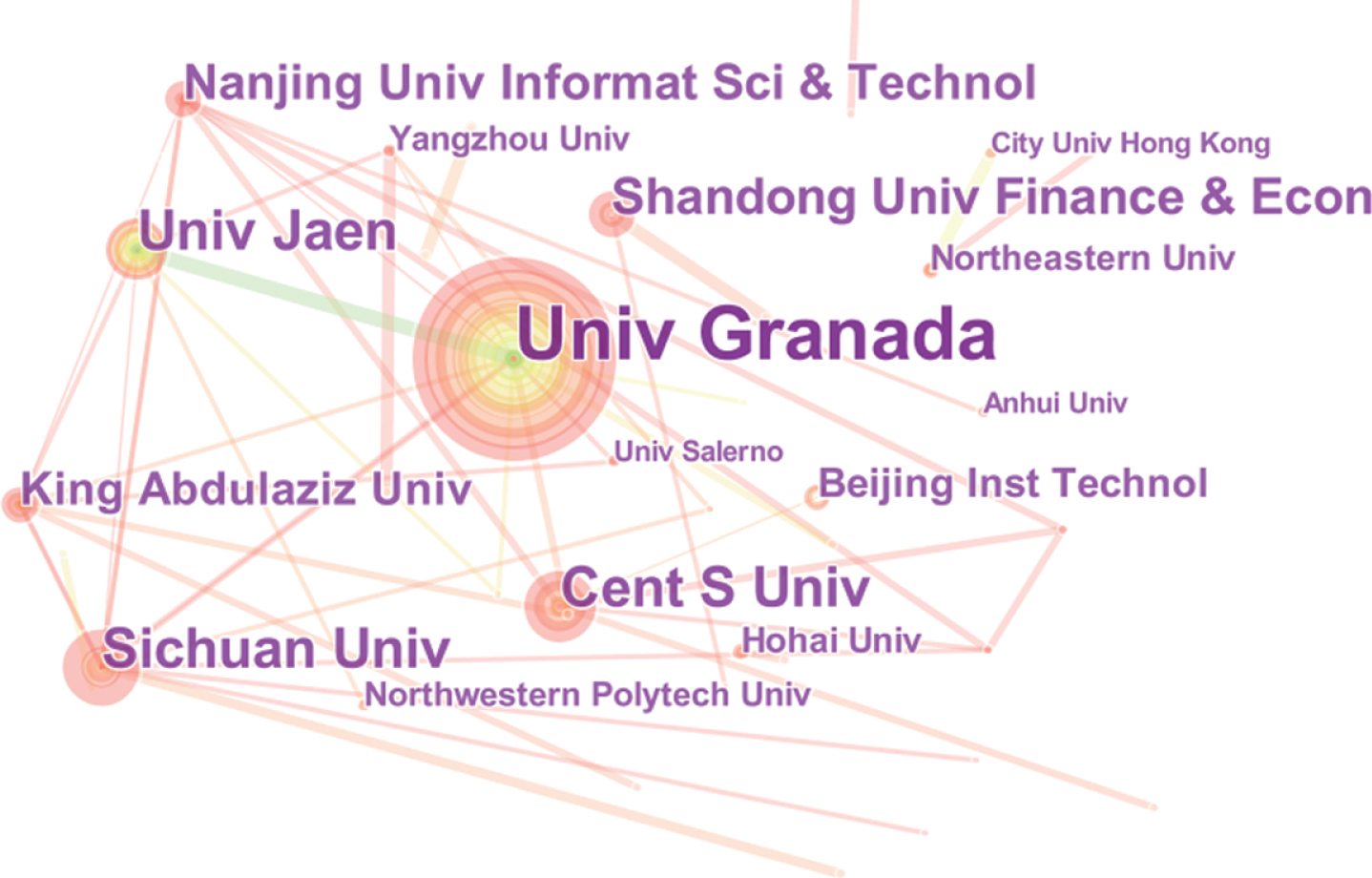
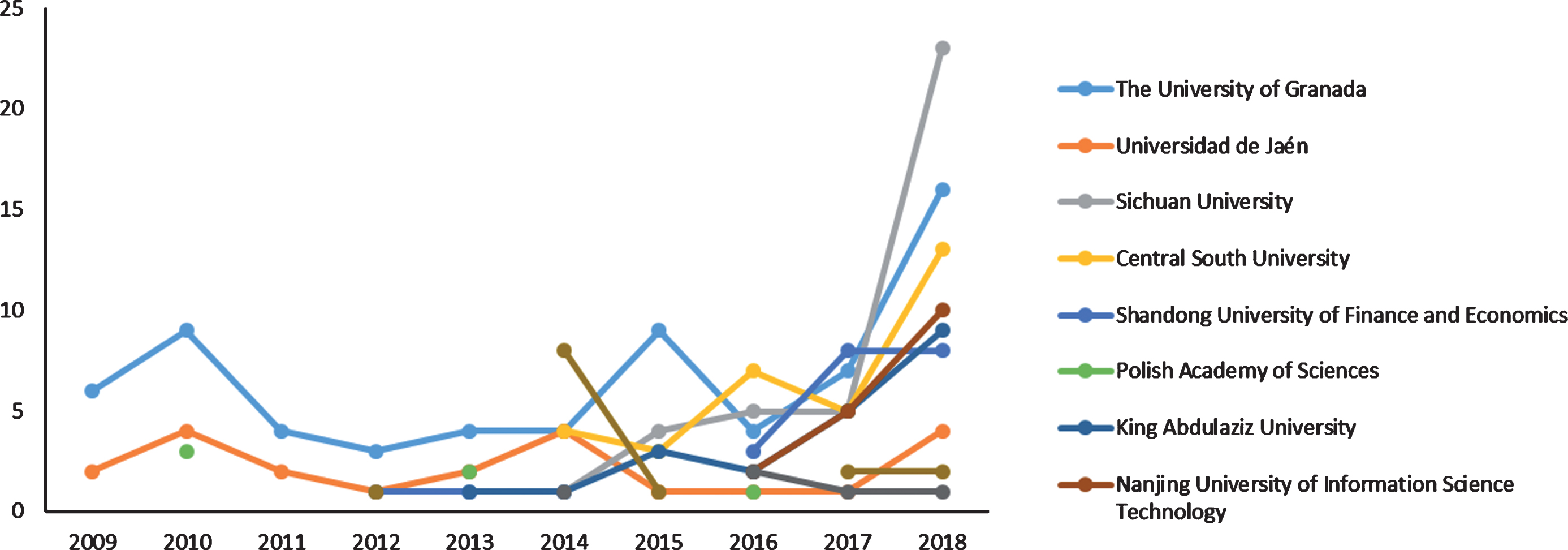
Besides, Fig. 4 shows the significant collaboration network among institutions in the world between 1975 and 2018. The structure of this network indicates the maturity of the institution collaborations. If the structure is relatively tight and close, then the collaborations among the corresponding institutions are more mature. According to Fig. 4, there are more collaborations among the institutions in the same countries. Thus, it is necessary to improve the cross-national interactions, especially for those countries which significantly impact the development of fuzzy linguistic research. Moreover, the development of some top universities in Fig. 4 can be seen from Fig. 5 which illustrates the publication numbers of these institutions between 2009 and 2018. It can be found that the development of The University of Granada is stable in the recent 10 years. Obviously, even though there was no record for Sichuan University before 2014, its research outputs sharply increased after that year. The article number even reached to the highest point compared with which of other universities in 2018. Overall, The University of Granada and Universidad de Jaén started fuzzy linguistic research earlier than other universities. After 2014, there are more institutions focus on this research area, and many of them are from China.
The development of the prolific institutions.
A visualization of the institution collaboration network.
The top 10 prolific journals and their impact factors released in 2017 are listed in Table 5. Journal of Intelligent Fuzzy Systems is the most prolific journal among the ten journals, following with IEEE Transactions on Fuzzy Systems, Fuzzy Sets and Systems and Information Sciences which have published over 30 papers related to fuzzy linguistic research. Particularly, the impact factor of IEEE Transactions on Fuzzy Systems is the highest. This journal also made great contributions in fuzzy linguistic research area due to the large number of research outputs and its impact factor. In addition, many papers mentioned in Section 2 are published by the above journals.
Top 10 productive journals in fuzzy linguistic research field
Top 10 productive journals in fuzzy linguistic research field
Besides, the articles published by other journals also made considerable contributions to this research area, such as “Group Decision Making with Incomplete Fuzzy Linguistic Preference Relations” [1] published by International Journal of Intelligent Systems and “Multi-criteria decision-making methods based on the Hausdorff distance of hesitant fuzzy linguistic numbers” [66] published by Soft Computing. These articles also have been cited frequently by improving the further investigations in terms of dealing with decision makers’ preferences and uncertain information. Overall, not only the journals listed in Table 5 are the most prolific, the articles published by them are also of great significance in improving the development of fuzzy linguistic research.
The top 15 productive authors are listed in Table 6. According to the records on WoS, Herrera-Viedma and Herrera are the most productive authors in fuzzy linguistic research with 40 and 34 papers, respectively. It should be noted that the number of publications here is not the actual research outputs for each author due to the reason that some papers were filtered out based on the searching method in this study. However, most of the papers with significant influence and written by these authors are taken into consideration. In terms of affiliations, both of Herrera-Viedma and Herrera are the professors of the Department of Computer Science and Artificial Intelligence, the University of Granada. The main author collaboration network of fuzzy linguistic research is shown in Fig. 6. It can be seen from Fig. 5 that not only Herrera-Viedma and Herrera are the co-authors in many papers, they also collaborate with other scholars such as Xu, Liao, Martinez and Alcala who are also the productive authors listed in Table 6.
Top 15 productive authors in fuzzy linguistic research field

A visualization of the author collaboration network.
In order to further investigate the authors who have greatly impacted fuzzy linguistic research, a visualization of the author co-citation network is given in Fig. 7 to show the frequently cited authors in the recent 43 years. It should be noted that only the first author of a certain paper is considered in this study. Based on the author co-citation analysis provided by CiteSpace, there are 387 nodes and 1546 links in the network.
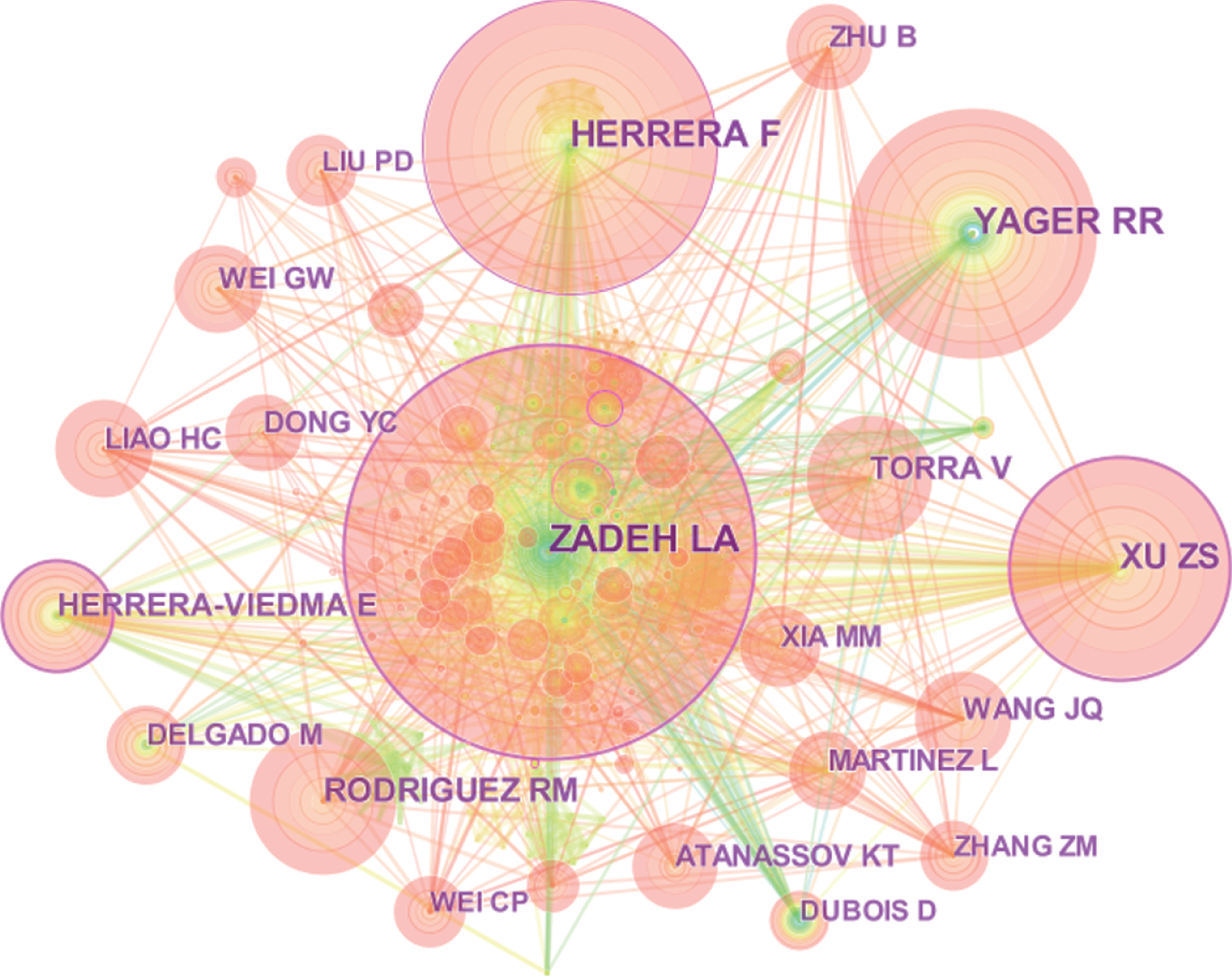
A visualization of the author co-citation network.
The top cited authors are Zadeh, Herrera and Yager. Since fuzzy set theory was proposed by Zadeh, various methods that utilize fuzzy sets, fuzzy logic, fuzzy algorithms, fuzzy system and etc. have been developed. Due to the reason that Zadeh provided the crucial theoretical basis of fuzzy linguistic research, he has become a best-known scholar in fuzzy mathematics. Based on the data on Google Scholar, Zadeh’s research outputs have been cited about 180,000 times in scholarly works. The paper “Fuzzy sets” [77] has received about 90,000 citations until September 2017.
In addition, Herrera and Yager also greatly impact fuzzy linguistic research area. According to the information on WoS, the article that introduced the 2-tuple fuzzy linguistic representation model [21] which is mentioned before has been cited for 1339 times. Herrera’s other two papers [20, 51] are identified as the frequently cited papers with 52 and 141 times, respectively in the nearly 5 years. Yager’s research outputs are also inspiring in this area. He analyzed the construction of multi-criteria decision functions from linguistic specifications in nature language based on fuzzy set theory [71]. Yager and Kacprzyk (2001) proposed basic thoughts and perspectives about the application of fuzzy logic for the derivation of data sets’ linguistic summaries. Besides, in order to apply fuzzy multi-criteria techniques to mobile APPs, Yager [72] pointed out the necessity to obtain aggregation operations on ordinal-based intuitionistic fuzzy subsets. In recent years, Yager focuses on the approaches of linguistic summarization and their extensions based on fuzzy sets [4, 7]. Comparing the 15 productive authors in Table 6 and the frequently cited authors shown in Fig. 7, even though there are still some differences, a high consistent correlation can be seen between the productive authors and the frequently cited authors.
The emerging trends are also what scholars concern about in the scope of fuzzy linguistic research as they give scholars some inspirations in terms of new research directions and cutting-edge methodologies. Therefore, several interesting points can be found by analyzing the results given by CiteSpace. In this section, the reference burst detection and the keyword analysis are illustrated to show articles that have received rapid increases in citations and explore research directions intensively.
Reference burst detection
In order to know the emerging trends of fuzzy linguistic research, the reference burst detection is utilized in this study. As shown in Table 7, there are 20 references with strong citation bursts in a certain period of time between 1975 and 2018. It is obvious to see that all the citation bursts started after 2000. The earliest reference citation burst in this research field was in 2002. This paper introduced a new fuzzy linguistic representation model on the basis of “Symbolic Translation” to deal with the loss of information led by other computation approaches [21]. The red lines represent the citation burst duration of each listed paper, so this paper’s impact lasted for a long time from 2002 to 2007. Besides, almost half of these articles were written by Herrera-Viedma listed in Table 7.
Top 20 articles with strongest citation bursts
Top 20 articles with strongest citation bursts
Combining with the analytic results in Table 6, it can be seen that Herrera-Viedma has significantly impacted fuzzy linguistic research area. His articles also received long citation bursts. For instance, the article entitled “An information retrieval model with ordinal linguistic weighted queries based on two weighting elements” [22] proposed an information retrieval (IR) model based on ordinal fuzzy linguistic method which made the user-IR system interaction more flexible. In the same year, the similar investigation [23] was published, which also received the citation burst from 2003 to 2009.
Moreover, the papers that focus on new aggregation and operational laws also gained much attention from the scholars in this research field. Herrera-Viedma et al. (2006) evaluated the information quality of websites by introducing 2 new majority guided linguistic aggregation operators. Xu [68] defined some operational laws of linguistic variables, and the new aggregation approaches were proposed. Also, he proposed some new aggregation operators and applied it to deal with the uncertain multiplicative linguistic preference relations in group decision-making process [70]. Moreover, the consensus model is one of the emerging research trends in recent years. 10 Herrera-Viedma et al. [29] proposed a consensus model to help experts in different backgrounds reach the consensus in group decision making. Cabrerizo et al. [9] also developed a consensus model on the basis of a fuzzy linguistic approach which can be utilized to deal with unbalanced linguistic term sets. With respect to dealing with unbalanced linguistic term sets, Herrera et al. [20] also developed a fuzzy linguistic method to address this issue. It is clear that the newest citation burst started from 2009 and ended in 2015, suggesting one of the emerging trends is to utilize fuzzy linguistic method as an efficient tool to deal with unbalanced linguistic information.
In order to know fuzzy linguistic research more directly, the keyword analysis provided by CiteSpace can be useful for readers to learn the specific hot topics. The time zone view of keywords is presented in Fig. 8. Many keywords and their publication or peak time on the bottom constitute the major topics of fuzzy linguistic research in the recent 24 years. As shown in Fig. 8, the big clusters are presented between 2000 and 2010. Combining with the aforementioned development phases of fuzzy linguistic research, these clusters are closely related to the articles published in Phase Two and Phase Three. Even though the number of publications in these phases are not as large as which in Phase Four, the theories and concepts have provided significant theoretical basis for the further research. As a result, there are many links between the early investigations and the late ones. Besides, from the labels in each cluster, it can be seen that fuzzy linguistic research has been transformed from general to specific.
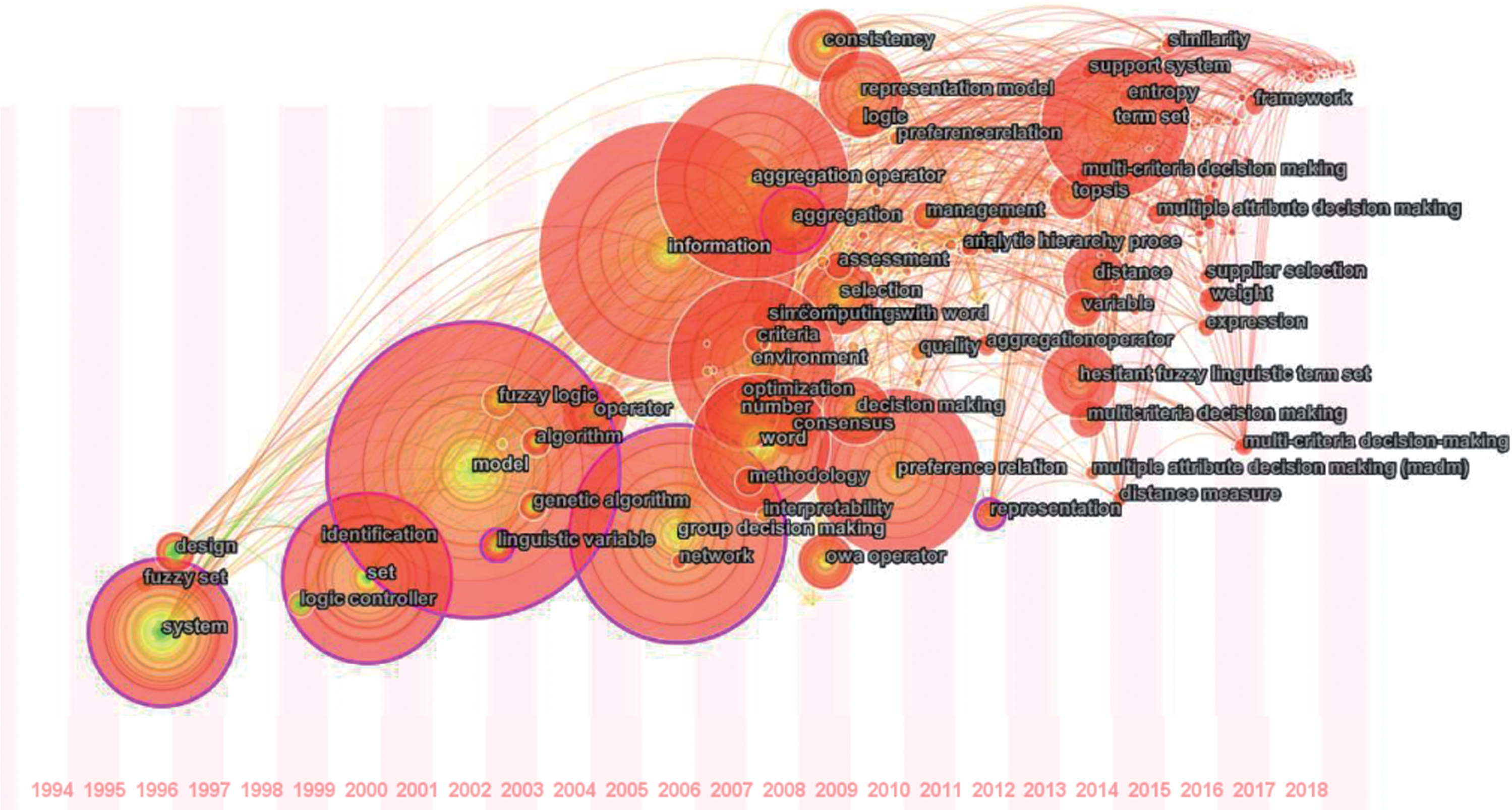
Time zone view of keywords.
The hot topics before 2000 are “system”, “fuzzy set” and “design”. Sine fuzzy logic was proposed by Zadeh [77], it had been applied to linguistic synthesis. There are many research directions such as fuzzy systems [43, 63] and Boolean information retrieval systems [8, 37] were developed to make some theoretical basis more general for the further investigations. After that, various models based on fuzzy logic and linguistics were proposed to solve practical problems, leading “model” become the largest hot spot in fuzzy linguistic research. Additionally, “group decision making”, “information”, “aggregation operator”, “environment”, “word” and “preference relation” are the main hot topics between 2000 and 2010. According to the analyses in the last sections, it is obvious that the fuzzy linguistic models are utilized to solve the real-world problems, especially group decision making. IR methods and aggregation operations are proposed to further improve fuzzy linguistic models and make them more efficient to help decision makers with their qualitative decision making. In addition, not only do fuzzy linguistic models can be utilized in fuzzy environment, the fusion of preference relations also further optimizes the models to meet decision makers’ specific requirements.
The recent research hot topics are “term set”, “distance”, “variables”, “hesitant fuzzy linguistic term set”, “multicriteria decision making”, “weight”, “framework” and etc. Among these hot spots, hesitant fuzzy linguistic term set is broadly investigated. Liao et al. [42] analyzed and developed different kinds of distance and similarity measurements for hesitant fuzzy linguistic terms sets. Liu and Rodriguez [44] proposed a new representation of hesitant fuzzy linguistic term sets based on a fuzzy envelope which can be directly introduced in fuzzy multicriteria decision making models. Besides, Wei [66] developed the arithmetic and geometric aggregation operators on the basis of interval valued hesitant fuzzy uncertain linguistic information to deal with multi-attribute decision making problems. According to the results given by Fig. 7, one of the latest research topics is multi-criteria decision-making. Yu et al. [76] proposed two hesitant fuzzy linguistic harmonic averaging operators to deal with multi-criteria decision-making problems in fuzzy environment. Feng et al. [17] extended the applicability of hesitant fuzzy linguistic term sets and developed two novel methods based on the priority method and the idea of PROMETHEE. Therefore, from general theories to specific model improvements and applications, the hot topics of fuzzy linguistic research is dynamic in different time periods.
This paper investigates the current state and emerging trends of fuzzy linguistic research by using CiteSpace. There are 648 papers retrieved from WoS which are published between 1975 and 2018. Based on the above results, the findings of this paper are concluded as follows. First, the number of fuzzy linguistic research outputs has been growing in the recent 43 years, especially in Phase Four. Fuzzy linguistic research has attracted increasing attention from scholars in the world. Second, China, Spain and the USA are the most active countries in this research field. Although the top productive institution and author are not from China, fuzzy linguistic research is also at a prosperous stage in this country. In addition, most of the active authors and institutions in fuzzy linguistic research are also significantly impacting this research field. Third, Journal of Intelligent Fuzzy Systems is the most productive journal of fuzzy linguistic research. IEEE Transactions on Fuzzy Systems and Fuzzy Sets and Systems made significant contributions as will due to the numerous research outputs and their impact on the development of fuzzy linguistic field. Meanwhile, the top 10 papers that received citation burst are analyzed, almost half of these papers were written by Herrera-Viedma. The papers that received citation bursts mainly focused on IR, new aggregation and operational laws and the consensus model. The latest citation burst was about proposing a fuzzy linguistic model to deal with unbalanced linguistic term sets. Moreover, the hot topics of fuzzy linguistic research are dynamic in different time periods, form general theories to specific model improvements and applications. Although the number of publications in the early years is not as large as which in recent years, the theories and concepts proposed in the early years have provided the significant theoretical basis for further research.
Since the fuzzy logic theory was established, fuzzy linguistic research has been broadly utilized for researchers to deal with decision making problems. In the recent 43 years, fuzzy linguistic models have been improved from different perspectives whxich makes some qualitative decision-making problems can be flexibly solved. This paper presents the mapping knowledge domain of fuzzy research field which makes the current status and emerging trends of this area easier and more direct to see, especially for the beginners who are interested in fuzzy linguistic research. In addition, the limitation of this study is that the data were retrieved on October 1st, 2018. The literatures published in the rest 2 years of 2018 were not covered. As for the future investigations, more fuzzy research can be considered to obtain a comprehensive picture about the development of this research area. Alternatively, the scientometric study in a certain country or region can be also investigated to provide detailed information about the current status and emerging trends of fuzzy linguistic research.
Footnotes
Acknowledgment
This work was supported by Natural Science Foundation of China (Nos. 71561026 and 71840001) and Social Science Foundation of Ministry of Education of China (No. 18YJC790118).