
Abstract
Software Release Planning (SRP) is to find, for a software, a subset of the requirements with the highest value while respecting the budget. The value of a requirement however may, to various degrees, depend on selecting or ignoring other requirements. However, existing SRP models ignore either Value-Related Dependencies altogether or the strengths of those dependencies even if they consider them. This paper presents an Integer Programming model for software release planning, which considers the variances of strengths of positive and negative value-related dependencies among software requirements. To capture the imprecision associated with strengths of value-related dependencies we have made use of algebraic structure of fuzzy graphs. We have further, contributed a scalable technique for automated identification of value-related dependencies based on user preferences for software requirements. The validity of the work is verified through simulations.
Introduction
Owing to budget constraints, software release planning (SRP) [1, 2] is needed to find a subset of software requirements (optimal set) with the highest value while keeping the cost of the selected requirements within the available budget [3]. The value of a requirement however, may be positively or negatively influenced by selecting or ignoring other requirements due to the dependencies among values of requirements [4–7]. Value-related dependencies [8, 9], also known as Increases-Decreases-value-of [7, 10], CVALUE [8], and Positive-Negative value dependencies [11] are commonly found in software projects [8, 13]. Requirement dependencies, including value-related requirement dependencies, on the other hand, are fuzzy relations [8, 15] meaning that the strengths of those dependencies are imprecise and vary from large to insignificant in the context of real software projects [6, 17]. It is important thus, to consider not only the existence but also the strengths of value-related dependencies [5, 18] in software release planning. Carlshamre et al. [8] observed the need to consider the strengths of requirement dependencies but they did not go further on how to formally achieve this. However, the existing software release planning models either ignore requirement dependencies [19–21] or do not consider the variance of strengths of those dependencies [2, 22] by treating them as precede relations [23, 24]. Following the latter direction, ignoring (selecting) a requirement r i results in ignoring all of the requirements whose values positively (negatively) depend on r i even if budget allows for their implementation [9].
This results in a condition referred to as the Selection Deficiency Problem (SDP) [25]. As a result of the SDP, any increase in the number of value-related dependencies will significantly reduce the value of the selected requirements [9].
To avoid these issues and properly factor value-related dependencies in software release planning, We proposed the notion of “Dependency-Aware Software Release Planning” in our earlier works [28, 29] to account for value-related dependencies. To achieve this, we have presented four major contributions as follows.
First, we have formulated an integer programming [26] model referred to as the Dependency-Aware Software Release Planning (DA-SRP) that finds a subset of software requirements with the highest Overall Value (OV), where overall value captures the influences of value-related dependencies (derived from user preferences) on the value of a selected subset of requirements. The DA-SRP model considers qualities (positivity or negativity) and strengths of value-related requirement dependencies.
Second, we have introduced Value Dependency Graphs (VDGs) based on fuzzy graphs [29, 30] for modeling value-related requirement dependencies and capturing the imprecision associated with strengths of those dependencies. A modified version of the Floyd-Warshall algorithm [31] is devised to infer implicit value-related dependencies in polynomial time.
Third, we have contributed a scalable technique for automated identification of explicit value-related dependencies and their characteristics (quality and strength) on the basis that values of software requirements are determined by user preferences for those requirements. In this regard, we have demonstrated using Eells measure of casual strength [32] for extracting qualities and strengths of value-related dependencies from user preferences. We have further, discussed value implications of certain structural and semantic dependencies among software requirements.
Finally, we have enhanced the accuracy of our proposed dependency identification technique through generating samples of large quantities based on the estimated distribution of the collected user preferences. In this regard, we have made use of a resampling [33] technique that generates samples from user preferences using a Latent Multivariate Gaussian model [33]. The employed resampling technique is computationally efficient and feasible for large numbers of software requirements [34].
We have verified the validity of the work by carrying out several simulations. Our results show that: (a) the DA-SRP model can properly consider qualities and strengths of value-related requirement dependencies in a SRP process while being computationally scalable, (b) The proposed DA-SRP model efficiently mitigates the adverse impact of the selection deficiency problem SDP, (c) the DA-SRP model always maximizes the overall value of the selected requirements, and (d) maximizing the overall value of a subset of requirements, where value-related dependencies are considered, and maximizing the Accumulated Value (AV) of that subset, where value-related dependencies are not considered, are conflicting objectives [35].
Related work
Several works [4, 37] have focused the attentions on considering value-related dependencies in software release planning (SRP). On this basis, we categorize the existing software release planning models into there main groups as follows.
The first group [19–21] of release planning models referred to as Binary Knapsack Problem (BKP) models find a subset of requirements with the highest accumulated value while ignoring value-related dependencies among requirements. Such models hence are formulated as the classical binary knapsack problem [23] as given by (1)-(3), where for a given set of requirements R : {r1, . . . , r n }, c i and v i denote the (estimated) cost and the (estimated) value of a requirement r i ∈ R respectively. Also, b denotes the available budget and decision variable x i specifies whether a requirement r i is selected (x i = 1) or not (x i = 0).
Ignoring the strengths of value-related dependencies and molding them as precedence constraints however, results in a condition referred to as the selection deficiency problem (SDP) [25]. The reason is that when value-related dependencies are formulated as precedence constraints of (6), ignoring (selecting) a requirement r i would result in ignoring all of the requirements whose values positively (negatively) depend on selection of r i even if the available budget is enough to allow for their implementation [9]. Hence, employing BKP-PC models may result in loss of value due to the selection deficiency problem. The effect of the SDP is also demonstrated in a simulation study carried out by Li et al. [9] where a 2% increase in the number of requirement dependencies resulted in almost 10% loss of value in the optimal set.
To care for variances of value-related dependencies, the third group of release planning models [4, 37] referred to as Increase-Decrease models consider value-related dependencies among software requirements through estimating the amount of the increased (decreased) values resulted by selecting various subsets of requirements.
An Increases-Decreases model proposed by Akker et al. [36] is given in (8)-(11). For a subset s j ∈ S : {s1, . . . , s m } , m ≤ 2 n , with n j requirements, the difference between the estimated value of s j (w j ) and the accumulated value of the requirements in s j (∑r k ∈s j v k ) is considered when computing the value of the selected requirements. y j in (8) specifies whether a subset s j is realized (y j = 1) or not (y j = 0). Also, constraint (10) ensures that y j = 1 only if ∀r k ∈ s j , x k = 1.
Increase-Decrease models however, are complex, subjective, and prone to human error as they rely on manual estimations for various subsets of requirements [25]. These problems persist even when estimations are limited to pairs of requirements [4, 37] as given in (12)-(14). For n requirements, a pairwise approach would reduce the worst case complexity of manual estimations from estimating all subsets (O (2 n )) to estimating the subsets of size two only (O (n2)) which is still way too complex to be used in software release planning.
Furthermore, relying on pairwise estimations results in ignoring implicit value-related dependencies among software requirements as the direction of dependencies are not specified in estimated increased (decreased) values. For instance, consider requirements R : {r1, r2, r3}, where the value of r1 positively depends on r2 and the value of r2 positively depends on r3. On this basis, it is logical to infer an implicit positive value-related dependency from r1 to r3. An Increase-Decrease model however, fails to capture this implicit dependency even if pairwise estimations show that selecting r1 and r2 as a pair, increases the value of that pair and the estimated value of the requirements r2 and r3 increases when selected together. As such, if no explicit value-related dependency is identified between r1 and r3 by pairwise estimations, the influence of r3 on the value of r1 will be ignored by the Increase-Decrease model.
It is widely known that using graphs for modeling requirement dependencies [8, 40–42] results in enhancing the accuracy of release planning [8]. On the other hand, fuzzy graphs and their algebraic structure have demonstrated to contribute to more accurate models as they can properly capture the imprecision associated with requirement dependencies [16, 17].
On this basis, we have introduced Value Dependency Graphs (VDGs) based on the classical fuzzy graphs for modeling value-related dependencies and their characteristics (quality and strength) in software projects. We have specially modified the classical definition of fuzzy graphs to consider not only the strength but also the quality of value-related dependencies as given by Definition 3.
For instance, in the VDG G = (R, σ, ρ) of Figure 1 with R = {r1, r2, r3, r4, r5}, σ (r1, r2) =+ and ρ (r1, r2) =0.4 state that selection of requirement r2 has an explicit positive influence on the value of requirement r1 and the strength of this influence is roughly 0.4. It is clear that we have ρ (r i , r j ) =0 if the value of a requirement r i is not explicitly influenced by selection of r j . In such cases we have σ (r i , r j ) =±, where ± denotes the quality of (r i , r j ) is non-specified.

A sample value dependency graph.
The strength of a value-related dependency d i : (r (0) , . . . , r (k)) is calculated by (15). That is, the strength of a value-related dependency equals to the strength of the weakest of all the k explicit value-related dependencies along the path. Fuzzy operator ∧ denotes Zadeh’s [44] fuzzy AND operation (taking infimum).
On the other hand, the quality (positive/negative) of a value-related dependency d i : (r (0) , . . . , r (k)) is calculated through qualitative serial inference [45–47] as given by (16) and Table 1. For instance, given d i : (r (0) , r (1) , r (2)), we can infer from σ (r (0) , r (1)) =+ and σ (r (1) , r (2)) =- that σ (r (0) , r (1) , r (2)) =-. This can be informally proved as given in (17), where ¬r (2) denotes ignoring r (2).
Qualitative Serial Inference in VDGs
Quantitative serial inferences in Table 1 are mathematically proved by Wellman [46] and Kleer [45]. Also, Kusiak [47] has explained the details of employing them in constraint negotiation.
Let D = {d1, d2, . . . , d m } be the set of all explicit and implicit value-related dependencies from r i ∈ R to r j ∈ R in a VDG G = (R, σ, ρ). As explained earlier, positive and negative value-related dependencies can simultaneously exist from r i to r j . The strength of all positive value-related dependencies from r i to r j is denoted by ρ+∞ (r i , r j ) and calculated by (18), that is to find the strength of the strongest positive value-related dependency [30] among all the positive value-related dependencies from r i to r j . Fuzzy operators ∧ and ∨ denote Zadeh’s [44] fuzzy AND (taking minimum over AND-ed operands) and fuzzy OR (taking maximum over OR-ed operands) operations respectively. In a similar way, the strength of all negative value-related dependencies from r i to r j is denoted by ρ-∞ (r i , r j ) and calculated by (19).
A brute-force approach to calculating ρ+∞ (r i , r j ) or ρ-∞ (r i , r j ) would compute the strengths of all possible paths from r i to r j which could get as complex as O (n !), where n denotes the number of requirements (VDG nodes). To avoid such complexity, we have formulated the problem of calculating ρ+∞ (r i , r j ) and ρ-∞ (r i , r j ) as a widest path problem (also known as the maximum capacity path problem [48]) which can be solved in polynomial time by Floyd-Warshall [31] algorithm.
In this regard, we devised a modified version of Floyd-Warshall algorithm (Algorithm 1) that computes ρ+∞ (r i , r j ) and ρ-∞ (r i , r j ) for all pairs of requirements: ∀ (r i , r j ) , r i , r j ∈ R : {r1, . . . , r n } with the time bound of O (n3). For each pair of requirements (r i , r j ) in a VDG G = (R, σ, ρ), lines 20 to 36 of Algorithm 1 find the strength of all positive value-related dependencies and the strength of all negative value-related dependencies from r i to r j .
1:
2:
3: ρ+∞ (r i , r j )← ρ-∞ (r i , r j ) ← - ∞
4:
5:
6:
7: ρ (r i , r i ) +∞ρ (r i , r i ) -∞ ← 0
8:
9:
10:
11:
12: ρ+∞ (r i , r j ) ← ρ (r i , r j )
13:
14: ρ-∞ (r i , r j ) ← ρ (r i , r j )
15:
16:
17:
18:
19:
20:
21:
ρ+∞ (r
i
, r
j
)
22: ρ+∞ (r i , r j ) ←
min (ρ (r i , r k ) +∞, ρ (r k , r j ) +∞)
23:
24:
ρ+∞ (r
i
, r
j
)
25: ρ+∞ (r i , r j ) ←
min (ρ (r i , r k ) -∞, ρ (r k , r j ) -∞)
26:
27:
ρ-∞ (r
i
, r
j
)
28: ρ-∞ (r i , r j ) ←
min (ρ (r i , r k ) +∞, ρ (r k , r j ) -∞)
29:
30:
ρ-∞ (r
i
, r
j
)
31: ρ-∞ (r i , r j ) ←
min (ρ (r i , r k ) -∞, ρ (r k , r j ) +∞)
32:
33:
34:
35:
The overall strength of all positive and negative value-related dependencies from r i to r j is referred to as the Overall Influence of r j on the value of r i and denoted by Ii,j. Ii,j as given by (20) is calculated by subtracting the strength of all negative value-related dependencies from r i to r j (ρ (r i , r j ) -∞) from the strength of all positive value-related dependencies from r i to r j (ρ (r i , r j ) +∞). It is clear that Ii,j ∈ [-1, 1]. Ii,j > 0 states that r j influences the value of r i in a positive way whereas Ii,j < 0 indicates that the ultimate influence of r j on r i is negative.
Overall influences for VDG of Figure 1
It has been widely known that the value of a software requirement is determined by user preferences (satisfaction) of that requirement. Hence, terms like customer value or business value have been preferred by some of the existing works [49, 50] to emphasize the importance of user (customer) preferences in specifying values of software requirements. User preferences for a software requirement however, may be influenced by user preferences for other requirements. In other words, users preferring (selecting or using) a requirement r j maybe be more likely or less likely to prefer a requirement r i . As such, the (customer) value of a software requirement can be influenced by user preferences for other requirements. Based on this logic, value-related dependencies among software requirements can be inferred from causal relations [32, 51–54] among user preferences for those requirements. For instance, when user preferences for a requirement r j positively influences user preferences for a requirement r i , this implies a value-related dependency from r i to r j with ρ (r i , r j ) ≠0 and σ (r i , r j ) >0.
User preferences can be gathered in different ways [50, 55–57] depending on the nature of a software release. For the very first release of a software, user preferences can be gathered by conventional market research approaches such as conducting surveys or referring to the user feedbacks or sales records of the similar software products in the market. For future releases of a software, or when re-engineering of a software is of interest (e.g. for legacy systems) however, user feedbacks and sales records of the previous releases of a software might be used in combination with market research results to find user preferences. Once user preferences are gathered, we can identify explicit value-related dependencies and their characteristics (namely quality and strength) using measures of causal strength [32, 51–54].
In this paper, we have used one of the most widely adopted measures of causal strength referred ton as the Eells measure [32]. Eells measure for an explicit value-related dependency (r i , r j ) is denoted by ηi,j and computed by (23). ηi,j specifies the extent to which selecting or ignoring r j influences user preferences of r i and consequently the value of r i . Eells measure properly captures both positive and negative value-related dependencies between a pair of requirements through subtracting the conditional probability p (r i | ¬ r j ) from p (r i |r j ), where conditional probabilities p (r i | ¬ r j ) and p (r i |r j ) denote strengths of positive and negative dependencies from r i to r j respectively. ¬r j denotes ignoring r j .
Complexity of computing Eells measure for all pairs of requirements in a requirement set of size n is n2 × u, where u is the number of users whose preferences are gathered. As such, the process is scalable to large number of requirements. Hence, automated identification of value-related dependencies adds a negligible overhead to software release planning.
To identify quality of a value-related dependency (r i , r j ), (24) gives a mapping from ηi,j to the qualitative function σ : R × R → {+ , - , ±}, where ηi,j > 0 indicates that the strength of the positive dependency from r i to r j is greater than the strength of its corresponding negative dependency: p (r i |r j ) > p (r i | ¬ r j ) and therefore the quality of d is positive (σ (r i , r j ) =+). Similarly, ηi,j < 0 indicates p (r i | ¬ r j ) > p (r i |r j ) which means σ (r i , r j ) =-. Also, p (r i |r j ) - p (r i | ¬ r j ) =0 specifies that the quality of the zero-strength value-related dependency (r i , r j ) is non-specified (σ (r i , r j ) =±).
To compute the strength of a value-related dependency (r i , r j ) in a VDG G = (R, σ, ρ), (25) gives a mapping from ηi,j to the fuzzy membership function ρ : R × R → [0, 1]. This mapping is demonstrated in Figure 2(a). Nevertheless, other membership functions such as the one in Figure 2(b) could also be used for this mapping depending on the desired behavior of the release planning model used. For instance, the membership function of Figure 2(a) ignores value-related dependencies with casual strengths below 0.16 (ηi,j < 0.16) while dependencies with ηi,j ≥ 0.83 are considered strong enough to be formulated as full strength dependencies (ρ (r i , r j ) =1).
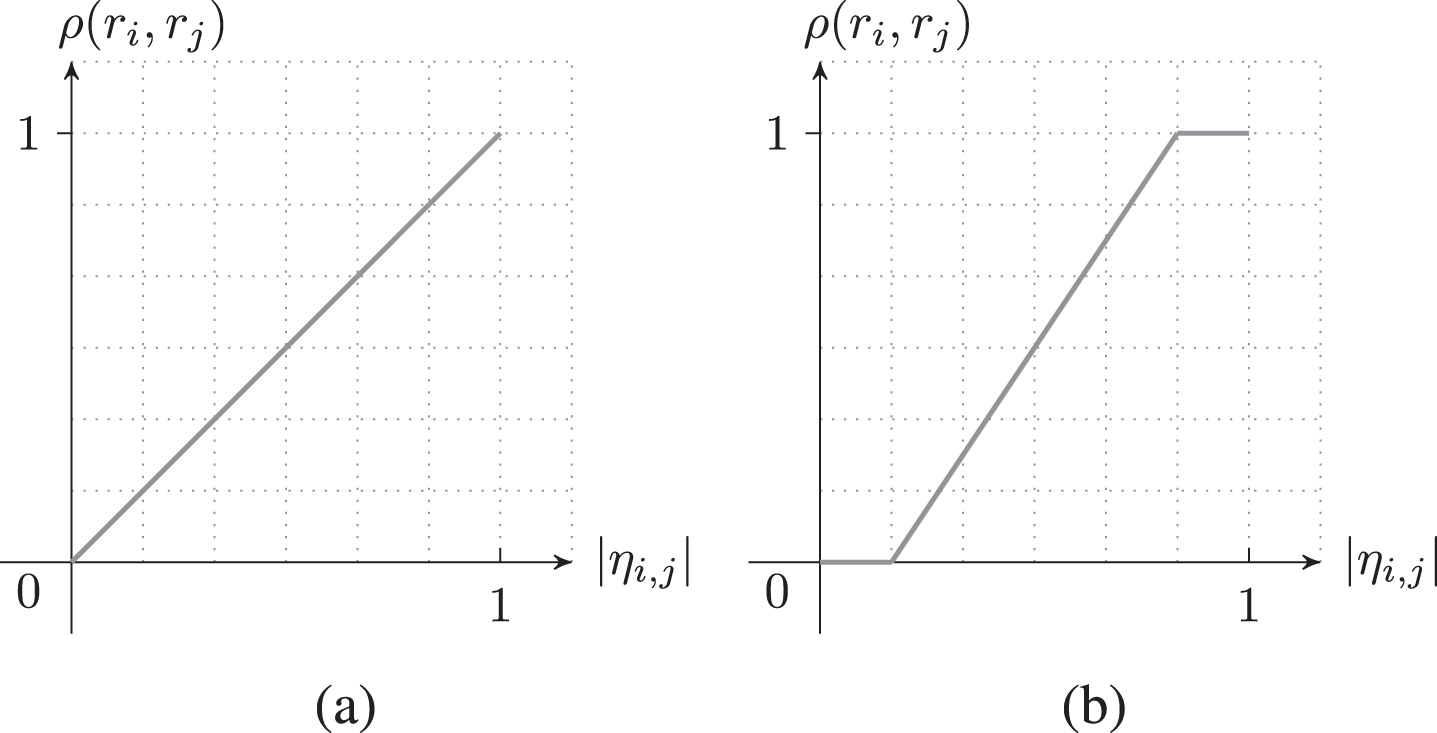
Sample membership functions ρ (r i , r j ).
When the number of user preferences gathered is limited, resampling can be used to generate samples of large (enough) quantities based on the estimated distribution of the collected user preferences. To achieve this, we use a scalable technique proposed by Macke et al. [34] to generate larger samples of user preferences using a Latent Multivariate Gaussian model [33]. Our resampling process starts with computing estimated means and variances of user preferences for each requirement. Then, covariances matrix of the requirements will be computed for generating new samples. Finally, samples of desired size will be generated based on the Dichotomized Gaussian Distribution model discussed in [33].
Finally, it is worth mentioning that, Intrinsic (structural or semantic) dependencies of full strength among software requirements (e.g. requires [7] and conflicts with [58]) also have value implications. For instance, a requirement r i requires (conflicts with) r j means that r i can not give any value if r j is ignored (selected). Hence, it is also important to be aware of value implications of intrinsic dependencies and consider them in software release planning. This could be achieved by carefully studying the structure (semantic) of a software.
As explained earlier, the value of a software requirement is determined by user preferences for that requirement [10, 59]. In other words, the higher the ratio of the users that prefer (select or use) a software requirement r i , the higher the expected value of r i would be. That means r i can achieve its highest expected value (which equals to its estimated value) when all users of r i are satisfied with that requirement. However, this only happens when user preferences for the requirement r i is not negatively influenced by selecting or ignoring other requirements. In other cases, a reduction from the estimated value of r i is predictable. The extent of such reduction is referred to as the penalty [60] of r i and denoted as p i .
We have made use of the algebraic structure of fuzzy graphs for modeling value-related dependencies and their characteristics (quality and strength) as explained in Section 3. Hence, p i is calculated using fuzzy OR operator, which is to take supremum over the strengths of all ignored positive dependencies and selected negative dependencies of r i in its corresponding value dependency graph. This is given in (26) and (33), where n denotes the number of requirements and x j specifies whether a requirement r j is selected (x j = 1) or not (x j = 0). Also, Ii,j denotes the overall strength of all positive and negative value-related dependencies from r i to r j which is referred to as the overall influence of r j on the value of r i as given in (20).
Equation (29) derives the expected value of a software requirement r
i
denoted by
Our proposed release planning model referred to as the DA-SRP (Dependency-Aware Software Release Planning), maximizes the overall value (OV) of a selected subset of requirements considering value-related dependencies among requirements. Equations (31)-(35) give the integer programming model for DA-SRP, where x i is a selection variable denoting whether a requirements r i is selected (x i = 1) or ignored (x i = 0). Also, p i specifies the penalty of a requirement r i which is the extent to which ignoring positive value-related dependencies and selecting negative value-related dependencies of r i reduce its expected value.
Simulation design
Simulation of requirement dependencies has been proposed in several works from the literature [9, 61] for analyzing the efficiency of release planning models. On this basis, we carried out simulations to compare efficiency of the DA-SRP model against that of the existing release planning models (BKP and BKP-PC models). The Increase-Decrease models however, could not be simulated as they do not specify how to formally achieve the amount of the increased or decreased values as explained in Section 2.
We simulated value-related dependencies among requirements of a real-world software project (Table 3) through random generation of qualities and strengths of explicit value-related dependencies. In doing so, for each candidate explicit value-related dependency (r i , r j ), a random number with uniform distribution in [-1, 1] was generated whose sign and magnitude determined the quality and the strength of (r i , r j ) respectively. A randomly generated 0 was interpreted as the absence of any explicit value-related dependency from r i to r j . Experiments were repeated for various levels of value-related dependencies (VDLs) and negative value-related dependencies (NVDLs) among requirements. To achieve this, certain VDLs and NVDLs were imposed on the value-related dependency graph the requirements by randomly removing edges (explicit value-related dependencies) of the graph. Also, experiments were repeated for different percentages of budgets %Budget ∈ [0, 100] to investigate efficiency of the experimented release planning models in the presence of various budget constraints.
Estimated costs and values of the requirements
Estimated costs and values of the requirements
Figure 3 and Figure 4 show percentages of the overall value (%OV = (OV/312) ×100) and percentages of the accumulated value (%AV = (AV/312) ×100) achieved from the experimented software release planning (SRP) models for two different levels of negative value-related dependencies (NVDL = {0.0, 0.5}). Give a NVDL, the experiments were repeated for various value dependency levels (VDL ∈ {0, 0.001, . . . , 1}), and different percentages of budget (%Budget = (Budget/222) ×100) as denoted by x-axis and y-axis respectively (Figure 3 and Figure 4). For selected subsets of requirements the color-bars in Figure 3 and Figure 4 denote the %OV and the %AV respectively. All our simulation results consistent with the results of our case study showed (Figure 3 and Figure 4) that for all %Budget, VDLs, and NVDLs, the BKP model always found a subset of requirements with the highest (compared to the BKP-PC and DA-SRP models) accumulated values while overall values of those subsets were not necessarily the highest. The DA-SRP model on the other hand, always found subsets of requirements with the highest overall values while accumulated values of those subsets were not necessarily the highest.
It was thus, concluded that maximizing the accumulated value of an optimal set and maximizing the overall value of that set are conflicting objectives. Nonetheless, for a given %Budget, the %OV and the %AV provided by the BKP and DA-SRP models tended to reduce and converge as NVDL was increased. To formally explain this, more information is needed. However, we can informally state that by increasing the NVDL, the chances that a selected requirement negatively influences the values of other selected requirements, will increase. As such, the chances will increase that ignoring a requirement r1 reduces the value of a requirement r2 (already selected) while selecting r1 reduces the value of a third requirement r3. The impact of increasing NVDL can be clearly observed in Figures 3(d), 3(e), 3(f), where %OV = 100 has almost never been achieved even in the presence of a sufficient budget. This is more significant in the case of the BKP-PC model (Figure 3(f)). The reason is that due to the selection deficiency problem (SDP) in BKP-PC models, increasing negative value-related dependencies will increase the chances that either selecting or ignoring requirements violates the precedence constraints and turn the candidate subset of requirements to an infeasible solution.
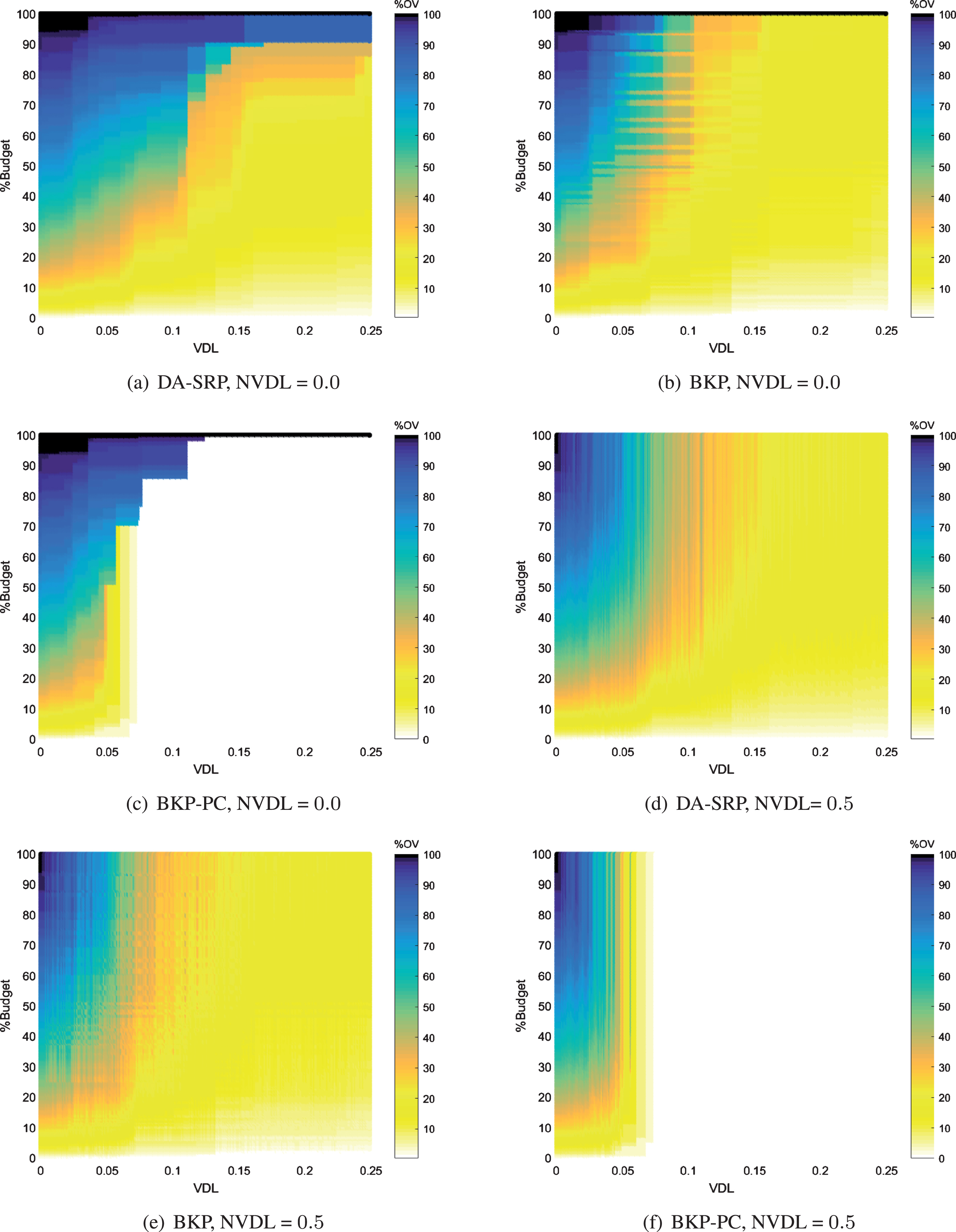
Overall values achieved from simulated software release planning models.
We also observed (Figure 3 and Figure 4) in all experiments that overall values given by BKP-PC model were equal to their corresponding accumulated values. The reason is that the BKP-PC model treats all value-related dependencies as binary relations which results in a situation, where a requirement is only selected if all of its positive (negative) value-related dependencies are selected (ignored). As such the penalties of requirements are always calculated as 0.
Our results further, showed the selection deficiency problem (SDP) [25] severely impacted the %AV and %OV achieved from the BKP-PC model in general. This was further exacerbated for higher NVDLs as in such cases not only ignoring but selecting certain requirement resulted in value loss due to the presence of negative value-related dependencies. For instance, for NVDL = 0.0 we have VDL > 0.12, % Budget < 100 ⇒ % AV (BKP - PC) = % OV (BKP - PC) =0 while for NVDL = 0.5 we have VDL > 0.07 ⇒ % AV (BKP - PC) = % OV (BKP - PC) =0.
Finally, we observed (Figure 3 and Figure 4 that) that DA-SRP properly mitigated the impact of SDP by providing some %AV and %OV when the BKP-PC model was not able to provide any value. The reason is DA-SRP considers the impacts of the ignored (selected) positive (negative) value-related dependencies rather than treating those dependencies as binary (exists/does not exist) relations. The BKP model however is not subject to the SDP as it completely ignores requirement dependencies all types.

Accumulated values achieved from simulated software release planning models.
Scalability of the work has two main aspects. First, scalability of the dependency identification and second, scalability of our proposed selection model (DA-SRP). Regarding the scalability of the dependency identification, we have automated the process of identifying value-related dependencies based on user preferences for software requirements as described in Section 4. Hence, there would be no need for manual comparisons. Our automated dependency identification process is based on the fact that the (expected) value of a requirement is determined by user preferences for that requirement. In this regard, Eells measure of casual strength [32] is used to measure strengths of value-related dependencies based on user preferences.
The algorithm for computing Eells measure is computationally efficient as it only calculates conditional probabilities for pairs of requirements and their complements. For n requirements hence the complexity is of O (n2). We have further suggested considering value-implications of precede dependencies (r1 requires/precedes/conflicts-with r2) when such information is available. Precede dependencies are normally identified prior to the release planning as part of requirement analysis. Identifying such dependencies is not specific to our release planning model and therefor does not add any additional overhead to it.
DA-SRP, as given by (31)-(35), formulates a Convex Optimization Problem since the model maximizes a Concave objective function over linear constraints [62]. Convex optimization problems are known to be efficiently solvable [62]. To further improve this we used the technique introduced in [63] to linearize the DA-SRP model. The model showed to be scalable to large number of requirements as depicted in simulations results of Figure 5). We performed simulations to demonstrate scalability of the DA-SRP model in comparison with the existing BKP and BKP-PC models. Uniformly distributed random numbers were generated to simulate the costs and values of requirements as well as the strengths of value-related dependencies among them. The callable library ILOG CPLEX [64] was used to implement and run the BKP, BKP-PC, and the DA-SRP models. All simulations were performed on a Windows machine (Windows 8.1) with 8 GB of RAM and a Core i5-4300 CPU with the speed of 1.9 GHz to 2.49 GHz.
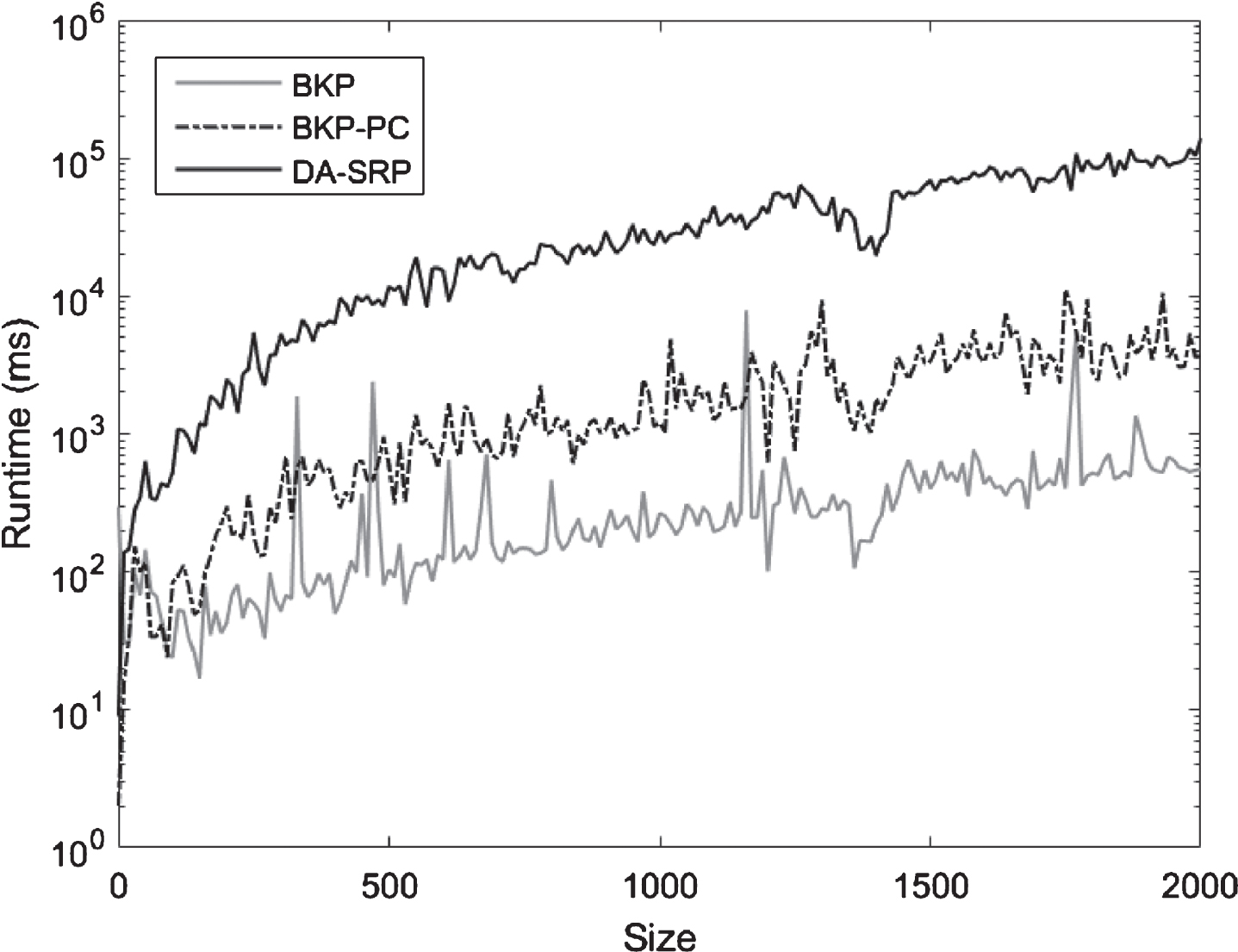
Runtime of experimented SRP models for different numbers of requirements (size).
Figure 5 shows our results with a logarithmic y-axis specifying the run-time of the experimented release planning models and a linear x-axis denoting the size of the experiment (the total number of requirements). Our simulations for random requirement sets of various sizes (Size = {0, 1, . . . , 2000}) demonstrated (Figure 5) that the DA-SRP model always found the optimal subset of the requirements (a subset with the highest overall value for a given budget) in less than 2 minutes. However, the run-time of the DA-SRP model was higher than that of the BKP and BKP-PC models while the BKP model performed faster than the BKP-PC and DA-SRP models (Figure 5). The reason is the BKP model ignores value-related dependencies and therefore can be executed in semi-polynomial time using dynamic-programming [65] while the BKP-PC needs to satisfy the precedence constraints which capture value-related dependencies and therefore, it takes longer for the BKP-PC model to find the optimal subset of the requirements (solution). The DA-SRP model on the other hand, considers value-related dependencies in addition to the precedence constraints, which increases the execution time of the model and makes it slower than BKP and BKP-PC in general.
In this paper we presented an integer programming model for software release planning which optimizes the overall value of a software release by considering strengths and qualities of value-related dependencies among software requirements. We further introduced, based on fuzzy graphs, value dependency graphs and their algebraic structure for modeling value-related dependencies and reasoning about qualities and strengths of those dependencies. A modified version of the Floyd-Warshall algorithm was introduced to infer value-related dependencies and their characteristics in polynomial time. Moreover, a scalable technique was proposed for automated identification of explicit value-related dependencies and their characteristics based on user preferences. We also demonstrated application of a latent multivariate Gaussian model for generating samples of large (enough) quantities from user preferences to enhance accuracy of dependency identification.
We demonstrated through studying an industrial software project and conducting several simulations that: (a) the DA-SRP model can properly capture value-related dependencies in software release planning while being reasonably scalable, (b) the proposed DA-SRP model efficiently mitigates the selection deficiency problem, (c) the DA-SRP model always maximizes the overall value of selected requirements, and (d) maximizing the overall value, with considering value-related dependencies, and the accumulated value, without considering value-related dependencies, of a selected subset of software requirements are conflicting objectives.
This work can be extended in several directions. One is to explore different measures of casual strength and comparing their efficiency in capturing value-related dependencies. To assist dependency identification, one may also consider mining online resources such as social media and software repositories. In this paper we studied value as the economic worth of a software. But, it is also important to consider social aspects of software and their impacts on the society. Considering social values of software are particularly important to stakeholders with special preferences e.g. users with disabilities. It would be interesting hence to integrate social values in software through considering those values in software release planning. In this regard, considering dependencies/conflicts among social values and reconciling those into software would be imperative.