
Abstract
Context Aware Recommender Systems exploit specific situation of users for recommendations, hence are more accurate and satisfactory. Neighborhood based collaborative filtering is the most successful approach in this area owing of its simplicity, intuitiveness, efficiency and domain independence. The key of this approach is to find similarity between users or items using user–item–context rating matrix. Typically, context aware datasets are highly sparse since there are not enough or no preferences under most contextual conditions. Traditional similarity measures such as Pearson correlation coefficient, Cosine and Mean squared difference suffer from co-rated item problem and do not consider contextual conditions of the users. Therefore, these measures are not effective for sparse datasets. Therefore, the aim of this paper is to propose a new similarity measure and its variants based on Bhattacharyya Coefficient which are suitable for sparse datasets weighted by contextual similarity. Subsequently, we have applied them in neighborhood based algorithms where each component is contextually weighted. The experiments are performed on two contextually rich datasets which are especially designed to do personalization research instead traditional well known datasets. The results for Individual and Group recommendations indicate that the proposed similarity measure based algorithms have significantly increased the accuracy of predictions over traditional Pearson correlation coefficient measure based algorithms.
Keywords
Introduction and motivation
Context aware recommender systems (CARS) [6, 7] have been shown to provide more accurate and refined recommendations by utilizing additional information called context, available to the system in various domains such as movie recommendations [2, 7], food suggestion [22, 25], travel accommodation [24] and mobile applications [6, 7]. Context influences the user preferences highly, so researchers have started focusing on utilization of the contexts to enhance accuracy and user’s satisfaction [2, 7]. To exemplify few situations, a) The choice of a movie for a person would be different if he/she is planning to watch it with friends at cinema rather than with kids at home. b) A person would choose a different restaurant when he/she is going on quick business lunch instead dining with family.
Typically, datasets are sparse and the sparsity problem become more severe when preferences are filtered with contextual information. Giving equal weightage to less contextually similar preferences can add noisy data and their not inclusion will cause data sparsity problem. Scalability refers to handling large amount of data efficiently and effectively. So utilization of context, managing sparsity and scalability problems in different techniques remains the challenging areas of researchers in CARS [6, 22–28].
To deal with these problems and provide more accurate recommendations, many techniques have been geared up. Among others, Matrix Factorization represents relationship between users and items through latent factors called features. For this it forms low rank matrices and the multiplication of these matrices allows item recommendations [19]. When contextual information is incorporated in standard matrix factorization it forms Context-Aware Matrix Factorization [11]. CSLIM in [23] is described as a contextual sparse linear method that incorporates contextual information in matrix factorization. Baltrunas et al. in [13] established a user–item splitting approach which holds multiple copies of user–item-ratings in different contexts and when recommendations are sought then user–item matching current context are retrieved. Yang et al. in [4] proposed a model based method that maps matrix factorization technique into social trust network for accuracy improvement and manage data sparsity. DCTMF is described as a trust and context based technique which forms dynamic trust model with context aware matrix factorization utilizing social network analysis [11]. Paradarami et al. in [20] proposed a hybrid model that uses content and collaborative based features with artificial neural network to generate model based prediction for business–user combination. However, the Collaborative filtering (CF) has drawn a great deal of research since it not only provides personalized recommendations to customers based on their tastes, preferences and restriction but also increase profits of electronic retailers such as Amazon and Netflix [6, 7]. The growing demand in this area leads to inclusion of context in collaborative filtering. Neighborhood based collaborative filtering (NBCF) approach is much appreciated in this area because of its simplicity, intuitiveness, domain independence and has no learning phase. It relies on active user’s neighbors having similar tastes. Also it requires a single parameter (K- number of neighbors) unlike other methods which require many parameters (regularization parameter ν, learning parameter η etc.) [6, 18]. In [24], Zheng et al. proposed a NBCF method with differential context relaxation where few relaxed constraints are used with valid and influential context attributes to fix data sparsity. [26] presented and evaluated an approach where contexts are weighted and utilized in user neighborhood based model. In [27], Zhang et al. proposed a framework to produce recommendations based on rough set theory and collaborative filtering. All NBCF methods employ various similarity measures such as Pearson correlation coefficient (PCC), cosine similarity and their variants to make predictions. Among these measures PCC is most popular and successful similarity measure since it produces least error [3, 16] but PCC and all other traditional measures suffer from the following drawbacks. Few co-rated items: These measures cannot calculate similarity between two users if there are no/few co-rated items and also between two items, if they are not co-rated by common user. One co-rated item: In this case, PC outputs value either +1 or −1 and cosine gives 1 in spite of their ratings assigned to item. Local information: Only local information is utilized by these measures ignoring global information of the users and/or items. Contextual information: Contextual information related to ratings are not considered by these measures.
Therefore, these measures are not suitable for sparse datasets especially context aware datasets where very few rating are assigned by the users to items in different contextual situations [1, 6–8]. Recently, similarity measures have gained a lot of attention. Patra et al. in [3] described and evaluated a similarity measure based on Bhattacharyya coefficient which uses all the ratings made by a pair of users. Monroy-Tenorio et al. in [5] introduced new correlation measures for measuring similarity and association of rating profiles obtained from bipolar rating scale which overcome the drawbacks of PCC. Also, Batyrshin et al. in [10] presented and discussed particular cases of bipolar rating scale. Furthermore, they proposed new correlation measures on bipolar scale which can be used by Recommender systems (RS), sentiment analysis and opinion mining.
In this paper, we propose a novel approach to compute similarity between two users/items which is suitable for sparse datasets. Proposed measure and its variants can also compute similarity in the presence of few/none co-rated items and consider all rating information made by a pair of users/items. Proposed measure and its variants also find and include similarity between the context in which ratings are assigned to give them appropriate weightage. Furthermore, we propose a framework utilizing the proposed measures to produce recommendations for users which is suitable for sparse dataset. Instead of evaluating the proposed framework on traditional well known datasets which are not representative enough to test the context aware approaches, we have used two contextually rich datasets. The proposed similarity measures and framework can work on any context aware recommendation problem independently of the number and meaning of context dimension. This makes it applicable in real life recommender systems.
Several variants of a weighted similarity measure are proposed which exploits all ratings made by a pair of users/items and give more importance to those ratings which are contextually more similar. We propose a range of user based and item based techniques where notion of context similarity is introduced in each component of the algorithm to make those rating more valuable which are contextually more similar. Also, these techniques use our proposed similarity measure. To analyze the effectiveness of our proposal, we extended our work to Group Recommendations where three group recommendation techniques are evaluated and compared on different sizes of groups.
The remaining paper is structured as proceeded. Section 2 mentions few related works. The model framework and detailed constructions of our recommender system are introduced in Section 3. Experimental results and analysis are presented in Section 4. The conclusions follow in Section 5 and finally, we give some perspective of future research.
Background and related work
This section presents background of neighborhood based CF approach and similarity measures briefly with some recent studies.
Neighborhood based approach
The memory based methods are also called neighborbood based methods (NBCF) and are introduced by GroupLens: Collaborative filtering of netnews article [3]. These methods are widely used in commercial domains because of single parameter requirement, their domain independence nature [6, 18]. The user NBCF method forms user neighborhood and utilizes similarity between active user and neighbor users [6, 18]. The prediction of rating by NBCF is defined by the following Equation:
sim (u
a
, u
k
) represents the similarity value between user u
a
and u
k
calculated using Equation (2), n is the total number of neighbors in neighborhood set,
The item based method was introduced in [3, 16] and is exploited by Amazon Inc., the biggest trader through internet on globe [3]. Unlike user based methods, it computes similarity between items and utilize neighborhood of active item for rating prediction task [3].
Similarity computation is a crucial step in NBCF. Researchers and practitioners are still working in this area. We are discussing them next in brief.
Traditional similarity measure such as PCC, cosine, adjusted cosine, constrained pearson correlation, mean square difference, jaccard are frequently used in CF but suffers from few co-rated item problem and do not utilize all ratings provided by pair of users [3, 16].Therefore these measures do not suit sparse data. For example, PCC computes similarity between users u a and u b using the following equation:
In [16], Candillier et al. suggested three variants of similarity measure by combining jaccard with PCC, cosine and manhattan in order to benefit from their complementarity. [28] evaluated various similarity measures suitable to categorical data and can be used in clustering. Yin and Deng in [17] proposed Belief Transferring Similarity model to address the issue of data sparsity by considering high-order similarity. The model also combined transferring similarity via information fusion. [12] proposed a modified heuristic similarity measure that combined PCC, jaccard and modified BC considering global preferences and local contexts of the user behaviour. A hybrid similarity model for CF is suggested in [21] using Proximity–Significance–Singularity pointing out the rating preferences of different users and hence improved reliability. But none of them have given any importance to contextual situation in which ratings are assigned. Also item based models are not explored by them.
In this section, we propose a framework, Weighted Context Similarity Based Recommendation Unit (WCSBRU) as depicted in Fig. 1 which provides techniques to generate context aware recommendations and is suitable for sparse dataset. These techniques intelligently use proposed similarity measures and contextual similarity between two vectors in different components of the user and item neighborhood based algorithms. The proposed techniques are explored in the domains where items are typically recommended to individuals as well as group of users.

The proposed framework.
The context factors that are utilized by the framework to compute context similarity are the ones which are assessed and detected relevant in the previous work done by the domain experts and feature selection approaches [2, 25]. Odic et al. in [2] statistically prove daytype, social, location, time, endEmo, domEmo, mood, physical, decision and interaction as valid and influential context factors in LDOS–CoMoDa dataset while season and weather are found irrelevant.
Movie genre may also change user preferences during the process of the actions as described in [22]. In LDOS–CoMoDa dataset, each movie belongs to three genres i.e. genre1, genre2 and genre3. So the context similarity is calculated using context factors and all genres.
Using IncarMusic dataset, all context factors including driving style, traffic conditions, sleepiness, natural phenomenon, landscape, road type, mood, weather and music genre are adapted to calculate context similarity [14].
Context similarity measures
To give importance to contextual situations while making recommendations [26], all the ratings are weighted based on context. It assumes that those ratings become more valuable in making predictions whose contexts are more similar to that of active user.
However, ratings with low context similarity may enhance noise while making predictions, so a set of similarity thresholds are established in each component of prediction algorithm. This also means that ratings having context below the threshold are ignored.
Overlap/simple matching coefficient
The simple matching coefficient (i.e. Overlap) [28] determines the similarity between two objects. Assume that o
pr
and o
qs
are two objects with context vectors r and s respectively. If cth feature of both vectors r and s matches then it takes value 1, otherwise 0. The similarity between two objects for cth feature is defined as:
Then the total similarity measure between two objects is defined by the following:
Advantage: It is simple, effective and widely used [28].
Disadvantage: It neglects characteristics of a dataset such as number of categories or frequencies of categories of a given context feature [28].
Eskin measure
The Eskin measure was proposed by Eskin et al. in the year 2002 [28] and assigns higher weights to mismatches in attributes with the higher number of categories. Eskin computes similarity between two objects o
pr
(with context vector r) and o
qs
(with context vector s) for the cth feature as:
Then the total similarity measure between two objects calculated by Eskin is as follows:
Advantage: It assigns higher weight to mismatches in attribute with higher number of categories.
Disadvantage: It performs poorly in those datasets where attributes take large number of values.
Illustrative example
Table 1 shows ratings assigned by different users to movie ‘M’ in different contextual situation.
Scenario of using Context Similarity
Scenario of using Context Similarity
From Table 1, the context similarity using Overlap measure between two users is computed as
In this section, we present the details of all the algorithms proposed in our framework.
Neighborhood selection
Here, the neighborhood (Na,θ1) of active/target user a is the weighted version of user neighborhood which includes those users as neighbors who have rated active item i and their context similarity is greater than the threshold value θ1 with the active user context vector c as described by Equation (3). The neighborhood (Ni,θ1) of active item i is weighted version of item neighborhood which includes those items as neighbors which are rated by active user a and are contextually similar as described by Equation (4). Typically, in context aware datasets an item is rated differently by a user in different contextual situation, so maximally similar context users are chosen by applying threshold.
For weighted version of neighbor contribution, the Equation (5) calculates sum of all ru,i,d (ratings obtained from neighborhood) which possess context (i.e. vector d) similarity greater than θ2 with active user (a)/active item (i) having context vector c. Furthermore, rating is weighted by context similarity.
The weighted average of all ratings of a neighbor user u in user neighborhood model is described by Equation (6).
The active user baseline
This section describes our proposed similarity measure and its variants which overcome the limitations of traditional similarity measures and suit well to sparse data.
Bhattacharya measure
The Bhattacharyya measure finds similarity between two probability distributions.
Let
Illustrative example
The rating vectors of items I and J by different users are given in the Table 2 where 0 represents that the item is not rated by the user and range of ratings is {1, 2, 3}. It can be seen in the Table 2 that there is no single user who has rated both items I and J. The traditional similarity measures could not compute similarity in this scenario.
Rating vectors of items I and J
The BC coefficient is given by
Weighted similarity measures exploiting Bhattacharyya coefficient in sparse dataset
The proposed similarity measures are named as Overlap with Bhattacharyya coefficient (O - BC) and Eskin with Bhattacharyya coefficient (E - BC). These similarity measures not only use co-rated items but also all other ratings made by both users. These measures also combine local and global similarity values. The similarity between two users u and v is defined by Equation (11).
O - BC and E - BC gives more importance to local similarity if both a and b are same items i.e. (BC (a, b) = 1) and minimum if they are totally dissimilar i.e. (BC (a, b) = 0).
The local similarity function loc (*) provides local information and can be computed using two Equations (12 and 13).
where r m is the median of ratings rated by user u and r ua is the rating assigned to item a by user u.
To provide more importance to those users which are contextually more similar, sim (u, v) or sim (i, j) is multiplied with context similarity between two context vectors c and d of corresponding users/items. The weighted variants of sim (u, v) or sim (i, j) are given by Equations (14)–(21).
In this section, we elaborate on all the algorithms proposed in the framework (Fig. 1) in detail which are described by Equations (22)–(29). The various notations used in the proposed algorithms are presented with their meaning in Table 3. The similarity measures used by the proposed algorithms are defined by Equations (14)–(21).
Notations and their meaning used in the algorithms
Notations and their meaning used in the algorithms
The Equations to predict the rating for unrated item i by active user a are as follows:
Weighted Context (using Overlap) User Based with correlation (WCUBO-BC(cor))
Weighted Context (using Eskin) User Based with correlation (WCUBE-BC(cor))
Weighted Context (using Overlap) User Based with median (WCUBO-BC(med))
Weighted Context (using Eskin) User Based with median (WCUBE-BC(med))
Weighted Context (using Overlap) Item Based with correlation (WCIBO-BC(cor))
Weighted Context (using Eskin) Item Based with correlation (WCIBE-BC(cor))
Weighted Context (using Overlap) Item Based with median (WCIBO-BC(med))
Weighted Context (using Eskin) Item Based with median (WCIBE-BC(med))
The main goal of this unit (as described in Fig. 1) to present the details of group recommendation techniques used in the framework i.e.: Merging, Multiplicative, and Merging–Multiplicative. Several works [9, 15] found Merging as a simple, efficient and widely used method as group technique. [9] suggests Multiplicative technique to be more effective in terms of individual satisfaction and Merging–Multiplicative as superior than the other two techniques. To see the effectiveness of our proposed algorithms on group of users, we evaluated them with the following grouping techniques.
Merging
In this method, top-n recommended items for each group member is obtained and then merged them into a single list and then top-n items are recommended to the group as a whole [9].
Multiplicative
This method makes an aggregated rating after multiplying the predicted ratings of each group member and finally, the candidate items i.e. top-n items with highest predicted ratings are selected for recommendations [15].
Merging–multiplicative
First off, this method receives top-n recommended items for each group member and then combine them into a single list for the group as a whole. Here, merging is used to filter items with highest ratings then aggregated rating is obtained after multiplying the predicted rating for individual member and then top-n items with highest predicted ratings are recommended to group as a whole [9].
Experimental evaluation
To analyze the effectiveness of Weighted Context Similarity Based Recommender System framework, we have performed several experiments. We address the following issues through these experiments: How do the proposed similarity measure and its variants perform in comparison of other traditional similarity measures? To analyze proposed algorithms based on user and item neighborhood model in context aware scenario. Do the proposed algorithms effective for group recommendations?
Data preparation and evaluation metrics
We conduct the experiments on two contextually rich datasets which are specially designed for context aware personalization research. The LDOS–CoMoDa dataset belongs to movie domain and can be obtained by requesting the associated researchers at the University of Ljubljana (User-adapted communications & ambient Intelligence Lab). The description of LDOS–CoMoDa dataset is available in previous research [1]. The IncarMusic dataset belongs to music domain and is publicly available [8]. The summary of these datasets are given in Table 4.
The statistics of datasets
The statistics of datasets
After filtering out users with less than three ratings, we randomly partitioned the datasets into three parts out of which two parts are used as training set and rest one is considered as test set. The experiments are repeated five times and average over five runs are presented for all measures. The predictive performance is measured by mean absolute error (MAE) and root mean squared error (RMSE). Precision, Recall and F1-score (F1-measure) for top 10 items are used to perform item recommendations task. Here, an item is considered relevant (a hit) only if it is rated greater than or equal to 4 (among 5) by the active user using both IncarMusic and LDOS–CoMoDa datasets. We set the minimal coverage threshold θ as 0.5 for all components of the algorithms after rigorous parameter tuning for both datasets i.e. IncarMusic and LDOS–CoMoDa since rating scale is same (1–5).
For group recommendation, each approach is evaluated with 5 Random Groups of each size i.e. Small Group (SG)(size 3–5) and Large Group(LG)(size 6–8). The average of F1-score metric for five runs is presented for this case.
We use the following methods based on user and item neighborhood models to compare the proposed algorithms using LDOS–CoMoDa and IncarMusic datasets.
Results and analysis
Here, we present and analyze the experimental results for LDOS–CoMoDa and IncarMusic datasets.
From Fig. 2(a) and (b), it is proved that the proposed similarity measure based algorithms perform much better than PCC based CF (MAE values are increased by more than 10%). The reason might be that CF using PCC measure could not utilize all rating information instead sometimes used only one or zero rating for prediction. It is seen in Figs. 2(a, b) and 3(a) and (b) that proposed similarity measures based on BC(med) is closest competitor of the ones using BC(cor) in terms of predictive accuracy (MAE and F1-score) amongst all others and correlation based proposed similarity measures outperform. Figure 2(a) shows that E-BC(cor) in LDOS–CoMoDa dataset produces more error than O-BC(cor) since Eskin performs poorly in those datasets in which attributes take large number of values. On the other hand, E-BC(cor) performs better than O-BC(cor) with IncarMusic dataset (see Fig. 2(b)). This clearly says that no single measure is always superior or inferior and different similarity measures handle different characteristics of a dataset (refer Table 5).

Performance comparison of various contextually weighted similarity measure based algorithms using MAE and RMSE on two datasets. (a) LDOS–CoMoDa (b) IncarMusic.
Summarized best results of the proposed algorithms for Individual User (Single) and Group of Users (SG represents Small Group and LG represents Large Group). Results for SG and LG are presented using Merging-Multiplicative technique
Hence, it can be concluded that proposed similarity measures shows significant improvement and BCF(cor) based similarity measures are the best performing one. Also, Overlap and Eskin measures used for contextual similarity are dataset dependent.
It can be seen in Fig. 3(a) and (b) that proposed algorithms are more accurate (F1-score improves more than 10%) compared to the algorithms based on PCC. Table 5 and Fig. 2(a) and (b) clearly indicates that WCIBO-BC(cor) is superior than WCUBO-BC(cor) using LDOS–CoMoDa dataset and WCIBE-BC(cor) is better than WCUBE-BC(cor) with IncarMusic dataset (in terms of MAE and F1-measure).
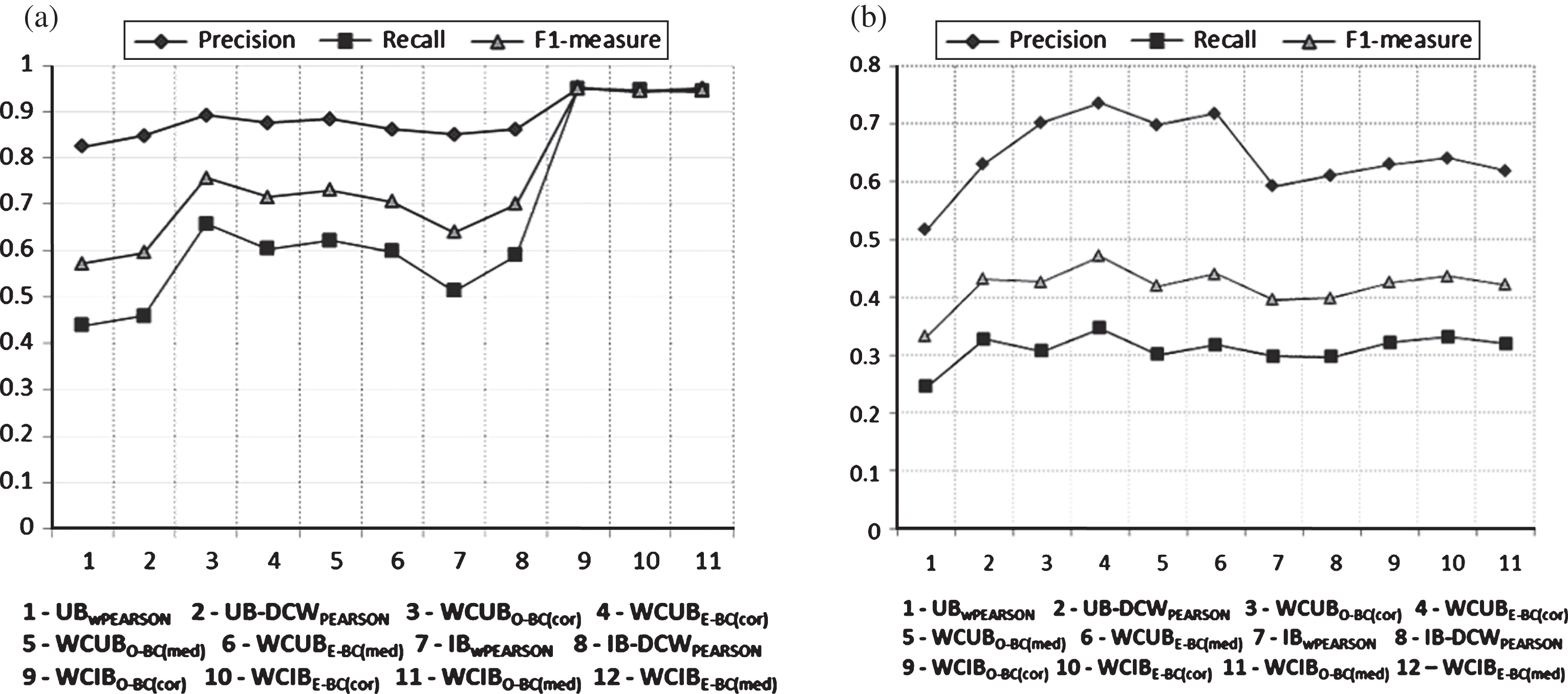
Effect of different weighted similarity measure based algorithms on Precision, Recall and F1-measure w.r.t. two datasets. (a) LDOS–CoMoDa (b) IncarMusic.
Figure 3(a) shows that F1-measure achieved by WCIBO-BC(cor) is close to 0.95 and its closest competitor WCIBO-BC(med) obtain the value close to 0.94. The difference in the accuracy (F1-measure) of recommendations in user and item neighborhood based models is more than 20% in movie dataset unlike the music dataset (refer Table 5, Fig. 3(a) and (b)). The PCC similarity measure based algorithms performed worst. This indicates that they could not retrieve items properly.
The PCC based algorithms i.e. UBwPEARSON, IBwPEARSON, UB - DCWPEARSON and IB- DCWPEARSON get F1-measure value less than 0.7 (from Fig. 3(a)) and 0.42 (see Fig. 3(b)) in movie and music domain respectively. This clearly indicates PCC based algorithms are not much reliable to produce recommendations in sparse datasets.
Our proposed algorithms can handle highly sparse datasets in much more effective way and algorithms using item neighborhood are better than user neighborhood based algorithms.
In general, Table 5 clearly says that the proposed algorithms perform equally well and produce accurate recommendations for group of users like individuals. The accuracy is slightly declined with increase in the group size since F1-measure values obtained using large group is approx. 1% less than small group in all algorithms (from comparison of Fig. 4(a) and (b)). Figure 4(a)–(d) also reveals that Merging technique performs uniformly worse and Merging–Multiplicative shows a substantial improvement over other two grouping techniques. An improvement in F1-measure value for Group recommendations is also noted during experimentation which reveals that the aggregation of the ranked lists of the group members is able to fix errors which otherwise produced by the individual predictions (refer Table 5). This might happen if individual predictions are not very good.
Hence, the proposed algorithms are effective for group recommendations also.
In this paper, we overcome the drawbacks of existing Pearson Correlation similarity measure using Bhattacharya coefficient based similarity measure and its variants. These measures suit well to even highly sparse data and give importance to contextual similarity. Furthermore, several algorithms exploiting the variants of proposed similarity measures are explored through the proposed framework. We have shown that the proposed algorithms make a significant improvement over traditional Pearson correlation similarity measure based algorithms in both user based and item based approaches because they do not depend on co-rated items and give importance to context similarity. We have also confirmed that item neighborhood based algorithms leads to better results than user neighborhood based algorithms. This also has been verified that correlation based variants of proposed similarity measure performs slightly better than median based variant. The performance of Overlap and Eskin measure used to find contextual similarity is dataset dependent. The reason might be Eskin depends on the number of values an attribute can get which is not true with Overlap. Finally, the algorithms are also proved to be significant for group recommendations.
In future, the research can be further directed to explore some other similarity measures as local measures in the proposed algorithms. The proposed framework can also be utilized to provide diverse recommendations with reliability.