
Abstract
With the development of science and technology and the continuous improvement of people’s living standards, the traditional staff quality evaluation can no longer meet the needs of production and life, and the BP neural network has also appeared many shortcomings in practical applications. This article mainly studies the company’s employee quality evaluation model based on BP neural network. This article first collects and preprocesses employees’ usual performance data, and then predicts their corresponding quality scores based on BP neural network. And use MATLAB software to simulate the constructed prediction model, and finally develop a complete set of employee performance data prediction system based on this model, so as to achieve the purpose of employee quality evaluation. The experimental data in this paper shows that the average relative error of model training output tends to be stable. After the 40th iteration of training, the average relative error of model training can reach 0.0128. After the prediction model training was completed, 15 sets of verification samples were used to verify the model. The verification results found that the average relative error of the model converged, so the model did not overfit. Experimental results show that although BP neural network has two excellent functions of adaptive and nonlinear approximation, it can solve the complex nonlinear relationship between normal performance and overall performance. But BP neural network still has its own inevitable shortcomings in some aspects. For example the redundancy between the employee scoring sample data; the problem that the input variable dimensionality is too high, which leads to the low efficiency of the model; the fuzzy neural network is easy to fall into the local optimum and it is difficult to find the global optimum.
Introduction
With the rapid development of computer science and technology, artificial intelligence has formed a discipline, and its application in the neighborhood of target recognition has also shown great vitality. Through the fusion of multiple intelligent recognition methods, the recognition rate of targets has been improved. With the development of artificial intelligence, more and more intelligent recognition algorithms based on target recognition have been proposed, and fuzzy neural networks (FNN: Fuzzy Neural Network) have also been proposed. Then it appears [1]. The fuzzy neural network is composed of fuzzy logic and neural network. It can deal with uncertain information, knowledge storage and self-learning ability. It has special advantages in target recognition and classification, so how to better apply fuzzy in the field of target recognition Neural network technology has received attention from all aspects and has become a hot spot in current target recognition research.
Fuzzy systems do not have many advantages in learning and automatic pattern recognition, but neural networks have great advantages in this respect. To solve the problem of the self-adaptability of the fuzzy system, the neural network is used to process the fuzzy information in the fuzzy system, which solves the problem of the automatic generation of fuzzy rules and fuzzy membership functions in the fuzzy system. A neural network can deal with information in a relatively narrow range, and the ability to process fuzzy information is relatively poor, then the fuzzy theory can be introduced to deal with fuzzy information, so that neural networks can handle both accurate and fuzzy information, and expands the neural network. Scope of application. The fuzzy neural network has the following advantages, strong learning and expression ability, strong adaptability, and the ability to process fuzzy information. Therefore, the prospect of fuzzy neural networks is very good, and the scope of application will be broader [2].
In this paper, fuzzy logic and BP neural network are organically combined, and a three-layer fuzzy quantization and BP neural network collaboration model is proposed. The model can integrate the approximate adaptability of the fuzzy theory and the randomness of state in the qualitative aspects of classic fault problems and combines the advantages of the BP network, can meet the self-training and learning ability of the neural network and will have a three-layer structure. The collaborative model is applied to the intelligent identification of a marine diesel engine failure and has high practicability. The combination of fuzzy theory and BP neural network can not only give full play to the characteristics of the original two but also improve each other’s less mature processes and algorithm mechanisms through mutual reference, especially in terms of fitness settings, which significantly improves the two common The performance of the applied algorithm provides a broader idea for the development of the fault diagnosis system.
Based on the research results of current forecasting methods, this article discusses in-depth the important role of employee quality assessment forecasting in company management. At the same time in-depth study of data mining, fuzzy systems, artificial neural networks, genetic algorithms, fuzzy neural networks and principal component analysis and other basic theories. A fuzzy neural network employee overall quality evaluation model based on principal component analysis and genetic algorithm is proposed. The model can accurately predict the quality of employees. Based on this, the completed quality prediction system can evaluate the overall quality of employees. The main contents are as follows: Introduces related concepts and basic processes of data mining. The employee quality sample data collected from the usual scoring has been pre-processed accordingly; The principle of principal component analysis is studied, and the steps of principal component analysis are introduced. Perform dimensionality reduction on the pre-processed employee quality score sample data; Introduced the related principles and basic flow of the genetic algorithm. Using a genetic algorithm to optimize the antecedent parameters of the fuzzy neural network, it is easy to find the global optimal value. In-depth study of the fuzzy neural network model. The results of MATLAB simulation experiments verify that the fuzzy neural network performance prediction model optimized by principal component analysis and genetic algorithm is feasible and effective.
Proposed method
Related work
Baowei Wang believes that using the Meteorological Wireless Sensor Network (WSN) to monitor air temperature (AT) can greatly reduce the cost of monitoring. It has the characteristics of easy deployment and high mobility. However, low-cost sensors are easily affected by the external environment, which usually leads to inaccurate measurement results. Previous research has shown that there is a close relationship between AT and solar radiation (SR). Therefore, he designed a backpropagation (BP) neural network model with SR as the input parameter to establish the relationship between all data in May and SR and AT error (ATE). Then, we use the trained BP model to correct errors in other months. He evaluated the performance of the data set in a previous study and then compared the maximum absolute error, average absolute error, and standard deviation, respectively. His experimental results show that the method has the good competitive performance. It is proved that the BP neural network has a strong nonlinear fitting function, which is very suitable for solving this problem [3]. Based on the second development of the FLUKE 411D laser ranging module, Bing Wu proposed a general implementation method for laser ranging from micro UAVs. The micro UAV DJI Phantom1 completed the airborne dynamic laser ranging experiment. Through the data processing based on the method based on the least square method and the BP neural network, the measurement error obtained by the method based on the BP neural network is 4.35%, much lower than the 6.69% based on the least square method. This means that the method based on BP neural network can significantly improve the measurement accuracy. Therefore, the airborne laser ranging error compensation method based on BP neural network is effectively verified [4]. Zhang J believes that a color correction algorithm based on color space conversion is an important part of the color management system. Depending on changes in conditions (such as limitations of imaging formation principles, equipment performance, and processing control), compared to actual images, captured images often contain certain color distortions. Therefore, he proposed a neural network color correction algorithm based on thought evolution calculation (MEC) -backpropagation (BP) -adaptive algorithm (Adaboost) for color image acquisition equipment. In the training process, MEC-BP-Adaboost was used to establish a color mapping model, using color target samples captured under color image acquisition equipment as input data and standard color data as output data. The color correction algorithm based on the MEC-BP-Adaboost neural network can not only improve the correction accuracy but also solve the problem that the color correction model obtained by the neural network method is not unique and there are differences between the color correction models [5]. The subject of Vukan Vujović’s research is the lack of research on the aesthetic dimensions of the overall quality, and these dimensions are also created through the “image” of the service personnel. His main purpose is to find a suitable measurement and evaluation method to prove the existence of the mentioned aesthetic dimensions in the overall quality, and to be able to analyze the relationship between dependent variables (with expectations and opinions) and independent variables (research Tourism facilities and cities, the age structure of respondents). For this purpose, five specific assessment determinants were assigned: appearance, charm, cleanliness, business attire and a team connection. The methods used in his research include research on primary and secondary sources, survey techniques, calibration techniques, analysis and synthesis methods, descriptive statistical analysis and analysis of variance (ANOVA) [6]. The fuzzy system uses the IF-THEN rule to describe the local characteristics of the modeled object. Faced with a complex system, it is often difficult to obtain a simple, global and effective fuzzy division to reflect the characteristics of the modeled object. Using a large number of “small” rules (that is, the applicable area of each rule is small is always not difficult to achieve higher accuracy, but the efficiency of the fuzzy system will be greatly reduced, and there is a dilemma between modeling accuracy and the effectiveness of learning operations. One characteristic of the system is its strong interpretability. However, the improvement of modeling accuracy is often at the expense of interpretability. There is also a dilemma between modeling accuracy and the interpretability of fuzzy systems. There are still many problems to be solved in practice [7].
Process of BP network
The Error Back Propagation (Error Back Propagation) network is generally referred to as the BP (Back Propagation) network. By combining the LMS (LeastMeanSquare) learning algorithm to reduce the mean square error between the actual output and the expected output of the network system [8].
BP network is a commonly used error processing method. When processing data in the network, it can quickly search and analyze the required results. It is widely used in function solving and information classification. The input and output vectors can be classified and connected to adapt to complex transmission and storage processing [9].
The BP network structure can realize the verification operation of the learning process. By comparing the two processes of forwarding propagation and backward propagation of the signal, and analyzing the specific nodes of the error, the process of information propagation is corrected. First, the signal is propagated in the forward direction, that is, the sample enters the network system from the input layer, and is processed by each hidden layer in the middle, and finally reaches the output layer to output the signal. There is nothing special about the previous process, but when the actual output of the output layer and the expected output have a large error, the BP network will perform the error backpropagation operation [10].
The backpropagation of the error signal is that the system returns the output error to the input layer through each hidden layer in a predetermined condition and way. In this process, the system allocates the error to all the neuron nodes passing by and obtains the error generated by the transmission signal of each neuron node through comparison. Determine the size of the error and calculate the proportional value, adjust the connection weight of the neuron node according to the calculation result, the larger the proportion, the smaller the weight of the signal processing [11].
The forward transmission of the signal and the backward propagation of the resulting error signal are alternately performed, and at the same time, the connection weights of the corresponding nodes have been adjusted accordingly. This is the concentrated embodiment of the algorithm’s self-learning ability and self-adaption, and it is also the learning and training process of the network [12]. The BP network model is shown in Fig. 1.
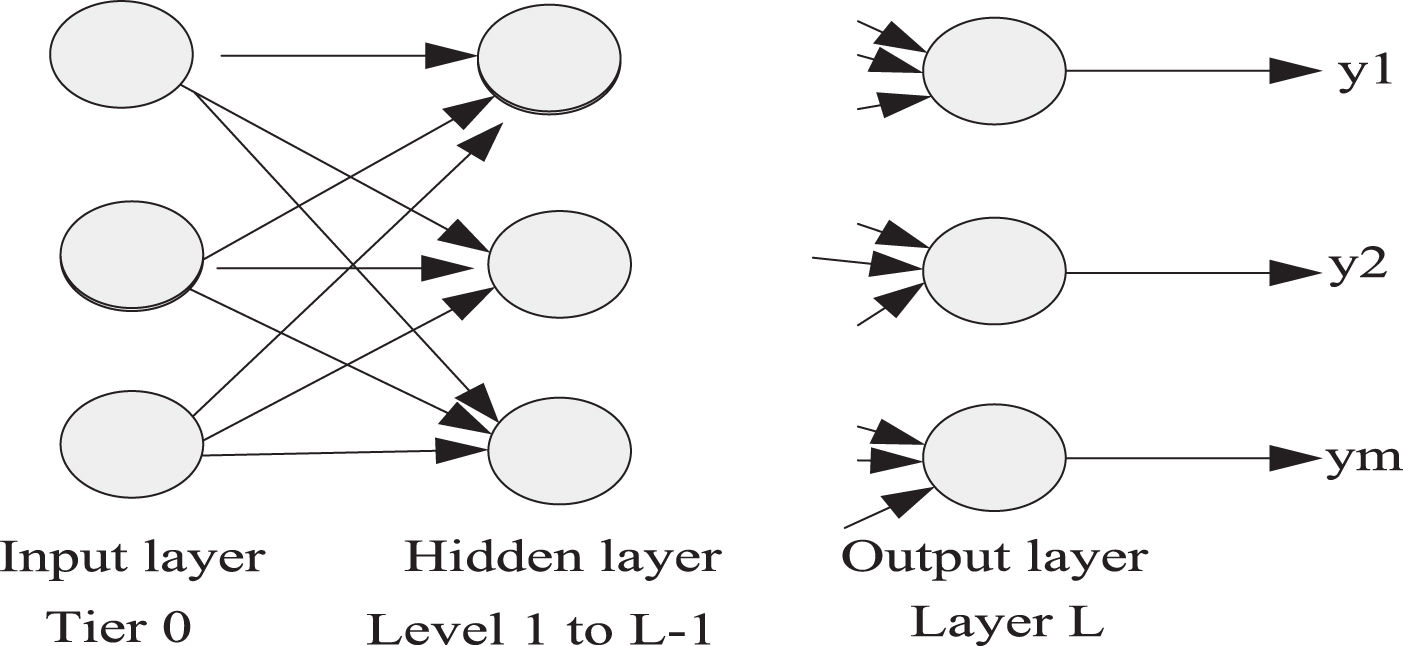
BP network model.
The BP network belongs to a learning model with a mentor, and usually uses the Sigmoid function (also called the S-shaped function) as the excitation function, and its expression is:
In the formula, the parameter c is set by the user to change with the application environment. When c is large, the function curve will quickly saturate.
When c = 1, Se (x) has the form
Through this derivation, the operation can greatly reduce the amount of calculation in the iterative process of the algorithm.
When applying the sigmoid excitation function, the BP algorithm has strong operability. The following uses this excitation function as an example to illustrate the specific operation steps of the BP network algorithm: Perform the weight value of each network node in the initial stage, the weight value cannot be negative, set the learning rate n and the inertia coefficient a [14]. Provide training samples: input vector k = 1, 2... P; Expected output dh, k = 1, 2... P; perform the following (3) to (5) Iteration. Calculate the actual output of the network and the state of the hidden layer unit:
Calculation error
Calculate the correction weight and threshold
After k has gone through a cycle, determine whether the index meets the set accuracy requirements.
End
The process of the BP neural network is shown in Fig. 2.

BP algorithm under sigmoid excitation function.
After a lot of long-term applications at home and abroad, a relatively fixed BP neural network design method has been formed, and its improvement mainly focuses on details. The design phase of the classic BP neural network is mainly divided into five steps: the number of input/output nodes of the network, the setting of hidden layers, the number of hidden layers, the transfer function, and the learning rules of the network (or training) Rules), etc. [15].
(1) Design method of input and output layer
The input layer and the output layer are the most complicated steps for the application of BP neural network in practical problems. It needs to analyze the actual requirements and abstract them into mathematical logic problems. Therefore, the actual problems and data are the main objects involved, and it is necessary to refer to specific problems to determine their specific representation.
(2) Number of hidden layers
According to the theory in network topology, it can be seen that the BP neural network with hidden layers can achieve an infinite approximation of continuous functions, that is, to achieve analog replacement of the function. This is the theoretical basis of BP neural network to solve the function problem. Only a three-layer BP neural network needs to be established to realize the substitution of functions, and an N-dimensional to M-dimensional mapping can also be achieved [16].
But how to choose a reasonable number of hidden layers and nodes of hidden layers is the key index to complete the system operation. We need to do more design based on theory: first look at its design requirements, minimize errors and quickly complete the calculation process. That is, on the basis that the network has a high training speed, no errors are generated as much as possible, and the integrity and accuracy of the input and output signals are guaranteed. To minimize the error, it is necessary to design as many hidden layers as possible, so that the generalization ability is high. But when it reaches a certain level, the amount of error reduction will no longer change, so it needs to be taken-a reasonable value [17].
Simply increasing the number of layers does not improve the accuracy of the calculation. Researchers often increase the number of neurons in the hidden layer to ensure the accuracy of the network output [18]. Therefore, the usual design step is to first use a hidden layer, try to increase the number of neurons in the hidden layer, if it has not achieved the effect, then add a layer to continue the experiment. The author combined with the later examples of this article selected the hidden layer as the single hidden layer.
(3) Selection of hidden layer nodes
For the analysis of the most widely used multi-layer feedforward network, its accuracy is ultimately determined by the number of hidden network nodes. This is the most critical factor in determining the quality of the algorithm, and it is also the most difficult part of the system design. The BP neural network should have an optimal number of hidden layer nodes [19], but because the algorithm has no clear theoretical guidance, the method of taking the maximum value after multiple experiments are generally used for confirmation.
After the initial setting of the number of nodes, if there is still a gap in the final accuracy, you can fine-tune through the construction method and the deletion method to obtain the appropriate value. Construction method: By gradually increasing the number of nodes, its amplitude is set according to the degree of error change, until the final output error no longer decreases signifi-cantly. Delete method, give the network a large number of hidden layer nodes in advance, and then gradually delete the number of hidden layer nodes, whose amplitude depends on the degree of error change.
Based on experience, when the performance of the computer system allows, the deletion method is usually preferred so that the results can be obtained faster.
(4) Selection of starting weight
Since the system processing is a nonlinear function problem, the choice of initial weights often affects the time of the system algorithm [15]. Afterward, due to the self-learning and adaptability of the network system itself, these settings can be modified. Generally, the initial weight is taken as a random number between (–1, 1). As long as the algebraic sum is close to 0 [20].
(5) Selection of learning rate
The choice of learning rate is the key to reflect the system’s adaptive and autonomous learning capabilities. It is the most concentrated manifestation of the system’s operating efficiency, which determines the range of weight changes each time the system is executed. If the setting is too large, it will cause the system to change drastically and cause system chaos. If the learning rate is small, it will increase the training time of the algorithm, which reduces the convergence efficiency and the performance of the algorithm. Through the research of past scholars, it has been found that an excessively large learning rate will greatly limit and affect the stability of the system. Therefore, a smaller learning rate will be selected, generally ranging from 0.0001 to 0.8.
There is no particularly rigorous theoretical research on its setting, and it mainly relies on experience summary to determine a more appropriate value through experiments. Many algorithm improvers learn from the improved methods of genetic algorithms, adopt an adaptive learning rate with a certain rate of change, and automatically set different learning rates at different stages, and have achieved good results.
Experiments
The main content of this article is to use the optimized fuzzy neural network model PCA-GA-ANFIS model in the evaluation of employee quality and then conduct simulation experiments through MATLAB software, and then verify the feasibility of the model for solving the overall quality problems of employees based on the experimental results. Compared with the unoptimized fuzzy neural network model (ANFIS model), it further verifies that the constructed model has higher prediction accuracy and better performance, and is more suitable for solving the problem of employee quality evaluation prediction.
Selection of sample data
The data set in this article is from the usual performance data of a company’s employees. Employee performance is mainly reflected in appearance, etiquette, instrumentation, attendance, ability, mental quality, ideological quality, cultural quality, and professional quality. During the company’s work, the main quality evaluation of employees is concentrated on commuting. It can be said that the performance of commuting to and from work is the key time for evaluating the quality of employees. The performance of company employees in the company is very important. Therefore, it is very necessary to study the impact of normal staff quality training on the whole. This article selects the main quality performance of the employees and removes some factors that have little effect on the overall quality evaluation. At the same time, the comprehensive quality before and after work is defined as the overall performance of quality evaluation.
Cleaning of sample data
The main purpose of data cleaning is to delete errors, outlier data, supplement missing data and smooth and noisy data. The data exported from the score management system may be caused by human errors, such as data errors and missing data. There may be some errors in the employee’s quality evaluation score data. For example, the employee’s usual quality score is missing due to absence, or an error occurs during manual entry. These data need to be processed accordingly: take the average value to fill in the missing information, and delete the errors in the sample. Information, leaving the correct information in the sample.
Data reduction refers to keeping the data without affecting the results and minimizing the amount of data. In data analysis, the data to be analyzed has many attributes, some of which do not affect the experimental results. Delete unimportant or irrelevant features from the original features to improve computing efficiency. The specification of data is very important in the data processing. The experiment in this chapter selects the performance of new and old employees to and from work, ignoring some other auxiliary factors such as absenteeism and early leave, because the distribution of these influencing factors is concentrated around 90 points, and the assessment performance of these influencing factors is very small to the employees It can be ignored. The sample of employee quality assessment is shown in Tables 1 and 2.
Sample data of employee quality evaluation
Sample data of employee quality evaluation
Sample data of employee quality evaluation
Processing and analysis of sample data
In this paper, although the data samples of employee quality evaluation have been preprocessed, there is still a problem of redundancy between the predicted sample data. At the same time, for the model system, due to the input variables, too high dimensions can easily lead to the problem of low model operating efficiency; through the principal component factor analysis method, the dimensionality reduction process is performed on the employee quality evaluation samples, making the original high-dimensional data set into -A new low-dimensional data set, thereby reducing the dimensions of the model input variables, and thereby improving the efficiency of the model.
The output of the system after linear interpolation and filling in spaces is shown in Fig. 3. We take the first two sets of data for research, and then use interpolation to fill in the spaces. Of course, various interpolation methods can be tried, and linear interpolation is selected here. Because linear interpolation only needs to use two effective points (points with function values) in the direction of each dimension coordinate axis, you can find the nearest effective point in each positive and negative direction of each dimension axis, or in one direction find the two most recent valid points. The interpolation process is local. The sample data processing results are shown in Fig. 3.

Sample data processing diagram.
In this paper, the simulation experiment of the PCA-GA-ANFIS fuzzy neural network prediction model is realized through the programming of the toolbox function in MATLAB software. After principal component analysis, 1250 sets of 7-dimensional employee performance data samples were obtained. 900 sets of data as training samples accounted for about 70% of the total sample, 15 sets as verification samples, and 345 sets of data as test samples accounted for about 30% of the total sample. First, use 900 training samples for the learning process of the PCA-GA-ANFIS prediction model. Then, use 15 sets of verification samples to verify the model, so that the structural attributes and parameter values of the model are determined. Finally, use training after the prediction model, 345 groups of test samples were used to predict employee performance. The results of the sample data are shown in Fig. 4.
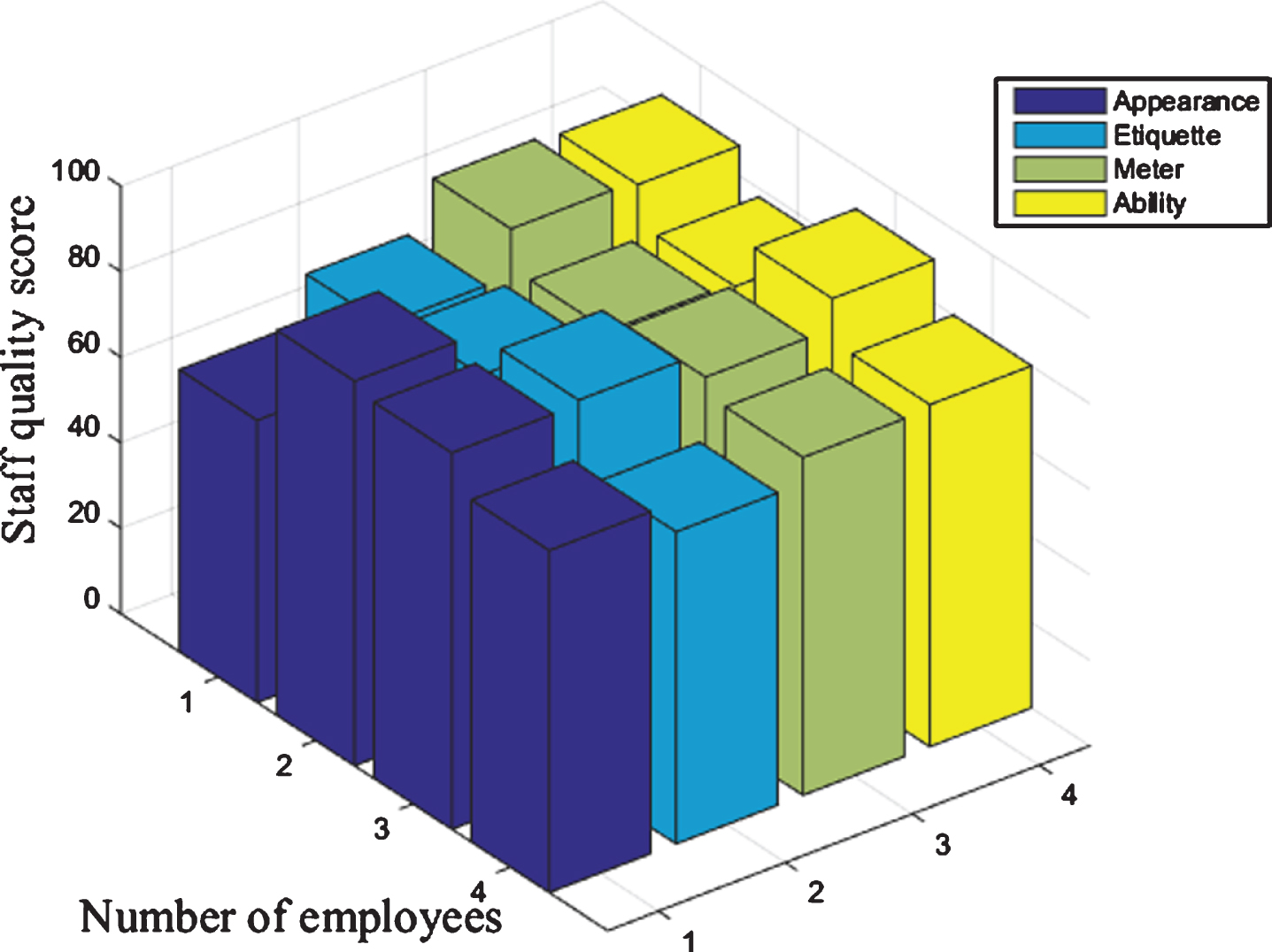
Histogram of sample data.
Figure 5 is the sample data fitting results. After the PCA-GA-ANFIS prediction model undergoes 20 iterations of training, the average relative error of the model training output tends to be stable. After the 40th iteration of the training, the average relative error of the model training can reach 0.0128. After the prediction model training is completed, 15 sets of verification samples are used to verify the model. The verification results show that the average relative error of the model converges, so the model is not over-fitted.
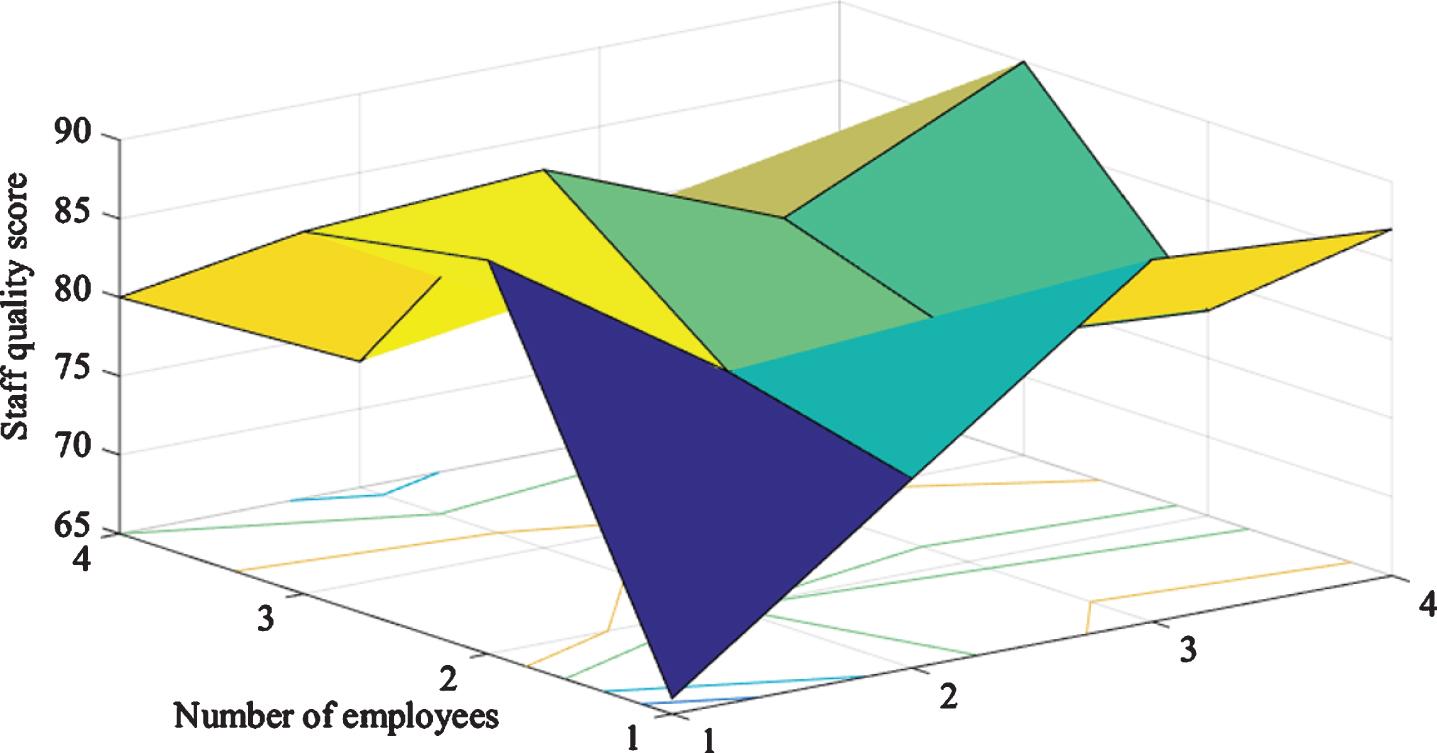
Sample data fitting graph.
By comparison, the simulation model after fuzzy quantization can achieve good convergence requirements. The reason why such a large difference occurs is due to the inherent defects of the BP neural network. The BP learning algorithm converges slowly and often requires thousands of iterations., Plus a large amount of irregular input data and inappropriate selection of the initial value of the network weight will cause the divergence of the neural network, so the input data of the BP neural network is fuzzified to ensure that the neural network input data is too large and irregular Divergence effect. At the same time, the combination of a fuzzy network and BP neural network has stronger stability and redundancy than a single neural network, and it is a better fault diagnosis mode.
The individual employee data is shown in Fig. 6. To speed up the convergence of the learning algorithm and avoid the neural network falling into the local optimal solution, we often introduce momentum terms in addition to the fuzzy quantization of the input data. The introduction of momentum terms can make the learning rate significantly improved, but the larger fixed momentum factor can improve the convergence speed of the neural network, but it may cause random oscillations, which makes it difficult for training to converge to a point, which affects the accuracy of convergence, and has no effect on falling into a local minimum. Therefore, when increasing the training speed and improving the performance of the neural network, an additional momentum factor algorithm is generally used. The additional momentum factor can adaptively change dynamically during the iteration process, and the changing process affects the speed of convergence. In this way, the dynamic change of the momentum factor is combined with the learning efficiency, so that the convergence speed of the neural network learning and training is unchanged.

Individual quality scores of individual employees.
Among them, a detailed introduction is made through the experimental simulation tool MATLAB, including the features and advantages of the software. After that, the detailed simulation design and simulation test are carried out on the experimental tool MATLAB with the aid of employee quality evaluation data, and the conclusion is drawn from the simulation results that the combination of BP neural network and fuzzy logic is a practical and feasible diagnostic method in the application of intelligent fault diagnosis. The diagnosis result is accurate and effective, and it is worthy of reference and promotion in intelligent fault diagnosis.
A fuzzy neural network is a very active branch in the field of intelligent control theory research. The future research direction of fuzzy neural network technology will focus on the following aspects: (1) expand the application range of fuzzy neural network and find fuzzy nerves of general fuzzy sets learning algorithm of the network. (2) Develop related hardware products of fuzzy neural networks. It is foreseeable that with the development of theory and the deepening of engineering applications, the fuzzy neural network technology will continue to be enriched and perfected, to obtain a wider range of applications.
Individual-based employee quality evaluation methods and tools need to be further verified and improved against different corporate backgrounds. The current depth and application of corporate performance management research in China vary greatly, and various quality management systems are far from perfect. Inheritance and reference have not received enough attention. At the same time, it is necessary to conduct surveys, collect and organize data through associations and scientific research institutes at all levels to form a performance management database, expert knowledge base, etc. In particular, the establishment of individual talents and superior databases should become the focus. At the same time, we must combine new ideas and methods to form an employee quality management database. The evaluation expert system in the database should also be regularly evaluated and selected, with a view to continuous improvement.
In practical applications, it is not difficult to obtain some rules, but the obtained rules often cannot cover the entire input state space very well. According to the existing rules, the interpolation method is used to generate new fuzzy sets and rules in the unknown part of the input state space, and a simple fuzzy system is designed to implement the interpolation algorithm to meet the requirements of generating new rules online. This method can enhance the continuity and stability of the fuzzy system.
Footnotes
Acknowledgments
This work was supported by Project Fund from Jilin Planning Office of Philosophy and Social Science (Project Title: Research on construction of industrial workers under the strategy of one master and six pairs in Jilin Provincial. Contract NO. 2020B088.