
Abstract
Text Sentiment Analysis is a system where text feeling polarity is positive or negative or neutral from a series of texts or documents or public opinions on a particular product or general subject. Using machine learning and natural language processing techniques, the current work aims to gain insight into sentiment mining on tweets. Text classification is accomplished using Machine Learning Algorithm-based fusion technique. This research suggested a system for grading feelings based on a lexicon. Bag-of-words (BOW) or lexicon-based methodology is currently the main standard way of modeling text for machine learning in sentiment analysis approaches. Marketers can use sentiment analysis to analyze their business and services, public opinion, or to evaluate customer satisfaction. Organizations can even use this analysis to gather significant feedback on issues related to newly released products. The main objective of this is to resolve the data overload problem.
Introduction
Currently, the Internet is not only a vital information supply, but also a platform for sharing views and experiences. We can simply collect product or service reviews in the network of [1]. Because of the sight of vast quantities of data on the internet, various businesses have begun to take an interest in mining this knowledge would be very useful to them. This creates a completely different and large area of study called Sentiment Analysis. This field has been given a variety of names such as opinion mining, opinion mining, etc. But there is a small difference in meaning between these varied terms in [5].
Sentiment analysis (SA) is a way to identify and differentiate user feelings from a piece of text into different feelings for example, positive, negative, or neutral, or emotions such as happy, sad, annoyed, or disgusted to evaluate the user’s actions towards a particular subject or entity. Different applications of opinion mining are like product reviews, film reviews, industry, politics, recommendation system for twitter info, etc. A business can increase changes accordingly depending on the feeling about a product or about different aspects of a product. Likewise, government policy changes can be generated on the basis of an organization’s opinion.
With more than 319 million active monthly users and more than 500 million tweets a day, one of Twitter’s social media has now become a gold mine for organizations and people with a keen interest in maintaining and enhancing their reach and credibility. Opinion polling enables these institutions to perform real-time surveys on various platforms of social media. Text Sentiment Analysis is an automated method for determining whether a text step contains objective or narrow-minded content and for testing the polarity of the text’s feeling.
The aim of Twitter sentiment analysis in [2] is to mechanically verify whether or not the sentiment polarity of a tweet is negative or positive. Sentiment analysis is useful in the application environment for business intelligence and recommendation systems, as it is a very convenient medium of interaction between the two ends of the supply. Many strategies and techniques have been used in sentiment analysis, such as machine learning, polarity lexicons, natural language processing. Tweets typically consist of incomplete, screaming and poorly structured phrases, irregular phrases, unformed words, and non-dictionary expressions. A sequence of pre-processing (e.g., removal of stop words, deletion of URLs, replacement of negations) is applied before feature selection to reduce the number of tweet noise. In developed approaches, preprocesses are carried out extensively, particularly in approaches based on machine learning. This paper focuses on exploring different forms of pre-processing to enhance the quality of Twitter analysis of sentiment. It used fused machine learning classifiers to define tweet feeling polarity on Twitter datasets.
NLP is used to reduce input from customers. Royal Bank of Scotland uses text analytics, an NLP methodology, in many ways to extract important patterns from customer feedback. To find the root cause of customer dissatisfaction and make improvements, the organization analyzes data from emails, surveys, and call center encounters. Watch the video to learn more about consumer relationships transformation analytics. Large volumes of textual information are processed using natural language processing. This allows computers to communicate in their own language with people and to scale up certain tasks related to language.
Today’s robots are able to accurately, unbiasedly, without fatigue, interpret more language-based data than humans. Given the enormous amount of unstructured data generated on a daily basis, from medical records to social media, automation will be essential to an efficient analysis of text and voice data.
Existing work
Multistrategy Sentiment Analysis Of Consumer Reviews [1] suggested a multi-strategy consumer reviews model focused on semanthropy. The Chinese-language characters are the most fluid in their context. This issue can not be solved by traditional machine learning algorithm. So to solve that this study proposes the hybrid[SVM+NB] sentiment analysis. First, this approach measures Chinese phrase sentiment lexicon, sentiment polarities, and strengths to examine semantine fuzziness. SVM and NB combination called multi-strategy process. They both work effectively and give the Chinese phrase a good feasibility. The naïve Bayesian used adversative conjunctions to analyze the sentiment of the word.
Twitter Sentiment Analysis [2] described the neural network model of deep convolution. This model used word embedding method to analyze feelings. This approach used latent linguistic contextual associations and statistical co-occurrence features in word-to-word twitter commands. This approach blends word embedding process with attributes of n-grams and polarity rating attributes of word sentiment. This model represents contextual information with repeated structure and uses a convolution neural network to create text description. For sentimental coverage, this method used pre-trained word vectors over five data sets that provide better performance.
Text Pre-Processing Methods On Twitter Sentiment Analysis [3] identified Twitter Sentiment Analysis Comparison Research on Text Preprocessing Methods. This uses four separate classifiers over five data sets, namely RF, NB, LR, SVM, namely STS-Test, SemEval2014, STS-Gold, SS-Twitter, SE-Twitter. This method classifies the dataset by using the classification of two types, namely binary task and classification task of three forms. Classification of binaries carried out by all five datasets. Four databases, such as SVM, NB, LG, RF, perform a 3 way mission. This method used different pre-processing techniques to classify feelings. To improve classification accuracy, preprocessing techniques replace denials, remove url links, reverse words containing repeated letters, remove numbers, remove stop words, and expand acronyms. The base line or C-method model applies to all six pre-processing techniques. These methods are very effective in calculating the polarity of the analysis of sentiments.
By using a pattern-based approach [4] suggested multi-class sentimental analysis. This novel-based approach relies on patterns of writing and on special unigrams for classifying text into seven different classes. SENTA implemented this form. It is a tool that works very user-friendly and allows a wide range of features to be extracted from text that includes both content and type.
In addition, it added several traditional attributes used to boost classification accuracy for writing pattern-based applications. This categorized the text into 7 different classes of feelings by extracting an optimal set of attributes using SENTA, namely fun, joy, sorrow, rage, neutrality, love and hate. The accuracy of the data set was obtained by 60.2 percent in multi-class sentiment analysis and it gives better performance for sentiment analysis.
The rating method [6] was described based on the Social Sentiment From Textual Reviews used to improve predictive accuracy in the recommender system. This approach finds clues from reviews and effectively predicts the ratings of social users. First, the function of the brand is derived from the user review set and this process is used to classify the feelings of social users. It also represents three sentimental factors called user feeling similarity, interpersonal feeling effect, and object reputation similarity.
There is substantial online communication knowledge at the moment. People tend to be expressing their views on the internet. Taking this situation into account [11] suggested a hybrid system focused on efficient mining of emotional distress patterns in the public blog. A blog is used to identify the people needed for timely public health support and interaction. It also describes a handmade template that requires human judgment and makes it easier to change the machine learning forecast for blog content.
Different types of writing, such as casual and formal, are used to express a written meaning. Generally speaking, through language and words, a little bit of a text can express a lot of emotional states, emotions or thoughts. Various techniques and strategies are used to collect the emotions of the text in the meadow of Opinion Mining and Sentiment Analysis.
Author [12] dissected the Formal and Informal material parts in widespread dialects in the degree of Opinion Mining and Emotion Analysis. With the final objective of the inquiry, the author considered eight general dialects (English, Arabic, Chinese, Turkish, Malaysian, Spanish, Persian, Korean) formal and casual content from any approximation of documents, ballads, propositions and records, and so on, as well as four parameters for component evaluation (IG, TF-IDF, n-gram, MI, and MMI). The results showed that in the field of mining feeling, Arabian Language has the highest performance and accuracy. Parameters are found to be higher than all others in the test results between the IG and TF-IDF.
Sentiment of social users used to indicate preferences of users. We can build a new relationship that is called interpersonal feeling influence among users and friends. The results of the rating prediction indicate that three sentimental factors contribute greatly to the analysis. This approach provides better output for the database of the real world. In the work [13] a cross-breed model is proposed that consolidates the predicted spatial and brief highlights. By estimating the pollution data using sensors and information indexes, this model uses the constant air quality data in a region. The workload [14] in aims to anticipate the emotions of the mental patient, using their Non-Verbal communication, and change the process of Emotional Mining (EM).
Proposed methodology
Text Sentiment Analysis is a system where text feeling polarity is positive or negative or neutral from a set of texts or documents or public opinions on a particular product or general subject. Using machine learning and natural language processing methods, the current work aims to gain insight into sentiment mining on tweets. Use the Naïve Bayesian Machine Learning Algorithm to classify text. This paper provides a framework for assessing feelings based on a lexicon. At present, bag-of-words (BOW) or lexicon-based technique is the primary standard way of modeling text in sentiment analysis approaches to machine learning. The proposed architecture is shown in Fig. 3.1.
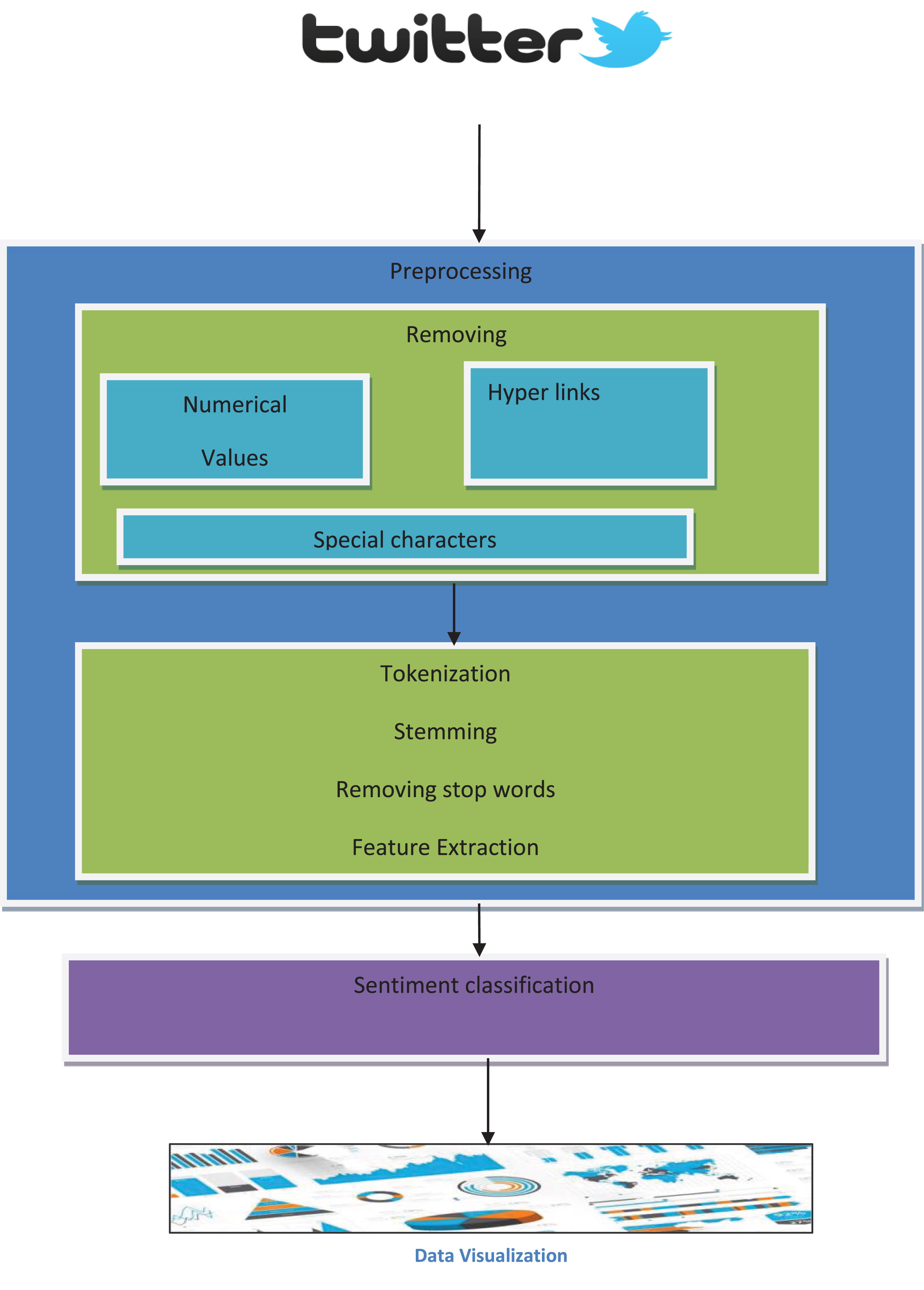
Proposed Architecture.
Marketers can use sentiment analysis to analyze the public opinion of their company and products or to investigate the satisfaction of customers. Organizations can even use this research to gather substantial input on recently released goods issues. The main objective of this is to overcome the information overload problem. This uses the learning algorithm for the Naïve Bayesian train and checks the data set. This process starts with the collection of the data set.
The architecture starts with the compilation from twitter of demonetization data set to examine the feeling. After the compilation of data set, preprocessing steps such as removing special characters, hyperlinks, numerical values accompanied by tokenization, removing stop terms, stemming and lemmatization are performed over the data set. Effectively perform classification of feelings.
This architecture outlines all pre-processing steps that are specifically involved in classifying sentiments. This proposed system provides better performance in the classification of sentiments by extracting the important features in the dataset. Using this simple architecture, sentiment analysis can be performed effectively. NB is then used to classify the data set by the most common machine learning algorithm. Eventually, the data set findings are visualized as a pie chart. The main stages are
For the purpose of analysis, data collection from internet or real-time data is taken. For research, the twitter database is used here. This database has 6000 records and 13 demonetization features including Address, FavoriteCount, ReplyToSN, Truncated, ReplyToSID, ID, ReplyToUID, StatusSource, ScreenName, RetweetCount, IsRetweet, Retweeted.
In the precise classification prediction, data preprocessing plays an important role. After data collection, they need to be pre-processed for review. This paper analyzed the findings on the identification of feelings in different pre-processing processes, along with the elimination of URLs, substitution negation, reversal of continuous letters, removal of stop terms, removal of numbers and of acronyms. Pre-processing is done with the help of NLP. Natural Language Processing is a technique that deals with human languages and is part of Science and AI data. According to industry, just 21 percent of structured data is expected in the 21st century. As we send in Whatsapp, Twitter, etc., data were created as tweets. By reality, they are mostly unstructured. We need to learn the techniques of text mining in order to structure. Text mining is a method of extracting meaningful information from natural language text or structuring data or patterning or creating interpreted output. NLTK(Natural Language Tool Kit) must be installed for preprocessing. The document is graded using it.
The text preprocessing technique contains the following preliminary methods
To increase the efficiency of system we need to remove special characters like ([,],.,/, ?,,,+,=,(,), etc ...) and hyper links
Example:“ <a href="http://twitter.com/download/android” rel="nofollow">Twitter for Android< /a> ”This links will not affect the data analyze result so better to remove this links for further process.
Remove numerical values (0-9). These values are not taken for analysis.
Tokenisation is the process by which paragraph or sentence is divided into words or phrases. For an additional system such as parsing and text mining, the tokens become the data. In computer science, tokenization is used wherever it plays a major role in the process of lexical analysis. The tokenize python function divides tweets or comments into words or tokens.
Stemming is the method ofcollapsing derivedwords into their root form called as mapping. A group of words can be stemmed to one single word.
Groups different inflected forms of a word called lemma (plural lemmas or lemmata). Somehow close to stemming, since it maps multiple words into one common root..
For example, affects, affected, affecting are all kinds of the word affect, thus affect is that the lemma of these words. The result of lemmatization gives an actual word of the language, it is used wherever it is need to desire valid words.
Stop Words are words which do not add any value to the study outcome. Can artificial language use its own stop words list. They are specifically words that people can use in language such as’ to, the, be, are, that’ etc. Stop words elimination improves the process by eliminating terms that are useless for the classification portion. As a typical example, a piece does not convey an emotion, but within the sentences it is a horrible gift.
Using a lexicon to map the information to often use Internet slang words, abbreviated content is condensed. For example, ’ gud ’ and ’ awsm ’ are mapped to ’ nice ’ and ’ awesome, ’.
Extraction feature plays a major role in the analysis of text. The most frequently occurring feature would increase classification performance. Function Extraction operates efficiently with help vector machine to identify feelings.
Fusion needs specific classifiers to be integrated and the search must be conducted within an exponential interval of increase. The complexity of time is high. It is therefore inappropriate to use it to extract large-scale text features.
Weighting method is a special class of fusion. It gives each attribute a weight to train inside (0, 1) during changes. The classifications of Bayesian are statistical classifiers. They can predict the likelihood of class membership, such as the likelihood that a given sample may or may not belong to a particular class. When applied to large datasets, the Bayesian classification demonstrated high accuracy and speed. Naive Bayesian classification assumes that it is independent of the value of other attributes that the impact of an attribute value on the category. It performs well in multi-class prediction.
Naive Thomas Bayes model makes terribly giant information sets straightforward and is significantly helpful. In addition to simplicity, Naive Thomas Bayes is thought to outstrip even extremely refined classification strategies. Bayes theorem provides a way to measure the posterior likelihood for P(c), P(c), P(y), and P(y). Naive Thomas Bayes ’ categorizer assumes that the influence of the value of a predictor (y) on a given class (c) is independent of the values of various predictors.
Classification issues may be the most common type of machine learning problem and as such there are a number of criteria that can be used to test predictions for these issues. In this section we will examine how the following metrics can be used.
Naïve Bayes Classifier is a probabilistic classifier based on the application of the theorem of Bayes with a clear presumption of autonomy that the existence of one function in a class does not depend on the presence or absence of another. Naïve Bayes is a simple model that works well in categorizing text. A multi-faceted Naïve Bayes template can be used for tweets.
Class c* is allocated to tweet and in equation 3.2 is represented. F is a function in formula 3.3 and d is the number of features found in tweet. There are a total of characteristics of m. Parameters P(c) and P (f) of the unit of area obtained by most estimates of probability. P(c) is the probability beforehand.
Support Vector Machine (SVM) is another algorithm used to solve the text classification problem. Help Vector Machine is a supervised machine learning algorithm that can be used for classification and regression problems. The data object is plotted in this algorithm as a point in n-dimensional space (where n is number of characteristics) with the value of each characteristic being a type of particle.
The advantage of this fused classifier is that by looking at the collection of knowledge, it is easy and simple to predict the classification. In multi-class forecasting, it also works well. A Naive Thomas Bayes classifier performs higher than different models when assuming autonomy holds, such as operational regression, and you want less coaching data. In the case of categorical input variables, it works well compared to numericalvariable(s). For the statistical parameter, statistical distribution (bell curve, a simple assumption) is assumed. The main disadvantage of the classifier is that if the categorical variable adds a class (look at the information set) that has not been included in the training data set, then the model assigns 0 (zero) probability and can not predict. This is often called’ zero amplitude.’ The smoothing method can be used to solve it. One of the simplest smoothing methods is Laplace approximation.
Real Time Prediction: Naive Thomas Bayes is a degree associate ready to identify, and it is fast optimistic. It can therefore be used to create predictions in real time.
Multi-category Prediction: This formula is also known for multi-category prediction function. The probability of multiple target classes can be predicted here.
Text categorization / Spam Filtering / Sentiment Analysis: Naive Thomas Bayes classifiers widely used in text classification (due to elevated multi-class problems and the law of freedom) have higher success rates than other algorithms.
Recommendation System: Naive Bayes Classifier and Collaborative Filtering together create a Recommendation System using machine learning and data mining techniques to process unknown knowledge and determine whether a user wants a specific resource or not.
Classification accuracy is that the variety of correct predictions generated as a magnitude relationship of all predictions made. This is the most common method for evaluating classification problems, it is the most widely used together. It is really only appropriate if there is an equal number of observations in each category (which is rarely the case) and all predictions and errors of prediction are equally important, which is often not the case.
The demonetization data set is used to test feelings which comes under twitter Database. Demonetization is an event that has brought substantial economic and social change to India. The program proposed is based on demonetization tweets. Demonetization tweets should be expressed in a simple word: positive or negative by sending the dataset to various algorithms to decide which algorithm best suits Sentiment Analysis based on the data set.
Demonetization is the declaration that the fragile constitutional status of a money unit is stripped. It happens at any change in national money at any point. The current form or forms of money are taken from scattering and withdrawn, often to be replaced by new notes or coins. The Indian government announced on 8 November 2016 that all Mahatma Gandhi Series 500 and 1000 banknotes will be demonetized.
Sudden demonetization for India is not a new phenomenon. In fact, after 1946 and 1978, this is the third demonetization. Nevertheless, the circulation of the higher denomination banknotes during that time was very limited, and most of the higher denomination banknotes were kept only with banks. Indian banknotes worth 16,664 billion b are registered in 2016 by the Reserve Bank of India (RBI).
The government has therefore stressed the fact that Rs five hundred and Rs thousand notes will be demonetized to curb black money holdings. However, as they could exchange their old banknotes with the banks from November 10, 2016, relief was given to people. These old banknotes, however, could also be deposited into their bank accounts. In addition, the government allowed these old banknotes to be used for necessary services such as purchasing gasoline, diesel, air tickets and rail tickets. Citizens have had a mixed response to this initiative since the announcement was made. Nonetheless, there was mayhem on November 10, 2016, when huge crowds flooded every bank in the country. The government began to face major criticism because the banks had insufficient new banknotes to meet people’s everyday needs. Nevertheless, the government maintained that these are only a few initial hiccups that would eventually kill the black money demon that had destroyed the economy in the last three to four decades.
The time complexity of the proposed work is better compared to the existing work because since the proposed work are extracting the most important features and it focus on most relevant dataset. The number of data used in the algorithm has been reduced. Table 4.1 shows the experimental result comparison between different classifiers.
Comparison of various Classifier
Comparison of various Classifier
Using python code to load that after selecting the dataset from your device to predict the outcome of feeling. Twitter data set is selected for review. This dataset contains public opinion with 6000 records and 13 features on demonetization, including Email, FavoriteCount, ReplyToSN, Truncated, ReplyToSID, ID, ReplyToUID, StatusSource, ScreenName, RetweetCount, IsRetweet, Retweeted. The F-score and accuracy rate analysis are shown in Figs. 4.1 and 4.2 respectively.

F-Score.

Accuracy.
Data visualization is the data and information graphical representation. Data visualization tools provide an interactive way of viewing and analyzing data trends, outliers, and patterns using visual elements such as charts, graphs, and maps. This shows how much positive, negative and neutral control over the demonetization dataset in this analysis of sentiments.
False positive rates and the identification of false negative rates play an important role in estimating the accuracy of the classifier. False positive rate deals with giving false document positive results, and False Negative rate deals with giving true document negative results. Accuracy deals correctly with predicting tweet feeling.
This form of representation is helpful in making decisions on any subject or item. The percentage of positive control in green color, negative command in red color and neutral command in gold color in pie chart are shown here. The proposed work has been compared in terms of F-Score with the different approaches. Figure 4.3 shows that if the domain is completely independent, most important features can be extracted.
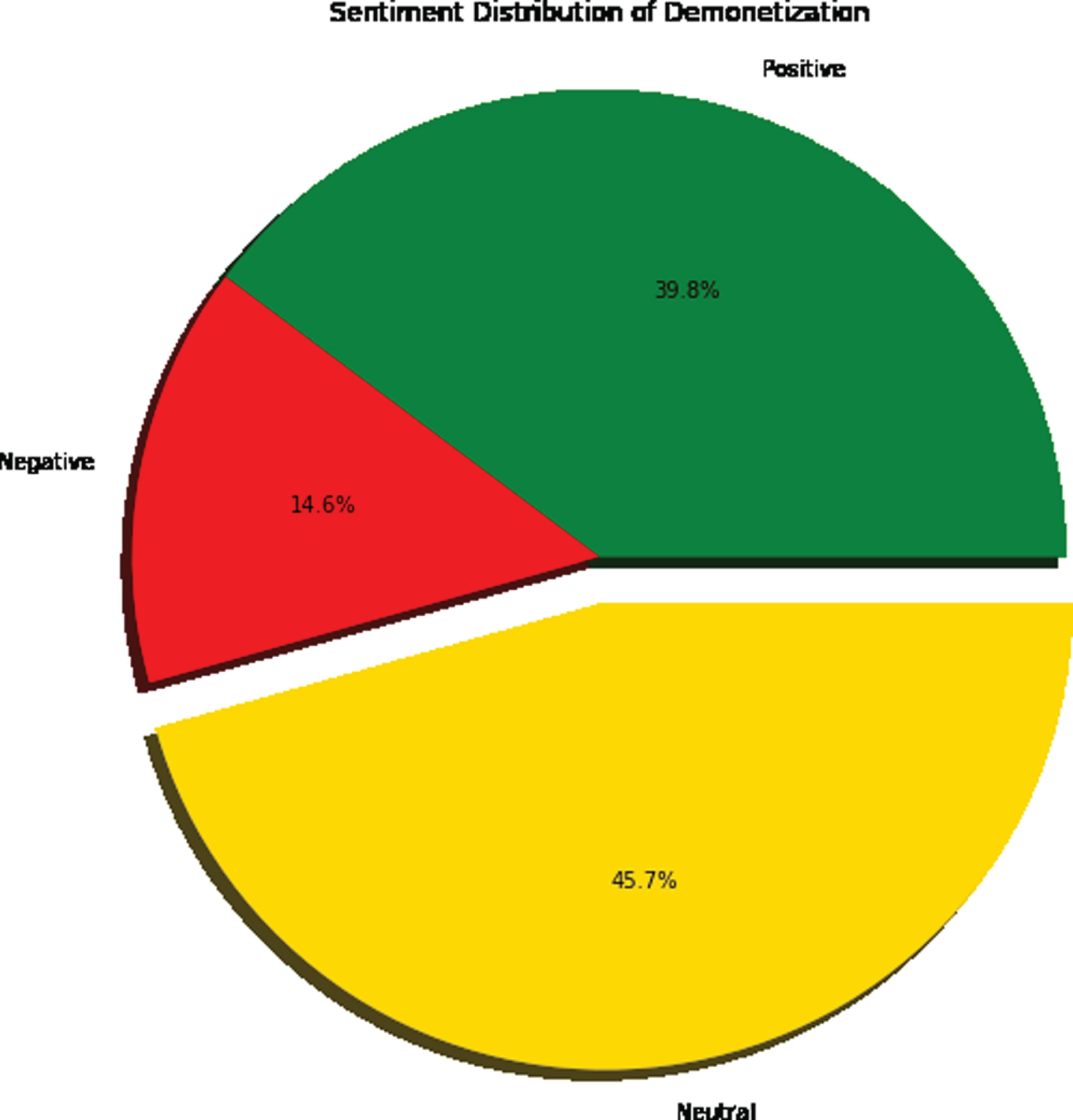
Pie Comparison Chart.
A lexicon-based model for the classification of feelings and the method of extracting features was proposed in this report. This proposed approach classifies tweets into comments that are positive, negative or neutral. This model has gone through the pre-processing stage, nostalgic score calculation and classification stage. Best of all, the classifier learning function is to adapt the SA application API to integrate with SRSs and online learning portals to enable real-time analysis of feelings. Additional Indian languages will be introduced in the future to improve the system’s multilingual capabilities. Try to find an active sentiment analyzer such as random forest, support vector machine, etc. for further study. Always seek to use the advantages of the two algorithms to implement a new algorithm so that it can be used effectively in data prediction.