
Abstract
The real-world data is multimodal and to classify them by machine learning algorithms, features of both modalities must be transformed into common latent space. The high dimensional common space transformation of features lose their locality information and susceptible to noise. This research article has dealt with this issue of a semantic autoencoder and presents a novel algorithm with distinct mapped features with locality preservation into a commonly hidden space. We call it discriminative regularized semantic autoencoder (DRSAE). It maintains the low dimensional features in the manifold to manage the inter and intra-modality of the data. The data has multi labels, and these are transformed into an aware feature space. Conditional Principal label space transformation (CPLST) is used for it. With the two-fold proposed algorithm, we achieve a significant improvement in text retrieval form image query and image retrieval from the text query.
Introduction
In modern days the multimodal community applications are increased. The multimedia data, like images and videos, are generated in large quantities on the web. The users get the content from heavily generated multimedia data to fulfil their requirements. The text features are exacted from the multimedia data while users are searching for them. The text description of an image or video shows the content of the data. The cross-modal retrieval process is used to retrieve multimodal data. It can be used for both text and image, to retrieve images and text, respectively. It uses the correlations of different modalities for retrieval data. For example, if a user is interested in sportsman, an image query can be used by the user and estimated related multimodal information with text details, videos, and images. The cross-modal retrieval provides enhanced multimodal results compare to the single- modal retrieval. The flexible search experience is also provided to users by cross-modal retrieval. Due to different modalities inconsistency in cross-modal retrieval, the image and text representation fails to match with each other directly. Various semantic learning techniques have been proposed for image-text retrieval in the past. Cross model retrieval has been a major challenge due to different modalities data available for classification ex. The image is input to search for text query or vice-versa. This problem is overcome by a classical mapping function that represents the data into a common space. The common space [1, and 4] representation of data provides the same dimensionality to the different modalities, and similarity is estimated via the simple metric. The similar representation of data for cross-media content is the fundamental research problem. The common space representation is used for single media data. The semantic information, like the class label and label space, are used by some supervised and semi-supervised cross-modal retrieval for mapping into the common representation (Table 1). A manifold regularization is used to learn the cross-media features from the vector-valued RKHS (Reproducing Kernel Hilbert Spaces) with kernel transformation. The retrieval accuracy is improved by the RKHS algorithm of SCVM [3].
Notations
Notations
For the heterogeneous multimedia data of high dimension, the nonlinear learning methods are used to extract semantic similarity. The canonical correlation analysis and multiple kernel learning are used to capture semantic information of high dimensional data. A hybrid approach is also used to extract the semantic information of big data by combining modal sharing transfer sub-network and layer sharing correlation networks. In layer sharing correlation sub-networks, the semantic correlation information of cross-modal is used to complete the cross-modal retrieval task in the target domain [4].
Multilabel double-layer learning (MDLL) is proposed for the multilabel cross model retrieval task [5]. A deep supervised cross model retrieval (DSCMR) is developed, which provides a common space to compare the different modalities of the dataset. A combined model of image and text components of multimedia content is presented in [6]. The authors in [7] suggested a Scalable Deep Multi-Model Learning (SDML) for the cross model retrieval task. The SDML works on the principle of maximizing the between-class variation and minimizing the within-class variation. A Generalized Semi-Supervised Structured Subspaces learning (GSS-SL) is proposed for the cross model retrieval task [15]. A joint optimization framework with Kernel Correlation Maximization and Discriminative structure is presented for the cross model retrieval task [16]. A combination of different modalities, features selection and multi-model graph regularization scheme is proposed for the cross model retrieval task [17].
The retrieval tasks of cross-modal are divided into four subcategories; a) Single Label Paired (SL-P), b) Single Label Unpaired (SL-U), c) Multi-Label Paired (ML-P) and d) Multi-Label Unpaired (ML-U). In SL-P, the samples of two different modalities present in the one to one mapping. In SL-U, the paring is missing; ML-P deals with the multiple label data with the pair information. In ML-U, both modalities are having the number of multi labels data in different forms. The paired and unpaired data cross-modal retrieval is performed with the hashing methods. The cross-modal retrieval process is classified into a single label and multilabel. A single label sample is that in which each sample belongs to the single semantic class. There are some drawbacks present in the cross-modal approach. The semantic word representation can easily learn by the cross-modal retrieval compared to text word representation. In most of the multimodal retrieval concepts, the autoencoders [1, 8–12] are used for decoding the semantic information of data. The new assign weights are multiplied with the dimension and content of the image or text. The modalities of text and visual are encoded in vectors automatically.
Research gap
From the above discussion, we can point out the following research gaps: In multimodal, the features are mapped into common latent space, but these features lose their locality, which makes them prone to noise and false classification error. Binary Labels in multimodality analysis include only the label information and ignores the mapped feature information. The data is not divided into the same classes based on the features or label only. High-dimensional features transformation in the encoder is prone to noise. So, the features are also transformed in multimodal space with hypergraph regularization.
Motivation and contribution
In this paper, we have worked twofold on the multi-modality classification. The data for this has multi labels, and for single modalities, the algorithm adaption (ex. Adaboost, rank-SVM, KNN) and Problem Transformation (PT) (ex. Label power set, binary relevance) are two algorithm categories. The binary relevance is a widely used method as PT can be used with any classifier, but it considers only the label and ignores the features information [29]. Figure 1 shows the relevance of our statement. The common latent space representation for the first two directions is shown in this figure. The image-text data are not mapped with distinctive, as shown in figure (a) and (b). The BR method for label transformation mixes the labels due to the unavailability of feature information as in Fig. 1(a). CPLST uses the feature information in label transformation and performs better in labelled data segmentation, but labels are not distinct. We also experimented with other label transformation schemes [30, 31] but CPLST outperformed other in multimodal analysis, section 4 also elaborates this. Although the multimodal extension of CPLST has mapped the labels into embedding space, yet the projection of the features in the common space is not efficient in multimodal semantic autoencoder.
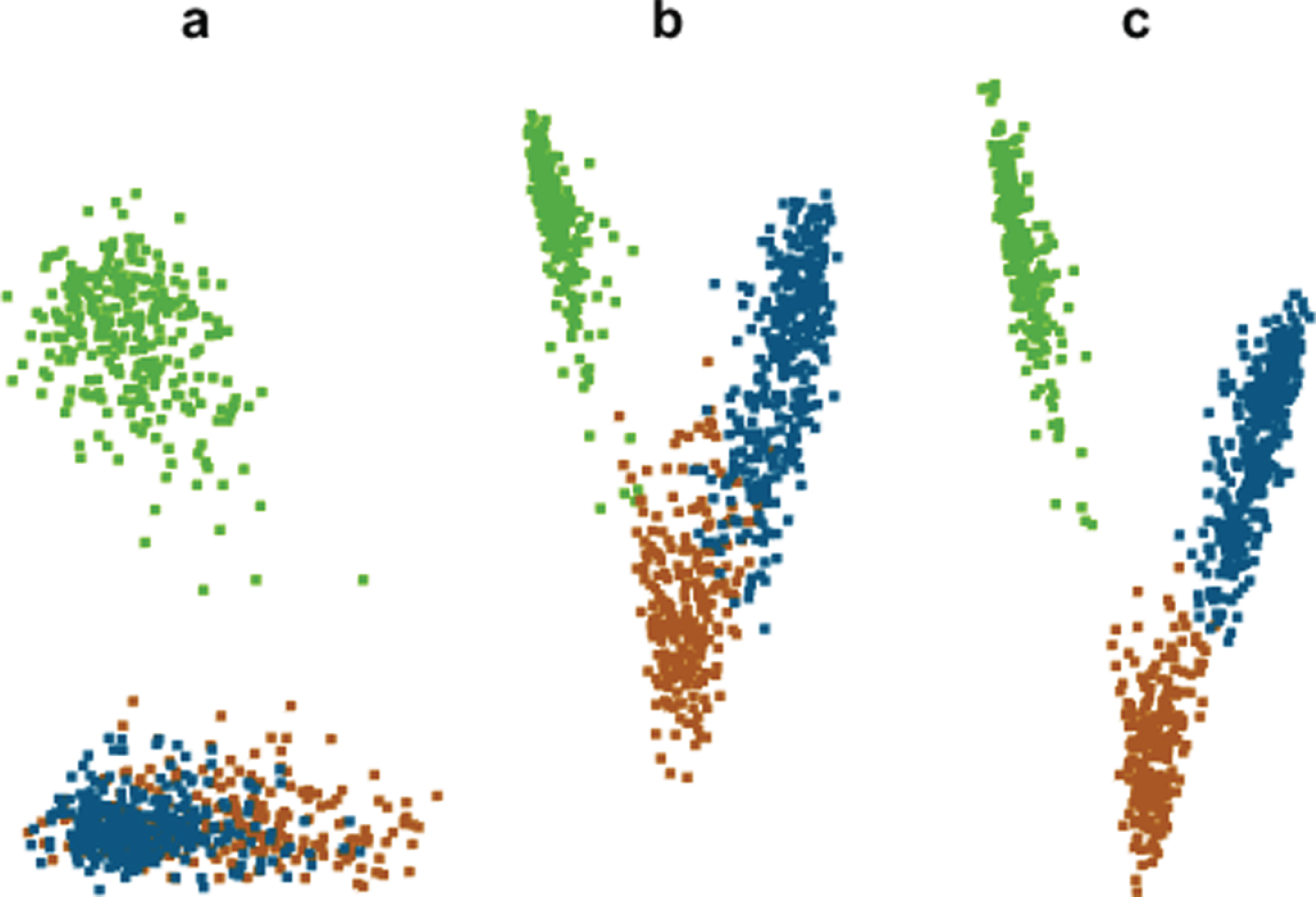
Common latent dimension representation for three categories with the most number of samples in wiki dataset. These are the results for (a) BR + DHMMSAE (b) MCPLST + MMSAE (c) MCPLST + DHMMSAE.
Our contribution to this work is transforming the features into multimodal space by Conditional Principal label Space Transformation (CPLST). Introduction of a novel multimodal semantic autoencoder named Distinctive Regularized Semantic Autoencoder (DRSAE). preserving the high-dimensional features locality information by hypergraph regularization.
This work presents the joint projection of image and text features into a common latent space in the semantic autoencoder with distinctive features. The locality information of the features can be lost due to the high dimensionality of these data. Preserving it can make the data less prone to noise. To preserve feature space’s locality in manifold space, we add the hypergraph regularization to semantic autoencoder. In machine learning, it is believed that the features near to semantic space are more likely to share the common labels. To make the manifold locality projection of AE successful, features with multi labels should be distinct. So, a discriminative regularization factor is also added into the multimodal semantic AE. Figure 1(c) validates our statement. The proof of contribution is discussed in section 3 of this article. We name the proposed semantic autoencoder as Distinctive Regularized Semantic Autoencoder (DRSAE).
We here transform the multilabel into a feature aware semantic space by following the extension of Conditional Principal label space transformation (CPLST) into the multimodal space by [1] before common space data mapping.
Further in this paper, section 2 deal with the semantic autoencoder work. In section 3, the proposed method and problem statement will be given. The results and discussion are provided in section 5 that followed by concluded section 5.
Proposed semantic autoencoder
As previously discussed, the low dimensional space features don’t project by semantic autoencoder (SAE) [8]. The multimodal SAE features projection depend on them [1]. To project the multimodal features into the low dimension space, we add the regularization into the SAE. The P v and P t are the projection vector of image and text data, respectively. V and T contain the original features of image and text data.
In the image modality, the features are projected to hidden representation, and these have the complete information of the original information matrix and recover back them to original features. It can be represented as
The hidden space would be shared for the semantic similarity for both modal data. We define the autoencoder as the loss function’s square, i.e., Frobenius norm’s square of the approximation error. It minimizes the error of projecting the feature matrix to hidden space and from the hidden space as:
Equation 3 represents the linear encoder with a single hidden layer. As discussed earlier, this equation doesn’t confirm that the projection can maintain the manifold structure of the data. To preserve the manifold data structure, the feature matrix has to be presented into low dimensional feature space. For this purpose, we add the hypergraph regularization in the autoencoder’s loss function. Then Equation 3 updates as:
The first two terms are the loss function for projecting the features into hidden space and from hidden space for image modality. 3rd component is the hypergraph regularization parameter. Here L is the Laplacian parameter which is calculated by constructing the adjacency matrix from the features graph. We also added the nuclear form and L21 norm regularization to have a low-rank structure. Similar is for the text modality. A soft regularizer parameter
Inspired by the work [23, 24], we add the supervised label information in the above equation. The discriminative label information can be added in Equation 4 as:
In it, the factor |S - AU|2 is the Frobenius norm for the localization of the label. Here
We have text and image modalities for the semantic analysis, so dual hypergraph regularization is proposed. To get the hypergraph regularization parameter, a weighted graph for given k points x1, x2, x3 … x k needs to be constructed with k nodes. Figure 2 demonstrates the proposed algorithm. The algorithm 1 lists the steps to calculate the hypergraph regularization parameter.
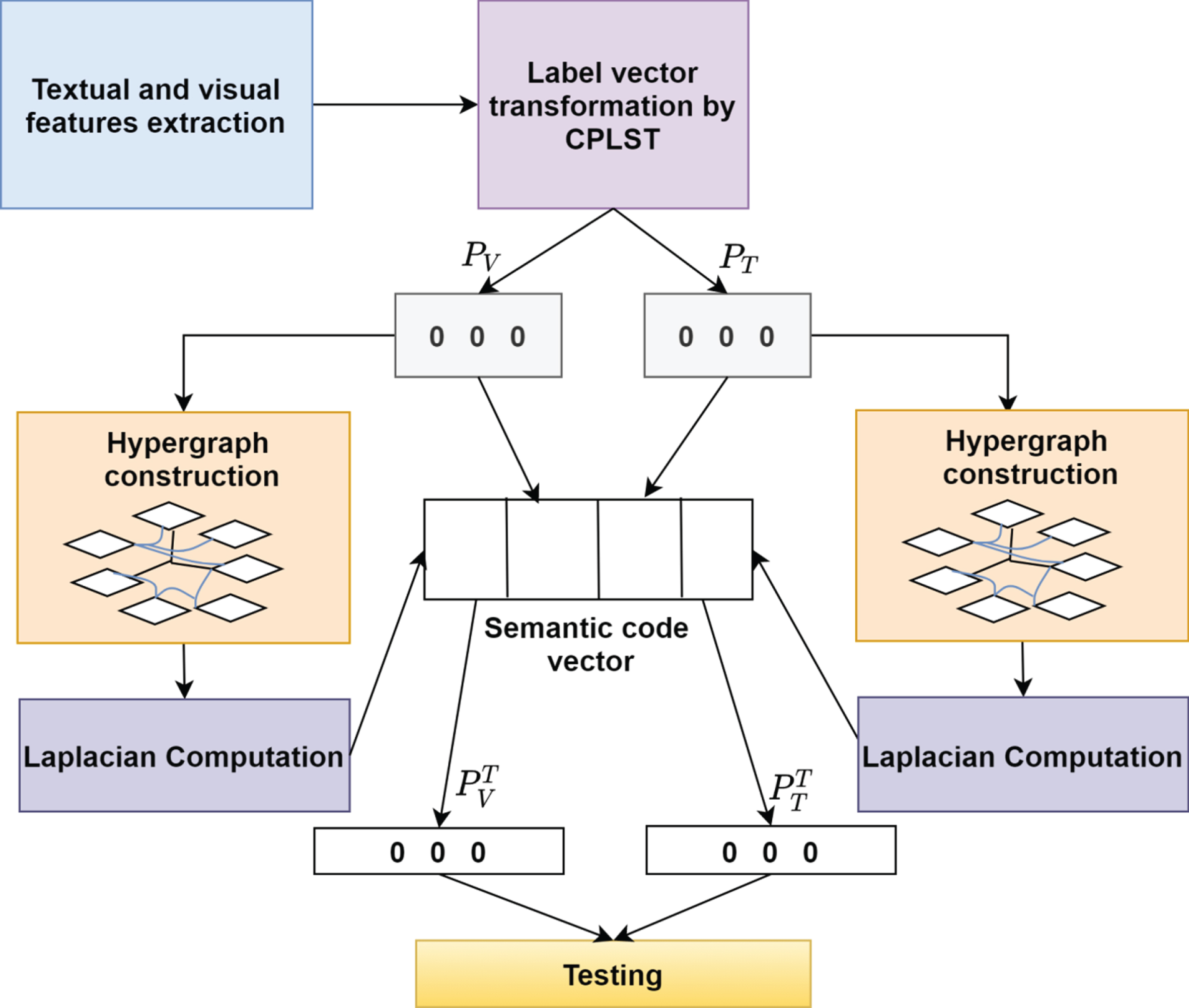
Multimodal semantic autoencoder with Hypergraph regularization for locality preservation.
Steps to calculate the graph regularization parameter
Equation 4 is the convex joint equation for P
v
, P
t
and U and solved by the iterative algorithm. P
v
and P
t
are similar, so we solve here P
v
only. The square of loss function for P
v
is solved and the image modality component is updated as in Equation 7.
Equation 7 is modified as;
Equation 8 can be written as
Similarly for text modality, the solution is
Equations 9 and 10 are the Sylvester equations and can be solved by Bartels-Stewart algorithm. To obtain the solution of U, we differentiate Equation 5 w.r.t U. The differentiation further can be solved as
Rearranging Equation 12:
The final solution for U is:
Multimodal semantic hypergraph regularized autoencoder Optimization
Dataset
Wiki dataset: It is the Wikipedia features article dataset that contains approximate 2866 relation of image to text. Among the Wiki dataset, 76% of features pairs are used for the training purpose and 24% for testing. The features of the dataset have ten different categories of labels. Text features are extracted with 10-dim LDA, and image features are extracted using CNN.
Evaluation parameter
We have evaluated the classification results based on mean average precision (MAP). MAP for text searching with image query as input and image searching with text query is evaluated. The hamming loss for the label transformation evaluation is used.
Results
The multimodal classification problem requires the projection of data into hidden space. We have used two modal data which has images and their text description. These have the same labels as their semantic meaning is similar. To extract the semantic code vector, we experimented with three label space dimension reduction prototypes: MCPLST [25], FaIE [26], CSSP [27]. The labels are transformed into a new paradigm instead of binary vectors for multiclass. Table 2 shows the results with the proposed feature vectors projection into the hidden space in semantic AE for wiki dataset for baseline comparison.
Baseline comparison of wiki dataset for multimodal classification
Baseline comparison of wiki dataset for multimodal classification
To evaluate the performance, MAE is calculated for the first R = 50 results of a query and all results. Image to text and text to image both modalities are checked for performance. The proposed projection scheme is tested with the no-label transformation. Without transformation, labels are converted into multilabel by one to many methods which are similar to BR. In that case, the accuracy is minimum amongst all baseline schemes. The label transformation by CPLST shows the most improved classification with the proposed projection for the image queries for text searching. Although for text queries, it’s not true. The FaIE transformation is best for it. The projection with baseline hypergraph regularization with MCPLST performs better than the MMSAE projection. We specified the MMSAE projection because the previous work by Wu et al. [1] has used this scheme. The results of MAE with all test results are also competitive, but we assume that in a multimodal searching framework, the user will hardly be interested in more than 50 search results. The plot for hamming losses for the label transformation methods is shown in Fig. 3.
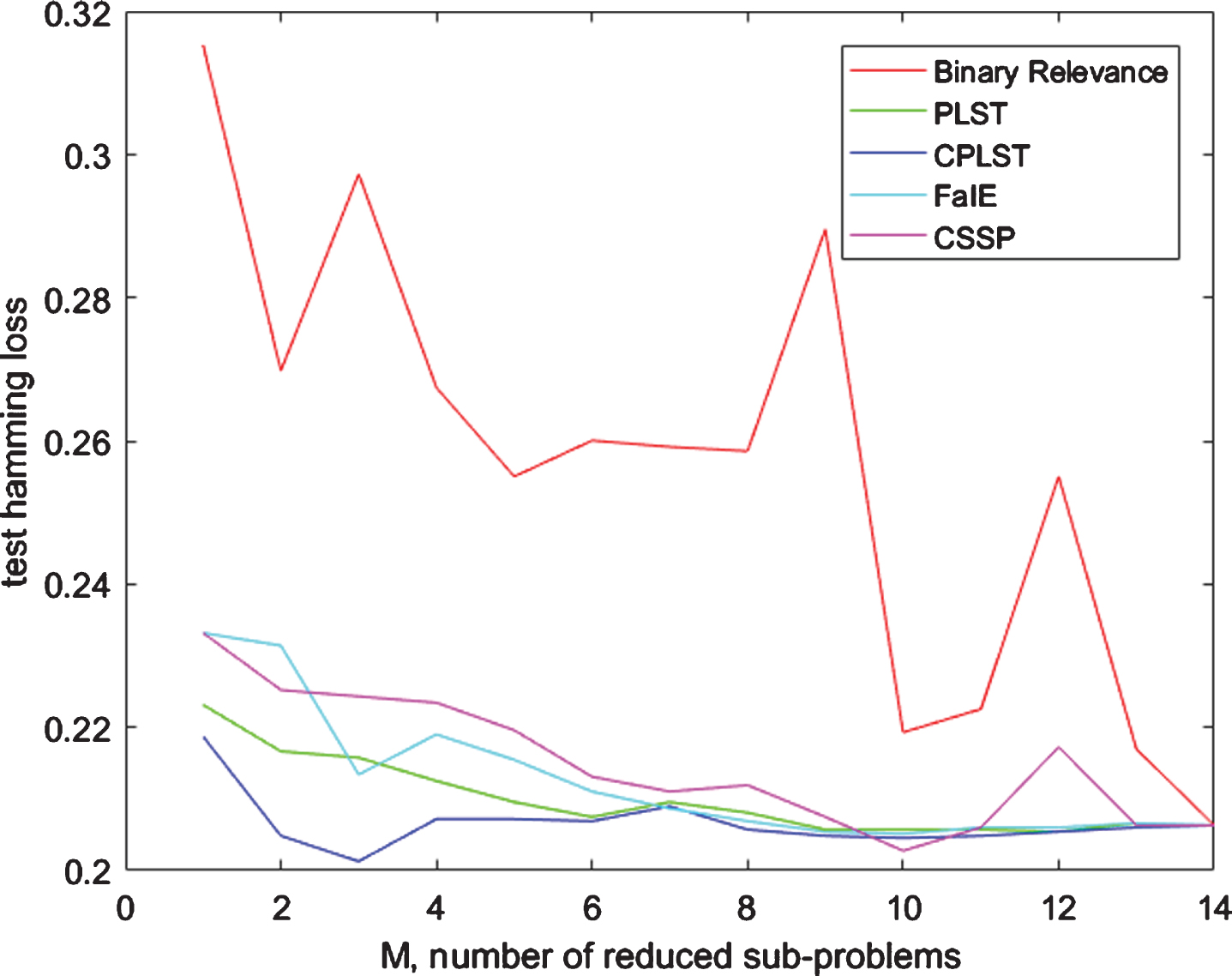
Hamming loss vs sub-problems reduction for Label transformation ratio.
The hamming losses are least for the CPLST label transformation and highest for BR. The parameters α, β, and σ are set to 1, 0.1, 0.1, respectively. The hidden space size can’t be more than the label categories (d ⩽ C). To set the hidden dimension, we evaluated the baseline methods for different dimensions of d and shown in Fig. 3. We tested for the hidden dimension di=2,4,6,8,10 for wiki dataset. This data has 10 label categories. The plot in Fig. 4 demonstrates that MAP increases with the increase in the hidden dimension. The discretized improvement in the scheme with no label transformation and DHMMSAE is more with the hidden dimension change. However, this pattern is not visible in others due to semantic label transformation with features information.
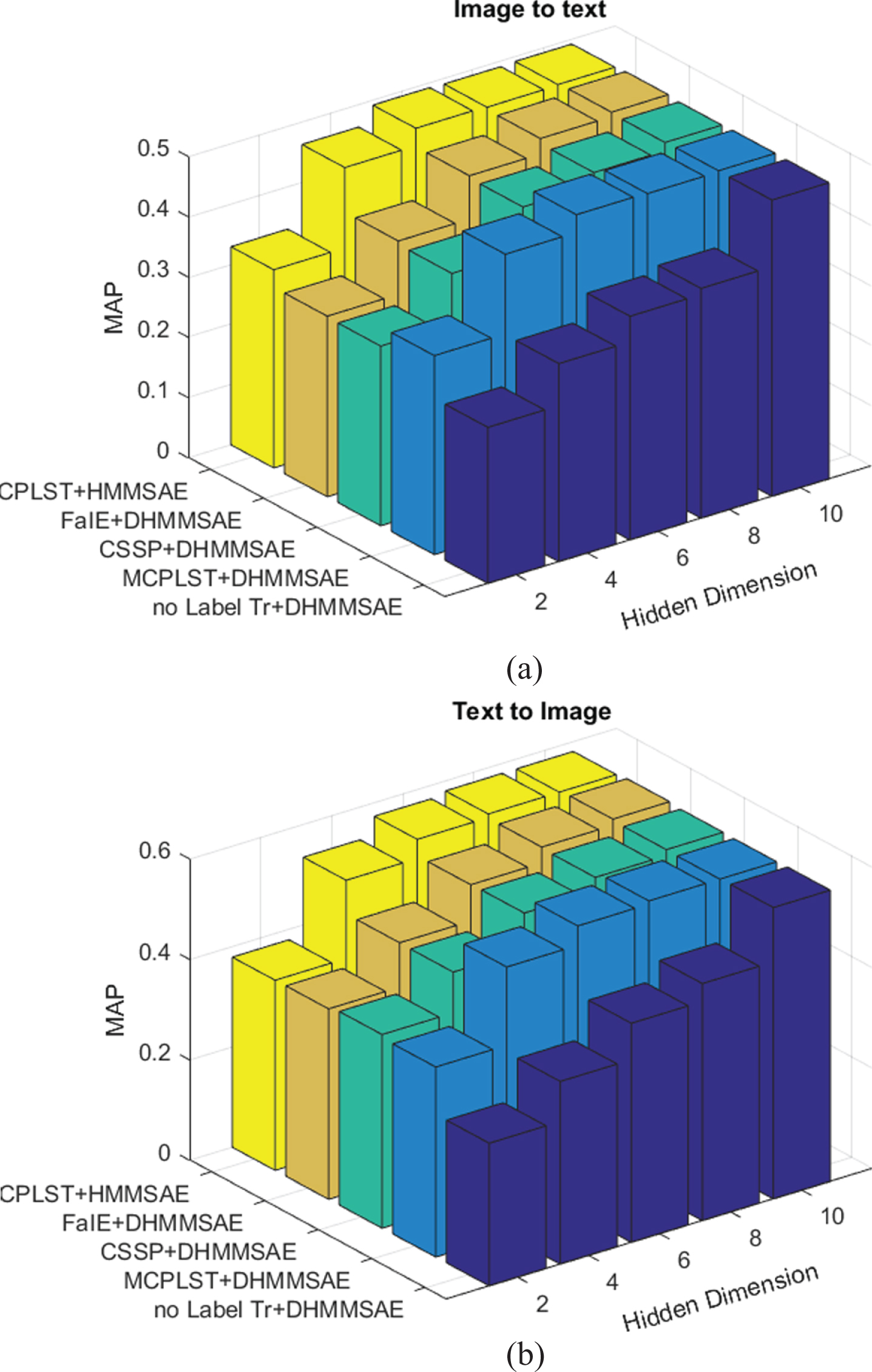
Baseline comparison of MAE for hidden dimension varying from 2 to 10 for wiki dataset.
It is also noticed that after di=4, the improvement in the MAP is not significant in case of MCPLST with DHMMSAE projection and MMSAE projection whereas, in FaIE and CSSP label transformation with DHMMSAE projection, it gains the noticeable improvement at every d i . It proves that with the higher hidden space dimension of semantic autoencoder, the MCPLST label transformation performs better. A similar improvement pattern can be noticed in both text to image and image to text modalities.
We compared the proposed project scheme with PLS [27], GMLDA [28], 3-view CCA [29], ml-CCA [30], LGCFL [31], JFSSL [32] and MMSAE [1] in Table 3. PLS uses the covariance/correlation between pairs for data to maximize the projection in the common space. In contrast, other schemes are supervised learning schemes to project the features into latent space. GMLDA combines the CCA and LDA. 3-view CCA, ml-CCA, LGCFL and JFSSL extend the algorithm to incorporate the label information. MMSAE project the features into semantic space after label transformation into embedding space. Due to distinct labels with projected features into LPP space, the DHMMSAE can improve the image to text classification accuracy up to 2.5% from the most recent SAE work MMSAE [1].
Wiki dataset classification evaluation for text to image and image to text search queries
Though the text to image query has no impact in the case of both schemes, this is because the text features are extracted from Linear Discriminant analysis (LDA), which extracts the low dimensional features. LDA also belongs to the feature space dimension reduction paradigm like MCPLST. Due to these LDA features, MMSAE and DHMMSAE is similar for text to image searching. The proposed scheme has shown a significant improvement from all other states of the art in Table 3 for both image 2 text and text 2 images.
In the field of multimodal semantic analysis, we have started with the multilabel transformation to inherit the feature information in labels. CPLST, FaIE, CSSP, BR label transformation methods are experimented with the proposed semantic autoencoder and evaluated by hamming loss curve. The CPLST transformation is the most effective method for semantic code vector generation. The semantic autoencoder is regularized with a hypergraph to preserve the manifold information of features in the latent space. To make the projection more distinct and robust to feature noise, a discriminative factor is also added to SAE. We name this semantic autoencoder as DHMMSAE. Results are tested with wiki dataset for image query for text searching and vice versa. An improvement of 2.5% over recent MMSAE work is achieved, and more significant performance is noticed with 6 other states of the art. Quantitative analysis with hidden space dimension is also discussed to analyze the hidden dimension effect.
Throughout this work, we worked with a linear single layer autoencoder, so we plan to experiment with a multilayer semantic autoencoder as the next part of our work. During this work, we noticed the LDA text features don’t improve DHMMSAE due to the prior extraction of distinctive features. It may require a good embedding space linking images and text to improve the multimodal classification.