
Abstract
With the ever-rising threat to security, multiple industries are always in search of safer communication techniques both in rest and transit. Multiple security institutions agree that any systems security can be modeled around three major concepts: Confidentiality, Availability, and Integrity. We try to reduce the holes in these concepts by developing a Deep Learning based Steganography technique. In our study, we have seen, data compression has to be at the heart of any sound steganography system. In this paper, we have shown that it is possible to compress and encode data efficiently to solve critical problems of steganography. The deep learning technique, which comprises an auto-encoder with Convolutional Neural Network as its building block, not only compresses the secret file but also learns how to hide the compressed data in the cover file efficiently. The proposed techniques can encode secret files of the same size as of cover, or in some sporadic cases, even larger files can be encoded. We have also shown that the same model architecture can theoretically be applied to any file type. Finally, we show that our proposed technique surreptitiously evades all popular steganalysis techniques.
Introduction
With the growth in internet usage, there has been an ever-increasing concern about information security. Cryptography can be considered one of the possible solutions, but it makes it even more apparent that there is some secret information. On the other hand, steganography conceals the fact that there is some information to hide in the first place. The ancient Greeks first conceptualized steganography, which has been an effective technique with its fair share of troughs and crests. It is an idea where a ’secret’ is hidden in a ’carrier,’ hiding its existence. The secret is usually smaller, with the cover being 80 or sometimes even 90 times bigger than the secret. The whole process of hiding the information needs to be easy and less computationally intensive. In recent times steganography has seen a rekindled interest noticeably due to the search for more efficient data hiding technology, but it has also been used by adversaries to perform illegal activities on the internet [1]. The study of steganographic files is called steganalysis. There has been quite a lot of research in the field of steganalysis involving deep learning and other statistical techniques, however the encoding process itself has not had enough research.
We believe, it is essential to have data compression as the centerpiece of any modern steganographic system. One of the biggest problems of steganography is the noticeable visual changes in the carrier after the secret is hidden. The solution to this problems is deploying an efficient data compression technique to compress the secret data. Hence, solving the visual discrepancy issue because there will be only a relatively small amount of data to be hidden.
Many compression algorithms exist today, but a neural network can be replaced by creating an end-to-end solution for data compression and data encoding. So let us assume we have a stream of bits stored in a disk. Each bit of data has its index of location on the disk. If we train the model to learn these indices to point at the data at that location, we have built a very efficient data compression technique–the models taken in the index as an input and outputs a data point.
To solve the problems in steganography, we believe deep learning is the best fit solution. Human brain is not efficient at understanding vast interconnected inferences; this is where deep generative models can help us understand, remember, and use them. These inferences are later used to better encode the compressed data into the carrier file. We use Auto-encoding Neural Networks (AE) in the form of Variational Auto-Encoders (VAE). These networks are designed to recreate the input at the output, forcing the model to learn all the latent variables in the process. An AE has two parts, an encoder, and a decoder. The output of the encoder is the compressed information that can be used to send over the internet. Another advantage of using AE is that after the encoding process, if there is some noise added due to transmission or data corruption, VAE’s generative properties can help it to recreate the original input again.
Current steganographic algorithms include manipulation of least significant bits (LSB) of images [2], where data is placed in the LSB of up to 5 bits. The LSB method is usually not very successful as the amount of secret to be encoded is quite small while also altering the carriers’ visual appearance. The second technique is HUGO [3], which is based on LSB methods and tries to solve the issue of first and second-order statistical steganalysis. A significant problem with the above methods is that the secret size is petite (<0.5 bpp). Other methods include storing the secret information within the phase of the frequency of carriers; this idea was primarily designed for audio data but was later modified for images [4].
In some of the recent studies, there has been wide adoption of deep learning methods for steganalysis, with impressive results it is the right candidate for steganalysis [5–7]. Neural networks in the hiding process were shown by Abadi et al. [8], where adversarial networks were trained for cryptographic information. In terms of secret message encoding, Fang et al. [9] have shown that it is possible by using LSTMs. Another interesting approach was brought to light by Uchida et al. [10], where the watermarks were embedded into the weights of the trained model.
ExypnoSteganos, an end-to-end framework which takes in a secret and cover and outputs a hidden carrier to be sent to the other party. Fig. 1 There is quite a bit of pre-processing required, which will be explained in the sections below. Section - II talks about similar research in this field, Section – III explains the architecture of the system, in Section - IV we analyse the results from various experimentation, and finally in Section - V we state our conclusions.

Proposed System.
In our contribution we develop a single end-to-end framework to hide data effectively using as little resources. The framework is scalable and works for any data size and file type, though our work will concentrate on high density data like images, videos and audio. Steganography usually assumes a lossless transmission, but our implementation will be able to rebuild the secret with a loss of up to 10%. It withstands tests on Capacity, Secrecy, and Robustness. Capacity – the size of the secret should be the same or at least 80% of the cover’s size. The bits-per-pixel (bpp) value should be less than 0.001, so the systems can fool all major steganalysis methods. Secrecy – the secret should be well encoded so that it does not distort the cover, and the distortion should be less than 10%. Robustness – the integrity of the secret should be held even if the encoded file is altered. This includes cropping the hidden file, data compression techniques.
The word ExypnoSteganos is derived from two Greek word; Exypno which translates to smart and Steganos means covered hence, smartly covered is the direct translation.
The most frequently researched Steganography technique is LSB manipulation, where secret embedding is in each pixel’s LSB. Most of the time, LSB techniques are susceptible to statistical analysis; hence, giving rise to adaptable replacements or more sophisticated methods [11, 12]. These approaches may or may not cause a perceivable difference in the cover depending on the type and size of the secret. Even if it is not perceivable, the presence of a secret can be detected by basic tools. To solve these glitches, more progressive approaches include HUGO [13], where the underlying statistics of the cover is preserved. Alternative methods include Wavelet Obtained Weights [14], which uses the distortion of foreseeable regions to embed data. Similarly, S-UNIWARD is used to embed data in random domains.
Watermarking, one of the associated tasks, has the same needs but with more robustness. LSB has been used in watermarking, too [15], with varying degrees of success. An exciting prospect is using a neural network for watermarking, where the owner’s copyright information is embedded in the weights or parameters of the network [16]. Adversarial techniques make use of artificial patterns that are cautiously designed by adding noise or artifacts to genuine instances. The patterns are designed to be unidentifiable but fail miserably [17]. The adversarial issue is a significant problem with machine learning models and are usually not acceptable to have. However, the researchers have used it to their advantage and use them to insert perturbations to make it more robust and encode useful information.
Only in recent years, false information has been used in the steganographic process, even more for steganalysis [18]. Most of these studies concentrate on increasing the robustness of the data being hidden, but at the cost of long training times and huge dataset requirements. Nevertheless, a motivating reason to consider is that despite these shortcomings using neural networks is still better as the output from this process is far superior in quality compared to the traditional methods.
With the surge in multimedia technologies, the number of videos on the internet is accrescent. Naturally, several want to take advantage of this for either safe communication or to protect copyright information. Steganography in videos has been developing in three different axes, which is where the data is stored. First is raw video domain or pre-embedding; second is in a compressed domain, or intra-embedding and third & last is in bit stream domain or post-embedding. All of the listed methods have either Discrete Cosine/Sine Transform (DCT/DST) encoding, motion estimation, angle estimation at its core. They are usually not considered apt methods for commercial usage [19].
The emergence of generative networks has led to remarkable advancements in artificially generating content. Hayes et al. used GANs for the state of the art steganography, where the secret was supplied, and the cover was explicitly generated based on the secret. The proposed systems have some flaws, which is shown by the experiment; imagine Alice, Bob, and Eve, Alice has the encoder network (EN), Bob uses the decoder network (DE) to decode the secret, and Eve uses a similar network to detect steganographic data. The experiments have shown that Eve has failed to detect secret with a reasonable probability, showing the secret can be detected by other algorithms, failing at the core objective.
Tang et al. proposed a steganographic distortion learning framework. [20], where two GAN networks were trained where the embedding changes for each pixel in a given three-dimensional image (RGB). The network would then produce a minimally distorted cover image; however, the results are about the same for a manually manipulated cover image. Typically neural networks were used only to detect the locations where watermarking information can be hidden effectively. However, in our system, we propose an end-to-end framework to identify the locations for encoding, compression and hiding processes.
Architecture
Auto-encoders
AE is a category of neural networks which attempts to reconstruct the input at its output. The network can be viewed as two functions, the encoder function e = f(x) (left) and the decoder function d = g(e) (right) shown in Fig. 2. If we set the model to optimize on g(f(x)) = x then it’s not very useful. However, if we instead train the model to learn the latent variables of the data, with some augmented approximation, we can tap into the generative properties of AE. Conventionally, they have always been used for dimensionality slimming or feature learning, but its generative modeling capabilities have made them a common choice for generative applications. In ExypnoSteganos, we use the encoder part of the AE to encode the secret information into the cover. The encoder takes the output from the compressor net (CN) and the cover file to produce a stego file, which is the cover file with secret encoding. The file is then used by the decoder to recreate the secret file [21]. Because of AE’s generative property, even if there is some loss in the stego file during transmission or some compression, ExypnoSteganos can recreate the secret with loss within the acceptable range. This is shown by adding a Gaussian noise layer in between, to replicate real-world loss.
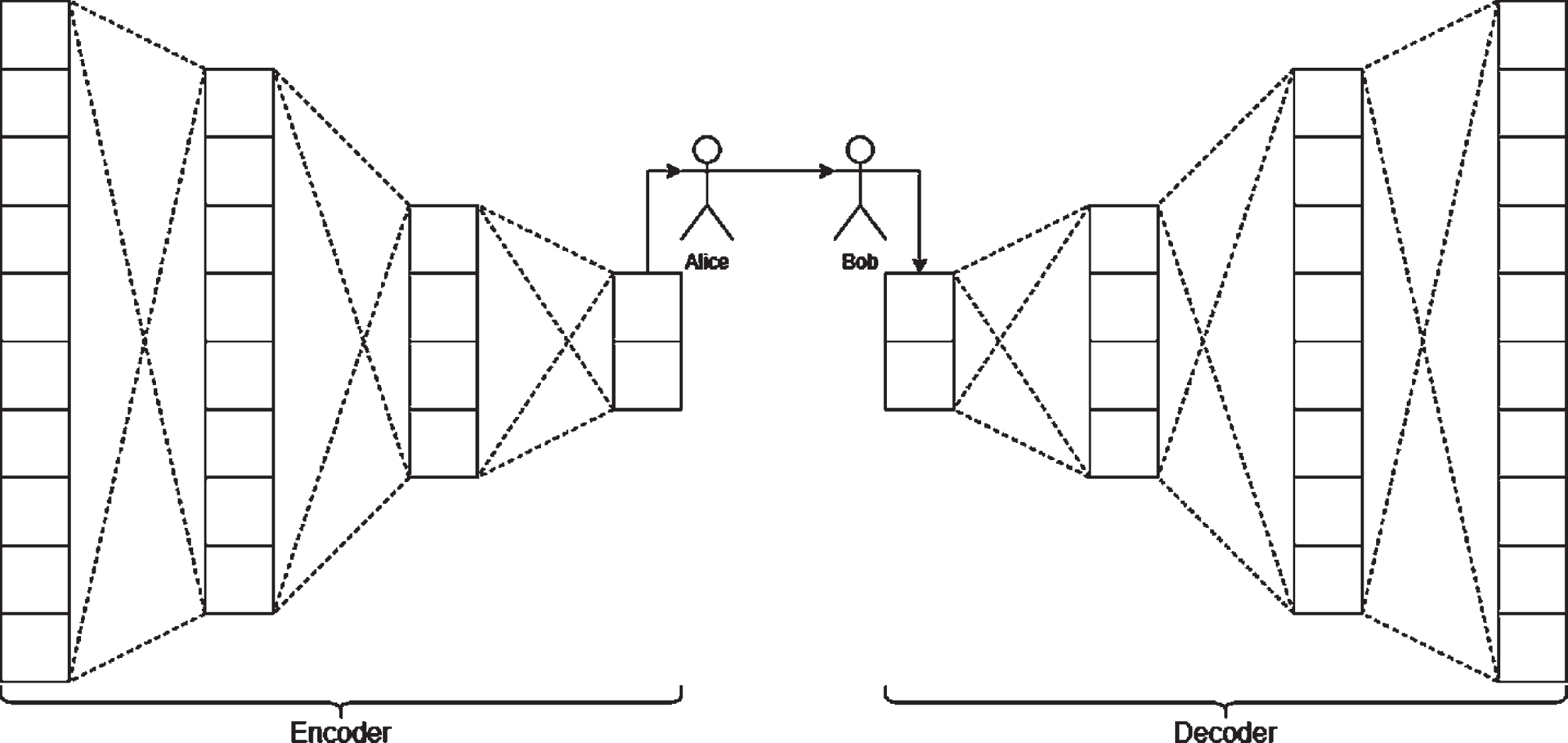
Auto-encoders.
CNN is a massive class of deep learning networks, primarily used for image or data with a high density of information. Conventionally, CNN was considered too computationally expensive, but with the profusion of data and processing hardware such as GPUs, CNN has become vital to any image or media learning. CNN is not a new algorithm; it has been used quite extensively in computer vision systems. They have been applied for processes like noise reduction, blurring, smoothing, and other image manipulation processes. In the field of machine learning CNN has been a popular choice for classification, object segmentation like applications. [22]. Old-style methods involved handcrafted patterns or filters used to identify patterns, edges, and objects from a picture. These techniques were extraordinarily technical and needed careful analysis and research. With the application of Neural Networks, we can automate the learning process of pattern creation. CNN’s are now able to build and correct the patterns by the method of backpropagation. This allows the model to learn more abstract features, making it exceptionally well suited for an application with complicated patterns and high-level features.
In our system, we use a relatively simple but effective CNN model. We designed a model built up of 15 layers with kernel sizes 4x4, 5x5, 6x6. The kernel size determines how much information is sent to the model. We use ReLU (Rectified Linear Unit) as our activation function to activate each node in the network. The Adams Optimizer is used to optimize for loss at each step. This helps us to learn to reduce the loss for the network as well as increasing the efficiency of the data being encoded in the cover.
Datasets and pre-processing
Images
We have chosen the CalTech256 [23] and ImageNet datasets for training the model. These datasets were chosen just because there were both random and vast in the number of images in each object category. To train the model, randomly chosen images were used for training and testing. We trained two separate models for PNG and JPEG images, both eventually leading to almost the same quality of steganography. Table 1 Shows the number of testing, training, and validation samples used. Most of these images had 300*250 pixels resolution, But all of them were re-scaled to 224*224 for training purposes, though the model is designed to work on any image sizes. The values of each pixel were normalized Fig. 3. and sent to the model in the shape of 224*224*3 (3 channels RGB).
Train-Test dataset sizes
Train-Test dataset sizes
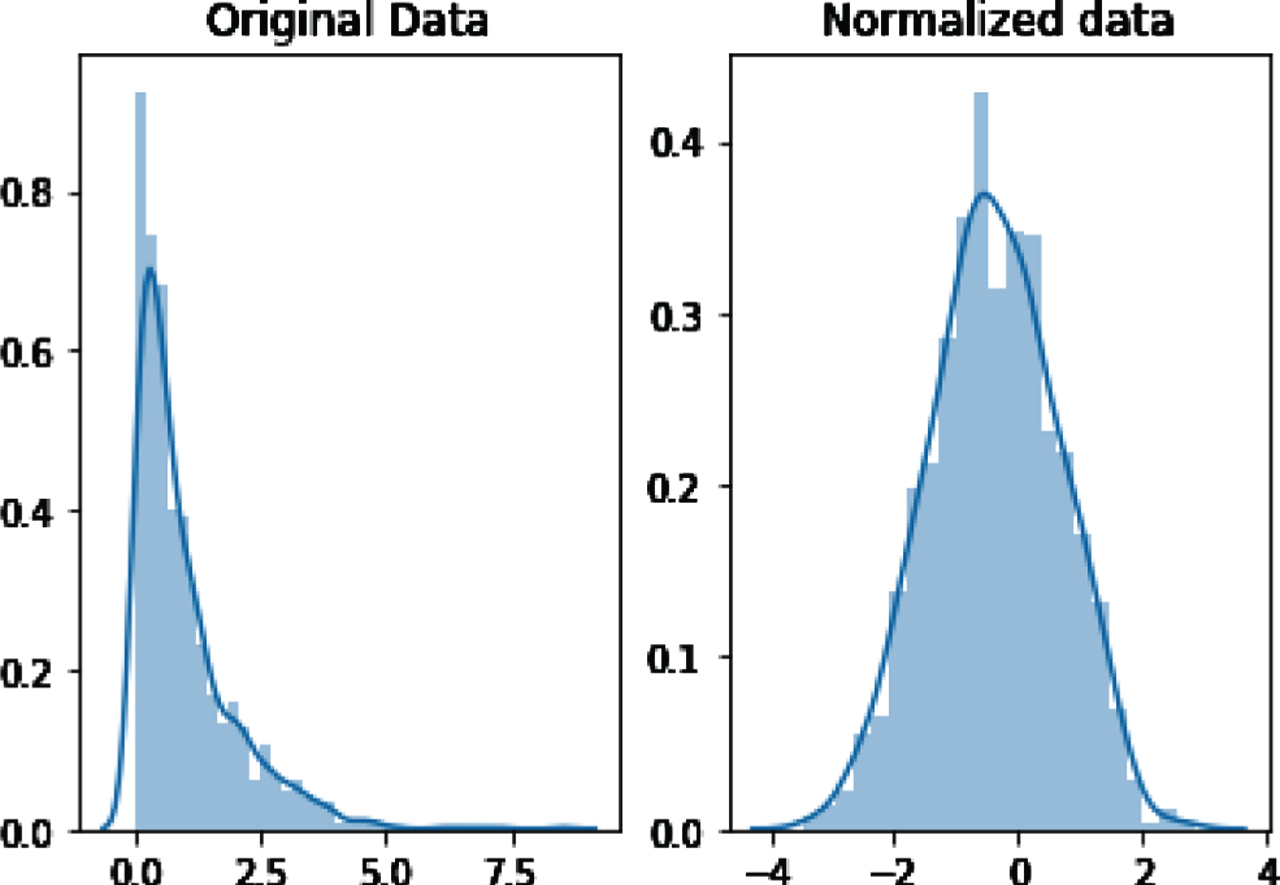
Normalized image data in all 3 channels.
For audio, we choose the UrbanSound8K and VIVOS corpus datasets. The UrbanSounds8K dataset has numerous categories, each made up of different types of sounds in a city life setting. These include various sounds and noise clips, giving us a huge variety to play with and teach the model. On the other hand, the VIVOS dataset has human spoken voices. This model combination gives us useful data to teach the model in a vast frequency range.
We consider only sound files above 4 seconds, anything below that will have too little information to manipulate. The pre-processing for audio is a little complicated; audio files are in the time domain. However, we need it to be in the frequency domain for any manipulation. There are a couple of ways we can achieve this. First is normalizing the raw data and reshaping it to meet the model requirements, this method is not very efficient as a recreation of the secret, and the covers are both affected. The second method is to create a spectrogram of the audio file by applying the Short-Time Fourier Transform (STFT); this effectively localizes the temporal information and reveals the sequence of frequency information. This spectrogram can then be fed into the model as images or textual information. We choose textual methods as they performed better and consumed fewer resources. After STFT, the data is reshaped to 224*224*2 and sent to the model. To recreate the audio file back again, we apply the Inverse Short Time Fourier Transform (ISTFT).
Videos
For videos, we used the VIRAT and YouTube8M datasets, with randomly chosen videos from both. Videos are reasonably easy to pre-process; we extract each frame from the video and send it to the encoder to do its job. As an added layer of security, we can also apply shuffling blocks to add confusion to the mix further. All the pre-processing required for images are also done for the frames extracted from the videos.
Exypno steganos model
Many model architectures were considered and experimented with to attain the most efficient model. One can further tweak the number of filters, kernel sizes, and the number of layers to achieve better results. The model was trained as an end-to-end system where all three subnets are trained together. Even in a commercial setup, the models would be trained together, so Alice and Bob will have to exchange them in person. ExypnoSteganos has a reasonably simple model architecture, made up of three sub-networks, namely CN, EN, and DN. All three subnets are fundamentally identical in the structure; other than slight changes in the EN, we will explain each in detail.
The original cover file is destroyed as it will be a little easier to find the secret if one had the original cover, making steganalysis more difficult for adversaries. In a real-world scenario, the sender would only use an image that is cent percent original and which cannot be found in any dataset on the internet. The security of the embedding will be discussed in detail later. The sender (Alice) needs to have the compressor and encoder model, but for the receiver (Bob) needs only to have the decoder model. The different file types can be encoded into different cover files due to the subnets’ similarities. We have tried the model on images in images, images in audio, audio in audio, audio in images, images in the video, video in video, audio in video. All these work as expected with proper pre-processing.
Base network
The base network (BN) has 15 layers stacked in groups of five layers, each into three parallel groups. Fig. 4 The first cluster consists of 5 layers of two-dimensionality Convolutional layer (Conv2D), with 32 filters and a kernel size of 4*4. This helps the model learn the finest of details. The second cluster is again built up of 5 layers of Conv2D, but with 64 filters and a kernel size of 5*5. This shows the models even more complex patterns in the bigger picture. The third and the last cluster has five layers of Conv2D, with 128 filters and a kernel size of 6*6. At this level, the learning is abstract and gives the highest representation of the secret file. Even though the last group has the best representation of the secret, it has a propensity of skipping important information as it is too much information for the layers to learn. All of the above groups are concatenated into a single array. This array is again fed into three different Conv2D layers with 32 filters each and kernel sizes of 6*6, 5*5 & 4*4, respectively. Finally, there is a last concatenation layer merging the output from three different layers into a single tensor.

Base Model.
With the combination of these three groups, the model is now more than capable of learning lower-level variables. As we are training an AE, the BN is used in all three subnets. This streamlines the overall model architecture. An additional advantage of using a BN is that it is moderately easy to build hardware specific for this model. The same circuit with minor changes can be used for all three subnets, reducing the electricity as well as the chip size.
The job of CN is to accept a secret file from the sender and understand its essential features in the form of its latent variable and compress that information into an array called a tensor, which is then fed to the EN. The CN accepts a secret file and passes it through the base model. This process generates a secret tensor, which is an array of size 224*224*3. The tensor does not have any meaningful information that humans can understand; hence, it is further used by the encoder to create the stego file. Fig. 5

Compressor Net.
EN accepts two inputs, the secret tensor from CN and a cover file are fed into the subnet. There is first a concatenation layer, which combines the secret tensor and the cover file into a single array of size 224*224*3, Fig. 6. Next up BN does its job and performs all the learning needed in this subnet. The network here takes the secret tensor and combines it with the cover file. It finds the best locations to save the secret information and compresses the information from the cover file. Since we are dealing with a 3D array, we can consistently embed the data in all three channels, i.e., RGB.

Encoder Net.
Due to the comprehensive filtering of information, the model can learn intricate patterns. In our experiments, we have seen the model encode secret information in noisy areas and edges of the cover image file. Finding the exact location of the secret information in the correct sequence manually is practically impossible. To have an image as close as possible to the original cover, we use another Conv2D layer with just three filters, one filter for each channel of RGB, and a kernel size of 1*1. This layer then generates the cover file with secret embeddings or stego file.
Every neural-based machine learning model needs an activation function; these functions are used to activated specific weights or nodes as some parameter is passed through the network. We have used ReLU as our activation function at each layer. Since we want to reduce loss in our secret file while also retaining the actual cover information, we should minimize loss throughout the network. To do so, we have to train our model to optimize for loss at each step. Therefore we use Adams Optimizer [24] to optimize for loss. The metrics collected throughout the training process were Mean Square Error (MSE), the reasons for which will be explained later. The learning is the amount of information the model learns. We use a Keras library named ReduceLROnPlateau; this is used to dynamically set the learning rate at every epoch, if the loss does not reduce for three consecutive epochs, we reduce the learning rate by half. We start with a minimum learning rate was 0.1, and the maximum was 0.0000001. In our experiments, we noted the optimal learning rate to be 0.00001 and batch size of 12 (due to memory constraints).
Decoder net
Bob would use the decoder model to decode the secret from the stego file. To do that, the DN Fig. 7, has taken in the stego file and sends it to the BN. The BN is trained to decode the secret based on its inferences. To create the image, we need to pass the tensor again though a Conv2D layer with three filters and a kernel size of 1*1. This process leads to the recreation of the secret file and the cover file.

Decoder Net.
Due to the model architecture and the loss optimization, there is not much difference between the cover and the stego file created, in order to reveal the secret, there is no other way, besides the DN itself. The decoder must be kept secret at all times. For any steganographic algorithm, two significant security aspects are considered. First is steganalysis, and second is its resistance to anti-forensics of the generated files. There are minute visual differences in the stego file and the cover file when compared to each other side by side but, if the cover file is not available, telling if there is a secret embedding in an image just by visual inspection is impossible.
To prove that ExypnoSteganos does stand the test of steganalysis, we consider both traditional and modern methods. To ensure that our system does not encode the secret data in the LSB, we use StegExpose; this will be explained in detail below under statistical analysis subsection. For more modern methods, three neural networks were trained to classify and differentiate between standard file and a file with secret encoding. The first classifier was proposed by Galjan and team [25], which proposes an extension of the spatial rich model, a color-rich model; this will be referred to as CF1. The second classifier proposed by Jian et al. and team is a CNN based steganalysis classifier [26], this will be referred to as CF2. Jiansheng et al. proposed the third classifier and team; this too uses CNNs to classify and detect the secret but with median filters and will be referred as CF3. The above three methods are considered state-of-the-art and used by many agencies all around the world.
For this experiment, we consider two different scenarios; the first is when the three classifiers are trained with a different dataset then what was used for training ExypnoSteganos. The second is when the classifiers were trained with the same dataset as ExypnoSteganos. The above experiment was performed on images, audio and video data, training in total about eighteen different classifiers. Each of these classifiers was then tested with approximately 11,000 of stego files created by ExypnoSteganos. The results are striking at first but obvious when the setup is studied in detail. Table 2, shows that when a different dataset was used for training, the accuracy of detection is extremely low, these classifiers tend to have some artifacts and often are not entirely accurate. However, when the classifiers are trained with the same dataset as ExypnoSteganos, the accuracy of detection is relatively better. This shows that the dataset plays a significant role in the process of data encoding efficiency. In a real-world scenario, the training dataset should be kept secret and include only images that are not available on the internet, or one should use many random images from multiple datasets. With this, we can ensure that, even if the process is publicly available to adversaries, the dataset is what needs to be kept secret. To suggest a workaround to the secret dataset limitation, we suggest prior encryption of the secret image before encoding it within the cover file. This does not solve the problem, but can still keep the contents of the integrity of the secret intact.
Accuracy of various classifiers
Accuracy of various classifiers
To ensure that the secret is not embedded just in the LSB, we test the stego files with a popular LSB analyzer named StegExpose. Fig. 9, the ROC curves show that it is randomly guessing if there is any data in the LSB, shown by red dots and the green line showing a random guess. The testing was done at the default setting of the threshold of 0.2.

Statistical Analysis.

StegExpose ROC.
In this experiment, we try to show the difference between ExypnoSteganos and LSB methods. Fig. 8, shows the difference between the original cover, stego file from ExypnoSteganos, and stego file from 3-bit LSB encoding. The output files look almost identical, but the LSB methods have a serious flaw if the files were statistically analyzed; it turns out to be extremely obvious that the file has tampered.
Fig. 8 also shows the output of the pixel-wise comparison between the cover of the stego files. The yellow in the picture signifies that there is a change in pixel value. Fig. 8 (e), shows that the stego file from ExypnoSteganos is uniform throughout the whole picture, assuring no statistical imparities, but the picture with LSB has data distributed randomly. It becomes evident that there is tampering only in some regions and not in the others. The histogram data of each channel is also more uniformly defined in ExypnoSteganos than LSB.
The most important metric we consider and work with is loss; hence, we optimize for the same. This was done to make sure the generated stego file looks as close as possible to the cover file. The loss equation can be summarized as:
Where the C = cover, S = secret, C’ = cover + secret, S’ = revealed secret, α = variable to alter cover loss, β = variable to alter secret loss. Eq. 1 shows the loss computation for the same file type encoding, while Eq. 2 shows the loss when there is a different cover and a secret file type involved. The α variable is used to alter the amount of loss in the cover, and the β variable is used to alter the loss of secret file. In our experiments, we keep α as one and β as.75; this means that we are training our model to have 0% loss in the cover file and 25% loss in the secret file. Variables of loss were introduced to add more flexibility in the encoding as typically, a certain amount of loss is acceptable in secret.
Mean Square Error (MSE) is the primary metric considered and shows the loss between the cover file and the stego file created during the process. The same metric is used to evaluate the loss of secret files also, Fig. 10. The tweaking of the β and α values have a direct correlation to the quality of the stego file generated, higher the β value higher will be the loss at the cover file. Note, for training; the network SSE was used to evaluate loss but, in a commercial set up, SSIM can be considered, which is closely related to human visual perception. Fig. 9 shows the net loss of all the three subnets; the loss starts to plateau after the 95th epoch with loss of 0.0029, 0.003, and 0.031, respectively, with β set to 0.75.
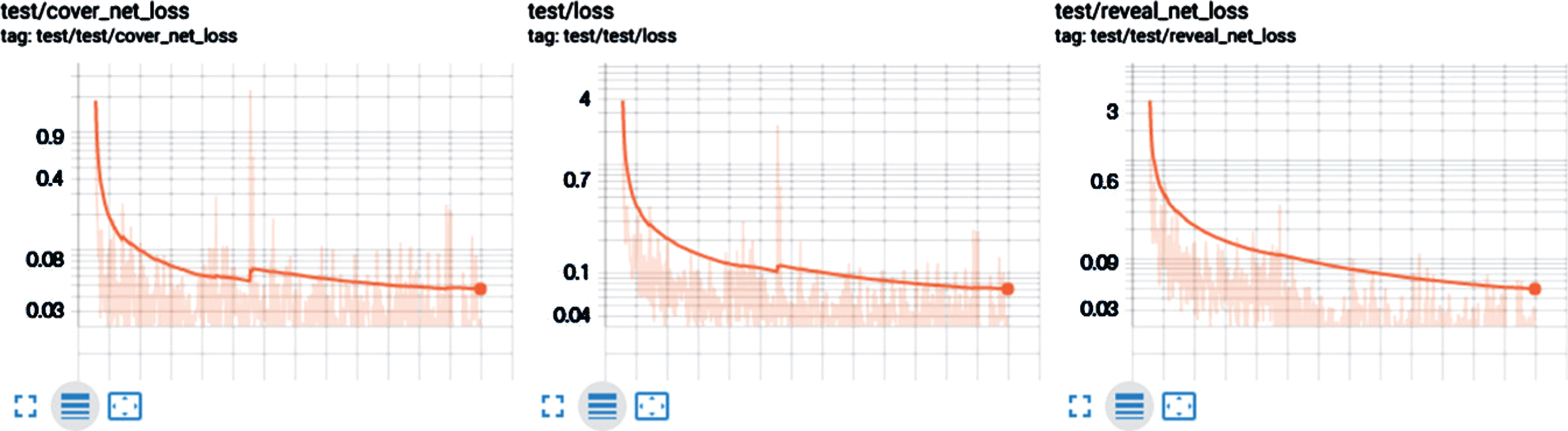
Network loss. Left = CN, Center = EN, Right = DN.
Fig. 11 shows examples of ExypnoSteganos from the last epoch. The first three rows show images of image steganography, the next three rows show audio steganography, and the last two are screenshots of video steganography. For audio, we use spectrograms to show the output on a print media. The spectrogram method can also be used to encode the data by the model, but we send in raw data. Examples of all file types will be available under github.com/sarrafgsarraf/ExypnoSteganos.

Example Output of various file types.
From the examples, it is clear that we can use deep learning as an eligible candidate for the state of the art steganography. We have successfully shown that ExypnoSteganos not only improves the data hiding process but is also able to increase the size of the secret significantly. We have also shown that it is, in fact, possible to generate stego files of high accuracy to evade visual inspection with losses as low as 98%.
By the usage of ExypnoSteganos, we can evade steganalysis techniques that use statistical analysis to find the presence of a secret. If a classifier was to be trained correctly as ours, the absence of the original cover makes it difficult to retrieve the secret. Either the dataset used for training can be kept secret, or the model can be used with minor tweaking. An exciting aspect of this system is that if the model architecture is tweaked even slightly, the secret embedding is entirely different in the stego files generated. These changes, if implemented correctly, make it extremely difficult for adversaries to launch an attack successfully.
In this paper, we have successfully shown that the state of the art steganography is possible to achieve by applying deep neural networks. ExypnoSteganos presents a single model architecture that compresses the secret and then encodes the secret into the cover file efficiently. We have shown and proved that we could increase the size of the secret and have it the same size as the cover. The system consists of an end-to-end framework for the steganographic process, with different data preprocessing techniques for each file type. ExypnoSteganos works efficiently for images, audio, videos, and other files also with varying degrees of success.
ExypnoSteganos has shown that the proposed technique does not distort the cover file; visual changes are almost negligible. We have shown the difference between the input secret and recovered secret file, we have also shown the difference between the input cover and the generated cover to show the negligible loss. The results also show that the StegExpose framework does not detect the secret as the data is not stored in LSBs; we also trained a Deep Neural Network Classifier to adopt more modern steganalysis methods.
Although we have tried to eliminate most of the limitations, some of them include long training times; the system also needs vast computer resources to train quickly. The quality of the encoding reduces significantly when we increase the loss coefficient β to more than 82%. Another major limitation is the success rate of text-based files is much lower than media files; this is probably because the model is too complicated for a low-density dataset The final model size is also quite huge because of the enormous datasets, which can quite easily be solved by using model compression techniques.
The current state of the project opens multiple avenues of future work. First, work needs to be done to encode textual information better. Second, the models’ size can be further compressed for mobile use and possible implementation of the framework as a cloud-based API. Third, work can also be done to try and apply similar techniques for data packets tagging for an IoT like set up. Few more exciting applications to consider are storing digital signatures on various documents to make it safer. This idea can further be expanded to store API keys and other secret information safely in executable. Sum of Squares Error (SSE) was used as an error metrics; this can probably be replaced by Structural Similarity (SSIM), which has a more excellent likeness with human vision.