
Abstract
Uncertain linguistic Z-numbers (ULZNs), which inherit the prominent characteristics of linguistic term sets and Z-numbers, can flexibly describe qualitative information as well as its reliability. To cautiously solve a qualitative multi-criteria decision-making (MCDM) problem with larger number of criteria than alternatives, this paper develops an ULZN-based QUALIFLEX (QUALItative FLEXible multiple criteria method) by considering the decision-maker (DM)’s psychological behavior character. First, the likelihood and diversity degree of ULZNs are determined and a comparison method is proposed. Second, a decision model combining the QUALIFLEX and prospect theory is developed to address MCDM problems with ULZNs, considering the incomplete compensation of criteria. An extended maximizing deviation method is developed to objectively obtain the weights of the criteria. Subsequently, an illustrative example concerning risk evaluation of high-tech project investment with larger number of criteria than alternatives is provided to demonstrate the application of the proposed approach. Finally, sensitivity analysis and comparative analyses are conducted to validate the proposed approach. The result shows that the proposed approach can effectively address MCDM problems with ULZNs, considering the DM’s psychological behavior.
Introduction
In multi-criteria decision-making (MCDM) process, decision-makers (DMs) may provide subjective evaluation information to deal with complex and unconstructed problems [1–3], which are difficult to be assessed with exact numerical values. Additionally, to provide precise quantitative decision information may be unavailable or may be associated with highly computational cost. In this sense, decision information with “approximate value” may be permitted. Thus, DMs’ judgments in the forms of linguistic terms are reliable and informative [4]. MCDM problems with linguistic preference information have emerged and have been the focus of various studies from both theoretical and applied perspectives [5–7]. Although it is suitable to use linguistic terms to approximate some complex or ill-defined preference values, the reliability of decision information in most of these MCDM methods is not cautiously considered. To copy with this limitation, Zadeh [8] proposed the concept of Z-numbers. A Z-number comprises two components that are usually expressed with an ordered pair of fuzzy numbers, denoted by (A, B). A indicates a restriction (constraint) on the values that a real-valued uncertain variable X takes. B measures the reliability (certainty) of A. In this regard, Z-numbers are an adequate formal construct to describe practical decision information. For example, a research company is appointed to predict the economy state of a large firm in the next year. The experts naturally provide evaluations with certain numerical information but would rather give the prediction, (strong growth, likely). The prediction can be represented by a Z-number “X is Z = (A, B)”, where X is the variable state of the economy state, A is the fuzzy number that is used to characterize the soft constraint “strong growth” and B is a fuzzy number that is employed to characterize a soft restriction in terms of the reliability of A.
In recent years, an increasing number of researchers has focused on Z-numbers, and many outcomes have been achieved. Aliev et al. [9] defined a family of operation rules for discrete Z-numbers. Aliev et al. [10] introduced a general methodology to define functions of Z-numbers based on the extension principle. Kang et al. [11] developed a new measure to measure the uncertainty of Z-numbers. Kang et al. [12] proposed the concept of the total utility of Z-numbers that is regarded as an effective tool to rank Z-numbers. These ground-breaking works have enriched the study of Z-numbers. Furthermore, some improvements in the operations of Z-numbers have been performed to overcome the complex calculations in Z-number operational laws. Yaakob and Gegov [13] developed a transformation-based approach to address Z-numbers, in which Z-numbers were translated into some corresponding fuzzy numbers. This idea is indeed simpler than that of previous ones; however, it may lead to information loss and distortion.
The aforementioned studies above mainly focused on the theoretical aspects. On the other hand, some MCDM methods using Z-numbers have been developed. Yaakob and Gegov [13] proposed a novel modification of the TOPSIS approach and applied it to tackle Z-number MCDM problems based on transforming Z-numbers into classic fuzzy numbers. Moreover, other transformation-based methods for Z-number MCDM have been proposed [14–17]. By contrast, Yang and Wang [18] developed a Z-number MCDM method based on the stochastic multi-criteria acceptability analysis and regret theory. Shen et al. [19] proposed an extended MABAC method for MCDM with Z-numbers. Khalif et al. [20] proposed a hybrid fuzzy MCDM approach with Z-numbers combining the fuzzy preference relationships and TOPSIS. Wang et al. [21] introduced a hybrid approach based on the Choquet integral operator and TODIM to manage linguistic Z-number (LZN) MCDM problems based on linguistic scale functions (LSFs) [22]. Compared with conversion-based methods, the LSF-based methods can effectively establish the bridge between linguistic terms and quantitative assessments, and flexibly characterize the DM’s preference of semantics [14]. LZNs have numerous advantages in qualitatively expressing decision information. However, in practice, people may prefer to use interval values instead of single values to capture decision information. Thus, uncertain linguistic variables (ULVs) [23] can flexibly express qualitative decision information, motivating the idea of this study. This paper first proposes the concept of uncertain linguistic Z-numbers (ULZNs) to capture highly uncertain decision information. In a conventional LZN, the first component of A can be expressed as an ULV. Thus, the restriction of values will be more flexible and agrees with the way that DMs provide their assessments. The introduction and practical example about ULZNs are presented in Example 1 and Section 5.
In addition to the classic MCDM models, QUALIFLEX (QUALItative FLEXible multiple criteria method) is one of the most effective outranking approaches for MCDM [24–26]. QUALIFLEX shows perfect performance in solving MCDM problems, in which the criteria’s number is significantly larger than that of the alternatives [27]. However, there has been little focus on how the QUALIFLEX method tackle MCDM problems with ULZNs. Although some approaches have been developed to solve Z-linguistic MCDM problems, almost all of them are based on the presupposition that DMs are entirely rational, ignoring the DM’s behavior preference. Fortunately, Kahneman and Tversky [28] proposed prospect theory, which was widely used to characterize the DM’s behavior in MCDM under risk and uncertainty [29–32].
This study was aimed to extend the theory of Z-numbers and develop an ULZN-based MCDM method by integrating QUALIFLEX and prospect theory. The proposed approach is applicable to solve qualitative and bounded rational MCDM problems, where the criteria’s number is significantly larger than that of the alternatives and the criteria weights is completely unknown. In the proposed framework, several LSFs are applied to address ULZNs, flexibly characterizing the semantics. Moreover, a likelihood-based comparison method and a diversity degree for ULZNs are proposed to deal with ULZNs. An extended maximizing deviation method (MDM) is developed to derive the objective criteria weights.
The remainder of this paper is set out as follows. Section 2 briefly reviews some basic concepts, including LSFs, LZNs and prospect theory. Section 3 defines the concept of ULZN. Additionally, the likelihood and diversity degree for ULZNs are presented. Section 4 develops a prospect theory-based QUALIFLEX method and applies it to tackle MCDM problems with ULZNs, where the criteria weight information is completely unknown. Section 5 provides a real example of HTPI to demonstrate the effectiveness of the proposed approach, followed by some discussion and analysis. Finally, Section 6 concludes this paper.
Preliminaries
This section introduces the basic concepts of LSFs, Z-numbers, LZNs and prospect theory.
Linguistic scale functions
Let S ={ s
α
|α = 0, 1, …, 2t } be a linguistic term set with s0 < s1 < … < s2t. S should satisfy the following characteristics [33]: The set S is ordered: s
α
> s
β
if α > β; There is a negation operator: neg (s
α
) = s2t-α.
Xu [33] further extended the discrete linguistic term set S to a continuous one
The symbol θ
i
(i = 0, 1, …, 2t) represents DMs’ preference with the linguistic items s
i
∈ S (i = 0, 1, …, 2t). In this way, the function can be used to capture the semantics of linguistic terms [34]. The following functions are suitable choices for LSFs.
F1 (s
i
) indicates that the linguistic information based on the scale is divided on average.
F2 (s
i
) indicates that the absolute deviation of two adjacent linguistic subscripts increases with the increase of the linguistic subscript i.
F3 (s
i
) indicates that the absolute deviation of two adjacent linguistic subscripts decreases with the increase of the linguistic subscript i.
F4 (s i ) indicates that the absolute deviation of two adjacent linguistic subscripts increases with the extension from the middle to both ends of the given linguistic term set. Wang et al. [22] stated that a is most likely to be obtained in the interval of [1.36, 1.4].
Assume t = 3 and a = 1.4, the features of formulae (1), (2), (3) and (4) can be graphically shown in Fig. 1.
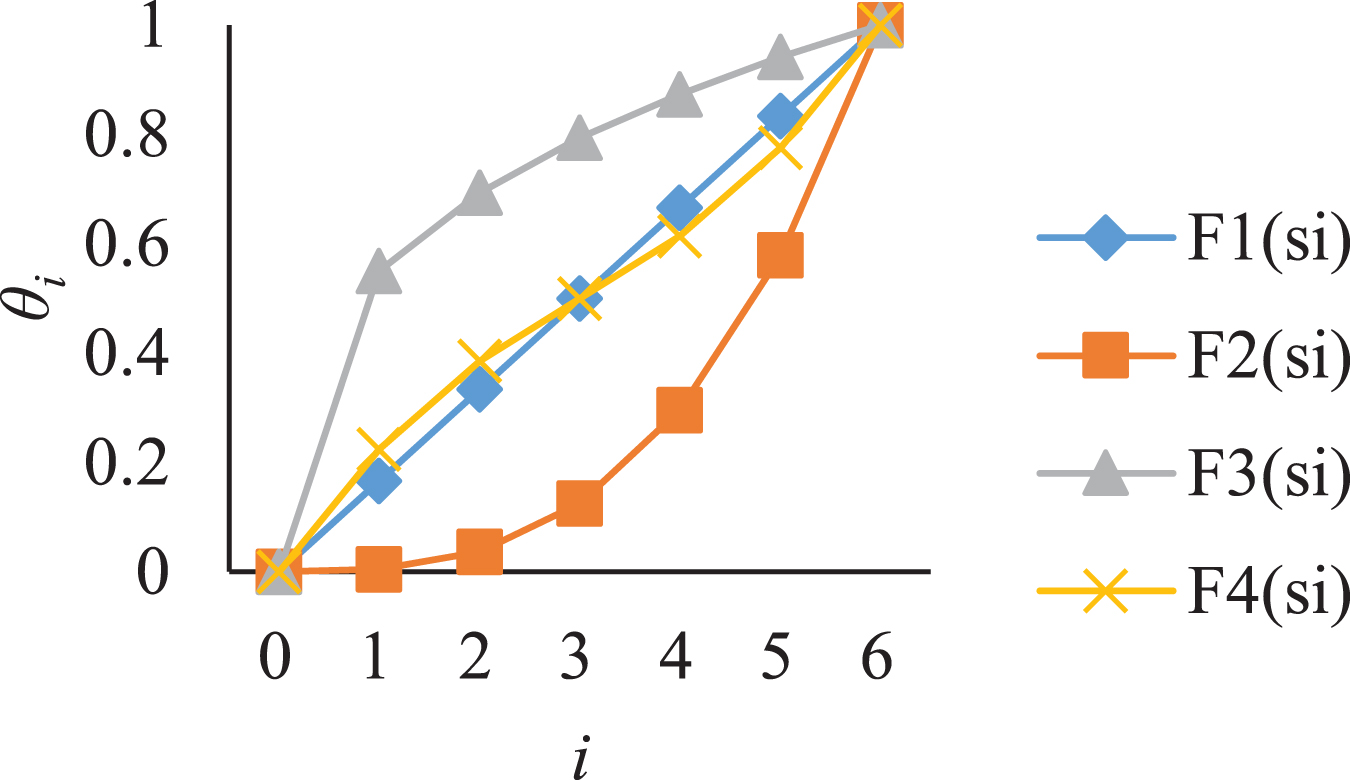
Graphical demonstration of Formulae (1–4).
Furthermore, Wang et al. [21] proposed the concept of LZN on the basis of LSFs [22].
Prospect theory
Prospect theory, originally introduced by Kahneman and Tversky [28], is an effective tool to cope with the DM’s behavior. Kahneman and Tversky [28] presented three behavioral principles in terms of the value function, including diminishing sensitivity, loss aversion and reference dependence. The principles can be portrayed by an asymmetric S-shaped function, as shown in Fig. 2. The value function is expressed as follows:

Value function of prospect theory.
Kahneman and Tversky [28] suggested that α = β = 0.88, λ = 2.25, γ = 0.61 and δ = 0.69 according to the empirical research.
This section introduces the concept of ULZN and presents the definitions of likelihood and diversity for ULZNs. Moreover, some comparison rules for ULZNs are developed.
Uncertain linguistic Z-numbers
Sometimes, people may prefer to express evaluations with interval values that are flexible and convenience [33]. Inspired by the idea of ULVs to capture decision information [35–38], ULVs play a role in restricting the uncertain variables. Thus, the concept of ULZNs is proposed in this subsection.
Likelihood, diversity degree and comparison rules for uncertain linguistic Z-numbers
The likelihood-based method is one of most effective methods to compare any two interval values [39, 40]. A comparison method for ULZNs is developed based on the likelihood of any two interval values.
It is clear that L (z i , z j ) measures the possibility of ULZ z i being greater than z j . Moreover, L (z i , z j ) of ULZs possesses the following properties.
0 ≤ L (z
i
, z
j
) ≤1; L (z
i
, z
i
) =0.5; L (z
i
, z
j
) + L (z
j
, z
i
) =1;
Obviously, Properties (1), (2) and (3) hold. The proof the Property (3) is presented as follows:
(1) Take Case (a) as an example.

Graph representation of interval relation.
b U - a L < 0 ⇒ (b U - a L ) / - (|z i | + |z j |) < 0. Thus, L (z i , z j ) =1. Moreover, because a U - b L > |z i | + |z j |, (a U - b L )/ - (|z i | + |z j |) > 1. Thus, L (z j , z i ) =0. L (z i , z j ) + L (z j , z i ) =1 holds for Case (a).
Similarly, Property (3) holds for other cases. The proof is omitted here.
Based on the likelihood of ULZNs, the following order relationship is presented.
If L (z
i
, z
j
) >0.5, then z
i
is greater than z
j
, denoted by z
i
≻ z
j
. If L (z
i
, z
j
) =0.5, then z
i
is indifferent to z
j
, denoted by z
i
∼ z
j
.
Generally,
Assume that
Particularly, if [a
L
, a
U
] ∩ [b
L
, b
U
] ≠ φ, then
0 ≤ D (z
i
, z
j
) ≤1 (a
U
= b
L
(or b
U
= a
L
) or [a
L
, a
U
] ∩ [b
L
, b
U
] ≠ φ, then D (z
i
, z
j
) =1); D (z
i
, z
j
) = D (z
j
, z
i
).
Property 2 is obvious and the proof is omitted here.
This section develops an extended QUALIFLEX based on the prospect theory to tackle MCDM problems with ULZNs.
For an MCDM problem with ULZNs, let X ={ x1, x2, …, x
m
} be a set of alternatives, C ={ c1, c2, …, c
n
} be a collection of criteria, and w = (w1, w2, …, w
n
) be a set of criteria weight vector, satisfying w
j
∈ [0, 1] and
To solve the above ULZN-based MCDM problem, the following steps are involved and the flowchart of the proposed framework is shown in Fig. 4.

Flowchart of the proposed approach.
The negation operator for linguistic terms is used to normalize ULZNs. The decision matrix Z = [z
ij
] m×n is normalized as follows:
For convenience, the normalized decision matrix is also denoted by
Based on Equations (5 and 6), the likelihood of ULZNs in Equation (7) and the diversity degree of ULZNs in Equation (10) can be used to establish the prospect decision matrix.
Wang [43] first proposed the maximizing deviation method (MDM), which has been widely used to objectively obtain the criteria weights in MCDM. This paper developed an extended MDM to derive criteria weights within the ULZN context as follows:
Model (M-1) can be solved by introducing a Lagrange function. The normalized criteria weight w
j
(j = 1, 2, …, n) of criterion c
j
can be calculated as
List all the possible permutations of the m alternatives. Let P l (l = 1, 2, ⋯ , m !) denote the l-th permutation.
The CI/DI
The comprehensive CI/DI I
l
can be obtained by using Equation (15).
The final ranking of alternatives can be derived using Equation (16).
This section presents an illustrative example concerning the risk assessment of HTPI to validate the feasibility of the proposed approach, followed by sensitivity and comparative analyses.
Considering a risk investment assessment problem, a reasonable indicators evaluation system is the foundation for the risk assessment in the HTPI. Based on the preliminary study [44, 45], the following risk assessment indicator system is constructed, which is suitable for the characteristics of the risk investment projects in China, as shown in Fig. 5.

With the rapid economic growth in China and because of world globalization, market competition is increasingly intense. To stand out in the fierce competition, an increasing number of firms or organizations tend to ask for help from consulting companies. The MP consulting group is a leading consulting company in South China. Its main business includes providing professional decision-making consultation and management consultation. This company would like to invest four potential high-tech projects. They are the mobile communications chip project (x1), intelligent industrial robot project (x2), intelligent transportation project (x3) and low carbon emission technique project (x4). Each project has three possible nature states {good, middle, poor} based on the risk evaluation indicator system shown in Fig. 5. P = (p1, p2, p3) = (0.25, 0.5, 0.25) is the possibility value vector of the nature states.
The DMs comprising the company manager and deputy manager who are responsible for these projects and two foreign experts have been gathered to identify the evaluation information. Moreover, A = {A0, A1, …, A6} = {very poor, poor, slightly poor, fair, slightly good, good, very good} and B = {B0, B1, …, B4} = {uncertain, slightly uncertain, medium, slightly sure, sure} are two linguistic term sets that are used in the evaluation process. For example, through the preliminary process of the information, the DM provides his/her qualitative evaluation on alternative x1 with respect to criterion c1 in nature state P1 as between “slightly good” and “good” and the reliability of this/her evaluation as “slightly sure”. The aforementioned qualitative rating can be expressed as an ULZN
ULZN evaluations in different nature states
ULZN evaluations in different nature states
The main procedures to derive the ranking of all the alternatives are presented.
Since all the criteria are benefit criteria except for the criterion c5, the decision information can be normalized based on Equation (11). Due to the limited space, the normalized decision information is omitted here.
The linguistic functions f* (s i ) = F4 (s i ) and g* (s i ) = F1 (s i ) are used in this example. The values of parameters are set as α = β = 0.88, λ = 2.25, γ = 0.61 and δ = 0.69 according to the experimental data reported in Kahneman and Tversky [28].
When the DM faces a profit situation, π (p1) =0.2907, π (p2) =0.4206 and π (p3) =0.2907 using Equation (12); when the DM faces loss situation, π (p1) =0.2935, π (p2) =0.4540 and π (p3) =0.2935 using Equation (12). Moreover, the prospect decision matrix Φ can be constructed.
Based on Equation (13), the criteria weights can be calculated. W = (0.0118, 0.0731, 0.0657, 0.0423, 0.0799, 0.0802, 0.0815, 0.0685, 0.0988, 0.0813, 0.1012, 0.0287, 0.0692, 0.0423, 0.0755) T .
The twenty four (4!) permutations of four alternatives are listed as follows:
P1 = (x1, x2, x3, x4), P2 = (x1, x2, x4, x3), P3 = (x1, x3, x2, x4), P4 = (x1, x3, x4, x2), P5 = (x1, x4, x2, x3), P6 = (x1, x4, x3, x2), P7 = (x2, x1, x3, x4), P8 = (x2, x1, x4, x3), P9 = (x2, x3, x1, x4), P10 = (x2, x3, x4, x1), P11 = (x2, x4, x1, x3), P12 = (x2, x4, x3, x1), P13 = (x3, x1, x2, x4), P14 = (x3, x1, x4, x2), P15 = (x3, x2, x1, x4), P16 = (x3, x2, x4, x1), P17 = (x3, x4, x1, x2), P18 = (x3, x4, x2, x1), P19 = (x4, x1, x2, x3), P20 = (x4, x1, x3, x2), P21 = (x4, x2, x1, x3), P22 = (x4, x2, x3, x1), P23 = (x4, x3, x1, x2) and P24 = (x4, x3, x2, x1).
Similarly, the other indices can be calculated. I2 = 1.4582, I3 = 2.6155, I4 = 4.5019, I5 = 3.3446, I6 = 4.8664, I7 = -2.0292, I8 = -1.6646, I9 = -3.6301, I10 = -4.8664, I11 = -2.9010, I12 = -4.5019, I13 = 1.0146, I14 = 2.9010, I15 = -2.9010, I16 = -3.3446, I17 = 1.6646, I18 = -1.4582, I19 = 2.1082, I20 = 3.6301, I21 = -1.0146, I22 = -2.6155, I23 = 2.0292 and I24 = -1.0936.
Use Equation (16) to obtain the optimal permutation and derive the best ranking of alternatives.
Sensitivity analysis
Sensitivity analysis was conducted to test the influence of LSFs on the ranking of alternatives. Sixteen experiments were performed, and results are shown in Fig. 6.
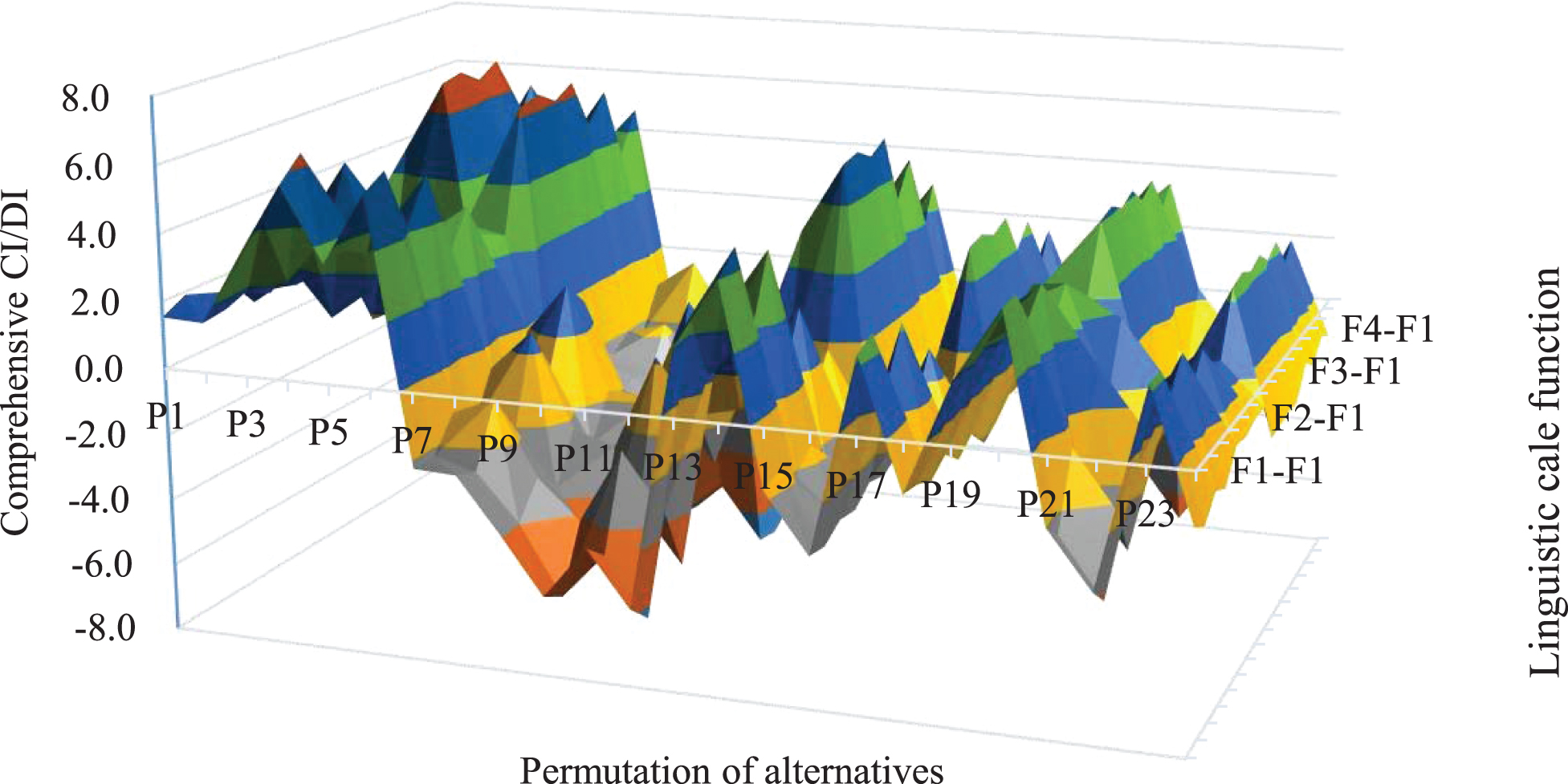
Permutations of alternatives with different LSFs.
The ranking result of four alternatives is generally consistent. When f* (s i ) = F2 (s i ) and g* (s i ) = F1 (s i ), f* (s i ) = F2 (s i ) and g* (s i ) = F3 (s i ) or f* (s i ) = F2 (s i ) and g* (s i ) = F4 (s i ), the optimal permutation of alternatives is P5, where the corresponding ranking order of the alternatives is x1 ≻ x4 ≻ x2 ≻ x3; when f* (s i ) = F1 (s i ) and g* (s i ) = F3 (s i ), f* (s i ) = F2 (s i ) and g* (s i ) = F2 (s i ), f* (s i ) = F4 (s i ) and g* (s i ) = F1 (s i ), f* (s i ) = F4 (s i ) and g* (s i ) = F3 (s i ) or f* (s i ) = F4 (s i ) and g* (s i ) = F4 (s i ), the optimal permutation of alternatives is P6, where the corresponding ranking order of the alternatives is x1 ≻ x4 ≻ x3 ≻ x2; regarding other situations, the optimal permutation of alternatives is P4, where the corresponding ranking of alternatives is x1 ≻ x3 ≻ x4 ≻ x2. The ranking sequence of alternatives x2, x3 and x4 is inconsistent using different LSFs, however, the best alternative is always x1. As we known, an ULZN comprises A and B components. The two parts of ULZNs can be processed through different LSFs because they represent evaluation preferences on different aspects. Using different LSFs to manage the first component of an ULZN can emphasize the DM’s preference when providing the rating on external things. Using different LSFs to address the second component of an ULZN can emphasize the DM’s confidence degree in the assessments. Since LSFs can portray different semantics, as introduced in Subsection 2.1, DMs can flexibly choose the LSFs according to the practical situations. For example, if the DM wants to strengthen the positive impact on the reliability, the LSF g* (s i ) = F4 (s i ) is a good choice. By contrast, the LSF g* (s i ) = F2 (s i ) can be selected.
Comparative analysis was conducted to verify the result yielded by the proposed approach based on the same illustrative example.
Yaakob and Gegov [13]’s method was used to determine the ranking of alternatives. The fuzzy TOPSIS method was employed to rank all the alternatives. The corresponding closeness coefficients of each alternative were cc1 = 0.4787, cc2 = 0.4766, cc3 = 0.4426 and cc4 = 0.4410.
Wang et al. [21]’s method was employed to obtain the ranking order of alternatives. According to the LZN-based TODIM, the overall prospect values of each alternative were Φ (x1) =1, Φ (x2) =0.8661, Φ (x3) =0 and Φ (x4) =0.4529.
The ranking orders of alternatives yielded by different approaches are presented in Table 2 (f* (s i ) = F4 (s i ) and g* (s i ) = F1 (s i )). There is a slight difference in the result. The best alternative is the same using the three methods; however, the order of alternatives x2, x3 and x4 yielded by the other two methods is different from that of the proposed approach. The main reason can be explained in two aspects. First, the proposed approach not only considers the DM’s behavior in the MCDM problem but also allows the incomplete compensation among criteria; thus, it can produce more suitable decision results in line with real-world decision-making situations. Second, the inherit characteristics of the proposed approach are different from the LZN-based TODIM. Compared with the other two methods, the proposed approach has the following advantages.
Rankings of alternatives with different methods
Rankings of alternatives with different methods
The proposed approach employs LSFs to process ULZNs, making it straightforward and easy to use. Moreover, it is flexible for DMs to choose appropriate LSFs according to practical decision situations. Generally, f* (s
i
) = F4 (s
i
) and g* (s
i
) = F1 (s
i
) can be used. Although transforming Z-numbers into trapezoidal fuzzy numbers can indeed avoid the tedious calculations [13], it will cause the loss and distortion of the original evaluation. In the proposed approach, the criteria weights are objectively obtained based on the MDM, effectively avoiding subjective randomness. However, the exact criteria weights should be provided in advance in the other two methods. The proposed ULZN-based QUALIFLEX belongs to the system of the outranking method. It is appropriate to tackle MCDM problems, in which the criteria are incompletely compensable. However, the other two methods do not have this outstanding characteristic. The proposed ULZN-based QUALIFLEX is based on prospect theory, considering the DM’s behavior. However, the fuzzy TOPSIS [13] is based on the assumption that DMs are completely rational. Thus, it fails to consider the DM’s behavior in actual MCDM.
ULZNs can flexibly describe qualitative information as well as its reliability. The QUALIFLEX is one of the most mature outranking approaches to manage MCDM problems because of its excellent characteristics. Nevertheless, it fails to deal with MCDM problems, where the DMs are bounded rational. In this regard, this paper develops a prospect theory-based QUALIFLEX method to cope with MCDM problems with ULZNs, in which the criteria weights are completely unknown. An illustrative example concerning a risk assessment of HTPI is provided to demonstrate the application of the developed approach. Sensitivity and comparative analysis are implemented to validate the priorities of the proposed approach. The result shows that the proposed approach is effective and considers the DM’s behavior simultaneously. Furthermore, the developed approach can employ different LSFs to process ULZNs according to the semantics of DMs and further enhance the reliability and flexibility of the decision processes.
There are some limitations in this study. For example, the proposed approach is unsuitable to solve MCDM problems with many alternatives. Moreover, identifying the exact values of parameters needs to cautiously consider the practical decision situations. In future studies, ULZN-based outranking methods, such as ORESTE [6] and ELECTRE III [14] can be developed. The developed approach can be applied to cope with other similar MCDM problems, such as renewable energy selection [17] and hotel selection [46].
Footnotes
Acknowledgments
The authors are very grateful to the anonymous reviewers for their valuable comments and suggestions to help improve the overall quality of this paper. This work was supported by the National Natural Science Foundation of China (Nos. 71871228, 71571193).