
Abstract
Group multi-criteria decision-making (GMCDM) is an important part of decision theory, which is aimed to assess alternatives according to multiple criteria by collecting the wisdom of experts. However, in the process of evaluating, because of the limitation of human knowledge and the complexity of problems, an efficient GMCDM approach under uncertain environment still need to be further explored. Thus, in this paper, a novel GMCDM approach with linguistic Z-numbers based on TOPSIS and Choquet integral is proposed. Firstly, since linguistic Z-numbers performs better in coping with uncertain information, it is used to express the evaluation information. Secondly, TOPSIS, one of the most useful and systematic multi-criteria decision-making (MCDM) method, is adopted as the framework of the proposed approach. Thirdly, frequently it exists interaction between criteria, so Choquet integral is introduced to capture this kind of influence. What’s more, viewing that decision makers (DMs) show different preferences for uncertainty, the risk preference is regarded as a vital parameter when calculating the score of linguistic Z-numbers. An application in supplier selection is illustrated to demonstrate the effectiveness of the proposed approach. Finally, a further comparison and discussion of the proposed GMCDM method is given.
Keywords
Introduction
Group multi-criteria decision-making (GMCDM) quite prevails in real life. Decisions will be taken after evaluating, ranking and selecting a number of alternatives with respect to multiple criteria by a group of decision makers (DMs). Amounts of scientific and systematic techniques have been researched to deal with this kind of problem, like TOPSIS [1] and ELECTRE [2]. They are broadly applied in many fields, like supplier selection [3], workflow scheduling [4], preventive maintenance planning [5], etc. The technique for the order of preference by similarity to ideal solution (TOPSIS) has addressed lots of attentions in recent years. Its key idea is that the ranking of alternatives is based on the shortest distance from the positive ideal solution (PIS) and the farthest from the negative ideal solution (NIS), which comprehensively considers the distances to PIS and NIS. The PIS maximizes the benefit attributes and minimizes the cost attributes, whereas the NIS maximizes the cost attributes and minimizes the benefit attributes. We recommend literature [1] for further details about TOPSIS.
However, because of the limitation of human knowledge and complexity of problem, the evaluation information provided by DMs often contains uncertainties, like fuzziness, ambiguity and imprecision [6–8]. Therefore, it is a valuable research point about how to develop an efficient decision-making method under uncertain environment. There have been numerous proposed techniques to cope with uncertain information, like fuzzy sets (FS) [9], D numbers [10], Z-numbers [11, 12], soft sets [13] and belief structure [14, 15]. What’s more, the method of TOPSIS has been combined with some of them, such as intuitionistic fuzzy sets (IFS) [16] and linguistic pythagorean fuzzy Sets (LIFS) [17]. One of defects of them is that the creditability of the collected information doesn’t take into consideration. In this paper, we mainly concentrate on the concept called linguistic Z-numbers. Through careful study of advantages of linguistic Z-numbers, it can be found that linguistic Z-numbers have stronger capability to express and deal with uncertain information. On the one hand, as a linguistic variable, natural language is used to represent evaluation information, which is more consistent with human cognition. On the other hand, Z-numbers are capable of capturing the information related to evaluation and reliability simultaneously. The reason is that they are composed of two components, the first component is a restriction on the values which the uncertain variable can take, and the second component reflects the reliability for the first component. They have already been used with other models and resulted in very good effects, including Bayesian Network [18] and evidence theory [19, 20].
The GMCDM approach with linguistic Z-numbers still exists some spaces to improve. Firstly, most GMCDM methods are developed based on the assumption that criteria do not interact with each other, evidently, this condition is hard to be satisfied in the real life. To address this issue, Sugeno introduced the concept of fuzzy measure into reflecting the relationship between criteria, where additivity property is replaced by only a monotonicity [21]. Based on it, Choquet integral was proposed by Murofushi and Sugeno, which applies fuzzy measure to represent the weights of criteria [22]. Hense, Choquet integral can better handle the influence between criteria. Secondly, it is the fact that DMs show different preferences for uncertainty because of the divergence in environment, experiences and characters [23]. In the process of decision-making, even though the provided evaluations are same, willingness of adopting the alternative will be various with the tolerance to uncertainty [24–26]. As a result, it is necessary to consider the risk preference to make the decision results more consistent with the very thoughts of DMs. The mechanism that risk preference affects decision making carries out as follows. For the hesitant evaluations, risk-seeking DMs prefer for higher value as to adopt the alternative, while risk-averse DMs are willing to give lower values. The risk-averse one would give up the alternative rather than adopting in order to avoid risk. Motivated by it, risk preference is regarded as an important factor when calculating the scores of linguistic Z-numbers.
Therefore, a novel GMCDM approach with regard to linguistic Z-numbers based on Choquet integral and TOPSIS is proposed. TOPSIS, as a typical MCDM method, provides us a practical framework for decision-making method under uncertain environment. Additionally, as for the representation of evaluation information, we not only utilize linguistic Z-numbers to better characterize the uncertainty of cognitive information, but also take into account risk preference of DMs. Also, the technique of Choquet integral is used to solve the problem caused by interaction between alternatives. Contributions of this study are listed as follows:
(1) A GMCDM approach with linguistic Z-numbers under uncertain environment is proposed, which combines advantages of Choquet integral and TOPSIS.
(2) A novel method of ranking linguistic Z-numbers is put forward, where the risk preference is considered as an important factor.
(3) We intend to solve some practical GMCDM problems to verify the effectiveness and practicality of the presented approach.
This paper is organized as follows. Some basic concepts are introduced in Section 2. Next, a GMCDM approach with linguistic Z-numbers based on Choquet integral and TOPSIS is presented in Section 3. Then, Section 4 applies the methodology into the field of supplier selection to indicate its effectiveness. Furthermore, some comparisons and discussion are shown in Section 5. Finally, Section 6 briefly summarizes some conclusions.
Preliminaries
Fuzzy set
Uncertainty is unavoidable in the real word [27–29]. To handle this kind of problem, amount of methods have been proposed, such as D-S theory [30–32], evidential reasoning [33, 34], belief rule-based [35, 36], etc. Because of their capabilities to handle the uncertainty, they have been widely applied in various fields, including classification [37–39], decision making [40–43], fusion [44, 45], medical diagnosis [46, 47] and industrial alarm systems [48].
As a very popular tool to model vague or imprecise information, fuzzy set (FS) has been applied in a variety of fields. It has been extended into many forms like interval-valued fuzzy sets [49, 50], intuitionistic fuzzy sets (IFS) [51–53] and pythagorean fuzzy set (PFS) [54–57]. They could handle uncertainties with more powerful capabilities. Some basic concepts of FS are introduced in the following:
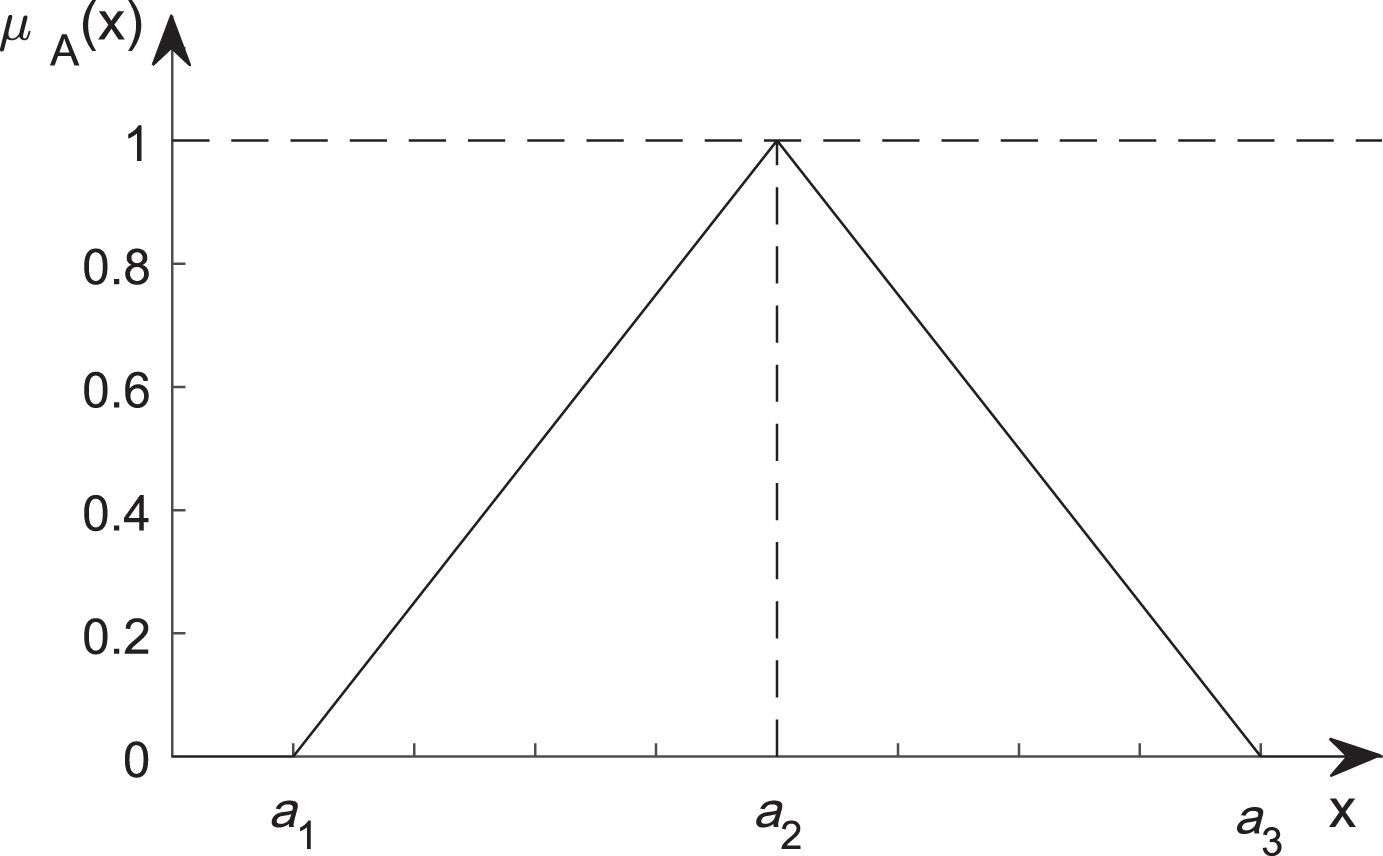
A triangular fuzzy number.
Z-numbers
DMs have different knowledge, experiences and backgrounds, and cognitive information provided by DMs is often uncertain, imprecise and/or incomplete. Hence, the reliability of information is an vital factor in the process of decision making. On the purpose of formalizing this capability, Zadeh proposed the concept called Z-numbers. Here are some basic definitions.
Typically, the two components of Z-number are described in natural language. For example, the phrase "Usually, it takes me about 3 hours to get home from work" can be expressed as a Z-number: (about 3 hours, usually).
Linguistic variable
It is often difficult for DMs to give the numerical evaluation, especially for the qualitative data. The type of numeric is far from human cognitive process. To cope with this problem, the concept of linguistic variable is proposed, whose values are words or sentences in a natural or artificial language rather than numbers. It provides a means of approximate characterization of uncertain phenomena.
Let S = {s i |i = 1, 2, …, T} be a totally ordered discrete linguistic term set, where s i represents the ith linguistic variable, T denotes the cardinality of S and s i < s j if i < j.
Linguistic Z-numbers
The concept of linguistic Z-numbers was proposed by Wang et al. [63], with construction of two components, it has more efficiency to express uncertain evaluation information.
Choquet integral
Fuzzy measure
It is a common phenomenon that the criteria are interactive and will affect each other. Fuzzy measure also called non-additivity measure was introduced by Sugeno in 1974. It is an effective framework to model the weights of dependent criteria, which makes a monotonicity instead of additivity property. Many fuzzy measures have been researched including the λ-fuzzy measure, k-additive fuzzy measure [64], etc, which are suitable for different situations.
(1) μ (∅) =0, μ (X) =1 ;
(2) If C, D ∈ P (X) and C ⊆ D, then μ (C) < μ (D).
If X is a finite set,
The value of parameter λ reflects the interaction relationship between different subsets. Since μ (X) =1, the value of λ can be computed by solving the equation:
As for the aggregation operators including ordered weighted averaging (OWA) operator and weighted arithmetic mean, the basis of them is the assumption that the criteria are independent from one another. However, it doesn’t apply for the real world. The Choquet integral makes it possible for aggregating data where the criteria are interactive. A fuzzy measure is used to represent the weight on each combination of criteria. The definition of the Choquet integral is described as follows.
It can be seen that the discrete Choquet integral is a linear expression and relevant to the ordering of elements. In some condition, it will coincide with the OWA operator and could be degenerated to the weighted mean if the fuzzy measure is additive.
In this section, a GMCDM approach under uncertain environment is proposed within the framework of TOPSIS, which combines both the advantages of linguistic Z-numbers and Choquet integral. The reliability of information and interaction among criteria are both taken into consideration. Moveover, the attitude towards risk is also a factor when calculating the score of linguistic Z-numbers.
For a GMCDM problem with linguistic Z-numbers, let a = {a1, a2, …, a
m
} be a discrete set of alternatives and c = {c1, c2, …, c
n
} be a collection of criteria. Assume that there are K DMs in the decision group, D
k
= [z
k
ij
] m×n = [(A
k
φ
ij
, B
k
φ
ij
)] m×n is the decision-making matrix. The linguistic Z-numbers are (A
k
φ
ij
, B
k
φ
ij
), which represent the evaluation information of alternative a
i
(i = 1, 2, ⋯ , m) under criteria c
j
(j = 1, 2, ⋯ , n) given by DM
k
. Let
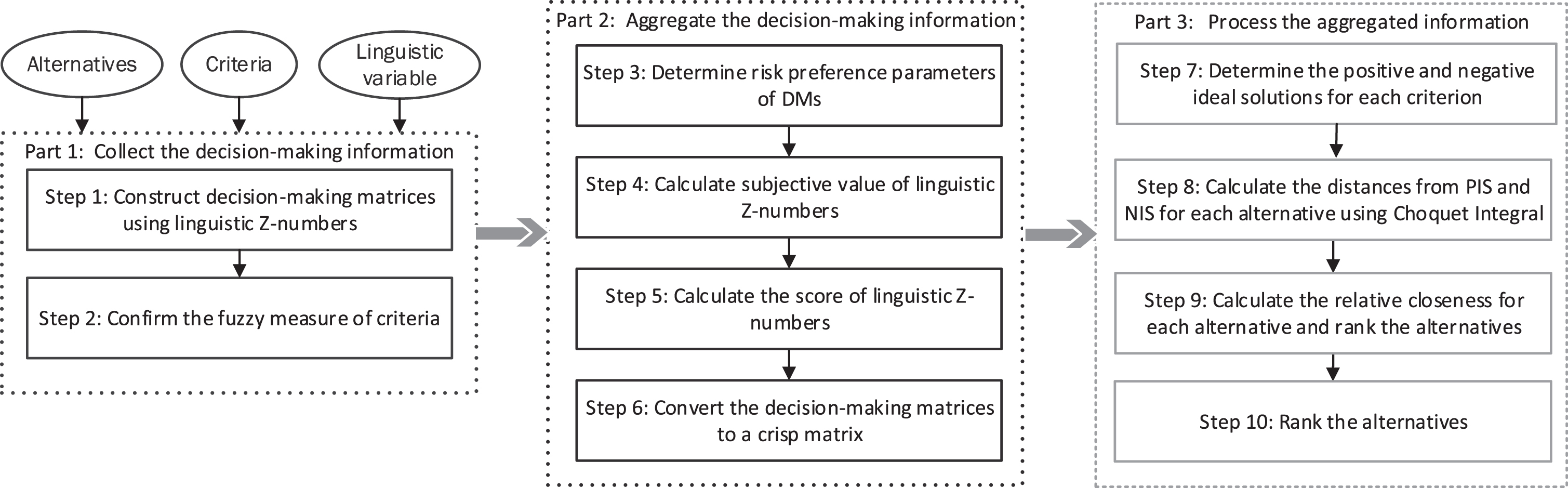
The flow chart of the proposed method.
This part begins with collecting decision-making information from DMs with regard to alternatives and criteria.
Step 1: Construct a decision-making matrix by assessing alternatives with regard to different criteria using linguistic Z-numbers.
Then the assessment matrix given by the k
th
DM can be constructed as follows:
Step 2: Confirm the fuzzy measure of criteria.
In the process of decision-making, the fuzzy density μ (c j ) of criteria c j can be given by DMs. According to Eq. (6), the parameter λ can be determined, then the fuzzy measure μ can be obtained based on Eq. (4).
Aggregating the decision-making information
This part aims at aggregating the obtained linguistic Z-numbers.
Step 3: Determine risk preference parameters of DMs.
The preferences of DMs play an important role in the process of decision-making. Under uncertain situation, different choices will be provided by DMs with various preferences for risk. The risk preference parameter (RPP) is used to identify the degree of the preference for risk, which is defined as follows:
The expert is risk-averse, when 0 ⩽ α < 0.5;
The expert is risk neutral, when α = 0.5;
The expert is risk-seeking, when 0.5 < α ⩽ 1.
The risk-averse one is willing to adopt higher value among hesitations, while risk-seeking one would adopt smaller value among hesitations. There are many tools to determine the degree of preference for risk [65]. Additionally, as the value of α becomes higher, the degree of preference for risk is increasing. Conversely, as the value of α becomes smaller, the degree of aversion for risk is increasing.
Step 4: Calculate the subjective value of linguistic Z-numbers.
Here we make a distinction between objective and subjective value of linguistic Z-numbers. The score of linguistic Z-numbers without consideration of risk preference could be viewed as objective information, sicne personal emotion or preference isn’t involved. Nevertheless, there is still a gab from the very thought of DMs. Thus, subjective value further considers the risk preference of DMs on the basis of objective value. RPP is used to obtain the subjective value of linguistic Z-numbers.
where n is the cardinality of the linguistic term set A. The function f (x) can be calculated by Eq. (3), which is the score of the fuzzy number.
It is overt that w- + w + w+ = 1. f (B j ) means the certainty degree to the evaluation value A i , then 1 - f (B j ) represents the hesitation or uncertainty degree to other evaluation values. Since the RPP is α, the hesitant degree w+ = α (1 - f (B j )) is assigned to higher evaluation value Ai+1, and the hesitant degree w- = (1 - α) (1 - f (B j )) is assigned to lower evaluation Ai-1. f (B j ) × f (A i ) can be regarded as the objective value of linguistic Z-numbers. In addition, subjective value S (Z) will be obtained under the guidance of RPP.
Step 5: Calculate the score of linguistic Z-numbers.
Generally, we are desirable for more certain or reliable information in real-life decision making. Thus to reduce the dependence on the subjective values, the certainty degree f (B j ) is used to modify the subjective value of linguistic Z-numbers.
Here we give some propositions:
Suppose
If i = 1, then
Assume the obtained RPP for k
th
DM is α
k
. According to above-mentioned ranking method, the scores of linguistic Z-numbers provided by k
th
DM will be calculated, which are denoted as follows:
Step 6: Convert the decision-making matrices to a crisp matrix.
The aggregated rating of alternative a
i
with respect to criterion c
j
can be calculated on the basis of Eq. (10).
In this part, decisions will be taken after processing the aggregated information.
Step 7: Determine the positive and negative ideal solutions respectively for each criterion.
Since all the criteria could be seen as benifit criteria, the positive ideal solution (PIS) denoted as V+ and the negative ideal solution (NIS) represented by V- are defined as follows:
Step 8: Calculate the distances from PIS and NIS for each alternative using Choquet integral.
The distance between each alternative and PIS could be obtained by the following equation:
The distance between the alternative and NIS can be calculated as follows:
Step 9: Calculate the relative closeness for each alternative.
According to the ideal solutions, the expression of relative closeness denoted as r
i
is given by:
Step 10: Rank the alternatives.
The best alternative has higher value of relative closeness, because it is relatively further from the NIS.
In this section, an application is given to illustrate the effectiveness of the proposed GMCDM approach.
In recent years, the competition between enterprises is serious. Therefore, understanding how to select an appropriate supplier based on both information of the enterprise itself and the supplier is particularly important for entrepreneur. However, the information between the two sides is frequently asymmetry, DMs couldn’t provide precise evaluation on some criteria, which can be considered as an uncertain GMCDM problem. In this process, ensuring the rationality and efficiency of the evaluating method is vital. Currently, an enterprise desires to select a suitable supplier among five alternatives. These five suppliers are a1, a2, a3, a4 and a5. Many factors are involved in supplier evaluation, and four main factors are considered, which are shown in Table 1.
The criteria for evaluating the suppliers
The criteria for evaluating the suppliers
In this study, DMs use linguistic variables in Table 2 to evaluate the rating of supplier with respect to each criterion and use information in Table 3 to express the certainty degree of DMs to the evaluation. Suppose there are three DMs in the decision-making group.
Linguistic variables for the rating of all alternatives
Linguistic variables for the certainty degree of decision makers
Step 1: Construct a decision-making matrix by assessing alternatives using linguistic Z-numbers.
The decision-making matrices built by DMs are listed in Table 4.
Decision-making matrices of decision makers
Step 2: Obtain the fuzzy measure of criteria.
Suppose that the fuzzy density of criteria are obtained according to DMs. They are μ (c1) =0.4, μ (c2) =0.27, μ (c3) =0.35, μ (c4) =0.3. λ = -0.58 is calculated based on Eq. (6). Then the fuzzy measure of the combination of criteria can be determined as shown in Table 5 on the basis of Eq. (4).
The fuzzy measure of criteria
Step 3: Determine the RPP of DMs.
Assume the RPPs of the three DMs are 0.3, 0.5, 0.7 respectively.
Step 4: Calculate the subjective value of linguistic Z-numbers.
Take
Step 5: Compute the score of linguistic Z-numbers.
Following above three steps, the scores of Z-numbers can be obtained, which are described in Table 6.
Score Matrices of decision makers
For
Step 6: Convert the decision-making matrices to a crisp matrix.
Crisp matrix will be calculated with aggregation of evaluations provided by DMs according to Eq. (10). The followings are the results.
Step 7: Determine the positive and negative ideal solutions respectively for each criterion.
According to Eqs. (11) and (12), the PIS and NIS are defined as follows.
Step 8: Calculate the distances from PIS and NIS for each alternative using the Choquet integral.
The results are shown in Table 7 based on Eqs. (13) and (14).
The distance to ideal solution and the obtained relative closeness
Step 9: Compute the relative closeness for each alternative.
The values of relative closeness are also listed in Table 7 in accordance with Eq. (15).
Step 10: Order the alternatives.
Following these steps, the final ranking of alternatives is a4 ≻ a3 ≻ a2 ≻ a5 ≻ a1. Therefore, the supplier a4 is the satisfactory one.
Comparison of the proposed ranking method with previous methods
Some different ranking methods of linguistic Z-numbers have been investigated in recent years. After careful research, we found that the method in [66] takes into account DM’s optimistic or pessimistic attitude towards the provided linguistic Z-numbers. Such attitude is a kind of hesitation about increasing or decreasing the provided evaluation value. In addition, the methods in [67] and [68] do not involve the attitude of DMs. Hence, we focus on comparing the proposed method with the methods in [66, 67] and [68] to show the advantages of our ranking method.
Suppose
Linguistic variables for the first component of Z-numbers
Linguistic variables for the first component of Z-numbers
Linguistic variables for the second component of Z-numbers
Results of different ranking methods of Z-numbers
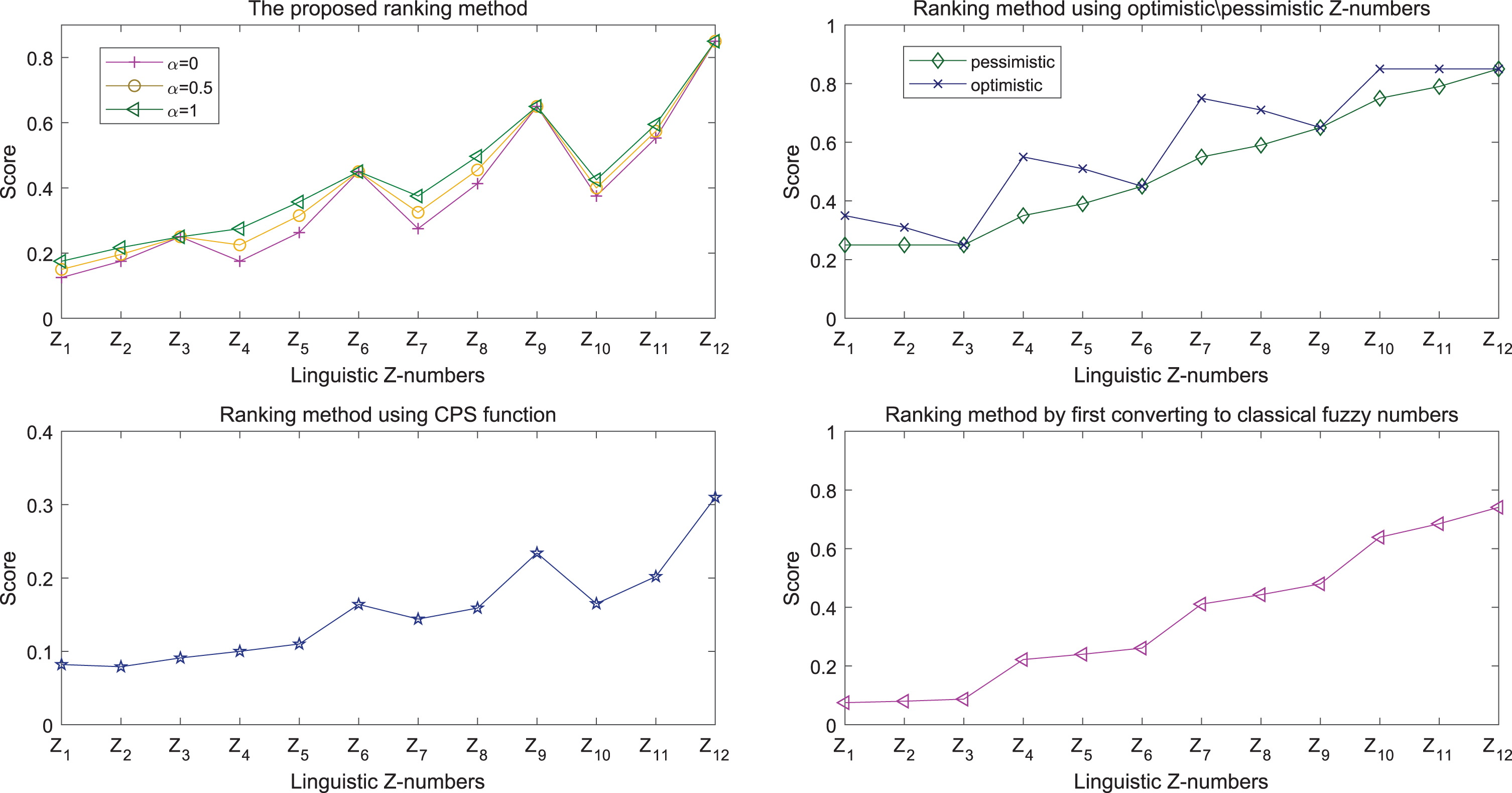
The results of different ranking methods.
It can be seen that the final score will get higher, as the evaluation value and reliability of linguistic Z-number increase. However, on the one hand, all these methods ignore the DM’s preference for risk. In [67] and [68], the score will be determined once the linguistic Z-number is given. Although the attitude of DMs is considered in [66], only two choices are provided, which are to increase or to decrease the evaluation value. The degree of increase or decrease is not taken into account. In our proposed method, we have quantified the risk preference of DMs, so that the score of Z-numbers will vary with the risk preference. On the other hand, with the exception of the proposed method, the factor of evaluation value makes a dominated contribution comparing with the impact of reliability, in the process of calculating the score of linguistic Z-numbers. The score of the linguistic Z-numbers with bigger evaluation value is higher than the one with smaller evaluation value. In our proposed method, both factors play an important role. Take Z3 and Z4 for example, although Z4 has a higher evaluation value (Medium) than Z3 (Low), but because the reliability of Z4 (Not sure) is too lower than Z3 (Very sure), its score may be lower than Z3.
We further discuss the proposed ranking method.
(1) Giving the situation that the values of linguistic Z-numbers are equal, but the risk preferences of DMs are different. According to the method, it is evident that the greater the degree of preference for risk, the higher the scores of linguistic Z-numbers. Additionally, when DMs are very confident about their evaluations, meaning the second component of linguistic Z-numbers is B3, the scores are same even though the risk preferences are various. This is consistent with reality.
(2) Considering the situation that the risk preferences are same but different linguistic Z-numbers are given. Under this case, it can be seen that if linguistic Z-numbers have higher evaluations and reliability, then higher scores it would be obtained. In a word, both the two parts of linguistic Z-numbers and risk preference will determine the final scores.
(3) The divergence of scores under different risk preferences is not same when evaluations are different. The results indicate that the variation range of scores on different risk preference is small, when the evaluation value is the minimum or maximum. It is because there aren’t any worse evaluations than minimum or better evaluations than maximum. This is in line with the human decision-making process.
(4) On the whole, the ranking results under different preferences for risk are basically the same. This shows risk preferences have slight impacts on the final ranking results. Appearance of this phenomenon is also reasonable.
We further develop quantitative and qualitative comparison of the advantages of the proposed MCDM method.
Results from quantitative comparison are listed in Table 11, to show the features of different related methods. In [63], though the interaction of criteria is taken into consideration, Z-numbers are represented by real numbers to simplify the computation. While the approaches in [68] and [66] work out on the hypothesis that criteria are independent. They utilize the weighted mean to obtain the score with regard to the weight of individual criterion. Literature [66] enables DMs to offer their attitude towards the evaluations given by them. Nevertheless, it may be hard for DMs in hesitate state to determine whether to increase or decrease the evaluation value. Furthermore, all the results can’t reflect the risk preferences of DMs. As a contrast, our approach copes with these problems well, since we make good use of the technique of Choquet integral and risk preferences. The problem that the criteria are interactive is solved by Choquet integral. In addition, the risk preferences will have a certain impact on the final score of linguistic Z-numbers.
Comparison results of different MCDM approaches with linguistic Z-numbers
Comparison results of different MCDM approaches with linguistic Z-numbers
An experimental analysis has been shown to demonstrate the rationality and efficiency of the proposed MCDM method. The brief introduction of the data source is described as follows. The evaluation data is obtained form DM1 in Table 4. In addition, the weights of criteria are the same as the corresponding part in section 4. For the proposed method and method in [66] and [68], the two parts of linguistic Z-numbers are represented by fuzzy numbers shown in Tables 2 and 3. As for the method in [63], the two parts of linguistic Z-numbers are converted to real numbers by linguistic numerical scale models. Suppose the fist part is determined by function f* (θ i ) = F4 (θ i ) (a = 1.4), and the second will the obtained by g* (θ i ) = F1 (θ i ) according to the literature [63]. The ranking results are shown in Table 12 and Fig. 4.
The results of different MCDM method
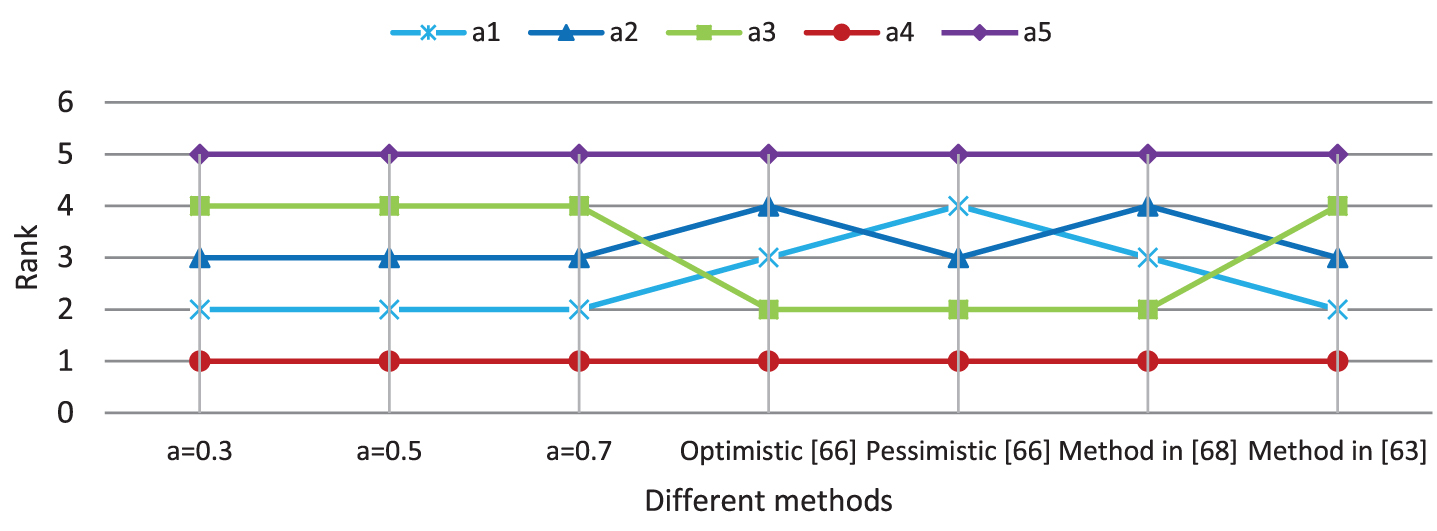
The results of different MCDM approaches.
It can be found that these methods reach an agreement on the best alternative and the worst one, which are alternative a4 and a5. However, when it comes to the rank of other alternatives, there are different opinions, especially for alternatives a1 and a3. According to the proposed method, the ranking results are consistent under different preferences for risk. The proposed method and the method in [63] believe that a1 is better than a3. On the contrary, other methods hold opposite view. The main reason lies on whether a1 performs better than a3 with respect to c2. Since the reliability degree of a1 is higher than alternative a3 and the distance between evaluation values of a1 and a3 is small, more scores are allocated to a3 with regard to c2 in the proposed method. It is obvious that a1 dominates a3 for criterion c1 and is dominated by a3 for criteria c3 and c4. Additionally, criteria c1 and c2 are more important than c3 and c4 based on given fuzzy measure. As a consequence, more scores are signed to a1. Therefore, the proposed method is more reasonable.
GMCDM problems have addressed a lot of attentions in recent years. One of the points worth exploring is how to handle uncertainty in the process of decision-making. In this paper, a novel GMCDM approach with linguistic Z-numbers based on Choquet integral and TOPSIS is introduced. It takes advantages of linguistic Z-numbers and Choquet integral under the framework of TOPSIS. As a tool for modeling cognitive information, linguistic Z-numbers can well represent the cognitive information from aspects of evaluation values and reliability. In addition, the Choquet integral, as an aggregation operator, can facilitate addressing the issue that the criteria influence each other. What’s more, the risk preference of DMs is considered to provide an appropriate method to rank linguistic Z-numbers. In a word, the proposed TOPSIS-based method has more efficiency under uncertain environment. In the future work, one possible work is combining linguistic Z-numbers with some extensions of fuzzy sets, like Pythagorean fuzzy set and qrung orthopair fuzzy set, to solve more complex and practical decision-making problems.
Footnotes
Acknowledgment
The authors greatly appreciate the reviews’ suggestions and the editor’s encouragement. This research is supported by the Research Project of Education and Teaching Reform in Southwest University (No. 2019JY053), Fundamental Research Funds for the Central Universities (No. XDJK2019C085) and Chongqing Overseas Scholars Innovation Program (No. cx2018077).