
Abstract
A normal human brain holds a high level of bilateral reflection symmetry. On the sagittal view, the brain can be separated into the left and the right hemispheres with approximately identical anatomical properties, so that symmetrical mirror pixels are almost similar. As a result, the symmetry information can be used to enhance results of brain segmentation methods. In this paper, I introduced a new version of the Fuzzy C-Mean (FCM) segmentation method which is called Genetic Spatial Possibilistic Fuzzy C-Mean (GSPFCM). GSPFCM integrates symmetry information with SPFCM. It is an extension of Possibilistic Fuzzy C-Mean (PFCM) on 3D Magnetic Resonance (MR) images. GSPFCM uses the spatial information and fuzzy membership values. Spatial and possibilistic information were added in order to solve the noise sensibility defect of FCM. To integrate the symmetry information, I first extracted the Mid-Sagittal Surface using a proposed genetic algorithm. According to this algorithm, inside each axial slice, a Thin-Plate Spline (TPS) surface was constructed and a genetic algorithm was applied to fit this TPS surface to the brain data. Then, the symmetry degree of each symmetry pair voxels was calculated. Finally, the membership values in SPFCM were updated based on the corresponding symmetrical values. The efficiency of GSPFCM, was evaluated using both simulated and real Magnetic Resonance Images (MRI), and was compared to the state-of-the-art methods. My results showed images with different degrees of Intensity Non-Uniformity (INU) and different levels of noise were segmented efficiently by the GSPFCM.
Keywords
Introduction
Image segmentation is an important step in image analysis. From all types of image-segmentation methods, Fuzzy C-Mean (FCM) clustering algorithm is a rather old method, which has been commonly used in image segmentation [3]. FCM is a cluster-based segmentation method. It assigns voxels in an image to different classes according to the distance of their features with the classes [3, 4]. Nevertheless, this method suffers from a number of problems; Noise sensitiveness [5], use of Euclidian distance as the similarity criterion of data points which leads to a limitation of equal partition trend for datasets [6], and high-time complexity are the main problems of conventional FCM [7_ENREF_7]. A large number of researches have been conducted to overcome these problems. These endeavors mostly include updating the objective function of FCM, or adding some terms to this function. The involved information for this purpose includes spatial information [5], grey information [7], cluster density [6], belief concept [8], and symmetry information [4].
When a data element is very far from the fuzzy centroids, for example a noise, FCM classifies this data to the nearest class, based on the distance between this data value and the centroids of the classes. Also, the centroids are updated so that they get nearer to this noisy data. It means the next data are classified based on the centroids being influenced by a noisy value, which leads to a less accurate classification result. A possibi1istic concept is used to face this problem; in a classifier using possibi1istic values, membership value of a data in a cluster (or class) represents the typicality of the voxel in the class, or the possibility of the voxel belonging to the class [9]. Possibi1istic C-Mean (PCM) assigns data values into different classes according to their possibi1istic values. PCM solves the noise sensibility defect of FCM, but it suffers from the coincident cluster problem [10]. A classifier which works using a combination of fuzzy membership values and possibilistic values seems to be a more practical classifier. In [10], Pal et al. proposed Fuzzy PCM. FPCM is a combination of relative (or membership) and absolute typicalities (or possibilities). Pal et al. improved their method by adding a new penalty to the objective function in order to suppress the noise affects. The new method was called PFCM [11].
On the other hand, a normal human brain holds a high level of bilateral reflection symmetry; a highly convolved brain can be separated into the left and the right hemispheres by the Inter-hemispheric Fissure (IF), or the longitudinal fissure, which is a long and deep furrow (see Fig. 1). Corresponding regions of two hemispheres have approximately identical anatomical properties, and also have comparable, if not identical, physiologic (e.g., blood perfusion) properties [12]. Owing to this high identicalness, the plane that passes vertically through this midline is considered to be the Mid-Sagittal Plane (MSP).
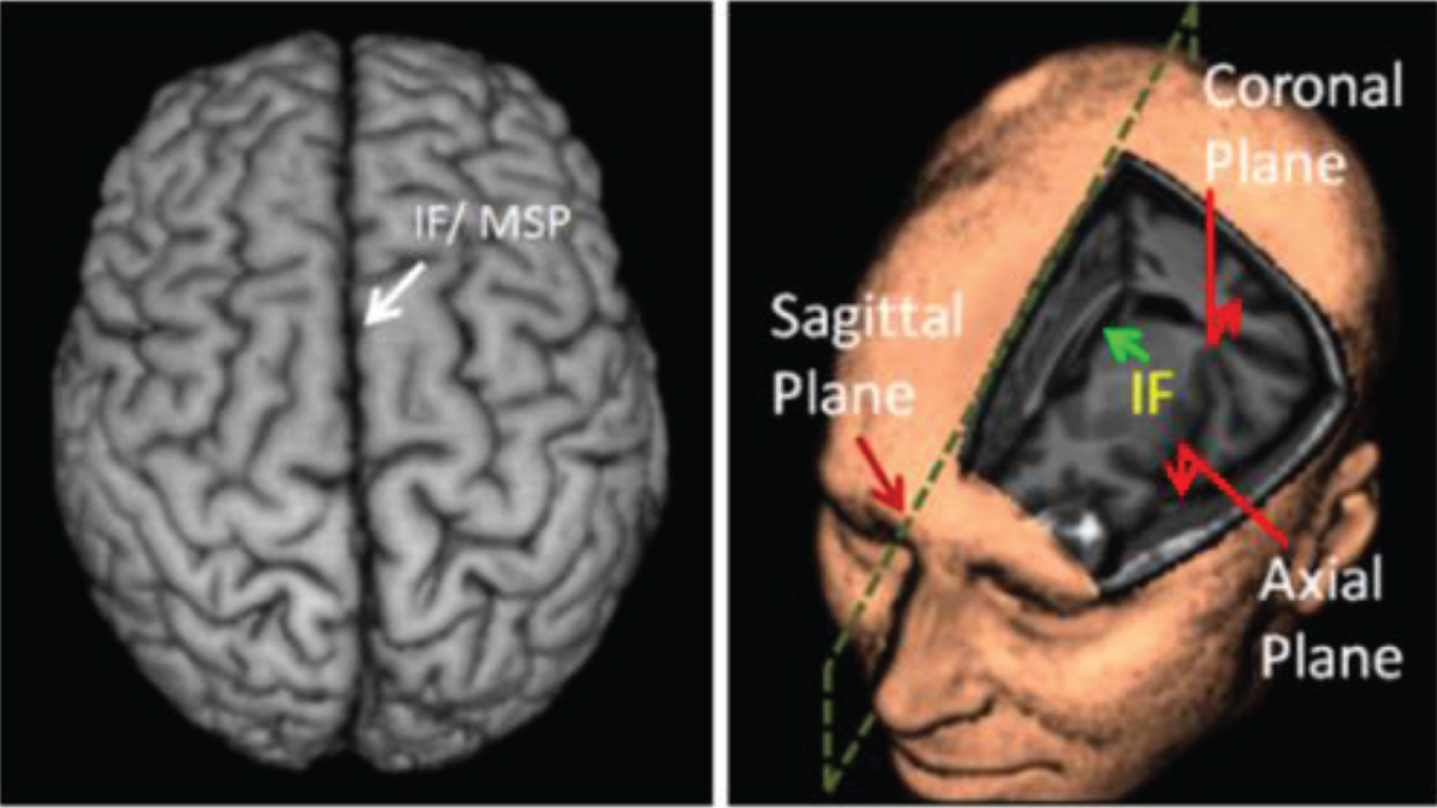
Human brain exhibits approximate bilateral symmetry (Image from [1]).
Incorporation of symmetry into generalized image segmentation is still immature [4, 13]. To the best of my knowledge, this kind of use of symmetry information can be traced back to the 1993 work of [14]. In this work, symmetry was used to reduce the redundancy in the images. In [15], using the symmetry information, the segmentation problem was formulated as a minimizer goodness of the fitness function. In [16], colour and symmetry were utilized to detect regions of interest (ROI) in an image. In [17], in order to find symmetric regions, global symmetry was integrated into the edge weights of the normalized cut (n-cut) segmentation. In [18], local symmetry was combined with an objective function of the level-set segmentation, to segment the boundary of the symmetric objects. And finally, in [13], bilateral symmetry was integrated into the image-segmentation algorithm, based on region-growing technique.
Symmetry information has been also used in brain MR image segmentation. In [12, 19], brain image segmentation was carried out to detect the existence and the outlines of tumours, based on the symmetry character of brain MRI image and its edge information. In [20], a symmetry-integrated brain injury detection method was presented. In this method, a symmetry affinity matrix was used to segment the brain slices, potential asymmetric regions were detected, a 3D relaxation algorithm was applied to the cluster pixels in the symmetry affinity matrix, and asymmetric regions were refined. Brain injuries were finally extracted. In [21], symmetry plane was used to determine asymmetric areas in the brain which was helpful to detect tumours. And finally, in [22], a fuzzy point symmetry-based genetic clustering was introduced to segment the brain image. In that work, the search capability of the genetic algorithm was utilized for automatically evolving the clusters’ centroids. Assignment of points to different clusters was made based on the point symmetry-based distance. A fuzzy point symmetry-based cluster validity index was used as a measure of ‘goodness’ of the corresponding partitions.
As a more accurate alternative concept for MSP, the Mid-Sagittal Surface (MSS) is a (curved) surface corresponding with the IF and separating the two hemispheres. Contrary to the MSP, the MSS has potential to be consistent with the natural shape of the IF. In the presence of asymmetries, caused either by natural variation or pathology, a MSS is able to correctly separate two hemispheres, whereas an MSP would intersect or misclassify some brain tissues [23]. This is illustrated in Fig. 2 where the Mid-Sagittal Plane (dotted line) and the manually delineated Mid-Sagittal Surface (solid line) are not matched.
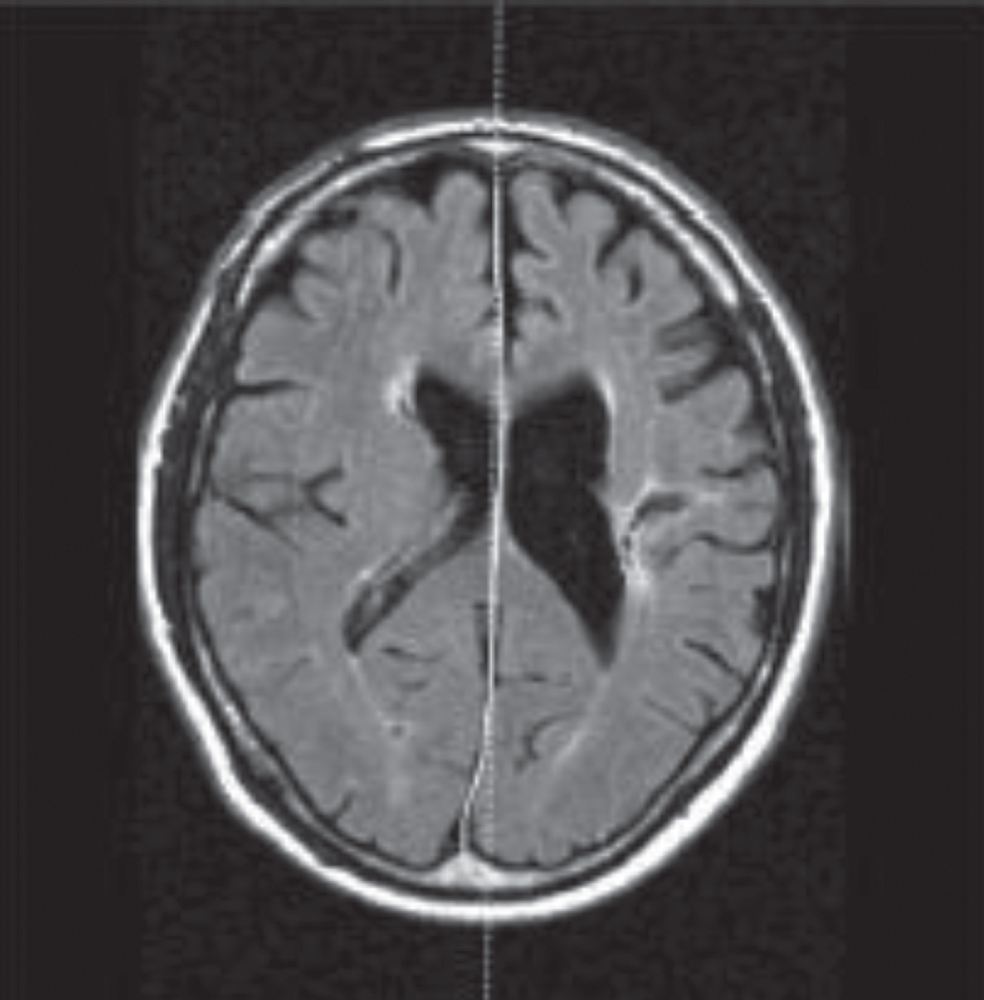
Example scan showing difference between the MSP (dotted line) and the manually delineated MSS (solid line) (Image from [2]).
In this research, I had two contributions; first I introduced SPFCM as a new version of PFCM which combines spatial values and possibilistic concept with fuzzy membership values. SPFCM was introduced in an attempt to handle the noise and Intensity Non-Uniformity (INU) effect. Second, I applied symmetry information to SPFCM. For this purpose, I introduced a genetic algorithm to extract the Mid-Sagittal Surface. Using the extracted MSS, I determined the symmetry pairs, and the symmetry degree of each pair. In the next steps, I injected the calculated symmetry degrees to the SPFCM objective function, and I amended the updating formulas of the centroids, as well as membership values in each class based on this new objective function. As a result, I have a classifier method called GSPFCM, which uses membership information, possibilistic information, spatial information, and symmetry information.
General view of the proposed segmentation method, GSPFCM is as follows (see Fig. 3). First of all, Spatial Possibilistic Fuzzy C-Mean (SPFCM) is modelled. SPFCM is used as the clustering model. In the next step, in order to apply symmetry information to the SPFCM, Mid-Sagittal Surface is estimated, Symmetry-Pairs are obtained, and symmetry information is applied to SPFCM. For the last purpose, Symmetry Degrees are calculated, and GSPFCM objective function, centroids’ updating formula, membership values’ updating formula, and possibilistic values’ updating formula are calculated. Each step is more described in the next sections.

Pseudo code of the proposed GASPFCM segmentation method.
SPFCM is an extension of FCM [24] and PFCM [11]. SPFCM takes into account of both possibilistic and membership values in the form of an optimization solution. In SPFCM, the local spatial continuity is applied to calculate the proximities [25].
The objective function for the SPFCM clustering algorithm is given by
ℵ is a neighbourhood of the
The necessary conditions for the minimization of JSPFCM over the membership
A high-level pseudo code of my MSS extraction method is presented in Fig. 4. In this algorithm, an initial MSP is estimated (line 1 of the pseudo code). Genetic algorithm is applied and the best chromosome expressing the most proper control points is achieved (lines 2 to 10). Finally, MSS is constructed crossing the selected control points using TPS (line 11).

Pseudo code of the proposed MSS extraction method.
First, an initial Mid-Sagittal Plane is estimated. For this purpose, a number of planes in the middle of the brain in sagittal view with limited number of coronal and axial rotation degrees are nominated, and among these nominated planes, a plane with minimum Fractal Degree (FD) coefficient, α, (as the same definition as Equation 2) value is selected. FD value is calculated for each box with variable size moving through both cerebral hemispheres. After detecting initial MSP according to a texture information, FD, which is fast and noise free, I calculate Correlation Coefficient (CC) for a very limited number of plate (two plates in each side) around the extracted MSP. The initial MSP is a plane with the minimum CC value. CC is calculated for all symmetry pairs in the cerebral hemispheres and using the pixels’ intensity values. This makes CC ineffective in Pathological images. In addition, determining pairs and calculating CC is time consuming compared to FD [27].
In the next step, candidate positions are selected. For this purpose, a genetic algorithm with the specifics explained before is applied. The output of this section is a chromosome consisting of a 2D array with P1 × P2 elements. Providing the volume of the chromosome which is much less than size of main image, time complexity is not more a constrain for my algorithm. The control points for constructing the Thin-Plate Surface are achieved from the resulted chromosome.
For the selected control points, a Thin-Plate Surface is constructed. The corresponding pixel values of the final Mid-Sagittal Surface including the selected ones, as the control points, and the others are calculated using the extracted TPS. In order to construct the Thin-Plate Spline instead of applying matrix inversion process which brings an extensive time complexity, Singular Value Decomposition (SVD) is used [26].
In my genetic algorithm, each individual of the population encodes one MSS and each MSS is presented by a P1 × P2 nominal 2D array encoding the control points of the MSS. P1 and P2 are the number of points in axial and coronal axes of the MSS (see Fig. 5). These control points in each line will be used to construct corresponding Thin-Plane Splines. According to [28], the number of points participating in this construction should be between 5 to 9. Thus, P1 and P2 are assigned to a value in this limitation. I set P1 and P1 with 7 and 6 respectively. These low values decrees size of chromosomes and enhance dramatically the speed of the genetic algorithm. Figure 5 shows genotype structure of a chromosome. While sub-figure (a) presents a chromosome, sub-figure (b) shows how the genes’ values are interpreted. The initial population are assigned with random values.
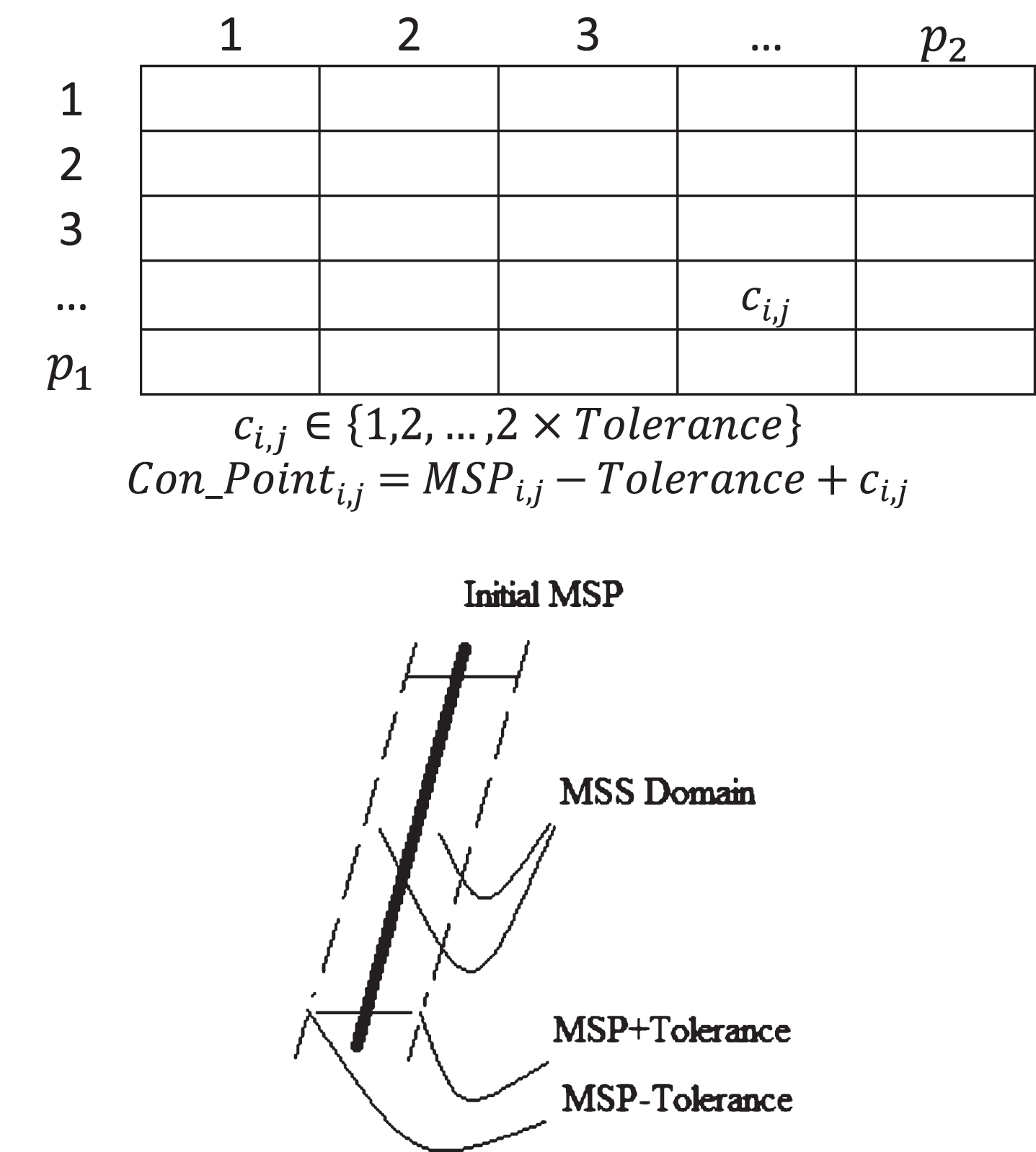
Structure of a Chromosome and its interpretation.
The fitness function rewards individuals encoding MSSs with high symmetry degree and low symmetry difference, α, with low vibration in two sides of the initial MSP. To this aim the following fitness function is used:
My experiments showed that fitness function without considering the spatial information of the control points in each chromosome leads me to a jagged MSS. To address this problem, I added γ to the fitness function. γ is calculated based on Local Binary Pattern (LBP) concept and using the following equation. γ shows how much neighbour control points in the corresponding MSS are located in two sides of the initial MSP.
The individuals are selected for reproduction with a tournament selection operator; a number of individuals are randomly selected, and the one with lower fitness is chosen as elite. The number of selected individuals determines the size of the tournament. Elitism is applied with a given size. 2D one-point crossover operator is used; in short, one-point crossover selects a point inside the two chromosomes and produces the offspring by exchanging the substrings of the parents. Standard mutation operator is employed; a row number and a column number are selected randomly and value of the corresponding gene is changed with a random valid number.
GA parameters setting
As most Evolutionary Algorithms, my proposed genetic algorithm for MSS extraction uses several parameters that control the genetic search, e.g., crossover and mutation probabilities, population size, etc. In general, for an EA to perform well, the issue of setting the parameter values that are used to guide the genetic search is critical. I used the values as whatever shown in Table 1. These values have been achieved experimentally.
GA Parameter values
GA Parameter values
One of the potential problems of using evolutionary algorithms is the high time consumption problem. The time complexity of these algorithms mainly depends on the values of a number of control parameters including Population Size, Number of Generations, Size of Chromosomes (P1 and P2). The best values for these parameters make an optimal balance between performance and time complexity. They are dependent on the problems naturally and the way of designation of optimisation method. I set these parameters with the optimal values as they were achieved from Fig. 6. In each part of this figure I present a chart that shows the ratio of mean accuracy on time consumption via different values of the corresponding parameter in the horizontal axis. In these tests, when a parameter is investigated, all other parameters are constant.
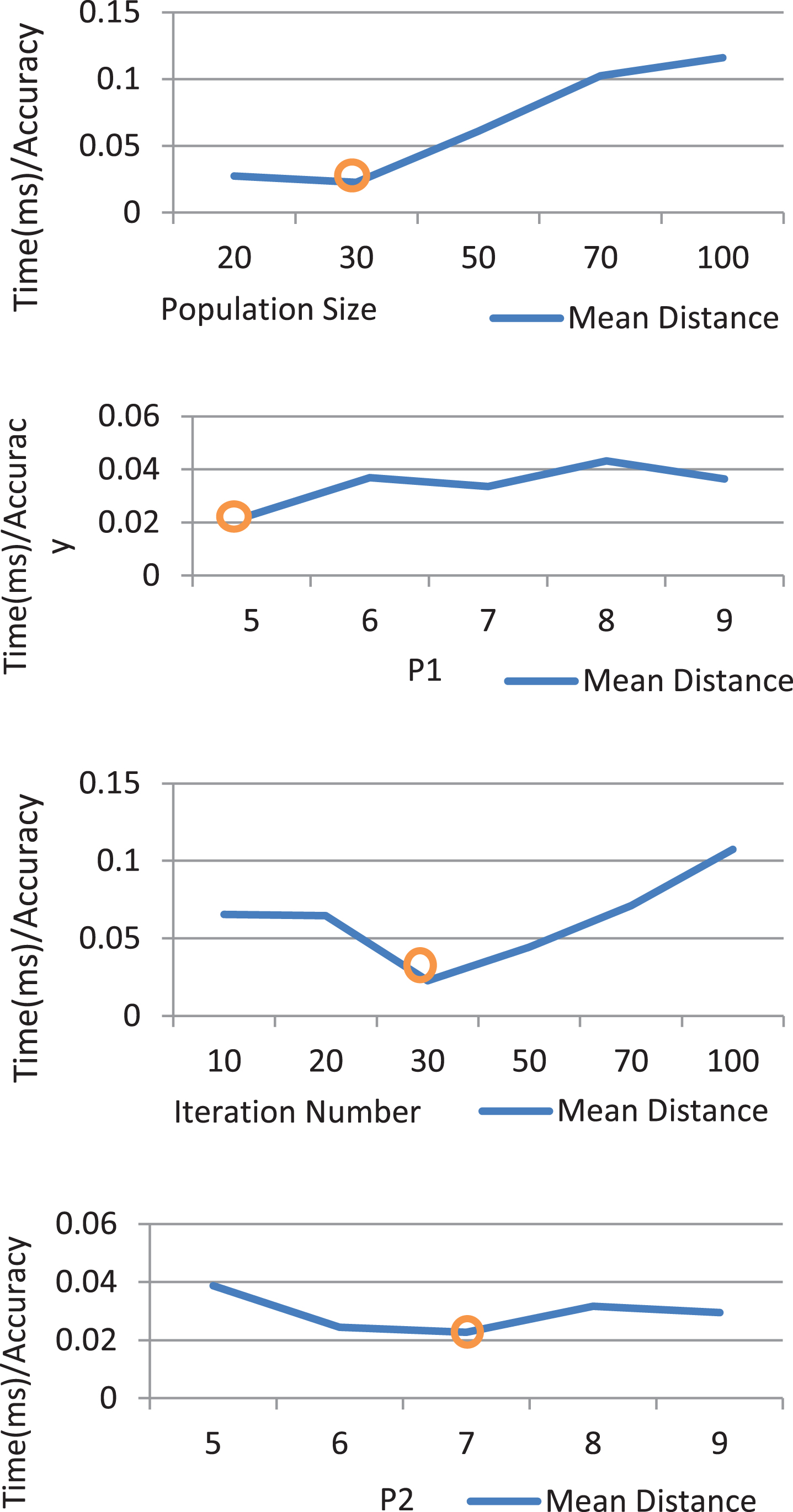
Effect of Genetic Algorithm’s Parameters on Efficiency in contrast to the Time Consumption.
I assume symmetric pixels in each axial slice have similar intensity values, and therefore the cluster of each one should be influenced by the other one. There are two limitations impacting this assumption: first, how to determine the symmetrical pairs, since reflection of the extracted MSS on each frame is a curve, not a symmetry axis; second, two estimated symmetry pairs are not completely match.
To overcome the first limitation, I introduced an automatic symmetric pair estimation method based on the extracted MSS (Fig. 7). Figure 7(a) shows the estimated symmetry curve in a number of frames on two sagittal and coronal views and Fig. 7(b) illustrates the applied method. In this figure, A is an arbitrary pixel in a 2D axial frame. This process determines its corresponding symmetric pair, A′, according to the symmetry cure, C. In the ideal state, C is orthogonal to the horizontal line crossing from A and its mirror pixel, which is located in
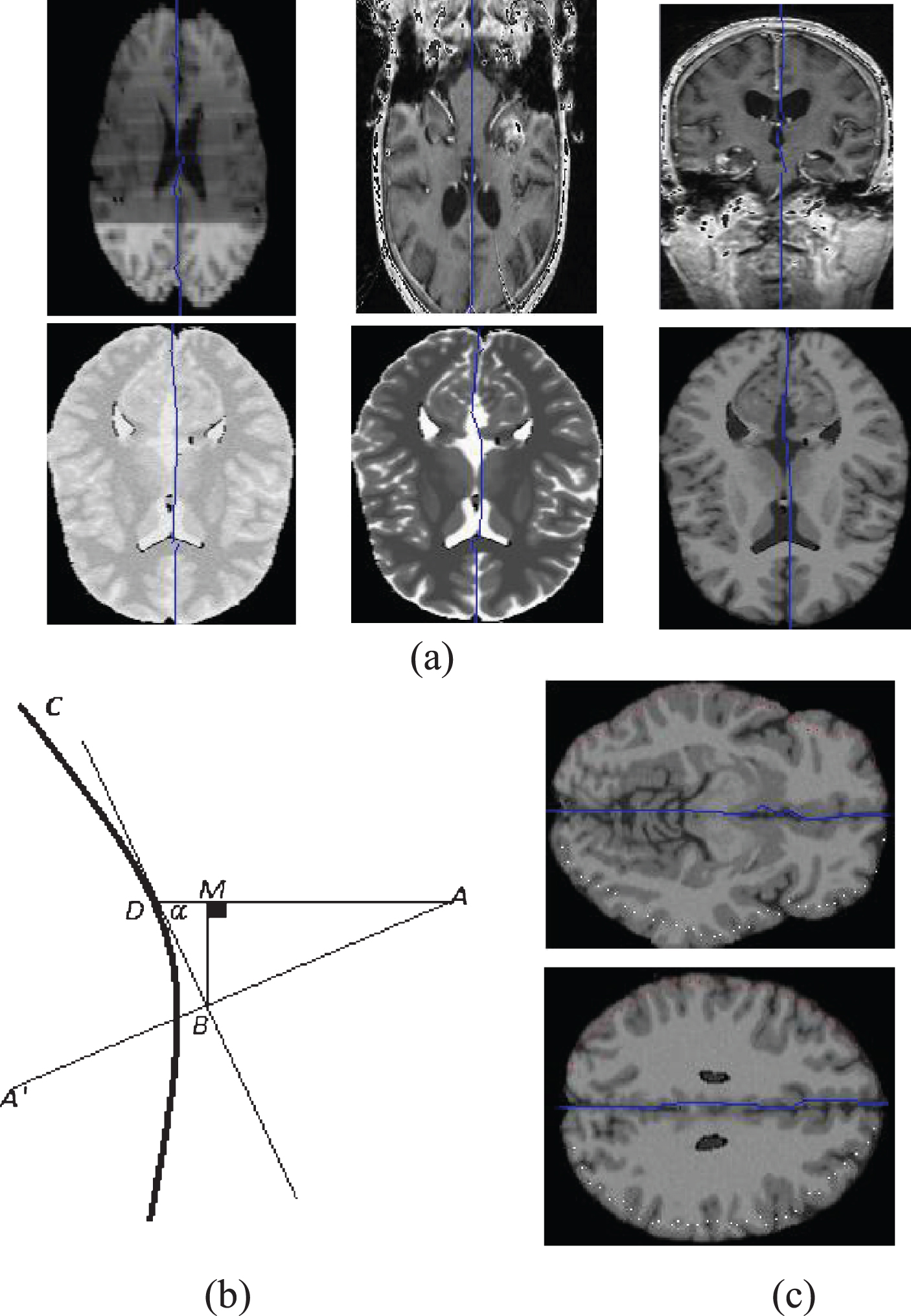
How to determine symmetric pairs? (a) Number of estimated MSS samples. (b) Method to detect symmetrical pairs for an arbitrary pixel in a 2D frame. (c) Two sample images and the corresponding estimated symmetrical pairs.
Figure 7(c) shows a number of pixels and their corresponding estimated symmetric pairs in two sides of the MSS.
I use spatial information to overcome the second limitation and to increase the adaptability between symmetric pairs. Let
So far I have specified the symmetric pair of each pixel in the image. The ideal is that each pair voxels have similar values and classes. In this step I use this principle to increase the accuracy of the SPFCM. The algorithm first computes symmetry measure for each pair (this parameter shows the similarity and the reliability of a pixel and its estimated pair). Several methods have been introduced in [29] to calculate the symmetry measure.
Here, I introduce a new method based on the fact that symmetrical pairs and their neighbors tend to have similar textures and intensity values. Contrary to others who only use intensity values, my symmetry measure is based on both textural information and intensity values. This definition immunizes the symmetry measure confront of the noisy pixels.
The proposed method calculates Local Binary Pattern [30] for each pixel to detect the differences between symmetric pixels. Symmetrical pairs are expected to have minimum texture difference.
Two symmetric pixels with similar textures may not have the same intensities. Here, the difference between intensity values of each pixel and its neighborhoods with the corresponding intensity value of the mirror pixel and its neighborhoods is calculated and multiplied by the calculated symmetry degree.
In the conventional FCM and in its derived versions such as SPFCM, the pixels are allocated to different classes according to the distance between their intensity values and centroids of the clusters, so that when a pixel is far from a centroid, it has less chance of belonging to that class. In this research, I add distances between the mirror pixels and the centroids to the distance of the pixels and the corresponding centroids. For this purpose, I introduce a weighting parameter, which weights the symmetric pair distances with each centroid.
By setting a threshold value to
After applying the symmetry information I calculate the objective function for the GSPFCM clustering algorithm by
The method was implemented using C++ in the MS Visual Studio environment and were tested on both simulated and real 3D MR images. Simulated brain data with different noise and INU levels and their ground truths were obtained from the BrainWeb Simulated Brain database at the McConnell Brain Imaging Centre of the Montreal Neurological Institute (MNI), McGill University [31], and the real MRI data were obtained from the Internet Brain Segmentation Repository (IBSR), Massachusetts General Hospital [32]. Extra-cranial tissues were removed from all images prior to segmentation. The number of tissue classes in the segmentation was set to three, which correspond to Grey Matter (GM), White Matter (WM) and Cerebrospinal Fluid (CSF). Background pixels were ignored in the computation. For the simulated 3D MRI brain images, the dimensions were 217 × 181 × 181 [row (y) × column (x) × depth (z)], and for the real 3D MRI brain images, these values were [55–61]×265×265. The algorithms were run on a Pentium i5 3.2-GHz 4 G PC.
Parameter setting
The first four results in Table 2 demonstrate that if I vary a, from 1 to 10, keeping all other parameters fixed, the best results are achieved when a, = 7. However, the changes are not a lot. It is because, increasing a, when the value of a is fixed, assigns more importance to typicality. The results do not change much since, in the simulated images, there are a number of nice-well separated clusters so that their segmentation is done well by membership concept of GSPFCM. However, if the data have outliers, giving more importance to typicality by increasing a,, improves the prototypes. Generally, this property can be used to get a better understanding of the data [33]. When I discuss the values of a and a,, a natural question comes: should I constraint these parameters to a + a, = 1 ? Acceptation of this constraint means that if I increase the importance of one (for example membership vale) it necessarily forces me to reduce the importance of the other one (for example typicality) which is too restrictive. In order to investigate this matter experimentally, I conducted tests in rows 6 and 7. The results show a considerable drop in results. In the rows 7 to 10, I evaluated the results when the values of m and n are changed and the values of two first coefficients are fixed. The changes were done in two states when m is much more that n and when n is much bigger than m. These values mean the effect of one factor, typicality via membership values, dramatically changes. The results showed that in both states the error rate increases and the best results are achieved with similar values for m and n. Because the more acceptable results with lower values for m and n parameters in the first rows compared to the recent evaluated rows (rows 7 to 10), it is concluded that the best results are achievable with low similar values for these two parameters. Finally the two last rows of the table show that the best value for m and n is 2. As a result, I assigned a, a,, m, and n parameters with 1, 7, 2, and 2 respectively.
Results produced by GSPFCM for different values of the parameters
Results produced by GSPFCM for different values of the parameters
The time complexity of GSPFCM is not much more than the other segmentation methods. Generally adding a number of information terms to objective function of GSPFCM increases its time consumption. However, the time complexity of this method is not much more than the other methods. Let’s have a look in details. The time complexity of GSPFCM equals to maximum complexity of triple phases of the proposed method; MSS extraction, Symmetry-pairs estimation, and applying symmetry information to SPFCM. For the MSS extraction, unlike this fact that naturally evolutionary algorithms are slow, the algorithm looks for a proper fitting set of pixels inside a limited area around the extracted MSP; I hope the genetic algorithm converges soon, so that in average total time complexity of the MSS extraction method is a ratio of the image slice number. In order to estimate symmetry-pair of each pixel in different slides, a sequence of calculations is done. As a result, time order of symmetry pair estimation for each pixel is o(1) and the total time complexity of the symmetry pair estimation algorithm is a ration of size of the picture. Finally, adding a number of terms to objective function of GSPFCM and the updating formulas increases time consumption of the method, but it does not have effect on the time complexity. As a result, I claim that time complexity of GSPFCM is not much more than other segmentation methods such as ASFCM, FCM, PFCM and so.
Visual performance of the MSS extraction method
In this experiment, a comprehensive qualitative experiment was conducted in the hope to show performance of the proposed method in extracting MSS under different conditions. For this purpose, both normal and pathological MR images from IBSR were used. Figure 8 presents a number of the results projected on the axial or coronal slices. Two first images of the first row show the output of a normal T1 MRI in the axial view and the next two images present the output in the coronal view. The second row illustrates effectiveness of the algorithm on the normal brain images captured under different INU conditions. The third row is belonged to T2 modality images while the fourth row shows the extracted MSSs for Parkinson’s Disease (PD) modality images. Finally, effectiveness of the algorithm on pathological images is highlighted in the last row images.
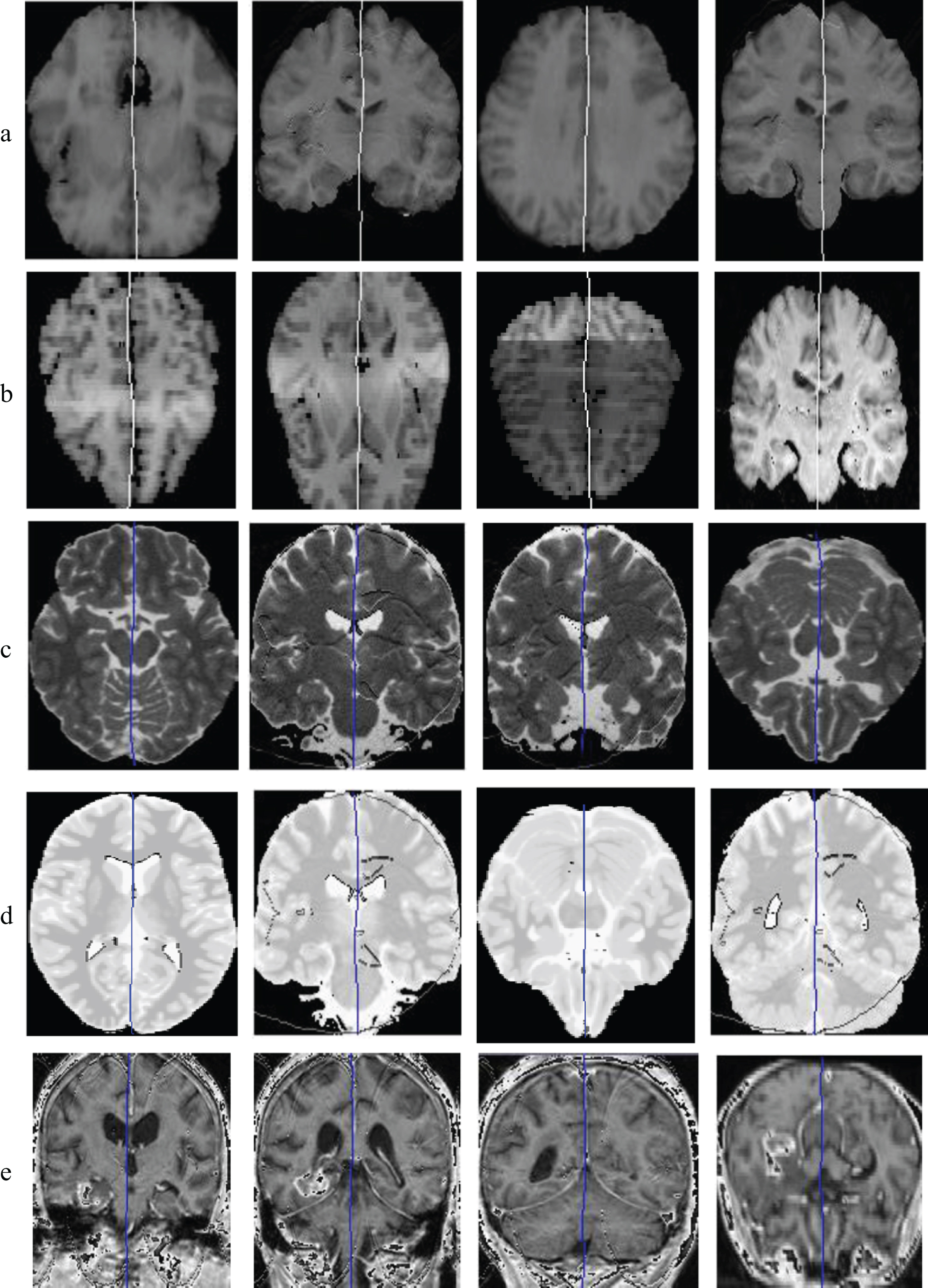
Estimated MSSs by the genetic algorithm projected at axial/coronal slices. a: Images at different axial locations and different coronal slices. b: Normal brain images captured under different INU conditions. c: T2 modality. d: PD modality. e: Pathological images.
In addition, the effect of noise, INU, slice thickness, and modality on the visual quality of the estimated MSS was investigated using the simulated images from BrainWeb dataset. The results are shown in Fig. 9. As it is shown in this image, the proposed algorithm is robust in facing various amounts of these effects.

Effect of different levels of noise, INU, and modality on the performance of the estimated MSS by the genetic algorithm.
Figure 10 shows a number of simulated MRI brain images, taken at different slices. The image of Fig. 10(1a) has been simulated from the true model with the following settings: modality, ICBM protocol [34], slice thickness of 1 mm (1 voxels), 3% noise level and 40% INU. Figure 10(1b) was generated based on a discrete anatomical normal brain model and serves as the true model. Figure 10(1c) shows the actual bias field producing the INU artefact. Figure 10(1d) shows the segmented image, and Fig. 10(1e) presents the recovered bias field, which resembles very closely the actual bias field of Fig. 10(1c). The next two rows in Fig. 10 illustrate the same information for slices taken near to the base of the brain (z = 39) and near to the top of the skull (z = 140), respectively.
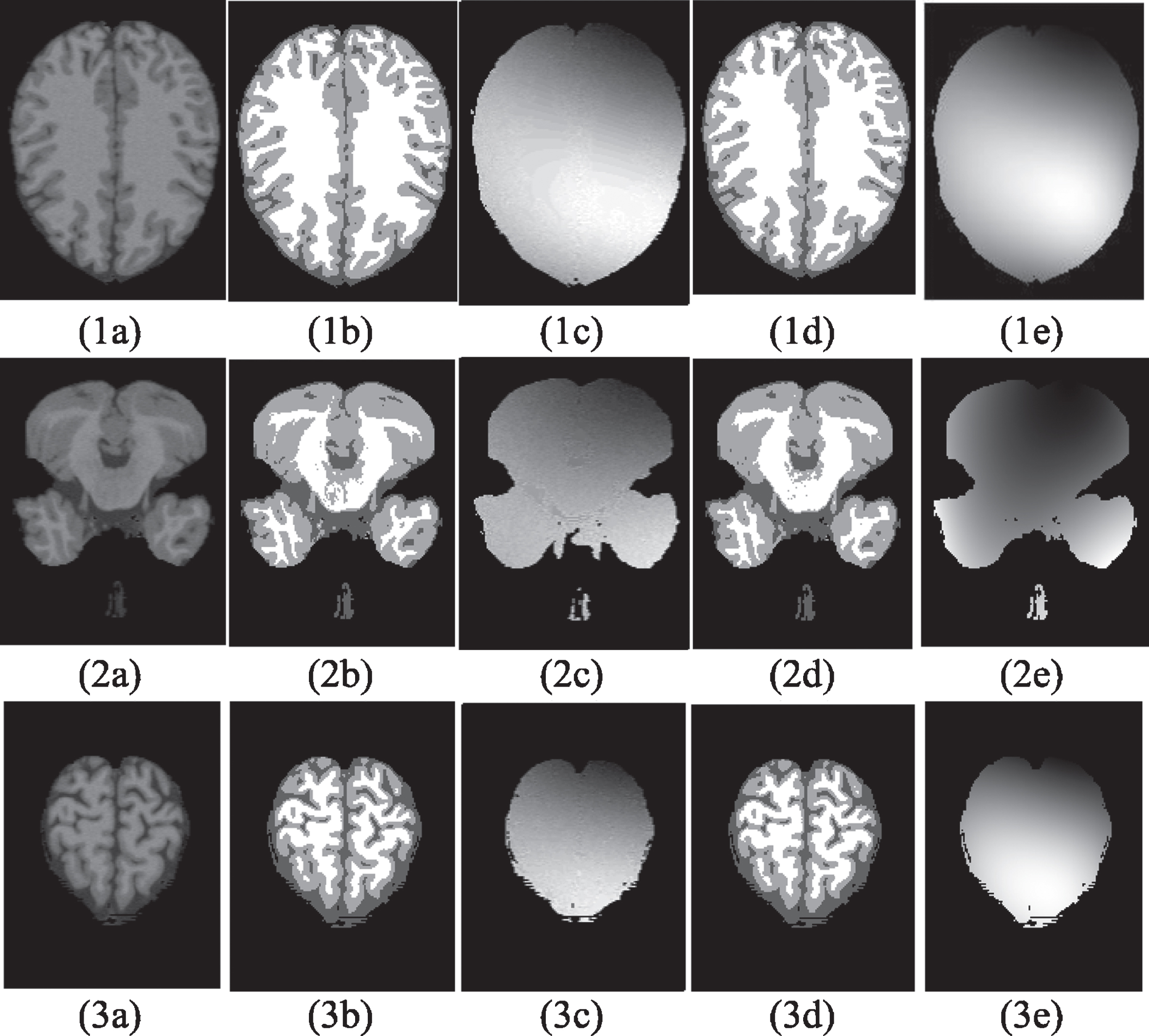
Segmentation Results by the GSPFCM for the Simulated MRI Slices. From Left to Right: Image Corrupted with Noise and INU Artefact, True Model, The Corresponding Bias Field, The Segmentation Result, and the Recovered Bias Field. From Top to Bottom: z = 110, z = 39, and z = 140.
To show the outcomes of the proposed segmentation method on real images, the following experiment was carried out. Figure 11 presents a slice (z = 36) of the IBSR 8 bit T1 Normal brain 6_10 image. In this figure, CSF, GM, and WM are shown in Fig. 11(1b), (1c), and (1d), respectively. The same images are shown in the next two rows for slices taken near to the back of the brain (z = 12) and near to the front of the skull (z = 45), respectively. Please note that in real MR data, images are scanned slice by slice in the sagittal direction.
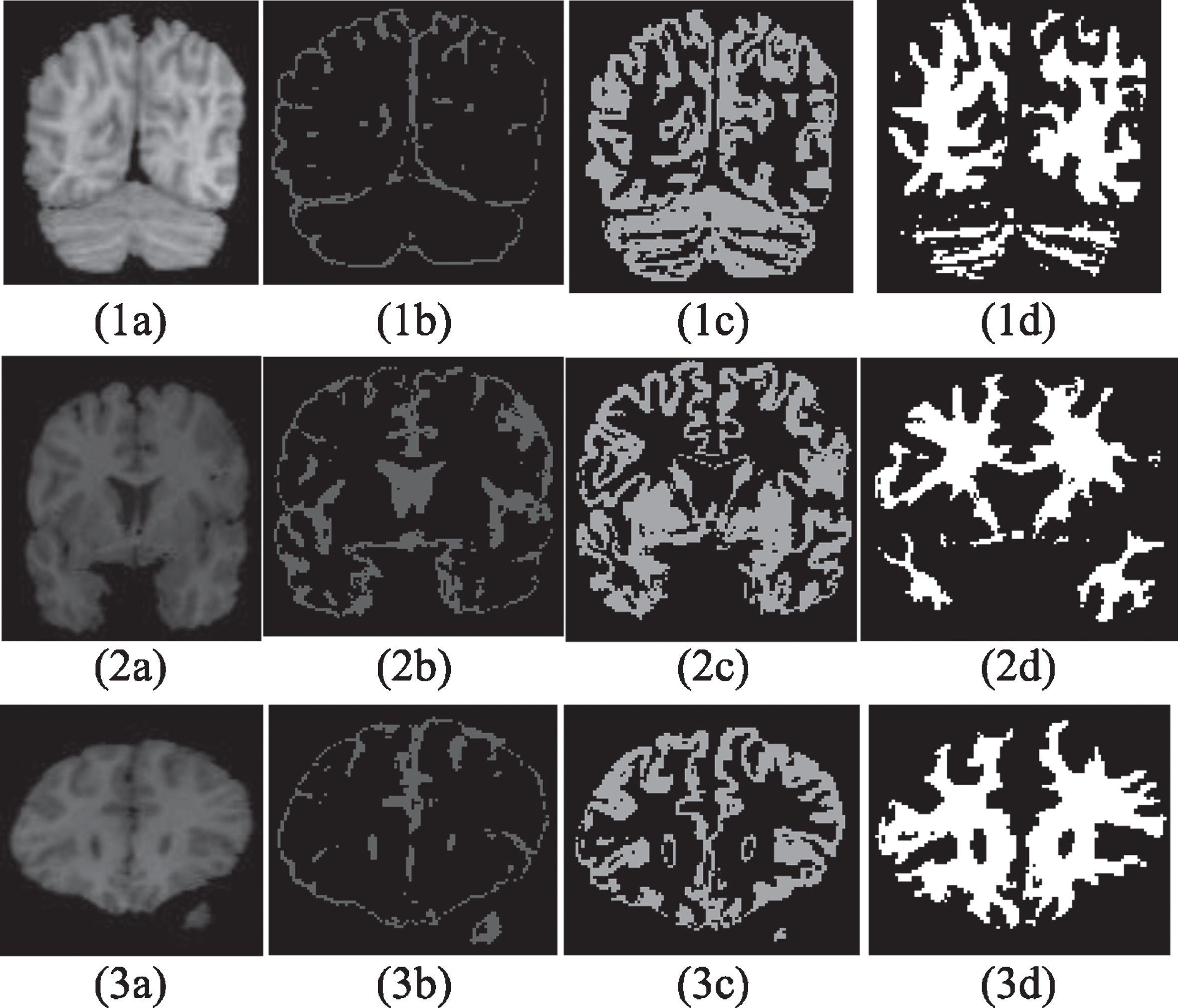
Segmentation Results for a Real Image (a) Slice Image, Segmentation Results show GM(a), CSF (b), and WM(c), (1) z = 36. (2) z = 12, (3) z = 45.
For comparison, I calculated the MCR value of a number of re-implemented segmentation methods, namely, ASFCM (Adaptive Spatial FCM) [26], SymFCM (Symmetry FCM) [4], FCM (Fuzzy C-Mean Classification) [24], MRF (Markov Random Field) [35], EM (Expectation Maximization) [36], and PCM (Possibilistic C-Mean) [11], FPCM (Fuzzy PCM) [10], and PFCM (Possibilistic FCM) [11] as the state-of-the-art methods in possibilistic methods. Simulated MRI data was used with weighted T1 voxels, 3% noise, 40% level of INU inhomogeneity and slice thickness of 1 mm. Table 3 shows that the GSPFCM had better performance compared to the other methods. Each column in this table shows the average result for all slices (all 145 non-empty slices from 217 ones).
Comparison of the ASFCM, SymFCM, FCM, MRF, EM, PCM, FPCM, and PFCM algorithms in terms of Overlap Metric (IN %) for different tissue classes, and the MCR (IN %), for the simulated image with INU = 40%
Comparison of the ASFCM, SymFCM, FCM, MRF, EM, PCM, FPCM, and PFCM algorithms in terms of Overlap Metric (IN %) for different tissue classes, and the MCR (IN %), for the simulated image with INU = 40%
A paired t-test was performed to reveal the reliable difference between the mean MCR value of my method and that of the other six methods. The comparison results with these methods for the probability value for a 95% confidence level are shown in Table 4. In these tests, all 145 2D simulated frames participated.
Results of the paired t-test in the simulated images
To show the enhancement of GSPFCM compared to all the segmentation methods used in the last test plus ASFCM [26], a more comprehensive experiment, the quantitative measures were calculated for 573 2D axial slices. The average values and the standard deviation values for the factors through different slices are plotted in Figs. 12 and 13. Overall, the charts show the enhancement of GSPFCM compared to the others.
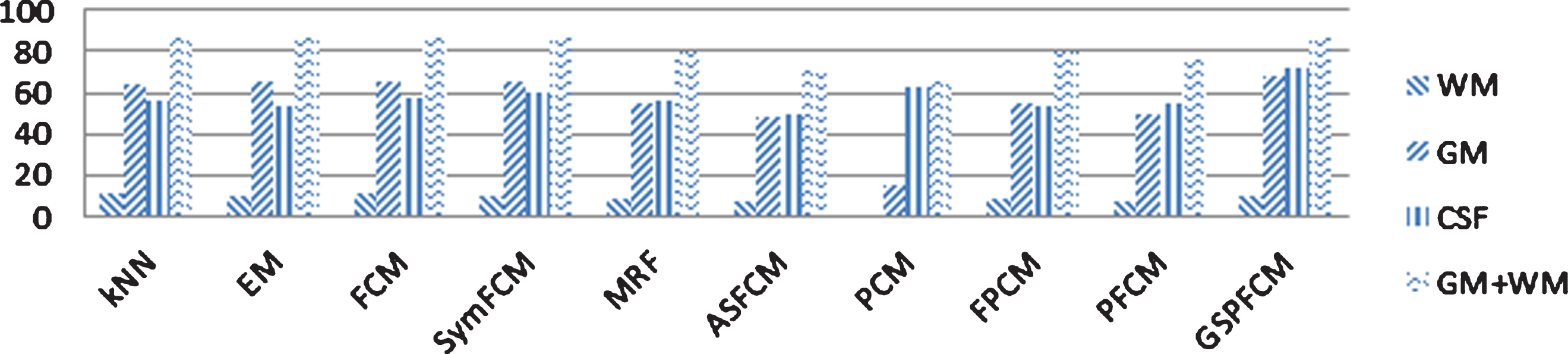
Average Quantitative Measures through 573 Real Images.

Standard Deviation Quantitative Measures through 573 Real Images.
Table 5 illustrates the average values between all these slices for each of the segmentation algorithms.
Comparison of GASPFCM, ASFCM, FCM, MRF, EM, FPCM, and PFCM algorithms in terms of Overlap Metric (IN %) for different tissue lasses, and the MCR (IN %), for real images
Like the simulated images, a paired t-test was performed between the mean MCR values of my method and those of the other four methods. Comparison results with a 95% confidence level are shown in Table 6. These results indicate that I have a statistically significant lower mean value. There are 573 2D images in this test.
Results of the paired t-test in real images
In this paper, I introduced a new version of Fuzzy C-Mean classifier named GSPFCM. In GSPFCM, symmetry information was integrated into SPFCM. SPFCM is a new version of PFCM, including possibilistic and spatial information. Briefly, first I added the possiblistic and spatial information to FCM via a new objective function for SPFCM. Then, I estimated the Mid-Sagittal Surface and determined symmetric pairs on two sides of the MSS. For each pair, I calculated a symmetry degree. A new objective function was introduced and the updating formulas of the cluster’s centroids and the membership values were modified. As a result, I had a classifier method which used membership information, possibilistic information, spatial information, and symmetry information. The comprehensive tests using two standard real and simulated datasets showed the effectiveness of GSPFCM. In the simulated images, where the accuracy is more, GSPFCM reached to 99 percent which was more than all the compared methods. In real images, segmentation accuracy is dependent on the quality of the images. However, in all the applied images, GSPFCM achieved a better result. In the best condition, I got 89.54 percentage, and in average, the results were about 5 percent better than the other methods.
Conflicts of interest
I, Seyed Hashem Davarpanah, certify that I have participated sufficiently in the work to take public responsibility for the content, including participation in the concept, design, analysis, writing, or revision of the manuscript. Furthermore, I certify that this material has not been and will not be submitted to or published in any other publication. I also certify that I have NO affiliations with or involvement in any organization or entity with any financial interest, or non-financial interest in the subject matter or materials discussed in this manuscript.