
Abstract
Fuzzy logic is a multi-valued concept, whose emergence in software sciences has eliminated 0 and 1 computations, putting them within an infinite space of [0,1]. This characteristic of fuzzy logic has resolved ambiguity in numerous previous problems. The sentence roles in Persian language were specified based on the fuzzy logic’s capability to resolve ambiguity. For that purpose, we first obtained the best classification for each defuzzifier, based on which a classified fuzzy was implemented. Nonetheless, the fuzzy system used in this research was classified based on statistical computations. To achieve the best classification, five defuzzification methods (Mean Of Max, Max Of Membership, Largest Of Max, Smallest Of Max, and Central Average) competed in 16 roles each in five classes (different matrices). Finally, Mean of Max with a success rate of 64% proved to be a defuzzifier delivering the best output among 5 different defuzzification methods.
Keywords
Introduction
Natural language processing (NLP) is an integral part of artificial intelligence. Hence, the definition provided by Turing in his test in the first section refers to NLP. In fact, NLP intends to develop a computational theory for each language through conventional algorithms and data structures, so that concepts can be comprehended automatically through a computer.
Unlike programming languages, natural language involves a well-defined structure and meaning, where there are huge complexities in analysis and understanding. Researchers in this interdisciplinary field need to gain computer expertise as well as essential linguistic skills. In the first stage, different types of sentence structure were extracted by several Persian language and literature experts as well as Persian grammar textbooks studied in Iranian high-schools [1]. In the next stage, Microsoft Office Excel 2013 was used for statistical labeling on sentences extracted in the first stage and words derived from Pars Process sentence analyzer software [2], Bijankhan Corpus [3], verb bank of Persian Language Database 3.0, and Encyclopedia of Names and Naming by National Organization for Civil Registration. The results were adopted to train the newly proposed fuzzy system. Then, the number of possible phrasing modes was obtained based on the number of words in input sentences and decomposition of sentences. In the next stage, the initial fuzzy computations were performed through programming language codes in Microsoft Visual basic.net 2012 while implementing the database of SQL Server 2008 database, where the best classification was achieved. In the final stage, the main fuzzy computations were performed through the same software according to the results of previous stages. The results from each defuzzification method were compared while presenting the best option.
Literature review
Terminology explores the complex structure of a sentence or word from the perspectives of form and meaning. This structure is examined from three aspects of grammar, decomposition and composition. In this paper, the morphological structure of sentences and words was examined based on analysis of the relationships between words and letters [4]. Construction Morphology refers to a theory examining the structure of words through the concepts of “decomposition and composition” [5, 6]. In that light, the current study revolves around Construction Morphology.
The role of each word relies on syntax to determine the meaning of that word. The semantic role of words is definitely not a new concept in linguistics. In a classical definition, semantic/thematic roles of compound words [7] involves a theory based on grammar, describing the relationship between syntax and meaning of a word. Most relevant studies focused on English, leaving a tremendous gap in Persian for such labeling systems. The insufficient number of studies can be associated partly with lack of a comprehensive corpus such as FrameNet in Persian and partly with the format of Persian as well as Arabic alphabets [8, 9].
The terminological research has so far concentrated on English for several reasons as follows: The modern methods of semantic analysis have emerged in the USA, including FrameNet (Palmer et al., 2005 [10]) and PropBank (Baker et al., 1998 [11]). Secondly, the majority of semantic role labeling (SRL) systems require, particularly over the early stages, manual training of information often available to scholars in English.
Nonetheless, terminological studies have been conducted in other languages, such as Spanish (Subirats and Petruck, 2003 [12]), Japanese (Ohara et al., 2004 [13]), Dutch (Moortgat et al., 2000 [14]), Urdu (Mukund et al. 2010 [7]) and German (Burchardt et al., 2006 [15]). These studies yielded impressive results, where output products developed in several versions [16]. One of the major projects in this area of research is known as EuroWordNet, involving a multilingual database and several European languages (Dutch, Italian, Spanish, German, French, Czech and Estonian) [17].
Basic works in semantic linguistics were initiated by Fillmore back in 1968 [18, 19]. Despite large lists of specific roles obtained by Fillmore and Ruppenhofer, Baker (2004) [20], and a small set of key roles by Jackendoff (1990) [21], there is still no definitive list of semantic roles [8, 9]. In identification of main semantic roles, only Dowty (1991) [22] studied two roles. However, the most important computational theories about main roles can be found in studies by Fillmore (1968) [18], Jackendoff (1990) [22] and Dowty (1991) [16].
Upon arrival of the 21st century, medium and large corpora manually adopted semantic roles to develop a statistical method for labeling in FrameNet research by Fillmore, Ruppenhofer and Baker (2004) [20], PropBank by Palmer, Gildea and Kingsbury (2005) [10] and in NomBank by Meyers et al. (2004) [23] [8]. In recent studies, Silva et al. (2016) [24] classified the semantic roles of words, while Rastle et al. (2008) [25] identified roles by splitting words into their original components.
In the scope of Persian language, the most prominent studies were carried out at Web Technology Lab (Ferdowsi University of Mashhad) [26] by construction, Dr. Bijankhan [27] and Dr. Shamsfard [28], who are among experts in this field. The most prominent studies include: Web Technology Lab (Ferdowsi University of Mashhad): In this laboratory, a summarization system was developed in 2012 known as Ijaz, in addition to several other NLP tools in Persian [29]. Dr. Mahmood Bijankhan (2004) created a text corpus called Bijankhan in Persian. From 1995 until today, Bijankhan has been conducting extensive research in the Persian language corpora, speech recognition and other NLP areas. Dr. Shamsfard et al.: One of their key studies dealt with a new system known as “Hasti”, which extracts lexical and semantic data from Persian texts [30]. In 2004, and in recent years, research efforts have focused on statistical machine translation (SMT) from Persian into English [31].
In the field of labeling sentence components or roles in Persian content, there are three pivotal studies as follows:
1) S. M. Assi and H. Abdolhosseini (2000) [32], whose study attempted to determine the grammatical categories of words in continuous Persian texts through mathematical and statistical measures generally known as Distributional Part-of-Speech Tagging [33]. 2) Najmeh Nouri (2013) designed a tool for semantic labeling of Persian sentences [34]. 3) Motameni and Peikar (2016) adopted a fuzzy system to determine the role of words [35].
Similar to NLP, terminological applications can be divided into two general categories: Written applications and speech applications. [8] The written applications cover the extraction of specific information from a text [36], translation of a text into another language [31, 37], finding specific documentation in a text-based database [36] (e.g. finding related books in a library), summarization system [38], text editing systems [2], and categorization of texts from semantic relations (thematic categorization) [8, 23]. [8] Examples of spoken applications include human-computer question answering systems [39], automatic customer relations via telephone or voice control systems [8].
Fuzzy systems
After Zadeh (1965) introduced fuzzy sets [40], other systems were released from the binary space of classical sets defined within a space between zero and one [0, 1] [41]. This capability of fuzzy sets provided three special features for fuzzy systems namely similarity, priority, and uncertainty. These three features adopted fuzzy sets as a major tool in information technology in order to bridge the gap between human formalized knowledge and recognized numerical data [42]. For this reason, the current study relied on a fuzzy-based statistical method so as to use the results of statistical method in training of the fuzzy system. This in turn will identify similarities, select the priority of each role and make a good decision in uncertain occasions [43, 44]. Among the various types of fuzzy systems, fuzzifier and defuzzifier was adopted in this paper to operate according to Fig. 1. [35]
According to Fig. 1, the terminological method in this paper involved two general stages. Fuzzifier (labeling of training sentences and words) and defuzzifier (identification of roles and decision-making) [45, 46].

Fuzzy system.
This section discusses how to identify sentence roles in Persian texts. One approach deals with statistical terminology [8], whose advantage is that lengthy manual work and grammar expertise are eliminated. This terminological method makes decisions through a trained statistical procedure based on a set of lessons learned about the role/type of words [8].
Labeling of training sentences and words
One of the methods used in this paper is known as N_gram statistical labeling (Uni_gram and Bi_gram). This labeling method is regarded as one of the most widely adopted statistical terminological methods. The output of N_gram labeling will be matrices used in fuzzy computations [47].
This leading method falls under the category of forward as opposed to backward. This implies that the method was assessed based on the preceding letters of each letter or the preceding words of each word. Equation (1) provides an overview of N_gram labeling computations. Depending on the type of statistical task, Equation (1) may be implemented on letters, words or sentences.
Equation 1: N_gram Labeling
In Equation (1), K is the counter for current letter/word while
Uni_gram examines each word/letter in a sentence without forward and backward dependencies. Bi_gram statistically evaluates each forward/backward letter/word consequently leading to next stages. Nevertheless, the N_gram labeling method in this paper was used to calculate the weight of each word. [48, 49] For instance, the Bi_gram of Persian word “” assuming a role of “adjective” can be calculated through Equation (1) is as follows:
Bi_gram: The probability of occurrence for “” followed by “”×the probability of occurrence for “” followed by “”×probability of occurrence for “” followed by “”×probability of occurrence for “” followed by “”×probability of occurrence for “” followed by “”. [32, 50].
In this statistical work, the fuzzy system was trained by 194 different phrasing styles in the Persian grammar. In total, the training involved 76274 words in 16 roles displayed in Table 1.
The number and symbol of each role for fuzzy system training and statistical work
The number and symbol of each role for fuzzy system training and statistical work
In Table 1, “letters and verbs” were excluded from statistical computations because they were imported exactly from the type of words, i.e. decomposition of sentences. Therefore, verb, noun, infinitive in decomposition, adjective, pronoun, marker, pseudo-sentence served as type of words input to the system. In Table 1, rows 1 to 4 indicate predicate, subject, object and complement as the main or independent roles. Meanwhile, rows 7 through 17 indicate dependent adverb, adjective, governing genitive, genitive, apposition, governing transducer, bending, retroactive, exclamation and annunciator as dependent roles in Persian grammar. In Table 1, it should also be noted that symbols of roles in Persian have been included. In case of dependent roles, there might be words assuming unknown dependent roles, represented by “–”. There are generally 12 dependent roles, 4 independent roles, and 2 common roles involved in the decomposition and composition in this research. The identification of sentence roles in Persian texts might be affected by numerous items extracted from the Persian grammar. Below are 5 effective items in the role of words or conversion of each word type into a specific role described through the two basic classes of N_gram labeling and presence percentage computations. Therefore, 5 statistical matrices in fuzzy computations were obtained as follows.
This matrix was obtained by initial computations delivering the “probability of occurrence” for each independent/dependent role in each type. At first, we extracted roles and types for 194 types of training phrasing compositions. Then, the total number of role substitutions in types was obtained, followed by examining each specific role in terms of how many roles there are in each type. Finally, the value of each substitution was calculated through Equation (2).
Equation 2: Average presence of each role in each type
The computational output of Equation (2) is a 10×21 matrix. In this regard, 10 is the number of words in decomposition while 21 is the total number of independent + dependent + spacing characters “” + common roles between decomposition and composition). Given Equation (2), it is clearly understood that the values are fuzzy.
The values from Equation (2) were obtained based on the correct type and independent correct and dependent roles of words in 194 training sentences as well as Persian grammar textbooks, NLP Tools v 1.3.3 (product of Web Technology Lab of Ferdowsi University of Mashhad) and experts in the Persian language [1, 26].
One example for 4 different phrasing modes with inputs “” meaning I read the book. This was one input sentence “pronoun, noun, marker, verb” as the type of words, while the other input to the system has been displayed in Table 2.
Calculation procedure for each possile phrasing mode according to Equation (3)
Calculation procedure for each possile phrasing mode according to Equation (3)
The values in Table 2 are hypothetical only illustrating the stages and computational procedure. The matrix derived from this stage can somehow be considered Uni_gram because computations are not dependent on previous/next roles.
This matrix deals with to the placement of each role in the sentence. The percentage of cases where each role is found in a place can offer the positive feature of HMM benefiting from initial probability in its computations, while examining the initial probability of other probabilities. This matrix is calculated as follows:
According to Equation (3), this is a 26×21 matrix, in which 21 represents the total number of roles in Persian grammar and spacing characters. Meanwhile, 26 for variable j indicates that computations covers up to 26-word sentences. In addition, it was found that values in Equation (3) is completely fuzzy since the computations are average within [0, 1]. Nonetheless, the Member_Word matrix can be considered Uni_gram through labeling because it is fully independent of previous/next words or previous/next roles.
Table 3 provides certain elements of this matrix.
Overview of Member_Word matrix
Overview of Member_Word matrix
Table 3 shows only 4 main roles and one unknown role associated with dependent roles in 4-word sentences.
This matrix is derived from two statistical stages
1. Firstly, Equation (4) obtained the presence probability of each letter and the next letter in the training sentences and words. The output of this 44×44, 2D matrix to a total of “” (inclu-ding the Persian alphabet letters, both isolated and medial) as well as a few characters used in multi-component words including spacing character and other signs and characters in Persian texts.
Equation (4): Average presence of each role in each type
A 44×44 matrix yields 4 independent roles and 12 dependent roles, a total of 16, to be included in computations of Stage 2.
2. After obtaining the values for Bi_gram matrix expressed in Equation (4), we achieved word weights for each input through conversion of Equation (1) to Bi_gram based on Equation (5). Table 4 provides the Bi_gram computation procedure for Equation (5).
Equation (5): Bi_gram Labeling for each input word.
In Equation (5), the weight of each word is computed through Bi_gram labeling. It is worth noting that Equation (5) covers only one word. For all words in each input sentence, a matrix was obtained with a length equivalent to the number of words in input sentence×21). Therefore, the number of words and letters were represented by n and m, respectively. As described above, 21 indicates the total number of the roles in the Persian grammar and spacing characters.
For example, if the input sentence is “”. and the sentence mode is “subject, object, marker, verb”, Table 4 provides the computations with hypothetical values according to Equations (5) and (4).
Len_Word computational procedure for a 4-word, 4-role sentence
Len_Word computational procedure for a 4-word, 4-role sentence
In Table 4, the value of 1 is considered for computations in rows 3 and 4 are not performed since they are shared between type and role.
This 21×21, 2D matrix is equivalent to the number of sentence roles in Persian+spacing characters. In fact, the statistical computations specified the frequency of a specific role. The total number of presence frequencies for all roles following a specific role were obtained, while calculating average values through Equation (6).
Equation (6): Average presence of each role after another role
In fact, this Bi_gram matrix adopts a forward approach similar to Len_Word matrix, except that Len_Word examines letters in forward mode, whereas Composition_Role views roles as forward.
Table 5 provides the main roles.
Part of Composition_Role Matrix For Basic Rol
Part of Composition_Role Matrix For Basic Rol
As shown in Table 5 and Equation (6), the values of Composition_role matrix are all fuzzy falling within [0, 1].
In this 10×21, 2D matrix, 10 represents the total number of “word types + spacing characters” while 21 represents the total number of “sentence roles in Persian + spacing characters’’. There are 7 word types in Persian sentences including “verb, noun, infinitive in composition, adjective, pronoun, marker, and pseudo-sentence. This matrix was obtained in 194 different Persian phrasing modes selected as the system trainer based on correct composition and decomposition of words, subject matter experts and a grammar textbook [1]. We specified the total number of presence for each role after a specific word type in ith place at i + 1-th place. Then, we achieved the number of presence for each role after each word type separately, while completing the computations through Equation (7).
Another matrix obtained in fuzzy computations operating forward similar to Bi_gram is called Decompostion_Composition, where each word type in ith place is compared against each word role in i + 1-th place. Table 6 displays several elements of Decompostion_Composition matrix.
Part Of Decompostion_Composition Matrix For Basic Rol
Part Of Decompostion_Composition Matrix For Basic Rol
Table 6 shows only the portion dedicated to independent roles as seen in computations of Equation (7) displayed in Table 6. The values of this matrix are all fuzzy similar to other 4 matrices falling within [0, 1].
In the coding section, along with the statistical measures, there are a variety of possible scenarios with specific probabilities of occurrence in two separate status matrices (double) and ValStatus (long type) depending on the number of words in the input sentence. In the Status matrix, the sequence of roles was summarized through symbols in Table 1. However, both matrices are formed separately for independent and dependent roles, while the matrix lengths are redeemed depending on word lengths. In the main roles, computations rely on the number of matrices achieved according to input sentence , where 9 derives from 2 common roles of “marker and verb’’, 5 main roles and 3 spacing characters. In the dependent roles, the number of matrices changes to 17, which is a sum of 11 dependent roles + 1-word role without unknown dependent role + 3 spacing characters + 2 common roles of “marker and verb” shared between decomposition and composition. It is noteworthy that, if long sentences are imported as system inputs, an overflow error may occur for the two arrays. This should therefore be taken into consideration in coding techniques.
Initial fuzzy computations
The fuzzy computations are implemented after labeling the effective components in adoption of each sentence role in Persian. The stage serves to obtain the best possible combination in each defuzzifier type. As stated above, this research intended to select the best defuzzifier among five candidates. To that end, it was first critical to obtain the best possible sequence in each defuzzifier. In order to achieve the best sequence of 5 matrices in each defuzzifier, we first obtained the value of each matrix separately based on each defuzzifier. This subsequently arranges the matrices in each role from highest to lowest success rates. In this stage, we first achieve the success values for each of 5 matrices in 5 different defuzzifiers (highest degree of membership, average maximums, largest of maximums, smallest of maximums, and mean of maximums). The sequence of matrices has been presented in Section 4.1, involving no particular priority. It should be noted that 3 defuzzifiers “largest of maximums, smallest of maximums, mean of maximums” deliver different outputs only two or more maximum values are extracted for each word from the matrix. Equation (8) is adopted to obtain the average success rate of each role in the initial fuzzy computing section or the main fuzzy computations.
Equation 8: Overall success rate/success rate of each role
Equation 8 involves the total number of each role in 73 input sentences previously extracted based on opinions of Persian grammar experts [1]. Moreover, the correct number is obtained based a role in a specific matrix or specific defuzzifier.
Equation (9) is employed to extract the total weighted average in the initial fuzzy computation or main fuzzy computation stages.
Equation 9: Average or weighted percentage of all roles/independent roles/dependent roles
Equation (9) provides a general formula to obtain the weighted average in independent roles, dependent roles and/or all roles together. In Equation (9), we first achieved the total sum of independent and dependent roles in all 73 input sentences. Then, we obtained the total numbers found in the method in each roles through the specific defuzzification method and in the specific matrix. These were arranged as denominator and numerator of Equation (9), respectively. If the weighted average of dependent/independent roles is considered, then not all roles are included. In the overall set, or the total sum obtained in the specific matrix and defuzzifier, only the sum of those roles is obtained.
Max of membership
This defuzzifier makes decisions based on the largest degree of membership. The generalized computational expression for this defuzzifier can be found in Equation (10).
Equation (10): Maximum membership for discrete fuzzy values
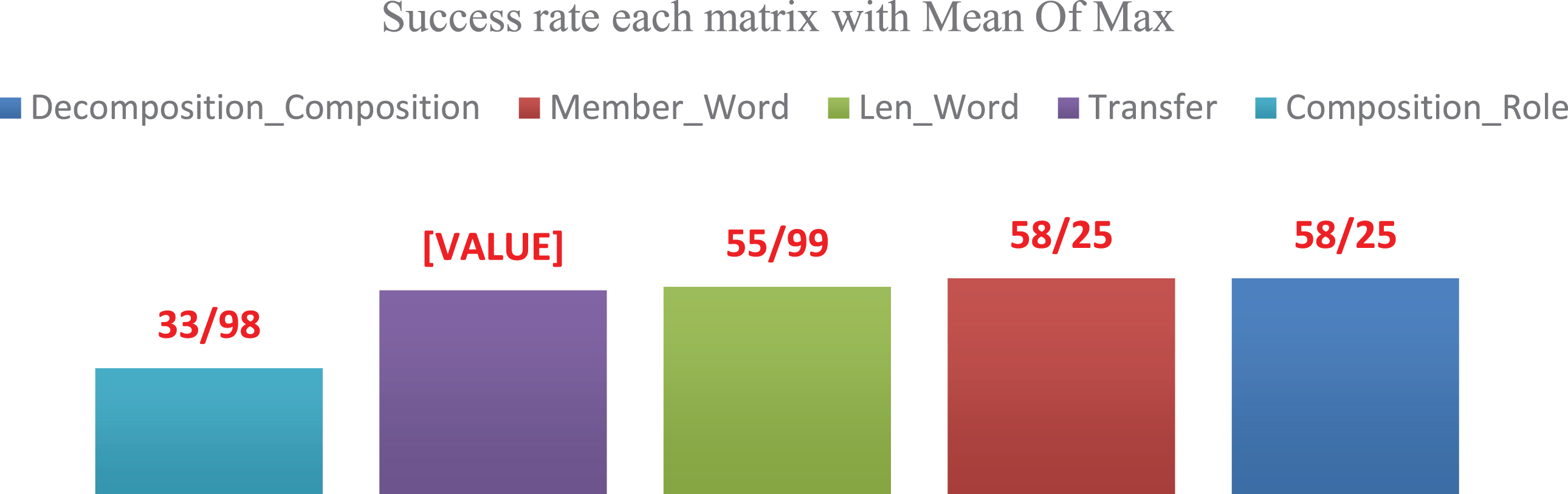
In fuzzy decision-making, it is crucial to decide on every input sentence depending on its decomposition. In addition, Equation (8) has been adopted in the two above-mentioned tables to obtain the success rate of each role, while Equation (9) has been used for the weighted average of all the roles in each category. According to Equation (9), the overall success rates of each matrix in the defuzzifier with the highest degree of membership have been provided in Chart (1). [40, 46].

Overall success rate of each matrix in the defuzzifier with the highest degree of membership.
As shown in Chart (1), the sequence of matrices in Max Of Membership defuzzifier will be as follows: Member_Word Transfer Decompostion_Composition Len_Word Composition_Role
This defuzzifier makes decisions based on the largest of maximums. The generalized computational expression of this defuzzifier can be found Equation (11).
Equation (11): How to obtain the largest of maximums
In the initial line of Equation (11), the maximums are first obtained, and then the maximum with highest rank in the second line is sent as a solution. Therefore, this defuzzifier operates in occasions different from Mean Of Max and Smallest Of Max, where there are several maximums for words in the matrix.
Prior to deciding on the sequence of matrices according to their importance in Largest Of Max, it is necessary to obtain the weighted average of all roles. According to Equation (9), the overall success rates of each matrix in the defuzzifier with the highest degree of membership have been given in Chart (2). [46, 51–53].
As shown in Chart (2), the sequence of matrices in Largest of Max defuzzifier will be as follows: Composition_Role Decompostion_Composition Member_Word Transfer Len_Word
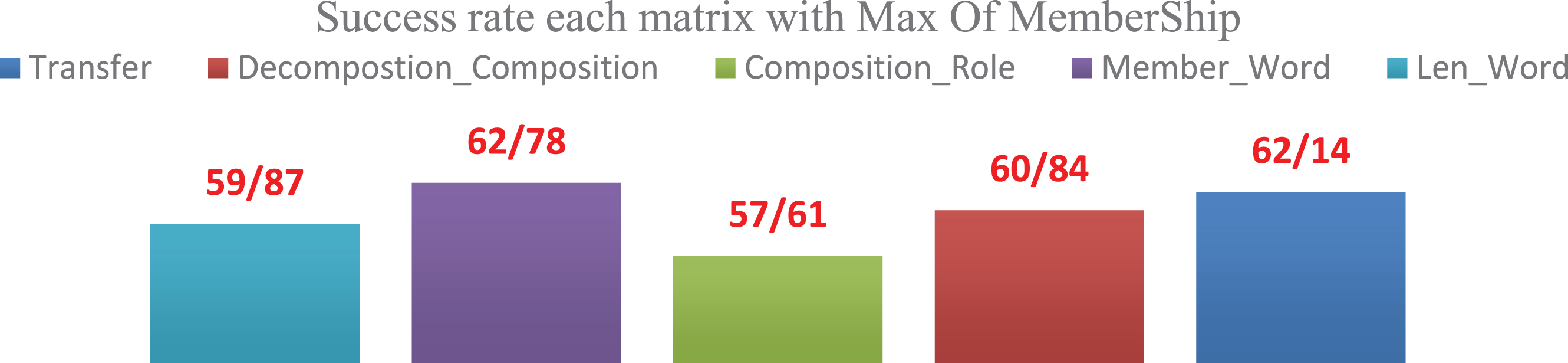
Overall success rate of each matrix in the defuzzifier with largest of maximums.
This defuzzifier makes decisions based on the smallest of maximums. The generalized computational expression of this defuzzifier can be found Equation (12).
Equation (12): How to obtain the smallest of maximums
In the initial line of Equation (12), the maximums are first obtained, and then the maximum with lowest rank in the second line is sent as a solution. Therefore, this defuzzifier operates in occasions different from Mean Of Max and Largest Of Max, where there are several maximums for words in the matrix.
Equation (8) has been adopted in the two above-mentioned tables to obtain the success rate of each role, while Equation (9) has been used for the weighted average of all the roles in each category. Prior to deciding on the sequence of matrices according to their importance in Smallest Of Max, it is necessary to obtain the weighted average of all roles. According to Equation (9), the overall success rates of each matrix in the defuzzifier with the lowest degree of membership have been given in Chart (3). [45, 55].
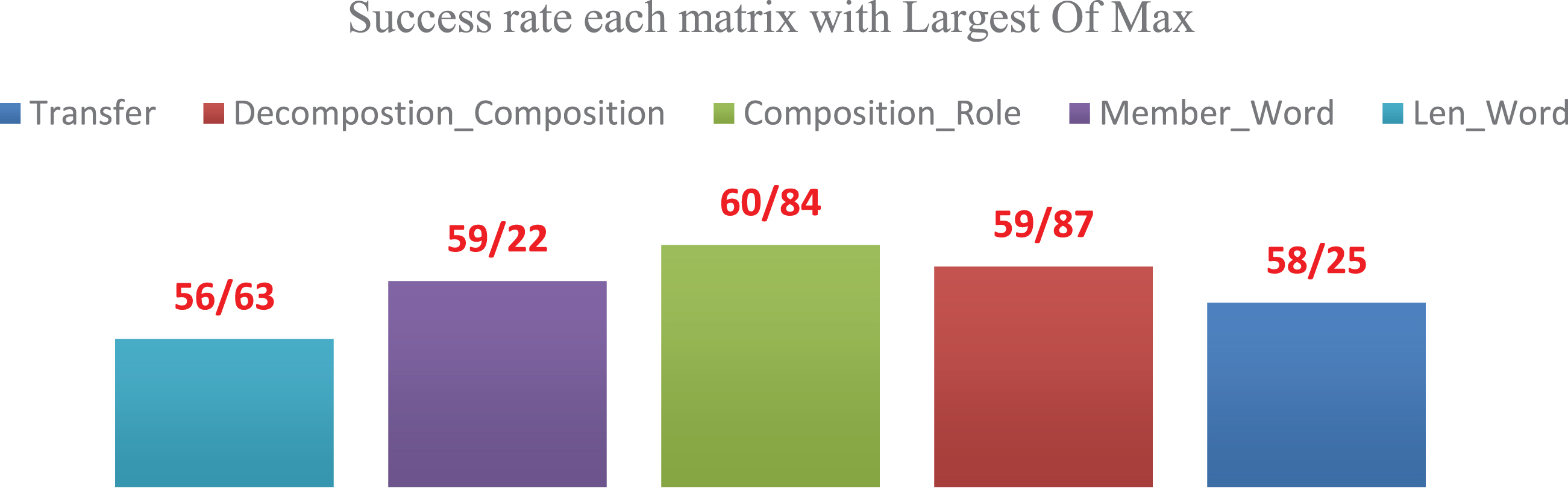
Overall success rate of each matrix in the defuzzifier with Smallest of maximums.
As shown in Chart (3), the sequence of matrices in Smallest of Max defuzzifier will be as follows: Member_Word Decompostion_Composition Transfer Len_Word Composition_Role
This defuzzifier makes decisions based on the mean of maximums. The generalized computational expression of this defuzzifier can be found Equation (13).
Equation (13): How to obtain the average maximums
In the initial line of Equation (13), the maximums are first obtained, and then the maximum with lowest rank as x j , highest rank as x j and average of the two in the second line is sent as a solution. Therefore, this defuzzifier operates in occasions different from Largest Max and Smallest Of Max, where there are several maximums for words in the matrix.
Prior to deciding on the sequence of matrices according to their importance in Mean Of Max, it is necessary to obtain the weighted average of all roles. According to Equation (9), the overall success rates of each matrix in the defuzzifier with the mean of maximums have been given in Chart (4). [42, 43].
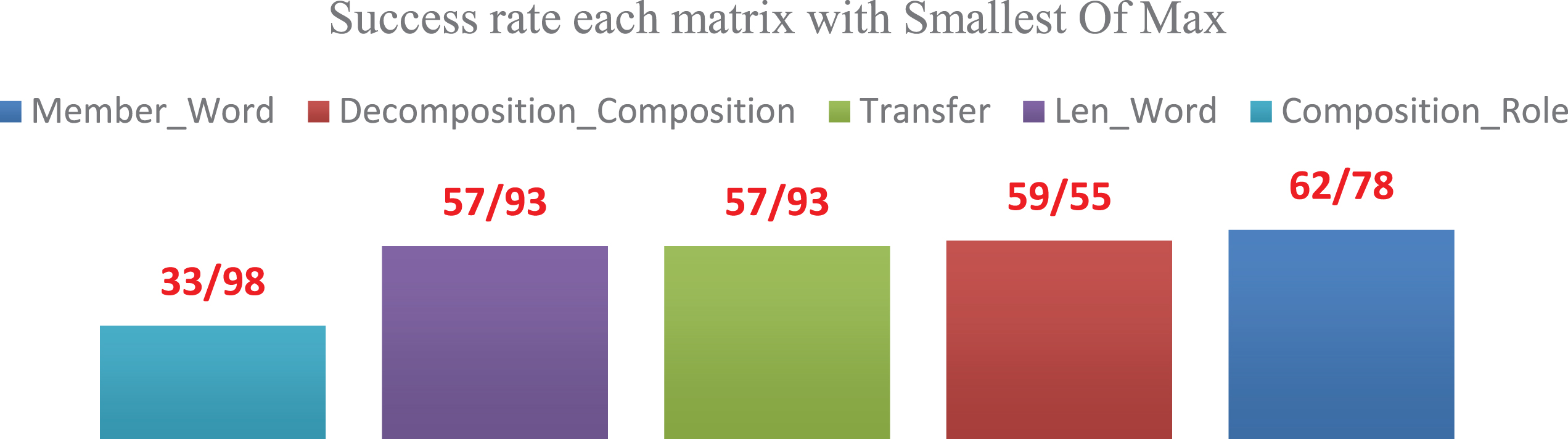
Overall success rate of each matrix in the defuzzifier with mean of maximums.
As shown in Chart (4), the sequence of matrices in Mean of Max defuzzifier will be as follows: Decompostion_Composition Member_Word Len_Word Transfer Composition_Role
This defuzzifier makes decisions based on the central average of membership elements. The generalized computational expression for this defuzzifier can be found in Equation (14).
Equation (14): How to obtain the average of membership elements
In Equation (14), y-l represents the center of fuzzy set l’. Moreover, w l is the height of fuzzy set. For a better understanding of Fig. 2, Equation (14) has been given below. This defuzzifier is the most widely used option in fuzzy and fuzzy control systems. The advantages include reasonable operation, easy computations, minimal variations in y-l and w l , slight variations in the output (i.e. Z CAVG ), and ultimately good continuity. These three criteria demonstrate that central avg is an ideal defuzzification method.
In fuzzy decision-making, it is crucial to decide on every input sentence depending on its decomposition. According to Equation (9), the overall success rates of each matrix in the defuzzifier with the mean degree of membership have been provided in Chart (5). [41, 45].

Overall success rate of each matrix in the defuzzifier with the mean degree of membership.
Central average of membership elements.
As shown in Chart (5), the sequence of matrices in Central Average defuzzifier will be as follows: Member_Word Transfer Decompostion_Composition Composition_Role Len_Word
In Section 4.3, each matrix has been arranged in descending order in each of the 5 defuzzifiers. At this stage, we followed the sequence of each defuzzifier for implementation of fuzzy classes. Therefore, a general algorithm was provided for each of the five defuzzifiers to arrange the classified fuzzy computations accordingly. Algorithm (1) illustrates the general computational procedure in the classified fuzzy.
Algorithm (1): Overall classified fuzzy algorithm
Start Obtain the number of possible modes Implementation of defuzzifier’s first class Maintaining 20% of the largest possible modes and removing the rest of possible modes Implementation of defuzzifier’s second class Maintaining 20% of the largest possible modes and removing the rest of possible modes Implementation of defuzzifier’s third class Maintaining 20% of the largest possible modes and removing the rest of possible modes Implementation of defuzzifier’s fourth class Maintaining 20% of the largest possible modes and removing the rest of possible modes Implementation of defuzzifier’s fifth class Obtaining the largest possible number of possible modes and sending it to the output as the roles of those input words. End
According to Algorithm (1), 80% of possible modes is removed in each stage. This offers two major advantages: 1) the highest values will be effective in any matrix achieving the highest percentage of success, 2) the computational load is significantly reduced in each stage.
Results
After coding and implementing Algorithm (1), we obtained the outputs of each of the 5 defuzzifiers, so as to present the best option. Hence, Chart (6) displays the overall success rate of each of the five defuzzifiers.
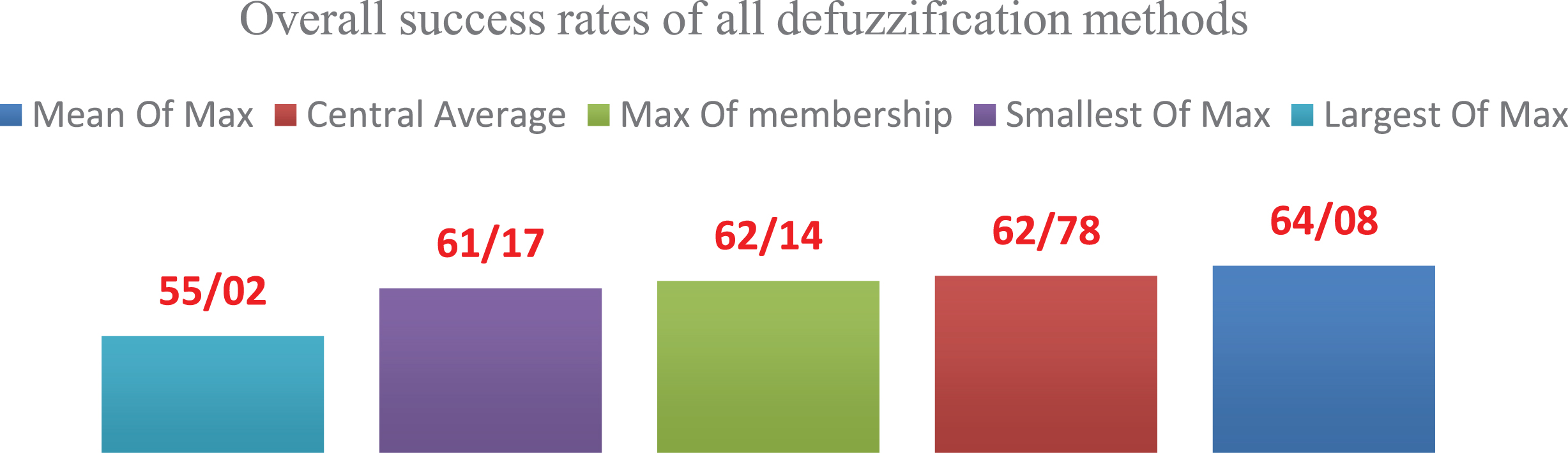
Overall success rate of each of the defuzzifiers with classification of matrices.
According to Chart (6), the best classified defuzzifier in identification of sentence roles in Persian among 5 different Mean Of Max defuzzifiers.
In each value obtained in Chart (6), two categories of dependent and independent roles are effective. Hence, the success rates of independent roles have been displayed in Chart (7) based on various defuzzification methods and classified fuzzy method.
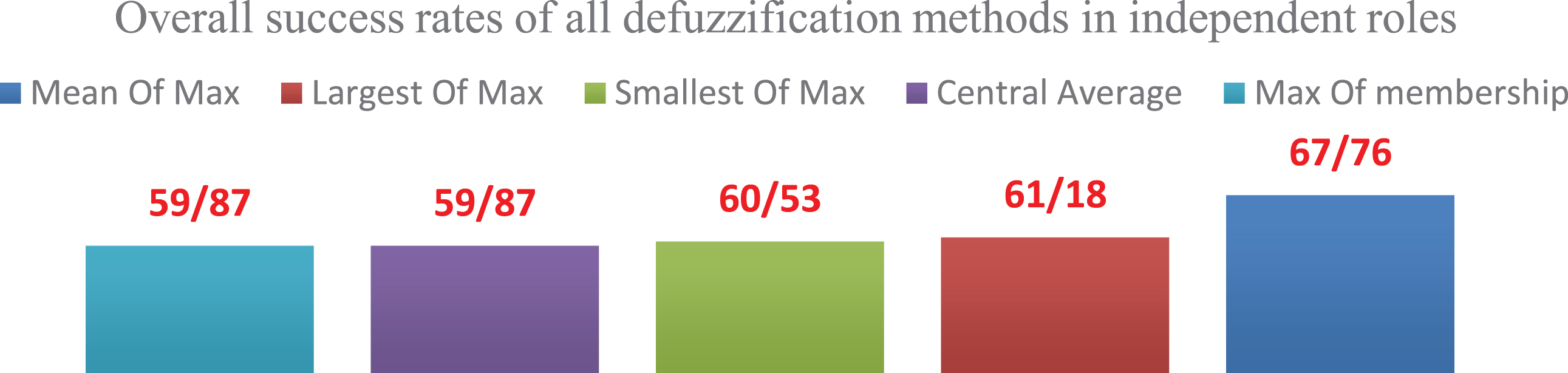
Overall success rate of dependent roles in each defuzzifier with classification of matrices.
As shown in Chart (7), the overall sequence is slightly disrupted in independent roles. In the first place, there is the Mean Of Max defuzzifier, Smallest Of Max in the second place, Largest Of Max in the third place, Central Average and Max Of Membership in the fourth and fifth places, respectively. Chart (7) indicates a significant relationship in the first three places, which implies that the three defuzzifiers dealing with membership maxima yield the best results in the output of independent roles.
Chart (8) provides the overall success rates of dependent roles separately for each defuzzifier in the classified fuzzy.

Overall success rate of independent roles in each defuzzifier with classification of matrices.
As seen in Chart (8), there is a significant difference in the sequence of success rates in two categories of independent and dependent roles. Therefore, in the category of dependent roles with classified fuzzy, Central Average falls in the first place, Max Of Membership in the second place, Smallest Of Max in the third place, Mean Of Max in the fourth place, and Largest Of Max in the fifth place. Nevertheless, the main roles proved to be more successful than the first two places in two categories of independent and dependent roles.
Chart (9) displays the success rate of each main role in each defuzzifier.

Success rate of dependent roles in each defuzzifier with classification of matrices.
As seen in Chart (9), the Mean Of Max defuzzifier, in the first place among main role defuzzifier, all roles are more or less present, followed by Largest Of Max.
Chart (10) shows the success rate of dependent roles in the classified fuzzy method.
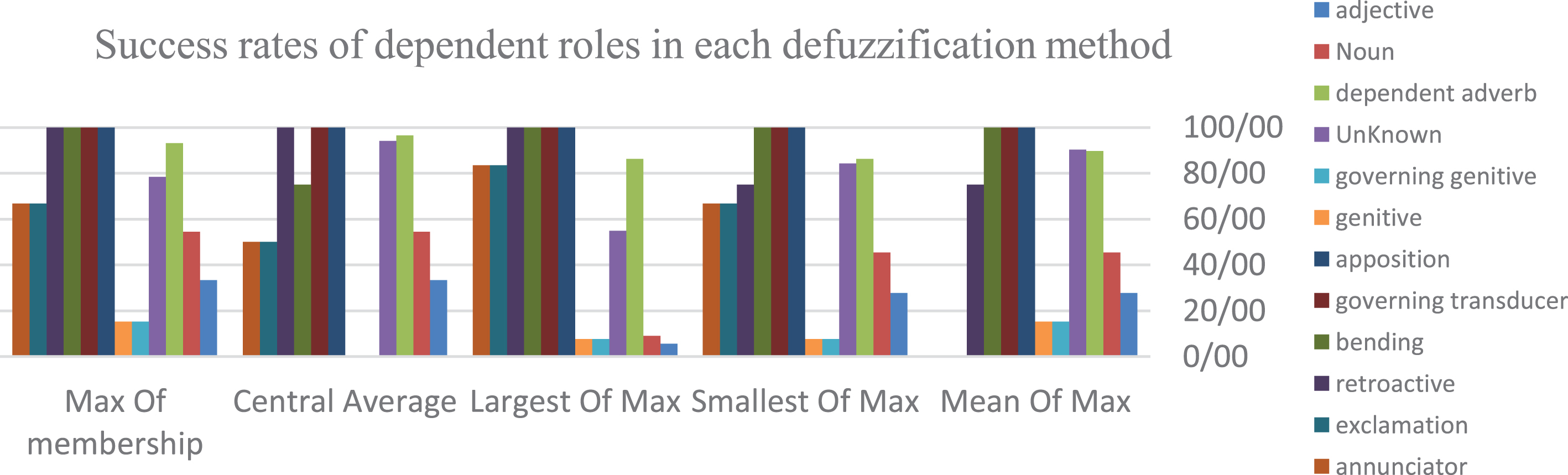
Success rate of independent roles in each defuzzifier with classification of matrices.
In the Central Average defuzzifier at the highest place in dependent role defuzzifier, there is 0% success rate only in two dependent roles of genitive and governing genitive. Meanwhile, success rates were higher in roles with greater weights such as words assuming unknown roles and adverbs. Therefore, the higher or lower places can be directly associated with their presence weights in test sentences or all sentences in the Persian language. On the other hand, certain dependent roles are rarely found in sentences due to the lower weight. In fact, the success rates of such roles may be altered by a correct or incorrect case. Therefore, such roles are less frequently found in Persian grammar.
The main advantage of the newly proposed method is that the number of modes in each place is reduced by 80%. This in turn offers the best options in each class during computations, while substantially decreasing the computational load. Nonetheless, the results in this study suggested that Mean Of Max and Central Average defuzzifiers fell in the first and second places, respectively. Central Average is known as the most ideal defuzzifier in fuzzy systems. However, it achieved the second place in identifying the roles of Persian sentences by a 2% margin. In the third place, there is Max Of Membership, Smallest Of Max in the fourth place and Largest Of Max in the last place with an approximate margin of 10% from the first place. Another notable fact is the 3% difference in the top four places, indicating the tight competition between the four contending defuzzifiers. Despite the fact that the Mean Of Max defuzzifier is not in the first place for most roles, it proved to be more successful than others owing to the heavy weights of roles such as subject.
In each role, however, if the highest percentages are considered, the best results were achieved in the role of “subject” with Max Of Membership and Mean Of Max defuzzifiers together, the role of “predicate and object” with Largest Of Max defuzzifier, the role of complement with Largest Of Max, “Adjective and Adverb” with Max Of Membership and Central Average together, “unknown” with Central Average, “genitive and governing genitive” with Max Off Membership and Mean Of Max, “apposition and governing transducer” with all defuzzifiers, bending with all defuzzifiers except Central Average, “retroactive” with Largest Of Max, Max Of Membership and Central Average, and finally “exclamation and annunciator” with Largest Of Max. For future research, we recommend that fuzzy classification be performed based on the best output obtained by each role among different defuzzifiers.