
Abstract
As the environment issue is put on the agenda, air pollution also concerns a lot. Nitrogen oxide (NOx) an is important factor which affects air pollution and is also the main gas emissions of the smoke and waste gas of FCC unit in petrochemical industry. It is important to accurately predict the NOx emission in advance for petrochemical industry to avoid air pollution incidents. In this paper, convolutional neural network (CNN) and long short-term memory (LSTM) are combined to predict the NOx emission in Fluid Catalytic Cracking unit (FCC unit). Convolutional-LSTM (CLSTM) is able to extract the spatial and temporal features which are essential information in the prediction of the NOx emission. The features in the factors of production which would affect the NOx emission are extracted by CNN which prepares time series data for LSTM. The LSTM layer is connected after CNN to model the irregular trends in time series. CNN, Multi-layer perception (MLP), rand forest (RF), support vector machine (SVM) and LSTM are implemented as baseline models. The results from the proposed CLSTM model showed better performance than all the baseline models. The mean absolute error and root mean square error for CLSTM were calculated with the values of 16.8267 and 23.7089 which are the lowest among all the models. The Pearson correlation coefficient and R2 for the proposed CLSTM model are calculated with the value of 0.9263, 0.8237 which are the highest among all the models. Furthermore, the residual graphs indicate the well matched performance between the observations and the predictions. The study provides a model reference for forecasting the NOx concentration emitted by FCC unit in petrochemical industry.
Introduction
Nitrogen oxide (NOx) is an important part of air pollution which mainly refers to nitric oxide (NO) and nitrogen dioxide (NO2) in the air. Reacting with oxygen, NO is easy to convert to NO2 due to the instability which is toxic to the human body. Furthermore, photochemical reactions would result in more toxic photochemical smog [1]. Besides, the main components of acid rain, nitric acid (HNO3) is also formed by the interaction of NO¬2 with water molecules which would acidify the soil and water resources. For Fluid Catalytic Cracking unit (FCC unit), NOx is one of major emissions released in the flue gas. To control the NOx emission and reduce the probability of air pollution, it is important for petrochemical industry to predict the NOx emission and perform corresponding measures in advance.
NOx emission forecasting is a prediction problem with multivariate time series [2]. Previous methods on forecasting time series mainly include: (1) the prediction analysis methods based on traditional statistics (e.g., autoregressive integrated moving average (ARIMA) [3]), and (2) the machine learning methods. However, it is very difficult to predict NOx emission of FCC unit using traditional statistical prediction methods because of the nonstationary of NOx emission data which contains irregular trends components and complex nonlinear relationship. Therefore, more and more researchers tend to use the machine learning methods.
Artificial neural network (ANN) is a kind of machine learning methods that imitates the mechanism of biological neuron. In 1962, multi-layer perception (MLP) model was proposed [4] which is a neural network with a fully-connected architecture with good performance. However, with the increase of complexity and amount of data, the MLP can hardly model the relationship between inputs and outputs.
Recent studies have shown that deep learning enhance the expressive ability and has broad prospects. In the field of image processing, convolutional neural network (CNN) [5] is superior to the existing methods. Long short-term memory (LSTM) [6, 7] have achieved excellent success in speech recognition and natural language processing (NLP). CNN can extract features of the input data and update the weights of the feature maps without the consideration of temporal information. LSTM stores and updates the long sequential information in hidden memory to capture the dynamics through time. However, in NOx emission prediction problem, the data is time series with various features, which cannot be fully utilized by conventional CNN and LSTM alone.
In this paper, a new architecture of deep neural networks based on the CNN and LSTM was proposed (refer to CLSTM hereafter) to predict NOx emission in FCC unit. This architecture combines the intrinsic advantages of CNN and LSTM which could be used by the petrochemical industries to predict NOx emission and adjust production plans. Some baseline methods (MLP, random forest (RF), support vector machine (SVM) and LSTM) were implemented and compared with CLSTM by mean absolute error (MAE), root mean square error (RMSE), Pearson correlation coefficient (PCCS) and coefficient of determination (R2). The major contribution of this paper is the proposal of a novel architecture which can extract the features in and between sequences. This rest of this paper is organized as follows. The classical machine learning methods and CLSTM are elaborated in Section 2. The experiment and results are illustrated in Section 3. Conclusions are given in Section 4.
Prior research
In many fields, the use of the method that combines CNN and LSTM to examine spatial and temporal information is an area that has received amount of interest. For example, Lieyun Ding et al. proposed a deep hybrid learning model that integrates convolutional neural networks and long short-term memory in [8]. In this instance, the CNN is used to extract visual features from videos and the learning features are sequenced by the LSTM. In air pollution prediction, a deep CNN-LSTM model for Particulate matter forecasting has been proposed by Chiou-Jye et al. [9]. CNN is used to capture the connection between different factors (such as temperature, wind speed, humidity, etc.).
In consideration of this earlier work, in this paper, the framework developed on the basis of AlexNet [10]. The AlexNet, which was developed by Hinton and Alex Krizhevsky, has won the ImageNet competition in 2012. Compared with traditional CNN, AlexNet used ReLU instead of tanh, which reduces the computational complexity of the model and improves the training speed.
Methods
Convolutional neural network
Figure 1 shows the structure of one-dimensional (1D) CNN. The convolution layer of CNN extracts different features of input data through convolution operation which conducted by convolution core [11, 12]. In order to reduce the amount of subsequent processing and persist the effective information, the features extracted from convolutional layer are sampled by pooling layer. Each connection has its own weight, and the connections of the same layer have the same weight. Therefore, the number of weights is much less than that of fully-connected architecture which simplify the training of CNN. The concept of weight sharing is the principal difference and advantage compared to the other deep learning methods. The convolution operation is shown in Equation (1).
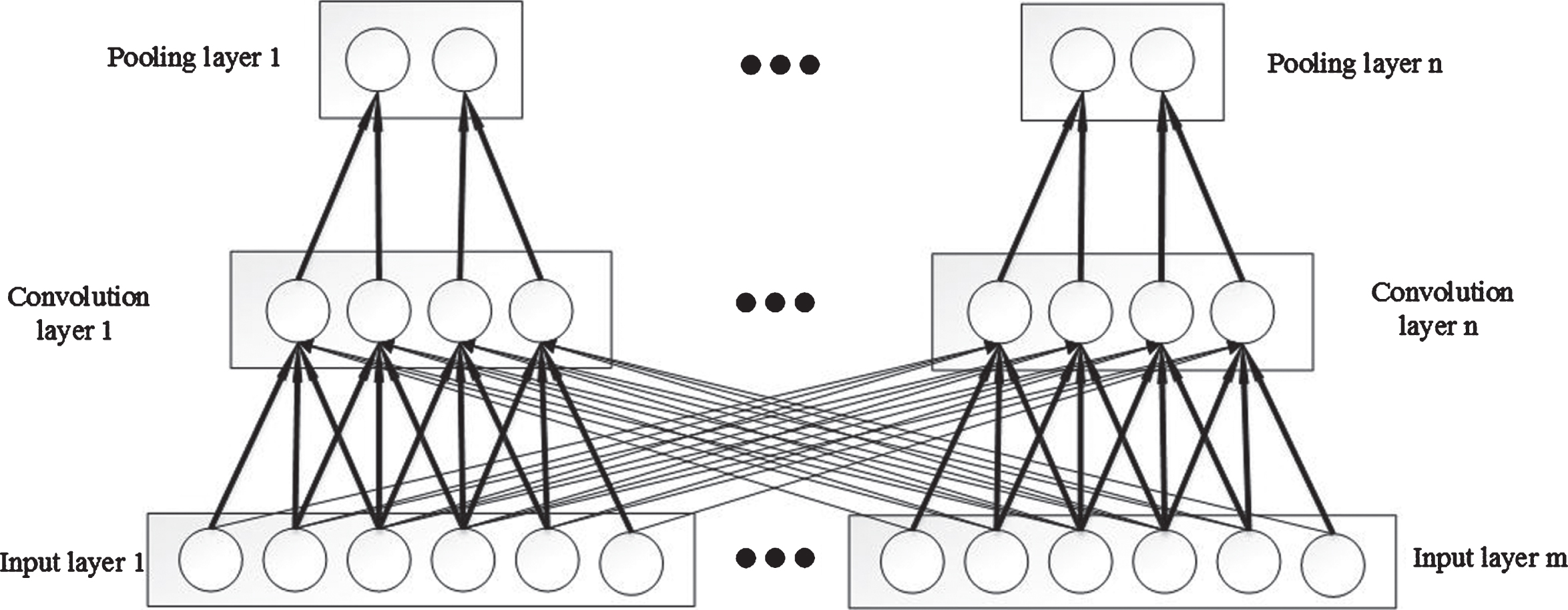
The structural sketches of 1D CNN [13].
Where
Recurrent Neural Network (RNN) has been widely used in speech recognition, language modeling, video processing and other fields. With the increase of time series, gradient disappearance or explosion will happen while training the traditional RNN network. Therefore, researchers proposed LSTM [14] model. LSTM introduces gate mechanism which consists of an input gate, an output gate and a forget gate (Fig. 2). Gate mechanism solves the problem of gradient dispersion in RNN and the long-term dependencies in the data. The formula derivation of LSTM is illustrated in Equations (2)–(7):
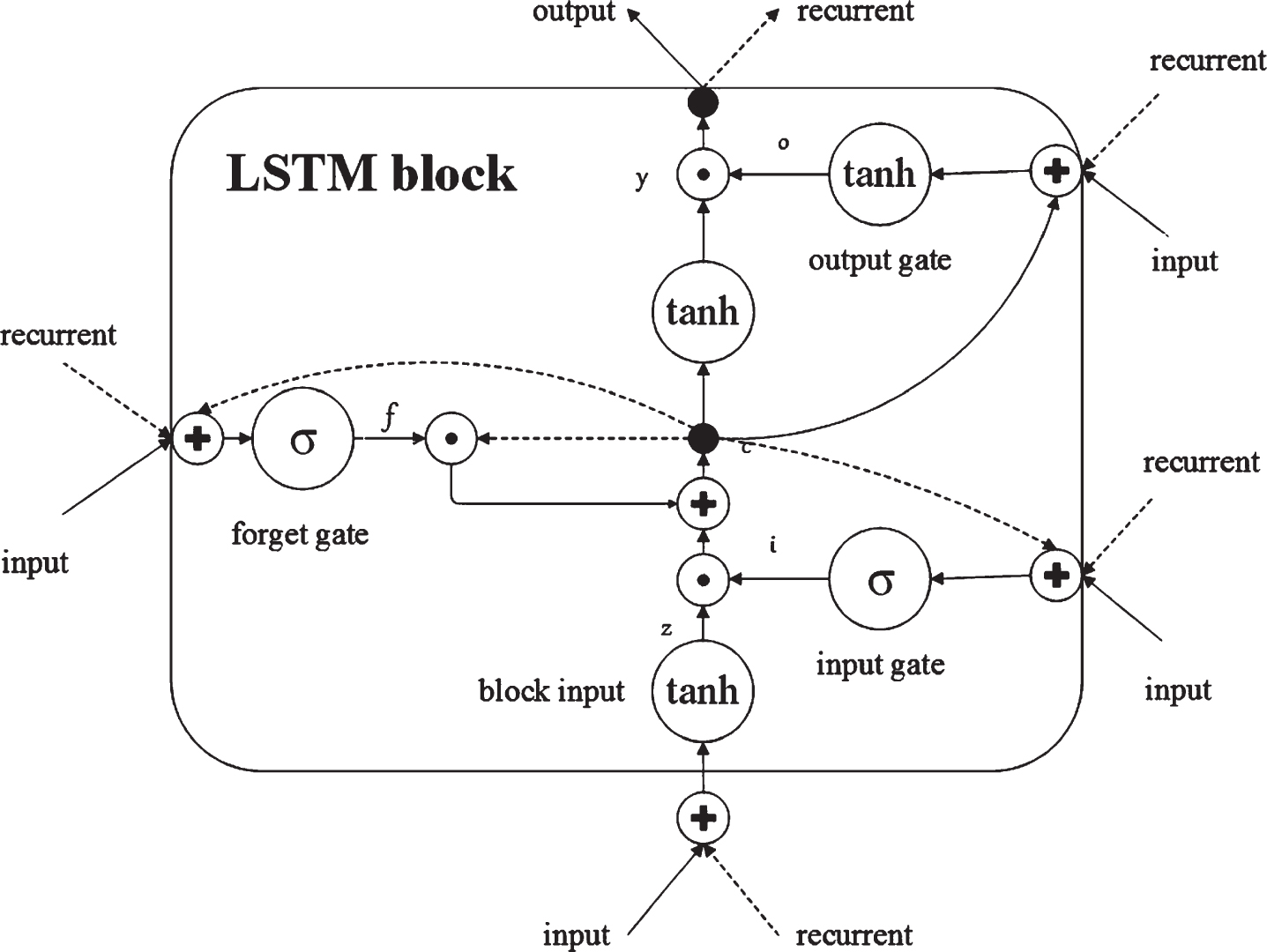
The schematic of LSTM [7].
Where W
f
, W
i
, W
c
and W
o
are input weights; b
f
, b
i
, b
f
and b
o
are bias weights; h
t
is the outputs; x
t
is the input; f
t
is the output of forget gate; i
t
is the output of input gate; O
t
is the output of output gate; C
t
is the cell state, which represents the specific value of a cell at a certain time. It is the only transfer variable between different times, determined by the state of all previous cells and the current input. ‘*’ represents convolution. The σ is sigmoid function, as shown in Equation (8). The tanh is shown in Equation (9).
There are some problems still exist during the training of deep neural networks. For example, a small change of the parameters in one layer may have significant impacts on the outputs of all the following layers because of the large number of layers. Frequent parameter modification will debase the training speed of the deep neural networks. In addition, it will cause data fall into the range that activation function is insensitive, which will make model training failure. To solve these problems, batch normalization (BN) [15] has been proposed, which can make full use of neurons in deep network. By centralizing and standardizing the input of each layer, BN layer can effectively improve the speed and accuracy of network training. The formulas of batch normalization are shown in Equation (10)–(13): operation which conducted by convolution core [11, 12].
Where x
i
is the input value and y
i
is the output after batch normalization; m is the mean of the mini-batch size; μ
B
refers to all the inputs in the same mini-batch; and
To reduce overfitting effectively, dropout was introduced by Hinton [16]. Neurons will be inactivated with probability p when dropout be used (Fig. 3) and the model will not depend too much on local features and specific network structure, which will enhance the generalization ability of the model. Dropout can force the network to be accurate even in the absence of certain information.

Neural network using dropout.
For predicting NOx emission in FCC unit, the proposed CLSTM model is shown in Fig. 4. The architecture consists of three parts: (1) two layers of CNN; (2) an LSTM layer; and (3) three full connected (FC) layers. Detailed descriptions of these three parts are as following.

The architecture of proposed CLSTM.
Two convolution parts (Conv in Fig. 4) are used as the CNN layer of the network structure. The first CNN layer contains 16 kernels of size 1*5, the second layer contains 32 kernels of size 1*5. Each convolutional layer is followed by a ReLU layer in Equation (14) and a max pooling layer. BN is added to the convolutional layer. The outputs of the second CNN part are reshaped to 32-dimensional vector. All the vectors form a sequence and feed into the LSTM layer which will be described in next section.
Where zi,j,k is the input of the activation function at location (i, j) on the k th channel. ReLU allows the neural networks to compute faster than sigmoid or tanh activation function. By using ReLU, deep neural networks can be trained efficiently [17].
In this layer, we employ the same LSTM structure as described in [14]. With the incorporation of the LSTM network, the proposed convolutional-LSTM network can be trained with multivariate time series data of FCC unit. The output of the LSTM layer in this approach is a sequence of 50 dimensional vectors.
Dropout and full-connected layer
The features extracted from the CNN layer are imported into two FC layers. The dropout layers randomly remove connections between CNN layer and FC layer in each iteration to and enhance the generalization ability. In this experiment, the probability has been set to 0.25.
Experiments
Data preparation
The different dimensions will affect the results of data analysis, so it is inappropriate to use the initial data in the training of CLSTM. Data preprocessing consists of the following steps.
Data standardization
In order to eliminate the influence of different dimensions, data standardization is conducted to process initial data. In this paper, Min Max Scaler is used to standardize data as shown in Equation (15-16):
Data must be converted into the supervised learning dataset in time series forecasting problems. We divide the time series into input (x) and output (y) using lag time method, and specifically, in the paper we have used different sizes of lag from 1 to 12.
Divide data into training set and test set
The data was divided into two datasets with training data and verification data. The models were trained with 70% of the observation data and verified with 30% of the observation data.
Performance criteria
The statistical measures used for comparing the model performance are the mean absolute error (MAE) [18], the root mean square error (RMSE) [19], Pearson correlation coefficient (PCCS) and coefficient of determination (R2). MAE in Equation (17) represents the mean value of absolute error between the predicted value and the observed value. It can avoid mutual cancellation of errors, and accurately reflect the size of actual prediction error.
RMSE reflects the deviation between predicted and observed values, the formula of RMSE is shown in Equation (18):
PCCS is used to measure the correlation between two variables. Its value is between -1 and 1. The greater the value of PCCS, the stronger the correlation. The formula of PCCS is shown in Equation (19):
for Equations (14), (15) and (16), N is the length of the data. o n is mean of observed values and p n is mean of predicted values.
The R2 reflects the fitting degree of the model. The formula of coefficient of determination is shown in Equation (20):
Where SSR refers to regression sum of squares, SST refers to total sum of squares. p
n
is mean of predicted values.
To prove the validity of the proposed CLSTM model for NOx emission in FCC unit. We conducted experiments using CNN, SVM [20, 21], MLP, RF [22, 23] LSTM. Models run 10 times to avoid the occasionality. The inputs of models are the concentration of NOx emission and other factors that can affect the NOx emission (i.e., material quantity, temperature of flue gas, temperature of dense bed and main air flow). The outputs are the NOx emission concentration of the next hours.
In the training process of CLSTM model, Adaptive Moment Estimation (Adam) [24] is used as the optimization algorithm. Adam obtains the advantages of Adaptive subgradient (AdaGrad) [25] and Root Mean Square Prop (RMSProp) [26]. Table 1 shows the concrete setting of the other models. The evaluation of different methods includes three aspects.
Parameters for machine learning methods
Parameters for machine learning methods
Figure 5 includes the performance of 10 experiments of machine learning models. SVM, MLP, RF, LSTM are adopted for comparison. Table 2 shows the average of 10 experiments. We have compared the statistical measures with the classical machine learning models in Fig. 5 and Table 2. By analyzing these statistical measures, we can conclude that the excellent performance of 16.8267 MAE, 23.7089 RMSE, 0.9263 PCCS and 0.8237 R2 in CLSTM.

The Statistical measures of 10 experiments.
Performance comparison of machine of machine learning
Figure 6 shows the residual graphs of all machine learning models in this paper. Residual graphs are used to estimate whether the residual of the predicted value is consistent with the random error [27], and it should not contain any interpretable and predictable information in residual. The residuals of the predicted and observed values are taken as ordinates and the predict values as abscissas. As we can see, in the whole range of abscissa, only the points on the residual graph of the proposed CLTM model are evenly spread on both sides of 0, although there are a few points with irregular distribution. The distribution of residuals effectively reflects the randomness and unpredictability. It indicates that CLSTM can fully capture the predictable information in the data of NOx emission.

The residual graph of machine learning models.
As the information belonging to the enterprise internal data, we intercepted a part of the prediction results and scale the values, which is shown in Fig. 7 The green curves refer to the observed value and the red curves represent the predicted value. As we can see that the proposed CLTM model achieves high performance at both global and local time periods.

The predicted results graph of machine learning models.
In this paper, the CLSTM model have been proposed for forecasting of NOx emission in FCC unit. The difficulties in predicting NOx emission in FCC lie in the properties of data with multivariate time series. The proposed CLSTM model accurately predicts NOx emission in FCC unit with low computational costs which benefit by the extraction ability of CNN between different sequences. The accuracy of CLSTM is further enhanced by the inclusion of LSTM layer. We compared the CLTM model with the classical machine learning models such as CNN, MLP, RF, SVM and LSTM. Better performance was achieved from CLSTM than that from the classical machine learning models. On the other hand, the CLSTM model relies on large efforts to determine the optimal hyperparameters. Although there are some methods to solve this problem, it is still a limitation of CLSTM. Future works include eliminate the influence of noise and effectively feature extracting in the CNN layers.
Footnotes
Acknowledgments
The authors would like to thank the associated editors and the reviewers for their precious time and efforts in reviewing our paper and providing constructive comments to improve the paper. This work was supported by Science Foundation of China University of Petroleum-Beijing under grant No. 2462018YJRC007, Research on Prediction and Early Warning System of Air Pollution Emission in Catalytic Fracture Device and New Control Model” under grant No. 2017D-5008.