
Abstract
The condensed nearest neighbor (CNN) is a pioneering instance selection algorithm for 1-nearest neighbor. Many variants of CNN for K-nearest neighbor have been proposed by different researchers. However, few studies were conducted on condensed fuzzy K-nearest neighbor. In this paper, we present a condensed fuzzy K-nearest neighbor (CFKNN) algorithm that starts from an initial instance set S and iteratively selects informative instances from training set T, moving them from T to S. Specifically, CFKNN consists of three steps. First, for each instance
Introduction
K-nearest neighbor (K-NN) [1] is a simple classification algorithm that only calculates the distances between test instances and training instances, but not trains classification models. Although K-NN has been successfully applied in many fields [2–7], it has the following two drawbacks [8]:
(1) High computational complexity. For classifying a test instance, K-NN calculates the distances between this instance and all training instances. In addition, the entire training set must be loaded into memory.
(2) K-NN is sensitive to noise. When the training set contains noisy instances or error instances, the performance of the K-NN algorithm will be seriously deteriorated.
To overcome the first disadvantage of K-NN, researchers proposed instance selection based solutions, which select a subset S from the training set T, and replace T with S for classification. The pioneering work of instance selection for K-NN is the condensed nearest neighbor (CNN) algorithm proposed by Hart [9]. Based on CNN, many instance selection algorithms for K-NN have been proposed, which can be roughly classified into three categories [8]: incremental, decremental, and hybrid algorithms.
Starting from an initial set S, incremental algorithms gradually select important instances based on instance selection criteria from the set T and add them to S until the predefined halt conditions are met. The set S can be initialized to an empty set or by several instances randomly selected from T. CNN is an incremental algorithm which first initializes S with one instance randomly selected from T, and then iteratively selects instance from T one by one. Specifically, if an instance
Starting from an initialization S=T, decremental algorithms gradually remove unimportant instances from S based on some criteria until the predefined stop condition is met. The representative works include the reduced nearest neighbor (RNN) [16], the minimal consistent set (MCS) [17] , and the decremental reduction optimization procedure (DROP) [18]. RNN [16] is an extension of the CNN, and it starts from S selected by the CNN from T. For each instance
Hybrid algorithms combine incremental algorithms and decremental algorithms. During instance selection, the instances in S may be added or deleted. Intuitively, the performance of hybrid algorithms should be better than that of the incremental and decrement algorithms. However, the computational complexity of hybrid algorithms is high since extra measurements of the importance of the instances in S are required. Therefore, researchers pay less attention to hybrid algorithms.
To overcome the second disadvantage of K-NN, Keller et al. [20] introduced the fuzzy set theory into K-NN, and proposed fuzzy K-NN which extended K-NN from deterministic scenarios to fuzzy scenarios. Since there are many phenomena with fuzziness in the real world, fuzzy set theory [21] has received more and more attention from researchers in a wide range of scientific areas, and has been applied to wide range of fields. Many methods have been proposed by different researchers, the details can be found in several review literature [22–24] published in recent years. Although fuzzy K-NN can effectively surmount the second drawback of K-NN, it does not overcome the first disadvantage of K-NN. To the best of our knowledge, only Zhai et al. [25] conducted a preliminary study on the instance selection for fuzzy K-NN. In this paper, we present a further investigation on this topic. The main contributions of this paper include the following three folds.
(1) We propose a simple yet effective instance selection algorithm called condensed fuzzy K-NN (CFKNN), which is more effective and efficient than the algorithm presented in [25]. The effectiveness is due to the use of dynamic thresholds, and the efficiency is due to the efficient calculation of the fuzzy membership degrees of the K-nearest neighbors using S rather than T. (2) We find that there are significant differences between the suitable thresholds for the selection of instances from different datasets with the proposed algorithm.
(3) Extensive experiments are conducted to demonstrate the effectiveness of the proposed algorithm by comparing with four state-of-the-art algorithms using metrics of number of selected instances, compression ratio, and testing accuracy.
The rest of this paper is organized as follows. In section 2, we review the related works. In section 3, we describe the details of the proposed method. In section 4, extensive experiments are carried out to verify the effectiveness of the proposed algorithm by comparing it with four state-of-the-art methods on three aspects: the number of selected instances, the compression ratio, and the testing accuracy. At last, we conclude our work in the section 5.
Preliminaries
In this section, we briefly review the preliminaries related to our work, including K-nearest neighbor, condensed nearest neighbor, and fuzzy K-nearest neighbor.
K-nearest neighbor
The idea of K-nearest neighbor (K-NN) [1] is very simple. Given a training set T and a test instance
Training set T = {(
y ∈ Y.
1: For(i = 1 ; i ≤ n ; i = i + 1)
2: Calculate d (
3: Find K instances in T that are closest to
4: Count votes for each class by
5: return y.
Condensed nearest neighbor
The condensed nearest neighbor (CNN) [9] is an instance selection algorithm for K-NN. Let T be a training set, and S be the set of selected instances. CNN firstly initializes S by an instance randomly selected from T, then it iteratively selects important instances from T, and move them from T to S. The important instances are those classified incorrectly by K-NN with S. The pseudo-code of the CNN algorithm is given in Algorithm 2.
Training set T = {(
S ⊆ T.
1: S =∅;
2: Randomly select an instance from T, and move it from T to S;
3: Repeat
4: For(∀
5: For(∀
6: Calculate the distance between
7: Find the nearest neighbor
8: If(
9: S = S ∪ {
10: T = T - {
11: until (T =∅ or all instances in T are classified correctly by K-nearest neighbor algorithm);
12: return S.
Fuzzy K-nearest neighbor
The fuzzy K-nearest neighbor (Fuzzy K-NN) [20] is an extension of K-NN to the fuzzy scenario, it can overcome the second drawback of K-NN. Given a test instance
In fuzzy K-NN, the fuzziness plays three roles in improving the performance of K-NN.
(1) For a given test instance
(2) For a given test instance
(3) Fuzziness can enhance the robustness of the classification algorithm to noise.
The pseudo-code of the fuzzy K-nearest neighbor algorithm is given in algorithm 3.
Training set T = {(
μ
j
(
1: For(i = 1 ; i ≤ n ; i = i + 1)
2: Calculate d (
3: Find K instances
4: For(i = 1 ; i ≤ K ; i = i + 1)
5: For(j = 1 ; j ≤ l ; j = j + 1)
6: Calculate μ ij with Eq. (2);
7: For(j = 1 ; j ≤ l ; j = j + 1)
8: Calculate μ
j
(
9: return μ
j
(
In this section, we present the CFKNN algorithm, which can be viewed as an instance selection algorithm for fuzzy K-NN or an extension of CNN to the fuzzy scenario (see Figure 1).
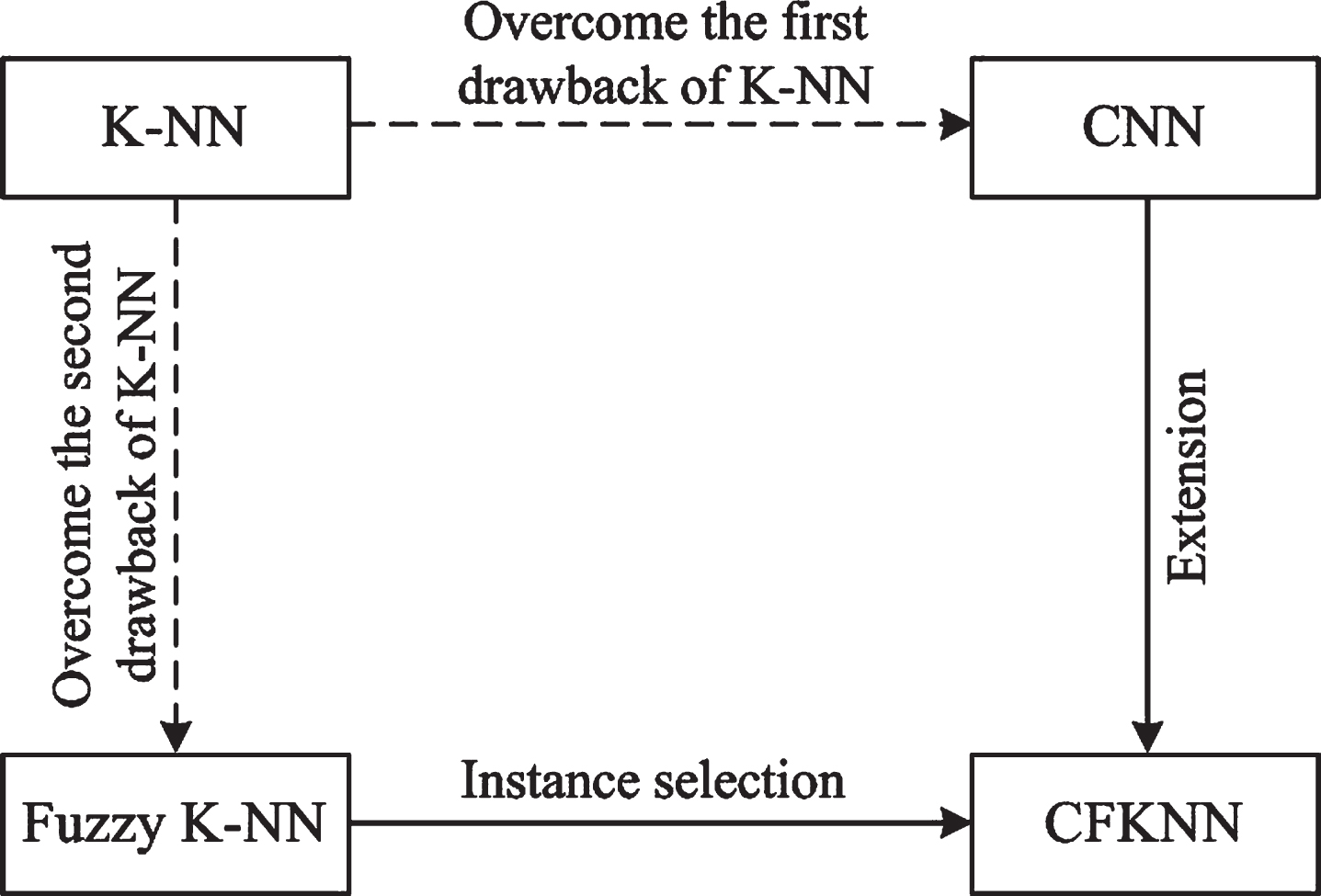
The technical route (solid line) of the proposed algorithm.
CFKNN differs from CNN in the following three aspects: (1) CFKNN is tailored for K-NN rather than the 1-nearest neighbor in CNN, and it uses K instances randomly selected from each class to initialize the set S. (2) Given a test instance

The relationship between the number of classes and the maximum entropy.
From the pseudo-code in Algorithm 4, we can easily find that the computational complexity of Algorithm 4 is determined by the “for loop" consisting of steps 2 to 6. The computational complexity of step 3 is O (n × s), s is the number of instances in S. In the worst case, the computational complexity of step 3 is O (n × n). The computational complexities of step 4 and step 5 are both O (K × l), where l is the number of classes. Since K and l are both small numbers, the computational complexities of step 4 and step 5 can be viewed as O (1); The computational complexity of step 6 is O (l), which can be also viewed as O (1). Hence, in the worst case, the computational complexity of Algorithm 4 is O (n × n) + O (1) + O (1) + O (1) = O (n2).
Training set T = {(
S ⊂ T.
1: Initialization: randomly selected K instances from each class to initialize the set S, and move the K instances from T to S;
2: For(each
3: Find its K nearest neighbors in S;
4: Calculate the fuzzy membership degrees of the K nearest neighbors of
5: Calculate the fuzzy membership degree of
6: Calculate the entropy of
7: If(E (
8: S = S ∪ {
9: return S.
To verify the effectiveness of CFKNN, we conducted extensive experiments on 11 datasets, the experiments include two parts: (1) The investigation of the impact of threshold on the performance of CFKNN, (2) The comparison with 4 state-of-the-art algorithms: CNN [9], edited nearest neighbor (ENN) [12], Tomeklinks [10], and OneSidedSelection [27]. The 11 datasets include 1 artificial dataset, 2 real world datasets [25], and 8 UCI datasets [28].
The artificial dataset is generated using two two-dimensional Gaussian distributions p (x|ω i ) ∼ N (μ i , Σ i ) (i = 1, 2), which corresponds to two classes, their mean vectors and covariance matrices are given in Table 1. The 2 real world datasets are the CT and the RenRU dataset. The CT dataset was obtained by collecting 212 medical CT images from a Baoding local hospital. All CT images are classified into 2 classes (i.e., normal class and abnormal class). The CT dataset has 170 normal instances and 42 abnormal instances. A total of 35 features are initially selected including 10 symmetric features, 9 texture features and 16 statistical features including mean, variance, skewness, kurtosis, energy and entropy. The RenRu dataset was created by the Key Laboratory of Machine Learning and Computational Intelligence of Hebei Province, China. The RenRu dataset consists of 148 Chinese characters REN and RU with different typeface, font and size. There are 92 Chinese characters REN and 56 Chinese characters RU. Each Chinese character is described by 26 numerical features. The 8 UCI datasets include WDBC, Parkinsons, Pima, Skin, Iris, Glass, Fertility, and Survival (i.e. Haberman’s Survival). The basic information of the 11 datasets are listed in Table 2. All experiments are conducted on a platform with Intel(R) Core(TM) i3-3120M CPU @ 2.50GHz, 8GB main memory, Windows 10, and Python3.6.3.
The parameters of Gaussian distribution of the artificial dataset
The parameters of Gaussian distribution of the artificial dataset
The basic information of datasets used in experiments
The experiments on the artificial dataset are used for three purposes: (1) to verify the feasibility of CFKNN; (2) to investigate the impact of threshold λ on the results of instances selection, and (3) to more intuitively elucidate the impact of λ by visualizing the distribution of the original instances and the selected instances with different thresholds. The distribution of the instances in the artificial dataset (Gaussian dataset) is illustrated in Figure 3. The distributions of instances selected by CFKNN (k = 5) from Gaussian dataset with λ = 0.5 and λ = 0.6 are given in Figure 4 and 5, respectively. It is observed from Figure 4 and Figure 5 that like most instance selection algorithms, instances selected by CFKNN are distributed near the classification boundary. The experimental results on artificial dataset confirm that (1) the CFKNN is feasible; (2) the threshold λ has significant influence on the experimental results. Next, we will show the impact of threshold λ on the performance of CFKNN.
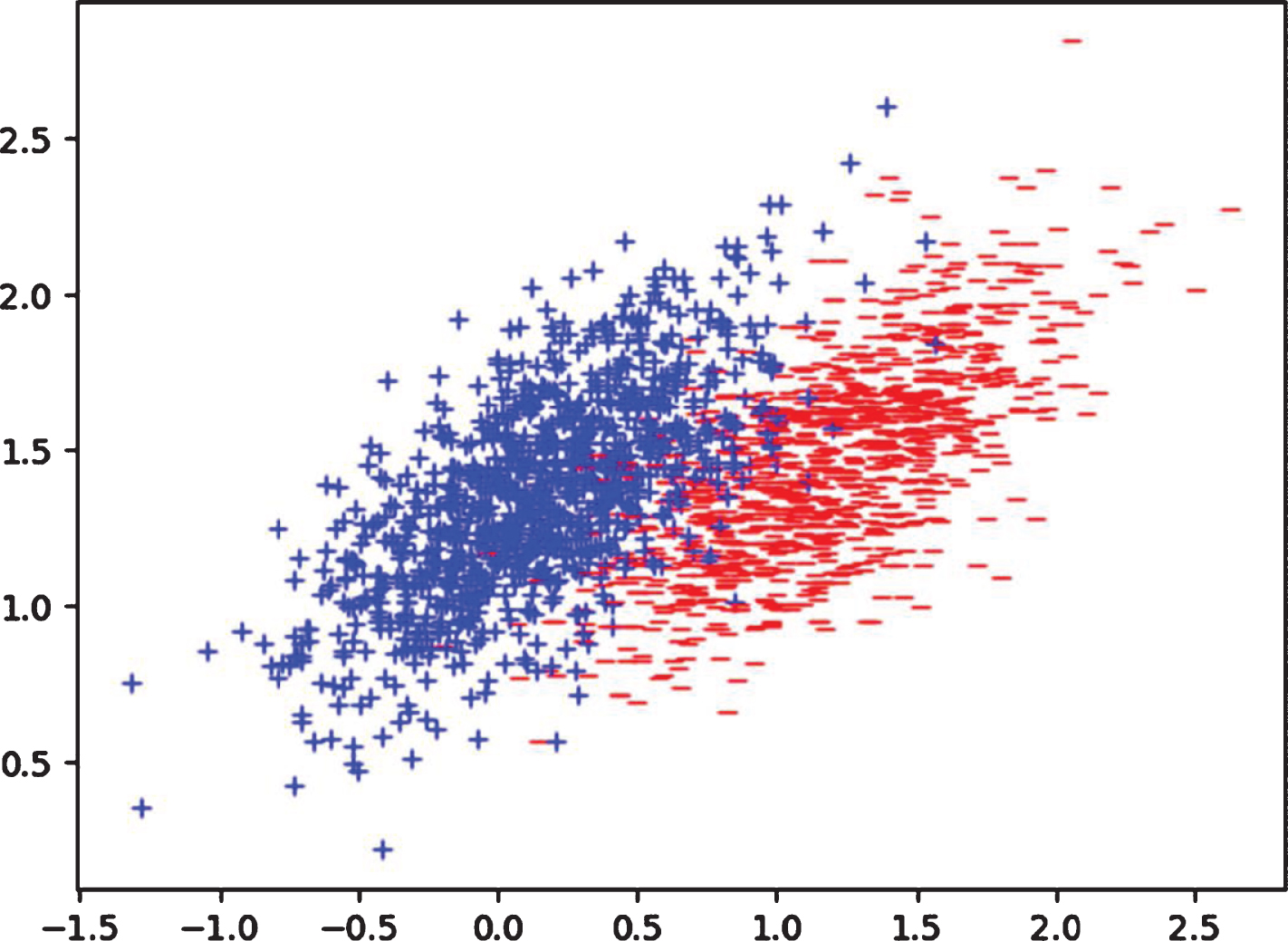
The distribution of instances in Gaussian dataset.
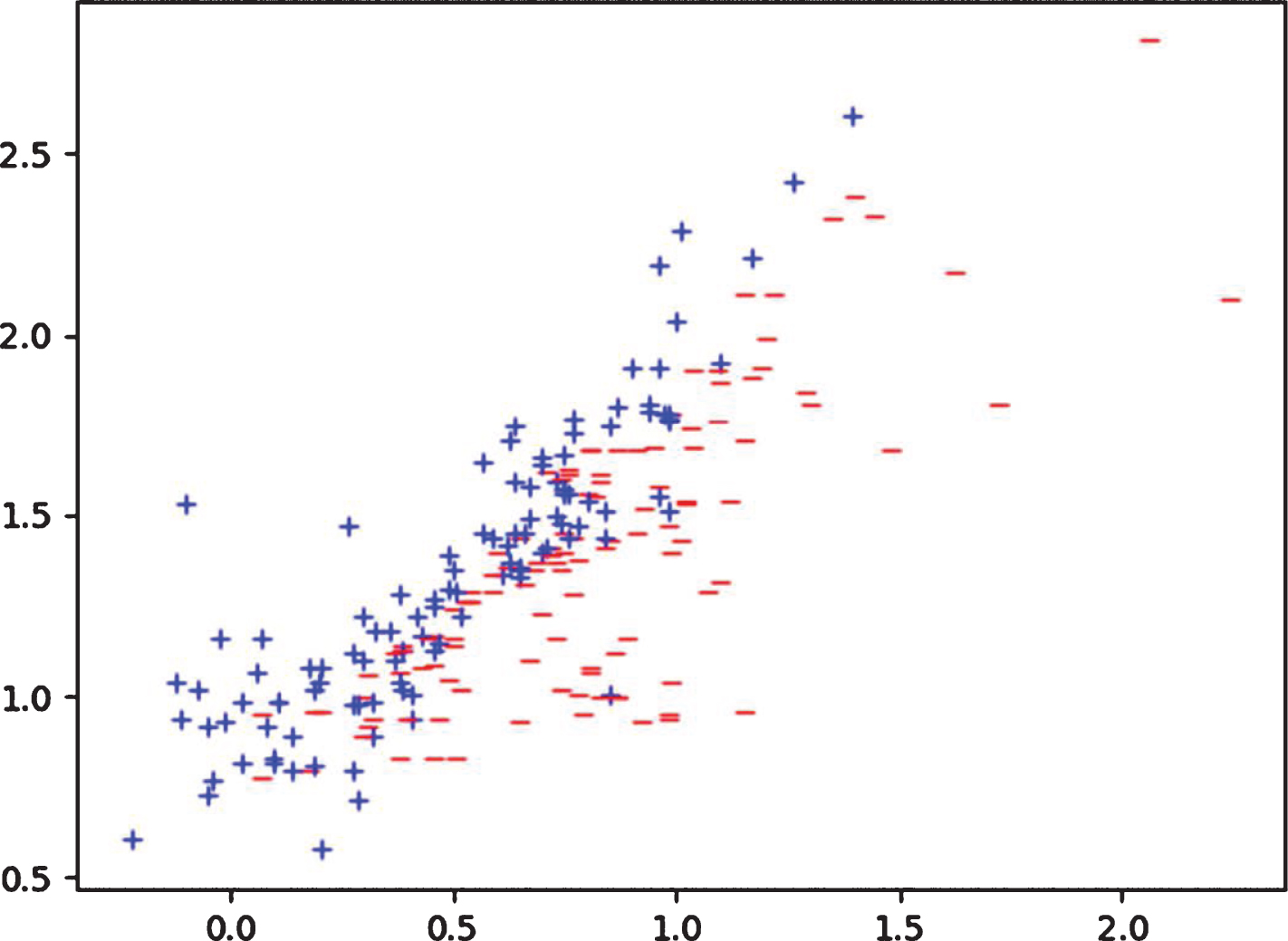
The distribution of instances selected by CFKNN (k = 5) from Gaussian dataset with λ = 0.5.
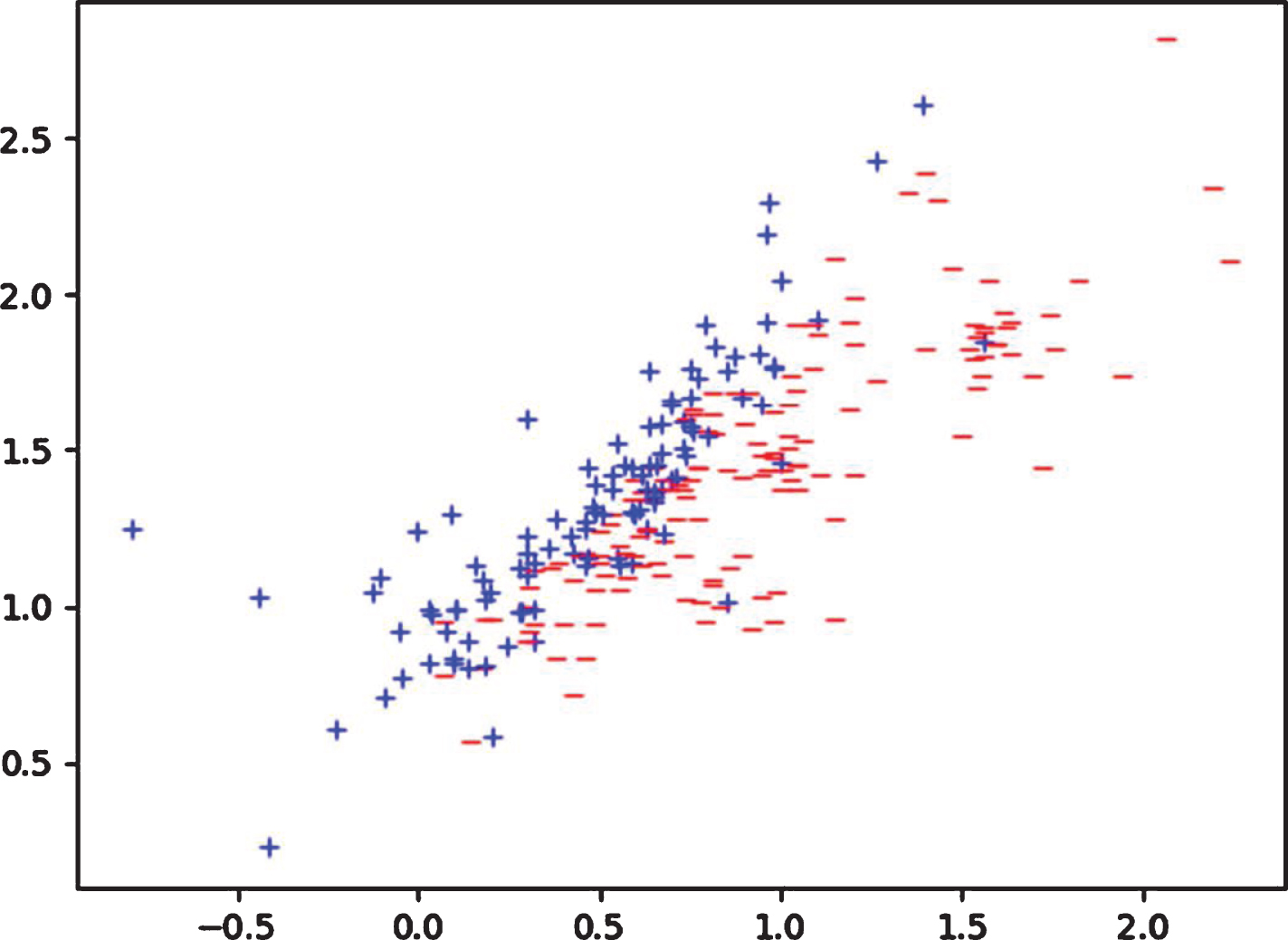
The distribution of instances selected by CFKNN (k = 5) from Gaussian dataset with λ = 0.6.
As illustrated in Figure 2, the maximum entropy differs for datasets with different numbers of classes. For instance, the maximum entropies are 1.0, 2.32, 3.32, and 3.91 for datasets with 2, 5, 10, and 15 classes, respectively. Accordingly, it is inappropriate to employ a static uniform threshold to select instance from datasets with different number of classes [25]. Based on the approach, we investigate experimentally the impact of threshold λ on the performance of CFKNN in this section.
For the dataset Iris with 3 classes, the threshold λ is gradually increased from 0.7 to 1.0 with a step size of 0.5. The number of selected instances and the testing accuracy of CFKNN with K = 3 and K = 5 are reported in Table 12.
For the datasets Glass with 6 classes, the threshold λ is increased from 1.0 to 1.6 with a step size of 0.1. The the number of selected instances and the testing accuracy of CFKNN with K = 3 and K = 5 are reported in Table 13.
In our experiments, for the datasets with 2 classes the threshold λ is gradually increased from 0.5 to 0.95 with a step size of 0.5. The number of selected instances and the testing accuracy of CFKNN with K = 3 and K = 5 are reported. The experimental results are listed in Table 11, respectively. In the following tables, TA represents the testing accuracy, and #SI is the number of the selected instances.
The experimental results on dataset Gaussian.
The experimental results on dataset Gaussian.
The experimental results on dataset CT
The experimental results on dataset RenRu
The experimental results on dataset WDBC
The experimental results on dataset Parkinsons
The experimental results on dataset Pima
The experimental results on dataset Skin
The experimental results on dataset Fertility
The experimental results on dataset Survival
From the experimental results listed in Table 11, it is observed that the optimal threshold λ are different for different datasets for both cases K = 3 and K = 5, even though the datasets have same number of classes. Moreover, there are multiple optimal thresholds for most datasets. Compared with the baseline 1 listed in the second row in the tables, we also found that for the case K = 3 CFKNN shows competence preservation 2 (marked with “ = ”) or competence enhancement 3 (marked with “ ↑ ”) on almost datasets except dataset Iris. On the dataset Iris, CFKNN is competence decrement (marked with “ ↓ ”), yet the testing accuracy decreases slightly (from 0.9778 to 0.9556). Compared with the baseline, in the case K = 5, CFKNN is competence preservation or competence enhancement on almost datasets except on dataset Gaussian and CT. On the datasets Gaussian and CT, CFKNN is competence decrement, but the decrease in test accuracy is also very little (from 0.9385 to 0.9301 and from 0.9403 to 0.9254 respectively).
To further verify the effectiveness of CFKNN, we experimentally compared CFKNN with four state-of-the-art methods: CNN [9], ENN [12], Tomeklinks [10], and OneSidedSelection [27], on three aspects: the number of selected instances (#SI), compression ratio (CR) and testing accuracy (TA). In this experiment, let K = 5. The experimental results are listed in Table 14, 15, 16, and 17. The testing accuracy and compression ratio are illustrated in Figures 6 and 7, respectively. The experimental results in Table 14 show that CFKNN outperforms CNN on testing accuracy on 8 datasets. On larger datasets, such as Gaussian and Skin, compared with CNN, CFKNN has much higher compression ratios (0.9059 and 0.9960, respectively). The experimental results in Table15-17 indicate that the performance of CFKNN is on par with state-of-the-art approaches ENN, Tomeklinks, and OneSidedSelection.
The experimental results on dataset Iris
The experimental results on dataset Iris
The experimental results on dataset Glass
Experimental results compared with CNN
Experimental results compared with ENN
Experimental results compared with TomekLinks
Experimental results compared with OneSidedSelection
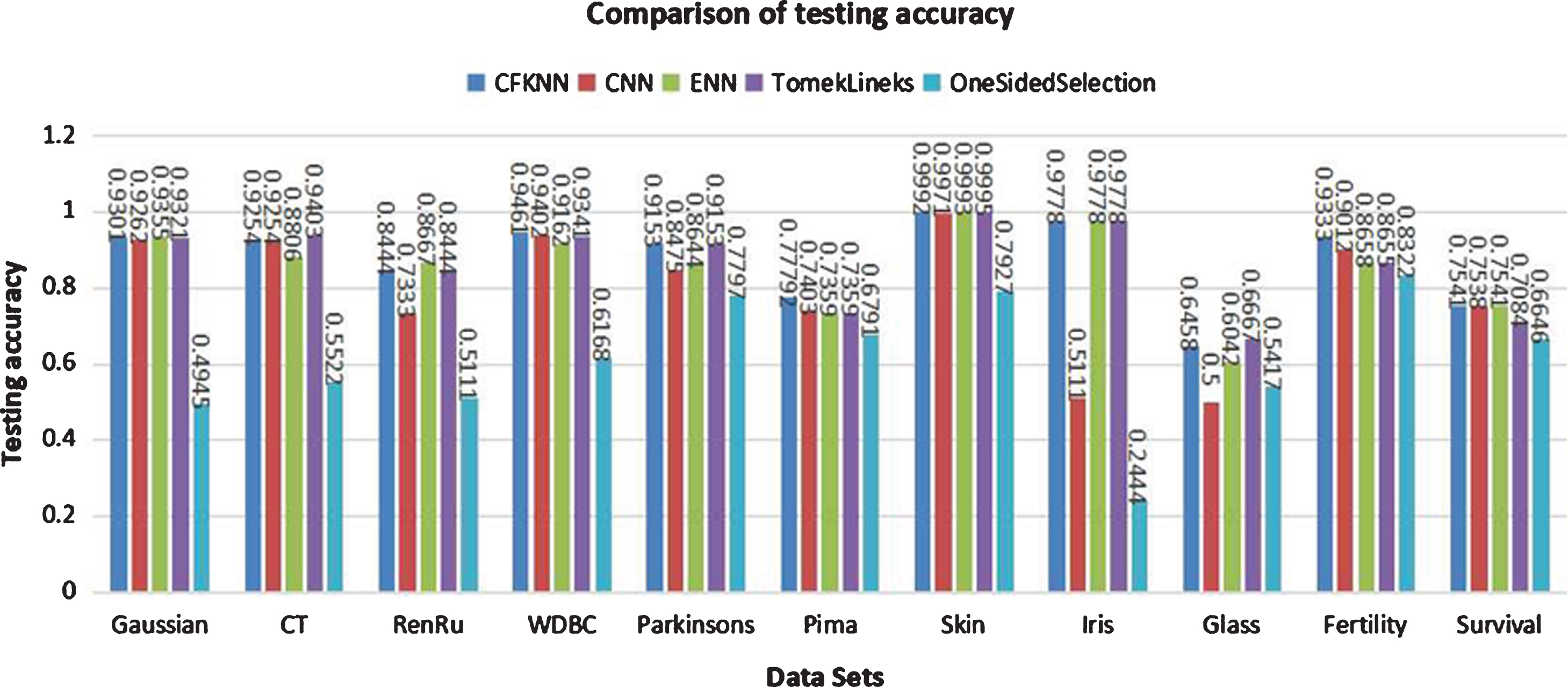
The comparison of testing accuracy
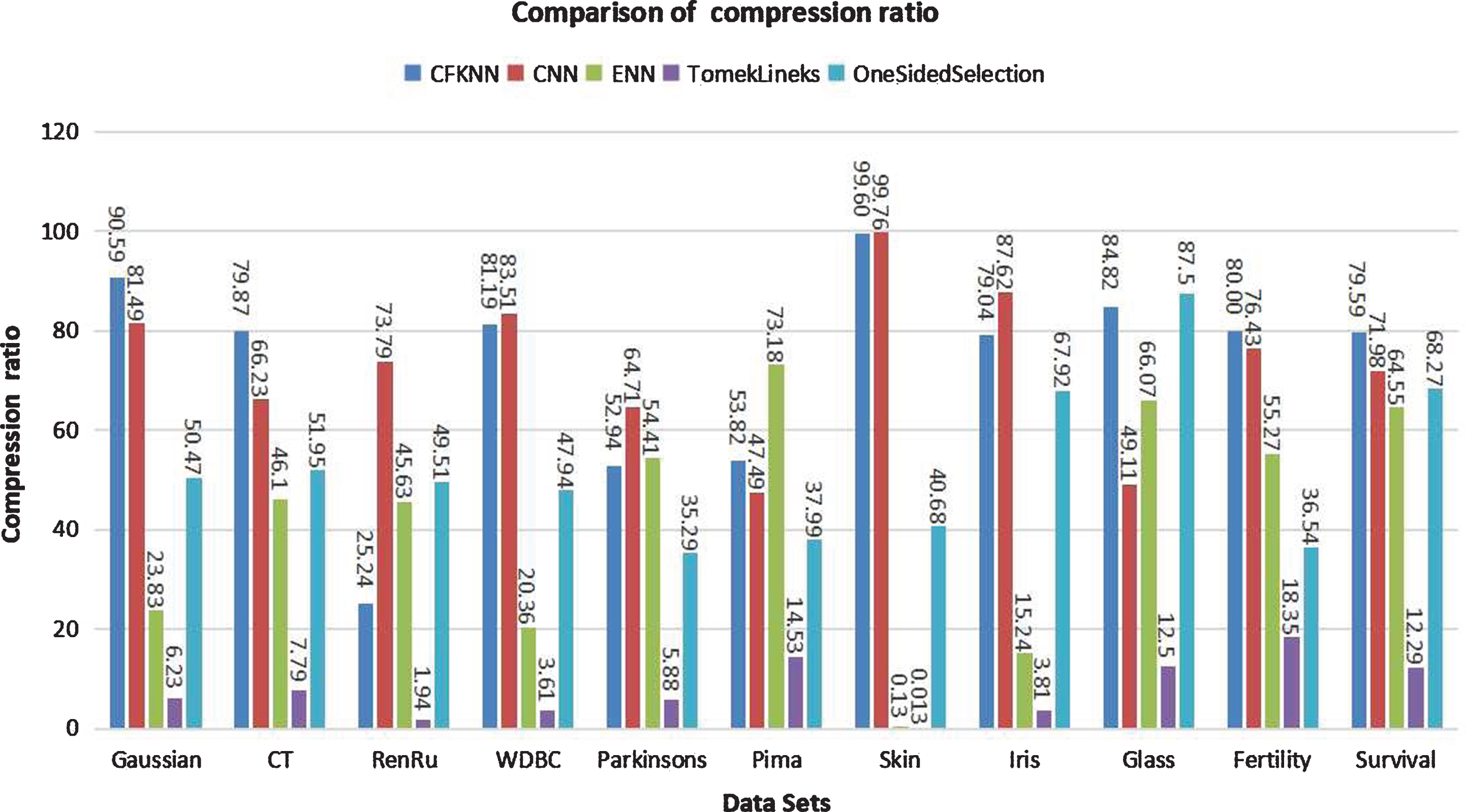
The comparison of compression ratio
To further confirm the superiority of the proposed algorithm to the 4 state-of-the-art algorithms, we statistically analyzed the experimental results of #SI, TA and CR using paired T-test with a confidence level of 0.05 [29]. First, for each dataset and algorithm, we run the 5-fold cross-validation 5 times and obtain five 25-dimensional statistics denoted by X1, X2, X3, X4 and X5 corresponding to CNN, ENN, TomekLinks, OneSidedSelection and CFKNN respectively. Next the paired T-test is applied to the experimental results by calling the Python library function ttest_rel(·, ·). The results of the statistical analysis on #SI, TA and CR are listed in Table 18, 19 and 20, respectively. The p-values listed in the three tables show that CFKNN statistically outperforms CNN, ENN, TomekLinks, and OneSidedSelection.
The results of statistical analysis on #SI
The results of statistical analysis on TA
The results of statistical analysis on CR
Motivated by the idea of CNN, an instance selection algorithm named CFKNN is proposed for fuzzy K-nearest neighbor. CFKNN can be viewed as an extension of CNN to the fuzzy scenario, also can be viewed as an improvement of our previous work presented in [25]. CFKNN has four advantages: (1) it is more generic: the hyperparameter K can adopt different values, while CNN only works for K = 1; (2) it is very efficient since it uses subset S to calculate fuzzy membership degree of instance rather than using set T; (3) it uses dynamic threshold λ to select informative instances for different datasets; (4) it has very high compression ratio without deteriorating testing accuracy, especially on larger datasets. In the future, we will investigate the scalability of CFKNN in big data scenario.
Acknowledgments
This research is supported by the key R&D program of science and technology foundation of Hebei Province (19210310D), and by the natural science foundation of Hebei Province (F2017201026).
Footnotes
The baseline corresponds to the case λ = 0.0, which means that no instances are removed from the training datasets.
The competence preservation means that the classification accuracy will not decrease or decrease very little when superfluous instances are removed.
The competence enhancement means that the classification accuracy is increased by removing certain instances.