
Abstract
This paper focuses on script identification in natural scene images. Traditional CNNs (Convolution Neural Networks) cannot solve this problem perfectly for two reasons: one is the arbitrary aspect ratios of scene images which bring much difficulty to traditional CNNs with a fixed size image as the input. And the other is that some scripts with minor differences are easily confused because they share a subset of characters with the same shapes. We propose a novel approach combing Score CNN, Attention CNN and patches. Attention CNN is utilized to determine whether a patch is a discriminative patch and calculate the contribution weight of the discriminative patch to script identification of the whole image. Score CNN uses a discriminative patch as input and predict the score of each script type. Firstly patches with the same size are extracted from the scene images. Secondly these patches are used as inputs to Score CNN and Attention CNN to train two patch-level classifiers. Finally, the results of multiple discriminative patches extracted from the same image via the above two classifiers are fused to obtain the script type of this image. Using patches with the same size as inputs to CNN can avoid the problems caused by arbitrary aspect ratios of scene images. The trained classifiers can mine discriminative patches to accurately identify some confusing scripts. The experimental results show the good performance of our approach on four public datasets.
Introduction
Script identification facilitates many important applications in document analysis [1–3] and video analysis [4, 5]. This paper focuses on a relatively new problem: identifying the script or language type of the text in scene images. It can also be viewed as a classification task. The text in scene images often carries rich, high-level semantics and helps with image understanding, image retrieval and other applications [6–8]. Many efforts have been made concerning text recognition [9, 10] in scene images. It is very common to have multiple scripts in scene images especially sign boards, as illustrated in Fig. 1. Thus, figuring out what script it is before text recognition is essential. Actually, script identification is one of the key steps of text recognition in natural scene images.

A sign board containing three scripts including Chinese, English and Korean.
Generally, script identification for scene text images consists of two sub-tasks: one is text localization to get pre-segmented text lines, and the other is identifying the script types of these pre-segmented text lines. The work in this paper focuses on the second sub-task, i.e., identifying the script type of texts in scene text images.Texts in natural scene images have difficulty in script identification due to the following characteristics:(1) large variations in their fonts, colors, sizes and layout shapes; (2) lack of context, such that scene text often appears as a single word or group of words without any large sentence or paragraph; and (3) poor quality of scene images caused by noises, uneven lighting, blurring and complex backgrounds etc. Recently, for scene images, CNN has achieved great success in image classification tasks because of its strong capacity and invariance to translation and distortions [11–13]. These CNN classifiers are all image-level classifiers which use the whole image with fixed size as input. Directly applying these CNN classifiers to scene text script identification is not a good choice because of two challenges. One challenge is the extremely variable aspect ratios of scene images which bring much difficulty to any CNN classifier with a fixed size image as the input. The other challenge is that there are many parts in different script images that are similar or even nearly identical. Some scripts such as English, Russian and Greek share some similar or even identical patches, as well as Chinese and Japanese. This similarity leads these scripts to be easily confused. Therefore, the type of script must be determined by some discriminative patches.As illustrated in Fig. 2(a), for English, Greek and Russian, “A”,“P” and “E” are not discriminative patches because they appear in three scripts simultaneously while “?”,“Σ” and “?” are discriminative patches because they appear only in a script. A similar situation appears in Fig. 2(b). In Fig. 2, the red boxes are labeled discriminative patches and they are the key factors for script identification. Thus, for script identification, the ability to identify these discriminative patches is very important. We argue that patch-level classifier is more suitable than image-level classifier for script identification in scene text images for two reasons: (1) avoiding the problems caused by extremely variable aspect ratios when using the whole image as input and (2) incorporating the idea that scene script identification should rely on some discriminative patches.
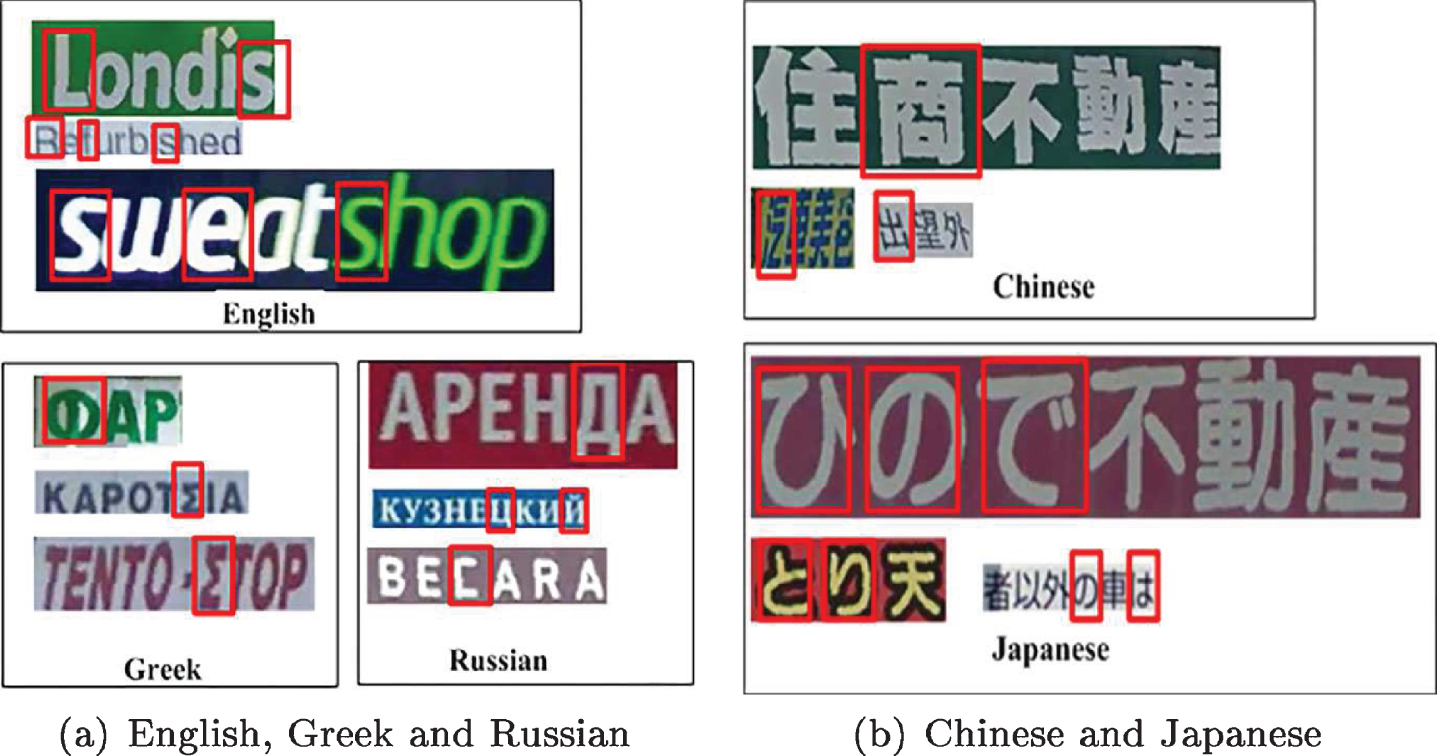
Scripts such as English, Greek and Russian share some similar or even identical characters; additionally, Chinese and Japanese share similarities. The red boxes are labeled discriminative patches and they are the key factors for script identification.
Existing patch-based script identification algorithms either identify the patch by designing an ensemble network [14], or train the classifier to extract complex features of patches and then combine different CNN such as single CNN, RCNN(Convolutional Recurrent Neural Network) or LSTM(Long-Short Term Memory) for script identification [15–17]. These methods use patches as inputs for extracting features or use all patches as inputs to CNN, but discriminative patches are not detected and utilized for script identification. In this paper, we propose a simple and effective approach to mine discriminative patches and obtain the results of script identification only through these discriminative patches.
Inspired by the work in [14, 18], we propose a new framework for script identification in natural scene images. Attention CNN and Score CNN are the main components of our approach. Both of them use patches with the same size as inputs. Firstly, all patches are extracted from scene images and used as inputs to train Attention CNN and Score CNN to get two patch-level classifiers named Attention CNN model and Score CNN model.Then for a scene text image, Attention CNN model is utilized to mine all discriminative patches and calculate the contribution weights of these discriminative patches to script identification of the whole image. Score CNN model uses these discriminative patches as inputs and predict the scores corresponding to each script type. Finally the scores and weights of all discriminative patches extracted from the image are fused to get the final predicted result of this image. The experimental results demonstrate that our approach has good performance on four public datasets named MLe2e [14], SIW-13 [15], ICDAR-2017 [19] and CVSI-2015 [20].
Our work has the two main contributions:
(1) We analyze that the key to similar script identification is discriminative patches and only use discriminative patches as inputs for script identification. To the best of our knowledge, this is the first time that only discriminative patches are used to do script identification. The experimental results on four datasets show that the good performance of our approach.
(2) When training Attention CNN, it is difficult to get the label of each patch. From the labels of the original dataset, we can only know the script type of each patch, but whether the patch is a discriminative patch cannot be determined. We propose a simple method to determine which patches are discriminative patches. For one patch, if the script type of this patch can be correctly identified via Score CNN model, the patch is considered a discriminative patch and the corresponding label is set to 1. Otherwise, it is not a discriminative patch and the corresponding label is set to 0.
The rest of this paper is organized as follows. In the section 2, we briefly introduce some related work. Our proposed method is described in the section 3. Section4 presents the experimental results and analysis. Section 5 summarizes the paper finally.
Previous work on script identification mainly focused on texts in documents and videos and many excellent algorithms have been proposed for script identification. But these methods are not suitable for script identification in natural scene images. The methods for documents are not suitable for scene text images and these methods often require a lot of text, but in scene images, there are only lines of text or several words. Methods for videos are not suitable for scene text images too because there are more complicated backgrounds in natural scene images.
In the field of document analysis, the methods of script identification mainly were divided into two broad categories: structure-based and visual appearance-based techniques [1,21, 1,21].The general procedure was first extracting the features and then using different classifiers such as SVM (Support Vector Machine), KNN (K-nearest neighbors) etc. to get the classified results for several scripts. The methods involving extracting and analyzing features of connected components belonged to the category of structure-based techniques and the methods using features that describe the visual appearance of a script region belonged to the category of appearance-based techniques. There were relatively few studies on script identification on texts of videos. In 2015, the ICDAR Competition on Video Script identification (CVSI) was held [20]. Unlike the traditional approaches based on hand-crafted features, the top performing methods in the competition were all based on CNN. The competition winner (Google) was also based on CNN, but applied a binarization pre-processing step to the input images. This pre-processing step is not suitable for scene images with complex backgrounds. There were also other methods [22–24] for visual script identification. Most of them were based on edge detection or texture-based features and not always are suitable for scene text images.
The existing methods of script identification in scene text images can be divided into two categories: CNN based methods and hand-crafted features based methods. Usually CNN based methods have better performance [14] and our approach belongs to this type of method.
The earliest study of script identification in natural scene images was proposed by Shi et al. in [25] in which they provided a 10-class dataset named SIW-10. In their method, Multi-stage Spatially-sensitive Pooling Network (MSPN) was used to handle input images with arbitrary aspect ratios. They got an error rate of 5.6% on SIW-10 dataset. In [15], Shi et al. extended their work and a larger and more challenging 13-class dataset named SIW-13 was provided. In this method, the mid-level representations were integrated into a single CNN for script identification. Two important factors named the image representation and the spatial dependencies within text line were exploited in [16]. Then a Convolutional Recurrent Neural Network and these two factors were brought together into one end-to-end trainable network for script identification. The authors also adopted an average pooling structure to deal with input images with arbitrary sizes. Gomez et al. studied the problem of script identification in scene text images in [14, 25]. The patch-based method in [25] combined convolutional features, the Naive-Bayes Nearest Neighbor classifier and a simple weighting strategy to discover the most discriminative parts per class and a fine-grained classification approach was proposed. Gomez et al. extended their work in two ways in [14]: making use of a much deeper Convolutional Neural Network model and replacing the NBNN with a patch-based classification rule that can be integrated in the CNN training process by using an Ensemble of Conjoined Networks. A new dataset named MLe2e was provided in [14]. Ankan Kumar Bhunia et al. [17] proposed a method that involved extraction of local and global features using CNN-LSTM frame work and attention-based weights calculated by applying softmax layer after LSTM. The above approaches are all based on CNN and belong to the first category.
Our approach and ECN [14] are all using patches as inputs to CNN for script identification. But our approach is different from ECN in three points. Firstly, we only use discriminative patches for script identification, while ECN uses all patches for script identification. Secondly, although our Score CNN is similar with the Ensemble of Conjoined Networks in [14], our score CNN has a different backbone and a different fine-tuning strategy. Finally, we introduce Attention CNN to mine discriminative patches and ECN has no this step.
There were some approaches for script identification in scene text images that belong to the second category. In [27–29], first the hand-crafted features were extracted and then SVM classifier was used to get the result. In [27], the features including LBP(Local Binary Pattern), CSLBP(Center Symmetric Local Binary Pattern), and DLEP(Directional Local Extrema Pattern) were extracted first and then SVM was used to identify scene texts. In [28], the authors computed the mid-level feature representation of words from labeled data and then used SVM to identify scene texts. In [29], different texture features such as the Gabor feature, the Log-Gabor feature and wavelet features were extracted from the segmented text images to classify the text images into three scripts: English, Kannada and Malayalam. Three different classifiers including KNN, SVM-L(Support Vector Machine - Linear kernel) and SVM-R(Support Vector Machine - Radial basis function kernel) were evaluated, and results were reported in their work.
The proposed approach
Given a scene image I, which may contain a word or a sentence, we predict its script class c∈ { 0, 1, 2, . . . , C } where 1 to C represents a specific script type and 0 means none of the above. Our approach is mainly composed of three parts, i.e., preparing patches, training Score CNN and Attention CNN, and inference. In subsequent subsections, we will introduce how to get patches, how to train Score CNN and Attention CNN and the detailed work in the testing stage.
Patches preparation
Our approach is based on patches; therefore patches must be extracted from scene images first during both the training stage and testing stage. We first convert the images into gray-scale images, and then resize them. To reduce distortion, we keep the same aspect ratio as the original images when resizing them. In the same way as in [14], for one scene image, the height is resized to 40 pixels and the width changes according to the aspect ratio. Then, we densely extract 32×32 patches from the resized images in both horizontal and vertical directions. The step size of the extraction is 8 pixels. Detailed process results are shown in Fig. 3. After patches are extracted from a scene text image, then we select N patches from these patches to form grouped patches which are used as inputs to Score CNN. The specific acquisition process is described in detail in subsequent subsection “Input strategy”.

(a) Is the original scene text image; (b) is the resized gray text image; (c) are the 32×32 patches extracted from b.
In our approach, Score CNN is very important and it has two functions. In the training stage, the trained Score CNN called as Score CNN model is utilized to determine the category of a patch. If a patch can be rightly identified using Score CNN model, then this patch is a discriminative patch, else it is not a discriminative patch. In the testing stage, Score CNN model is utilized to obtain the score of each script type. Activated by the work in [14, 18], Score CNN is designed to be an ensemble of N networks. Specifically, only the first network is used for inference, and the other networks are used to improve the classification accuracy of the first network during the training phase. In order to highlight the first network, input strategy and fine-tuning strategy are proposed here.
Architecture
ResNet is a very good structure for CNN and has achieved surprising performance in the field of image classification [11]. ResNet-20 is a 20-layer ResNet network that is very suitable for the classification task in small images. Here Score CNN consists of N networks of RestNet-20 which are joined at their outputs with an “Eltwise” layer in order to provide a unique classification response. Then a “Softmax” layer is added for the final classification. The architecture of Score CNN is shown in Fig. 4. The response of the “Eltwise” layer and the “Softmax” layer in Score CNN are shown in equations (1) and (2). N denotes the number of networks in Score CNN and C denotes the number of script types in the dataset. We use (x1, x2 … x
N
) to denote the input of Score CNN. The output of each network in Score CNN is a (C+1)-length vector denoted by (Score0, Score1 … Score
C
). In equation (1), Score0 (ResNet
i
(x
i
)) denotes the first value in the vector output by the i-th network in Score CNN when the input patch is x
i
. In equation (2), (p0, p1 … p
C
) is the probability of each script type and script type with the highest probability is the last identification result. We use Cross Entropy loss to train Score CNN; it is displayed in equation (3) where p
i
denotes the predict probability of the script type of the sample i and M denotes the number of samples.

The architecture of Score CNN.
For the ensemble of N networks, a general input strategy is to randomly select N patches as the inputs. We argue that this operation is not very suitable for Score CNN. In Score CNN, only the first network is utilized for inference. Selecting randomly N patches as inputs may enter duplicate patches for the first network and cannot give rich inputs to the first network. Therefore, in order to give rich inputs for the first network and improve the ability of generalization of the first network, we use all patches extracted from a same scene image as inputs to the first network in turn and randomly select patches as inputs to the remaining N-1 networks. Especially, if the number of patches is less than N, we multiply the number of patches by 2 until it is greater than N. Detailed input strategy for Score CNN is displayed in Algorithm 1. In our input strategy, if the input of Score CNN is (x1, x2 … x N ), these N patches must be extracted from a same scene text image and has the same label for script identification. Therefore for Score CNN, its inputs are grouped patches extracted from a same text image and its output is a label representing the script type of this scene text image.
1: lstGroup = [];
2:
3: count = the number of patches;
4: patchNumber = count;
5:
6: patchNumber = 2* patchNumber;
7:
8: everygroup = []; i = 0;
9:
10: everygroup.append(the mod (i, count)-th patch);
11: lstChoice = random.choice(patchNumber, N-1);
12: everygroup.append(eachPatch ∈ lstChoice);
13: i = i + 1
14:
15: lstGroup.append(everygroup);
16:
17:
Fine-tuning strategy
In the “Eltwise” layer, the sum of the outputs of the N networks is used to predict script type. It means that all networks in Score CNN contribute to the final result. We believe that using the trained models of ResNet-20 to fine-tune Score CNN can improve the accuracy. But like [14], only using a trained CNN model to fine-tune the first network is not good for the final accuracy because of the low accuracy of the other networks. Hence, we use a compromise proposal to balance the first network and the others in Score CNN. We first train a network of ResNet-20 to obtain N CNN models with different accuracy. Then we use a CNN model with higher accuracy to fine-tune the first network and use the CNN models with relatively lower accuracy to fine-tune the remaining networks in Score CNN. In our experiments, we use the trained model obtained from the 110,000 iterations to fine-tune the first network and the trained models obtained from the 40,000 iterations to fine-tune the remaining networks on SIW-13 dataset. We will discuss in detail how the parameters of fine-tuning strategy are determined in subsequent section.
Using the above input strategy and fine-tuning strategy, the accuracy of the first network in Score CNN will be increasingly higher than other networks during training. After training Score CNN, we obtain Score CNN model which will be used in the training of Attention CNN and the testing stage.The detailed training process of Score CNN is shown in Fig. 5.
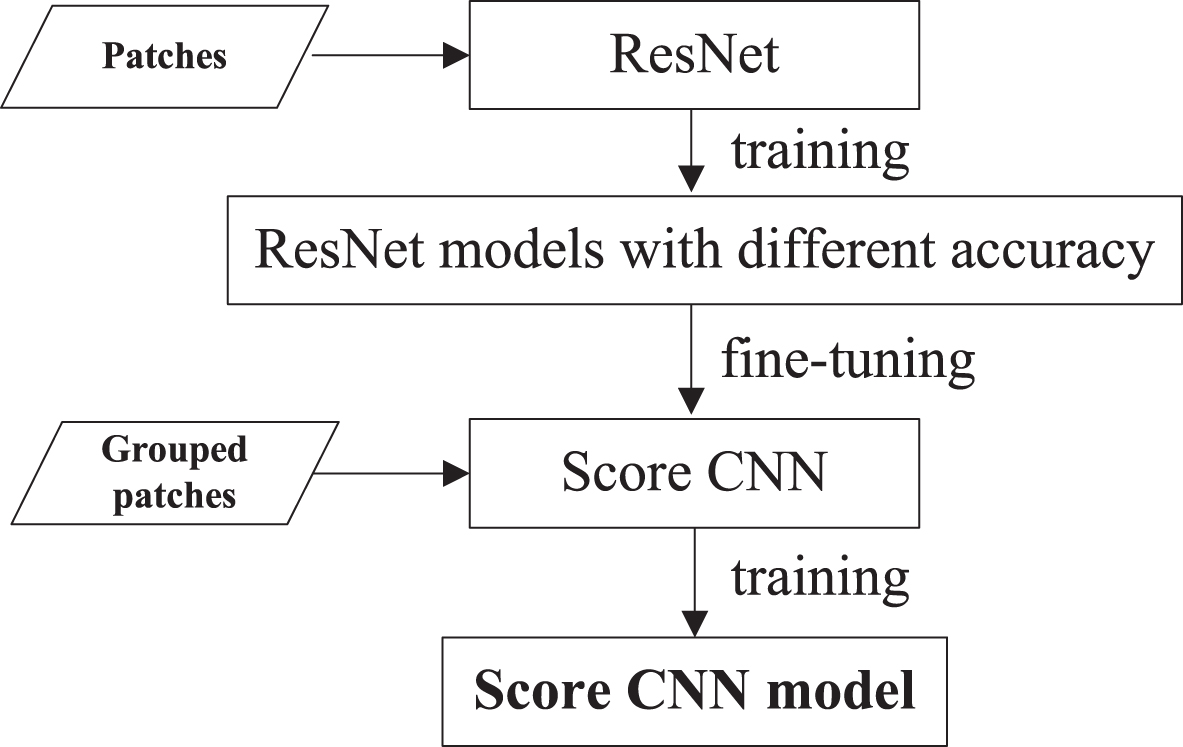
The training diagram of Score CNN.
Attention CNN is also an important component of our method. Its main role is to predict whether each patch is a discriminative patch and calculate the weight of each discriminative patch that contributes to the script identification of the whole image. Here, Attention CNN is designed to a classification network and its architecture is a single ResNet-20 (including “Softmax” layer).
Before training Attention CNN, there is a very tricky thing. How to set a label for each patch, that is, how to determine which patches in the training set are discriminative patches and which are not. If manual marking method is used to judge all patches, there is not only large workload, but the accuracy will not be very high. Because few people are very proficient in all scripts and understand the characteristics of each script. Therefore the manual marking method is obviously inappropriate. In our approach, we use Score CNN to automatically determine whether the patch is a discriminative patch. For one patch, if the script type of this patch can be correctly identified via Score CNN model, the patch is considered a discriminative patch. Then we set the label of this patch is 1, else the label is 0.
We use all patches as inputs and the corresponding labels as outputs to train Attention CNN to get Attention CNN model which will be used in the testing stage. The detailed training diagram of Attention CNN is shown in Fig. 6.
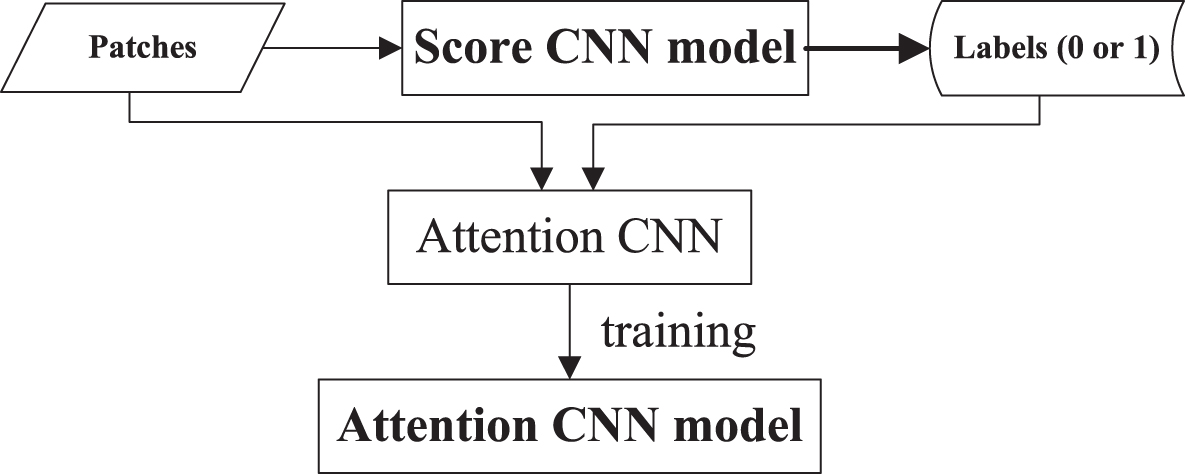
The training diagram of Attention CNN.
In the testing stage, we use Score CNN model and Attention CNN model to predict the script type. For a scene image, we first get 32×32 patches densely from it. Supposing that there is M patches and all patches are denoted by (patch1, patch2 … patch
M
). For patch
k
in these patches, it is first as the input to Attention CNN model to get a 2-length vector represented by (Weightk0, Weightk1) through the response of “Softmax” layer in Attention CNN model. If the value of Weightk1 is larger than the value of Weightk0, this patch is considered a discriminative patch. If patch
k
is a discriminative path, then it is used as input to Score CNN model to get a C+1-length vector denoted by (Scorek0, Scorek1 … Score
kc
) through the response of the last fully connected layer (“FC_20” in our case) in Score CNN. So for all patches of a scene image, we obtain the number of discriminative patches using formula (4). In formula (4), an indicator function 1{ • } takes on a value of 1 if its argument is true, and 0 otherwise. Finally,we obtain the average score of each script type using formula (5) and obtain the predicted type of the whole image using formula (6). The detailed inference process is shown in Fig. 7.
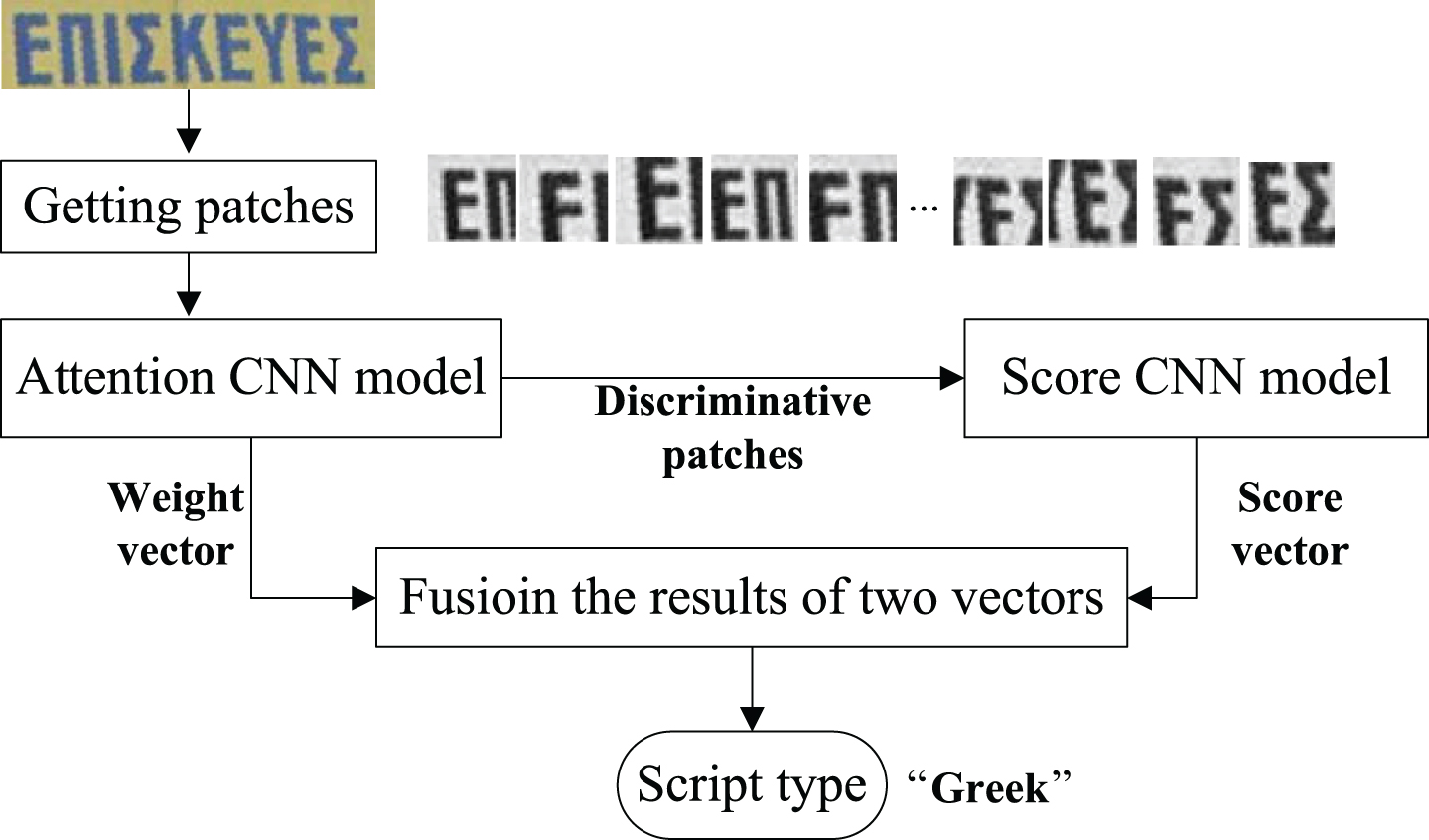
The flowchart of our approach in the testing stage.
We verify our approach on four public datasets named SIW-13, MLe2e, ICDAR-2017 and CVSI-2015. There are all scene text images in SIW-13, MLe2e and ICDAR-2017 datasets and only a few scene text images in CVSI-2015 dataset. Our approach is specifically designed for the text in natural scene images. To prove the extensibility of our approach, we also compare our approach with some methods specifically designed for the video text on CVSI-2015 dataset. SIW-13 dataset: 16291 pre-segmented text lines involving 13 scripts including Arabic, Cambodian, Chinese, English, Greek, Hebrew, Japanese, Kannada, Korean, Mongolian, Russian, Thai and Tibetan are in SIW-13 dataset. All text images are extracted from natural scene images from Google Street View. There are 500 images of each script type in the testing set and others in the training set. There are some very similar scripts in SIW-13, such as English, Greek and Russian, as well as Chinese and Japanese. MLe2e dataset: Relatively fewer script types and fewer scene text images in MLe2e dataset. There are 4 scripts including Latin, Chinese, Kannada and Hangul, 1177 and 642 pre-segmented text lines are in the training set and the testing set respectively. Although the number of script types of the text in MLe2e dataset is small, the aspect ratio of the text image varies greatly, and the images of various sizes are in MLe2e dataset. ICDAR-2017 dataset: It is a large dataset and there are 68613 pre-segmented text word images in the training set and 16255 word images in the validation set. Especially, there are some non-horizontal text images in this dataset. The dataset consists of 9 scripts including Arabic, English, French, Chinese, German, Korean, Japanese, Italian, and Bangla. English, French, German and Italian share the same Latin script and are assigned the same script class: Latin. Additionally, isolated punctuation or other special characters are considered as a special script class, namely Symbols. Hence, we have total 7 script types. CVSI-2015 dataset: CVSI-2015 contains mainly overlay video texts and only contains a few scene text images. There are 10 scripts including Arabic, English, Hindi, Bengali, Oriya, Gujrathi, Punjabi, Kannada, Tamil, and Telegu with approximately 1100 pre-segmented text lines in each script. There are four tasks on CVSI-2015 dataset and we only address Task-4, classifying all 10 scripts, as it is the most generic task.
Implementation details
We have used the open source Caffe [30] framework to run deep learning running on commodity GPUs. All CNNs used in our approach are optimized by stochastic gradient descent (SGD). When training the single network of ResNet-20, the initial learning rate is set to 10-2 and decreased by a factor of 10 after every 100,0000 iterators. When training Score CNN, the initial learning rate is set to 10-3 and decreased by a factor of 10 after every 10,000 iterations. The value of momentum is set to 0.9 and the batch size is set to 64. The size of the patch is 32×32 and the step of the sliding window is 8 pixels. In our experiments, in the same way as in [14], we set the value of N to 10.
Script identification in pre-segmented text lines
For a script identification task, the input is an image containing lines of text, and the output is a specific script type. The performance index used to evaluate methods for script identification is the accuracy rate, and its definition is shown in equation (7) where Num
sum
presents the number of all text images and Num
right
presents the number of text images that are correctly identified.
We study the performance of the proposed approach for script identification in pre-segmented text lines. Table 1 shows the overall accuracy of our approach and comparison with other approaches on the four public datasets. As shown in Table 1, our approach has the highest accuracy on the MLe2e, SIW-13 and ICDAR-2017 datasets and there are totally scene text images in these datasets. The approaches in [14–16, 26] are all designed for script identification in natural scene images. Compared to them, our approach improves the overall accuracy from 0.944, 0.948 and 0.871 to 0.958, 0.957 and 0.927 on MLe2e, SIW-13 and ICDAR-2017 datasets. Especially for ICDAR-2017 dataset, our approach has increased accuracy by 5%. Our approach achieves better performance mainly due to the following points. First, we use ResNet-20 as the backbone of CNN. Second, we deploy input strategy and fine-tuning strategy in Score CNN. Finally, we introduce Attention CNN to identify all discriminative patches and use only these discriminative patches for script identification in the testing stage. We will describe in detail the impact of each point in subsequent section. Compared with other methods designed for texts in natural scene images [14–16, 26], our approach has the highest accuracy of 0.979 on CVSI-2015 dataset. Google [20] has the best overall accuracy of 0.989 on CVSI-2015 dataset, but applies a binarization pre-processing step to the input images. This pre-processing step is not suitable for scene text images with complex backgrounds. We compare our approach with other CNN-based approaches [24, 31] which are all designed for texts in videos. These approaches achieve good performance on CVSI-2015 dataset, but have much lower performance than our approach on MLe2e and SIW-13 datasets. The main reason is that the text in a scene image has a much more complicated background than the text in a video. These approaches are not suitable for scene text script identification. We also compare our approach with the approaches in which Scale Invariant Feature (SIFT) [32] in three different encodings (Fisher Vectors, Vector of Locally Aggregated Descriptors (VLAD), and Bag of Words (BoW)) is combined with the SVM classifier [14]. From the results in Table 1, we can see that the overall accuracy of our approach is also higher than these approaches based on hand-crafted features.
Overall classification performance comparison with other methods on four datasets: MLe2e, SIW-13, CVSI-2015 and ICDAR-2017
There are 13 script types and some scripts are very similar in SIW-13 dataset. Therefore, we next analyze the accuracy of each script in detail in SIW-13 dataset. We divide the testing set into three categories: Set_1, Set_2 and Set_3. There are scripts in English, Greek and Russian in Set_1, and in Chinese and Japanese in Set_2. The scripts within Set_1 and Set_2 have similar holistic appearances and are easily confused with one another. Set_3 includes other types of scripts and these scripts have unique writing styles and can be easily distinguished from one another. All methods are trained on the training set and tested on different subsets.
We focus on comparing our approach with the other two methods in [14] and [16] for two reasons. One is that these two methods are also specifically designed for scene text script identification. The other is that the identification performance of these two methods is better than other methods. As shown in Table 2, our approach achieves the highest accuracy of 0.901 on Set_1 and 0.956 on Set_2. The results show that our approach has better performance on such confusing scripts. All approaches have high accuracy on Set_3 because these scripts are unique and easy to distinguish, and our approach still achieves the highest accuracy. The rightmost three columns in Table 2 give the detailed accuracy of each script. Our approach has a 100% accuracy rate on Tibetan and has especially good performance for English, Russian, Greek, Chinese, Japanese, Arabic, Korean, Cambodian, Hebrew and Kannada.
The accuracy of each script on SIW-13 and compared with other approaches
Although we have taken certain measures to identify similar scripts, there are still some misidentified samples. We have listed the confusion matrixes on four public datasets in Fig. 8. From Fig. 8, we find that the errors in script identification are mainly caused by the similarity of scripts and the unbalanced number of image samples. For CVSI-2015 dataset, Kannada has a high probability of being misclassified as Telegu. For SIW-13 dataset, we find that Greek, Russian and English are often confused, so as are Chinese and Japanese. These confusing scripts have very similar appearance and are also difficult to be distinguished by human eyes. In addition, each script has a certain probability of being misclassified as Latin in ICDAR-2017 dataset. That is due to the imbalance of samples in the training set. There are 47,446 samples labeled as Latin, which are more than the sum of samples (21,167) labeled as other six scripts in ICDAR-2017 dataset.
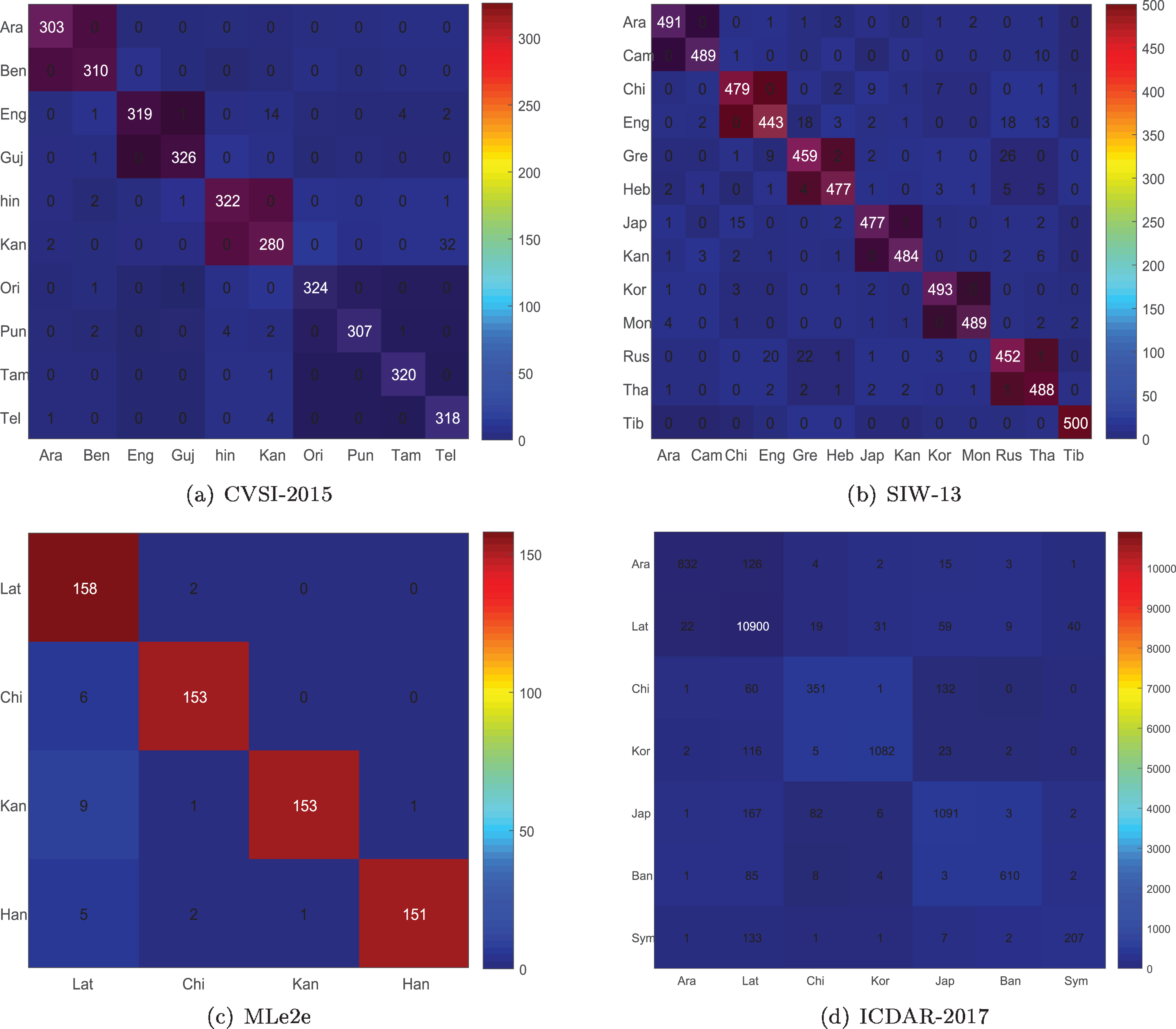
Confusion matrixes on four datasets.
Impact of each part in our approach
Our approach achieves good performance on four public datasets mainly due to three parts. First, we use the network structure of ResNet-20 as the backbone. Second, we deploy input strategy and fine-tuning strategy in Score CNN, and third, we introduce Attention CNN to identify the patch with discriminative power. We analyze in detail the impact of each part and the experimental results are shown in Table 3.
The overall accuracy of combination of different parts in our approach and comparison with ECN on four datasets.
The overall accuracy of combination of different parts in our approach and comparison with ECN on four datasets.
Firstly, we try to train only the single ResNet-20 in the training stage and predict script types in the testing stage. We achieve an overall accuracy of 0.901 on ICDAR-2017 dataset and 0.954 on MLe2e dataset which is higher than the accuracy of ECN [14]. This result indicates that the network of ResNet-20 is very suitable for script identification task. Secondly, our Score CNN is an ensemble of N networks of ResNet-20. Combining our input strategy and fine-tuning strategy, compared to ECN, Score CNN has higher accuracy on all datasets. Finally, we introduce Attention CNN to mine discriminative patches for script identification. After the integration of results of Score CNN and Attention CNN, the overall accuracy on four public datasets are further improved.
The structure of Score CNN is an ensemble of multiply same networks. When training Score CNN, we first utilize patches and their corresponding labels to train a single network and then use models obtained from different iterations to fine-tune Score CNN. So how to choose CNN models with different accuracy to fine-tune Score CNN is the key. Here, for SIW-13, we randomly obtain 650 images (50 images selected for each script type) from the training set and then confirm the valaue of the parameter of fine-tuning strategy based on the identification performance of these images. First, we should choose a CNN model with higher accuracy to fine-tune the first network. We use the trained model of 110,000 iterations to fine-tune the first network because of its high accuracy of 0.9. Then we use fine_tuning_110000_M to represent fine-tuning strategy; this means the trained CNN model obtained from 110,000 iterations is used to fine-tune the first network and the trained CNN models obtained from M iterations are used to fine-tune the remaining networks in Score CNN. The experimental results have been shown in Fig. 9 where the highest accuracy achieved when M is set to 40,000. Other datasets use the same operation to obtain specific settings for fine-tuning strategy.
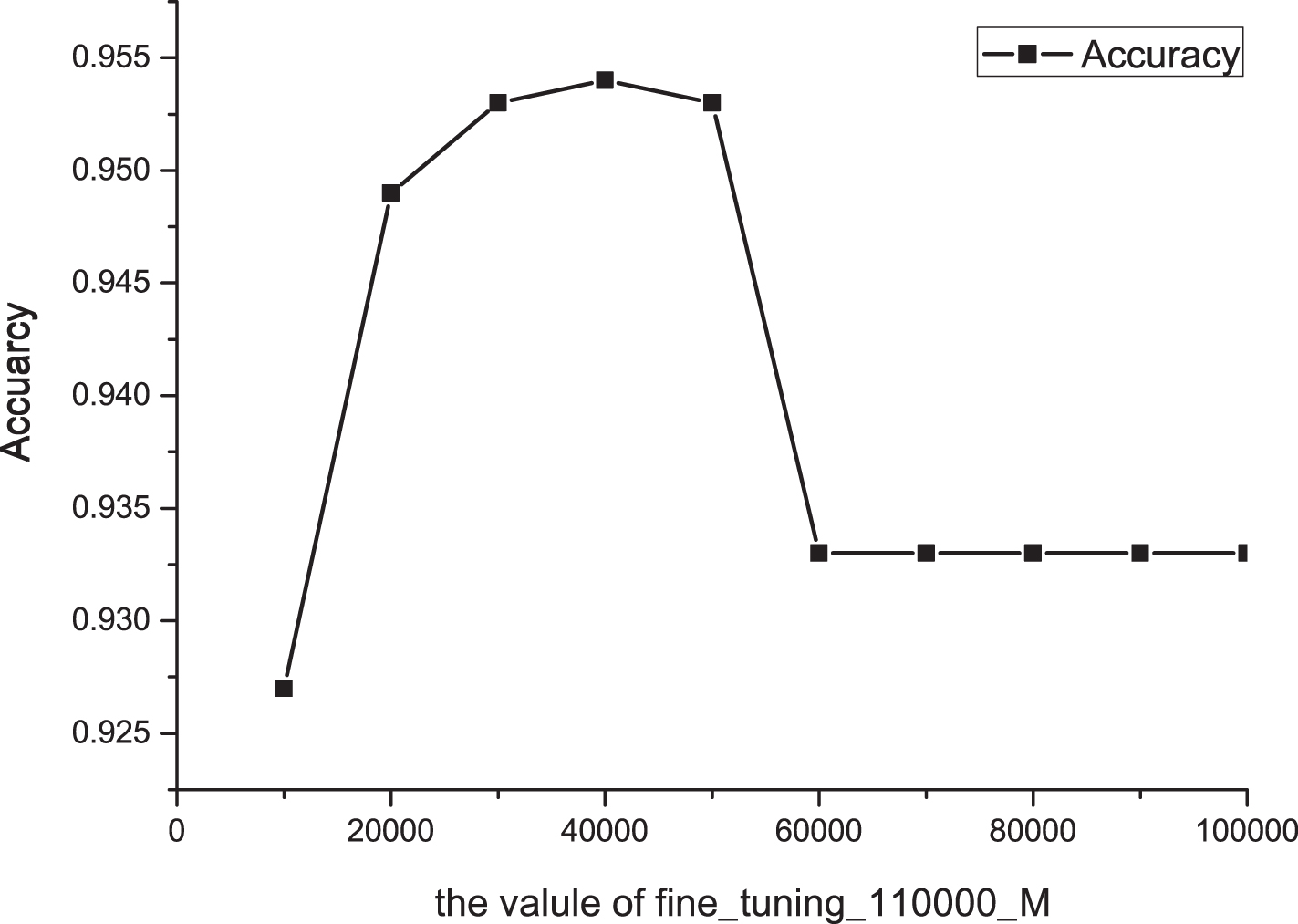
The accuracy changes according to the value of M.
From the results we also find that the difference between the iteration numbers of the first CNN model and other (N-1) CNN models cannot be too big or too small. If the difference is too big, the following (N-1) networks may have low accuracy and lead to low overall accuracy. However, if the difference is too small, the first network cannot be highlighted and can also lead to low overall accuracy.
To prove the effectiveness of our approach, we have displayed some image samples in the testing set as shown in Fig. 10. The script types of some image samples which our approach successfully identifies while the method in [14] fails to identify are shown in Fig. 10(a). From Fig. 10(a), we know that our approach can correctly identify when the images have extremely variable aspect ratio, complex background, poor quality and few characters.

(a) The script types of some image samples in the testing set which our approach identifies successfully but ECN [14] fails. (b) Image samples that our approach fails to identify.
We also list the script types of some image samples that our approach fails to identify. From Fig. 10(b), we find that our approach fails to identify the script types of some scene text images containing non-horizontal texts or very poor quality texts even invisible to the naked eye. Beyond this, when there are shelters in front of text or background and text are mixed together, script types of these scene images are difficult to identify by our approach. Our follow-up work focuses on these scene text images particularly on non-horizontal scene text images.
In this paper, we have proposed an approach for script identification in scene text images. Our approach is based on patches with the same size and avoids the problems caused by extremely variable aspect ratios. At the same time, we combine Score CNN and Attention CNN to mine discriminative patches and get the score and weight of each discriminative patch. In the testing stage, we fuse the results of Score CNN and Attention CNN to get the last script type. Experimental results on four public datasets demonstrate the outstanding performance of our approach. Our method has certain defects when dealing with non-horizontal text images, mainly because patch extraction is performed from horizontal and vertical directions. If the text is non-horizontal, it will cause some patches to include some background areas and affect the overall accuracy. Our future work will be focus on script identification in non-horizontal text images.
Conflict of interest
The authors declare that there is no confilict of interest regrading the publication of this paper.
Footnotes
Acknowledgments
This work is supported by the Natural Science Special Talent projects of Lingnan Normal University (No. ZL2021015), the Natural Science Foundation of China (No. 61962038) and the “BAGUI Scholar” Program of Guangxi Zhuang Autonomous Region of China (No. 201979).