
Abstract
Speech enhancement is a very important problem in various speech processing applications. Recently, supervised speech enhancement using deep learning approaches to estimate a time-frequency mask have proved remarkable performance gain. In this paper, we have proposed time-frequency masking-based supervised speech enhancement method for improving intelligibility and quality of the noisy speech. We believe that a large performance gain can be achieved if deep neural networks (DNNs) are layer-wise pre-trained by stacking Gaussian-Bernoulli Restricted Boltzmann Machine (GB-RBM). The proposed DNN is called as Gaussian-Bernoulli Deep Belief Network (GB-DBN) and are optimized by minimizing errors between the estimated and pre-defined masks. Non-linear Mel-Scale weighted mean square error (LMW-MSE) loss function is used as training criterion. We have examined the performance of the proposed pre-training scheme using different DNNs which are established on three time-frequency masks comprised of the ideal amplitude mask (IAM), ideal ratio mask (IRM), and phase sensitive mask (PSM). The results in different noisy conditions demonstrated that when DNNs are pre-trained by the proposed scheme provided a persistent performance gain in terms of the perceived speech intelligibility and quality. Also, the proposed pre-training scheme is effective and robust in noisy training data.
Keywords
Introduction
The development of the robust methods in the speech processing has captivated substantial attention. Robust processing addresses the problems by actual usage scenarios to maintain or improve the performance of various systems. There can be approaches for robust processing in system pipeline, either replacing some stages, e.g. robust feature extraction or adding method at vital step, e.g. feature normalization. Speech enhancement appears as pre-processing step, and act directly on the speech signals to either improve the speech intelligibility and quality or feeding a speech processing system; e.g., automatic speech recognition (ASR) system. The aforementioned scenario aims to design a robust speech enhancement method that can attain performance in both purposes; however, simultaneous performance gain is a challenging task [1].
Speech enhancement has been the goal of research efforts for previous several decades. Indeed, substantial advancements in understanding the acoustic distortion of the speech signals have been observed during these periods, and countless useful proposals have been presented attempting more effective enhancement methods. The problems and associated solutions differ whether dealing with single-channel or multi-channels. Single-channel speech enhancement has been widely explored and has developed state-of-the-art methods which have been divided into two major classes: supervised and unsupervised speech enhancement. Usually, unsupervised speech enhancement has been performed using statistical methods and established several spectral filtering approaches such as spectral subtraction [2–4] and Wiener filtering [5, 6]. In addition, estimators of the clean speech signals, such as Minimum-Mean Square Error (MMSE) estimator [7] and log-spectral amplitude estimator [8], which have been the motivation for various speech estimation methods, e.g. the Minima Controlled Recursive Averaging (MCRA) [9], Multiplicatively-Modified Log-Spectral Amplitude (MM-LSA) [10], and Optimally-Modified Log-Spectral Amplitude (OM-LSA) [11]. Although, the statistical methods have developed as state-of-the-art for many years, these methods have few main shortcomings which affect their performance, especially performance in non-stationary noise sources. Their formulations are based on the unrealistic assumptions, such as, uncorrelated nature of spectral coefficients in speech frames. However, spectral coefficients in speech frames are actually correlated at different time intervals and in various frequencies [12]. These methods are also involved in a running estimate of noise and clean speech variances; still such estimates are usually deprived for non-stationary noisy speech samples.
Alternatively, learning approaches, for illustration, the Gaussian Mixture Models (GMMs) [13, 14], Support Vector Machine (SVM) [15], Non-negative Matrix Factorization (NMF) [16–18] and Neural Networks [19] have been developed and examined for speech enhancement. In recent years, the speech enhancement is considered as a supervised learning problem, formerly motivated by the approach of time-frequency (T-F) masking in Computational Auditory Scene Analysis (CASA). In such enhancement methods, the trained learning machines directly estimate the underlying clean speech or estimate a T-F mask like IBM, IRM etc. which are enforced to the T-F representation of the contaminated speech to procure estimate of enhanced speech [20]. Perhaps, paradigms of the data-driven methods present a convenient explanation to grasp the complex mechanism of acoustic speech distortion. Recently, lots of DNN frameworks have been developed with encouraging outcomes. Starting from the autoencoders to feed-forward DNNs, many frameworks have been evaluated on speech enhancement task [21–26]. DNN-based enhancement deal with three primary attributes: the learning algorithm, the training-target, and the complementary acoustic features. Pursuant to the above explanation, DNN-based supervised speech enhancement methods can be categorized into two underlying classes: (
In recent past, supervised speech enhancement methods using deep learning frameworks have accomplished enormous performance gain and outperformed the conventional speech enhancement methods based on signal processing techniques [27]. Wang and Wang [15] first suggested and implemented the deep neural network for the binary classification. Their proposed scheme notably outperformed the earlier methods by using feed-forward deep networks and RBM pre-training for subband classification to estimate IBM [15]. It has demonstrated that DNN comprises of IRM achieved even better results than IBM and considerably improved the speech quality and predicted speech intelligibility [28]. A unified Stochastic Gradient Descent (SGD) and Monte Carlo Markov Chain (MCMC) method is proposed for RBM pre-training and demonstrated better outcomes [29]. Bayesian estimation methods have been realized for RBM pre-training [30]. Alternative variants of RBM such as Recurrent Temporal RBM [31], conditional RBM, Gaussian RBM, pointwise gated RBM and cardinality RBM have been evolved by changing regular RBM framework. RBMs and their deep frameworks have been usually enforced in several applications, e.g., feature learning, classification, etc. A comprehensive insight of RBMs and their deep structures can be found in the study [32]. A Deep Auto-Encoder (DAE) has been proposed to enhance the noisy speech and learnt mapping from the Mel-frequency power spectra of noisy speech samples [33]. A non-linear noise-aware regression DNN network for the speech enhancement has been proposed, which was based on the spectral-mapping by utilizing the log power spectra of noisy speech signals for better generalization to unseen noise [21]. The masking based speech enhancement methods outperformed the mapping based methods; however, large performance deterioration can take place because of mismatch between the noisy and clean speech. A masking-based deep speech enhancement method is proposed in [34], where two separate restoration layers are integrated to address mismatching. In addition, a DNN-based multi-target approach has been proposed to estimate the target speech and interfering noise. Such dual-output method showed improved perceived speech quality [35]. Besides, a number of speech enhancement methods are available in the literature, where sources have been modeled jointly in mixtures using a deep RNN framework [37, 38]. In [38], RNN-based speech enhancement method is proposed which exploited the recurrent temporal RBM to explore temporal-correlation between speech frames. This idea has been extended to the features of input and output signals into the elemental feature-spaces. The proposed network has been fine-tuned by a jointly optimized deep RNN with additional masking layer which has been enforced a restoration limitation.
In this paper, we have studied the complex theoretical background of the learning algorithms to train deep neural networks in order to formulate the T-F masking-based speech enhancement. The bottom line of deep learning is the adaptation of hidden layers quantity such that network may learn from the input speech features [39, 40]. In contrast to shallow neural networks (SNNs), if DNNs are directly trained by using a standard backpropagation, the errors propagate backward in network and the gradient turns insignificantly small that alters the weights updating capability of a very deep network in the prior layers. In deep networks research, this gradient-vanishing problem is recognized to be one of the core challenges. To address this problem, a robust multi-layer generative framework is proposed, called as Deep Belief Network (DBN), a layer wise pre-trained DNN with stacked multiple-RBMs [41]. After pre-training, the backpropagation is applied. This present work differs from the previous studies. We have formulated and examined three different T-F masking-based DNNs for single-channel supervised speech enhancement. A layer-wise pre-training scheme for DNN is proposed by stacking GB-RBM, examined to be more efficient in dealing the noisy training data than typical RBM. The aim of this work is not to develop a state-of-the-art, but somewhat to examine GB-RBM-based deep learning and to analyze performance of the GB-DBN with other speech enhancement approaches which have used the regular RBM. Additional improvements can be obtained with more complex and robust deep networks. The main contributions of this study are summarized and discussed below: A layer wise pre-training scheme is proposed by stacking GB-RBM, examined to be more efficient in dealing the noisy data than typical RBM. Instead of binary values in visible layer, GB-RBM has adopted the real-valued data and replaced binary visible units with real-valued Gaussian distribution; but, hidden layers remained binary. The parameters have been initialized by layer wise unsupervised pre-training using GB-RBM. The output layer is combined with the pre-trained network. The parameters of DNNs are fine-tuned through adaptive gradient descent and backpropagation. In experiments, it has been noticed that a pre-trained GB-RBM outperformed the DNNs that have been randomly initialized or pre-trained with regular RBM for the speech enhancement. Conventional speech enhancement based on DNNs usually uses mean square error (MSE) as loss function. Since MSE measures the errors using a linear-frequency scale; therefore, error measurements are not aligned with human auditory perception. Here, DNNs are trained by applying Mel-frequency scaled gradients which are more sensitive towards the vital perceptual bands. The proposed GB-DBN is optimized by minimizing the error using LMW-MSE loss function. In experiments, it has been noticed that improved speech quality is obtained when LMW-MSE loss function is used. Performance of the proposed pre-training scheme is examined by using different DNNs which are created on IRM, IAM, and PSM.
The remaining paper is organized as follows: In Section 2, we presented the main design methodology of the proposed GB-DBN-based speech enhancement with a detailed description of T-F masks; feature extraction, DNN architectures and loss function. In Section 3, experiments are presented. We have presented results and discussions in Section 4. Finally, the concluding remarks are drawn in Section 5.
Proposed deep belief network with GB-RBM
We have proposed a supervised speech enhancement method to estimate T-F masks from input noisy speech features. For robust learning of the input acoustic features, DNNs are formulated with pre-trained GB-DBN, constructed by a layer-wise stacking of multiple GB-RBMs. The input noisy speech y(n) is transformed into Short-Time Fourier Transform (STFT) domain by computing DFT of overlapped windowed frames. Time-frequency masks are estimated from the noisy acoustic features and the estimated mask is applied to magnitude of the noisy magnitude, given as:
Where
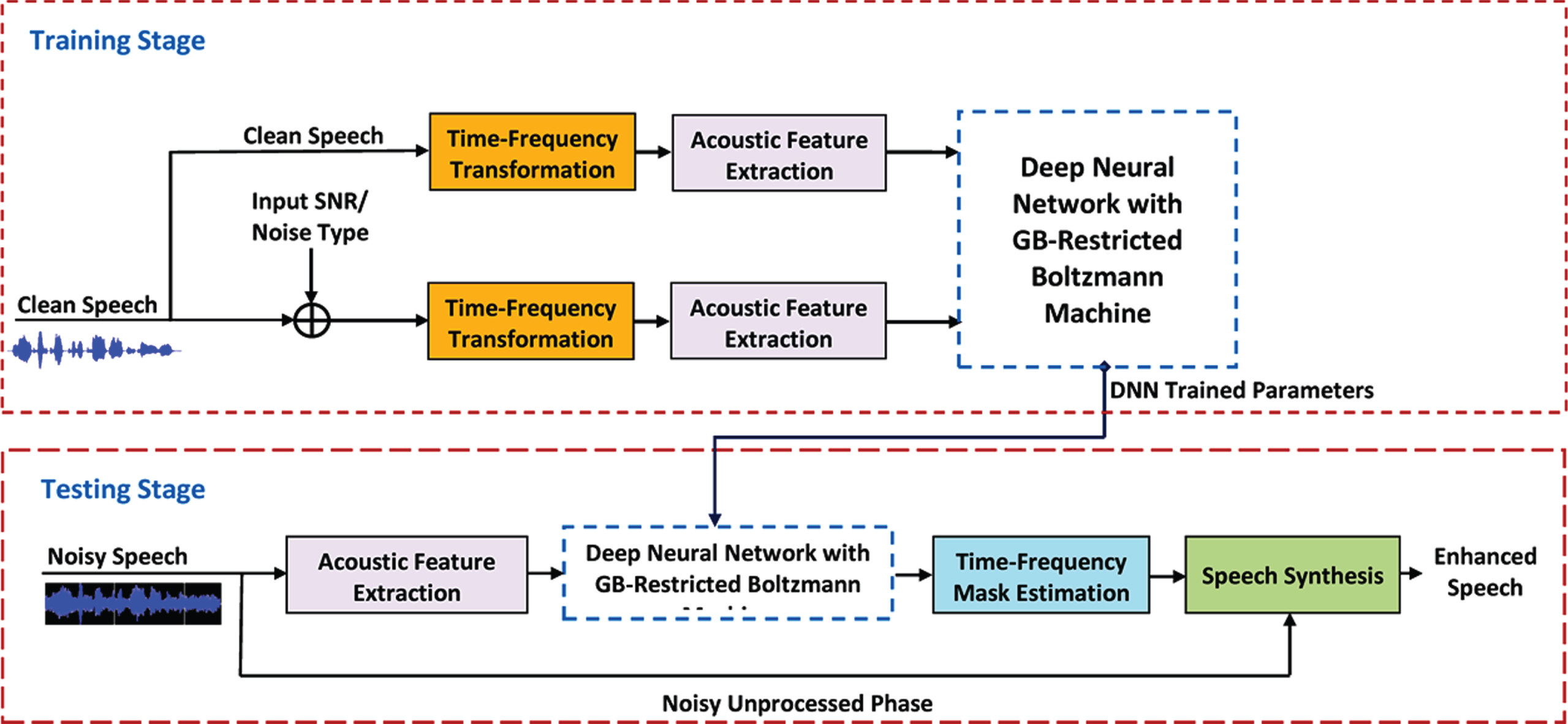
Block diagram of Deep Speech Enhancement framework.
The RBM is energy-based model and is convenient for representing latent features that cannot be observed but surely exist in the background. The Bernoulli-Bernoulli RBM (BB-RBM) was first introduced and it defines distribution of the binary-valued visible variables
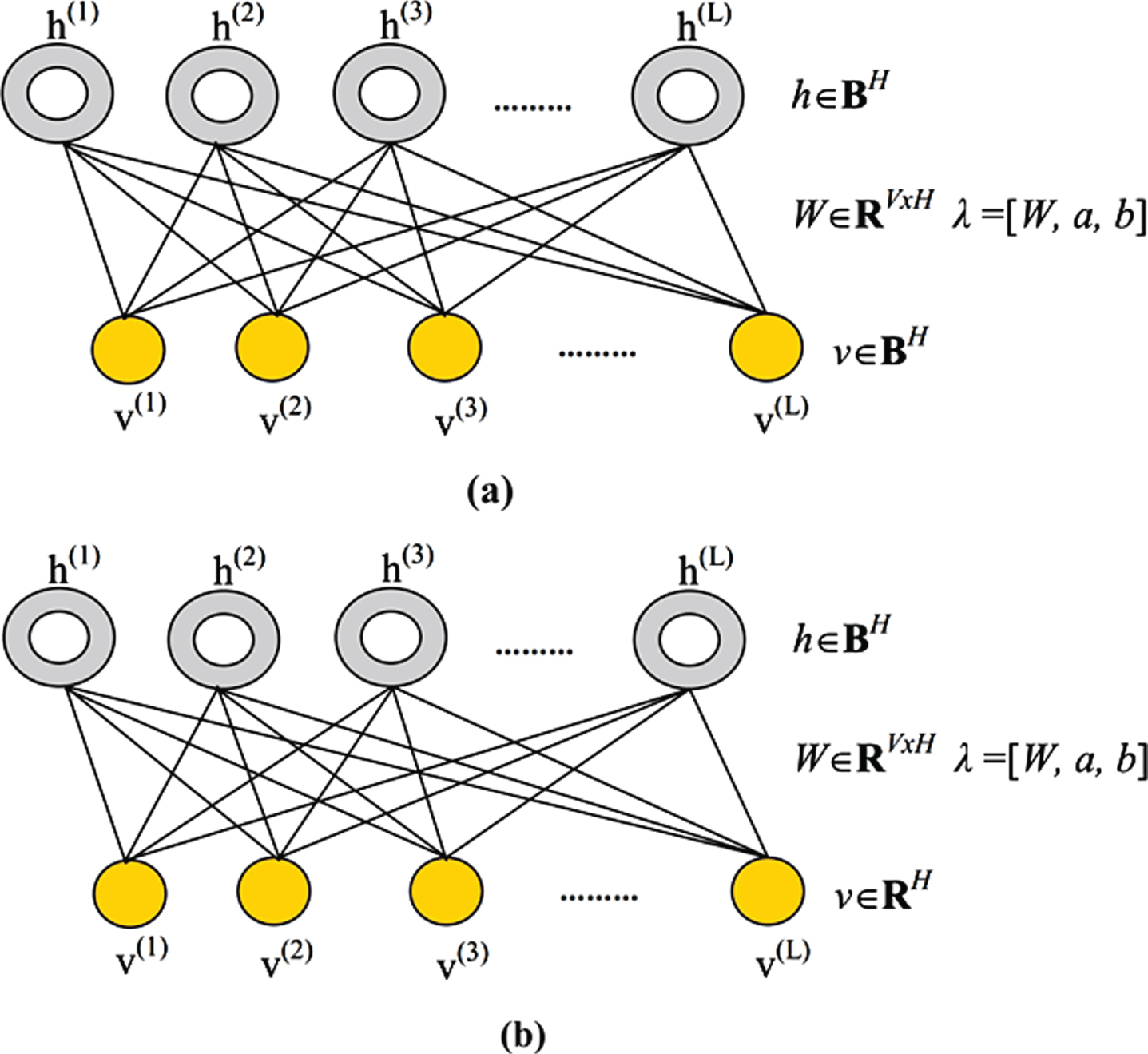
Schematics of (a) BB-RBM, and (b) GB-RBM.
The corresponding probability is given by equation as:
Where, Sig (.) shows sigmoid function and N
L
+1 =0. For a given training data, the aim of GB-RBM pre-training is to identify the best possible parameter λ that increases the probability of training data. For identifying the optimal parameter λ, the stochastic gradient-descent method is applied as:
Where,
Estimating time-frequency masks is an important step towards predicting the estimate of magnitude spectra of clean speech signals. We trained different DNNs, which are formulated on three on hand time-frequency masks comprised of IRM, IAM, and PSM.
Ideal ratio mask (IRM)
IRM represents a soft adaptation of IBM; and can be defined on the cochleagram or spectrogram [28] time-frequency representation of the noisy speech:
Where, |S(k,f)|2 and |E(k,f)|2 shows magnitude squared spectrum of the underlying clean speech signal and the noise, whereas β indicates a tuning parameter and is fixed to β=0.5. IRM is a usual time-frequency mask for speech enhancement methods [43–45] and is bounded to follow
Another useful time-frequency mask is IAM, also known as FFT-Mask [20] and is defined as:
By using the IAM, we can estimate the exact |S(k,f)| given the magnitude spectrum of the noisy speech |Y(k,f)|. IAM follows
IRM and IAM do not deal with the phase between clean speech and noisy speech signals. The PSM [46], however, takes this difference into the account and is defined as:
Where,
φ
Y
and
φ
S
denotes the phase of the noisy and underlying clean speech, respectively. Although, PSM is unbounded theoretically, we found analytically that majority of PSM is in range of
Sets of the complementary acoustic features are extracted from input speech at frame level. The acoustic features include: 13-D relative spectral transformed perceptual linear prediction coefficients (RASTA-PLP), 31-D Mel-frequency cepstral coefficients (MFCC), 15-D amplitude modulation spectrogram (AMS) and 64-D Gammatone filter energies (GFE). All acoustic features are concatenated with the corresponding delta (Δ) and double-delta (ΔΔ) features and affixed with all raw features. Finally, a set of 1845-D acoustic features is obtained which is used for the training and enhancement phases. Additionally, an ARMA (Autoregressive moving average) filter is also used in order to flat the acoustic features trajectories [47]. All the feature vectors are normalized to the zero-mean and unit-variance.
Network architecture
The selected parameter settings for DNN training are as follows. The deep network has been optimized by using non-linear Mel-scale weighted MSE criteria. Each DNN has three hidden layers. Each hidden layer contains 1024 neurons. The rectified linear unit (ReLU) has been used as an activation function in the hidden layers since ReLU allows excellent optimization with quick learning [48]. The output layer has used sigmoid activation function. The number of epochs for backpropagation training has set to 50. Moreover, the dropout regularization has been used to avoid overfitting. The dropout rates of 0.2 and batch size of 128 are used. The scaling factor for adaptive stochastic gradient descent is set to 0.0010, and the learning rate is minimized linearly from 0.06 to 0.002. The momentum term for the initial few epochs is set to 0.4, and increased for other epochs and set to 0.8. The training process is illustrated in Fig. 3.

DNN training architecture to estimate IRM, IAM and PSM.
In conventional training stage, MSE between estimated and the target mask is minimized, which is given by:
The LMSE in (11) has been replaced with LMW-MSE in the proposed method which follows Mel-frequency scale in order to learn error weights from different frequency bins selectively. Since MSE measures the errors using a linear-frequency scale; therefore, error measurements are not aligned with human auditory perception. Here, DNNs are trained by applying Mel-frequency scaled gradients which are more sensitive towards vital perceptual bands. Mel-frequency fMel is given as:
Where, f is linear frequency. The significance of all spectral coefficients could be measured by the derivatives of fMel at the corresponding frequencies fC, such that:
Where, ξ shows a constant used to set the minimum value of the weights. The CMW-MSE is determined by multiplying the normalized weights W(f) with all elements of CMSE as follows:
Where, W(f) is given as:
Compared to CMSE, CMW-MSE targeted the errors in frequencies that are more important for the human auditory system.
The random initialization of the parameters usually underperforms during optimization. In order to circumvent this problem, an unsupervised pre-training scheme using RBMs has been selected to initialize network parameters. The significant preference of the pre-training is initialization of network parameters. During fine-tuning (back-propagation) enforcement, a less over-fitting is produced and also, the network is prevented to be stuck at the local optima. RBM represents a generative graphical model composed of multiple layers of latent variables (hidden units), with connections between the layers but not between units within each layer. We explicitly adopted the greedy layer wise pre-training approach [49]. This approach works as: First, for a hidden layer, the network parameters are locally trained by enforcing the unsupervised GB-RBM learning method and secondly, the parameters of the previous hidden layer are considered as the feature extractors. Each new layer that is stacked on the top of the GB-RBM will model the output of the previous layer and aims at extracting higher-level dependencies between the original inputs variables, thereby improving the ability of the network to capture the underlying regularities in the data. The greedy layer-wise training of a RBM with 3 hidden layers is depicted in Fig. 4. The GB-DBN in Fig. 4 contains a layer of visible units
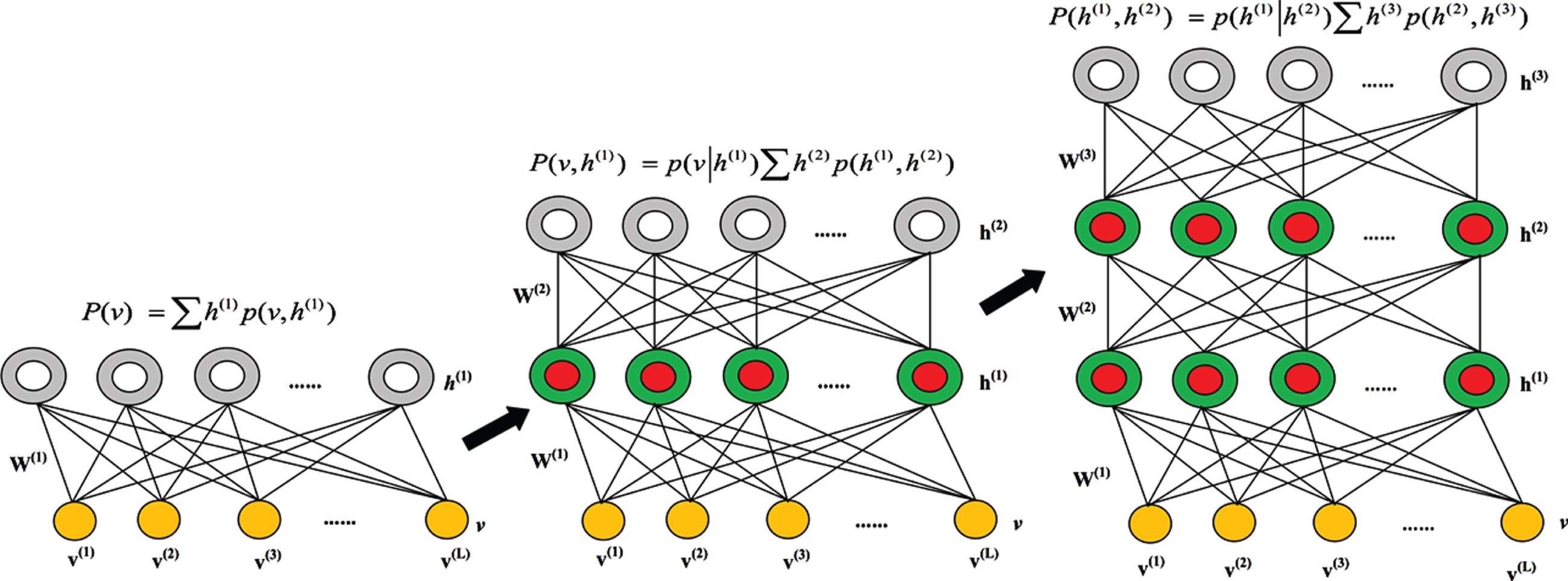
Flow diagram of Greedy layer-wise training scheme to construct GB-DBN in unsupervised approach.
After pre-training the hidden layers, the parameters of network are initialized. Hereafter, a trained DBN structure is added, which formulates a fully pre-trained DNN. The complete structure is then fine-tuned by using back-propagation scheme with define data. The optimization method in [50] (Adam: Adaptive momentum estimator) has been used for fine-tuning, which provides the advantage of the stochastic gradient descent with momentum. Additionally, batch-normalization [51] has also been enforced that improves the robustness of DNN.
Experimental setting
To access the performance of the proposed method, the clean speech utterances are collected from GRID corpus [52], and IEEE corpus [53]. The GRID corpus contains 1000 speech utterances, spoken by 34 different speakers (18 male and 16 female). Similarly, IEEE corpus contains 720 phonetically balanced utterances. To generate noisy stimuli during DNN training, we have used 12 different noises: airport, babble, buccaneer, coffee-shop.
Destroyer-engine, destroyer-ops, f16, factory, hf-channel, pink, volvo and white noise from the AURORA database [54]. The spectrograms of all the noise sources used for training are depicted in Fig. 5. The speech utterances and noises are re-sampled to 16 kHz. Acoustic Features are extracted with frame length set to 20 ms and the frame shift is set to 10 ms. All clean utterances are mixed with the aforesaid noises at SNR levels ranging from –5 dB to+5 dB with 5 dB step.
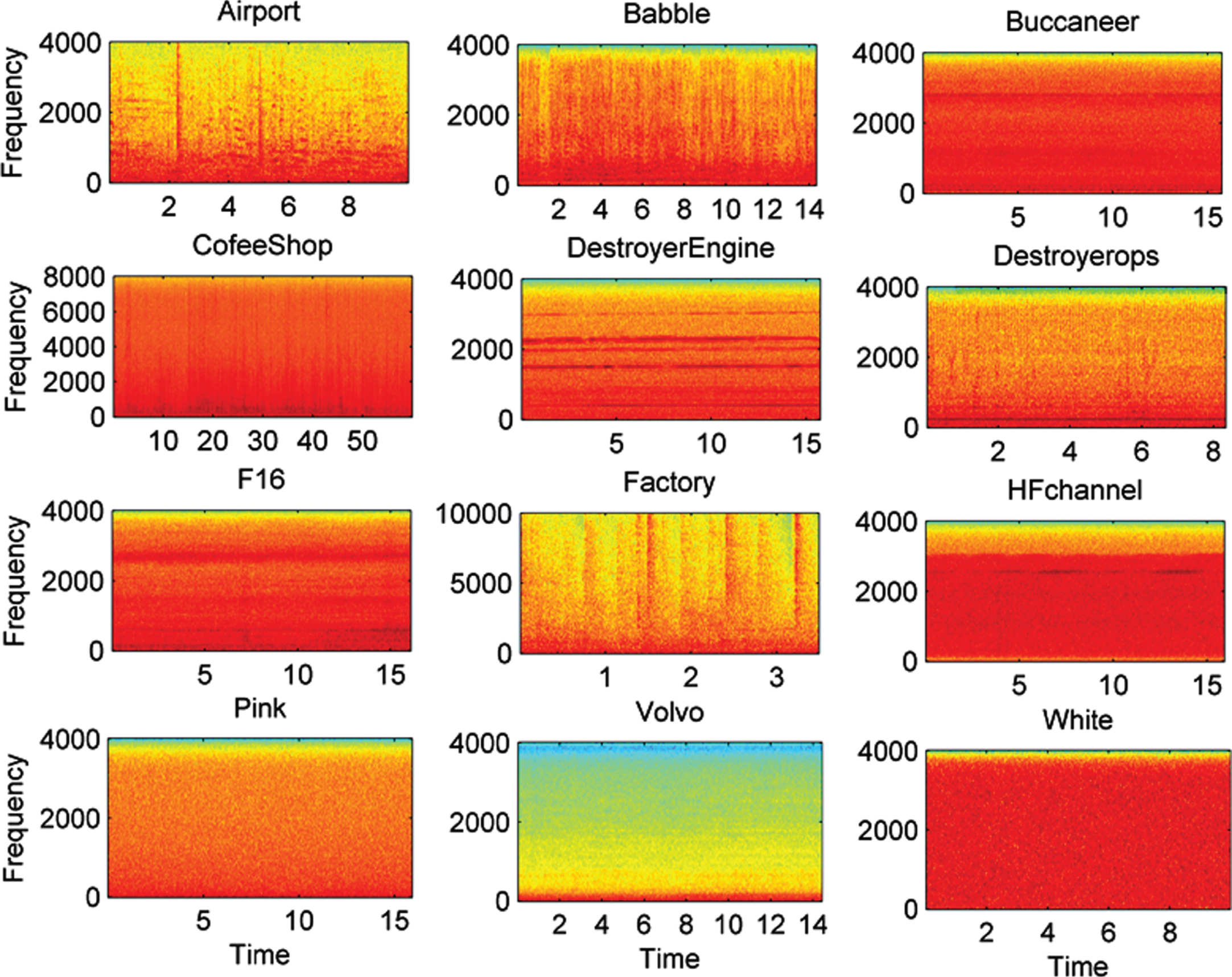
Spectrograms of 12 noise sources used to generate noisy training set.
According to the time-frequency masks, the training criterion, and pre-training approach, we have created various DNNs, listed in Table 1. To express all DNNs, we have adopted a representation: (DNN-<time-frequency Mask> -<Pre-Training>). For example, a speech enhancement method denoted by DNN-IAM-RBM, it implies that the training-target of this deep speech enhancement method is IAM and the RBM is enforced for pre-training of parameters. Similarly, a deep speech enhancement method which have not been pretrained by either RBM or GB-RBM, are expressed as DNN-IAM-Random, which implies that the network parameters are randomly initialized. After pretraining, all DNN structures have been trained in supervised style using back-propagation with Adam optimizer. The dropout regularization has been used to avoid overfitting [55]. The dropout rate of 0.2 and batch size of 128 has been used. The time-frequency masks are constructed from the DFT of the noisy and underlying clean speech utterance. The DFTs are computed by segmenting the noisy time-domain speech signal into 20 ms frames, using 50% overlap between contiguous frames after applying the Hanning windowing function. The Gmin is set to 20 dB for all deep enhancement methods. All the DNN structures listed in Table 1 have been trained with the same training dataset, and we have evaluated the CMW-MSE cost function during the training. The cost optimization curves at epochs for different deep speech enhancement methods with IAM training-target have been depicted in Fig. 6.
DNN Speech Enhancement Methods with all settings
DNN Speech Enhancement Methods with all settings

Cost optimization curves of different Deep speech enhancement methods.
Four objective evaluation measures have been considered to examine the performance of the proposed deep speech enhancement methods. Short-time objective intelligibility (STOI) and extended STOI (ESTOI) are used to predict the intelligibility of the speech. Perceptual evaluation of speech quality (PESQ) is used to measure the quality of the perceived speech. Moreover, the Segmental SNR (SNRSeg) is used to examine the noise reduction capacity in the enhanced speech. Each of the objective evaluation metrics is briefly expressed as: PESQ: An ITU-T P.862 standard objective evaluation metric, predicts the perceptual quality of the perceived speech by providing an output score from 0.5 to 4.5, and a high score implies better speech quality. PESQ output scores correlate with the MOS (mean opinion score) in the subjective listening tests. Initially, PESQ [56] has been developed for the narrow-band (08 kHz) telephone speech. However, PESQ has been extended to ITU-T P.862.2 [57], which can deal with the wide-band (16 kHz) systems. The PESQ extension has been widely used to evaluate speech enhancement methods. STOI: It is also an objective evaluation metric, which predicts the intelligibility of the perceived speech by providing an output score in 0 to 1 range, and a high value implies better speech intelligibility. The computation of STOI scores is based on the correlation between the underlying clean speech and the processed speech signal in the short-time overlapped segments [58]. ESTOI: It is also an objective evaluation metric, which predicts the intelligibility of the perceived speech by providing an output score from 0 to 1, and a high score implies better speech intelligibility [59]. SNRSeg: Signal to noise ratio objective evaluation metric is one of the earliest methods used to evaluate a speech enhancement method. However, the SNR metric has shown a poor correlation with the speech quality as the average has been computed over entire signal. Since the speech signals are highly nonstationary; rapid variations in speech signals can cause incorrect SNR average. As a result; average over entire signal can remove vital speech components. To evade this problem, SNR is calculated in segments and then averaged, known as the segmental SNR (SNRSeg) [1].
Results and discussions
We first examined the performance of the deep speech enhancement methods in terms of the speech intelligibility by using STOI and ESTOI at -5 dB, 0 dB and 5 dB SNR levels. STOI and ESTOI measure the overall speech intelligibility of the enhanced speech. The higher scores of the STOI and ESTOI imply the improved performance. Table 2 shows the achieved STOI and ESTOI scores of all deep speech enhancement methods. The STOI and ESTOI scores have been averaged over all noise sources and training utterances. It is evident in the Table 2 that the proposed training scheme with different training-targets outperformed the RBM and random training schemes consistently at all SNR levels. The only exceptions are at 5 dB SNR, where we deem that all deep speech enhancement methods performed very well. However, the proposed training schemes outperformed the competing methods at all SNR levels. The deep speech enhancement with IAM training-target and GBRBM (DNN-IAM-GBRBM) provided the highest intelligibility scores (STOI≥77%, and ESTOI≥67%) for all noise sources at SNR≥-5 dB. Overall, the best intelligibility scores in terms of the STOI and ESTOI are achieved with DNN-IAM-GBRBM, which are: 89.36% and 84.19%, respectively. Similarly, IRM training-target and GBRBM (DNN-IRM-GBRBM) provided the second best intelligibility scores (STO I≥74.16%, and ESTOI≥66.26%) for all noise sources at SNR≥-5 dB. The highest intelligibility scores with the DNN-IRM-GBRBM are: 83.31% and 82.14%, respectively. DNN-PSM-GBRBM outperformed the RBM and Random training schemes; however, underperformed the DNN-IRMM-GBRBM and DNN-IAM-GBRBM. The highest intelligibility scores with the DNN-PSM-GBRBM are: 81.90% and 80.35%, respectively. For example, the average intelligibility scores are improved from 51.6% and 41.40% with unprocessed noisy speech to 77.32% and 67.16% with DNN-IAM-GBRBM (ΔSTOI=25.71% and ΔESTOI=25.76%) at -5 dB SNR. Similarly, the average scores are improved from 68.25% and 57.74% with DNN-IRM-RBM to 74.16% and 66.26% with DNN-IRM-GBRBM (ΔSTOI=5.91% and ΔESTOI=8.52%) at -5 dB SNR. Finally, the average scores are improved from 60.10% and 49.01% with DNN-PSM-Random to 70.67% and 64.39% with DNN-PSM-GBRBM (ΔSTOI=10.6% and ΔESTOI=15.38%) at -5 dB SNR.
Average Predicted Objective Scores for all DNN-Speech Enhancement Methods
Average Predicted Objective Scores for all DNN-Speech Enhancement Methods
Note: The shaded boxes show the best performance.
We examined the performance of proposed deep speech enhancement methods in terms of the speech quality by using PESQ at -5 dB, 0 dB and 5 dB SNR levels. Table 3 shows the PESQ scores of all speech enhancement methods. The PESQ scores have been averaged over all noise sources and training utterances. It is clear in the Table 3 that the proposed training scheme with different training-targets outperformed the RBM and random training schemes consistently at all SNR levels. The deep speech enhancement with IAM training-target and GBRBM (DNN-IAM-GBRBM) achieved the best scores (PESQ≥1.99) for all noise sources at SNR≥-5 dB. Overall, the best score in terms of the PESQ is achieved with DNN-IAM-GBRBM, that is, 2.66. IRM training-target and GBRBM (DNN-IRM-GBRBM) achieved the second best scores (PESQ≥1.94) for all noise sources at SNR≥-5 dB. The highest score with DNN-IRM-GBRBM is: 2.48. Again, DNN-PSM-GBRBM outperformed the RBM and Random training schemes in terms of PESQ; however, underperformed the DNN-IRMM-GBRBM and DNN-IAM-GBRBM. The highest PESQ score with the DNN-PSM-GBRBM is: 2.41. The average PESQ scores are improved from 1.39 with unprocessed noisy speech to 1.94 with DNN-IRM-GBRBM (ΔPESQ=0.55) at -5 dB SNR. Similarly, the average PESQ scores are improved from 1.95 with DNN-IAM-Random to 2.39 with DNN-IAM-GBRBM (ΔPESQ=0.44) at 0 dB SNR. Lastly, the average PESQ scores are improved from 2.33 with DNN-PSM-RBM to 2.41 with DNN-PSM-GBRBM at 5 dB SNR. We also examined the performance of the proposed deep speech enhancement methods in terms of the noise reduction in the enhanced speech by using SNRSeg at -5 dB, 0 dB and 5 dB SNRs. Table 3 shows the average results of all deep speech enhancement methods in terms of the SNRSeg. The average predicted SNRSeg scores with the proposed DNN structures are consistently higher than the competing structures at all noise sources and SNR levels, indicates that the proposed methods efficiently reduced the noise in enhanced speech. Figure 7 demonstrates the average STOI, ESTOI, PESQ and SNRSeg improvements achieved with all speech enhancement methods. The proposed DNN structures outperformed the competing structures consistently; however, the only exceptions are at 5 dB SNR, where we deem that all DNN structures performed well. Table 4 indicates the performance comparison against conventional speech enhancement methods. The competing methods include: Non-negative matrix Factorization (NMF) [16], Non-negative Dynamic System (NNDS) [60], Non-negative Robust Principle Component Analysis (NRPCA) [61], and Deep denoising Audio Encoder (DDAE) [62]. The results in Table 4 indicate a consistent improvement in all measuring parameters. To validate the superiority of the proposed DNN structures at high SNRs, we have conducted the one-way analysis-of-variance (ANOVA) statistical analysis (at 0 dB and 5 dB). All the statistical tests are conducted at 95% confidence interval.
Average Predicted Objective Scores for all DNN-Speech Enhancement Methods
Note: The shaded boxes show the best performance.

Average PESQ, STOI, ESTOI and SNRSeg improvements for 12 noise sources with three timefrequency masks (training-targets).
Differences between achieved scores are deemed statistically significant if probability (Pvalue) is lower than 0.05 (P < 0.05) and Fvalue of FDistribution is higher than critical value of FDistribution (Fvalue > FCritical). Table 5 demonstrates the statistical test at 95% confidence interval with FCritical is 3.09. It is clear from the Table 5 that Pvalues of all the proposed DNN structures are less than 0.05 and FCritical are higher than 3.09, which indicates the statistical significance of the proposed structures over the competing methods.
Finally, we have conducted the time-varying spectral analysis to evaluate the performance of deep speech enhancement methods. For time-varying spectral analysis, we have mixed a clean speech utterance with the babble noise at 0 dB SNR. The spectrograms of the different DNN structures with training-targets and training schemes are depicted in Fig. 8. It is evident in the spectrograms that the harmonic spectrums of the vowels and the formant peaks are sustained. Moreover, the spectrograms of the proposed speech enhancement methods also revealed an excellent structure during speech activity. The spectrums during the speech-pause areas show that the proposed DNN structures outperformed in reducing residual noise. The weak harmonics in high-frequency bands are well structured. Therefore, the proposed DNN structures achieved the better perceived speech quality. The utterances with weak energies are better preserved, and yielded less speech distortion. Hence, the proposed DNN structures achieved the improved speech intelligibility. Figure 9 shows the spectrograms of the proposed speech enhancement methods with various training-targets and training schemes and a clean speech utterance is mixed with the factory noise at -5 dB SNR level.
Average Predicted Objective Scores for the Proposed and competing methods
Statistical Analysis of Average Objective Scores at High SNRs at 95% confidence interval with FCritical is 3.09 and PCritical is 0.05
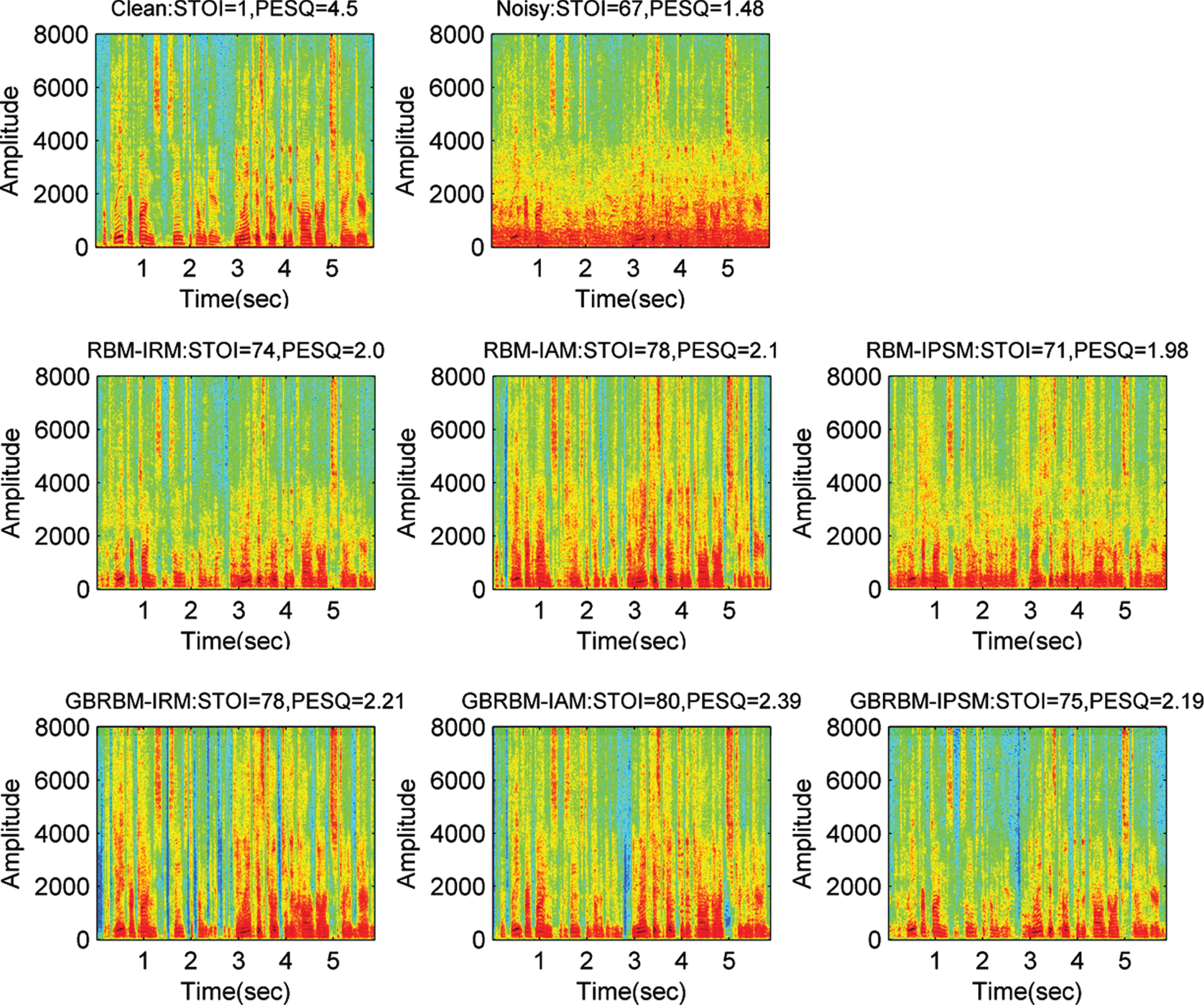
Spectrograms of utterance processed by DNN-IAM-GBRBM, DNN-IRM-GBRBM, and DNN-IPSMGBRBM systems trained with IAM, IRM and IPSM. The input utterance is corrupted by factory noise at -5 dB.

Spectrograms of utterance processed by proposed deep speech enhancement trained by GB-RBM and regular RBM with IAM, IRM and IPSM training targets. The input utterance is corrupted by babble noise at 0 dB.
In this study, we have presented the time-frequency masking-based supervised deep learning structures for the speech enhancement. We have established and examined that a significant gain in the performance can be achieved if the DNN structures are layer-wise pretrained by stacking the GB-RBM. We have estimated three training-targets (IRM, IAM and PSM) with GBRBM training scheme and the proposed deep structures are named as the GB-DBN. All the DNN structures are optimized by minimizing the error using the CMW-MSE objective cost function. We have examined in this study that DBN with regular RBM is not very effective in supervised speech enhancement and extended the concept to present an effective training scheme. It is examined that in regular RBM, the weights and biases are binary-valued which have been imposed the constraints on their representations in the real-world environments. Secondly, the RBM underperforms when trained by severely noisy data. We have extended the concept of the regular RBM to GB-RMB and instead of using binary-values in the visible layer; the RBM has been extended to deal with the real-valued data. The proposed deep structures are evaluated with four objective metrics: STOI, ESTOI, PESQ and SNRSeg. We also conducted one-way ANOVA analysis to show the statistical significance at high SNRs. Based on results, following conclusions are drawn: The DNNs pre-trained by formulating the GB-DBN with stacked GB-RBM optimized more than DNN pre-trained with RBM and without any pre-training. It is concluded that in terms of the speech intelligibility, the proposed training scheme with different training-targets outperformed the RBM and random training schemes consistently at all SNR levels. The average intelligibility scores are improved from 51.61% and 41.40% with noisy speech to 77.3% and 67.16% with DNN-IAM-GBRBM (ΔSTOI=25.71% and ΔESTOI=25.76%) at -5 dB SNR. Also, the average intelligibility scores are improved from 68.25% and 57.74% with DNN-IRM-RBM to 74.16% and 66.26% with DNN-IRM-GBRBM (ΔSTOI=5.91% and ΔESTOI=8.52%) at -5 dB SNR. lastly, the average scores are improved from 60.10% and 49.01% with DNN-PSM-Random to 70.7% and 64.39% with DNN-PSM-GBRBM (ΔSTOI=10.8% and ΔESTOI=15.4%) at -5 dB SNR It is concluded that in terms of the speech quality, the proposed training scheme with different training-targets outperformed the RBM and random training schemes consistently at all SNR levels. The average PESQ is improved from 1.39 with noisy speech to 1.94 with DNN-IRM-GBRBM (ΔPESQ=0.55) at -5 dB SNR. Similarly, the average PESQ scores are improved from 1.95 with DNN-IAM-Random to 2.39 with DNN-IAM-GBRBM (ΔPESQ=0.44) at 0 dB SNR. Lastly, the average PESQ scores are improved from 2.33 with DNN-PSM-RBM to 2.41 with DNN-PSM-GBRBM at 5 dB SNR. We also concluded that the proposed deep speech enhancement outperformed in terms of the noise reduction in the enhanced speech by using SNRSeg at -5 dB, 0 dB and 5 dB SNRs. The average predicted SNRSeg scores with the proposed DNN structures are consistently higher than the competing DNN structures. It is concluded that in terms of the Pvalues of all the proposed DNN structures are less than 0.05 and FCritical are higher than 3.09, which indicates the statistical significance of the proposed structures over the competing methods. The spectrogram analysis concluded that the harmonic spectrums of the vowels and the formant peaks are sustained. Also, the spectrograms of the proposed methods showed an excellent structure in speech activity areas. The enhanced spectrograms of the proposed method also showed less residual noise during the speech-pause areas. The weak harmonics in high-frequency bands are well structured.
To conclude, the proposed training scheme (GB-RBM) with various training-targets (IRM, IAM and PSM) outperformed, provided high speech quality and intelligibility. In the future work we would be devoted in attempting further improvements in the performance of proposed deep speech enhancement methods through incorporating the phase information. Also, we will systematically examine the acoustic features set to find more robust acoustic features set in order to train the masking based enhancement methods.