
Abstract
Fuzzy C-means clustering algorithm (FCM) is an effective approach for clustering. However, in most existing FCM type frameworks, only in-cluster compactness is taken into account, whereas the between-cluster separability is overlooked. In this paper, to enhance the clustering, by incorporating the feature weighting and data weighting method, we put forward a new weighted fuzzy C-means clustering approach considering between-cluster separability, in which for achieving good compactness and separability, making the in-cluster distances as small as possible and making the between-cluster distances as large as possible, the in-cluster distances and between-cluster distances are taken into account; To achieve the optimal clustering result, the iterative formulas of the feature weights, membership degrees, data weights and cluster centers are obtained by maximizing the in-cluster compactness and the between-cluster separability. Experiments on real-world datasets were carried out, the results showed that the new approach could obtain promising performance.
Introduction
Clustering is a commonly used tool for unsupervised machine learning. Clustering is to divide a dataset into clusters in which the data in different clusters have dissimilar properties whereas data in the same cluster have similarities as more as possible by identifying inherent structures [1]. Clustering has a wide range of uses in kinds of application fields such as image segmentation [2], fault detection [3], vehicle suspension system [4], text organization [5], bioinformatics [6] and others.
Due to simple structure, low computation complexity and easy implementation, fuzzy C-means clustering approach (FCM) [7] has been a widely known clustering approaches and used in many real-world applications [8–18]. In addition, FCM can overcome the problem existing in the hard clustering algorithms with soft partition, that is, a given data could be partitioned into different clusters by different membership degrees.
In most existing FCM type frameworks, only in-cluster compactness is taken into account, whereas the between-cluster separability is overlooked; in the basic FCM, each feature and each data are treated equally, the different importance of different data objects and different features cannot be distinguished effectively. To overcome the above two shortcomings simultaneously, in this paper, we put forward a new weighted fuzzy C-means clustering approach considering between-cluster separability, in which by incorporating the feature weighting and data weighting method, for achieving good compactness and separability, making the in-cluster distances as small as possible and making the between-cluster distances as large as possible, the in-cluster distances and between-cluster distances are taken into account, we maximize between-cluster separability by maximizing the sum of the distances between all data and the other cluster centers; to avoid overfitting and avoid the situation that few features with large feature weights or few data with large data weights may dominate the clustering process, we incorporate the l2-norm regularization terms to feature weights and data weights, so, a novel objective function is developed; based on the new objective function, the iterative formulas of the feature weights, membership degrees, data weights and cluster centers are obtained by maximizing the in-cluster compactness and the between-cluster separability. Real-world datasets are used to assess the performance of the new approach, experimental results have shown that the new algorithm can achieve good clustering performance.
Related work
In this section, we get the related works improving the performance of FCM briefly reviewed.
By learning according to the gradient descent technique, a new feature-weight assignment method is given, and an improving FCM is proposed [19]; To address the problem that the feature-weight vector cannot be adjusted adaptively during the training phase, an improved feature-weighted FCM (IFWFCM) is put forward [20]; Taking the internal connectivity of all data into account, an adaptive fuzzy clustering algorithm (AFCM) is proposed [21]; Considering data weights, an enhanced FCM method in which the values of adaptive parameters are optimized by simulated annealing integrated with particle swarm optimization (SA-PSO) is presented [22]; Taking the neighborhood of each data into account, a conditional spatial fuzzy C-means method is presented [23]; For clustering incomplete data and general non-spherical datasets, an attribute weighted mercer kernel based fuzzy clustering algorithm is put forward [24]; By considering different feature weights and data weights, an improved fuzzy C-means method (DwfwFcm) is proposed [25]; In order to enhance the quality of segmentation for images, considering local information, a generalized kernel weighted FCM is presented [26]; By introducing the feature weighted distance and the power exponent, a double-indices fuzzy subspace clustering algorithm is put forward [27]; A fuzzy clustering integrating the entropy regulation to feature weights (EWFCM) is put forward [28]; By adding the sum of the distances between cluster centers as the separation item, the fuzzy inter-cluster separation clustering method (FICSC) is proposed [29].
Considering the limitations that in most above FCM type frameworks, only in-cluster compactness is taken into account, whereas the between-cluster separability is overlooked, we put forward a new weighted fuzzy C-means approach which not only can perform data weighting and feature weighting, but also can take in-cluster compactness and between-cluster separability into account, at the same time. Also, the l2-norm regularization terms to feature weights and data weights are incorporated into the objective function to harmonize the weighting scatter which makes the approach more effective.
A new weighted fuzzy C-means clustering approach considering between-cluster separability
The proposed approach
In this paper, to achieve good compactness and separability, to make the in-cluster distances as small as possible, make the between-cluster distances as large as possible and make the data not belonging to cluster i be away from the center of cluster i as far as possible, the in-cluster distances and between-cluster distances are taken into account; to distinguish the significance of different feature and different data, an adaptive feature weights matrix and data weights vector [23] are introduced; to avoid overfitting and avoid the situation that few features with large feature weights or few data with large data weights may dominate the clustering process, we incorporate the l2-norm regularization terms to feature weights and data weights into the objective function, so the novel objective function of the new weighted fuzzy C-means clustering algorithm considering between-cluster separability (WFCM_bc) can be defined as:
JWFCM_bc is subjected to the constraint:
In Equation (1), the first item is the sum of in-cluster distances indicating the compactness of the fuzzy partition, X = [x1, x2, ⋯ , x
n
], x
k
= [xk1, xk2, ⋯ , x
km
], m is the number of features,
We can solve the above optimization problem by introducing Lagrange multipliers function:
Let
Because
Let
Because
We can get:
By setting ∂ϕWFCM_bc (U, V, W, F) / ∂f
ij
= 0, we can get the updating rule of f
ij
:
Because
The iterative rule of v ij
By setting ∂ϕWFCM_bc (U, V, W, F) / ∂v
ij
= 0, we get the updating rule of v
ij
:
During the process of clustering by the new approach, in each iteration, we need to update the membership matrix U, feature weights F, data weights W and centroids V, respectively. Suppose the number of iterations is t, we can get the computational updating cost: O (tcmn).
Experiments and results
Datasets
To assess the performance of WFCM_bc presented, by using UCI datasets, experiments were carried out. Knowledge, Haberman, Messidor, Wine and Sonar datasets are used. The information of different datasets is shown in Table 1.
The number of categories, number of features and sample size of different datasets
The number of categories, number of features and sample size of different datasets
In this paper, we apply external cluster performance metrics: normalized mutual information (NMI), Accuracy (AC), Rand index (RI) [30] and internal cluster performance metric: Xie and Beni index (XB) [31] to assess clustering performance.
All datasets are dealt with normalization. To figure out the different impacts on the clustering results with different values of ɛ, γ and θ, we have carried out experiments by comparing the clustering performance (AC, NMI, RI) with the increments of ɛ, γ and θ with 0.0001,0.001, 0.02, 0.2 and 1 when the values of ɛ, γ and θ are in the range of (0,0.001], (0.001,0.01], (0.01,0.1], (0.1,1] and (1,15], respectively. In general, we could obtain the best clustering results when the values of ɛ, γ and θ are set in the range of (0,0.05], (0,0.5] and (0.01,10], respectively, depending on different datasets. The smaller γ is, the difference between data weights will be larger; The smaller θ is, the difference between feature weights will be larger, the difference between feature weights will be smaller with the increase of the value of θ.
We compare the clustering results produced by the proposed WFCM_bc, the conventional FCM [7] and commonly used weighted FCM algorithms: AFCM [21], double-indices fuzzy subspace clustering algorithm based on feature weighted distance (DI-FSC) [27], EWFCM [28]. The clustering results are obtained over 30 independent experiments by different approaches for reducing the impact of initialization.
Take the Knowledge dataset as example, the comparison of XB when the algorithms are convergent is shown in Table 2. XB is the ratio of compactness (COMP) to separation (SPT),
The comparison of XB index on Knowledge dataset with format: mean (±standard deviation)
The comparison of XB index on Knowledge dataset with format: mean (±standard deviation)
The comparison of the mean AC among different approaches on different datasets is shown in Fig. 1; The analysis of variance (ANOVA) has been conducted based on a confidence level of 95%, the statistical analysis including ANOVA results and the comparison of the three external performance metrics is shown in Table 3. Based on the p-values, we can see: AC and RI of the different five approaches have significant difference; we can see from Fig. 1 and Table 3: the mean three performance metrics: NMI, RI and AC of WFCM_bc are better than the other clustering approaches, which shows that the new approach can effectively get the clustering performance improved.
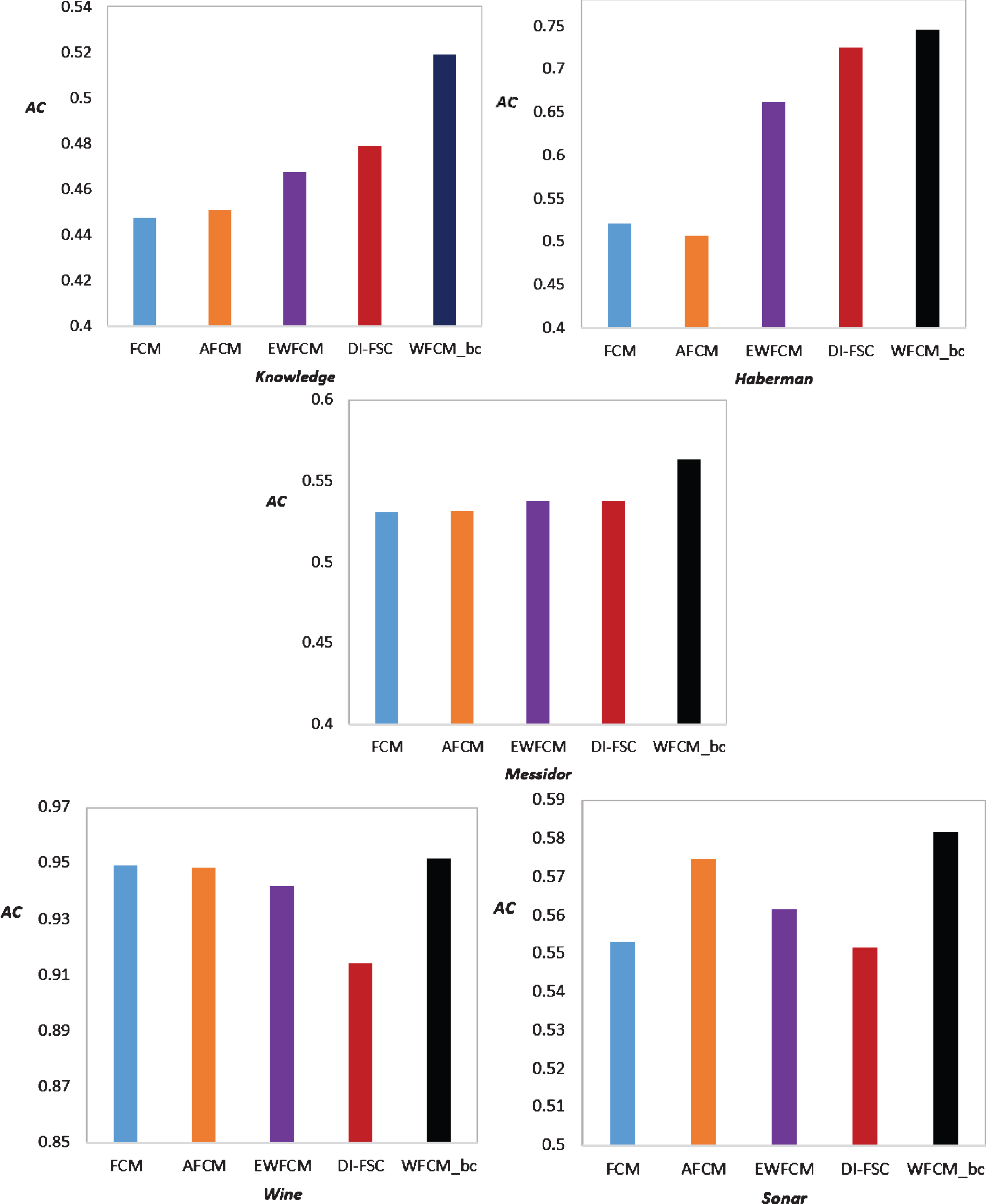
The comparison of the mean AC among different approaches on different datasets.
The statistical analysis of the external cluster performance metrics: ANOVA results and the comparison with format: mean (±standard deviation)
In this paper, a new kind of weighted fuzzy C-means clustering approach considering between-cluster separability is put forward. By incorporating the feature weighting and data weighting method, considering between-cluster separability, we put forward a novel objective function in which the in-cluster distances and between-cluster distances are taken into account, to avoid overfitting and avoid the situation that few features with large feature weights or few data with large data weights may dominate the clustering process, the l2-norm regularization terms to feature weights and data weights are incorporated into the objective function. The iterative formulas of the feature weights, membership degrees, data weights and cluster centers are obtained by maximizing the in-cluster compactness and the between-cluster separability. Experimental results show that the new algorithm can effectively get the clustering performance improved.
There still are some limitations of this approach, such as: it is sensitive to initialization. In future studies, we could combine other methods to further improve the clustering quality and apply this approach to address some practical problems.
Compliance with ethical standards
Conflict of interest: the authors declare that there is no conflict of interest.
Footnotes
Acknowledgments
This work is supported by open project of Anhui province key laboratory of special and heavy load robot (No.TZJQR004-2020), science and technology projects of Xuancheng (No.1932) and national natural science foundation of China (No.61601004, 61602008).