
Abstract
In order to solve some optimization problems with many local optimal solutions, a microbial dynamic optimization (MDO) algorithm is proposed by the kinetic theory of hybrid food chain microorganism cultivation with time delay. In this algorithm, it is assumed that multiple microbial populations are cultivated in a culture system. The growth of microbial populations is not only affected by the flow of culture fluid injected into the culture system, the concentration of nutrients and harmful substances, but also by the interaction between the populations. The influence of culture medium which is injected regularly will suddenly increase the concentration of nutrients and toxic substances, it will suddenly increase the impact on the population. These characteristics are used to construct absorption operators, grabbing operators, hybrid operators, and toxin operators; the global optimal solution of the optimization problem can be quickly solved by these operators and the population growth changes. The simulation experiment results show that the MDO algorithm has certain advantages for solving optimization problems with higher dimensions.
Keywords
Introduction
In engineering, there are many optimization problems with a large number of local optimal solutions, and in many cases, the mathematical expressions of the objective function and constraint conditions of these optimization problems have no restrictions, traditional optimization algorithms cannot solve such optimization problems. At present, the method to solve such optimization problems is swarm intelligence optimization algorithm [1–5]. Different from the traditional optimization algorithm, when the swarm intelligence optimization algorithm solves an optimization problem, it uses a number of trial solutions to perform evolutionary calculations at the same time. This “group attack” method can solve some very difficult optimization problems [6–11]. However, there is no swarm intelligence optimization algorithm that can solve all types of optimization problems [12]. In the swarm intelligence optimization algorithm, each trial solution is compared to an individual with biological characteristics. Some special biological evolution scenarios are converted into the logical structure of the swarm intelligence algorithm. The interaction between the biological individuals active in the scenario is used to construct the evolution operator of individual organisms [13].
Population dynamics is a mathematical theory that reflects the interaction between biological populations [14]. Population dynamics contains many branches, and each branch has the potential to transform into a swarm intelligence algorithm. Based on the Lotka-Volterra model, a special population dynamics optimization algorithm is constructed [15]. The algorithm uses the interaction relationship between the three populations, namely the mutually beneficial coexistence relationship, the competition relationship, and the predator-prey relationship to construct an evolution operator. The evolution characteristics of all operators can ensure that the algorithm has global convergence. By using population dynamics theory, a population dynamics-based optimization (PDO) algorithm is constructed [16]. The algorithm uses predation-being, mutual benefit, fusion, competition, mutation, and selection between any two groups to construct the evolution strategy of the population. An improved PDO algorithm is proposed based on the theory of population dynamics [17]. This algorithm is used to quickly determine the best guide path for eliminating concentrated mine dust from multiple points underground. Another improved PDO algorithm is proposed by using the predation-being theory in population dynamics [18], it can quickly determine the best installation positions of underground mine dust collection stations, underground fans and ventilation structures. In a multi-agent framework, distributed optimization problems are generally described as the minimization of a global objective function, where each agent can get information only from a neighborhood defined by a network topology. To solve the problem, an information-constrained strategy was presented based on population dynamics [19], where payoff functions and tasks are assigned to each node in a connected graph. Searching for the optimal subset of features is known as a challenging problem in feature selection process. To deal with the difficulties involved in this problem, a robust and reliable optimization algorithm is required. Grasshopper Optimization Algorithm (GOA) is employed as a search strategy to design a wrapper-based feature selection method [20]. A new mutation strategy and a bionic bi-population structure are incorporated, a new differential evolution variant is used to enhance the overall performance of the canonical differential evolution algorithm [21]. The biological activity scenarios that have been proposed for swarm intelligence optimization algorithms are very simple and have weak mathematical foundations, such as genetic algorithm, ant colony algorithm, biogeographic algorithm, and bee colony algorithm. Some swarm intelligence optimization algorithms do not even have biological activity scenarios, such as particle swarm algorithm and differential evolution algorithm. If a swarm intelligence optimization algorithm has a clear and vivid biological activity scene, and the scene can be accurately described by mathematical theory, then this scene is extremely conducive to constructing a swarm intelligence optimization algorithm, because the swarm intelligence optimization algorithm is based on good mathematics, its performance is easy to be analyzed.
Microbial culture is the use of a culture room to cultivate one or more microbial populations. Microbial culture kinetics is a mathematical theory that studies the interaction and continuous evolution of microbial populations in a culture room under human control. Microbial culture dynamics is one of the branch of population dynamics [14]. In order to use some special properties of microbial culture dynamics to construct a high-performance swarm intelligence optimization algorithm, in this paper, a time-lag-affected hybrid food chain microbial pulse culture dynamics model is used to construct a microbial dynamics optimization algorithm (microbial dynamics optimization, MDO). In this algorithm, a design idea is adopted, it is different from the existing population dynamics optimization algorithm, and a microbial culture dynamics model is proposed and transformed into a general method, some optimization problems can be solved. The constructed operator can fully reflect the influence of the toxic substances in the culture system and the culture fluid on the microbial population and the interaction relationship between the microbial populations, thus the basic idea of the microbial culture dynamics theory is reflected. The MDO algorithm can converge globally and has certain advantages for solving optimization problems with higher dimensions.
Basic principles of the algorithm
Scene design of MDO algorithm
Suppose that there are N microbial populations living in the microbial culture system E, namely P1, P2,...,P i ,...,P N ; each population not only feeds on the culture fluid in E, but also feeds the other K populations in E for food. In the process of microbial cultivation, the prepared fresh medium is periodically injected into E; at the same time, the useless medium is continuously removed from E; the medium absorbed by the microbial population will not be converted into immediately new microbial population, in other words, there is a period of time in the process of transforming from the culture fluid to the microbial population; as the culture fluid is injected, harmful substances are also injected. In order to control the destructive effects of harmful substances on the population, it is necessary to continuously assess the degree of damage to the population by the harmful substances. The operation of the culture system can be achieved by differently controlling two factors: one is the concentration S of nutrients in the culture solution; the other is the flow rate Q of the culture solution. Changes in the concentration of S will cause changes in the growth of microbial populations.
The characteristics of the microbial population P i can be represented by P i = {fi,1,fi,2,...,fi,n}, where fi,j are the characteristics j of P i , n is the total number of characteristics of each population, i = 1∼N, j = 1∼n; the influence of the nutrient concentration of the culture medium in E on the population P i is reflected in the random influence on the characteristics of the population P i .
Suppose the optimization model of the required solution is Equation (1):
In the formula (1), R n is the n-dimensional Euclidean space, H is the search space; f(X) is the objective function; X is the n-dimensional solution vector, X = (x1,x2,...,x i ,...,x n ), and x i is the solution component. N initial solutions are selected arbitrarily in H, namely H = {X1,X2,...,X N }, where X i = (xi,1,xi,2,...,xi,n), i = 1∼N; culture system E corresponds to the search space H. The N initial solutions of the optimization model correspond to the N microbial populations in E, that is, X i corresponds to P i one to one; more precisely, the variables xi,j of X i correspond to the characteristics fi,j of P i one to one.
In summary, the initial solution and the microbial population are equivalent concepts and will not be distinguished later. After P i takes in nutrients, its growth state will change. This change is projected to H, it is equivalent to transferring the initial solution Xi from the spatial position a to b. A spatial location is called a state and is described by its subscript.
Assuming that the current state of P i is c, this is equivalent to the position X c in H. If P i evolves from state c to state d after taking in nutrients, this is equivalent to jumping from position X c to position X d in H. Calculate according to formula (1), if f(X c ) > f(X d ), indicating that position X c is better than position X d , then P i is considered strong. Conversely, if f(X c )≤f(X d ), indicating that the position X d is worse than the position X c , or there is no difference (because f(X c ) = f(X d )), then P i is considered weak. The strong population can continue to grow with a higher probability, while the weak population may not grow anymore.
The strength of P
i
can be expressed by the microbial growth index (MGI). A good quality solution corresponds to a population with a higher MGI index, that is, a strong population. A poor quality solution corresponds to a population with a lower MGI index, that is, a weak population. For formula (1), the MGI index of Pi is calculated according to formula (2):
In E, the biological intelligence characteristics of microbial cultivation are reflected in the following aspects: Various groups have mutual influence due to competition for culture solution. Such influence will be reflected in the random interaction between certain characteristics of the group. This is the “competitive intelligent characteristic”. When a population feeds on other populations, some characteristics of the eaten populations will be incorporated into some characteristics of the population, which is the “smart characteristic of eating”. The evolution of any population is obtained by continuously learning from other strong populations, which is the “intelligent feature of learning”.
The characteristics of biological intelligence cultivated by microorganisms are finally embodied in the form of biological evolution operators. The interaction between all microbial populations is projected to H in Equation (1), that is, there is an interaction between the solution vectors.
The MDO algorithm uses such strategies to solve the global optimal solution of Equation (1).
Suppose there are N species of microorganism populations in the culture system E, and each population feeds on the culture fluid and L other populations in E as food. In addition, toxic substances will poison all populations. At period t, the concentration of the population P
i
is y
i
(t), y
i
(t) ≥0, i = 1∼N; the culture fluid flows into E at a flow rate Q, where the concentration of nutrients is S0. This culture system has a time-lag effect on the mixed food chain microbial pulse culture dynamic model, as shown in formula (3) [14]:
In the formula (3), S(t) represents the nutrient concentration of the culture solution at period t; μ 0 represents the relative growth coefficient of the population; C0 represents the consumption rate of the culture solution by the population; MS(t) represents a collection of numbers of the K populations captured by the population P i at period t; K0, α0, γ0, W0 represent constants related to population growth; y i (t) represents the concentration of the population P i at period t; c(t) represents the concentration of harmful substances, c(t)≥0; q0 represents the quantity of harmful substances input in each culture medium feeding period; r represents the reduction rate of the population due to poisoning and death due to harmful substances, r > 0; T represents the feeding period of the culture fluid; τ represents the lag time of the transformation of the culture fluid to the microbial population; t+ is the time when the culture medium is put into use; k represents a positive integer, k≥1.
At period t, the proportion r
i
(t) of the population P
i
is calculated according to formula (4):
The larger the proportion r
i
(t) of the population P
i
, the greater the chance of being preyed by other populations. The values of the time t parameters C0, Q, K0, S0, α0, μ0, r, γ0, W0, and q0 are respectively Ct0, Qt, Kt0, St0, αt0, μt0, rt, γt0, Wt0, qt0. In order to facilitate the calculation, the formula (3) is changed to a discrete recursive form, with the following formula:
Refer to Table 1 for the meaning of each parameter and its value restriction conditions in formula (5) and formula (6).
Strategy of taking value for parameters of microbial dynamics model
In Table 1, Rand(A,B) means generating a random number that obeys a uniform distribution in the interval [A,B]. A and B are constants, and A≤B.
At period t, suppose the current population is P
i
, the generation strategy of the characteristic microbial population set is as follows: Generate the set MS(t) of the eaten population. At period t, the population P
i
feeds on another K populations, that is, K populations are randomly selected from N-1 populations with {r1 (t), r2 (t),...,r
N
(t)} as the probability distribution (But P
i
cannot be selected), these populations form a set MS(t), let us set MS (t) = {i1,i2, ... ,i
k
, ... ,i
K
}, where i
k
is the number of the population P
ik
, k = 1∼K. Generate aggregates FM
t
, GM
t
, and HM
t
of 30%, 20%, and 10% strong populations respectively. At period t, L populations are randomly selected from N populations. The MGI index of these populations is 30% higher than the current population P
i
, forming a set FM
t
= {Xs1 (t),Xs2 (t),...,X
sL
(t)}, where s1, s2,...,s
L
are the numbers of these selected populations. Then randomly select L populations from the remaining N-L populations. The MGI index of these populations is 20% higher than the current population P
i
, forming a set GM
T
= {Xg1 (t), Xg2 (t),...,X
gL
(t)}, Where g1, g2,...,g
L
are the numbers of these selected populations; finally L populations are randomly selected from the remaining N-2L populations, and the MGI index of these populations is 10% higher than the current population P
i
, forming a set HM
t
= {Xh1 (t),Xh2 (t),...,X
hL
(t)}, where h1,h2,...,h
L
are the numbers of these selected populations. Generate 15% AS
t
, BS
t
, CS
t
of strong population, weak population, and ordinary population respectively. At period t, L strong populations are randomly selected from N populations, and their MGI index is higher than 15% of the current population P
i
, forming a strong population set AS
t
= {Xa1 (t),Xa2 (t),...,X
aL
(t)}, where a1, a2, ... , a
L
are the numbers of these selected populations; then L weak populations are randomly selected from N populations, whose MGI index is lower than 15% of the current population P
i
, forming a weak population set BS
t
= {Xb1 (t), Xb2 (t),...,X
bL
(t)}, where b1, b2,..., b
L
are the numbers of these selected populations. Finally, L common populations are selected randomly from the remaining N-2L populations, their MGI index has nothing to do with the MGI index of the current population P
i
, forming a common population set CS
t
= {Xc1 (t),Xc2 (t),...,X
cL
(t)}, where c1,c2,..., c
L
is the number of these selected populations.
Design of microbial population evolution operator
The MDO algorithm uses the microbial cultivation dynamics model formula (3) to construct the evolution operator, so as to realize the information exchange between the cultivation system and the population and between the population and the population, and then realize the search of the search space H of the formula (1).
(1) Absorption operator. The absorption operator describes the nutrient supply relationship between the population P
i
and the other K populations. Pass a randomly selected feature fs,j,s∈MS(t) of the eaten population in the set MS(t) to the current population P
i
, so that the population P
i
can grow:
In formula (9), xs,j(t) represents the state value of the feature j of the population P s at period t, that is, the value of the variable xs,j at period t; vi,j(t + 1) represents the state value of the feature j of the population P i at period t + 1, that is, the value of the variable xi,j in the period t + 1; Take β s = Rand(-0.95,0.95), η i = Rand(0.45,0.65).
(2) Snap operator. The snap operator describes that a population grabs the dominant characteristics of other populations to make it stronger. Let the characteristics fsl,j, s
l
∈ {h1,h2, ... ,h
L
; g1,g2, ... ,g
L
; s1,s2, ... ,s
L
} correspond to the characteristics of the 3 L strong populations in FM
t
, GM
t
and HM
t
, fsl,j The value is passed to the characteristic fi,j of the population P
i
, making P
i
strong. Assuming that the current population is P
i
and the feature for dominance grabbing is fi,j, then there is formula (10):
In the formula (10), d1, d2, d3, e1, e2, e3, p1, p2, and p3 are randomly selected from the sets FM t , GM t , and HM t respectively, and they satisfy d1≠d2 ≠d3, e1≠e2≠e3, p1≠p2≠p3.
(3) Hybrid operator. The confounding operator describes the interaction between the population and the population. For the current population P
i
, the state value of which the features fsl,j, s
l
∈{a1,a2, ... ,a
L
; b1,b2, ... ,b
L
;c1,c2, ... ,c
L
} of the 3 L populations in AS
t
, BS
t
, CS
t
correspond to is passed to the characteristic fi,j of the population P
i
after being mixed and fused, then there is formula (11):
(4) Toxin operator. The toxin operator describes the toxic effects of toxic substances in the external system on microorganisms, and the toxic effects can be transmitted between microbial populations. For the current population P
i
, there is formula (12):
In formula (12), g1, g2, g3 are randomly selected from {1, 2, . . . , N}, and they satisfy g1≠g2≠g3.
(5) Growth operator. The definition of the growth operator is as formula (13):
In formula (13), X i (t) = (xi,1(t),xi,2(t),...,xi,n(t)); V i (t + 1) = (vi,1(t + 1), vi,2(t + 1),...,vi,n(t + 1)); Equation (2) is used to calculate MGI(V i (t + 1)) and MGI(X i (t)).
(S1) Initialization: ➀ Let t = 0, the number of evolutionary periods G = 8000∼60000, the error requirement ɛ = 10–5∼10–10, N = 50∼500, the highest probability of predation of the microbial population E0 = 1/1000∼1/100, K = 2∼10, T = 1∼10, τ=1∼10, L = 2∼10. ➁ Randomly determine {X1 (0), X2 (0),...,X N (0)}, {y1(0), y2(0),...,y N (0)},S (0).
(S2) Perform the following operations:
For t = 0 to G
Calculate C t 0, Q t , K t 0, S t 0, α t 0, μ t 0, r t , γ t 0, W t 0, q t 0 according to the strategy given in Table 1.
Calculate r1(t), r2(t),...,r N (t) according to formula (4).
If T is not divisible by t, calculate c(t + 1) and S(t + 1) according to formula (5);
If T can divide t, calculate c(t + 1) and S(t + 1) according to formula (7).
For i = 1 to N
With r1(t), r2(t),...,r N (t) as the probability distribution, K populations are randomly selected, but P i cannot be selected, forming a population number set MS(t).
If T is not divisible by t, calculate y i (t + 1) according to formula (6);
If T can divide t, calculate y i (t + 1) according to formula (8).
For j = 1 to n
p = Rand(0,1), p is the probability that the growth of the population will be affected by osmotic mixing, dominance grabbing and feature absorption;
If p < E0 then
q = Rand(0,1), where q is the probability that the absorption operator, the grab operator and the hybrid operator are executed;
If q≤1/4 then
Execute the absorption operator according to formula (9) to obtain vi,j(t + 1);
Else if 1/4 < q≤2/4 then
Execute the grab operator according to formula (10), and get vi,j(t + 1);
Else if 2/4 < q≤3/4 then
Execute the confounding operator according to formula (11) to obtain vi,j(t + 1);
Else if 3/4 < q≤1 then
Execute the toxin operator according to formula (12) to obtain vi,j(t + 1);
End if
Else
vi,j(t + 1) = xi,j(t);
End if
End for
Execute the growth operator according to formula (13) to obtain Xi(t + 1);
End for
If |X*t +1-Y*t +1| < ɛ then
Goto step (S3);
Else
Save the optimal solution X*t +1;
Y*t +1 = X*t +1;
End if
End for
(S3) End
Algorithm feature analysis
Time complexity analysis
The time complexity calculation process of the MDO algorithm is shown in Table 2.
Computation table of time complexity in MDO
Computation table of time complexity in MDO
Markov characteristics. From the definition Equations (9)–(12) of each operator of the MDO algorithm, the calculation of any new solution in the period t + 1 only involves the state of the solution in the period t, and the same as the solution is irrelevant to the process of how to evolve before the period t to the state at time t, indicating that the evolution process of the MDO algorithm has Markov characteristics. “Not bad at every step” feature. From the definition formula (13) of the growth operator, it is known that the MGI index of any population at period t + 1 will never be lower than its MGI index at period t, that is, the evolution process of the MDO algorithm has the characteristic of “step by step”.
According to the literature [22], the MDO algorithm that satisfies the above two characteristics has global convergence. The relevant proof can be found in the literature [19], which will not be repeated here.
Comparison of MDO algorithm with other algorithms
CEC2013 is an international general intelligent optimization algorithm test package [23], which includes 28 carefully designed benchmark function optimization problems. In this paper, 15 benchmark function optimization problems are selected to test the performance of the MDO algorithm, as shown in Table 3.
15 benchmark function optimization problems
15 benchmark function optimization problems
In Table 3, O is an n-dimensional vector whose value can be randomly generated. In this paper, the MDO algorithm is used to solve the 15 function optimization problems in Table 3. The parameters are N = 200, n = 50, G = 107, ɛ=10–7, E0 = 1/200, K = 3, T = 4, T = 3, L = 3. The seven intelligent optimization algorithms compared with the MDO algorithm are all selected from well-known algorithms published in recent international journals. These algorithms are shown in Table 4, namely RCGA (real-coded genetic algorithm) [24], DASA (differential ant-stigmergy) algorithm) [25], NP-PSO (non-parametric particle swarm optimization) [26], MpBBO (metropolis biogeography based optimization) [27], Copt-aiNet (artificial immune networks for combination optimization) [28], SLADE (symmetric Latin -based adaptive differential evolution) [29] and GRABC (grab artificial bee colony algorithm) [30]. The termination conditions of these seven algorithms are: evolutionary algebra G = 107 or optimal solution error ɛ = 10–7.
Parameters setting of compared intelligent optimization algorithms
For each benchmark function optimization problem, the above 8 algorithms are run independently 51 times to find the global optimal objective function. Tables 5 7 show the average deviation, median deviation, standard deviation, and fitness evaluation times of the optimal objective function value obtained by each algorithm. The performance ranking of 8 algorithms for solving each benchmark function is the ranking of these algorithms based on the average deviation of the optimal objective function value and the number of fitness evaluations; the final ranking is based on the ranking total points obtained by solving 15 benchmark functions based on 8 algorithms While ranking.
Optimal solutions of all algorithms when solving unimodal benchmark functions
Optimal solutions of all algorithms when solving multimodal benchmark functions
Optimal solutions of all algorithms when solving composite benchmark functions
Note: The color word indicates that the global theoretical optimal solution has been reached.
Non-parametric Friedman test [31, 32] is a non-parametric test based on the best results obtained by the MDO algorithm and the best results obtained by the seven compared algorithms to determine whether the results produced by the MDO algorithm are consistent with The results obtained by the seven compared algorithms are statistically different. The results of Friedman’s test are shown in Table 8, where Significance = 1 indicates that the performance of the MDO algorithm is 99% statistically different from the compared algorithm, and Significance = 0 indicates that the performance of the MDO algorithm is not significantly difference from the performance of the compared algorithm. In Table 8, the number of cases with Significance = 1 and the number of cases with Significance = 0 respectively represent the number of the MDO algorithm and the seven compared algorithms that are significantly different and almost the same to solve the benchmark function optimization problems.
Comparison of Friedman test results (α = 0.01)
From Tables 5 7, it can be seen that MDO, RCGA, DASA, NP-PSO, MpBBO, Copt-aiNet, SLADE and GRABC are sorted by the accuracy of the average optimal objective function value as follows:
MDO > SLADE > Copt-aiNet > NP-PSO > DASA> RCGA = GRABC > MpBBO
It can be seen from Table 8 that the total number of significant cases of the MDO algorithm for solving 15 benchmark function optimization problems is 88, which is significantly larger than the total number of insignificant cases, which indicates that the performance of the MDO algorithm is significantly better than the seven compared algorithms.
Figure 1(a)–(f) illustrate F3, F5, F14, F19, F26, F28 sample convergence curve while the MDO, RCGA, DASA, NP-PSO, MpBBO, Copt-aiNet, SLADE, GRABC algorithm are used to solve the 6 typical benchmark function optimization problems shown in Table 3, the horizontal and vertical axes in the figure adopt a logarithmic scale. From Tables 5 7, it can be seen that when the MDO algorithm solves these six optimization problems, it can find the global optimal solution with high accuracy. From a comprehensive point of view, the comprehensive performance of the MDO algorithm is better than the seven compared algorithms, indicating that its solution accuracy is high and the calculation speed is fast.

Convergence curves of all algorithms when solving 6 benchmark functions.
Measurement methods of penetration ability and expansion ability
In the solution process of the MDO algorithm, the penetration ability and the expansion ability are used to describe the ability to escape from the trap after falling into the local optimal solution trap and converge to the global optimal solution with a certain accuracy. Penetration ability is used to describe the ability of MDO algorithm to quickly escape from traps or quickly converge to the global optimal solution when solving optimization problems; while expansion ability is used to describe the ability of MDO algorithm to tentatively jump out of local optimization pitfalls, or tentatively improve the ability of optimal solution accuracy when solving optimization problems. The penetration and expansion capabilities of the MDO algorithm can be described by the behavior of microbial populations. When a population is searching, its state can be divided into penetrating state and expanding state. A population can only stay in one state at a time: either in a penetrating state or in an expanding state. In order to emphasize the behavior of the population entering the local optimal solution trap, the expansion state is divided into two states, one is called the expansion state and the other is called the sticky state.
When the population is searching, if the current position of the population remains unchanged for a long time, it is considered that the population has fallen into a sticky state. Two situations may lead to a sticky state: one is that the population falls into a local optimal solution trap; the other is that the current position of the population cannot be updated by information thrown by other species.
When all populations fall into a sticky state, the search will automatically stop, and the global optimal solution will always remain unchanged. On the other hand, if some optimization problems have high condition numbers, it is always difficult to improve the accuracy of the global optimal solution when the population is prone to fall into a sticky state.
When the MDO algorithm solves the optimization problem, if the penetration state is always dominant, it means that the search will either quickly escape from the trap or quickly approach the global optimal solution. Therefore, higher penetration capability is a good thing for the MDO algorithm; If the expansion state is always dominant, it means that the search is tentatively jumping out of the local optimal solution trap, or is tentatively improving the accuracy of the current optimal solution, but it may consume huge computing time, so the expansion ability of the algorithm should be controlled to a certain extent; if the sticky state is dominant, it means that the search is almost stopped, so the sticky state must be completely avoided.
The evaluation of penetration and expansion capabilities can be based on four convergence curves: (1) the convergence curve of any population, tracking the behavior of any population to search for the optimal solution; (2) the convergence curve of the best population, which tracks the best population search behavior of the optimal solution; (3) The average convergence curve of all populations, which tracks the average behavior of all populations when searching for the optimal solution; (4) The best convergence curve, which tracks all populations during the search process, and finds the current optimal Solution behavior.
The convergence curve of any population may cause huge computational burden and computer memory because there are many populations in the ecosystem; in addition, the behavior of the populations is too random to control them. The convergence curve of the best population is difficult to grasp, because the best population may change over time. The average convergence curve of all populations is similar to the convergence curve of any population, which may not only cause a huge computational burden and computer memory, but also increase the MGI value of the bad population and compress the MGI value of the good population. The best convergence curve can produce the smallest computational burden and computer memory between the four convergence curves, and the curve does not focus on any single population, but the best behavior produced by all populations.
The penetration and expansion capability evaluation of the MDO algorithm is based on the optimal convergence curve, which is a simple and intuitive method to judge the penetration and expansion capability of the MDO algorithm.
Figure 2 is the best convergence curve when the MDO algorithm solves a certain optimization problem. Point C is the starting position of the evolution, and the corresponding best objective function value is F0, and the CPU time t = 0; when the evolution reaches time t = t1, the current best position is at A, the corresponding best objective function value is F1; when the evolutionary arrival time t = t2, the current best position is at B, and the corresponding best objective function value is F2. The penetration and expansion ability of the population can be identified by the slope of the straight line AB, so the following formula:
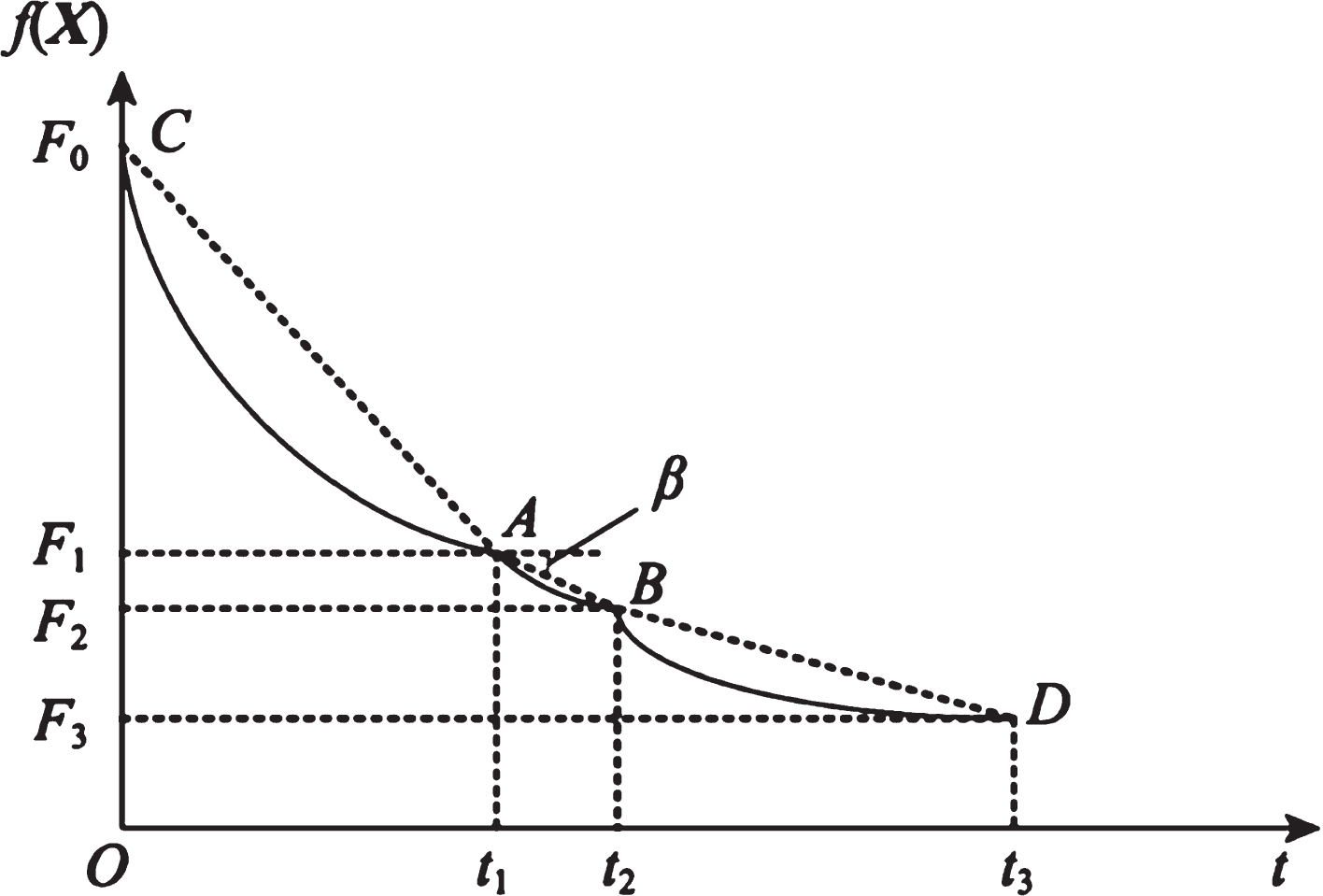
Evaluation of penetration and expansion capacity of MDO algorithm.
Obviously, if the straight line AB is steeper, the penetrating ability will be higher; if the straight line AB evolves from steep to gentle slope, the expansion ability will change from good to bad, especially when slope(t1) is close to 0, the expansion ability becomes worse, a sticky state appears. Therefore, two thresholds λ
Ps
and λ
Es
must be defined to illustrate these situations: λ
Ps
is used to distinguish between penetration state and expansion state, and λ
Es
is used to distinguish between expansion state and sticky state. If slope(t1) > λ
Ps
, it means that some populations stay in the penetrating state. If λ
Es
< slope(t1)≤λPs, it means that some populations are in a state of expansion. If slope(t1)≤λEs, it means that most populations have a tendency to enter a sticky state, and evolution may stop.
Now the penetration and expansion capabilities of the population are considered in the time interval [t
A
, t
B
]. Let CountPs(t
A
,t
B
) denote the number of positions in the interval [t
A
, t
B
], t
A
≤t≤t
B
that satisfies slope(t) > λ
Ps
; CountEs(t
A
,t
B
) denote the number of positions in the interval [t
A
, t
B
] that satisfies λ
Es
< slope
i
(t)≤λ
Ps
; CountSs(t
A
,t
B
) represents the number of positions that satisfy slope(t1)≤λ
Es
in the interval [t
A
, t
B
]. There are the following formulas:
Wherein, Count (.) is a function to calculate the position that meets the given conditions.
The measurement method of the coordination between penetration and expansion defined in the time interval [tA, tB] is as follows:
Wherein, CPs/Es(t
A
,t
B
) is called penetration-expansion coordination coefficient. If CPs/Es(t
A
,t
B
) > C
Ps
, it means that the search is in a penetration dominant state within the time interval [t
A
,t
B
]. If CPs/Es(t
A
,t
B
)≤C
Ps
, it means that the search is in a state of expansion dominance within the time interval [t
A
,t
B
].
Similarly, the measurement method of the degree of coordination between expansion and viscosity in the time interval [t
A
, t
B
] can be defined as follows:
Wherein, CEs/Ss(t
A
,t
B
) is called the expansion-viscosity coordination coefficient. If CEs/Ss(t
A
,t
B
) > C
Es
, it means that the search is in a expansion dominant state within the time interval [t
A
,t
B
]. If CEs/Ss(t
A
,t
B
)≤C
Es
, it means that the search is in a state of viscosity dominance within the time interval [t
A
,t
B
].
The Michalewicz function is chosen to illustrate the penetration and expansion capabilities of the MDO algorithm. The form of the Michalewicz function is as follows:
This function has the characteristics shown in Table 9. The Michalewicz function has n! local extremum points. When n = 80, there are 7.156 9×10118 local extremum points, so it is extremely difficult to obtain the optimal solution for this function.
Characteristics of benchmark function F3 and Michalewicz function
Characteristics of benchmark function F3 and Michalewicz function
Figure 3 shows the distribution of penetration, expansion and viscous state when MDO algorithm solves the Michalewicz function in the time interval [0,694]. The calculation parameters are n = 80, E0 = 0.005, K = 3, T = 4, τ= 3, L = 3, N = 200, G = 80000. It can be seen from Fig. 3 that when the MDO algorithm solves the Michalewicz function, CountPs(0,694) = 103, CountEs(0,694) = 297, CountSS(0,694) = 40, it takes 23.41% of the time to penetrate, 67.50% for expansion, there is only 9.09% probability of falling into a sticky state.
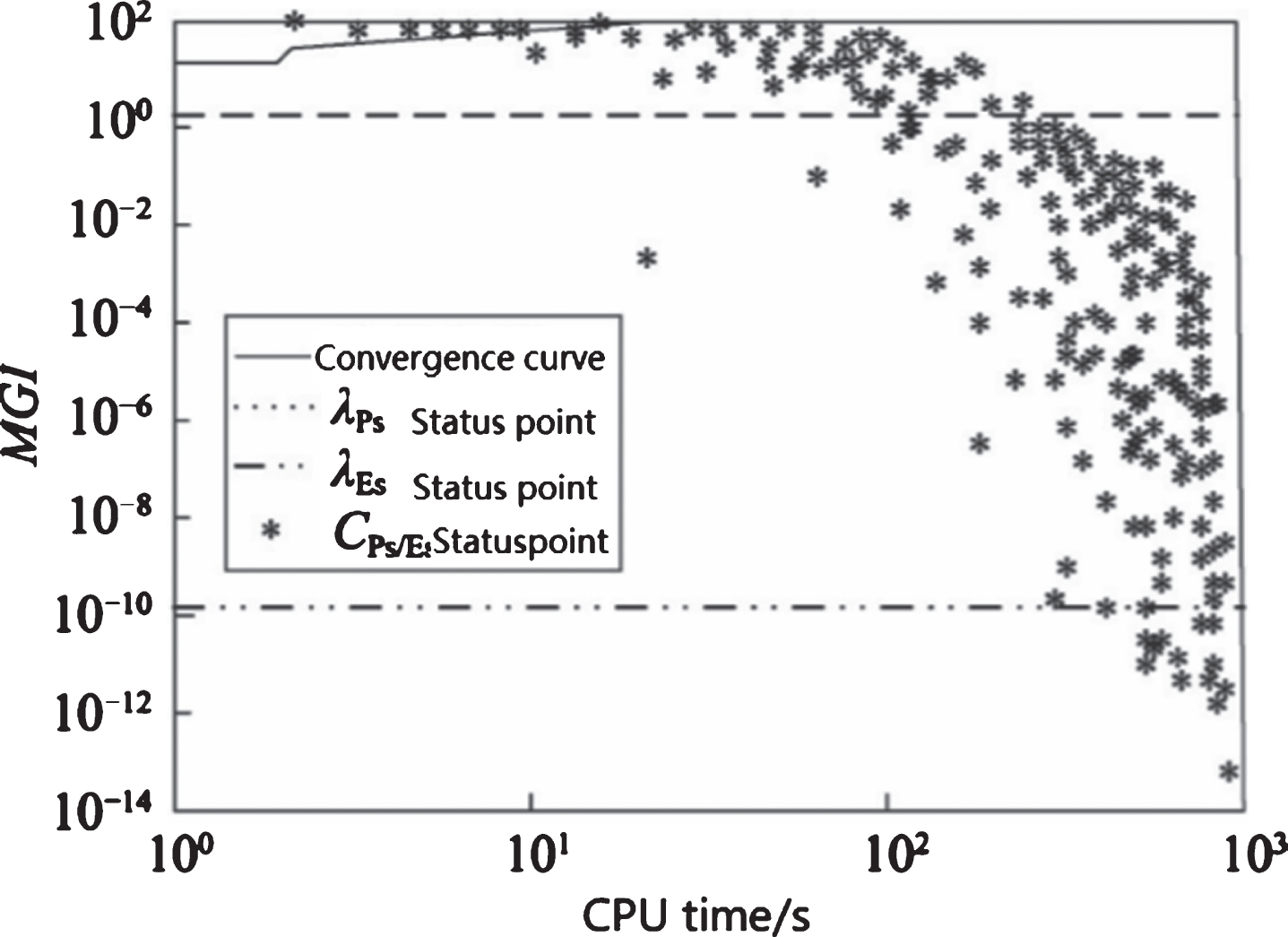
Distribution of penetration, expansion and viscosity(ɛ = 1.0E-11,λ Ps = 1.0,λ Es = 1.0E-10).
When the MDO algorithm solves the Michalewicz function, Fig. 4 shows the number of penetration, expansion, and viscous states in the time interval [0,694]. It can be seen from Fig. 4 that when the MDO algorithm solves the Michalewicz function, the penetration and expansion states alternate from 0 to 250 s, but the penetration state is always dominant from 0 to 250 s. Only the expansion state occurs between 250 s and 350 s; after 350 s, the expansion and the viscous state alternately appear, but the probability of the occurrence of the viscous state increases, and the expansion state always prevails after 350 s. This means that penetration and expansion are carried out sequentially from 0 to 250 s; between 250 s and 350 s, the search is close to the global optimum, and only expansion is required; when the search is carried out for 350 s, the sticky state occasionally starts to appear.
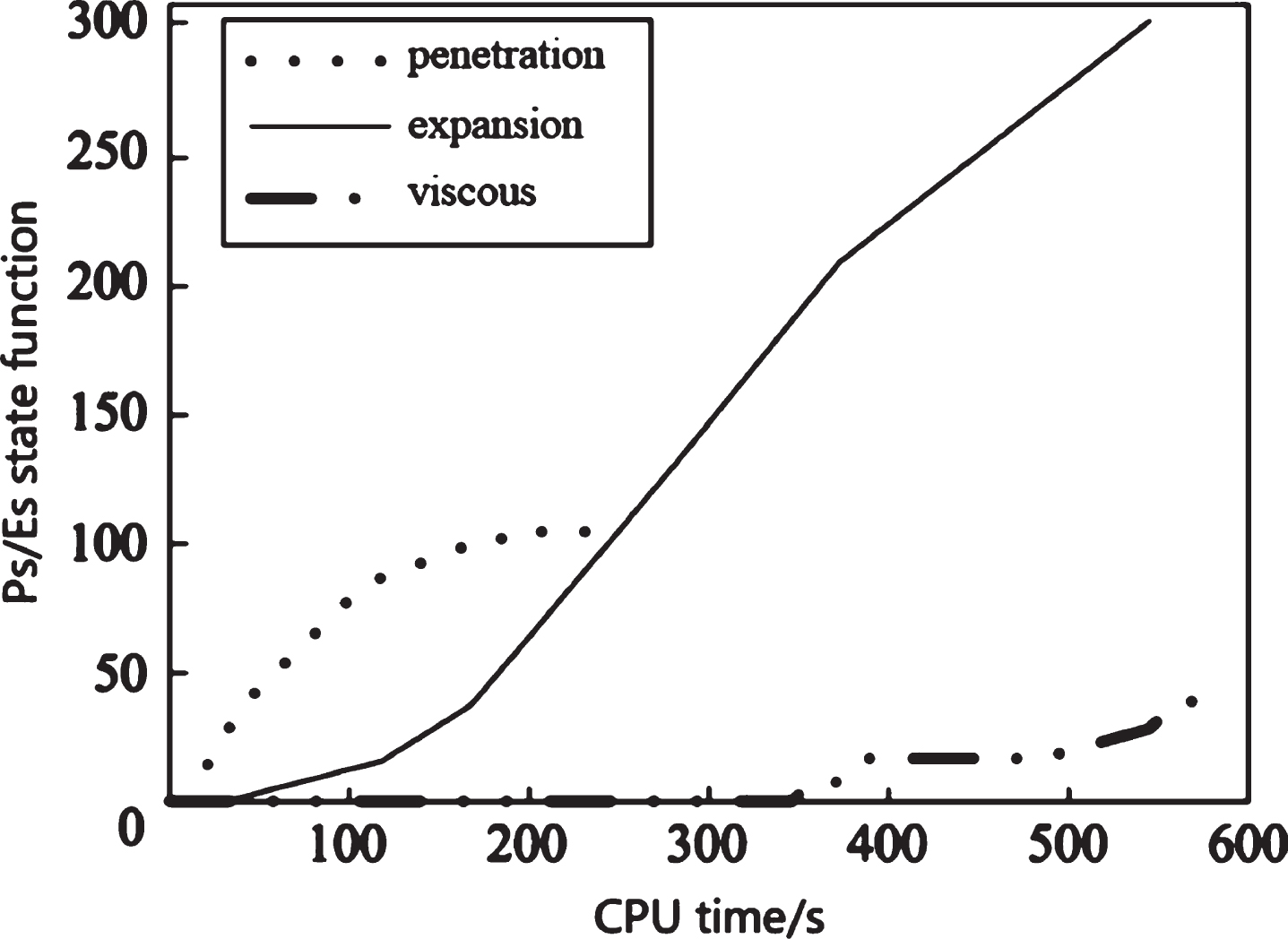
Number of times of penetration, expansion and viscous state λ Ps = 1.0,λ Es = 10-10).
When the MDO algorithm solves the Michalewicz function, Fig. 5 shows the coordination between penetration and expansion in the time interval [0,694]. It can be seen from Fig. 5 that when the MDO algorithm solves the Michalewicz function, the penetration state is dominant from 0 to 250 s; when t = 250 s, the penetration state is dominant and reaches the maximum value; after 250 s, the penetration state is dominant. The superiority begins to decrease; on the contrary, the probability of the inflated state begins to increase. This conclusion is consistent with the conclusion obtained from Fig. 4.
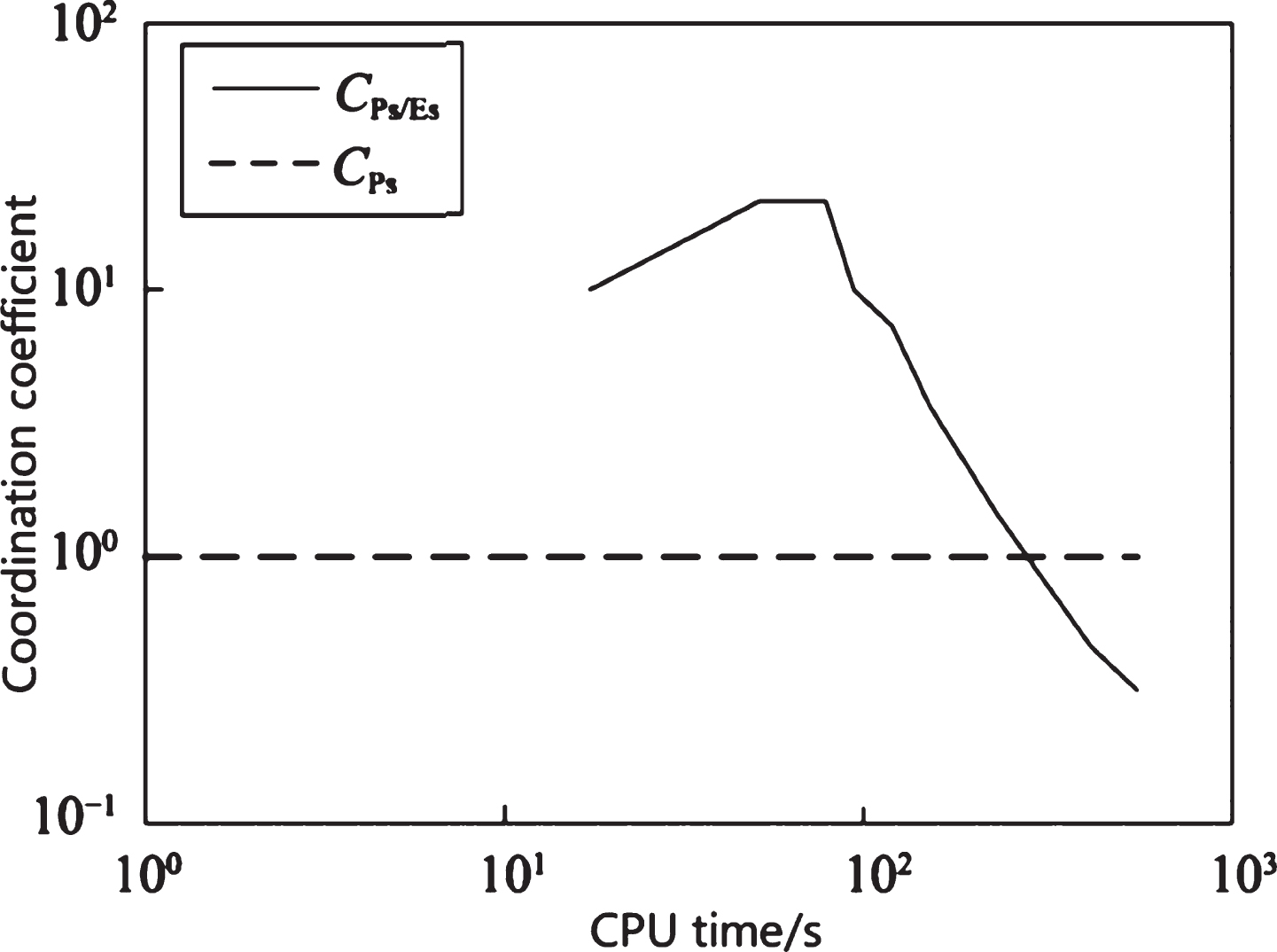
Variation of coordination coefficient of penetration and expansion with time (C Ps = 1.0).
When the MDO algorithm solves the Michalewicz function, Fig. 6 shows the coordination between expansion and stickiness in the time interval [0,694]. It can be seen from Fig. 6 that when the MDO algorithm solves the Michalewicz function, when t = 350 s, the expansion state dominance reaches the maximum value, and then the number of occurrences of the dominance state begins to decrease. On the contrary, the number of occurrences of the sticky state begins to increase, but the number of occurrences of the sticky state is always not dominant.
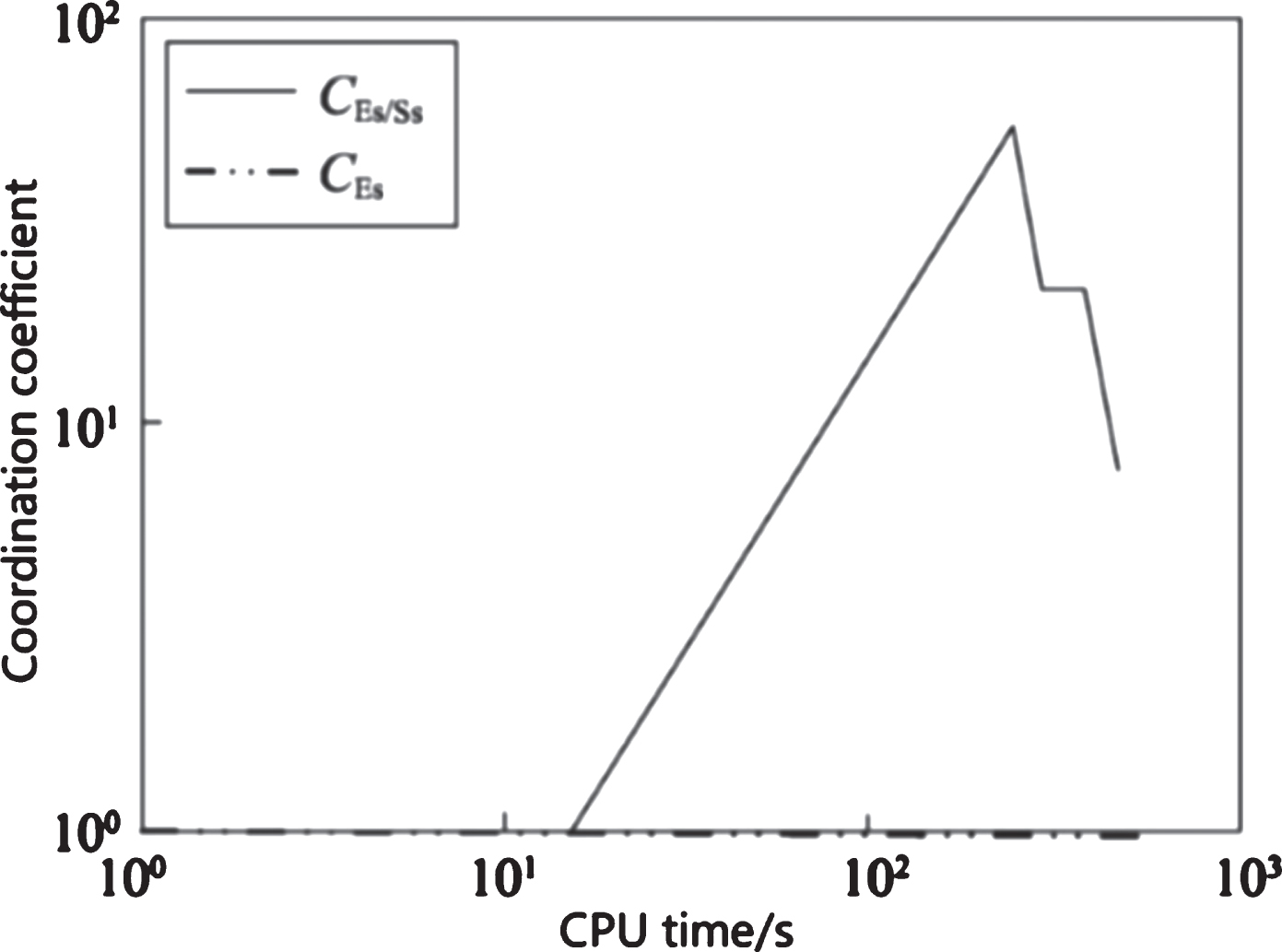
Variation of coordination coefficient of expansion and viscosity with time (C Es = 1.0).
From the above analysis, it can be seen that when solving optimization problems with a large number of local optimal solutions and optimization problems with high condition numbers, the MDO algorithm shows a good global optimization ability, and the balance between the local optimization ability and the global optimization ability is well control.
In this paper, a new optimization algorithm with global convergence is proposed based on the kinetic theory of microbial cultivation in the hybrid food chain with time delay. Compared with other typical swarm intelligence algorithms, the MDO algorithm has the following characteristics: Absorption operators, grabbing operators, hybrid operators and poison operators can increase its search ability. The random method is used to determine the relevant parameters in each operator, which not only greatly reduces the number of parameter inputs, but also enables the model to better express the actual situation. The microbial culture process involved in the algorithm fully reflects the concentration of various microbial populations, the amount of culture solution and its nutrient concentration, the concentration of toxic substances contained in the regular amount of culture solution, the period of culture solution, and the direction of culture solution. Complex changes in parameters such as the lag time of microbial transformation. All operators are constructed by using the kinetic theory of hybrid food chain microbial pulse culture with time lag and the interaction relationship between microbial populations, and it do not need to be related to the optimization problem to be solved. Therefore, the MDO algorithm has good universality. The impulse increase in the concentration of the culture medium and the toxic substances contained in it will cause the trial solution to suddenly shift from one state to another. This property helps to make the search jump out of the local optimal trap. The algorithm takes into account the discontinuous intervention of external factors in the process of microbial population cultivation. The interaction between the microbial populations involved in the algorithm is rich and colorful, reflecting the complex predation-being relationship and competition relationship among the microbial populations in the culture system. The algorithm reflects the complex changes of various parameters in the microbial culture dynamics model. When performing iterative calculations, the algorithm only processes 1/1 000∼1/100 of the number of features of each population each time, which greatly reduces the time complexity. Therefore, the MDO algorithm is suitable for solving high-dimensional optimization problems.
The next steps to improve the MDO algorithm are as follows: The microbial culture kinetic model is used to optimize the relevant parameters of the MDO algorithm to make these parameter settings more reasonable. In-depth study of the dynamic characteristics of absorption operators, grabbing operators, hybrid operators and toxin operators. In-depth study of the dynamic characteristics of microbial populations.
Footnotes
Acknowledgments
This work was supported by the Scientific Research Project (No: 20B335, No: 18C1122) of Hunan Provincial Education Department, China & Hunan Natural Science Foundation (Grant No: 2019JJ40154), Hunan Province, China (Grant No. 2019JJ40154).