
Abstract
Granular computing is a relatively new platform for constructing, describing and processing information or knowledge. For crisp information granulation, the universe is decomposed into granules by binary relations on the universe, say, preorder, tolerance and equivalence relations. A knowledge structure is composed of all information granules induced by a relation that corresponds to the granulation. This paper establishes a novel theoretical framework for the measurement of information granularity of knowledge structures. First, two new relations between knowledge structures are introduced through the use of their respective Boolean relation matrices, where the granular equality relation is defined based on an orthogonal transformation with the transformation matrix being a permutation matrix, and the granularly finer relation is presented by combining the classical finer relation and the orthogonal transformation. Then, it is demonstrated that the simplified knowledge structure base with the granularly finer relation is a partially ordered set, which can be represented by a Hasse diagram. Subsequently, an axiomatic definition of information granularity is proposed to satisfy the constraints regarding these two relations. Moreover, a general form of the information granularity is given, and some existing measures are proved to be its special cases. Finally, as an application of the proposed measure, the attribute significance measure is developed based on the information granularity.
Keywords
Introduction
Granular computing, the term first proposed by Zadeh in 1997 [1], has emerged as one of the information processing paradigms in the domain of computational intelligence and human-centric systems [2, 3]. According to Zadeh [1], granulation is one of three basic concepts that underlie human cognition besides organization and causation. More concretely, granulation involves decomposition of whole into parts, organization involves integration of parts into whole, and causation relates to association of causes with effects. Therefore, granular computing, a well-defined theory built on a solid foundation, provides an efficient tool for dealing with imprecision, uncertainty and partial truth. Nowadays, granular computing is usually loosely regarded as an umbrella term to cover theories, methodologies, techniques, and tools that make use of granules in complex problem solving [4–12].
The basic components of granular computing are granules, such as subsets, groups, classes and clusters of a universe. Each object is associated with a granule which is informally a clump of objects drawn together by indistinguishability, similarity, proximity or functionality [1, 13–15]. In granular computing, the objects within a granule have to be dealt with as a whole rather than individually. As pointed out by Lin [16, 17], information granulation is a collection of granules constructed by a given granulation strategy which is mainly based on binary relations. According to the absence or presence of fuzziness in the granules, information granulation can be generally categorized into two groups: crisp information granulation and fuzzy information granulation. In crisp information granulation, granules are crisp, i.e., they have sharply defined boundaries. Basic ideas of crisp information granulation have appeared in many related fields, such as interval analysis [18], rough set theory [19] and Dempster–Shafer theory [20]. While in almost all of human reasoning and concept formation, granules are fuzzy rather than crisp, which could be reflected in the theory of fuzzy information granulation [1, 21–27]. Fuzzy information granulation underlies the basic concepts of linguistic variable, fuzzy if-then rule and fuzzy graph and also underlies the remarkable human ability to make rational decisions in conditions of imprecision, partial knowledge, partial certainty and partial truth. Li et al. [22] investigated uncertainty measurement for fuzzy relation information systems by using fuzzy information structures. Song et al. [25] employed knowledge distances to construct algebraic lattices, which are useful in characterizing the hierarchies on fuzzy information granulations. Yang et al. [26] introduced a fuzzy knowledge distance measure to distinguish hierarchical rough approximation spaces of a fuzzy concept.
Lin [16, 17] suggested that a granular structure is a mathematical structure of the collection of granules, in which the inner structure of each granule is visible, and the interactions among granules are detected by the visible structures. Furthermore, a granular structure base is a family of all granular structures on the same universe. In granular computing, one often needs to measure the uncertainty of a granular structure for a given data set, which is called the information granularity. Actually, this term, which first appeared in 1979 [27], comes much earlier than the term granular computing. Granularity, together with granule and granulation, is a basic concept involved in human intelligence. In a broad sense, information granularity denotes an average granulation degree of information granules hierarchically. In Ref. [12], it is ascertained that (i) the level of granularity of information granules becomes crucial to the problem description, but (ii) there is no universal level of granularity of information. The essence of information granularity is revealed by its axiomatic definition constrained with a partial order relation among granular structures [23, 28]. This paper is an attempt to unify previous works on measuring the information granularity of knowledge structures.
Modes of crisp information granulation play important roles in a wide variety of methods, approaches and techniques. In these modes, granules are crisp, and thus in this paper, they are uniformly called (crisp) set-based granular computing. Generally, crisp information granules are captured by an arbitrary binary relation on the universe of discourse. To guarantee that each granule, usually the successor neighborhood [29–34], is nonempty, we always assume that the relation is at least reflexive. Although a serial relation can fulfil the condition, the reflexivity is commonly considered according to practical demands. Such a granular structure is called a binary neighborhood system [16, 35]. In this paper, our attention is paid to the issue of information granularity in a neighborhood system space. Up to date, this problem has already been faced in the literature. Several forms of the information granularity were proposed according to various views and targets, which were effectively applied in feature selection, rule extraction, decision tree construction, decision making, etc [36–42]. For example, Liang et al. [43, 44] proposed the knowledge granulation and rough entropy (also called the co-entropy [45, 46]) in both complete and incomplete data sets. Similar measures were also introduced in ordered data sets [47, 48]. In these three types of data sets, three kinds of granules are utilized in equivalence, tolerance and preorder granular structures, respectively. Moreover, Qian et al. [49, 50] presented the combination granulation with an intuitive knowledge content nature to measure the size of information granulation. In all these aforementioned forms of the information granularity, a certain measure of cardinality, which counts the number of elements in the information granule, establishes a sound descriptor of information granularity. And in this paper, we follow this convention in the present research.
Had noticed that the partial order relation between granular structures is of great significance in characterizing the monotonicity of information granularity, Qian et al. [28, 51] proposed an axiomatic definition of information granularity in a neighborhood system space. In their axiomatic definition, the granulation partial order relation, an extension of the traditional rough one, plays a critical role. There are two points we want to restate here about the granulation partial order relation: (i) arrangement of granules and (ii) cardinality of a granule. More specifically, for two granular structures, if the cardinalities of granules for one are all less than or equal to the cardinalities of a sequence of the other, then the former is granulation finer than the latter. In this way, many granular structures which are incomparable by the rough partial order relation might be compared. Thus their information granularity should be subject to the constraint that a finer knowledge structure implies a smaller information granularity. Along this line of research, Zhu [52] proposed an improved axiomatic definition of information granularity based on a kind of special partial order relation. The granularity of a partition was defined by Yao and Zhao [53] as the expected granularity of all blocks of the partition with respect to the probability distribution.
In this paper, we intend to generalize the original partial order relation in a more cautious manner. Two granular structures are perceived to be granularly equal only if one could be transformed to the other by an arrangement of elements. This linear transformation is, in essence, a special case of orthogonal transformation, where the transformation matrix is a permutation matrix. Furthermore, a granular structure is accepted to be granularly finer than another one if there exists a granular structure granularly equal to the former such that it is finer than the latter in the classical sense. We also show that the simplified knowledge structure base with the granularly finer relation is a partially ordered set (poset for short) but not always a lattice. Based on these two relations, a revised axiomatic definition of information granularity is introduced. A general form of the information granularity is proposed, and some commonly used terms are proved to be special instances of the proposed measure. The application to attribute significance measure is presented to measure the significance of attributes by using information granularity. In summary, the main contributions of this paper are as follows: We put forward the granular equality relation and granularly finer relation originated from arrangements of objects, which is a novel research perspective in granular computing. We develop a general form of information granularity constructed by a monotonic function, starting from its axiomatic definition. We provide a practical application of information granularity to measure the attribute significance and identify the most important attribute.
An outline of this paper is as follows. Section 2 reviews some basic concepts relating to binary relations and characterizations of their matrix representations. In Section 3, through a nondegenerate linear transformation, the granular equality relation and granularly finer relation between knowledge structures are defined. It is proved that the granularly finer relation is a partial order relation on the simplified knowledge structure base whose Hasse diagram is visualized. Section 4 introduces an axiomatic definition of the information granularity of knowledge structures, whose general form is presented. In Section 5, an application of information granularity in measuring the significance of attributes is presented. Section 6 concludes this paper and indicates further research directions.
Binary relation and its matrix representation
In this section, we introduce the matrix of a relation and its usage in characterizing some specific relations.
Let U be a finite and nonempty set called the universe of discourse, and R ⊆ U × U be a binary relation on U. For x, y ∈ U, we shall say that x and y are R-related whenever the ordered pair (x, y) ∈ R, which is often written in the equivalent form x R y. If (x, y) ∈ R holds, then x is a predecessor of y, and y is a successor of x. Denote R
s
(x), the successor neighborhood of x with respect to R [54, 55], consisting of all and only successors of x, i.e.,
There are several important properties that a relation on a set may or may not have. Suppose that R is a relation on U. Then it is said to be [56, 57] reflexive iff (x, x) ∈ R for all x ∈ U; symmetric iff (x, y) ∈ R implies (y, x) ∈ R for all x, y ∈ U; transitive iff (x, y) ∈ R and (y, z) ∈ R together imply (x, z) ∈ R for all x, y, z ∈ U.
Given two relations Q and R on U, the composition of them, denoted by Q ∘ R, is given by
In reality, since any object is trivially indiscernible with itself, it is, a fortiori, similar to itself [58, 59]. The reflexivity seems quite necessary to express other types of relations. Furthermore, combined with the other two properties, R is called [57] a preorder relation if R is reflexive and transitive; a tolerance relation if R is reflexive and symmetric; an equivalence relation if R is reflexive, symmetric and transitive.
Another commonly used relation is the so-called partial order relation which is reflexive, antisymmetric and transitive.
The identity relation I = {(x, x) : x ∈ U} and the universal relation E = {(x, y) : x, y ∈ U} are two special cases of equivalence relations. Note that the identity relation relates every element to itself and only itself while the universal relation relates every element to all items in U. Clearly, for any reflexive relation R, we always have: I ⊆ R ⊆ E, x ∈ R
s
(x) for all x ∈ U, and {R
s
(x) : x ∈ U} constitutes a covering of U. That is, R
s
(x) ≠ ∅ , ∀ x ∈ U and ⋃x∈UR
s
(x) = U.
If R is a reflexive (preorder, tolerance) or an equivalence relation, then (U, R) is called a reflexive (preorder, tolerance) or an equivalence granular structure. Furthermore, if all relations in
The relation R can also be conveniently represented by a Boolean matrix M
R
with each of its entry r
ij
being set to 1 if (x
i
, x
j
) ∈ R and to 0 otherwise [60]. Matrix M
R
is called the matrix of the relation R relative to the same ordering for its rows and columns. If the cardinality of U, denoted by |U|, is n, then M
R
is a square matrix of order n. For Q, R ∈
Using these terminologies and notations, we can equivalently express the properties of R in terms of that of M
R
. For example, R is reflexive iff M
I
≤ M
R
; symmetric iff transitive iff M
R
•
M
R
≤ M
R
.
It is worth mentioning that the operator • is developed to compute the composition of two relations (in the sense of this paper), which works based on Boolean operators. However, the usual manipulation of numbers or matrices is performed based on ordinary (not Boolean) arithmetic. Therefore, for computational convenience, a novel characterization of the transitivity of a relation using the common multiplication · of matrices is revealed by the lemma below.
The proof breaks down into two cases. If r
ij
= 1, it is trivial to show that If r
ij
= 0, then by the transitivity of R, there is no k ∈ {1, 2, …, n} such that r
ik
× r
kj
= 1 (or else it would contradict the transitivity of R). Hence, we have If r
ik
= r
kj
= 1, then
Summarizing both cases, we obtain M
R
· M
R
≤ nM
R
.
In this section, after introducing the concept of knowledge structures, we define two novel kinds of relations between them, the granular equality and granularly finer relations, which are fundamental concepts in this paper.
In the following discussion, we always suppose that R is at least reflexive.
Granular equality relation between knowledge structures
From a general relation R on U, we can derive a knowledge structure K (R) = (R
s
(x1) , R
s
(x2) , …, R
s
(x
n
)) with each of its component being an information granule. Thus, there is a one-to-one correspondence between the knowledge structure K (R) on U and the granular structure (U, R). Similarly, corresponding to (U,
Before presenting the notion of the granular equality relation, let us return to the matrix of a relation. In determining M
R
, we only require that the rows and columns are arranged in the same ordering. For example, given K (R) = ({x1} , {x1, x2} , {x1, x3}), a preorder knowledge structure on U = {x1, x2, x3}, we have, relative to the ordering x1, x2, x3,
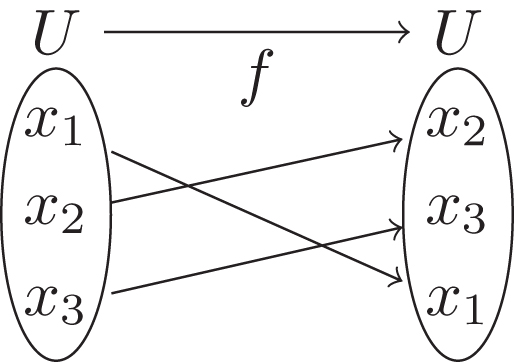
Then, we can confirm that
The foregoing discussion provides us with the transformation method among knowledge structures. We say two knowledge structures are granularly equal if one could be changed to the other through such a transformation. More formally, we have the following definition.
If K (Q) ≅ K (R), then the multisets [61] {|Q s (x) | : x ∈ U} and {|R s (x) | : x ∈ U} are equal (notice that here we do not mean that |Q s (x) | = |R s (x) |, ∀ x ∈ U). However, the inverse does not hold in general, as illustrated by a counterexample in Remark 3.1.
In the aforementioned example,
By Theorem 3.1, the quotient set K (
Assume that R is reflexive, then we have M
R
≥ M
I
. Furthermore, M
Q
= P
T · M
R
· P ≥ P
T · P = M
I
, i.e., Q is reflexive. Assume that R is symmetric, then we have Assume that R is transitive, then by Lemma 2.1, we have M
R
· M
R
≤ nM
R
. Thus,
If two knowledge structures are granularly equal, then by Theorem 3.2 and Corollary 3.1, they are of the same type. In other words, through the orthogonal transformation proposed in this paper, the new generated knowledge structure maintains the property of the original one. Furthermore, in granular computing, we do not distinguish these two knowledge structures here because they are of the same type and their information granularity (shall be introduced in Section 4) are identical. In this sense,
Granularly finer relation between knowledge structures
First, let us recall the definition of the classic finer relation between knowledge structures.
From Definition 3.3, we can get the following easily. If K (Q) ⪯ K (R), then K (Q) ≾ K (R). Namely, the relation ⪯ is a subset of the relation ≾. If K (Q) ≾ K (R), then there exists a knowledge structure K (S) such that K (Q) ⪯ K (S), where K (S) is granularly equal to K (R). If K (Q) ≅ K (R), K (R) ≾ K (S), and K (S) ≅ K (T), then K (Q) ≾ K (T).
Items (1) and (2) indicate the relations between ⪯ and ≾, and Item (3) suggests that relation ≾ is compatible with ≅.
Since M
I
∈ If K (Q) ≾ K (R) and K (R) ≾ K (Q), then there exist P1, P2 ∈ If K (Q) ≾ K (R) and K (R) ≾ K (S), then there exist P1, P2 ∈
Thus the relation ≾ is a partial order relation on
In light of Theorem 3.3, the pair (
Hasse diagram of simplified knowledge structure base
As stated in Section 3.2, (
In (
Every knowledge structure in
If U = {x1, x2}, there are four reflexive knowledge structures on U, which are K (Q) = ({x1} , {x2}), K (R) = ({x1, x2} , {x2}), K (S) = ({x1} , {x1, x2}) and K (T) = ({x1, x2} , {x1, x2}). The relations between them are presented in Fig. 1(a), meaning that K (Q) ≾ K (R) ≾ K (T), K (Q) ≾ K (S) ≾ K (T) and K (R) ≅ K (S). For briefness, we denote the label of each node, for example, ({x1, x2} , {x2}) by (12, 2). The same abbreviations are employed in the discussion below.

Hasse diagrams of simplified knowledge structure bases of all types on U = {x1, x2}.
Because K (R) ≅ K (S), according to the above analysis, we can choose one representative into the simplified knowledge structure base. The Hasse diagram of the simplified reflexive or preorder knowledge structure base on U is shown in Fig. 1(b). While the Hasse diagram of the simplified tolerance or equivalence knowledge structure base on U is given in Fig. 1(c).
As can be seen from Fig. 1(b) and (c), both of them are chains, and therefore they are lattices, obviously. Then, a natural question arises: can all the simplified knowledge structure bases with the granularly finer relation form a lattice? A negative answer to this question is given by the following examples.
The ordered structures of simplified reflexive, preorder, tolerance and equivalence knowledge structure base (
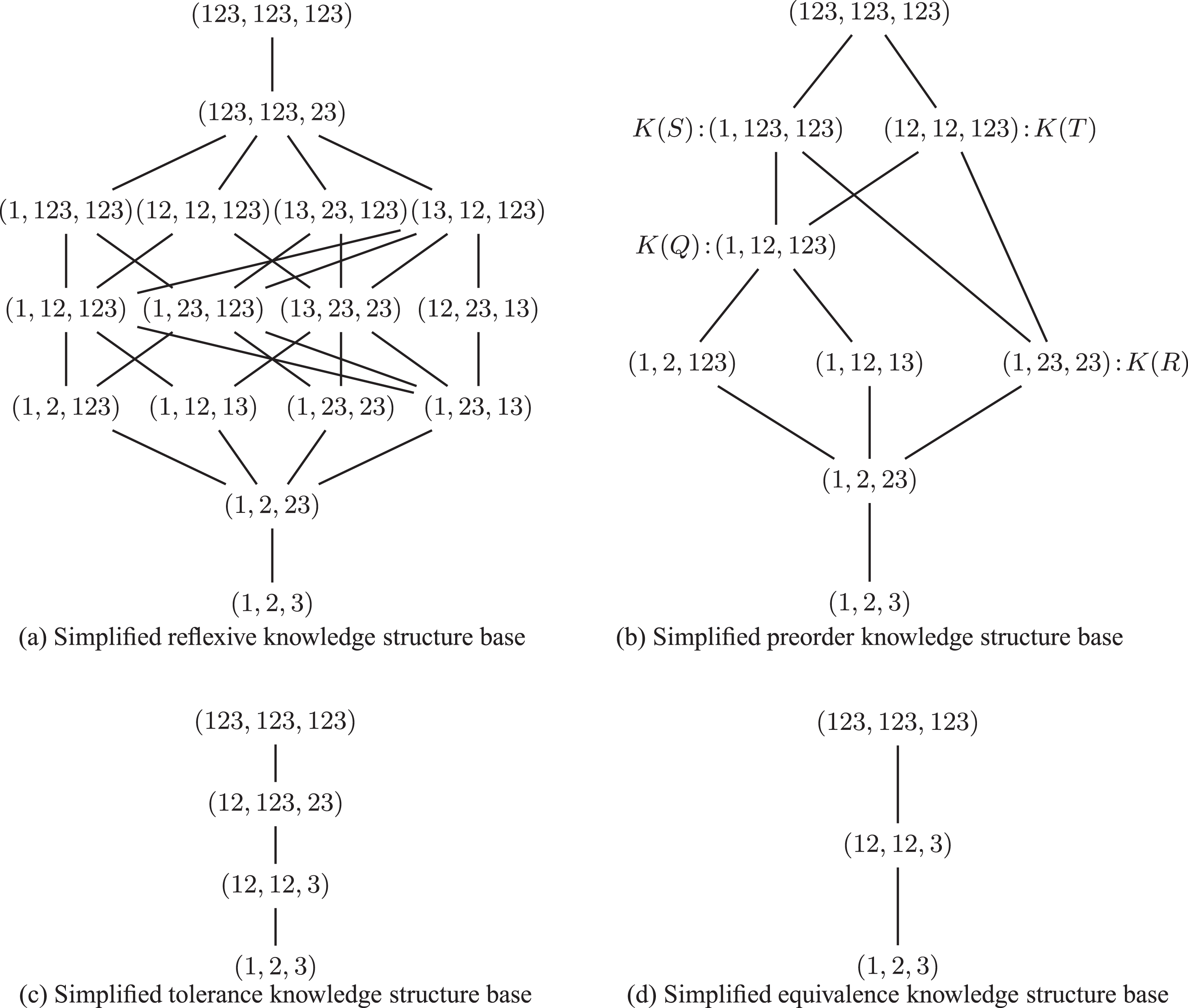
Hasse diagrams of simplified knowledge structure bases of all types on U = {x1, x2, x3}.
Clearly, the ordered sets in Fig. 2(c) and (d) are chains of lengths 3 and 2, respectively, and therefore they are lattices. Now let us turn our attention to the other two posets. Denote by K (Q), K (R), K (S) and K (T) the knowledge structures that are marked in Fig. 2(b). Thus, we can get that the infimum of K (S) and K (T) does not exist, nor does the supremum of K (Q) and K (R). Therefore, the simplified preorder knowledge structure base is not a meet semilattice, neither a join semilattice, let alone a lattice. Likewise, the ordered structure given in Fig. 2(a) is not a lattice either.
The Hasse diagram of the simplified equivalence knowledge structure base on U is depicted in Fig. 3. It can be easily verified that (
In fact, there are 52 equivalence knowledge structures on U originally. After simplification, only 7 kinds of equivalence knowledge structures are left (the numbers of the granularly equal knowledge structures are listed in the right column of Fig. 3). That is, we only need to investigate these 7 knowledge structures, which significantly decreases the complexity. Operators ∪, ∩ , - and ≀ were introduced in-between knowledge structures, which can effectively achieve composition, decomposition and transformation of knowledge structures [28, 51]. It is proved that (K (

Hasse diagram of the simplified equivalence knowledge structure base on U = {x1, x2, x3, x4, x5}.
In this section, an axiomatic definition of the information granularity of knowledge structures is proposed based on the concepts of granular equality relation and granularly finer relation.
(Nonnegativity) G (R) ≥0; (Invariability) ∀K (Q) ∈ K ( (Monotonicity) ∀K (Q) ∈ K ( (Strict monotonicity) ∀K (Q) ∈ K (
Moreover, G (R) is called a strict information granularity of K (R) if it satisfies (1), (2) and (3’):
The first property indicates that the information granularity G (R) requires nonnegativity for an arbitrary knowledge structure K (R) ∈ K (
In a broad sense, the information granularity of K (R) indicates an average measure of information granules induced by R. Define a mapping
Note that G (R) is bounded with G (I) ≤ G (R) ≤ G (E). If G is a nonnegative constant function, it meets all three conditions but is meaningless in practice. Thus, we can always set G (I) < G (E). The following transform can be applied if one additionally requires that G′ (I) =0 and G′ (E) =1,
Several different kinds of measures of knowledge structures have been given in the existing literature. In the following, we show that they are special forms of the information granularity in the sense of Definition 4.1.
Let (U, R) be a granular structure. The granulation of knowledge of K (R) is defined as [43, 44]
For all K (Q) ∈ K ( For all K (Q) ∈ K ( For all K (Q) ∈ K (
Summing up the above results, we obtain GK (R) is an (strict) information granularity of K (R).□
Inspired by this formula, we can define a general form of an information granularity based on the set-size character of information granules.

Information granularity of knowledge structures in
For simplicity, we take
Information granularity of knowledge structures in
From Table 1, one can observe that the granularly finer knowledge structure has a smaller information granularity, but not the other way around. For example, K (Q) ≾ K (R) does not hold, but IG (Q) ≤ IG (R) is true in all these cases. In fact, if the poset (
The result is extended to a boarder class as follows.
Below let F (0, 0, …, 0) ≥0; F is symmetric, i.e., F (t1, t2, …, t
n
) = F (tp(1), tp(2), …, tp(n)) for every (t1, t2, …, t
n
) and every permutation (p (1) , p (2) , …, p (n)) of (1, 2, …, n); F is monotone nondecreasing in all its arguments, i.e., F (s1, s2, …, s
n
) ≤ F (t1, t2, …, t
n
) if s
i
≤ t
i
for all 1 ≤ i ≤ n.
By the monotonicity of F and nonnegativity of f, we have
For all K (Q) ∈ K ( For all K (Q) ∈ K (
Furthermore, if F is strictly monotone nondecreasing, then IG′ (R) is a strict information granularity of K (R).
Specially, if
Moreover, if we choose suitable F and f, we can confirm that
The attribute significance measure is usually used to measure the importance of attributes and used in many applications. In this section, we carry out a method of measuring the attribute significance based on the information granularity.
For algorithmic reasons, the information regarding the objects is supplied in the form of an information system, whose separate rows refer to distinct objects, and whose columns refer to different attributes considered, and entries of the information system are attribute-values, called descriptors.
A decision system [19] is a two-tuple (U, C ∪ D), where U is a finite and nonempty set of objects, C and D are condition attributes and decision attributes, respectively. Let a (x) denote the value of sample x at attribute a. According to the descriptors, we can induce binary relations on U. For example, if all descriptors are numerical, then, ∀A ⊆ C ∪ D,
The joint information granularity of K (R
A
) and K (R
B
) is
Moreover, the conditional information granularity of A relative to B is
If B =∅, then IG (B | A) =0. If K (R
B
) ⪯ K (R
A
), then IG (B | A) = IG (A) - IG (B) and IG (A | B) =0.
For a decision system (U, C ∪ D), we usually consider the conditional information granularity IG (D | A), where A ⊆ C. For the three commonly used forms of information granularity, we have
Based on the notations introduced above, we give the significance of a with respect to B (a ∉ B) relative to D:
A simple example about Play Golf? on Saturday mornings [66] is elaborated below to substantiate the conceptual arguments. The dataset is shown in Table 2, each instance being characterized by four different aspects of weather conditions: outlook (o), temperature (t), humidity (h) and windy (w).
Play Golf? in response to weather conditions
First, we can compute the equivalence classes generated by U/R
o
:
Secondly, the equivalence classes generated by U/R{o,d} are
Then, the conditional rough entropy of o relative to d is
Subsequently, by E
r
(d | ∅) = log 14 - E
r
(d) =0.9403 bits, we can calculate the significance of o relative to d:
We can thus conclude that “outlook” is the most important among these four weather conditions, which is in accordance with the result of ID3 algorithm.
Analogously, one can obtain the attribute significance measures by employing the granulation of knowledge and the combination granulation. The detailed results are displayed in Fig. 5.
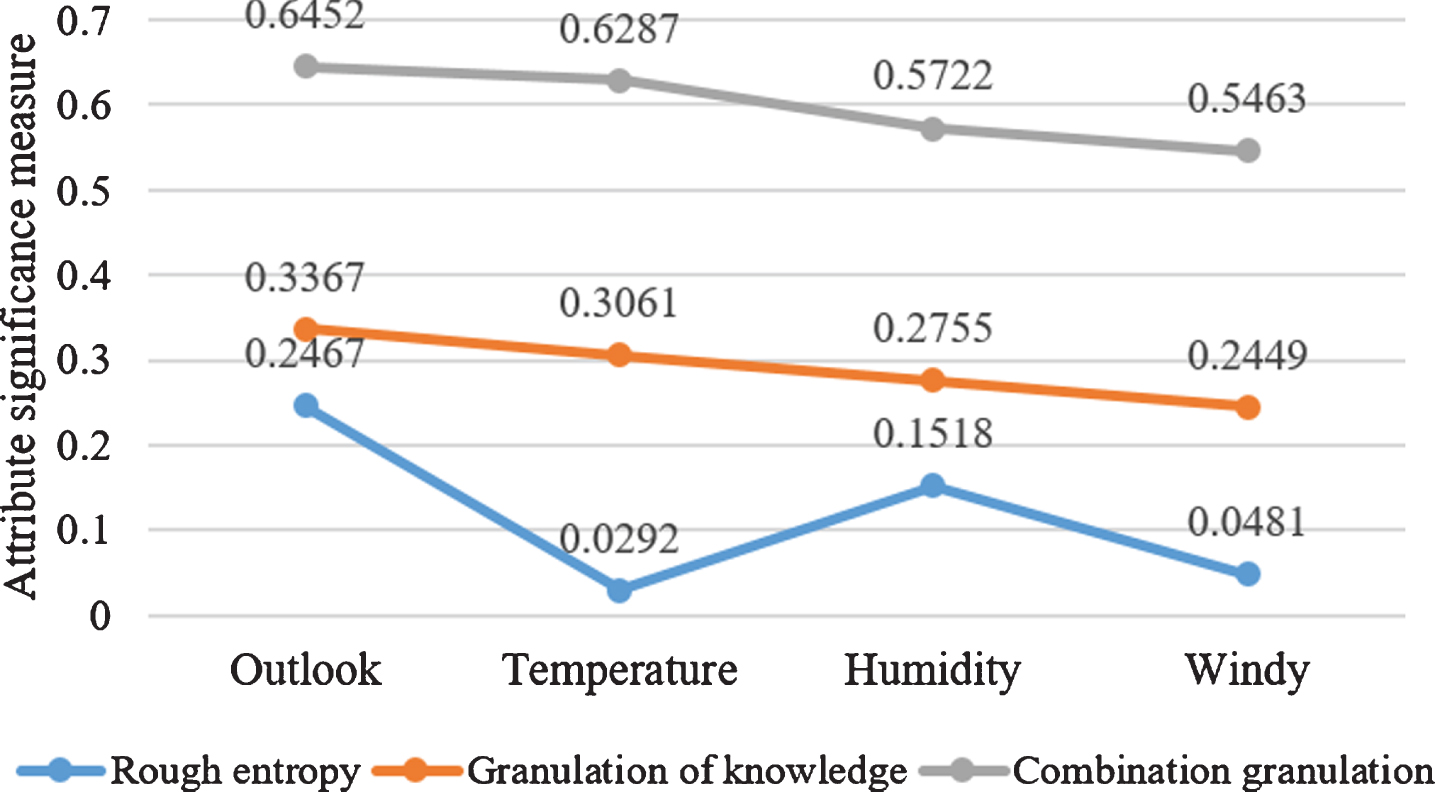
Attribute significance measures acquired by different information granularity.
From Fig. 5, we can see that the most important weather condition for playing golf outside is always “outlook”, although the attribute significance measures are different based on distinct forms of information granularity.
In real-life situations, crisp information granulation is an important format of information granulation, and set-based granular computing plays a fundamental role in human reasoning and problem solving. In this setting, the universe is clustered into granules by binary relations. To examine the average granulation degree of information granules, we introduce the granular equality relation and granularly finer relation in this paper. The former is defined through an orthogonal transformation with the transformation matrix being a permutation matrix, while the latter is defined based on the traditional finer relation and the orthogonal transformation. Moreover, the former is proved to be an equivalence relation on the knowledge structure base, while the latter is a partial order relation on the simplified knowledge structure base. By the simplified knowledge structure base, we mean a simplification of the whole knowledge structure base by choosing one representative element from every equivalence class of the knowledge structure base with respect to the granular equality relation. We emphasize again that although the granularly finer relation is a subset of the finer relations presented in Refs. [28, 52], it does not mean that our approach is inferior nor superior to the others. In fact, the granularly finer relation overcomes the restriction of the classical finer relation and the looseness of the other existing finer relations. Thus, it is, from a conservative viewpoint, the most suitable relation between knowledge structures. Moreover, the (strict) information granularity of a knowledge structure is defined by a mapping that satisfies nonnegativity, invariability and (strict) monotonicity. A general form of the information granularity is given based on the set-size nature of information granules, and several existing concepts are shown to be its special cases. Finally, the attribute significance measure is proposed by using the information granularity which can serve as an alternative measure to feature selection.
Note that this paper is built upon the assumption that all objects in the universe are equipped with the same weight. However, due to the frequency of occurrences or preferences of decision makers, different weights are assigned to the objects sometimes. If so, only the objects with the same weight can be permutated, otherwise, there is no need to emphasize the weights of objects. To solve this problem, we can pretreat the set of permutation matrices by deleting some elements corresponding to arrangements of objects with different weights. For example, for U = {x1, x2, x3}, if x1 and x2 are assigned with the same weight which differs from that of x3, then x1 and x2 can be permutated if needed and we can take
Footnotes
Acknowledgments
The author is grateful to the anonymous referees for their excellent comments on the initial manuscript. This research was supported by the National Natural Science Foundation of China (Grant no. 61806182), the Scientific Research Fund for Young Teachers of Zhengzhou University (Grant no. 32220326), the Research Base Program of New Disciplines in Economics and Management of Zhengzhou University (Grant no. 101/32610168) and the Training Project for Young Backbone Teachers of Colleges and Universities of Henan Province.