
Abstract
An information system (IS) is an important mathematical tool for artificial intelligence. A fuzzy probabilistic information system (FPIS), the combination of some fuzzy relations in the same universe which satisfies the probability distribution, can be seen as an IS with fuzzy relations. A FPIS overcomes the shortcoming that rough set theory assumes elements in the universe with equal probability and leads to lose some useful information. This paper integrates the probability distribution into the fuzzy relations in a FPIS and studies its reduction. Firstly, the concept of a FPIS is introduced and its reduction is proposed. Then, the fuzzy relations in a FPIS are divided into three categories (P-necessary, P-relatively necessary and P-unnecessary fuzzy relations) according to their importance. Next, entropy measurement for a FPIS is investigated. Moreover, some reduction algorithms are constructed. Finally, an example is given to verify the effectiveness of these proposed algorithms.
Introduction
Research background and related works
Rough set theory is an extremely important mathematical tool for dealing with uncertain knowledge, which was first proposed by Pawlak in 1982 [23]. Until now, it has been applied to various fields, such as machine learning, process learning and knowledge discovery. An approximation space is from a given universe and equivalence relations on this universe, which can be regarded as the basis of rough set theory and revealed the knowledge hidden in an IS.
Relation holds an important site in an approximation space, which represents the correlation between elements in a given set. Relation can be widely implemented in the fields of feature selection [15, 32], uncertainty modeling [3, 29], and granular computing [8, 22]. However, in practical applications, there are often real value data and fuzzy information. Fuzziness is not taken into consideration in rough set theory. So relation in rough set theory has some limitations in various applications.
Zadeh’s fuzzy set theory [45] was thought of as another powerful mathematical implementation. A great many researchers have paid great attention to this theory, one that has been widely used in the area of fuzzy decision making [42], fuzzy reasoning [5] and fuzzy systems [46].
A fuzzy relation can be viewed as a generalization of a crisp relation, whose value range is a subset of [0, 1]. It had better performance than crisp relations when ones deal with fuzzy situations. Some researchers have paid great attention to this. For example, Yager [41] introduced the concept of information entropy into fuzzy similarity relations; Tamura et al. [31] analyzed pattern classification from the perspective of fuzzy relations; Hu et al. [13] proposed an measurement method for fuzzy relations and crisp relations.
An IS has been proposed by Pawlak [23], which contains some objects and their attributes as a knowledge representation. An IS can be applied to reasoning with uncertainty [11, 40], rule extraction [2, 33], classification [12, 24] and so on.
In order to further study the uncertainty of an IS, many scholars have studied an IS from different research perspectives. For instance, Wang et al. [35] provided the concept of a fuzzy IS. Cai et al. [4] researched a fuzzy related IS. A fuzzy IS, as an IS under the fuzzy environment, is widely used in many fields, such as fuzzy comprehensive evaluations [38] and fuzzy decision making [6, 28].
Information entropy, proposed by Shannon [26], is an effective tool to measure the uncertainty of an IS. For example, Beaubouef [1] studied a new information theory measurement method for the uncertainty of rough sets and rough relational databases; Slezak [27] used information entropy to calculate the uncertainty of equivalence relations; Dai et al. Yu et al. [43] obtained some information entropy measures suitable for fuzzy relations; Li et al. [18] proposed some methods for measuring a fuzzy relations IS.
Motivation and inspiration
Although many researchers have conducted researches on ISs based on fuzzy relations, most of them have ignored the probability distribution of the objects in the universe, namely, they assume that the probability distribution of objects in the universe is uniform. However, in many real world applications, there is a probability distribution of the objects [44]. These studies are just held when the probabilities of all objects is entirely ignored. Hence, it can not fully reflect the nature of things. Therefore, in order to work around this problem, we define a fuzzy probability information system (FPIS) for the first time.
In this work, a FPIS, the combination of some fuzzy relations in the same universe which satisfies the probability distribution, can be seen as an IS with fuzzy relations. Hence, this system can overcome the situation of missing information caused by the uniform probability distribution of elements in fuzzy relation ISs. This also means that it makes sense to study FPISs.
Reduction as a crucial notion in ISs, which is often used in data mining and machine learning. As we all know, the attributes of an IS are not of the same importance, some even are redundant. So ones often consider attribute reduction in an IS by deleting unrelated or unimportant attributes with the requirement of keeping the ability of classification [3, 10]. As mentioned earlier, a FPIS can be seen as an IS with fuzzy relations on the universe which satisfies the probability distribution. That is to say, fuzzy relations in a FPIS are not of the same importance, some even are redundant. Those relations may be structured in several categories according to the importance which is based on a certain standard. To date, reduction for FPISs has not been discussed. Clearly, it is worthwhile to study its reduction. So we consider reduction in a FPIS by deleting unrelated or unimportant fuzzy relations with the requirement of keeping some of its ability. Additionally, the measurement uncertainty of FPISs is a basic investigation theme that has not been studied at present. How to use a measure to distinguish the importance of fuzzy relations in FPIS is an interesting problem. By solving this problem, we can propose some effective reduction algorithms based on the measurement of fuzzy relations.
The purpose of this article is to solve the issue of fuzzy relations reduction in a FPIS. Firstly, we regard the combination of some fuzzy relations in the same universe which satisfies the probability distribution as a FPIS. Next we investigate reduction in a FPIS. Then, we give uncertainty measurement for a FPIS by using information entropy. Base on the obtained uncertainty measurement, we propose some effective reduction algorithms.
Organization
The rest of this paper is structured as following. In Section 2, we review relevant concepts for fuzzy relations and Fuzzy probabilistic approximation spaces. In Section 3, we recall the notion of an IS, and develop a new concept: FPIS. In Section 4, we propose a reduction algorithm and divide fuzzy relations in a FPIS into three categories depending on the importance. In Section 5, we investigate a entropy measurement for a FPIS. In Section 6, we verify and analyze all algorithms proposed in this paper by an example. In Section 7, we discuss several references on reduction of fuzzy relations. In Section 8, we make a summary of this paper.
Preliminaries
We first recall some basic concepts about fuzzy relation, and fuzzy probabilistic approximation spaces.
Throughout this paper, U denotes a finite set and I means [0, 1].
Put
Fuzzy relations
Recall that F is a fuzzy set whenever F is a function defined by F : U → I.
For a ∈ I,
In this article, I U shows the collection of fuzzy sets on U.
Given F ∈ I U , |F| = ∑x∈UF (x) expresses the cardinality of F.
If R is a fuzzy set in U × U, then R is called a fuzzy relation on U.
In this article, IU×U denotes the collection of all fuzzy relations on U, and [IU×U] <ω denotes the subfamily of all finite subsets of IU×U.
Given R ∈ IU×U. Then R can be denoted by the following matrix
If R = E (here, E is an identity matrix), then R is said to be a fuzzy identity relation on U, and written as R =▵; if R = 0, then R is said to be a fuzzy zero relation on U, and written as R = o; if R (x i , x j ) =1 for any i, j, then R is said to be a fuzzy universal relation on U, and written as R = ω.
Suppose R ∈ IU×U. Given x ∈ U. the fuzzy information granule of the point x with respect to R is defined as follows:
Obviously, [x] R ∈ I U .
For any
Fuzzy probabilistic approximation spaces
Let (U, R, P) be a FPA-space where
Denote
Then
Obviously,
Then (U, R, P) is a FPA-space.
We have
Fuzzy probabilistic information systems
In this section, we recall fuzzy probabilistic information systems.
Information systems
If B ⊆ A, then (U, B) is called a subsystem of (U, A).
Let (U, A) be an IS. Given B ⊆ A. Then an equivalence relation ind (B) can be defined by
Obviously,
For any x ∈ U, denote
If u, v ∈ [x] B , then we may say that u and v cannot be distinguished under ind (B). So [x] B can be seen as an information granule consisting of indistinguishable objects. Thus, ind (B) is also called the indiscernibility relation on U.
Since ind (B) partitions the object set U into some disjoint equivalence classes, we can say that ind (B) represents the ability of classification of the subsystem (U, B).
It is well known that attributes in an IS are not of the same importance, some even are redundant. So we often consider attribute reduction in an IS by deleting unrelated or unimportant attribute with the requirement of keeping the ability of classification. This is the meaning of attribute reduction in an IS. The concept of attribute reduction is defined as follows.
(1) B ⊆ A is referred to as a coordinate subset of A, if ind (B) = ind (A).
(2) B ⊆ A is said to be an attribute reduct of A, if B is a coordinate subset of A and every proper subset of B is not a coordinate subset of A.
“ind (B) = ind (A) " means that (U, B) and (U, A) have the same ability of classification. Thus, an attribute reduct of A is a minimal attribute subset that maintains the ability of classification.
In this paper, co (A) (resp., red (A)) denotes the family of all P-coordinate subsets (resp., all attribute reducts) of A.
(1) a ∈ A is called a P-necessary attribute, if a ∈ core (A).
(2) a ∈ A is said to be a relatively P-necessary attribute, if a ∈ ⋃ B∈red(A)B - core (A).
(3) a ∈ A is referred to as a P-unnecessary attribute, if a ∈ A - ⋃ B∈red(A)B.
FPIS
If
Actually, a FPIS as a combination of some fuzzy relations on the same universe which satisfies the probability distribution is not an IS. But we may view it as an IS with fuzzy relations. In this way, we can handle it like an IS.
Reduction in a FPIS
In this section, we consider reduction in a FPIS and divide fuzzy relations in this system into three categories according to the importance.
A FPIS can be seen as an IS with fuzzy relations on the universe which satisfies the probability distribution. As mentioned earlier, we can handle it like an IS. Thus, elements (i.e., fuzzy relations) in a FPIS are not of the same importance, some even are redundant. So we often consider a reduct of a FPIS by deleting unrelated or unimportant elements with the requirement of keeping some of its ability. This is the meaning of reduction in a FPIS.
(1)
(2)
(3)
(4)
The set of all P-coordinate subfamilies (resp., all reducts) of
Obviously,
Proof. Obviously,
Suppose
Thus, there always exists a P-reduct of

As described above, Algorithm 1 stops when deleting any relation in
Proof.
“
“⇐". Denote
Assume n ≥ 2. Since
Thus n = 1. □
Since elements in a FPIS are not of the same importance, they may be divided into several categories according to the importance which is based on a certain standard. Below, we divide fuzzy relations in a FPIS into three categories according to the importance.
(1)
(2)
(3)
(1) R is P-necessary in
(2) R is P-independent in
Proof. Obviously. □
(1) R is P-necessary in
(2)
Proof.
(1) R is P-unnecessary in
(2) For any
Proof.
Thus
Since
Since
Suppose
Pick
We have
By Algorithm 1, we have
{R2, R5, R6, R7, R8, R9} , {R4, R5, R6, R7, R8, R9}} .
Thus
From the above facts, we can obtain the following results:
(1) R5, R6, R7, R8, R9 is P-necessary in
(2) R1, R2, R4 is relatively P-necessary in
(3) R3 is P-unnecessary in
Entropy measurement for a FPIS and reduction algorithms based on this measurement
In this section, we investigate entropy measurement for a FPIS and give reduction algorithms based on this measurement.
Entropy measurement for a FPIS
In physics, entropy is frequently employed to estimate the out-of-order degree of systems. Shannon [26] employed the notion of entropy for measuring their uncertainty.
Let
Then
Denote
Obviously,
The uncertainty of a given FPA-space is derived from the uncertainty of the fuzzy relation imposed on its universe.
Given U = {x1, x2, ⋯ , x n } ,
Then
If
Thus
Proof. (1) Given
U = {x1, x2, ⋯ , x
n
},
Then
It should be noted that ∀ i, j, 0 ≤ r
ij
≤ 1 . Then ∀ i,
Thus ∀ i,
This implies that ∀ i,
Hence
(2) Suppose that
Thus ∀ i,
Hence
By (1),
(3) Suppose
This implies that
Hence, H achieves the minimum value 0 when
□
Proof. (1) Since
This implies that
Then ∀ i, j,
By Definition 5.4
Homoplastically, we have
Thus
Proof. “
Thus
“⇐" By Definition 5.4,
Homoplastically,
Since
Note that
This implies that ∀ i, j,
Then ∀ i,
Thus ∀ i,
It follows from that ∀ i,
Then ∀ i,
Note that
This implies that
Hence
(1)
(2)
Proof. It is proved by Proposition 5.8. □
Proof. It is proved by Propositions 5.7 and 5.8. □
Proof. It can be proved by Propositions 4.7 and 5.8.
□
(1)
(2)
Proof. It can be obtained by Propositions 4.8 and 5.8.
□
Reduction algorithms based on entropy measurement for a FPIS
Based on the above discussion, the information entropy reflects the classification power of a fuzzy relations. It can be used to measure the importance of a fuzzy relations. Since

As described above, Algorithm 1 stops when deleting any relations in
According to Definition 5.13, the inner-importance degree of R in

As described above, Algorithm 3 stops when any relations that the minimum inner-importance degree is not zero in
Proof. It can be proved by Proposition 5.11. □
According to Definition 5.15, the outer-importance degree of R in

As described above, Algorithm 4 stops when any relations that the maximum outer-importance degree is zero in
An illustrative example
In order to evaluate the effectiveness of the proposed reduction algorithms, we give the following example.
Suppose
Pick
Fuzzy relations selected in reducts obtained by Algorithms 1–4
Fuzzy relations selected in reducts obtained by Algorithms 1–4

The work flow of this paper.
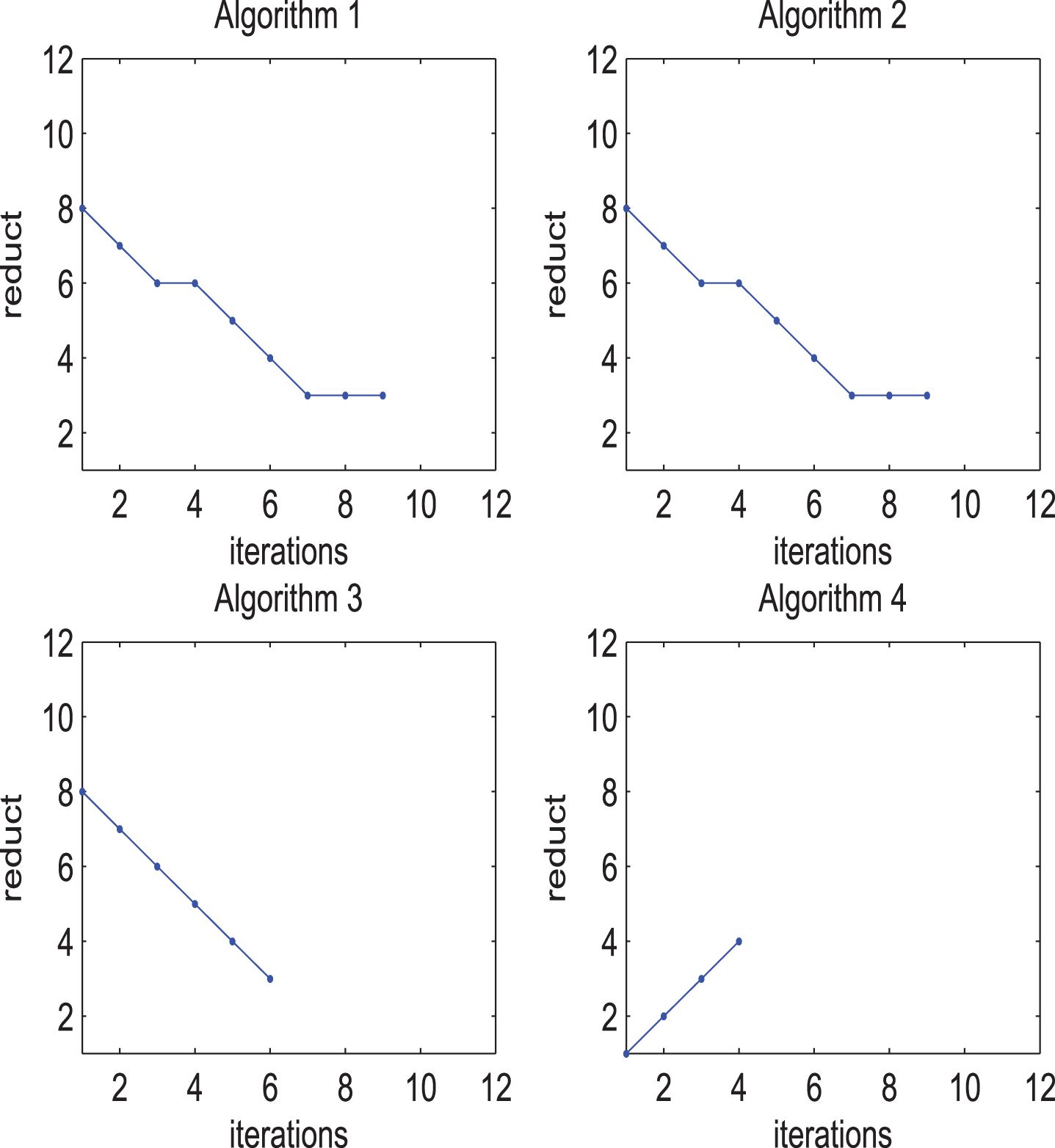
The relationship between the number of iterations and reducts in
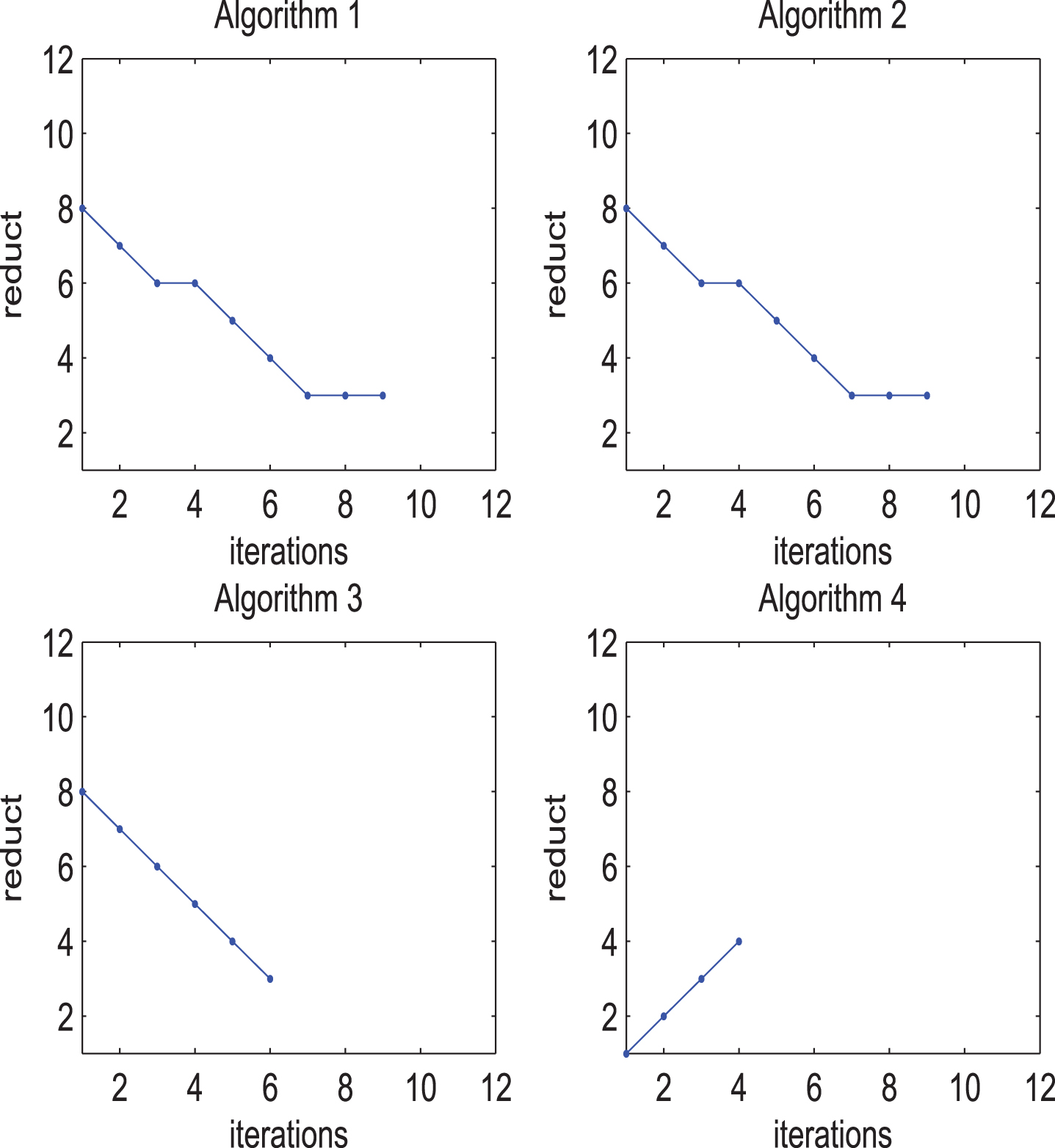
The relationship between the number of iterations and reducts in
Suppose
Pick
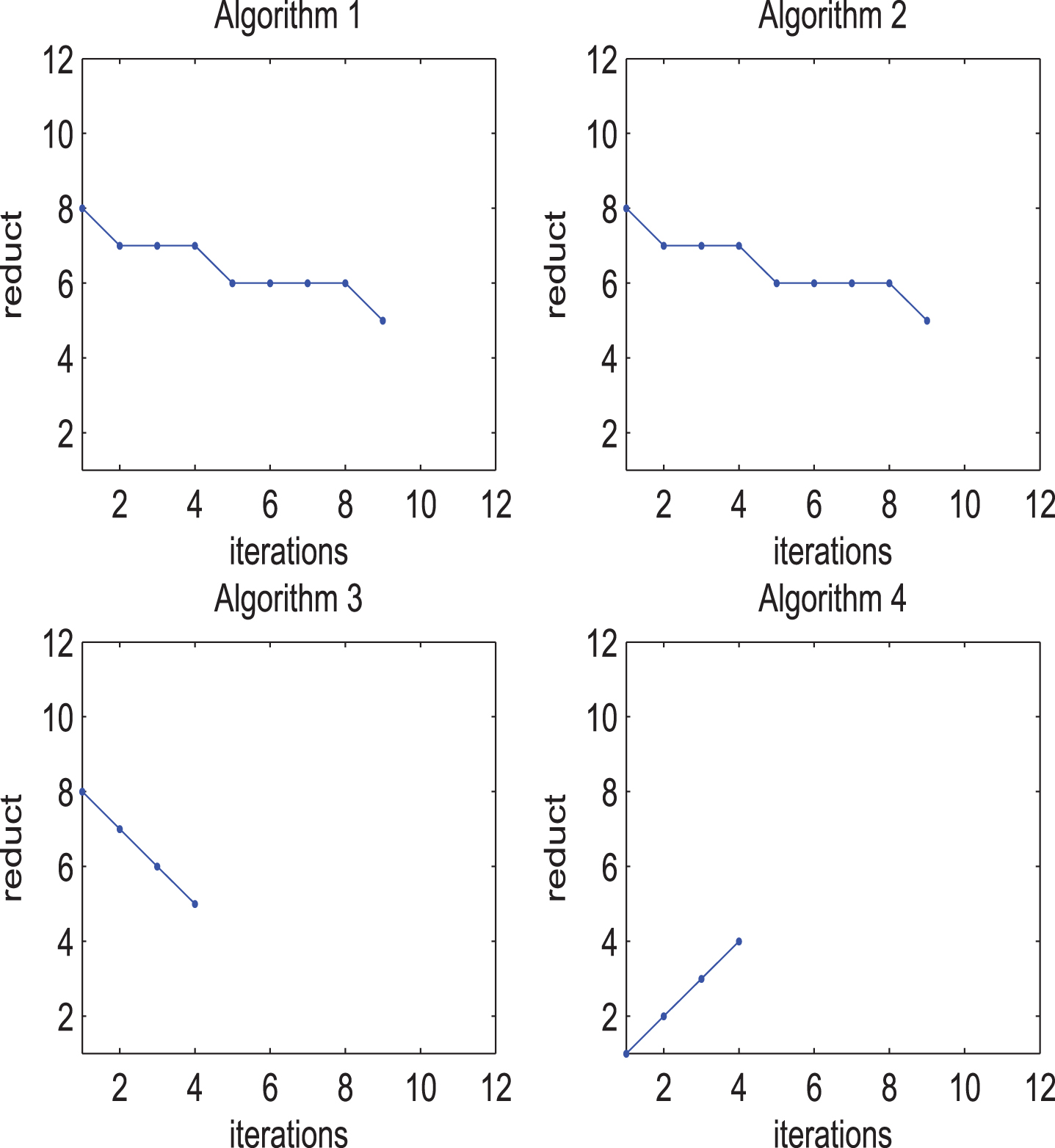
The relationship between the number of iterations and reduction in
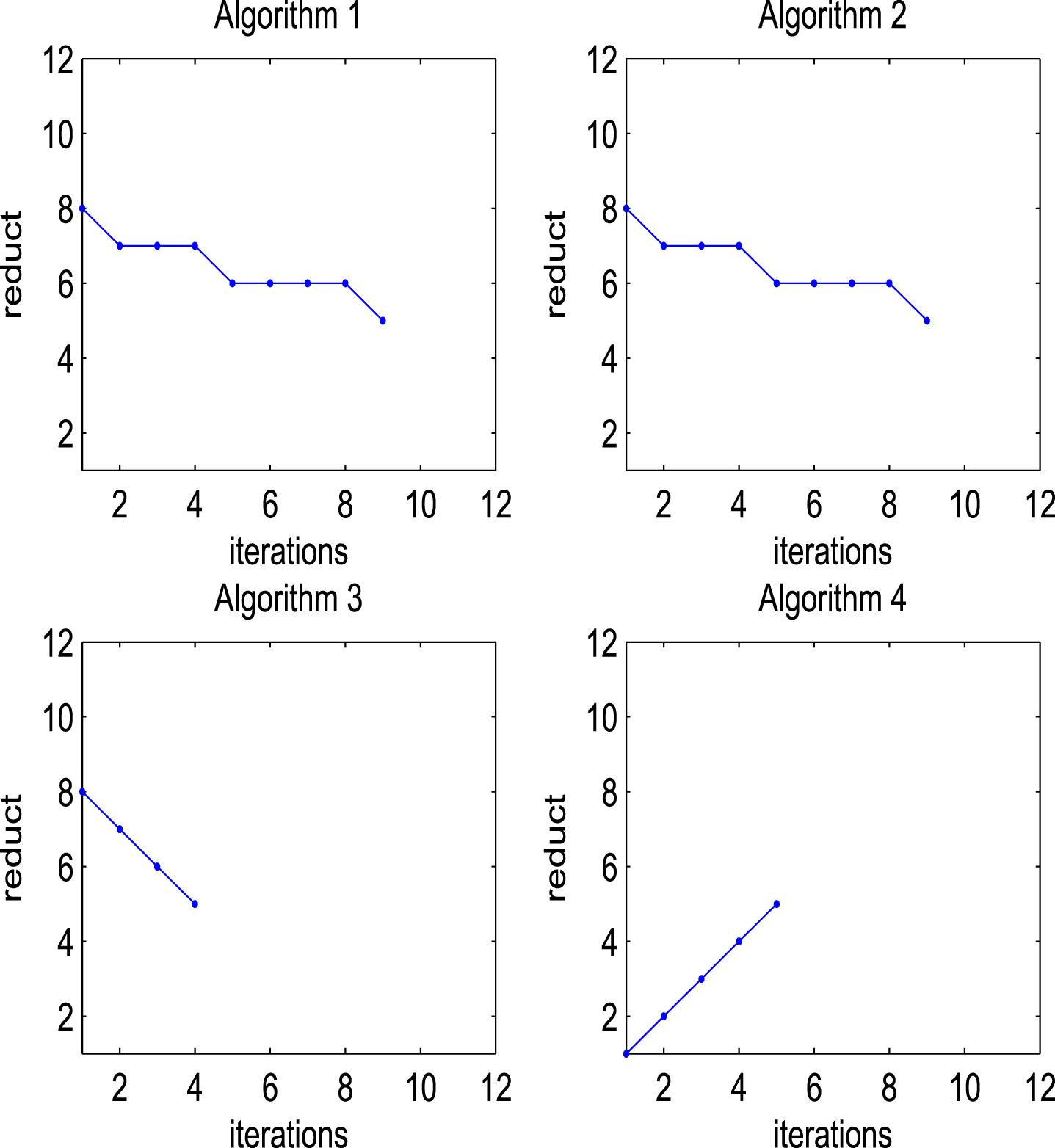
The relationship between the number of iterations and reducts in
Table 1 shows that reducts obtained by Algorithms 1-3 are completely consistent, while reducts obtained by Algorithm 4 may be the same or different from that of Algorithms 1-3. Moreover, the change of the probability distribution of the object set may affect the reduction selected by Algorithm 4.
Figures 2-5 display that the reducts varies with the number of iterations in four FPISs of Algorithms 1-4. Among them, the number of iterations of Algorithms 1-2 are the largest and consistent with the number of fuzzy relations in FPIS. Therefore, although Algorithms 1-3 are consistent in reduction, the number of iterations of Algorithm 3 is usually less than that of Algorithms 1-2. In addition, the more fuzzy relations are selected, the fewer iteration times of Algorithm 3 and the more iteration times of Algorithm 4.
By summarizing the above example, some conclusions are obtained as following: If the influence of the probability distribution on reducts needs to be considered, Algorithm 4 has better performance. If the iteration time of the obtained algorithms needs to be considered, Algorithms 3 and 4 have better performance than Algorithms 1 and 2. If the iteration time of proposed algorithms needs to be considered, Algorithm 3 has better performance when there are more fuzzy relations. If the iteration time of those algorithms needs to be considered, Algorithm 4 has better performance when there are fewer fuzzy relations. If the probability distribution of object set and iteration time of proposed algorithms both need to be considered, Algorithm 4 has better performance.
In this section, we discuss several references for fuzzy relations in this article so as to highlight advantages of proposed algorithms. Wu et al. [36] explored some properties of relational ISs under homomorphism. In addition, they also gave reduction in a relational IS and proved that the reduction of this system is equivalent to that of an image system under homomorphism condition. Hu et al. [13] provided a measurement method for fuzzy relations and crisp relations. Additionally, they proposed two greedy dimensionality reduction algorithms based on the obtained measurement method for unsupervised and supervised data. Yu et al. [43] obtained some information entropy measures suitable for fuzzy relations. They also figured up the diversity quantity of multi classifier systems and the granularity of granulated problem spaces according to the proposed measures respectively. Since each numerical attribute can generate a fuzzy similarity relation in a sample space, they proposed a forward greedy search algorithm for numerical feature selection founded on the obtained conditional entropy. Singh et al. [30] studied how to reduce fuzzy relations according to a given fuzzy context and obtained a reduction method. Through this method, fuzzy relations can be projected not only to objects, but also to attributes. Cai et al. [4] investigated the homomorphism between fuzzy relational ISs in a dynamic environment and gave the construction method of consistent function between these fuzzy relations. In addition, they use homomorphism to generate some algorithms to reduce the fuzzy relations of a fuzzy relational IS. Wang et al. [38] mentioned a different means about uncertainty measurement for fuzzy relations and its basic properties. In addition, they linked a fuzzy binary relation and each attribute together by establishing a fuzzy binary relation between samples, so they applied the results to attribute reduction of heterogeneous data sets. In this paper, we combine some given fuzzy relations with the probability distribution of objects to form a FPIS. Moreover, we divide fuzzy relations in this system into three categories depending upon these important and give a reduction algorithm 1 by the importance of fuzzy relations. On the basis of information entropy, we use the fuzzy granules formed by fuzzy relations containing probability distribution to propose a method to measure the information uncertainty of FPISs. In addition, we propose some reduction algorithms based on this measure. Finally, we analyze the effectiveness of the proposed algorithms in this article.
In general, a FPIS can be regarded as a generalization of a fuzzy relational IS, which can overcome the information loss caused by fuzzy relation ISs ignoring the probability of objects. In addition, when the probability of objects is uniformly distributed, the measurement and reduction algorithms proposed in this paper will be degenerated into the measurements and reduction algorithms of fuzzy relational IS. This also verifies the rationality of the measurements and algorithms from the side.
Reduction plays a critical role in pattern recognition and data mining. In a given data set with a probability distribution, different attributes can be used to generate different fuzzy relations. This means that we can generate the corresponding fuzzy relation through the attributes of the data and the reduction of fuzzy relations is equivalent to the reduction of its corresponding attributes. Therefore, the obtained reduction algorithms can be applied to the data reduction, so as to realize the application of the obtained results in the real world. Additionally, since fuzzy relations are diffusely used in areas, such as multi-classifier systems, text categorization, hyper spectral image fusion, etc., the reduction algorithms and measurements obtained in this paper may be useful in these fields.
Conclusions
Fuzzy relation as a critical notion in fuzzy set, which can be views as foundations of information fusion, artificial intelligence and granular computing. In this paper, a FPIS has been proposed for the first time and contains three kinds of uncertainties (roughness, fuzziness and probability). It has been treated as an IS with fuzzy relations where the probability distribution is integrated into the fuzzy relations. By fusing probability distribution with fuzzy relations, it is may be helpful to dig out more potential knowledge in information. In this work, fuzzy relations in a FPIS have been classified according to the importance. The definition of reduction in this system has been given, and the reduction Algorithm 1 has been devised by this definition. Information entropy has been proposed, which can compare the amount of knowledge formed by different fuzzy relations and find the important or redundant fuzzy relations in a FPIS. It is worth noting that the more the fuzzy relations of the system, the greater the uncertainty of the system by proving the monotony of the measures. In addition, it can be found that the proposed measure will be seen as a measure of fuzzy relation ISs in the case of the probability distribution is uniform. Reduction algorithms based on the obtained entropy measure have been presented. Note that these four algorithms can also be regarded as reduction algorithms for fuzzy relation ISs when the probabilities of the objects are equal. To verify the rationality of the proposed algorithms, effectiveness analysis has been performed. The results show that all the four algorithms can effectively reduce the fuzzy relations in a FPIS. Additionally, Algorithm 4 is more sensitive to the change of the probability distribution. The performance of Algorithms 1 and 2 is lower than Algorithms 3 and 4 in most cases. Since this paper does not study how fuzzy relations are generated, the application of the proposed algorithms in reality has not been investigated. In future work, we will study information structure in FPISs and consider the other reduction algorithms for a FPIS by put forward different measures. Obviously, for a given data set with a probability distribution, different attributes are used to construct different fuzzy relations, namely, relational functions with attributes can be constructed to generate relational matrices. We will explore how to generate fuzzy relations between objects with a probability distribution so as to apply the results to attribute reduction in real world.
Footnotes
Acknowledgments
The authors would like to thank the editors and the anonymous reviewers for their valuable comments and suggestions, which have helped immensely in improving the quality of the paper. This work is supported by National Natural Science Foundation of China (11971420), Natural Science Foundation of Guangxi (AD19245102, 2020GXNSFAA159155, 2018GXNSFDA294003, 2018GXNSFAA294134), Guangxi Higher Education Institutions of China (Document No. [2019] 52) and Special Scientific Research Project of Young Innovative Talents in Guangxi (2019AC20052).