
Abstract
Classification problem is an important research direction in machine learning. υ-nonparallel support vector machine (υ-NPSVM) is an important classifier used to solve classification problems. It is widely used because of its structural risk minimization principle, kernel trick, and sparsity. However, when solving classification problems, υ-NPSVM will encounter the problem of sample noises and heteroscedastic noise structure, which will affect its performance. In this paper, two improvements are made on the υ-NPSVM model, and a υ-nonparallel parametric margin fuzzy support vector machine (par-υ-FNPSVM) is established. On the one hand, for the noises that may exist in the data set, the neighbor information is used to add fuzzy membership to the samples, so that the contribution of each sample to the classification is treated differently. On the other hand, in order to reduce the effect of heteroscedastic structure, an insensitive loss function is introduced. The advantages of the new model are verified through UCI machine learning standard data set experiments. Finally, Friedman test and Bonferroni-Dunn test are used to verify the statistical significance of it.
Keywords
Introduction
Machine learning is a common research hotspot in the field of artificial intelligence and pattern recognition. Support Vector Machine (SVM) is a new technology introduced by Vapnik et al. in the 1990 s to address machine learning problems with optimization methods [1–5], and have been successfully applied in a wide variety of fields such as face recognition, text categorization, bioinformatics [6–12], etc.
Recently, a branch of SVM, nonparallel hyperplane SVM which considers the difference in data distribution of samples, is developed and has attracted many interests. The representative algorithms include the generalized eigenvalue proximal support vector machine (GEPSVM) [13–15], the twin support vector machine (TWSVM) [16–18] and the nonparallel support vector machine (NPSVM) [19, 20]. For the GEPSVM, it opened a new chapter in the research of non-parallel hyperplane SVM classification methods. In this method, the samples of each class are located near one hyperplane and maintain a clear separation from the other. Two non-parallel planes are represented by eigenvectors, which depend on the smallest eigenvalue obtained from the generalized eigenvalue problem. For TWSVM, it seeks two non-parallel proximal hyperplanes such that each hyperplane is close to one of the two classes and is at least one distance from the other. The formulation of TWSVM is totally different from that of GEPSVM and is very much in line with standard SVM. It is implemented by solving two smaller QPPs instead of a larger one, which increases the TWSVM training speed by approximately fourfold compared to that of standard SVM. Twin support vector machines (TWSVM) have been studied extensively [21–25]. For NPSVM, it seeks two nonparallel hyperplanes, such that each class locates as much as possible in the ɛ-band of the hyperplane and each hyperplane is at least one distance from the other. NPSVM has many advantages over TWSVM in theory such as the same two convex quadratic programming problems for both linear and nonlinear cases, no need to compute the inverse matrices before training and sparsity. Therefore, NPSVM has attracted a lot of attention [26–28].
In NPSVM, the parameter ɛ and the regularization constant C controlling the sparseness need to be specified beforehand. The value of them is qualitatively clear: the larger C implies the more attention has been paid to minimizing the training error, the larger ɛ implies greater sparsity. However, it is gravely lacking in quantitative meaning, which means that we cannot estimate the sparseness even we are given the value of C and ɛ. In order to overcome this problem, υ-NPSVM [29–31] is introduced. Parameter υ lets one effectively control the number of support vectors.
However, when solving classification problems, υ-NPSVM will encounter the problem of sample noises and heteroscedastic noise structure, which will affect its performance. In υ-NPSVM, it is assumed that the noise level is uniform throughout the domain. However, in many practical problems, there may be noises in the data samples and they may not be uniform which is called heterogeneous noises. That means some noises depend largely on the position of the sample points. In response to these problems, a parameter-insensitive loss function and a nearest neighbor fuzzy membership are introduced respectively in υ-NPSVM. Combining the above two improvements, this paper constructs a υ-nonparallel parametric margin fuzzy support vector machine model (par-υ-FNPSVM). Based on the data of heteroscedasticity structure, contribution of each sample to the classification is treated differently. So the classification accuracy and generalization ability is improved obviously. Thereafter, two statistical test methods also help us to verify the statistical significance of the established model.
The rest of this paper is organized as follows. Section 2 is a review of υ-NPSVM. In section 3, parameter margin fuzzy υ-nonparallel support vector machine is presented in detail. Experimental results and discussions are given in section 4. The last section is the conclusion.
υ-Nonparallel Support Vector Machine (υ-NPSVM)
Linear υ-NPSVM
In this section, a review of linear and nonlinear υ-NPSVM will be described briefly.
Consider the training set T = { (x1, + 1) , . . . , (x
p
, + 1) , (xp+1, - 1) , . . . , (xp+q, - 1), where x
i
∈ R
n
, i = 1, …, p + q the inputs are, y
i
∈ { - 1, 1 } are the outputs. υ-NPSVM is to find two nonparallel hyperplanes
Among them, C
i
⩾ 0, i = 1, 2 are penalty parameters, which control the coordination between the maximum boundary and the number of misclassifications. Parameters v
i
∈ (0, 1] , i = 1, …, 4 control the sparsity of positive and negative classes respectively.
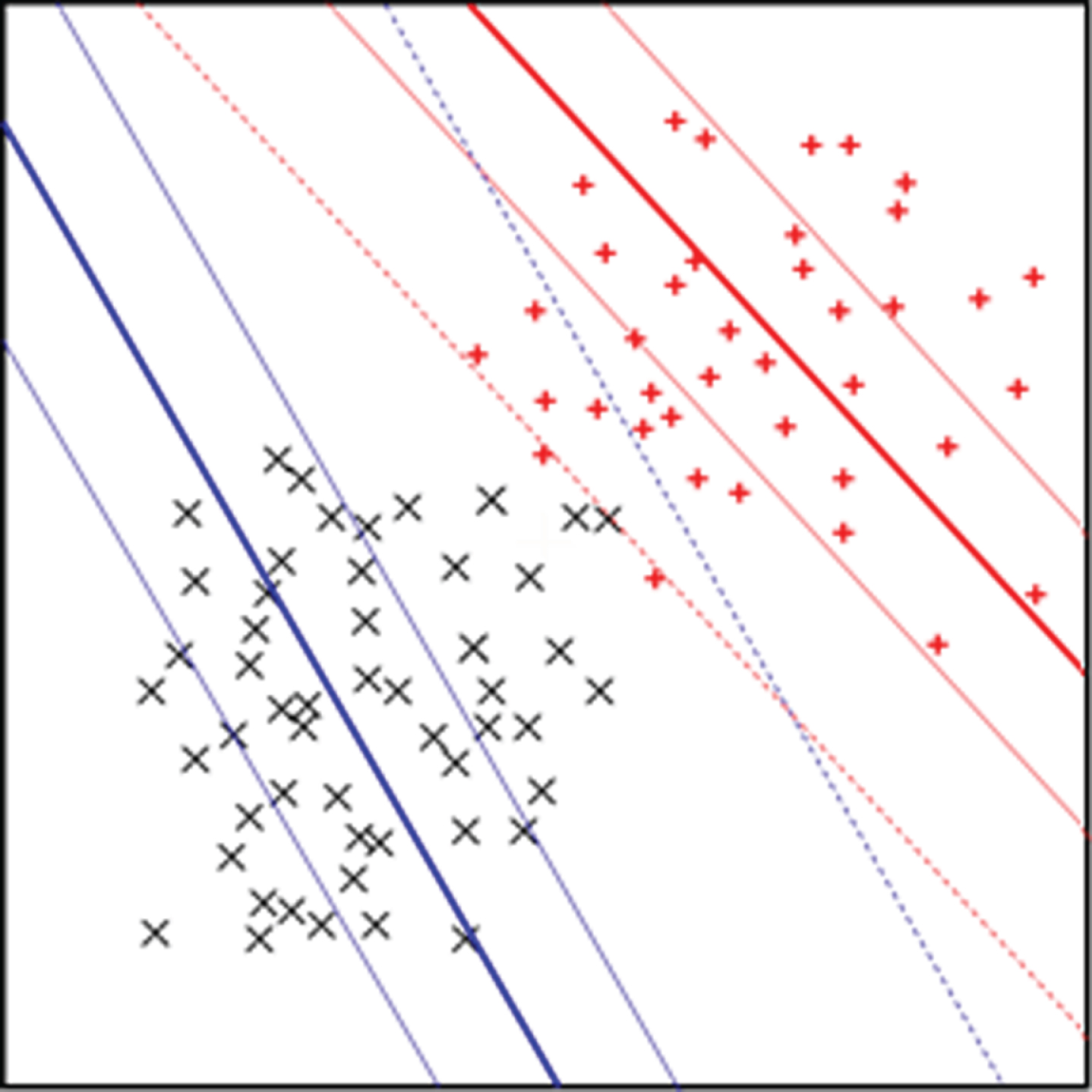
Geometrical illustration of υ-NPSVM in R2.
The Wolfe dual forms of the original problems (2) and (3) are:
Similarly, in (5), α = (αp+1, …, αp+q)
T
, β = (βp+1, …, βp+q)
T
By calculating the dual problems (4), the solution (α, β, γ) is obtained, w+ can be expressed as
Similarly, by calculating the dual problem (5), w _ can be expressed as
Then, the two decision functions are obtained
In many cases, the sample points cannot be separated by the linear class boundary. Therefore, we can use the kernel technique to extend the linear υ-NPSVM to the nonlinear case. After the sample points are projected into the high-dimensional feature space, they are easier to separate. By introducing the kernel function K (x i , x j ) = φ (x i ) · φ (x j ), the optimization problems corresponding to problems (4) and (5) are as follows:
By solving two convex QPPs (12) and (13), we get the solution (α, β, γ), and two decision functions are obtained.
and
In order to solve the problem of heteroscedastic noise encountered in classification problems and the influence of noises in training, a parameter margin function and a fuzzy membership degree are introduced on the basis of υ-NPSVM, thereby constructing the par-υ-FNPSVM model. The introduction of parameter margin function is to solve the problem of heteroscedastic noise. Introducing the nearest neighbor chain fuzzy membership is to reduce the influence of noises on finding the best hyperplanes. The detailed flow chart of this method is shown in Fig. 2.
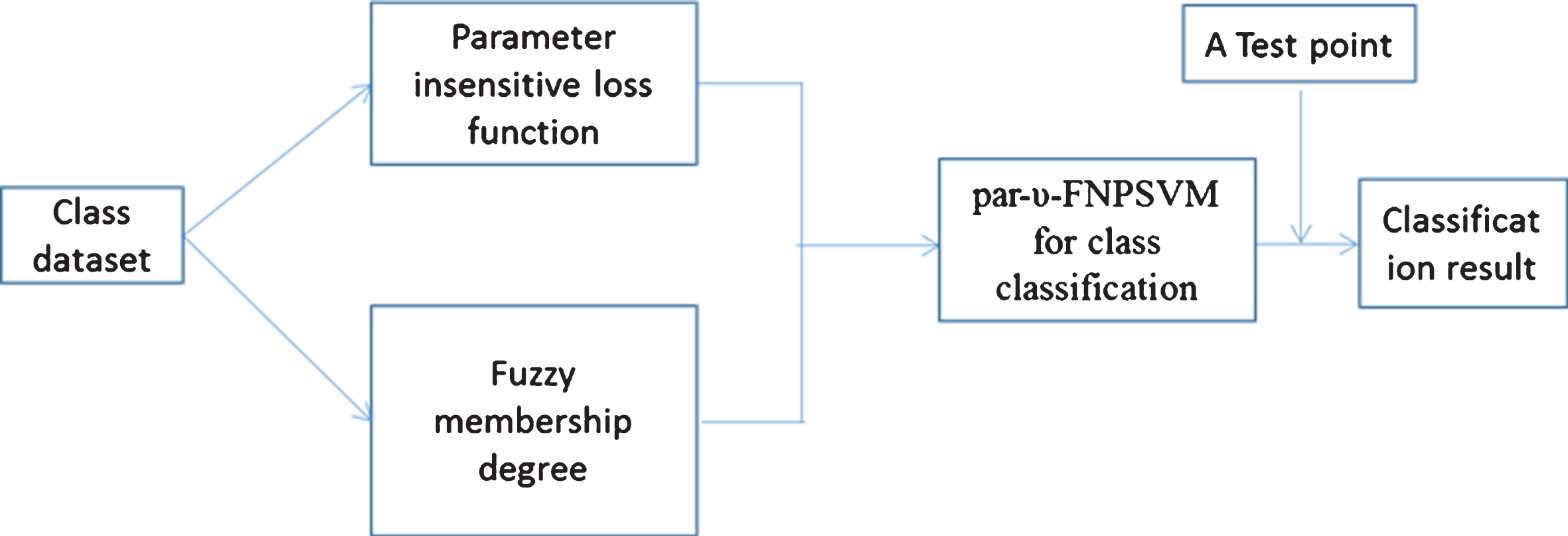
Flow chart of par-υ-FNPSVM.
Define parameter margin loss function
We know that υ-NPSVM assumes the noise level is uniform throughout the domain, but in fact this assumption is usually not true. There may be heteroscedasticity noise in the sample points. In this paper, in the υ-NPSVM model, improvement is made by adding a parameter margin loss function. The parameter margin loss function L
g
(x, y, f) is defined as
In other words, we do not care about errors as long as they are inside the parametric-margin zone f (x) ± g (x). Only the points outside the parametric-margin zone contribute to the cost, insofar as the deviations are penalized in a linear fashion. The goal of adding L g (x, y, f) to υ-NPSVM is to automatically adjust the parameter margin area of arbitrary shape and minimum size to include the data model. By replacing ρ in the υ-NPSVM model with a parameter margin function g (x) = u · x + d, it can improve the problem of poor classification accuracy caused by heteroscedastic noise. Figure 3 depicts the situation graphically.

υ-NPSVM algorithm with parametric margin model. (The shaded region represents the parametric margin zone f (x) ± g (x)..
υ-NPSVM treats all training samples as equally important. At this time, the noises and outliers in the training samples are also treated equally. Therefore, the learning of the model is prone to overfitting, which affects the performance. In order to solve this problem, we introduce the fuzzy membership degree based on the nearest neighbor chain [32] into υ-NPSVM.
By studying the model characteristic of υ-NPSVM, we know that in υ-NPSVM, support vectors close to the classification edge should be given a higher degree of membership, and noise points should be given a lower degree of membership. This degree of membership can also be understood as the possibility that a sample point belongs to the support vector set. υ-NPSVM does not know which sample points are support vectors before establishing the classification model, but only knows that most support vectors should be close to the edge of the classification. Therefore, in this section, the membership of the sample points based on the nearest neighbor chain is established. The samples close to the classification edge and far away from the classification edge are distinguished.
The nearest neighbor chain of x i is composed of a list of nodes like xi,1, xi,2, …, xi,m, where m is a designated positive integer, and the corresponding labels are yi,1, yi,2, …, yi,m, respectively. The first node is xi,1 itself, and the other nodes xi,j (j = 2, . . , m) are the nearest neighbors of the previous node labeled X -{ xi,1, …, xi,j-1 } in the yi,1 set. When j is odd, yi,j = y i ; when j is even, yi,j ≠ y i .
A sequence (D1,2, D2,3, …, Dm-1,m) based on sample point x i can be established according to this method, where the distance between node xi,j and node xi,j+1 is Dj,j+1 = ∥ xi,j - xi,j+1 ∥ 2, j = 1, . . , m - 1.
Establish fuzzy membership degree x
i
based on the nearest neighbor chain
Because
Here is an example, as shown in Fig. 4. The blue point represents the positive point, and the red point represents the negative point. The figure shows a nearest neighbor chain (m = 11) of x i in the positive point. Since this point is close to the classification edge, according to the definition, it belongs to the support vector and should be given a larger degree of membership.

The nearest neighbor chain of x i .
In this section, the parameter margin function and the nearest neighbor chain fuzzy membership are combined to act on υ-NPSVM, and a new model par-υ-FNPSVM is established.
Linear par-υ-FNPSVM
For the linear case, the optimization problem of υ-nonparallel parameter margin fuzzy support vector machine is
According to the reasoning process in
In short, (21) is equal to the following QPP
Among them,
and
According to the reasoning process in
In short, (29) is equal to the following QPP
and
For question (29), we can derive a corresponding result similar to Theorem 1, which is omitted here.
Once the solutions (w+, b+) and (w-, b-) of problems (19) and (20) are obtained, a new data point xɛR
n
is predicted to the class by
Similar to υ-NPSVM, the kernel function can be directly applied to the dual problems (21) and (29), so linear par-υ-FNPSVM can be easily extended to nonlinear classifiers. Except that the kernel function K (x, x′) is used instead of the inner product (x, x′), the corresponding conclusion is similar to the linear case. Take problem (21) as an example, the formula with kernel function is shown below
Relative to problem (29), the nonlinear case is
For Training:
For i=+, -, indicates positive and negative classes. Establish parameter margin loss function (16) and fuzzy membership s
i
by (17); Select a kernel function K and construct original problems of nonlinear par-υ-FNPSVM (38) and (39) with parametric margin; Select all optimal parameters on the basis of validation; Solve the dual problem (21), (29) to obtain w
i
and b
i
; Generate hyperplanes using (1).
Construct two decision functions:
and
During testing phase, a class is assigned to test point by using (37).
We have mentioned that the proposed par-υ-FNPSVM is motivated by the υ-NPSVM. So we show some comparisons of par-υ-FNPSVM and υ-NPSVM. As we can see both the par-υ-FNPSVM and υ-NPSVM first optimize a pair of smaller sized QPPs, which are used to construct a pair of nonparallel hyperplanes, while the separating functions are then constructed. This strategy makes the par-υ-FNPSVM obtain the similar learning cost as the υ-NPSVM with the complexity of # iteration × O (0.5l) where # iteration is the number of the iterations, if most columns of the kernel matrix are cached throughout iterations. Of course, it should be noted that the fuzzy membership degree is added before training, so it does not affect the training complexity. However, there are some differences in the two classifiers. First, the ends of the par-υ-FNPSVM and υ-NPSVM are different. The par-υ-FNPSVM finds a pair of parametric-margin hyperplanes such that each one determines the positive or negative parametric-margin, while the υ-NPSVM find a pair of nonparallel hyperplanes such that each hyperplane is closer to one of the two classes and is at least one far from the other class. Second, the constructions of the QPPs of the par-υ-FNPSVM and υ-NPSVM are totally different, including the objective functions and the constraints. For instance, in the case of the par-υ-FNPSVM, the number of constraints is the number of points in the same class for each QPP. Whereas, in the case of the υ-NPSVM, the number of constraints is the number of points in the other class. Essentially, this is because the par-υ-FNPSVM and υ-NPSVM have the different ideas.
Experimental environment and data
In order to verify the performance of par-υ-FNPSVM, this paper compares it with SVM, υ-SVM, υ-NPSVM, par-υ-SVM, par-υ-NPSVM and par-υ-FNPSVM on different types of data sets. UCI Machine Learning Repository is a collection of databases, domain theories, and data generators that are used by the machine learning community for the empirical analysis of machine learning algorithms. We perform the 6 algorithms on 15 UCI datasets. They are Echocardiogram, Echocardiogram, Australian, Balance scale, Cancer, CMC, Diabetes, Echocardiogram, Heart, Hepatitis, Ionosphere, Iris, Parkinson, Sonar, Teaching, WDBC and WPBC which cover many fields such as agriculture, physics and medicine. Respectively, CMC, WDBC and WPBC were Contraceptive Method Choice, Breast Cancer Wisconsin and Wisconsin Prognostic Breast Cancer data sets. The number of samples, feature dimensions, and sample classes are shown in Table 1. These methods are all performed on a PC with Intel(R) Core(TM) i3-3317U 1.70 GHz processor and 4GB memory in MATLAB 2014b.
Basic data set description
Basic data set description
In order to compare the test results fairly, this article adopts a five-fold cross-validation method, that is, the sample data is randomly divided into five groups, four of which are used as training samples, and the other group is used as test samples. Different parameter settings have a certain impact on the classification results. The grid search method is used to optimize the parameters, and the kernel function uses Gaussian kernel function (RBF): K (x i , x j ) = exp{ - |x i - x j |2/2p2 }. The model established in this paper is compared with other support vector machines through its classification accuracy, F1 score and training time. For simplicity, we set C1 = C2 = C, υ1 = υ2 = υ3 = υ4 = υ. For the values of parameter C and kernel parameters p and υ in these algorithms, p = [2-2, 2-1, 20, 21, 22], the regularization parameter C = [10-1, 100, 101, 102, 103, 104, 105] and υ = [0.1, 0.2, 0.3, 0.4, 0.5] to estimate the generalized accuracy. The best classification accuracy and F1 score is shown in bold.
From accuracy and F1 score data, we find that the results of the six models are different, but the overall ranking is almost the same. Since accuracy cannot fully reflect the prediction ability in the case of unbalanced samples, while F1score is a comprehensive index of precision and recall rate, subsequent analysis is based on F1score in this paper.
(1) In Table 2, it can be found that in 15 data sets, the F1 score of par-υ-FNPSVM ranks first on 14 data sets, and the average F1 score of the remaining five algorithm models is arranged in order. Therefore, the average F1 score of par-υ-FNPSVM ranks first, par-υ-NPSVM ranks second, υ-NPSVM ranks third, par-υ-SVM ranks fourth, υ-SVM ranks fifth and SVM ranks last.
Comparison of the classification results of several classifiers related to par-υ-FNPSVM
Comparison of the classification results of several classifiers related to par-υ-FNPSVM
Training time comparison of several classification models (s)
a. Compared with SVM, υ-SVM and par-υ-SVM, the F1 score of υ-NPSVM is 3.02% higher than that of SVM, 1.30% higher than that of υ-SVM, and 1.14% higher than that of par-υ-SVM. The experimental results show that in this experiment, the classification result of υ-NPSVM is better than SVM’s. υ-NPSVM can be shown to be superior as the base model.
b. In par-υ-FNPSVM, if the fuzzy membership of all sample points is 1, then the model can be degenerated to par-υ-NPSVM. Par-υ-NPSVM is an improvement of υ-NPSVM, which increases the average F1 score of υ-NPSVM by 2.84%. Therefore, Par-υ-NPSVM has the highest average F1 score relative to the other four algorithm models. We can prove that the introduction of parameter insensitive function makes the classification of 15 data sets more accurate and reduces the influence of heterogeneous noise.
c. Par-υ-FNPSVM is another improvement of par-υ-NPSVM. In par-υ-FNPSVM, if the fuzzy membership of all sample points is one, then the model can be degenerated to par-υ-NPSVM. Par-υ-FNPSVM increases the average F1 score of par-υ-NPSVM by 1.09%. The experimental results show that adding the nearest neighbor fuzzy membership can improve the F1 score of classification, achieve the purpose of reducing overfitting of training samples and reducing the impact of sample noise.
(2) The corresponding training time is also listed in Table 3. We can be found that:
a. The training time of par-υ-NPSVM is much shorter than that of SVM, υ-SVM and par-υ-SVM. Among them, the average training time of par-υ-NPSVM is 1.59, and the average training time of SVM, υ-SVM and par-υ-SVM are 6.33, 6.39, 6.58 respectively. And the average training time of par-υ-NPSVM and υ-NPSVM differs by 0.02, which indicates that par-υ-NPSVM will not reduce any general performance.
b. The training time of par-υ-FNPSVM is also a little shorter than SVM, υ-SVM and par-υ-SVM, mainly because it also calculates two smaller QPPs. Compared to the average training time of par-υ-NPSVM of 1.66, and the average training time of par-υ-FNPSVM is only 0.04 longer than it. Experimental results show that the training time of par-υ-FNPSVM is not much different, but it has the effect of noise immunity and improvement of heteroscedastic noise.
Average level of F1 score in Table 2
In order to further analyze the performance of these six algorithms, this paper uses Friedman test [33] and Benferroni-Dunn test [33] to test whether there are significant differences between the above experimental results. Table 3 calculates the average level of classification F1 score of the nonlinear classifiers of the SVM, υ-SVM, υ-NPSVM, par-υ-SVM, par-υ-NPSVM and par-υ-FNPSVM algorithms of 15 benchmark data sets.
Friedman test
Friedman test is proved to be a simple non parametric method used to test whether there is a significant difference between multiple algorithms. To compute the Friedman statistic, the average ranking based on F1 score in Table 2 is listed in Table 4. Under the null hypothesis that all the algorithms are equivalent, the Friedman statistic can be computed as follows:
According to (42) and (43), for the nonlinear case, we can obtain
The Bonferroni-Dunn test is used to compare whether our new algorithm (control algorithm) is significantly different from the other five algorithms. Here, the average ranking differences between par-υ-NPSVM and the other five algorithms are compared with the following critical difference (CD):
If the difference is greater than CD, it means that the algorithm with high average ranking is statistically superior to the algorithm with low average ranking. Otherwise, there is no significant statistical difference between the two. We have q a = 2.128 at significance level α = 0.1, and thus CD = 1.45 (m = 6, N = 15). To visually show the performance of par-υ-FNPSVM comparing with other algorithms, Fig. 5 provides the CD diagram, where the average ranks of each comparing algorithm are plotted along the axis. The lowest (best) rank on the axis is to the right since we perceive the algorithms on the right side as better. And any comparing algorithm with the average rank within one CD is interconnected with par-υ-FNPSVM. Otherwise, any other algorithm whose average rank is one CD outside par-υ-FNPSVM is considered to have significantly different performance with par-υ-FNPSVM. As shown in Fig. 5, the average ranks of SVM (4.67-2 = 2.67 > 1.45), υ-SVM (4-2 = 2 > 1.45), υ-NPSVM (3.94-2 = 1.94 > 1.45) and par-υ-SVM (3.47-2 = 1.47 > 1.45) are all one CD outside par-υ-FNPSVM, while the average rank of par-υ-NPSVM (2.93-2 = 0.93 < 1.45) is less than but close to one CD. The results show that par-υ-FNPSVM is statistically significantly better than SVM, υ-SVM, υ-NPSVM and par-υ-SVM, but not significantly better than par-υ-NPSVM. However, compared to the other six methods in Table 3, par-υ-FNPSVM can obtain better F1 score on most data sets. This shows that par-υ-FNPSVM has better generalization ability.
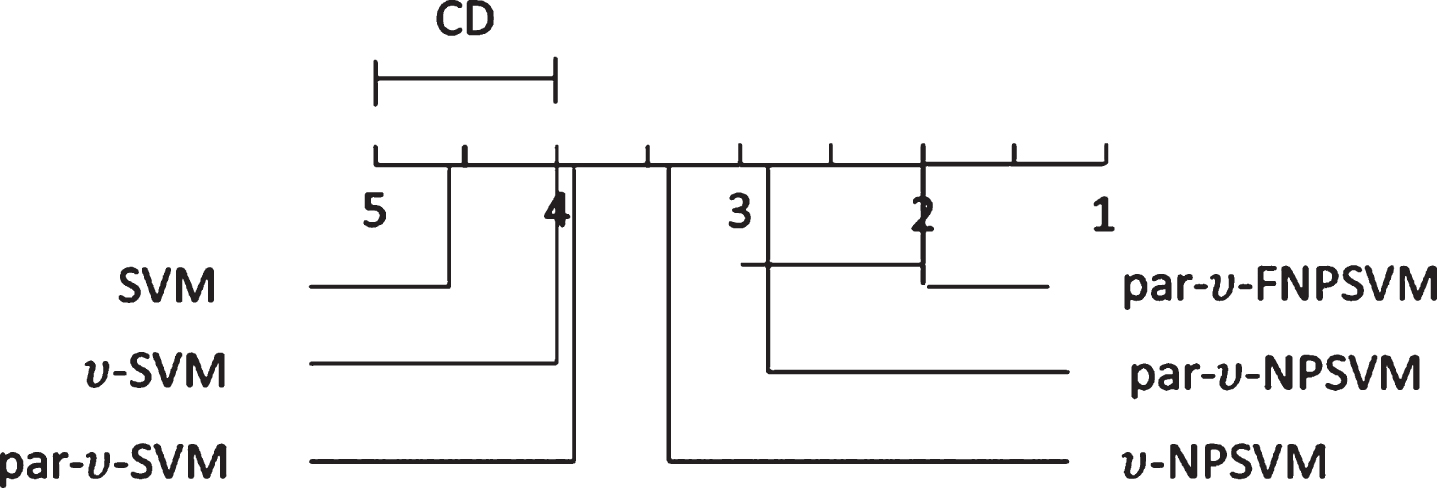
Comparison of the par-υ-FNPSVM against other five comparing algorithms with the Bonferroni-Dunn test.
In order to make υ-NPSVM take into account non-uniform noise and reduce the influence of noise, this paper adds parameter margin and fuzzy membership degree of nearest neighbor chain to υ-NPSVM and establishes par-υ-FNPSVM. In the numerical experiments on UCI data sets, the new model has achieved good classification F1 score, and the training time has not changed significantly. This shows that the new algorithm is indeed superior in dealing with problem of heteroscedastic noises and reducing the influence of noises.
When adding the parameter margin, it is necessary to calculate the parameter margin loss function; when adding the nearest neighbor fuzzy membership degree, it is necessary to optimize the selection of the parameters for membership degree. Although the establishment of parameter-margin loss function and the method of grid optimization can improve the classification F1 score and find the ideal parameters, both tasks require a certain amount of calculation time. In other words, the improvement of classification F1 score comes at the cost of parameter optimization time. Therefore, how to quickly and effectively select the best parameters is a problem for further study.
Footnotes
Appendix 1
For problem (19), we introduce its Lagrangian function
For w+, b+, u+, d+, ɛ+, ξ-, we use the Karush-Kuhn-Tucker (KKT) necessary and sufficient optimality conditions to get the following equations
Then, using (19) and the above K.K.T conditions, we can obtain the Wolfe dual problem (21).
Appendix 2
For problem (20), we introduce its Lagrangian function
For w+, b+, u+, d+, ɛ+, ξ-, we use the Karush-Kuhn-Tucker (KKT) necessary and sufficient optimality conditions to get the following equations
Then, using (20) and the above K.K.T conditions, we can obtain the Wolfe dual problem (29).