
Abstract
Unsupervised aspect identification is a challenging task in aspect-based sentiment analysis. Traditional topic models are usually used for this task, but they are not appropriate for short texts such as product reviews. In this work, we propose an aspect identification model based on aspect vector reconstruction. A key of our model is that we make connections between sentence vectors and multi-grained aspect vectors using fuzzy k-means membership function. Furthermore, to make full use of different aspect representations in vector space, we reconstruct sentence vectors based on coarse-grained aspect vectors and fine-grained aspect vectors simultaneously. The resulting model can therefore learn better aspect representations. Experimental results on two datasets from different domains show that our proposed model can outperform a few baselines in terms of aspect identification and topic coherence of the extracted aspect terms.
Introduction
Online reviews are useful sources for evaluating entity aspects. Identifying aspects accurately from reviews is crucial for downstream tasks such as aspect-based sentiment analysis and summarization. Given a collection of reviews from the same domain, aspect identification aims to discover different clusters of aspects (aspect categories), each cluster associated with a set of aspect terms or a distribution over such terms. For example, in the review sentence, “my salmon was completely raw”, the aspect term is “salmon”, which belongs to the aspect category “food”. The tasks of our model are: (1) extracting all representative aspect terms from the review corpus, (2) clustering aspect terms with similar meanings into corresponding categories, and each category represents a single aspect, e.g. clustering “beef”, “pork”, and “salmon” into one aspect category “food”, (3) clustering review sentences into corresponding aspect categories, e.g. the above sentence is clustered to “food”.
Previous solutions for aspect identification can be summarized into three methods: rule-based, supervised, and unsupervised method. The rule-based method is usually based on syntactic rules, which are not suitable for online reviews that lack syntactic rules. Supervised methods need data annotation and domain adaptation, which is also not a good choice for fast aspect identification. Unsupervised methods are usually based on topic models such as Latent Dirichlet Allocation (LDA) [1]. Here each aspect is modeled as a topic, which is essentially a multinomial distribution over words, and review sentences are modeled as mixtures of these topics. And Embedded Topic Model (ETM) [3], a generative model of documents that marries traditional topic models with word embeddings, but still uses Bag of Words document representations as model input. Some special topic models and their extensions have been proposed for aspect identification [14, 28]. Despite topic models have achieved success, these models are limited to formal and well-edited documents, such as news reports and scientific articles because they rely on document-level word collocations. When we process short texts, such as online reviews, the performance of these models will likely be inevitably compromised, due to the severe data sparsity issue.
It is worth considering how to use the powerful feature representation ability of neural networks for aspect identification. Compared with the traditional multinomial word distribution-based language models, neural language models constructed in a continuous space may better handle low-frequency words in reviews and address the data sparsity problem. To this end, some neural topic models [6, 27] have been proposed and shown to produce more coherent topics than earlier models such as LDA. In Aspect Based Autoencoder model (ABAE), He et al. exploit the word vectors pretrained on the dataset to acquire the distribution of word co-occurrences, and predict aspect probabilities of a sentence to reconstruct a sentence vector as a combination of multiple aspect vectors (i.e. aspect matrix). Each sentence is associated with more than one aspect, so its aspect vector (i.e. the vector representing aspect, we call it sentence vector simply in this paper) can be reconstructed by multiple aspect vectors.
ABAE uses a linear layer to transform a sentence vector to a low dimensional vector of aspect probabilities, which needs to train extra parameters. In fact, the aspect probabilities of a sentence are related to the distances between its sentence vector and these aspect vectors. This relation is not employed in ABAE. Different from this, our model calculates these aspect probabilities directly, by applying the distances to the fuzzy k-means membership function. Besides, ABAE fixes the number of aspect categories, i.e. the number of clustering, which means the reconstruction is only based on one aspect matrix. We notice that if the number of aspect categories changes, the clustered aspect categories, and aspect terms changes simultaneously. A small clustering number can get coarse-grained aspects (each aspect is a large cluster), which correspond to some relatively abstract topics, while a big clustering number can get fine-grained aspects (each aspect is a smaller cluster), which correspond to some relatively specific topics. Motivated by such an observation, we consider that a sentence vector can be reconstructed by two different aspect matrixes: one for coarse-grained aspect and the other for fine-grained aspect. By two reconstructions for sentences, the model can learn more robust and reasonable aspect representations.
We summarize the main contributions as follows: We propose an unsupervised aspect identification model based on aspect vector reconstruction with the fuzzy k-means membership function. We propose a multi-grained aspect vector learning mode in our model to get better aspect representations, including the coarse-grained aspect vector and the fine-grained aspect vector. We tested our model on two datasets of restaurant and beer domains. Compared with other aspect identification models, our model had excellent performance in sentence-level aspect identification and discovered more meaningful and coherent aspects.
The rest of the paper is organized as follows. Section 2 lists the related work. Section 3 describes the proposed model for aspect identification. The experiments on datasets are conducted in Section 4 and their results are discussed in detail. The brief conclusions and future work are given in Section 5.
Related work
Early studies of aspect identification mostly focus on the design of hand-crafted rules or features [15, 18]. Recently, the proposal of neural models enables automatic representation learning, treating it as a supervised sequential labeling task [11, 25]. These approaches can achieve better performances than their prior works. Besides, the Non-iterative supervised learning model [8] also provides a solution for this task. But these supervised models, rely on manually annotated data, thus restricted their scaling ability for new domains or language.
Our work is mainly in the line with unsupervised aspect extraction research. Unsupervised methods are mainly based on probabilistic topic models, such as LDA, pLSA, infinite replicated Softmax model (iRSM) [7], bi-Directional Recurrent Attentional Topic Model (bi-RATM) [10] and Embedded Topic Model(ETM) [3]. They are often used to extract topics from text collections and learn latent document representations. Though they have been shown to be powerful in modeling large text corpora, these topic modeling still remains a drawback in the sparse-data setting, especially for cases where word co-occurrence data is insufficient. This is because traditional topic models do not directly encode word co-occurrence statistics. Assuming that each word is generated independently, they implicitly capture such patterns by modeling word generation at the document level. Besides, topic models need to estimate the topic distribution of each document. Online reviews tend to be short, making it more difficult to estimate the distribution of themes. So, they do not work well on short text or a corpus of few documents.
To deal with such an issue, many previous efforts incorporate external representations, such as word embeddings [9, 17] and knowledge pretrained on large-scale high-quality resources [4, 5]. In another line of the research, some work focuses on how to enrich the context of short messages, such as Biterm topic model (BTM) [26]. It extends a message into a biterm set with all combinations of any two distinct words appearing in the message.
Recently, neural topic models have been shown better performance than topic models [6, 27]. In ABAE, He et al. proposed to predict aspect probabilities of a sentence and then use this probability to reconstruct an embedding for the sentence as a combination of multiple aspect embeddings. The aspect embeddings are initialized by clustering the word embeddings using the k-means algorithm. ABAE is trained by minimizing the sentence reconstruction error. Vargas et al. [20] propose SUAEx which is a deep neural network approach for unsupervised aspect extraction, which relies on the similarity of word-embedding.
Inspired by neural topic models, the principle of our model is to use two different aspect matrixes to reconstruct each sentence. In the process of reconstruction, we directly use the membership function of fuzzy k-means to calculate the reconstruction weights. We finally learn two reasonable aspect matrices and all sentence aspect vectors. Here each row of the aspect matrix is equivalent to the centroid of each aspect cluster in the vector space. Through reconstruction, our model completes aspect clustering and sentence clustering.
Model description
We describe our model in this section. Our goal is to learn two sets of aspect vectors (aspect matrix), in which one set is coarse-grained aspect and the other is fine-grained aspect. We infer the aspect categories and identify aspect terms mainly by the coarse-grained vectors, infer some extra aspects by the fine-grained vectors. Through two reconstructions, we can get a better and more reasonable aspect representation. The meaning of these aspects can be inferred by words whose vectors are nearest to aspect vectors in the embedding space. In the first place, we pretrain word embeddings of the dataset by Skipgram to map words that often co-occur in a context to points that are close by in the embedding space [12]. Skipgram takes as its input a large corpus of text and produces a vector space, typically of several hundred dimensions, with each unique. The word vectors correspond to the rows of a word embedding matrix
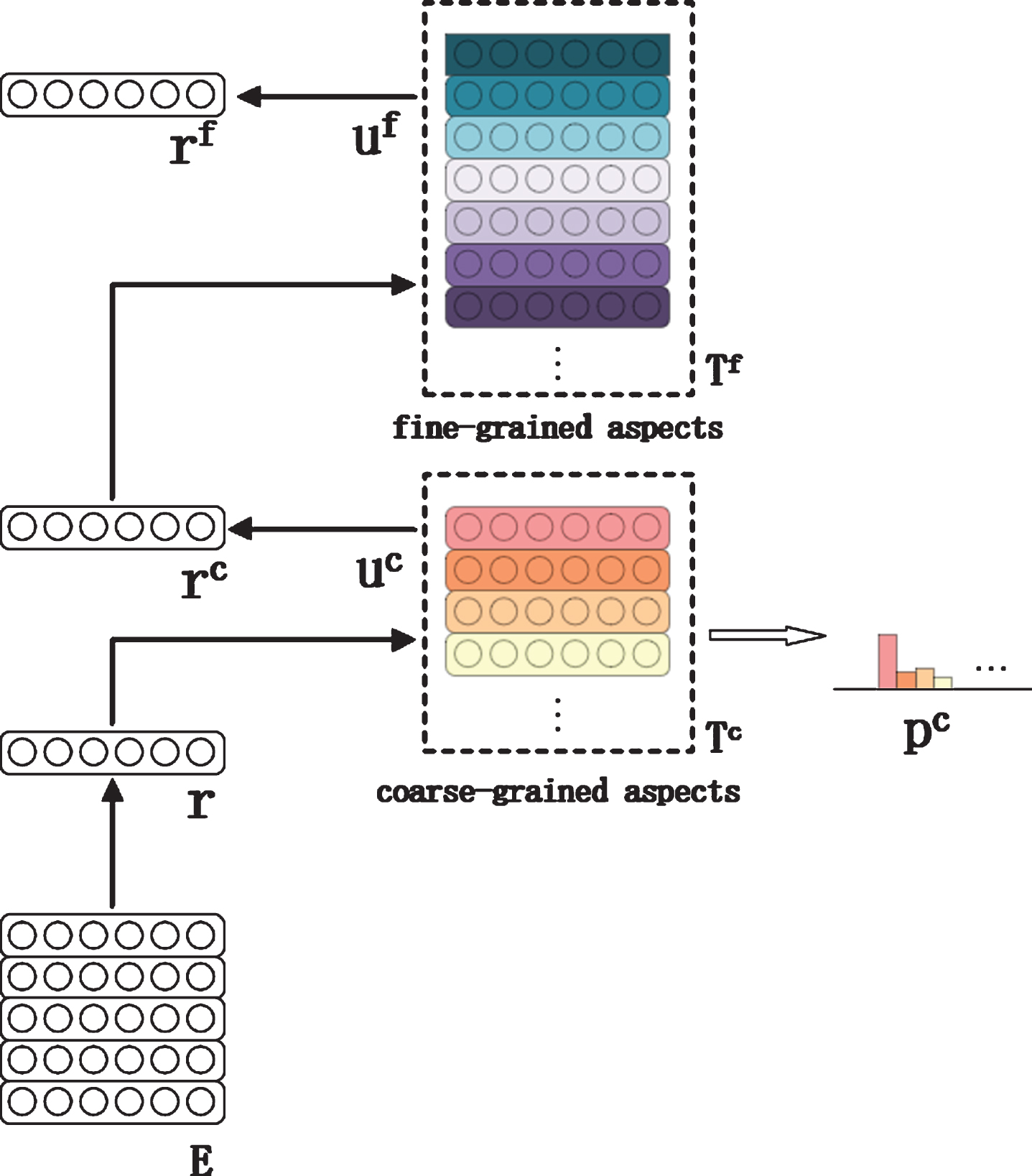
The structure of our model.
The specific flow of the model is as follows:
Let
Where M
If there are L
c
coarse-grained aspects for a collection of reviews, then a review sentence can be reconstructed by these aspect vectors. Let
If there are L
f
fine-grained aspects for a collection of reviews, then a review sentence can be reconstructed by these aspect vectors. Similar to the previous reconstruction of coarse-grained aspect vectors, let
According to the above steps, we have three representations for a sentence, i.e. r, r
c
and r
f
. If in the dataset, the coarse-grained aspect vectors and fine-grained aspect vectors are reasonable enough, then the reconstructed aspect vector of a sentence should be reasonable, which means r, r
c
and r
f
should be similar. Our model is trained to minimize the reconstruction error. We adopted the contrastive max-margin objective function used in previous work [6]. For each input sentence, we randomly sample num sentences from the dataset as negative samples. We represent each negative sample as n
i
which is computed by averaging its word embeddings. Our objective is to make r
c
and r
f
similar to r while different from those negative samples. Therefore, the objective J
j
(θ) of the j sentence in the dataset is formulated as a hinge loss that maximizes the inner product between r
c
, r
f
and r, and simultaneously minimize the inner product between r
c
, r
f
and the negative samples. We calculate the reconstruction loss of a sentence by the following equation:
Where λ is a hyperparameter that controls the weight of the reconstruction by fine-grained aspect vectors. num is the number of negative samples. We sum J
j
(θ) of each sentence in the dataset to get the total loss J (θ) of the reconstruction. What’s more, the aspect matrix
Where β is a hyperparameter that controls the weight of the regularization term. The corresponding learning objective is to minimize L (θ) by optimizing parameters {
After training, the sentences in the model are clustered, and vectors in
Datasets
We evaluate our method on two datasets 1 from restaurant and beer domain respectively. The restaurant dataset contains over 50,000 training reviews and a subset of 3,400 sentences with manually labeled aspects. There are six manually defined aspect labels: Food, Staff, Ambience, Price, Anecdotes, and Miscellaneous. For the evaluation of aspect identification, we use three labels of them, following the work [6]. The number of training samples in the beer dataset is almost 30 times that of the restaurant. There are 6,301 sentences manually defined five aspect labels: Feel, Look, Smell, Taste, and Overall. For the evaluation of aspect identification, we use the sentences annotated with Feel, Look, Smell, Taste labels. The detailed statistics of the datasets are summarized in Table 1.
Dataset description
Dataset description
Review corpora are preprocessed by removing punctuation symbols, stop words and words appearing less than 10 times. We applied pre-trained word2vec embedding for initialization of the word embedding
We experimented with the different number of aspects and set the number of the coarse-grain aspects to 14 and the fine-grained aspects to 50. The coarse-grained number is set to 14 for comparison with the baseline models. We manually labeled each coarse-grained aspect to one of the gold-standard aspects (refer to Table 1) according to its representative aspect terms, in accordance with the previous work [2, 29]. Representative terms of an aspect are those words whose vectors are most similar to the corresponding aspect vector.
Baseline methods
To validate the performance of our model, we compare it with some baselines: LocLDA [2]: This is a standard implementation of LDA, in which each sentence is treated as a separate document. We set Dirichlet priors α=0.05 and β=0.1, and run 1,000 iterations of Gibbs sampling. k-means: We adopt the k-means algorithm for clustering the pretrained word embeddings and use the centroids as aspect vectors directly. In the experiment of this paper, different centroids of the model are iterated 10 times. SAS [14]: It is a hybrid topic model that jointly discovers both aspects and aspect-specific opinions. This model has been shown to be competitive among topic models in discovering meaningful aspects. For SAS, we set α=50/K and β=0.1. BTM [26]: This is a biterm topic model that is specially designed for short texts. The major advantage of BTM over conventional LDA models is that it alleviates the problem of data sparsity in short texts by directly modeling the generation of unordered word-pair co-occurrences (biterms) over the corpus. For BTM, we set α=50/K and β=0.1. SERBM [21]: a restricted Boltzmann Machine (RBM) that learns topic distributions, and assigns individual words to these distributions. By doing so, it learns to assign words to aspects. For the experimental setup, we use 10 hidden units. ABAE [6]: This is an unsupervised neural topic model, which has been shown to produce more coherent topics than earlier models such as LDA. We fix the word embedding matrix E and optimize other parameters using Adam with a learning rate of 0.001 for 15 epochs and batch size of 50. SUAEx [20]: This is an unsupervised aspect extraction model based on the similarity of word-embeddings. In the experiment, we use word 200 embedding dimension, 50 batchsize, and 15 training epochs. ETM [3]: Embedded Topic Model, a generative model of documents that marries traditional topic models with word embeddings. In the experiment, the learning rate of the model was set as 0.002, the iteration was 15 times, and Adam was used as the optimizer.
Experimental result
Inferred aspects and extracted representative aspect terms
Previous literature has demonstrated the superiority of ABAE in aspect inference. In this paper, we compare the aspects learned from the ABAE model and our model, shown in Table 2. In Table 2, the left is the gold-standard aspect labels, and the right is representative aspect terms for each inferred aspect. From Table 2, we can see that in fourteen aspects, three aspect vectors can be inferred as the theme of Food by our model, while two by ABAE; two aspect vectors can be inferred as Staff by our model, while only one by ABAE. These three aspect labels are easy to infer manually and are the most important aspects for restaurant domain. More inferred aspects mean that we can get more corresponding aspect terms. For example, in “Food” aspect inferred by our model, Aspect 1 includes the aspect terms about dessert, Aspect 2 includes the aspect terms about the main course, and Aspect 3 includes the aspect terms about seafood. Similar results can be seen on the beer dataset. The topic consistency of these obtained aspect terms is illustrated in the following section.
The inferred aspects and representative aspect terms for restaurant reviews
The inferred aspects and representative aspect terms for restaurant reviews
We also evaluated our models with topic coherence, which is a metric measuring aspect quality based on the co-occurrence of words [13]. It is defined as:
Where V(t) contains the M most probable words in aspect t.
In our experiment, the number of aspects K is set to 14. Figures 2 and 3 show the average topic coherence COH AVR calculated for different models in the Restaurant domain and the Beer domain, respectively. Conventional LDA models do not directly encode word co-occurrence statistics, they implicitly capture such patterns by modeling word generation from the document level, assuming that each word is generated independently. So their performance is significantly lower than our model. All topics based on our model can get better performance than others. Especially for the top 30, 40, and 50 terms, our model obtains obvious improvement than other models. It proves that aspects discovered by our models are more coherent than those discovered by the competitors.
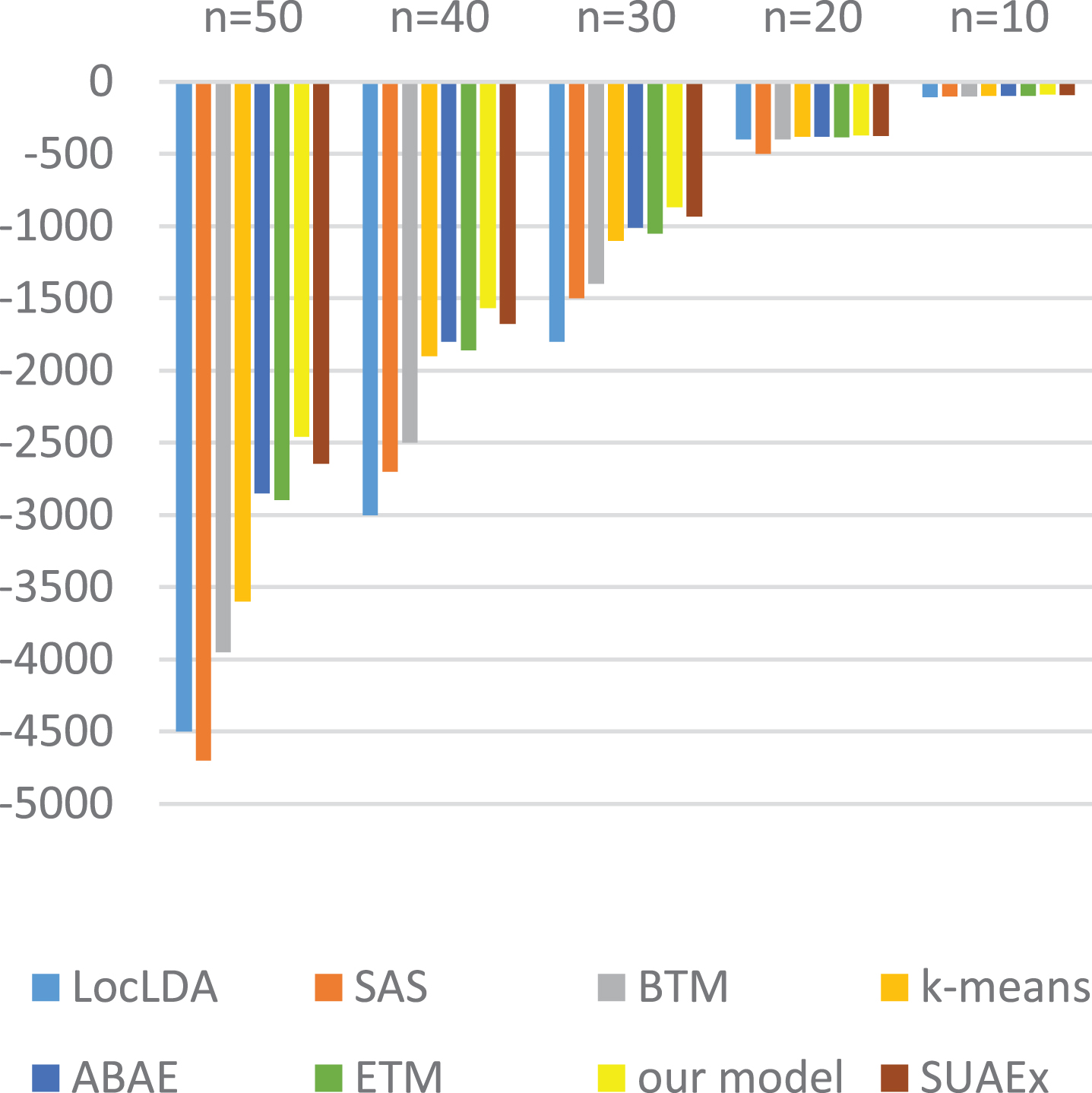
Average topic coherence score versus number of top n terms for the restaurant domain.
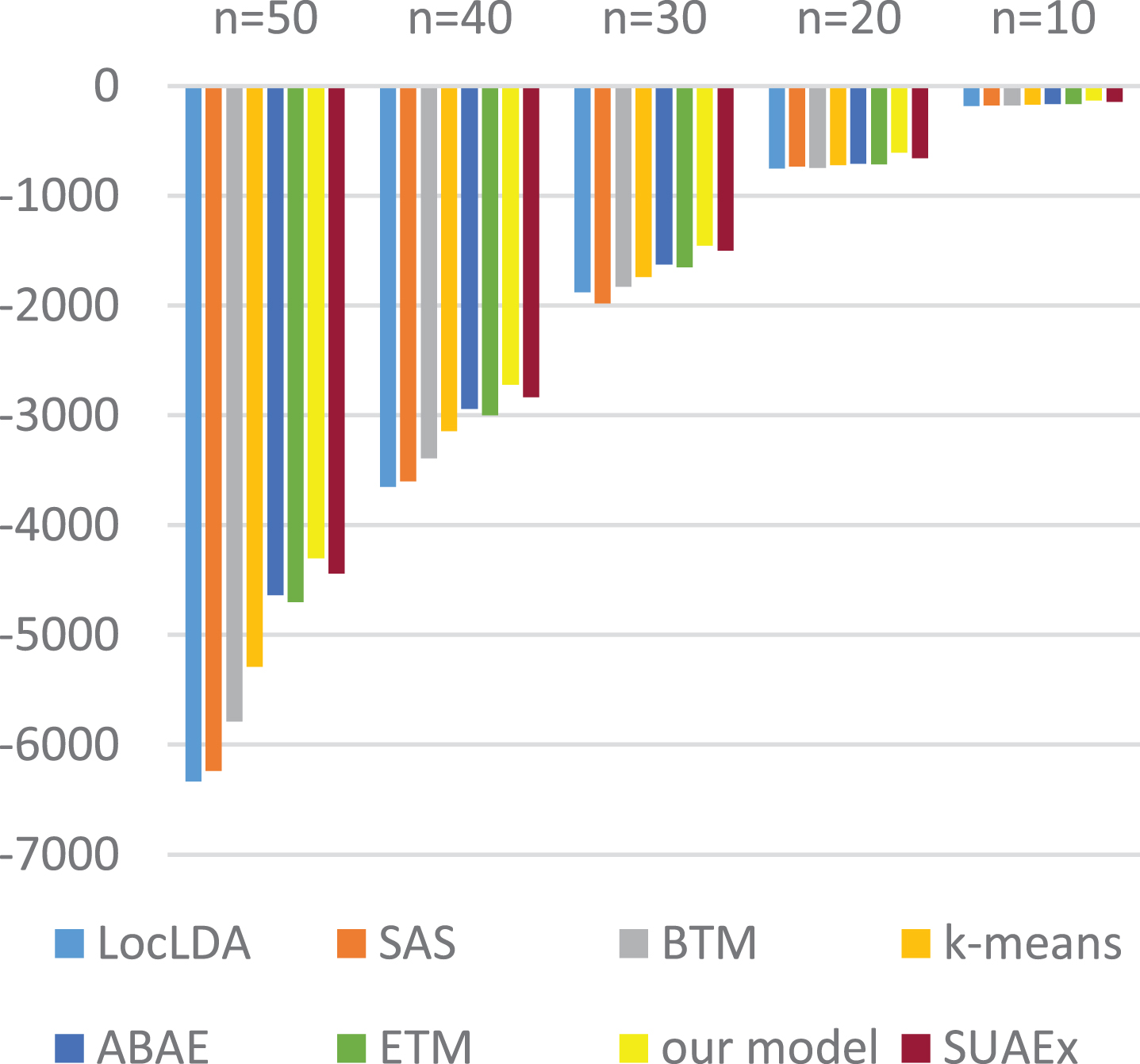
Average topic coherence score versus number of top n terms for the beer domain.
We calculate p
c
for each test sentence by Equation (6), and assign the sentence an inferred aspect label according to the highest weight. Then we assign the gold-standard label to the sentence according to the above mapping between inferred aspects and gold-standard labels, shown in Table 1. For example, for the sentence “my salmon was completely raw”, if
Sentence level aspect identification results of different models on the restaurant domain
Sentence level aspect identification results of different models on the restaurant domain
We can see that our model outperforms all other competitors. As all sentences are from the same domain, it is uneasy to effectively discover clear aspects and cluster sentences by using co-occurrence statistics. So traditional topic models and ETM perform poorly, especially for Staff and Ambience. The Recall score of our model for Food improves by 12.9% compared with ABAE, which accord with the result in Table 2. The macro-average F1 of our model is 80.9%, which is 3.4% higher than ABAE, for that our model learns a more robust and reasonable aspect representation after two reconstructions of the sentence. The macro-average F1 of our model which is 3.1% higher than that of SUAEx. We think that SUAEx considers more words for comprehensive expression, which may introduce more noise and damage the performance.
We further compare the performance of our model and other models on the beer dataset. The results are shown in Table 4.
Sentence level aspect identification results of different models on the beer domain
In the Beer domain, we combined Taste and Smell to form the single aspect “Taste+Smell”, because “Taste” and “Smell” aspects are so similar that many words can be used to describe both aspects. We can see F1 score in every aspect of our model is better than all the methods. All of the models scored slightly lower in F1, and the analysis found that most of the sentences in the unrecognized Feel aspect were ambiguous, describing something close to the Taste+Smell aspect, such as “Way Bitter perhaps bit Thin”, labeled “Feel”, but the model classifies this to the “Taste+Smell” aspect based on “bitter”, because “bitter” is also closely related to the Taste+Smell aspect. Such as “low medium Body”, labeled “feel”, but the model has a hard time judging the aspect of sentence based on the information provided by the sentence, and these two similar descriptions cause all the models to have a slightly lower F1 score for feel aspect. The macro-average F1 of our model is 86.8%, which is 3.6% higher than that of SUAEx, because the multi-grained reconstruct makes our model get more accurate aspect representation. The results show that our model has a better ability to identify aspects than all the base models.
We conducted an ablation study on our model to analyze the role of membership function and fine-grained aspects. Model 1 refers to that we only reconstruct sentence vectors with coarse-grained aspect vectors and use the following equation to calculate u
c
, instead of the Equation (5).
Model 2 refers to that in our model structure, we only use the coarse-grained aspect vectors to reconstruct sentences, without the fine-grained aspect vectors. The other settings of the two ablation models are consistent with our full model. We compared the performance of ablation models for sentence-level aspect identification on restaurant domain. The results are shown in Table 5.
Sentence level aspect identification results on the restaurant domain
We mainly compare F1 score for different models and make the following observations from Table 5: (1) Generally speaking, our Model 1 has little difference from the performance of ABAE, which shows that there is hardly any loss of performance by directly using the distance between the original sentence vector and the aspect vectors to reconstruct the sentence vector, without using the dense layer of ABAE. Specifically, compared with ABAE, our model 1 increases 1% for Food, 0.7% for Ambience, but decreases 1.3% for Staff. Food has 887 test samples, 2.5 and 3.5 times the other two aspects. Therefore, the performance improvement of Food has a greater impact on the overall performance. (2) Compared with Model 1, Model 2 has a further performance improvement, which proves the rationality of using the membership function of equation (5). By using the membership function to calculate the weights and reconstruct sentence vectors, the overall performance of Model 2 is about 2% higher than that of ABAE. (3) Fine-grained aspect vectors play a very important role. Adding this module, the performance of our full model significantly improves for the three aspects. This proves that the employment of two different granularity aspects can improve the rationality of sentence representation and thus better aspect identification. Besides, in the previous experiments, we have seen that our full model can learn consistent aspect terms. It shows that the aspect representation is more reasonable through two reconstructions.
The above experiment shows that the performance of our model is improved by adding the fine-grained aspect vectors. We infer the aspect categories and identify aspect terms mainly by the coarse-grained vectors. In fact, we also can infer some extra aspects by the fine-grained vectors. Table 6 lists seven fine-grained aspects inferred by the fine-grained aspect vectors for the restaurant domain. All these aspects belong to Food, and each aspect has its specific description of Food. Except for the topic coherence scores of the third and seventh aspects are little, the rest aspects have a good performance on topic coherence.
The inferred aspects and representative aspect terms using fine-grained aspect vectors for restaurant reviews
The inferred aspects and representative aspect terms using fine-grained aspect vectors for restaurant reviews
We propose a new aspect identification model, which combines two aspect matrixes with different granularity to reconstruct sentence representation. Our experimental results show that our model not only learns higher quality aspects but also more effectively captures the aspects of reviews than previous methods, meanwhile produces more coherent topics. The macro-average F1 values of our model for sentence-level aspect identification are 80.9% and 86.8% respectively on Restaurant and Beer datasets, which have obvious improvement compared with the other state-of-the art models. But in we need to manually infer the aspect category for each aspect vector, which limits the application of the model. In the future, we will explore investigate our model in a broader range of datasets.