
Abstract
U-Net is a commonly used deep learning model for mammogram segmentation. Despite outstanding overall performance in segmenting, U-Net still faces from two aspects of challenges: (1) the skip-connections in U-Net have limitations, which may not be able to effectively extract multi-scale features for breast masses with diverse shapes and sizes. (2) U-Net only merges low-level spatial information and high-level semantic information through concatenating, which neglects interdependencies between channels. To address these two problems, we propose the U-shape adaptive scale network (ASU-Net), which contains two modules: adaptive scale module (ASM) and feature refinement module (FRM). In each level of skip-connections, ASM is used to adaptively adjust the receptive fields according to the different scales of the mass, which makes the network adaptively capture multi-scale features. Besides, FRM is employed to allows the decoder to capture channel-wise dependencies, which make the network can selectively emphasize the feature representation of useful channels. Two commonly used mammogram databases including the DDSM-BCRP database and the INbreast database are used to evaluate the segmentation performance of ASU-Net. Finally, ASU-Net obtains the Dice Index (DI) of 91.41% and 93.55% in the DDSM-BCRP database and the INbreast database, respectively.
Keywords
Introduction
Globally, breast cancer is the most common cancer among women, and it is also the main cause of female death. According to the statistics [10], there were 2.09 million breast cancer incidents and 630,000 deaths due to breast cancer worldwide in 2018. Thus, Breast cancer has become a major public health problem in current society. Currently, reducing breast cancer mortality depends on early detection and diagnosis [35].
Participating in regular high-quality mammography screening is one of the best ways to reduce the risk of premature death from breast cancer [25]. One of the main symptoms of breast cancer is breast masses [2]. Mammography is one of the imaging methods that has been proven to reduce breast cancer mortality [7]. It can present smaller breast masses than possible when diagnosed by clinical breasts or detected by patients. Specifically, the median size of the masses observed by mammography is 1.0–1.5 cm, while the median size of malignant masses detected by autologous or radiologists is 2.0–2.5 cm [4]. Consequently, early detection by mammography has a significant survival benefit [45].
Normally, clinical experts can determine whether it is a malignant mass by observing the shape of the mass [9]. The characteristics of masses vary from benign to malignant. Benign masses, including cysts, fibroadenoma, and breast hematoma, are usually round or oval, while malignant masses that grow in an abnormal and uncontrolled manner are some rounded, irregular, or sharp peaks. Usually, the malignant mass looks brighter than any surrounding tissue [37]. In other words, the more complex the shape of the mass, the greater the possibility of malignancy. In addition, because the mammographic image could be affected by noise and distortion during the detection, the color of the mammographic image is relatively monotonous and the edges of the breast mass are blurred [42].
In the traditional diagnosis, mass segmentation is usually performed manually. The manually performed procedure has potential advantages, which can be easily adopted by clinical diagnosis. But their quality and efficiency are usually restricted by the following two factors: The manually performed procedure is a long and arduous task. It requires radiologists to spend a lot of time and energy to complete the judgment of the mass. Inevitably, the problem of misjudgment due to fatigue may occur. Therefore, the accuracy of the segmentation results is largely affected by human factors. Even for the same mass with the clear feature, the diagnosis of radiologists with different prior knowledge may be different. [31].
Therefore, clinical experts can use computer-aided detection (CAD) technology to improve the overall accuracy of mass detection, segmentation, and classification. False positives are reduced via an in-depth analysis of visual details in mammograms, which assists radiologists in the early detection of cancer [43]. The identification task is challenging due to the different textures, shapes, sizes, and locations of the masses in the surrounding tissues. Most traditional CAD systems rely on manual identification of breast masses and manual extraction of their features to perform segmentation works [11]. In a few cases, the high similarity between mass and non-mass, benign and malignant breast tissue may affect the segmentation performance of traditional CAD systems based on manual feature extraction [34]. Later, people proposed several methods of segmentation based on the CAD system, such as the semi-automatic segmentation method [19, 33] and the fully automatic segmentation method [14, 50]. Usually, these methods rely heavily on the functions generated by a series of pre-processing and post-processing, which are not only sensitive to subjective operations but also inefficient.
In recent years, with the continuous development of artificial intelligence, some new algorithms based on deep learning can achieve more objective and excellent breast cancer diagnosis performance [8]. Deep learning allows a network model composed of multiple processing layers to learn data representations with multiple levels of abstraction, and it uses backpropagation to guide the network to update its internal parameters. It is very good at discovering complex structures in big data sets, thereby greatly improving the latest level of computer vision. Compared with traditional methods, these new algorithms based on deep learning can directly extract advanced features from the original input, which brings more possibilities for breast cancer diagnosis.
Currently, Convolutional Neural Network (CNN) is considered to be the first robust deep learning method, which successfully adopts a multi-layer structure network. It performs well in image classification tasks, such as: VGGNet [24], GoogLeNet [5], ResNet [23], etc. The CNN model is an end-to-end classification model, which directly inputs the image into the model, and then the image with the classification result be obtained. It does not rely on complex pre-processing and post-processing, but on continuous optimization to update network parameters. In 2015, Jonathan Long et al. proposed a segmentation network for image semantics in an article [21], namely Fully Convolutional Neural Network (FCN). FCN classifies images at the pixel level, introducing deep learning into image semantic segmentation for the first time. With the rapid development of deep learning, more semantic segmentation networks have gradually been designed, such as SegNet [46], PSPNet [15], DeepLab series [27–30], and DANet [17], etc. SegNet [46] is a deep fully convolutional neural network architecture for understanding scenes. SegNet uses a simple encoder-decoder structure and skip-connections to achieve pixel-by-pixel image segmentation. Where the encoder layer and the decoder layer have a one-to-one correspondence. The difference with FCN is that SegNet calculates and saves the maximum pooling indices during the max-pooling process of the encoder. Then, with the help of the maximum pooling indices, nonlinear upsampling is performed on the input in the decoder. This upsampling process does not require learning, but only takes up part of the storage space. Therefore, SegNet is efficient in terms of memory and calculation time during training. Considering that FCN lacks a suitable strategy that can utilize the global contexts, Zhao et al. [15] proposed the Pyramid Scene Analysis Network (PSPNet) including a Pyramid Pooling Module. The Pyramid Pooling Module can provide more contextual information for the semantic segmentation algorithm. This module integrates the features of four different pyramid scales to fuse the contextual information of different regions and provides good global prior knowledge for the network to avoid mis-segmentation. DeepLabV3 [27] is improved based on atrous spatial pyramid pooling (ASPP) proposed by DeepLabV2 [28]. The improved ASPP is composed of BN layers and dilated convolutions with different dilation ratios. They capture multi-scale information in a serial and parallel manner. Besides, DeepLabV3 does not use the DenseCRF post-processing of DeepLabV2. In DeepLabV3+ [30], the encoder-decoder structure is proposed, which regards the ResNet or Xception as the backbone network. ASPP consists of three dilated convolutions with different dilation ratios, a 1 × 1 convolution layer, and an image-level feature. It is used to capture contextual information of different scales. The recently proposed DANet [17] is a dual attention network for scene segmentation works. Fu et al. design the position attention module and channel attention module, which are based on the self-attention mechanism to capture rich contextual dependencies. The position attention module establishes the correlation between similar features regardless of distance. The channel attention module enhances the semantic interdependencies in the channel dimensions. Finally, the outputs of two attention modules are summed to enhance the feature representation of the network.
With the continuous development of deep learning, medical image segmentation which is the branch of image segmentation is also constantly innovating. In recent years, many medical image segmentation networks based on deep learning have also demonstrated outstanding performance. U-Net [41] is a classic fully symmetric fully convolutional network, and it is also one of the earliest networks that use multi-scale features for semantic segmentation. U-Net inherits the idea of FCN. It is mainly composed of the contracting path, expansive path, and skip-connections. The contracting path is a conventional convolutional network, which uses downsampling to extract feature information. The expansive path mainly employs upsampling to combining the low-level texture information of each layer in the contracting path and the high-level semantic information of upsampling in the expansive path to restore the detailed information. The resolution of the output gradually restores to the high-resolution level of the original image. U-Net can effectively integrate low-level texture information and high-level semantic information. Therefore, the network can finally output segmentation results with spatial information and semantic information. Considering that U-Net has the uncertainty of the optimal network depth and the limitation of skip-connections, U-Net++ [52] embeds a built-in ensemble of U-Net with variable depth in the skip-connections, which share the same encoder. U-Net only allows the fusion of encoders and decoders of the same level is broken by adjusting the skip-connection structure. The flexibility of its feature fusion is increased. Besides, the model pruning strategy is designed to make full use of the features at different levels and improve the variability of the network during testing. At the same time, the deep supervision strategy is employed to supervise the output of the network to provide a higher segmentation performance for the network. Recently, Wang et al. proposed the structure of Non-local U-Net [51] based on the self-attention mechanism for biomedical image segmentation. Non-local U-Nets proposes a global aggregation block to tackle the limitations of the single-use of local operators. This module allows the network to fuse the global information in feature maps of any size during upsampling or downsampling, which improves the efficiency and effectiveness of segmentation.
In this work, a U-shape adaptive scale network (ASU-Net) for mass segmentation is proposed. Our main contributions include adaptive scale module (ASM) and feature refinement module (FRM). Generally, the deeper the encoder, the smaller the resolution of the feature map, and the size of the mass will change accordingly. Therefore, the feature map generated by the middle layer contains a large amount of multi-scale contextual information. In the multi-level feature level of the encoder, we consider that only adding a conventional multi-scale extraction module cannot effectively utilize multi-scale information. Therefore, a novel ASM is developed in this work. ASM is designed for the challenge which allows the network to selectively extract and effectively use the multi-scale feature information of the masses in the feature maps of different resolution. Specifically, with the softmax function, ASM learns three related weights of three scale convolutions and then redistributes these weights, thereby dynamically adjusting the appropriate receptive fields. Besides, in the decoder of U-Net, if only the concatenation is employed to fuse low-level spatial information and high-level semantic information, it may not be sufficient to represent the feature of the mass. As a result, we propose a novel feature refinement module (FRM). FRM fuses low-level spatial information with high-level semantic information, and then adaptively selects the features of the two branches. Specifically, FRM calculates the weight vector for the feature information after connection and redistributes the weights of high-level and low-level features, which adaptively enhances the useful feature channel representation and suppresses the interference of irrelevant noise. As a result, the decoder retains more important semantic information via FRM.
In summary, the main contributions in this article are the following three points: We propose a novel ASM to adaptively select the appropriate scale of convolution kernel to extract feature information based on the semantic perception of the input features. In addition, the multi-scale information is aggregated in a non-linear manner, which allows the network to obtain more powerful multi-scale adaptability. We propose a novel FRM to construct the channel-wise dependencies in a computationally efficient manner, so as to guide the discriminative fusion of low-level and high-level features, which allows the network to adaptively enhance the useful feature channel representation and suppress the interference of irrelevant noise for a more refined segmentation. We propose a novel ASU-Net for mass segmentation in mammograms, which effectively improves the false positive problem of mass segmentation. ASU-Net achieves a DI of 91.41% in the DDSM-BCRP database and a DI of 93.55% in the INbreast database.
The rest of the paper is organized as the following. Section 2 elaborates the relevant literature on the mass segmentation of mammograms. Section 3 describes the proposed method. Section 4 introduces the experimental process, results, and analysis. The conclusion is shown in Section 5.
Related work
In recent years, with the development of medical image semantic segmentation based on deep learning, the study of breast mass segmentation has had a positive impact. Dhungel et al. developed a series of CNN-based breast mass segmentation algorithms [38–40]. The first article [38] proposes a method for breast mass segmentation in mammograms. The training process of this method follows the structured support vector machine (SSVM). The cutting plane algorithm is employed to optimize the learning process. Besides, this method combines three potential functions to improve segmentation accuracy, which includes latent functions based on the proposed Deep Belief Network (DBN). A series of experiments in this article has shown that the application of structured learning and deep learning in breast mass segmentation can produce competitive results. However, this method relies heavily on pre-processing that can improve the contrast of the input image. The second method [39] explores the statistical learning method using Conditional Random Field (CRF) and combines a variety of potential functions through deep learning, Gaussian Mixture Model (GMM), and shape priors. Finally, a statistical model is developed. Where the innovation is the use of tree re-weighted belief propagation (TRW) with the supervised learning features for reasoning, and it also proves the applicability of TRW to the work of breast mass segmentation. Using these inference methods and potential functions can indeed improve segmentation performance and efficiency. However, the test results still need to use pre-processing to improve the segmentation results. In addition to the Gaussian Mixture Model (GMM) and the prior shape of the shape between the image and the segmentation plane, their last work [40] proposes to use CNN and DBN as deep learning models to perform mammograms segmentation of breast masses. Then, the segmentation results of the two are used as input into the structure prediction model. This model uses CRF and SSVM as the loss minimization parameter learning algorithm to regularize the deep learning model. The structure prediction model outputs the final segmentation results via inference and training. This article has been proved that CRF has greater advantages in reasoning and training speed of these two structured learning methods. However, these two types of post-processing not only fail to train but also increase the number of model parameters. Besides, the test results show that image pre-processing is very important, and the improvement of the DI still requires image pre-processing. Zhu et al. [48] proposed a semantic segmentation model based on FCN and integrated the position prior of the mass into the model. Then, CRF is used for structured learning of the output of the model. This method also combines adversarial training to provide a powerful regularization function for the model to reduce overfitting when processing small-scale training sets. However, the algorithm relies on cumbersome pre-processing and post-processing to a large extent, which makes the model lack robustness. Recently, CRU-Net [13] proposed by Li et al. integrates the residual learning function into U-Net which employs explicitly mapping layers with residuals to alleviate the disappearance and explosion of network gradients. Besides, CRF is employed to combine label consistency with similar pixels, which uses the advantages of probabilistic graphic modeling to achieve a more refined segmentation. However, CRF has a high computational cost, and the use of CRF increases the complexity of the network.
Method
Adaptive scale module (ASM)
The encoder-decoder structure of U-Net can combine shallow spatial information and deep semantic information using skip-connections. In the lower stage of the encoder, U-Net simultaneously captures the fine spatial information and insufficient semantic information of the feature. Because the receptive field of the network is small, the encoder obtains more spatial information. As the number of network layers deepens, the network gradually has a larger receptive field. The network obtains more high-level semantic information, which can provide the position of the segmentation target in the entire image and reflect the relationship between the semantic contexts. With skip-connections, the network can fuse low-level spatial information with high-level contextual information to obtained high-resolution feature representations with high-level semantic features.
Because of the different sizes and shapes of the masses, breast masses usually show multi-scale features. Besides, as the network depth increases, feature representations with different spatial resolutions will be generated after each downsampling, and the scale of the corresponding segmentation target will also change accordingly. However, directly fusing the low-level spatial features and the high-level semantic features, the multi-scale contextual information will be ignored. Inspired by the multi-level strategy literature [6], one adopts a multi-level feature extraction strategy to capture the low-level texture information better. Especially, the edge information of the masses is critical, which makes the mass segmentation more accurate.
Therefore, one can embed conventional multi-scale feature extraction modules, such as ASPP, into different feature levels to extract multi-scale information of feature maps with different resolutions. However, the spatial resolution of feature maps produced by multi-feature levels is different, so the network has different requirements for the size of the convolution kernel used to extract features. Nevertheless, ASPP does not adjust the size of the convolution kernel according to the scale information of the actual input. Specifically, the contribution value of each convolution kernel in ASPP is equal, which makes the network unable to capture more discriminating feature information. For example, when using a relatively larger-scale convolution kernel to sample feature maps with smaller masses, because of ASPP lack of adaptability to select a receptive field with a reasonable scale, useless information may be introduced into the feature map to interfere with the segmentation results. Furthermore, using linear fusion methods, such as concatenation and add strategy, to aggregate multi-scale information in different branches may not be sufficient to provide the network with strong multi-scale adaptability [49].
Motivated by the above problems, we design an adaptive scale module (ASM). The structure is shown in Fig. 1. Unlike U-Net, ASM aims to select a convolution kernel of a suitable scale for convolution according to the scale of masses in different resolutions feature maps, which extracts features information of different scales in a more effective manner. In addition, the multi-scale information is aggregated in a non-linear manner. ASM be embedded into each level of skip-connections in ASU-Net, which is employed to aggregate multi-scale features in a non-linear manner and improve the segmentation performance. ASM includes Multi-scale Feature Selection Branch and Global Feature Extraction Branch.
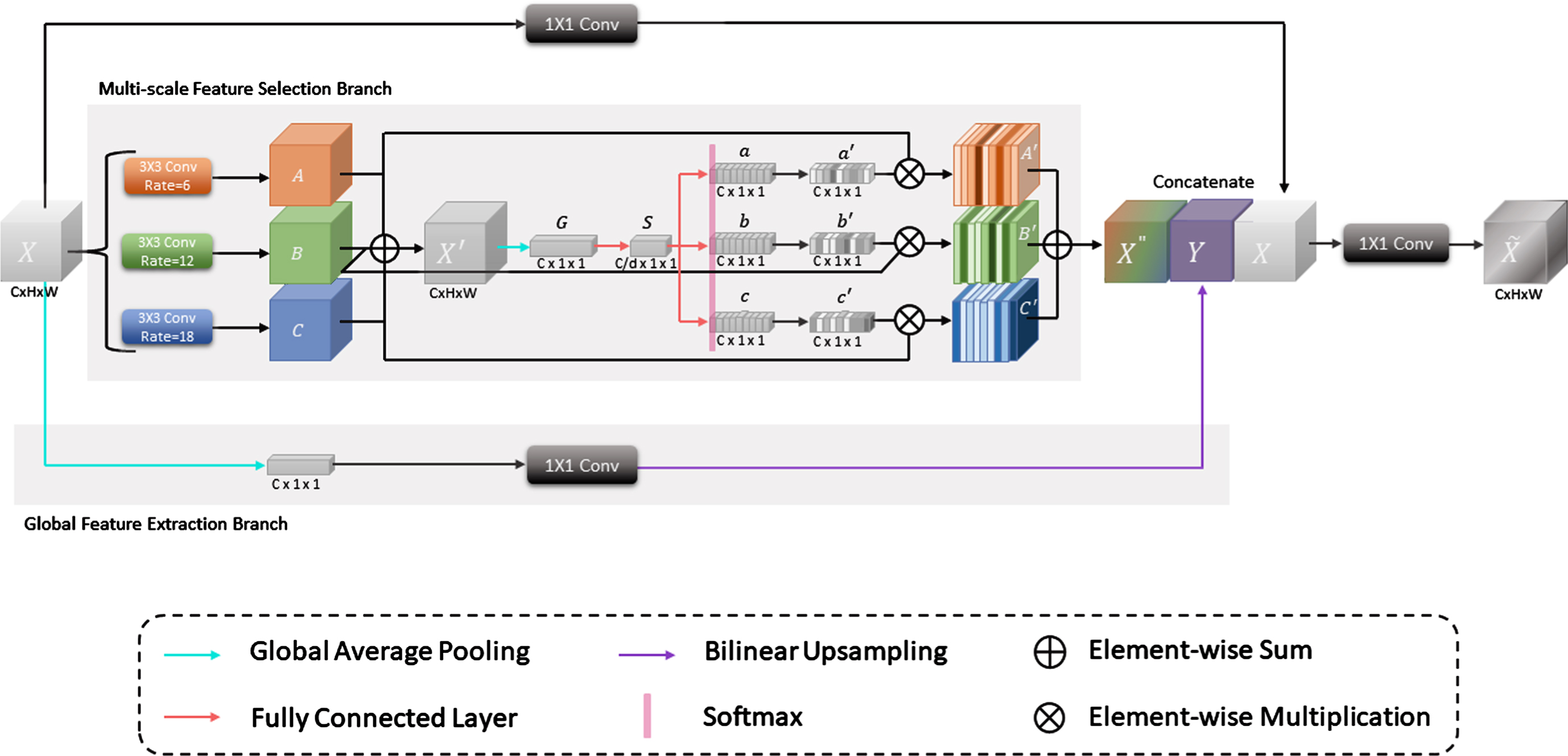
Adaptive scale module (ASM) contains Multi-scale Feature Selection Branch and Global Feature Extraction Branch.
We use three 3 × 3 kernels with different dilation ratios to convolve the input X ∈ RC×H×W. The dilation ratios are set to 6, 12, 18 [27, 30]. Through three different convolution operations
Then X′ obtains the global information G ∈ RC×1×1 of the feature map via the global average pooling layer. Specifically, the spatial dimension H × W of the C channels in the feature map is compressed to 1 × 1. Then, let it enter a fully connected layer to prepare for the guidance of adaptive selection. The dimensionality is reducted, in order to reduce the parameter overhead. The compressed feature S ∈ RC/d×1×1 is generated, where hyperparameter d is the reduction ratio. S gathers a lot of feature information with fewer channels. This not only reduces the number of network parameters but also allows the network to perform data training and feature extraction more intuitively and effectively. In all the experiments we conducted, d is set to 16 [18]. For a detailed discussion of the value of d, see section 4.3.3.
Next, the feature S guides the subsequent process of accurately and adaptively selecting the size of the convolution kernel. Specifically, the feature S generates a, b, and c ∈RC×1×1 respectively via three fully connected layers in parallel. Where a, b, and c corresponds to three receptive filed sizes in this feature level. To achieve this goal, the softmax function is employed to calculate three related weights of a, b, and c and generates feature vectors a′, b′, and c′ with spatial attention weights, which represent the soft attention vectors of A, B, and C, respectively. Then, these three soft attention vectors are used to dynamically adjust the appropriate receptive field. Their formulas are shown in Equations (2), (3) and (4):
Then a′, b′ and c′ are weighted with A, B, and C respectively to obtain A′, B′, and C′. Finally, the weighted features are added pixel by pixel for fusion, and the feature map X″ after adaptive scale selection is generated. It can be expressed as Equation (5):
Where F GAP denotes a global average pooling layer, W denotes a 1 × 1 convolutional layer, and η denotes the bilinear interpolation.
In the ASM, the Multi-scale Feature Selection Branch and the Global Feature Extraction Branch are parallel structures. The results obtained via two branches are concatenated with the input X to enhance the global contextual representation of the input X. The overall process can be summarized as Equations (7), (8) and (9):
Where B
s
(X) denotes the process that the input X obtains the feature map X″ ∈ RC×H×W via the Multi-scale Feature Selection Branch, B
e
(X) denotes the process that the input X obtains the feature map Y ∈ RC×H×W via the Global Feature Extraction Branch, and CONCAT[X″, Y, X] denotes the concatenation of X″, Y and the input X to obtain
Finally, a 1 × 1 convolutional layer is employed to restore the channel number of the feature map
Where
In summary, the feature map
In U-Net’s decoder, multiple upsampling is used to gradually restore feature maps containing high-level semantic information to the original resolution. After each upsampling, the low-level features are directly concatenated with the corresponding high-level features in the encoder. Then, two 3 × 3 convolutional layers are employed to learn the fused features. The simple encoder-decoder structure can fuse low-level spatial information with high-level semantic information to achieve segmentation.
However, it may not be enough that using only convolution operations to refine the fusion of two types of features. In feature fusion, we can suppress the channel of useless information and enhance the channel of useful information to achieve the enhancement of feature representation.
Inspired by the channel attention module [18], we design the feature refinement module (FRM) and embedded the FRM into each feature level of the decoder of ASU-Net. The structure of FRM is shown in Fig. 2. Firstly, FRM concatenates the low-level spatial information generated by the encoder with the advanced features generated by the decoder. Then, we use a reweighting mechanism to model the relationship between low-level feature channels with discriminative feature and high-level feature channels with strong semantic consistency in a computationally effective manner. The decoder obtains channel-wise dependence through FRM, adds attention to the selected channel of the feature map, and enhances the representation of useful features while suppressing the representation of useless features which ensure that the network effectively increases the attention to useful feature information.

The structure of the feature refinement module (FRM). The low-level feature map and the high-level feature map are used as input. The channel-wise relationships of the features in the two branches are captured through the FRM, which strengthens the feature representation of the useful channel information.
We think that the features of the two branches are different at the feature representation level. Therefore, after concatenating two branch features, we use a 3 × 3 convolutional layer with BN to refine it. Then, the network captures aggregated global contextual information via a global average pooling layer. At this time, the global feature map X ∈ R2C×1×1 is generated. This process can be explained as Equation (11):
Where the concatenated feature map has a total of 2C channels, M c ∈ R1×H×W denotes the cth element of the feature map M ∈ R2C×H×W obtained after 3 × 3 convolutional layers, F GAP denotes the global average pooling layer, and x c ∈ R1×1×1 denotes the cth element of the global feature map X ∈ R2C×1×1.
The global feature map X passes through two fully connected layers for refining and obtains the feature map S ∈ R2C×1×1. Then, the Sigmoid function is employed to reweight the channels of the feature map S to generate the channel attention feature vector. Finally, the channel attention feature vector and the feature map M are multiplied for weighting to obtain the feature map Y ∈ R2C×H×W. This process be expressed as Equation (12):
Where W1 ∈ R2C×2C and W2 ∈ R2C×2C denote two fully connected layers, γ denotes the ReLU function, and δ denotes the Sigmoid function.
Based on the adaptive scale module (ASM) and feature refinement module (FRM), we propose the U-shape adaptive scale network (ASU-Net) and apply it to the work of mass segmentation. The network architecture is shown in Fig. 3.
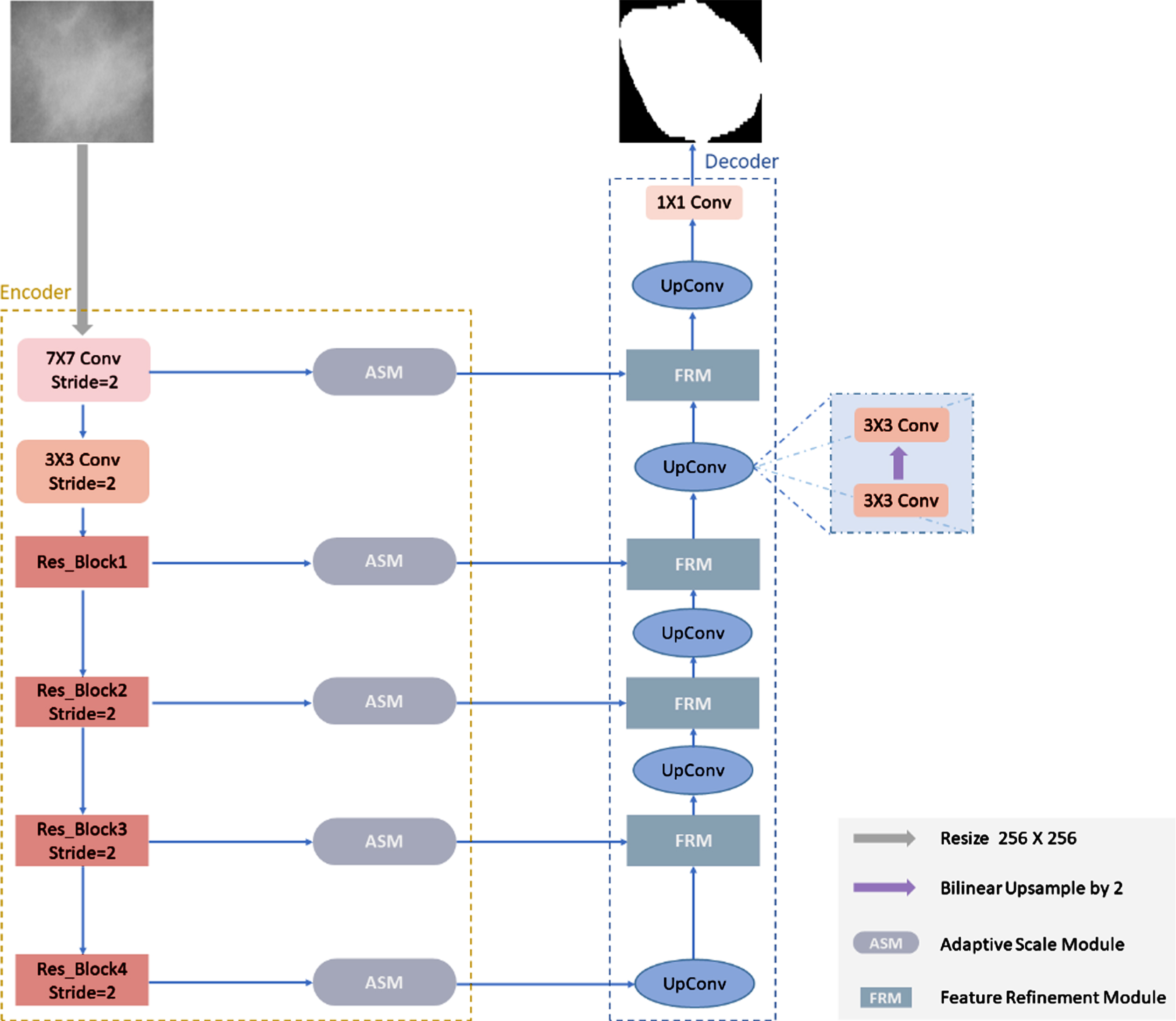
The structure of ASU-Net. According to the features of different scales of the masses, the feature of the appropriate scale is adaptively selected via the ASM in each layer of the encoder, which improves the effectiveness of the network in extracting multi-scale information. Besides, the channel attention of the useful channels is added via FRM in the decoder, which enhances the feature representation ability of the network.
ASU-Net uses an encoder-decoder structure and extends the standard U-Net model. ASU-Net mainly includes the ASM and the FRM. Through many tests, we use the pre-trained ResNet34 [23] as the backbone. In the multi-level skip-connections, the ASM is embedded to guide the aggregation of multi-scale information in a non-linear manner, so that the network can further effectively utilize the multi-scale features of the mass. At the same time, FRM is used to replace the feature fusion method in the standard U-Net, which enhances the feature representation capability of the network.
Database
In this work, two commonly public mammogram databases including the DDSM-BCRP database [36] and the INbreast database [16] are used to evaluate the performance of ASU-Net. The DDSM-BCRP database contains two subsets which include mass and calcification. The mass subset contains 316 mammograms, which has a total of 79 cases including 160 mammograms of breast masses with annotations. Generally, the annotations provided by the DDSM-BCRP database are inaccurate [1, 16], which may cause problems such as unstable segmentation results of the model. Therefore, we select the mass subset of the DDSM-BCRP database to tackle this problem. Where 80 mammograms are used for training and 80 mammograms are used for testing. The INbreast database contains 410 mammograms, which has 115 cases in total including 116 mammograms of breast masses with annotations. To facilitate the comparison with the previous method, we extract the region of interest (ROI) from the patch centered on masses. Taking into account the size of the GPU memory, we set the resolution of the ROI to 256×256 pixels according to the size of the model input port. Finally, we refer to the setting method [12, 48] to divide the ROI into a training set and a testing set. The results of the division of training set and testing set are shown in Table 1.
The results of the division of training set and testing set
The results of the division of training set and testing set
ASU-Net is implemented based on the deep learning framework Pytorch, using an i5 Intel CPU with 8GB RAM and GTX1080 GPU with 8GB. We use the cross-entropy loss function to calculate the loss between the network output and the ground truth, which assists the network in training. The optimization algorithm during training is Stochastic Gradient Descent (SGD). The initial learning rate is set to 0.05, which decayed by 10 times every 5 epoch. The momentum is set to 0.9 and the weight attenuation is set to 0.0001. The DI is a common evaluation index in medical images, which is employed to measure the degree of overlap between two samples. For example, The DI is used in related works [12, 48]. We also use the DI to evaluate our method. The DI is defined as Equation (13):
Where TP refers to the pixel numbers of mass that are correctly predicted as a mass, FP refers to the pixel numbers of the surrounding tissue that are incorrectly predicted as a mass, and FN refers to the pixel numbers of mass that are incorrectly predicted as surrounding tissue.
Ablation study of backbone network
Generally, the role of the encoder in the segmentation work is to extract the feature of the image. Its structure is relatively similar, most of which come from the network structure used in the field of image classification, such as VGGNet [24], ResNet [23] series, etc. The reason for choosing a classification network is that the segmentation network can be trained in a large database to obtain the weight parameters of the network, and then a better segmentation effect can be achieved through migration learning. The ResNet series can alleviate the problems of gradient disappearance, explosion, and network degradation caused by the increase in the number of network layers. We prefer the ResNet series to replace the encoder in U-Net. It is crucial to choose the right encoder according to the nature of the segmentation work. Therefore, we regard each network in the ResNet series as the backbone, then build a corresponding segmentation network based on ASU-Net. The experimental results are shown in Table 2.
The DI (%) of network which uses the ResNet series as the backbone network
The DI (%) of network which uses the ResNet series as the backbone network
As shown in Table 2, the segmentation network using ResNet34 as the backbone obtains the highest DI on both the DDSM-BCRP database and the INbreast database. Moreover, the segmentation network with ResNet18, ResNet50, ResNet101, and ResNet152 as backbone performs worse than ResNet34 in the DDSM-BCRP database and the INbreast database. The comparison in Table 2 reveals that the segmentation performance of the ASU-Net does not improve as the number of network layers increases. Generally, the depth of CNN affects the learning ability of its network. The deeper CNN structure, the stronger their learning ability. Note that a larger training set is usually required to make a deeper CNN have good generalization [3]. However, a large amount of accurately labeled data is lacking in the field of breast mass segmentation based on deep learning. Therefore, we need to select the appropriate CNN as the encoder for breast mass segmentation works. Eventually, ResNet34 is regarded as the encoder in ASU-Net.
In this section, how to embed multi-scale information in the feature level is more effective is discussed. Then, the implementation of ASM is introduced. As introduced in Section 3.1, inspired by the multi-level strategy, the multi-scale feature extraction module is embedded in the multi-level feature level of ASU-Net. We use two embedding strategies to verify the performance of the module in extracting multi-scale information from feature maps of different resolutions. One is to embed the conventional multi-scale feature extraction module ASPP into each layer of skip-connections to form RU-Net (ASPP), and the other is to embed ASM into each layer of skip-connections to form ASU-Net*. The experimental results are shown in Table 3.
The DI (%) achieved by using two different multi-scale feature extraction modules, ASPP and ASM
The DI (%) achieved by using two different multi-scale feature extraction modules, ASPP and ASM
Table 3 shows that the segmentation performance of ASU-Net* in the DDSM-BCRP database and the INbreast database is better than RU-Net (ASPP). In particular, taking the INbreast database as an example, ASM increases the segmentation performance from 92.94% to 93.32%, which is a more obvious improvement. In the DDSM-BCRP database, ASM is only 0.13% better than ASPP in terms of the DI. We speculate that this may be the reason for the inaccurate labeling of the DDSM-BCRP database. The results in Table 3 illustrate using ASM to extract multi-scale feature information can achieve better segmentation performance. Specifically, the ASM has the function to adaptively guide the aggregation of multi-scale features in a non-linear manner, which can effectively complete the work of extracting feature information of different scales.
In this section, the hyperparameter d mentioned in Section 3.1 is discussed. By setting the hyperparameter d, the parameter capacity and calculation cost of ASM can be controlled. Referring to the relevant experimental settings in SENet [18], four values are set for the hyperparameter d in ASM, which are 4, 8, 16, and 32 respectively. To study this relationship, we conduct a series of ablation experiments with different values of d based on ASU-Net.
As is illustrated in Table 4, the segmentation performance of the network does not improve with the increase of parameter capacity. We speculate that this may be caused by ASM’s overfitting of the correlation characteristics between channels in the training set. It is worth noting that when d = 16, a good compromise can be provided for the network between segmentation performance and computational complexity. In this way, the parameter scale of the network can be reduced without reducing the network performance, thereby saving the calculation cost. Therefore, we use 16 as the value of the hyperparameter d.
The DI (%) metric comparison at the different value of d in ASM
The DI (%) metric comparison at the different value of d in ASM
The FRM is embedded after each feature level of the decoder of ASU-Net. As described in section 3.2, after concatenating low-level features and advanced features, a channel attention mechanism is added to complete the refining of features and enhance the feature representation of the useful information. To verify the effectiveness of FRM, ASU-Net* which only keeps the ASM is used for the ablation experiment about FRM. The experimental results are shown in Table 5.
The DI (%) of the two networks in the DDSM-BCRP database and the INbreast database
The DI (%) of the two networks in the DDSM-BCRP database and the INbreast database
Table 5 shows the segmentation performance of ASU-Net* and ASU-Net. The segmentation accuracy achieved by ASU-Net is higher than that of ASU-Net*. In particular, in the INbreast database, ASU-Net outperforms ASU-Net* by 0.23% in terms of the DI, which proves that FRM can ensure the network effectively increase its attention to useful feature information. Besides, we calculate the parameters of the network. As shown in Table 7, the parameter amount of ASU-Net only increased by about 3.97 M after embedding FRM. It can be shown that FRM can bring about 0.1 0.2% improvement for the mass segmentation with its slight increase in parameter. This shows that the performance of FRM is good.
The DI (%) of networks which include ASU-Net and the latest segmentation methods
Params(M) and FLOPS(G) of each network
In order to demonstrate the superiority of ASU-Net, we quantitatively compare it with some of the latest breast mass segmentation methods. The comparison results are shown in Table 6.
As shown in Table 6, ASU-Net achieves the best DI of 91.41% on the DDSM-BCRP database and the best DI of 93.55% on the INbreast database. Compared with U-Net serving as the baseline, the DI of ASU-Net in the DDSM-BCRP database increased from 90.82% to 91.41%, and the DI of ASU-Net in the INbreast database increased from 91.48% to 93.55%. This result illustrates the significant performance improvement induced by ASM and FRM. Specifically, ASM can enhance the ability of the network to adaptively extract the multi-scale features of the mass. FRM can ensure that the network effectively increases its attention to useful feature information. Compared with other state-of-the-art methods, ASU-Net has also obtained obvious advantages, which fully indicates the effectiveness of ASU-Net.
Computational complexity analysis
In this section, we analyze the computational complexity and the amount of parameters of baseline, backbone and a series of ablation experiments. In Table 7, the FLOPS and the number of parameters of each network are listed. The FLOPS shows the complexity of the network. The amount of parameters shows the number of weights for the network.
As shown in Table 7, U-Net has 31.04 M parameters, and its FLOPS reach 54.69 G. RU-Net, the backbone model we chose, has 24.53 M parameters and its FLOPS are only 10.92 G, compared with U-Net. This shows that using RU-Net as the backbone can not only save computational costs but also simplify the complexity of the network. For the multi-scale feature extraction module, ASM is slightly higher than ASPP in terms of parameter count and computational complexity. Note that ASU-Net* increases the amount of calculation within a reasonable range while also improving the segmentation performance of the network. For details, see section 4.3.2. In particular, the proposed ASU-Net based on the backbone RU-Net not only improves the segmentation performance of the model but also greatly reduces the complexity of the model by adding fewer parameters. ASU-Net reduces 28.94 G in FLOPS compared to U-Net. The reduction of the computational complexity of ASU-Net raises the inference speed of the network.
Qualitative analysis
In order to make a more adequate evaluation of the segmentation results of ASU-Net, the experimental results are visualized. Figure 4 shows some visual examples of segmentation results.
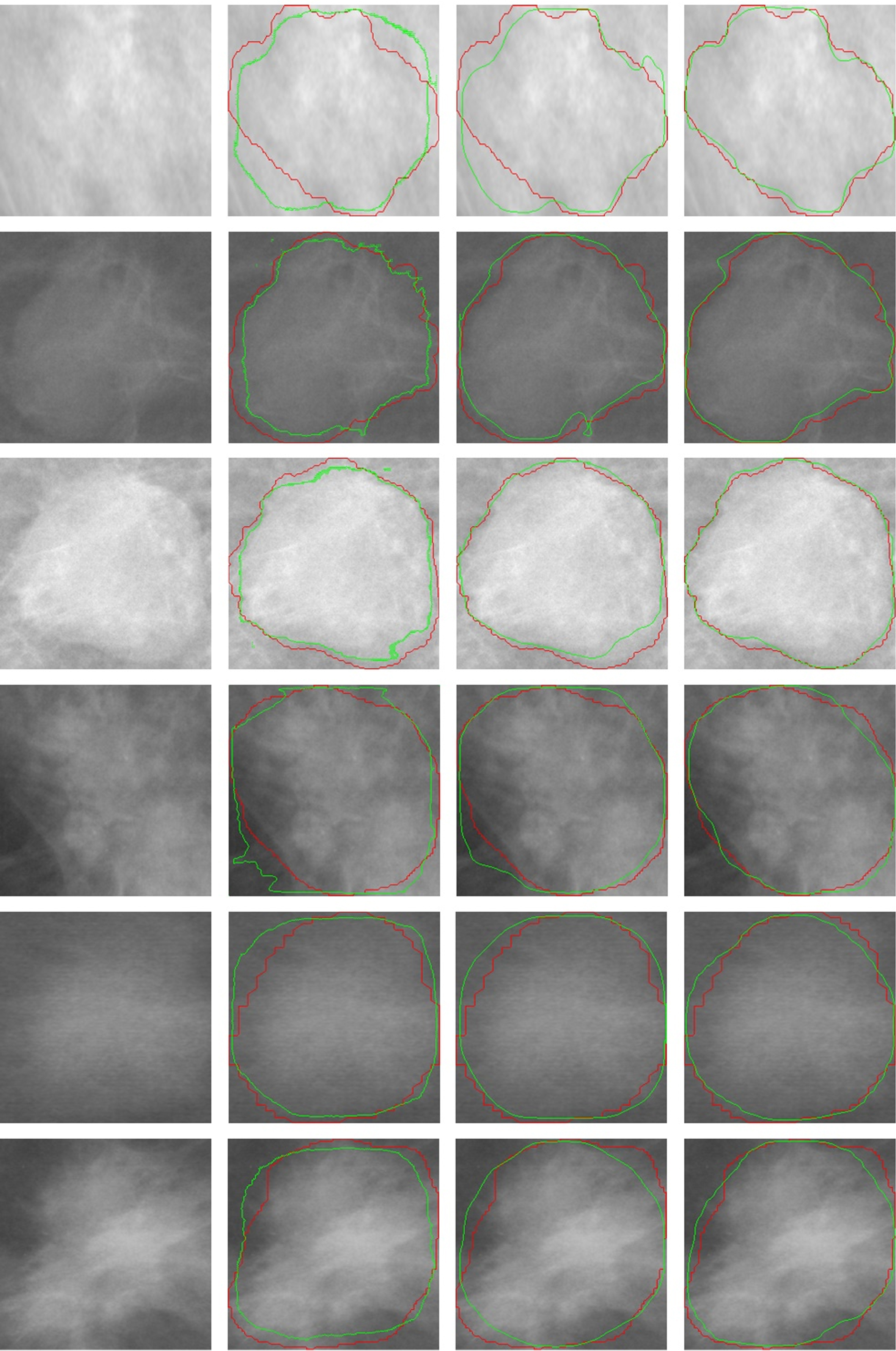
Partial visual examples of segmentation results in the INbreast database (row 1 to 3) and the DDSM-BCRP database (row 4 to 6). From left to right, these columns correspond to the visualization results of the input image, U-Net, RU-Net, and ASU-Net. The red outline is the ground truth, and the green outline is the predicted result generated by the corresponding model.
For images with relatively regular mass shapes, U-Net can obtain good segmentation results. In this case, the segmentation performance of ASU-Net is only slightly higher than that of U-Net, such as the segmentation result of the third row. However, for images with irregular shapes, U-Net and RU-Net have more false-negative samples and false-positive samples. In comparison with U-Net and RU-Net, the segmentation performance of ASU-Net is more excellent, such as the segmentation result image in the first row. We speculate that the conventional skip-connections in the standard U-Net or RU-Net just sends the low-level spatial information in the encoder directly to the decoder. This causes the network to ignore the multi-scale information of the multi-level feature level, which makes the network to be unable to capture the feature information of different shapes and sizes of masses.
When ASM is embedded in the multi-level feature level, multi-scale features are introduced into the network, which improves the extraction performance of multi-scale information of the network. Specifically, according to feature maps of different resolutions, ASM can learn the nonlinear interaction between convolution kernels of different sizes, and adaptively select a convolution kernel of appropriate size to complete the extraction of the feature. Then, they merge with the high-level semantic features in the decoder through skip-connections. In addition, FRM is introduced to integrate the channel-wise relationships to improve the feature fusion performance in the decoder. FRM improves the fusion method of each level in the decoder, selectively strengthens the representation of low-level spatial features and high-level semantic features, which effectively enhancing the feature representation of the network.
In this article, adaptive scale module (ASM) and feature refinement module (FRM) are proposed. ASM can adaptively extract multi-scale information according to different scale masses. FRM can integrate the channel-wise relationships among channels, which allows the decoder to obtain channel dependencies. Based on ASM and FRM, ASU-Net can make full use of the multi-scale feature information extracted from the encoder. Moreover, the network can selectively enhance the feature representation of useful channels in the decoder to achieve effective feature fusion. Finally, our proposed ASU-Net obtains the DI of 91.41% and 93.55% in the DDSM-BCRP database and the INbreast database, respectively. A series of experimental results show that ASU-Net effectively improves the false positive problem of mass segmentation and improves segmentation performance.
It is noteworthy that, the design of the current study like most studies is subject to certain restrictions. To compare with other related algorithms, we extract ROI from the database in advance. On this basis, ASU-Net shows good segmentation performance, which means that this method is promising. However, our method has certain limitations. Currently, our method can only have excellent breast mass segmentation performance in a small ROI. Enhancing the robustness of the model will be our future study work.
Conflict of interest
The authors declare that they have no conflict of interest.
Footnotes
Acknowledgments
We would like to thank the Breast Research Group, INESC Porto, Portugal for the INbreast database. This work is jointly supported by the National Natural Science Foundation of China (Nos. 61662062) and Sub-project of Qinghai Province Major Science and Technology Project (Nos. 2019-ZJ-A10).