
Abstract
The influencing factors of coal and gas outburst are complex, and now the accuracy and efficiency of outburst prediction are not high. In order to obtain the effective features from influencing factors and realize the accurate and fast dynamic prediction of coal and gas outburst, this article proposes an outburst prediction model based on the coupling of feature selection and intelligent optimization classifier. Firstly, in view of the redundancy and irrelevance of the influencing factors of coal and gas outburst, we use Boruta feature selection method to obtain the optimal feature subset from influencing factors of coal and gas outburst. Secondly, based on Apriori association rules mining method, the internal association relationship between coal and gas outburst influencing factors is mined, and the strong association rules existing in the influencing factors and samples that affect the classification of coal and gas outburst are extracted. Finally, svm is used to classify coal and gas outburst based on the above obtained optimal feature subset and sample data, and Bayesian optimization algorithm is used to optimize the kernel parameters of svm, and the coal and gas outburst pattern recognition prediction model is established, which is compared with the existing coal and gas outburst prediction model in literatures. Compared with the method of feature selection and association rules mining alone, the proposed model achieves the highest prediction accuracy of 93% when the feature dimension is 3, which is higher than that of Apriori association rules and Boruta feature selection, and the classification accuracy is significantly improved. However, the feature dimension decreased significantly, the results show that the proposed model is better than other prediction models, which further verifies the accuracy and applicability of the coupling prediction model.
Introduction
Coal resource is one of the main energy sources in the world, which has been increasing year by year since the early 1990 s [1]. Due to the complex natural conditions of coal mines, there are some hidden dangers in the mining process of many underground coal mines. Gas is the first disaster threatening the safety of miners. Gas accidents are highly destructive and harmful, so it is still one of the main tasks of coal mine safety to promote the advanced management of gas disasters. However, with the decrease of coal reserves and the increase of coal consumption, it is necessary to exploit deeper underground coal resources, which may have many safety and environmental problems such as coal and gas outburst, mine earthquake, mine water accumulation and so on [2]. Among them, coal and gas outburst is a complex geological disaster in coal mine in the world. Outburst accidents easily cause a large number of casualties and suddenly spray a large amount of gas coal and natural gas into the mining space in a short time. This is usually accompanied by high-pressure shock wave and results in such serious consequences as the burial or suffocation of miners and the destroying of equipment. In addition to coal mining, coal and gas outbursts accidents will occur in the area of tunnels and underground space where construction takes place. Furthermore, the natural gas released by outbursts will explode in case of fire, resulting in very dangerous underground construction. The greenhouse effect generated by outburst produces methane is 28 times that of carbon dioxide, which will cause serious pollution to the air [30]. Therefore, accurate and real-time prediction of coal and gas outburst is an important measure to realize green and safe production in mines in the world. The process of coal and gas outburst is characterized by being dynamic and non-linear and is affected by many factors. The relationship between the influencing factors is complex, and there is a lot of uncertainty, coupling, randomness and non-linearity. It is still uncertain which factors play the main role in the outbursts process and what is the mechanism underlying their interrelated actions. Therefore, before applying the classifier model, it is necessary to carry out feature selection and correlation analysis of the influencing factors and find out the key influencing factors and the corresponding association rules in the influencing factors and sample data in order to improve the accuracy and reliability of coal and gas outburst prediction.
The mechanism underlying coal and gas outbursts is very complex and there are many influencing factors. The nonlinear relationship between outburst risk and the factors affecting coal and gas outburst cannot be expressed by a clear mathematical model, which increases the difficulty of prediction. At the same time, it is very necessary to extract useful disaster information after the accident, and it is very helpful to prevent future accidents. Through the risk analysis of accident factors, we can understand the main hazard parts and degree of the accident, the relationship between the influencing factors and the risk level. Risk analysis is mainly based on accident statistical analysis and safety evaluation. Aiming at the above key problems in coal and gas outbursts classification, we propose a outburst prediction and influencing factors analysis model based on Apriori - Boruta and BO-SVM algorithms. The main contributions are as follows: Firstly, we propose a risk analysis model based on the combination of Boruta feature selection and Apriori association rules analysis to obtain the significant influencing factors and the internal correlation relationship between them. Secondly, on the basis of the obtained high-quality features and sample data, we established the BO-SVM classifier based on Bayesian optimization, which improves the accuracy and reliability of outburst prediction. Finally, based on the above results of feature selection and optimized classifier model, we valuate the efficiency and accuracy of the above proposed methods. The results are verified by several statistical tests and it can obtain the higher accuracy than other classifiers combining with other exiting feature selection methods, the rationality and effectiveness of the proposed model are verified by real datasets.
Related works
At present, the influencing factors of coal and gas outburst may contain some irrelevant, redundant features, which will weaken the performance of the learning model. Therefore, for the data analysis and processing of coal and gas outburst, feature selection is often an important preliminary work. The research shows that feature selection is not only helpful to find the correlation of coal and gas outbursts influencing factors, but also is helpful to complete the data analysis task of coal and gas outbursts influencing factors with low calculation cost. Feature selection method is to select an optimal subset from the original high-dimensional features according to certain evaluation criteria. Therefore, they can retain the semantics of the original features and make the dimensionality reduction results easier for domain experts to understand. The common research methods of feature selection in coal and gas outbursts are network analysis method and connection entropy [4], RS [5], EW [26], fault tree [20], genetic projection pursuit [28], GRA [24], variance ratio test [9], fuzzy clustering [2], FCBF [13], CIE [12], etc. These models follow the characteristics of space-time evolution of coal and gas outburst from different aspects, and enhance the prediction ability of coal and gas outburst to a certain extent, but each has its own advantages and disadvantages. Feature selection technology has strong theoretical research and practical application value, which is very important for the construction of coal and gas outburst prevention and control system A concise and efficient classification system plays an important role in revealing the hidden patterns and rules of the system. According to the applicability of class labels, feature selection methods can be divided into filtering, wrapper and embedding methods. The disadvantage of filtering method [13] is that it may deviate from the subsequent classification algorithm due to the application of the feature evaluation criterion independent of the classification algorithm. And the classification accuracy of the selected feature subset is not high. Therefore, it is difficult for most filtering model methods to comprehensively consider the influencing factors existing among multiple features in the evaluation function, such as redundancy and interactivity between multiple features, complementarity among the multiple features, etc. The wrapper model [17] integrates the classification learning algorithm into the feature selection process. The evaluation of the feature subset is realized by training and testing a specific classifier model. The accuracy of the learning algorithm is directly taken as the evaluation standard of the feature. The advantage of this strategy is that the selected feature subset usually has higher recognition performance than the subset selected by the filtering model. That is, it has a higher classification accuracy rate. The results show that the classification accuracy is higher, and the encapsulation model can effectively measure the influence of multi features on the recognition target. However, they still have high computational complexity, and the selection of feature subsets depends on learning algorithms. Due to these limitations, we have paid special attention to wrapper in this study. Filters and embedded methods are not the focus of this article and will not be discussed further here. Boruta algorithm is a wrapper feature selection model combined with random forest classification algorithm. RF classifier can reliably and robustly estimate the classification accuracy of different feature combinations [19]. No studies have reported reliable methods for evaluating the influencing factors of coal and gas technology using the RF classifier of Boruta machine learning algorithm. For this reason, this paper introduces a new coal and gas feature selection method. Boruta feature selection can select the best feature subset from the perspective of features, but coal and gas outburst sample data may also have incorrectly labeled sample data, and the formation of noise data may affect the classification effect. Hereby we study how to improve the accuracy of outburst classification from the analysis of association rules.
The association rules mining algorithm [16] is used to find the frequently occurring interdependence and association relations between things and features from the data. If there is an association between two or more attributes, the attribute value of one of them can be predicted based on its attribute. Correlation characteristics exist between the values of two or more influence factor variables in the influencing factors of coal and gas outburst. And correlation rules mining can find various association rule relationships existing in data samples and attributes, so as to determine the correlation rule relationship between main factors affecting coal and gas outburst and main control factors. This paper takes the correlation relationship between coal and gas outburst influencing factors and outburst as the knowledge and rules of outburst diagnosis, and this is used for judging whether the current coal and gas outburst is in a outburst state. Apriori algorithm [27] is a classical data mining method to find association rules from data. By setting support threshold and confidence threshold, a large number of rules with low probability of occurrence are filtered out to generate frequent item sets, and then the frequent item sets are scanned to extract strong association rules with high support and confidence. At present, the methods of support and confidence parameters of association rules algorithms are still artificially designated by users according to prior knowledge, and this is subject to subjectivity and nonscientific nature. The different values of support and confidence thresholds in mining models have significant effects on the size of frequent item sets and the number of association rules in the mining results. Current various association rule algorithms have common redundancy, and the information provided by many association rules can is the same, resulting in a significant reduction in the efficiency and accuracy of the classifier. Deleting some association rules do not affect the integrity of the overall information of association rules. Therefore, it is necessary to improve these algorithms or explore new algorithms to meet the needs of coal and gas outburst. According to the characteristics of coal and gas outburst sample data, this paper selects the Apriori algorithm to extract the association rules of coal and gas outburst influencing factors based on the feature selection of coal and gas outburst influencing factors, and obtains the optimal pretreatment data from the sample data.
The classifiers of coal and gas outbursts include RF [22], BP neural network and its variants [20, 31], extreme learning machine [21] and LSSVM [9] and so on. These classifiers all can solve nonlinear problems, have better learning and generality ability in prediction, so these classification models play an important role in improving the prediction of coal and gas outbursts, but there are some problems. For example, dynamic fuzzy neural network and probabilistic neural network have the disadvantages of complex calculation, long learning time and large sample space. RF is a combination prediction method, and it is very suitable for nonlinear and small sample data. The BP neural network is built on the basis of empirical risk minimization principle and has the problem of low prediction accuracy and generalization ability. The setting of network parameters is greatly random and man-made, and there is no relatively perfect theoretical basis. Therefore, it has low prediction accuracy for small sample data. The prediction results of coal and gas outburst with BP neural network have large errors and are not ideal due to the networks limitations such as falling into local optimum easily, slow convergence rate, a large demand for training samples and so on. Support vector machine [8, 18] has certain advantages in solving nonlinear and small sample, and is very suitable for predicting coal and gas outburst.
However, it is difficult to determine the penalty factor of support vector machine, and the experimental results are very sensitive to the data. Improper setting will lead to over-learning and other problems. The parameters of support vector machine kernel function are the key factors affecting the performance, and the appropriate parameter combination is very important to the classification performance of the classifier. How to obtain the optimal combination of kernel function parameters is also the key of this research. At present the commonly used parameter optimization algorithms in the literature include GA, AC, PSO, AFS and RS, GS etc. Documents [3, 28] use different intelligent optimization algorithms to optimize the kernel parameters of support vector machine. The intelligent optimization algorithm for the kernel parameter solves the shortcoming that the optimal solution of the kernel parameter cannot be obtained through experience setting to a certain extent, but these optimization algorithms are generally based on the mode of evolutionary algorithm. And the disadvantage of evolutionary algorithm is that the algorithm optimization is easy to fall into local optimum and the parameters sought are not necessarily optimal. The operation efficiency is not high, and the algorithm needs continuous iteration to optimize the parameters, thus affecting the classification performance of the SVM. Bayesian optimization algorithm [11] has the advantage of simple algorithm, easy understanding, fewer parameters, easy adjustment, combination of local and global optimization and so on, and it can be widely applied to the optimization of machine learning or data mining parameters.
Theory and method proposed
Boruta-Apriori correlation analysis and feature selection
Boruta
The basic idea of Boruta [15] is a wrapper constructed by a random forest classifier. The random forest classification algorithm can run without adjusting the parameters, and gives the estimation of feature importance. Random forest is an integration method, which performs classification by voting on a plurality of unbiased weak classifiers such as decision trees. The trees are independently constructed on different bagging samples of the training set, and the classification accuracy caused by the random arrangement of attribute values between objects is taken as the importance measure of attributes. Z-score is used instead of average accuracy loss and standard deviation to measure the recognition performance of a single feature because it can take into account the volatility of accuracy loss between different decision trees in the forest. The wrapper function identifies relevant parameters by performing multiple runs of the provided classification factors that test the performance of different subsets of the input parameters. The RF function can be used without extensive parameter adjustments and returns an estimate of the importance of the feature (Z-score). Z-score can not be directly used to measure the importance of features because they do not necessarily follow a standard normal distribution in general.
The Boruta algorithm solves this problem by constructing the corresponding shadow feature for each single feature and then measuring the importance with Z-score. The way of iterative is mainly used to evaluate the importance of each feature. In the process of evaluation, it is necessary to set shadow features for the original features and compare the importance of the two in each iteration. If the importance of the original feature is significantly higher than the importance of the shadow feature, the original feature is considered as important. And if the importance of the original feature is significantly lower than the importance of the shadow feature, the original feature is then considered as unimportant. The original feature is one that needs to be selected, and the shadow feature is generated based on the original feature. And the generation rule is as follows: First, adding a random interference term into the original feature can generate an extended feature. Second, sample from the extended features to generate shadow features, which are generated during each iteration. The process of the algorithm is shown as follows: The extended data set is obtained by adding random components (also called shadow attributes) of all attributes of the original data set, and then running a random forest classifier on the extended data set to obtain the Z score for evaluating the importance of features. Mark the attribute whose shadow attribute score is lower than the maximum Z-score (Zmax) as +1, which is recorded as hits. If the importance of a shadow feature can not be determined Zmax, then bilateral significance test on the attribute will be carried out, marking the features whose score is less than Zmax as 0. According to Bernoulli Equation (1). Repeat the above steps until all attributes are considered important, or the algorithm reaches the limit set in the random forest operation.
The influencing factors of coal and gas outburst contain redundant and irrelevant features, which reduces the classification accuracy. In order to better select the features closely related to outburst, feature selection is required. Boruta feature selection method based on RF is used to select the optimal feature set, RF is used as classifier, and the influence of single feature and multiple feature combinations on outburst classification is considered. In Boruta algorithm RF classification algorithm is used to guide the feature selection process, and the recognition performance of features is determined by measuring the loss of classification accuracy. Each single feature constructs a decision tree in the forest, and then the tree is used to recognize the target category independently and calculate the average and standard deviation of the classification accuracy loss.
The association rules [16] are to find the correlation between different items that appear in the same transaction, and to find out all subsets and their relevance of items or attributes that occur frequently in the transaction. Association rules mining are a rule-based unsupervised machine learning algorithm, and the main purpose is to explore the association between the internal structural features of data. In mathematics, the association rules are defined as: there exist two disjoint non-empty sets x, y. If x and y have a logical implication relationship such as x⟶y, x⟶y is called an association rule, where x is called the rule left term, y is called the right term. x and y are both item sets. The purpose of association rules mining is to export associations between items hidden in the project set and export the relations between them. The correlation between items can be described by association rules, which can intuitively reflect the potential connections between data item sets. The validity of rules is often measured by Support and Confidence. Support is an indicator of how often an item set appears in a data set, which measures the universality of the application of simple association rules and is defined as the probability that item sets x and y appear simultaneously. The calculation formula of support is shown in Equation (2). Confidence is a measure of the authenticity of a simple association rule, which is defined as the probability that an transaction containing item set X also includes item set Y, and is calculated as shown in Equation (3).
The rule A → B has a support of S, which means that S is the percentage of A ∪ B contained in transaction D, i.e. the joint probability P(A ∪ B), expressed as:
The rule A → B has confidence C, indicating that C contains an item set B as well as A, i.e. conditional probability p (A|B), expressed as:
Association rule mining is to find association rules whose support and confidence are greater than the minimum support (Minsup) and the minimum confidence (Minconf) given by the user respectively. When the confidence and support of a rule are greater than Minsup and Minconf respectively, the association rule is considered as valid, which is called a strong association rule. The mining of association rules can be divided into two steps. The first step is to find all the frequent item sets that meet the minimum support given by the user from the transaction data.the second step is to generate all the Association rules that meet the minimum confidence given by the user on the basis of the frequent item sets. The higher the support and self-confidence are, the stronger and the more effective the rules are. In the process of association rules mining, if the threshold of support is too small, a large number of weak association rules will be generated and the mining time will be prolonged; otherwise, valuable association rules may be overlooked. Therefore, it is necessary to carry out interactive mining by modifying the threshold to determine the optimal support threshold. The minimum support is the threshold to measure support, indicating the lowest importance of item sets in the statistical sense. Minimum confidence is the threshold to measure confidence, which indicates the lowest reliability of association rules. Strong association rules can satisfy both the minimum support threshold and the minimum confidence threshold.
The Apriori algorithm [27] clustering algorithm is a classic association rule mining algorithm. And the core idea is to find frequent item sets through candidate set generation and downward closed detection. That is, the “K item set” is searched by using the iterative method of layer-by-layer search and the “K-1 item set”. The specific steps are as follows: let C be the candidate item set and L be the frequent item set. Through iteration, all frequent item sets in the transaction database with a support not lower than the threshold set by the user are retrieved, and all the items appearing in the transaction set are taken as candidate 1-item sets. Count the support of candidate item sets, delete all items with support below the threshold, and generate frequent 1-item sets L1. Generate a candidate item set to be trimmed by using a connecting step, and prune by the pruning step to obtain a candidate 2-item set C2. Traverse the transaction set again to obtain the support of each candidate set, deleting all the items with the support below the threshold, and finally obtaining the frequent 2-item set L2. Iteratively perform the above process until the candidate set Ck is empty and until the frequent K-item sets Lk can not be found.
Due to the difficulty of sampling data of coal and gas outbursts, there may be errors in sample data and class labels, and the formation of noise data affects the classification effect, which is not conducive to outburst diagnosis. Through the analysis of Apriori association rules, we can find the relevant rules in the sample data and the wrong sample data labels. Then we can correct them, and form a new data set to improve the classification accuracy, the relevant flow chart is shown in Fig. 1.
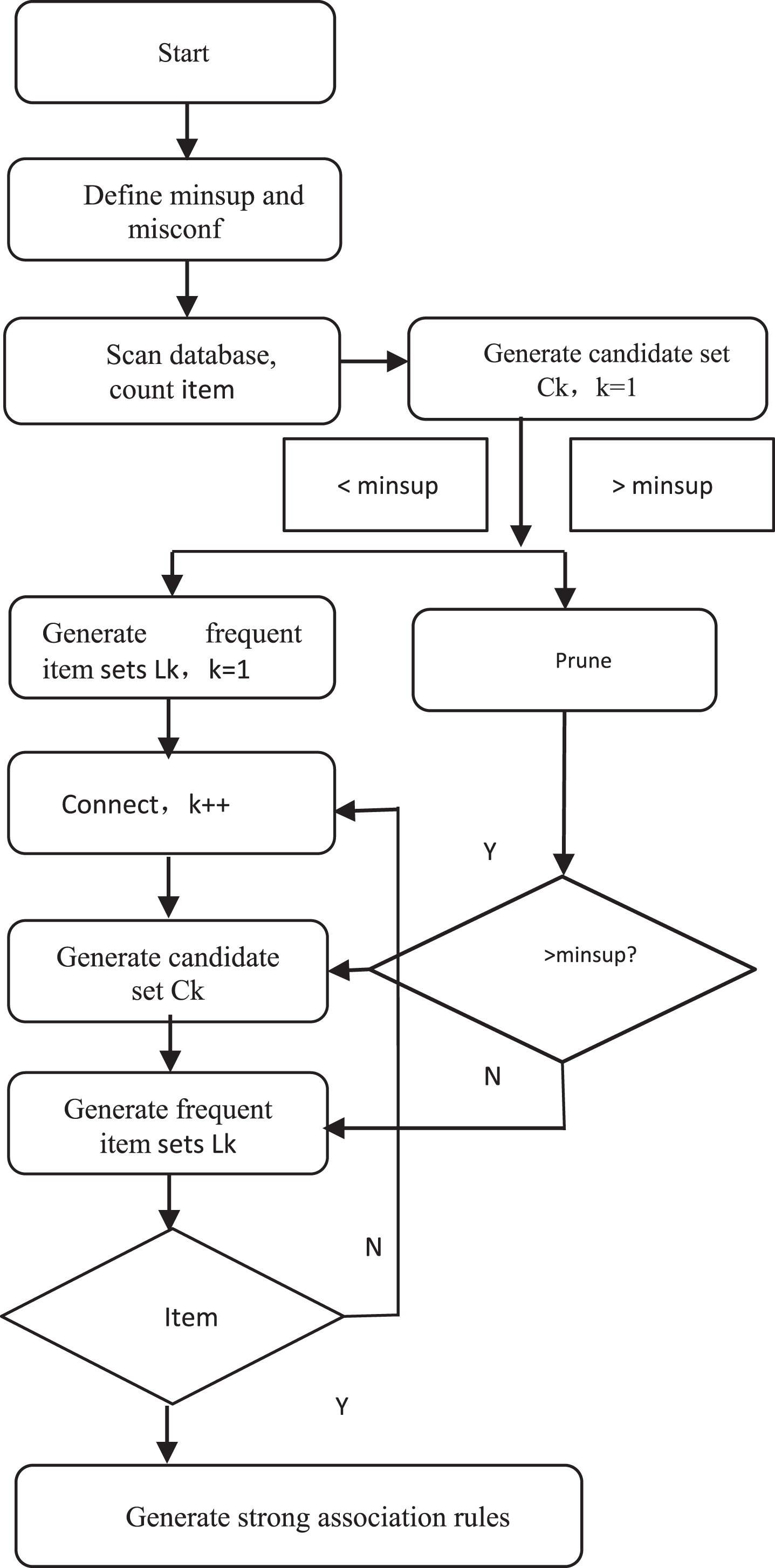
Flowchart of Apriori algorithm.
Coal and gas outburst is affected by many factors which are difficult to determine or estimate quantitatively. Therefore, it remains uncertain which factors play a major role in the outburst process and what the mechanism of action is. Apriori association rules can not only mine the association between coal and gas outburst and index features, it can also can get effective coal and gas outburst sample data. However, the relation between coal and gas outburst impact factors and the sample data are complex, Apriori association rules cannot remove the redundancy and irrelevance of feature attributes and cannot be used as outburst recognition knowledge and rules. The noise data affect the classification effect. Feature selection is the process of selecting some of the most effective features from the original feature set to reduce the dimension of the dataset. It saves the physical explanatory meaning of the original attribute, and gives it an advantage in functional readability and interpretation. By deleting irrelevant, redundant or noisy attributes etc., we select a smaller subset of related attributes from the original attributes and then identify a plurality of feature selections. Usually an optimal feature subset that optimizes a certain evaluation criterion is selected from the feature set. Boruta is a fully correlated encapsulated feature selection method, which tries to find all the features that carry the information that can be used for prediction, instead of finding the feature subset that produces the smallest error on the classifier like most traditional encapsulation algorithms. Boruta will find all relevant features regardless of the correlation between features and decision variables, which makes it very suitable for determining the best feature subset. Boruta algorithm can find all the features related to the category in the candidate features, so as to determine the number of features directly. And through Boruta feature selection, the correlation characteristics between coal and gas outburst and influencing factors can be found in order to determine the relationship between the main influencing factors of coal and gas outburst.
Boruta can find all the relevant features, which can solve the problem that Apriori algorithm cannot automatically give the best feature subset. Therefore, we consider building a hybrid model that integrates Apriori and Boruta. In the hybrid model, Apriori method is used to determine the correlation between coal and gas outburst sample data and feature attributes, and then it will find effective feature attributes and sample data as strong correlation rules for coal and gas outburst judgment. The Boruta encapsulation algorithm can remove the irrelevant features in the rules, and obtain the feature subset with higher classification performance, which improves the running efficiency and accuracy, so the characteristics of the two methods are well complementary. Therefore, this section proposes a hybrid model based on Apriori association rules mining and Boruta feature selection, and designs an efficient feature selection algorithm from the perspective of feature and sample selection to select a group of feature datasets with small redundancy and high-quality. This is helpful to find the significant factors affecting coal and gas outburst and improve the classification accuracy. The corresponding flowchart is shown in Fig. 2.

Boruta-Apriori based feature selection and association analysis.
The idea of BO algorithm
The basic idea of BO algorithm [29] is to estimate the posterior distribution of the objective function f using the Bayesian Equation (4) based on the data, and then select the super-parameter combination of the next sample according to the distribution. BO makes full use of the information of the previous sampling point, and the working mode of optimization is to learn the shape of the objective function and find the parameters that make the result of Equation (5) lift to the global maximum. Bayesian optimization learns the shape of the objective function by assuming the acquisition function according to the prior distribution. Each time a new sampling point is used to test the objective function, it uses this information to update the prior distribution of the objective function, and then the algorithm tests the most probable point given by the posterior distribution. BO uses prior knowledge to approximate the posterior distribution of the unknown objective function f, so as to adjust the super-parameters. BO is extremely powerful in the case of unknown objective function and high computational complexity and has the advantages of combining local optimization with global optimization.
The core of the BO framework is a probability proxy model and an acquisition function (AC). Bayesian optimization uses the probability model to represent the complex black box function. The prior knowledge of the target to be optimized is introduced into the probability model to make the model more accurate, the following are the steps as shown in algorithm 1.
The probabilistic proxy model is used to represent the unknown objective function, starting from the assumption of a priori, by iteratively increasing the amount of information and modifying the priori, we can get more accurate results probabilistic surrogate model can be divided into parametric model and nonparametric model according to whether the number of parameters is fixed. Probability proxy model comprises a prior probability model and an observation model. The prior probability is p(f). The observation model describes the mechanism of observation data generation, i.e. likelihood distribution p(D1:t|f). Updating the probability proxy model means that a posterior probability distribution p(f|D1:t) containing more data information is obtained according to the Equation (4).
When using Bayesian method to solve specific problems, it is necessary to select the appropriate probability model to represent the black box function according to the problem background and expert knowledge. It is even more important to select the appropriate probability proxy model for Bayesian optimization than to select the appropriate acquisition function. In this paper, according to the characteristics of coal and gas outburst sample data, we choose the convenient and powerful Gaussian process optimization modeling algorithm to solve the problem. The process of finding optimal parameters is a Gaussian process. In the process of Bayesian parameter adjustment, we assume that a group of super parameters combination is x = x1, x2,..., xn (xn represents the value of a super parameter), and there is a functional relationship between this group of super parameters and the loss function that we need to optimize finally. The final evaluation result is y. we assume that f (x), y = f (x) is the best x through which we can get the optimal y. This is a graph of a Gaussian process, as shown in Fig. 3.

Curve of Gaussian process.
In order to satisfy the behavior of black box function effectively and reduce unnecessary sampling, Bayesian optimization uses active selection strategy to determine the next step, compared with the random jump or neighborhood search strategy of the model free optimization method, the active selection strategy utilizes historical information and uncertainty. Qualitatively, by maximizing the acquisition function constructed according to the posterior distribution of the model, it can effectively balance the width search (explore the uncertain area to obtain more undecided information). In order to reduce unnecessary evaluation of objective function, the relationship between knowledge search and deep search is analyzed. The so-called acquisition function is from the input space, observation space and super parameter space. The function is defined by the observed data set D1, the posterior distribution is obtained by x t : t is constructed, and the next evaluation point xt+1: t is selected by maximizing the posterior distribution Equation (6):
The acquisition function is constructed according to the posterior probability distribution, and the next most potential evaluation point is selected by maximizing the acquisition function, and the effective acquisition function can ensure that the selected evaluation point sequence of the total loss l is minimized Equation (7),
Where, y* is the optimal solution, y t is the target function value.
For BO algorithm, once it finds a local maximum or minimum, it keeps sampling in this area, so it can easily fall into a local maximum or minimum. To alleviate this problem, Bayesian optimization can find out a balance between exploration and exploitation. Exploration is the acquisition of sampling points in areas that have not yet been sampled. Exploitation is to sample in the area where the global maximum value is most likely to occur according to the posterior distribution. The next selected point (x) should have a relatively large mean (exploitation) and a higher variance (exploration). These two standards are contradictory, so how to find a balance between them is the main challenge for function extraction. The choice of acquisition function may affect the effect of super parameter optimization model, there are three common acquisition functions: EI, PI and UCB.
The purpose of PI method is to maximize the probability that the new sampling can improve the maximum value. Suppose the maximum value is f(x+), then the acquisition function is as following Equation (8):
Where μ(x) represents exploitation, σ(x) represents exploration, δ (·) represents the normal cumulative distribution function, which is also called MPI (maximum probability of improvement), or PI algorithm. This will prevent a very slight increase near f(x+). PI is the first acquisition function proposed,different from the other ones, it can maximize the probability that the next sampling point can produce non-zero improvement. This function will tend to exploit rather than explore, so it is likely to converge close to f(x+). To solve this problem, we can add a trade-off coefficient ɛ in Equation (9).
This will prevent a very slight increase near f(x+). Here, the coefficient ξ can be defined by itself, which can be adjusted dynamically to control whether it is biased towards exploration or exploitation. It is worth noting that Pi uses a greedy search strategy, so it is more like local search to some extent.
Using EI as acquisition function is a good choice to balance exploration or exploitation. When exploring, we should choose those points with large variance, while when exploiting, we should give priority to those points with large mean value, and the introduction of formulas are as following:
In the formulas, the parameter I can usually be fixed to 0.01, it is worth noting that the experiment shows that the dynamic parameter I cannot improve the effect, even it is worse sometimes.
In addition to EI and PI, UCB is a simpler idea to directly compare the maximum values in the confidence space. This method compares the maximum value within the confidence interval. UCB is typical described in terms of maximizing f rather than minimizing f, in this paper, according to the characteristics of coal and gas outburst sample data,we use UCB as AC,and in the context of minimization, AC takes the following Equations (13–14):
Where k is a trade-off parameter, although it looks simple, the actual effect is surprisingly good, the following Fig. 4 is curve of Gaussian process.

Curve of Gaussian process.
BO framework is an iterative process, mainly including three steps:
First, according to the maximization of the acquisition function, we select the next most potential point.
Second, according to the selected evaluation point
Third, the new input observation values are matched to {
SVM [18, 23] is a supervised learning algorithm, which is based on VC theory and structural risk minimization criterion in statistical learning theory. Its basic idea is to construct an optimal hyperplane in the sample input space or feature space, so that the distance between the hyperplane and the two types of sample sets can be maximized, and the best generalization ability can be obtained. In this paper, according to the characteristics of the sample data, it is mainly nonlinear support vector machine classification. The learning process is to find the optimal separation hyperplane to maximize the segmentation of the two classes. The principle is as follows: for a binary classification problem, given the training sample set
In the above formula, ∅(X) is a non-linear mapping function from the input space x to the high-dimensional feature space, w is the weight vector, b is the bias value, and the classification hyperplane should meet the following constraints Equation (16):
For each sample xi, a non-negative relaxation variable ɛi needs to be introduced to measure the extent to which w and b violate the constraints.
Such a linear decision function can be defined by the following dual optimization problem:
SVM has a better generalization ability to test samples that have never been seen before. Its kernel method makes the linear non-separable problem linearly separable in high dimensional space by mapping the original data to high dimensional space. At the same time, it avoids solving the problem in high dimensional space. The kernel method represented by SVM has achieved great success in solving nonlinear pattern analysis problems. The nonlinear mapping function can map the original data to a linearly separable high dimensional feature space. The nonlinear decision function is as follows:
The selection of kernel function and the determination of its parameters have a significant impact on the classification performance, and there is no perfect theoretical basis so far. The parameter combination of kernel function includes regularization factor and kernel parameters. The regularization factor is structural risk and sample error. The value of kernel function bandwidth is related to the range and width of input data space, and there are different methods to optimize these parameters. The BO algorithm is simple, globally optimal and highly efficient, and its performance is stable and reliable. It can be used for optimization problem of kernel. The BO algorithm is used to optimize the basic parameters to obtain the best parameter combination. And its effectiveness is verified by function fitting and relevant parameter optimization in coal and gas outburst prediction. Therefore, this paper proposes a support vector machine parameter optimization algorithm based on BO and 10-fold cross verification.
Based on SVM framework and existing BO algorithm, this paper proposes an improved algorithm, the super parameters of SVM are optimized by BO algorithm. This method is highly efficient. The improved Markov chain Monte Carlo method is used to model the parameters algorithm to accelerate training. The training of Gaussian process model is to calculate the super parameter of Gaussian surrogate model. The UCB sampling method is used as the acquisition function to obtain the next sampling point. The loss value is calculated and then merged into the historical observation set. This process iterates until set of super parameters with good performance is obtained. This method can be used in different super parameter spaces Super parameter optimization is carried out under SVM framework. Using coal and gas outbursts dataset, the test set is used to test the performance of the algorithm, which shows the super performance of the proposed method. The parameters are better than those obtained by TPE, GPEI, MCMC and other similar optimization algorithms, the performance are more stable. The flow chart is shown in Fig. 5.

SVM classifier based on BO algorithm.
Eexperimental design
The mechanism of coal and gas outburst is very complex, and it is the result of geological stress, gas and coal seam physical properties and other factors. This article takes the coal and gas outburst of the coal mine in Henan province as the research object. Six index parameters are selected to analyze and evaluate the risk of coal and gas outburst: gas pressure, initial velocity of gas output, initial velocity of gas emission, structural coal thickness, complexity of fault structure, firmness coefficient, etc. These indexes are operable, universal and applicable real projects. Gas outburst is binary: outburst or non-outburst. In order to make the experimental results more objective, the method of 10-fold cross verification is used to verify the classification effect. That is, the data in the data set are randomly and equally divided into 10 parts, one of which is taken as the test set, and the other 9 are used as training sets. Then the corresponding classification method is run to learn the data in the training set and test the testing data. The average value of the corresponding 10 test results is taken as the classification result.
According to the characteristics of coal and gas attribute data, we use the normalization method to process the data. In the pre-processing stage, we use the normalization method to eliminate the influence of dimension and reduce the size difference between the attribute values, and we normalize each attribute value to the range [0,1]. The evaluation of the recognition system is mainly obtained by using the existing experimental data to make statistics on the system model. The common performance indicators include the following:(1) accuracy, which represents the ratio of the correctly recognized feature vector to the whole, and (2) precision, which represents the ratio of the correctly recognized positive feature vector to the recognized positive feature vector.(3) specificity, which is used to measure the ability of classification system to correctly identify actual negative feature vectors.(4) sensitivity, which is used to measure the ability of classification system to correctly identify actual positive feature vectors.
The configuration environment used in the experiment is as follows: the programming language is Python 3.7, the processor configuration is Intel Core i5-4590, the speed is 3.30 GHz, the memory is 8 G, and the operating system is 64-bit Win10. In the experiment, the support vector machine classifier uses Gaussian kernel function, and the generalization ability of classification performance depends on the combination of kernel parameters C and γ. In this paper, we set C ∈ 1,100 and γ∈ 0,1. Bayesian optimization is used to optimize (C, gamma) parameters, and the default values are used for the parameters of random forest and decision tree. The parameters of Bayesian optimization algorithm are set as: num_iter = 60.
Experimental results and analysis
Comparison of different feature selection methods
From Tables 1–3, we can see the comparison of feature number and performance indexes of different feature selection methods on different classifiers. In the feature selection of coal and gas outbursts data, the effect of feature subset formed by Boruta is the highest with the three classifiers compared to other feature data sets. The accuracy in SVM, NB and KNN are 92%, 87% and 83% respectively. The highest accuracy obtained by feature selection method CFS on the three different classifiers is 83%, 86% and 81% respectively, which is close to the Boruta feature selection method, but the number of features is high. The feature number of feature selection method FCBF is only 2, but the accuracy on different classifiers is 83%, 79% and 79% respectively, which are lower than Boruta and CFS.
Comparison of different feature selection using SVM
Comparison of different feature selection using SVM
Comparison of different feature selection using KNN
Comparison of different feature selection using NB
Boruta is a fully correlated encapsulated feature selection method, which tries to find all the features that carry the information that can be used for prediction, instead of finding the feature subset that produces the smallest error on the classifier like most traditional encapsulation algorithms. Boruta will find all relevant features regardless of the correlation between features and decision variables, which makes it very suitable for determining the best feature subset. Boruta algorithm can find all the features related to the category in the candidate features, so as to determine the number of features directly. Through the above results, we can conclude that the feature selection Boruta can achieve the goal, by screening out the optimal index characteristics, so we select the Boruta feature selection method to obtain the highly relation features from the outbursts influencing factors and the prediction effects are obviously improved.
Since Apriori requires that the attributes of the sample to be non-numerical, the six attribute indicators should have discrete rules according to expert experience and relevant references. The continuous attribute values in the database are made discrete and are encoded, and the preprocessing and partial coding results are shown in Table 4. Rule extraction is carried out on the data samples after feature selection through Apriori association rules. Table 4 obtains the performance comparison of different indexes by setting different confidences and supports. Through association rule mining, we can easily obtain outstanding association rules: in the experiment, we set the minimum confidence as 10% and the minimum support as 60%, and the obtained results are shown in Table 5. From the above mined association rules, it can be seen that the initial velocity of gas output, the initial velocity of gas emission and the complexity of fault structure are closely related to coal and gas outburst. Considering the interaction, the influences of the main factors on coal and gas outburst can also be obtained. Through the above analysis of the relevant association rules, the influence degree and association degree between each influencing factor and prominence can be accurately judged. This not only helps the decision-maker to judge the probability that a certain influencing factor and another influencing factor may lead to prominence, and it can also help them understand the acceptance degree of a certain influencing factor to other influencing factors. Therefore, it can not only help improve the accuracy of the selection of influencing factors, and it can also carry out burst prediction activities in a targeted way and further improve the accuracy and efficiency of prediction. In order to verify that effectiveness of our proposed model, our experimental steps are as follows. First, we tested a single model; in other words, we created a classifier-based single model (Apriori and Boruta) to compare the predictability of fluctuations between individual models. Secondly, we construct a hybrid model combining Apriori and Boruta. This paper aims to evaluate the superiority of the Apriori + Boruta Model over the existing models.
Encoding for preprocessing data rules
Encoding for preprocessing data rules
Frequency-iem-based strong association
Tables 6–8 show the comparison of classification performance of different classifiers combined with different feature selection methods, it can be seen from the table that the classification accuracy of the individual association rule mining algorithm is 88% with SVM,85% with KNN and 75% with NB respectively, and the feature size is 6. The classification accuracy of the individual Boruta algorithm is 92% with SVM,87% with KNN and 82% with NB respectively, and the feature size is 3, the dimension is lower than association rule mining algorithm. This is because the rules extracted by the independent association rule algorithm will produce redundancy, so the recognition effect is not high. The simple feature selection method only considers the effect of feature attribute comparison on the prominent target, but it ignores the noise data in the sample data, and the classification effect is not high. However, the combination of Apriori association rules mining and Boruta can significantly improve the classification accuracy compared with the feature selection and association rules mining alone, and the overall classification accuracy can reach 93% with SVM, 92% with KNN, and 83% with NB. The classification accuracy of proposed method is improved by 2 percent compared with the simple Apriori association rules mining and Boruta, and the feature size is only 3. The reason is that the combination of association rules mining and feature selection can make full use of the advantages of feature selection and association rules methods, it can remove redundant features and noise sample data of coal and gas outburst and improves the effectiveness of coal and gas outburst prediction feature selection, so it further verifies the universality of the method of combining Apriori association rules mining and Boruta feature selection.
Comparison of different feature selection on SVM
Comparison of different feature selection on KNN
Comparison of different feature extraction on NB
In order to verify the effectiveness of acquisition functions in BO algorithm in the parameters optimization of SVM, we evaluate UCB, EI and PI functions, from Table 9, we can see that different AC can obtain different effects in accuracy and efficiency, the accuracy are 93%, 90%, 93% respectively, among them the accuracy of UCB and EI are close, which are 93%, Pi is poor; For runtime, we also seen that UCB is highest, is 4.74 s, which is lower than EI and PI. Comprehensive results conclude that UCB method is very effective in BO algorithm, and it can obtain the tradeoff between exploit and explore, so we select it as AC.
Comparison of different algorithms
Comparison of different algorithms
At the same time we verify the effectiveness of BO algorithm in the parameters optimization of SVM, we evaluate and compare with other optimization algorithms such as GS, RS, GA and PSO in optimizing the parameters of SVM. From the simulation results in Table 10, we can see that the BO algorithm has good accuracy and convergence speed, when its iterations is 14, the accuracy reach the highest value, and remain unchanging, and it is superior to other optimization algorithms in efficiency and accuracy. Among all kinds of indexes of prediction effect, BO algorithm can achieve the best results, and the prediction accuracy obtained by different algorithms are all 92% expect that RS. In terms of execution efficiency, BO algorithm performs the best, the runtime is 2 seconds, the runtime of GS, RS, PSO and GA algorithm are 45,36,33 and 33 seconds, respectively, which are far more than that of the BO algorithm. Based on above the statistical results, the BO algorithm is found to be the most effective among these methods.
Comparison of different algorithms
Comparison of feature selection methods using SVM
Many abbreviations in the paper
The reason is that the parameter adjustment of BO algorithm adopts Gaussian process, considers the previous parameter information, constantly updates the prior, and adopts the active optimization strategy, so it omits many useless sampling point operations. On the premise of selecting the correct probability agent model and acquisition function, the BO algorithm finds a group of slightly better parameters than others after only a few iterations are performed, and considers the computing cost of the dataset in the parameters of the algorithm, so the optimization efficiency of the model parameters is significantly improved, then it is very suitable for finding a group of very good parameters in a short time. Moreover, the BO algorithm uses the information feedback mechanism of the individual to search, and realizes the balance between the local development ability and the global searching ability of the population, so it can find the best parameters combination. For the same dataset, the other algorithms can converge after more iterations are performed, with more iterations and slow running speed. The GS and RS algorithms are very easy to lead to dimension explosion when there are many parameters, and the prior parameter information is not considered in parameter optimization, so it is easy to get local optimization. PSO and GA algorithms are local or global optimization, and their optimization effects are very limited, which are lower than the optimization effect and execution efficiency of BO algorithm, it is seen that BO algorithm has more potential compared to the other optimization algorithms, so we choose BO algorithm to optimize the parameters of SVM.
In order to verify the effectiveness of our proposed model, RF is selected as the classifier to select the optimal feature subset. SVM is used as the classifier, and the prediction results of the method are compared with other prediction-based models mentioned in the literature. From Table 11, we can see that the accuracy, feature dimension of the model are better than those of the feature selection models in the current literature. The accuracy and precision of the model proposed in this paper are 93% and 96%, respectively, and the feature dimension is 3. At the same time, we can also see that different feature selection and classifiers produce different effects, and proves the effectiveness of the combination of association rule mining and feature selection gas outbursts prediction.
We should choose the appropriate method according to the characteristics of data distribution. From Table 11, we can see the comparison of experimental results of different feature selection. we can see the comparative analysis of this method and the feature selection methods in the literature, including FCBF, MIFS, NMIFS, MRMR, MIFS-ND. The results show that the classification performance of the proposed algorithm is higher than those in the literature. By verifying the feature selection results in the classifier, we find that the accuracy of these feature selection methods is between 79% and 83%. Compared with FCBF, MIFS, NMIFS, MRMR and MIFS-ND, the classification accuracy of this method is improved by 0.5-1 on average, but the feature dimension is less than these methods. This shows that the feature selection method in this paper can improve the prediction performance of each classifier. The main reason is that the feature selection methods of FCBF, MIFS, NMIFS, MRMR and MIFS-ND in judging the correlation between features and class markers and redundancy between features, and overestimate the importance of some features, while ignoring the joint effect between combined features and incomplete measurement of correlation information between features, resulting in inaccurate classification. The FCBF algorithm eliminates the redundancy feature one by one through the approximate Markov blanket, and the MRMR algorithm has relatively high performance and stable performance due to the addition of redundancy elimination function. The MIFS and MIFS-ND algorithms make the selected set more compact and efficient by adding redundancy elimination function, but it scatters the interdependent combinations. However, as previously described, FCBF and MRMR algorithms treat the correlation as redundancy and ignore the role of interaction in recognition. In proposed hybrid model, Apriori is used to determine the correlation between coal and gas outburst sample data and feature attributes, and then it will find effective feature attributes and sample data as strong correlation rules for coal and gas outburst judgment. Apriori has the following defects: the extracted association rules have universal redundancy, many association rules can provide the same information, resulting in the efficiency and accuracy of classifier greatly reduced, so it is necessary to carry out effective feature selection on the rules obtained by Apriori. The Boruta encapsulation algorithm can remove the irrelevant features in the rules, and obtain the feature subset with higher classification performance, which improves the running efficiency and accuracy, so the characteristics of the two methods are well complementary. This paper makes full use of the advantages of association rule algorithm in mining effective sample data and feature selection to select all relevant features. It considers various relationships between the influencing factors of coal and gas outbursts and provides a new idea for the feature selection of coal and gas outbursts. In the selection of classification model and optimization algorithm, we make full of the advantages of SVM classifier’s adaptability according to the distribution characteristics of small sample data of coal and gas outbursts. And we also consider Bayesian optimization’s execution efficiency, and good local and global optimization ability. High prediction accuracy on coal and gas outburst data set is obtained by this combined comprehensive model. Therefore, this section proposes a hybrid model based on Apriori association rules mining and Boruta and designs an efficient feature selection algorithm from the perspective of feature and sample selection to select a group of feature data sets with small redundancy and high-quality feature data sets. This is helpful to find the significant factors affecting coal and gas outburst and improve the classification accuracy. Therefore, the classification accuracy of these methods in the literature is not very high on the data set of this paper.
At the same time we also compare their performances in terms of computation complexity, assuming that the number of samples in a given dataset is n and the feature dimension is m, the number of candidate feature subset is k, the time complexity of Boruta feature selection is O(mn), the time complexity of Apriori is O(n4), Our proposed feature selection is composed of two parts: Boruta and Apriori, in conclusion, the time complexity of the our proposed feature selection is O(mn) + O(n4);For the time complexity of optimization algorithm and classifier are O(n) and O(m2n2), so the complexity of proposed methods is O(mn) + O(n4) + O(n) + O(m2n2). Therefore, our model is completely suitable for the needs of coal and gas outburst prediction. In a word, compared with the comprehensive model of coal and gas outbursts feature extraction and classification model in the literature, the model proposed in this paper has better recognition effect.
Conclusion and future work
In this paper, the Boruta feature selection method is introduced into Apriori association rules mining. Compared with the simple Apriori association rules and Boruta feature selection algorithm, this method greatly reduces the redundancy of association rule mining and improves the efficiency of the algorithm. Bayesian optimization is introduced into the parameter optimization of SVM classifier, and the proposed prominent prediction model improves the accuracy of prediction and significantly reduces the prediction error. In a word, the Association rules mined by the Association rule algorithm based on Boruta feature selection have a great auxiliary effect on outburst prevention and governance. At the same time, the prediction accuracy of the Boruta-Apriori + BO-SVM model is obviously better than that of Apriori-SVM and Boruta-SVM model. Compared with the method of feature selection and association rule mining alone, the proposed model achieves the highest prediction accuracy of 93% when the feature dimension is 3, which is 1–5 percentage point higher than that of Apriori association rule and Boruta feature selection, and the classification accuracy is significantly improved, the feature dimension decreased significantly; The results show that the proposed model is better than other prediction models.
However, this study still has some limitations. First, the method based on Apriori association rules has no unified principle to follow in support and confidence, and the quantity and quality of the extracted association rules need to be further studied. The second limitation is that BO-SVM classification method is not necessarily the optimal classifier, and a better classifier can be selected to improve the accuracy of coal and gas outbursts.
Data availability statement
The raw/processed data required to reproduce these findings cannot be shared at this time as the data also forms part of an ongoing study. Some or all data, models, or code generated or used during the study are available from the corresponding author by request.
Declaration of competing interest
The authors declare no competing financial interest.