
Abstract
With the development of the web 2.0 communities, information retrieval has been widely applied based on the collaborative tagging system. However, a user issues a query that is often a brief query with only one or two keywords, which leads to a series of problems like inaccurate query words, information overload and information disorientation. The query expansion addresses this issue by reformulating each search query with additional words. By analyzing the limitation of existing query expansion methods in folksonomy, this paper proposes a novel query expansion method, based on user profile and topic model, for search in folksonomy. In detail, topic model is constructed by variational antoencoder with Word2Vec firstly. Then, query expansion is conducted by user profile and topic model. Finally, the proposed method is evaluated by a real dataset. Evaluation results show that the proposed method outperforms the baseline methods.
Introduction
The current information is vast and keeps on increasing explosively. Information retrieval has to face the problem of how to obtain valuable information from the mountains of data effectively. With the maturity of related technology, information retrieval is a major area of research in various areas [1]. However, a user issues a query that is often a brief query with only one or two keywords, which leads to a series of problems like inaccurate query words, information overload and information disorientation [2, 3]. To solve the problems, query expansion approach is proposed. New query is constructed by query expansion (QE) that can provide effectively expansion words. Query expansion is one of the research in the field of information retrieval.
The automatic approaches of query expansion have played a major role in the improvement of efficiency for information retrieval system [4]. Automatic query expansion techniques focus on linguistic, corpus specific, query specific, search log-based and web data-based techniques [5]. In automatic QE, many papers are based on analysis of document corpora (referred as the statistical approach) or knowledge structures (referred as the semantic approach) or hybrid approach [4].
At the same time, more and more social resource sites support tagging mechanism (referred as folksonomy) that provides low interference source of information to construct user profile in recent years [6]. For example, Last.fm allows users to annotate music. Users can annotate and upload their favorite photographs and videos in Flicker. These collaborative tagging systems allow users to annotate resources freely according to their interests. In other words, collaborative tagging systems organize and share tags for all users, besides the tags are more accurate information for construct user profile [7].
However, there is not a hybrid QE approach with user profile for search in folksonomy. A hybrid QE approach combines two or more procedures for obtain an advantage greater than that from applying a single QE approach. And in folksonomy, user profile is constructed by tags accurately to reflect personalized preferences. As a result, it is urgent to propose a hybrid approach with user profile.
The main contributions of this paper are as follows:
This paper reveals and discusses the limitations of main current relevant works on query expansion. A method of query expansion based on topic models and user profile for search in folksonomy is proposed. Topic model is generated by variational autoencoder and Word2Vec. The reasoning and constructing processes of topic model are presented in details. User profile is composed of user tags. For a preliminary evaluation, the proposed method is compared with the state-of-the-art methods in experiments. The experiment results show that the proposed method is more effective.
The rest of the paper is organized as follows. The related research works are reviewed firstly. Then, the method of query expansion based on topic models is described in details. Next, experiments are conducted to compare our proposed method with baseline methods. Finally, this paper is concluded. In order to describe topic model clearly, the notations are summarized in Table 1.
Notations description
Notations description
In this section, some representative works on statistical approaches, semantic approaches and hybrid approaches of automatic query expansion are reviewed respectively. Furthermore, query expansion in folksonomy is reviewed.
Statistical approaches
Statistical query expansion approaches focus on the documents information. The basic idea is to apply statistical approaches to mine word-query association and word-word association. Jin et al. [8] propose a query expansion method that utilizes the tag co-occurrence information to select the most appropriate expansion words. However, Peat et al. [9] analyse the limitations of word co-occurrence data for query expansion in document retrieval systems. Meanwhile, topic model is used in query expansion. Sankhavara et al. [10] report the results on query expansion using topic model. Furthermore, in order to indicate that the statistical method has more performance than others, some different versions of QE have been developed and compared under the categories of lexical, statistical and content-based methods in [11]. Statistical methods and semantic methods have been compared in [12] by using a social media data repository. In addition, Rocchio algorithm [13] is classical method that gets the optimal solution by constructing the prototype vector and is widely used in query expansion.
Statistical query expansion approaches have highlighted mine word-query association, without considering the relevance of the user’s query or intent.
Semantic approaches
The main drawback of the statistical approaches is it may have more relevance to document collection rather than to the query of user. To address this issue, semantic approaches use semantic knowledge structures to extract meaningful word relationships according to the original search query. Nasir et al. [14] introduce a new method that it employs different types of external information to automate and improve the relevance feed-back process by selecting relevant words from the documents that best match the semantics of the query. Azad et al. [15] propose a novel technique named Wikipedia WordNet based QE technique for query expansion that combines Wikipedia and WordNet data sources to improve retrieval effectiveness. Huang et al. [16] propose a novel QE algorithm with the semantics of change sequences. It not only captures which changes occurred from GitHub commits but also understands why changes occurred with Deep Belief Net-work. Zaiem et al. [17] first built a query expansion training set by using sentence embedding based keyword extraction, and then assess the ability of the Sequence to Sequence neural networks to capture expanding relations in the space of words embeddings. Fang et al. [18] propose a query expansion method that provides an innovative combination of semantic information and the conventional sequential dependence model. Specifically, synonyms are obtained automatically through the word embeddings which are trained on the domain-specific corpus by selecting an appropriate language model. Word2Vec is proposed by Google in 2013, which improves the shortcomings of the previous word vector training models and has attracted extensive attention from industry and academia. In the training process of Word2Vec, the deep learning technique is used to map words into high-dimensional vectors for extracting the feature of words. The semantic similarity can be calculated by Word2Vec, e.g., cat and kitten are close together in the semantic space of word vectors. Zhou et al. [19] uses Word2Vec to train the label data. The labels are mapped to the multi-dimensional semantic space, and the optimal extended words are obtained by computing the vector similarity between query words and other words. Although the Word2Vec has been widely used in query expansion, there are few researches on the combination of topic model.
Semantic approaches have reported improved results in search. However, it can lead to the phenomena of topic drift, which may occur due to addition of some irrelevant concepts to the knowledge base during expansion of the query. When expansion words are more related to individual query words than to the whole query, resulting in irrelevant retrieval of results [20].
Hybrid approaches
A hybrid query expansion approach combines two or more models in order to obtain the further advantage over a single approach. Hybrid methods achieved the best results on the experimental benchmarks [12]. Esposito et al. [21] propose a hybrid query expansion approach based on lexical resources and word embeddings for question answering systems. Singh et al. [22] capture the limitation of pseudo relevance feedback based query expansion and propose a hybrid method to improve the performance of pseudo relevance feedback based query expansion by combining corpus based word co-occurrence information and semantic information of word. Singh [23] proposes a model for combining multiple expansion words selection methods by using a variety of ranks combining approaches. Then, semantic filtering used to filter out semantically irrelevant words obtained after combining multiple words selection methods. The genetic algorithm used to make an optimal combination of query words and candidate expansion words obtained by applying ranks combination and semantic filtering approach.
Although hybrid query expansion approaches obtain an advantage greater than that from applying a single approach, user profile is not introduced, especially in folksonomy.
Query expansion in folksonomy
At present, the collaborative tagging system has become popular. However, there are few researches on query expansion in folksonomy.
Kin et al. [24] explore the possibility of social annotation as a new resource for extracting useful expansion words. In the first phase, they propose a word-dependency method to choose the most likely expansion words. In the second phase, they develop a machine learning method for word ranking, which is learnt from the statistics of the candidate expansion words, using ListNet. Bouadjenek et al. [25] propose a new approach to query expansion through the combination of semantic and social information to reduce some of the limitations of the personalization approaches. The similarity between query words and candidate extension words is calculated by the jaccard similarity, and the weight of candidate extension words is calculated in the user personalized preference model.
Although there are methods to implement query word extensions in social tagging systems, there is not a hybrid approach with user profile to construct query expansion in folksonomy.
This paper uses a novel hybrid query expansion method, based on topic model. In detail, topic model is constructed by variational antoencoder with Word2Vec firstly. User profile is consisted of user tags from folksonomy. Then, query expansion is conducted by user profile and topic model.
Methods
In this section, a hybrid query expansion approach with user profile is described in detail. First topic model and user profile are constructed, respectively. In particular, topic model is generated by variational autoencoder and Word2Vec, and user profile is composed of user tags. Then, query expansion is implemented by user profile and topic model.
Topic model
Topic model is a research of natural language processing and information retrieval in recent years [26]. The most classic topic model is Latent Dirichlet Allocation (LDA) that is a generative probabilistic model of a text corpus. The idea of LDA is that documents are represented as random mixtures over latent topics, and each topic is characterized by a distribution over words [27]. A common special case is the symmetric Dirichlet distribution, where all of the elements making up the parameter vector α have the same value. The generative process of LDA is as follows: For each topic k ∈ { 1, … K } : Generate β
k
= ∼ Dirichlet (η) For each document (d): Generate θ ∼ Dirichlet (α). For each of the N words wd,n: Generate a topic z
n
∼ Multinomial (π (θ)). Draw wd,n ∼ Multinomial (π (β
z
n
)).
where β is the topic-word distribution for a corpus, θ is topic distribution for documents, z is the vector of topic-words and N is the number of words in document.
According to the generation process of LDA [27], the marginal likelihood function of generate documents
However, all variables are independent in the process of constructing topic model by variational autoencoder in this paper. Approximate distribution function q uses the another two variational parameters γ and Φ to approximate θ and z. The approximate function can be written as q (θ, z|Φ, γ), the derivation of the variational objective function is shown in Equation (2) according to the Jensen’s inequality.
Topic model is constructed by using variational autoencoder that is composed of encoder and decoder. Encoder is to generate a variational approximate posterior distribution q (θ, z|Φ, γ) of the document-topic. Decoder estimates the optimal generation probability

Network structure of variational autoencoder of topic model.
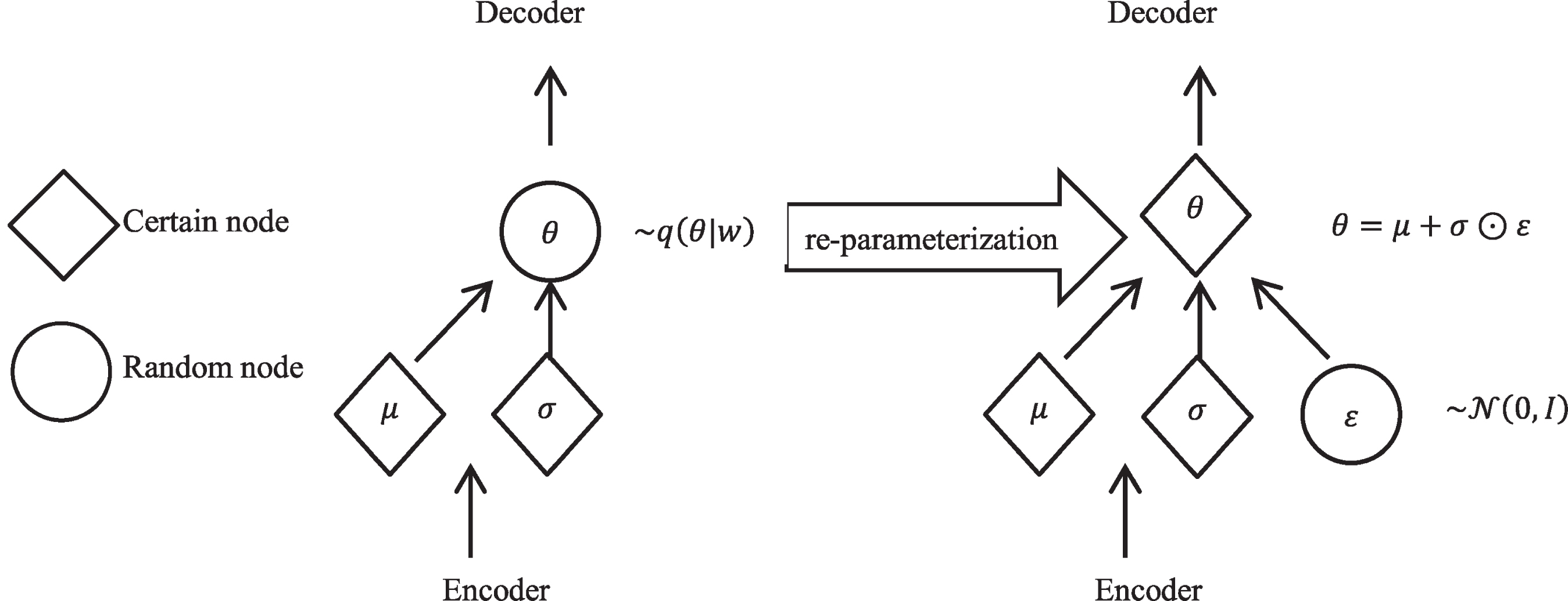
Graphical model of the re-parametrization trick.
In Fig. 2, z ∼ q (θ|ɛ, σ) can be reparameterized as a Gaussian function and a random variable
It is difficult to re-parameterize the Dirichlet distribution. This paper uses Gaussian distribution to instead of Dirichlet distribution, that is
For p (Z, θ|α), it uses the Laplace approximation with the property that the covariance matrix becomes diagonal for large K (number of topics). This approximation to the Dirichlet prior p (Z, θ|α) is results in the distribution over the softmax variables as a multivariate normal with the mean μ′ and covariance matrix σ′ that are represented in Equations (4) and (5) respectively according to literatures [28] and [29].
As loss function, the final variational target is shown in Equation (6).
The topic model is considered from a statistical point of view and often ignores the semantic relationship between words. In this paper, Word2Vec is used to enhance the semantic of the topic model. This paper adopts Skip-gram model to predict the contexts of a given target-word. The specific generation method can be referred to the literatures [30]. A word similarity matrix is obtained by calculating the cosine similarity between word vectors.
Some semantically relevant words can be used to instead the words that are irrelevant to the topics. During the training process of the topic model, this paper uses non-parametric sampling method. The relevance of word w j and topic k is denoted by Correlation (w j , z = k), which is shown in equation (7).
This paper chooses the word w j that is the largest proportion of the topic k, then the word w i is sampled by equation (8).
It should be noted that the Skip-gram model is not introduced for each iteration until topic model becomes stable. If the Skip-gram model is introduced at the beginning, topic model may not converge.
The optimal extension word is chosen by the topic similar of words in topic model. In the topic model, if the KL distance between the topic distributions of two words is smaller, the two words are considered to have a higher similarity. At the same time, query expansion combines with user profile that is considered as a technique to measure the degree a user is interested in a feature (tag). Based on the above illustrations, the following assumptions is proposed.
Assumption 1. For two words Topicword1 and Topicword2, in topic model, higher similarity indicates the more relevance.
Assumption 2. For a query vector
Assumption 3. For a user profile User i , in topic model, if the word Topicword t has more relevance with most words of user profile User i , then Topicword t has more relevance with user profile User i .
Assumption 4. For a user profile User
i
and a query vector
Based on assumptions 1-4, the process of query extension is described as follows.
A user issues a query that is pre-processed by performing tokenization, processing lemmatization and deleting stop words. The query vector
where m is the total number of words in query, q
j
is a word and w
j
is the weight of the word q
j
, w
j
is calculated by (9).
According to the query vector
For each word in Extension, the relevance between the pth word and user profile User
i
is denoted by φ
ip
, which is calculated by equation (11).
Based on the two results of equation (11) and equation (12), the final value of the pth candidate extension word is calculated by equation (13).
The candidate word with the highest value is selected as the final extension word. A query is issued for searching the extension word and query word together. This query extension method can alleviate the impact of query word mismatch and improve the search quality.
In addition, according to the content of research literatures [25, 26], the number of query extension words in this paper is decided as follows: If the query contains the number of non-repeating words m⩽3, then the number of extension words is m. If the query contains the number of non-repeating words m>3, then the number of extension words is 3.
This section conducts experiments to verify the effectiveness of the proposed method in a large real dataset. This section describes dataset and metrics used. Performance improvement of the method is compared with some query expansion methods.
Experiment environment
This section uses TensorFlow 1.4.0 with CPU support only and Python 3.6 for the proposed method implementation and the experiments are run on a single processor machine equipped with an AMD FX-Series CPU FX-8350 @4.0GHz, the processor having eight physical computing cores, 24 GB DDR3 RAM memory @1600MHz. The machine runs on Windows7 64 bits.
Dataset
Although some social resource sites support tagging mechanism, it is difficult to find more public and real datasets to evaluate the proposed model. The paper uses a benchmark dataset to evaluate the proposed method: The MovieLens-20M datasets (https://grouplens.org/datasets/movielens/) collected by the GroupLens Web site. The MovieLens-20M dataset has 465,564 tags, annotated by 138,493 users on 27,278 movies. Every movie is annotated by 17.06 tags averagely. In order to avoid the influence of tag data sparsity, more than 20 tags of movies and users are chosen for constructing topic model and user profile, respectively.
The MovieLens-20M dataset is randomly divided into training and test sets. For the dataset, 80% of the dataset is chosen in the training set, while the rest of the dataset is retained in the test set.
Evaluation metrics
In order to determine the optimal number of topics for the topic model, the Normalized Point-wise Mutual Information (NPMI) is used to evaluate the qualitative of topics. NPMI is close to the ordinary understanding of people [32]. NPMI (k) can express the coherence of topic k, and NPMI (k) is shown in Equation (14).
The evaluation of query expansion is a professional human judge that classifies the generated query expansion words into five types: excellent, good, fair, bad, and not sure [33]. This paper gets 500 query expansion words.
Two metrics are used for the evaluation of search. The first one is MRR (Mean reciprocal rank) that measure ranked query results. The reciprocal rank of a query result is computed while the first correct relevant resource is retrieved. The value of MRR is the average of the reciprocal ranks of results for a set of queries, as defined by Equation (15).
Imp is a widely adopted metric to measure how the proposed method is better than baseline methods, as defined by Equation (16).
A user issues a query (q
i
), r
p
is the ranking of the relevant resource in the result list by the proposed method, while r
b
is the same by a baseline method. Thus the average of imp shows the overall improvement in the test data, as defined by Equation (17).
To evaluate the efficiency of the proposed approach, some baseline methods are chosen to compare with the proposed method. The first baseline method uses Word2Vec to train the label data directly [19], denoted by Baseline1. The labels are mapped to the multi-dimensional semantic space, and the optimal extended words are obtained by computing the vector similarity between query words and other words. The second one constructs the topic model by the variational auto-encoder, and the optimal extended words are obtained by computing the topic similarity between query words and other words, denoted by Baseline2. The next one uses user profile to expand the query based on Baseline2, denoted by Baseline3. This paper constructs topic model that is based on Word2Vec, denoted by Baseline4. A query expansion approach is proposed based on topic models, Word2Vec and user profile, denoted by PQE. In addition, in order to show that query extension can improve search quality, a personalized search method is compared with query extension methods, denoted by Original-Q [31].
Comparison with Baseline Methods
First, the key of topic model is to determine the optimal number of topics. The NPMI is used to calculate the average topic relevance under different number of topics from 40 to 100. The result is shown in Fig. 3.

Average topic relevance under different number of topics.
In Fig. 3, the number of topics begins to increase from 40, the average topic relevance gradually increases to the highest value 0.149 when the number of topics is 70. The average topic relevance decreases slowly when the number of topics is from 70 to 90. And then, the average topic relevance decreases rapidly to 0.1037, The average topic relevance is high and stable when the number of topics is from 70 to 90 that is appropriate for the experimental dataset. In order to obtain the optimal topic model, 70 is the optimal number of topics in this paper.
To determine the optimal parameter γ in Equation (13), 500 extension words are evaluated by the method of professional human judge. The larger number of extension words has less error of subjective judgment. The range of γ is from 0.1 to 0.9, and the step size is set to 0.2. The number of extension words in five criteria of excellent, good, fair, bad, and not sure under different parameter values is shown in Table 2.
Five criteria under different parameter values
The more excellent and good extension words show that the parameter γ is better for query extension. In Table 2, as the parameter γ increases, the number of excellent and good extension words grows. When γ =0.7, the numbers of excellent and good extension words reach the highest values at 163 and 196 respectively. The result indicates that the similarity between extension words and query vector is more important, and the role of user profile cannot be ignored.
At the same time, the less fair and bad extension words show that the parameter γ is better for query extension. In Table 2, the number of fair extension words reaches the least value when γ =0.7. The number of bad extension words reaches the least value at 41 and 40 when γ =0.7 and γ =0.9. The number of extension words in not sure is a general reference that has the least influence on the parameter selection.
According to the experimental results of the training set, this paper chooses the optimal parameter value γ=0.7.
Then, a series of experiments are conducted on test dataset. All methods on MRR metric are shown in Fig. 4.

Comparison of the proposed method and baseline methods on MRR.
According to Fig. 4, PQE has the highest MRR value at 0.2344, while the other methods are at 0.1844, 0.2112, 0.1869, 0.2233 and 0.2211, respectively. PQE outperforms the baseline methods. Furthermore, on imp metric, PQE outperforms the method of Original-Q by 5%, the method of baseline1 by 2.32%, the method of baseline2 by 4.75%, the method of baseline3 by 1.11% and the method of baseline4 by 1.33%.
All query extension methods outperform Original-Q, proving that query extension can improve search quality. Query extension with Word2Vec outperforms topic model by comparing baseline1 and baseline2. The result of query extension using topic model with Word2Vec (baseline4) is little difference from using topic model with user profile (baseline3), and they outperform the methods of query extension that only uses Word2Vec (baseline1) or topic model (baseline2). On the whole, the best one is PQE that is constructed by topic model, Word2Vec and user profile.
This paper proposes a query expansion approach based on topic model and user profile for search in details. Topic model is constructed by variational antoencoder with Word2Vec, and query expansion is conducted by user profile and topic model. Finally, the PQE approach is evaluated by a real dataset. Experimental results demonstrate that the proposed method outperforms the baseline methods. The accuracy of search using the proposed method is over 1% higher than baseline methods. The largest advantage of this work is in solving the problem that is not a hybrid approach with user profile to construct query expansion in folksonomy.
The main limitation of the proposed method is the process of constructing user profile without the rating score. The future research will focus on the following three directions. In order to improve efficiency, the research will explore the parallel variational autoencoder to construct topic model. This research will construct the more accurate user profile with the rating tags and scores to improve the efficiency of query expansion. This research will also apply PQE approach in recommender systems, text classification, and other fields.
Footnotes
Acknowledgments
This research was funded by the Scientific Research Project of Hebei Education Department of China (Grant No. QN2020198).