
Abstract
Proksch has proved the changed terms of source code negatively affect code search quality. However, current query expansion (QE) methods always ignore it. In this paper we propose a novel QE method based on the semantics of change sequences (QESC). It not only captures which changes occurred by extracting change sequences from Github commits, but also understands why changes occurred by learning sequence semantics with Deep Belief Network (DBN). Thus it could extract relevant terms to expand or irrelevant terms to exclude from the changes semantically similar to a query. Our experimental results show QESC outperforms the existing QE methods by 15–23% in terms of precision on inspecting the first query result.
Introduction
Query expansion (QE) techniques are widely used for code search. CodeHow [1] expanded a query with online API information on MSDN. QECK [2] expanded a query with Question & Answer (Q&A) pairs on Stack Overflow. However, they always suffer from over-expansion, i.e., expand a query with irrelevant terms confusing the search engine to rank the most relevant result behind all the other results. This is because the expansion terms that should have been relevant will be irrelevant after a code change. As Proksch [3] said, the changed terms of source code have a major effect on many real query cases. Here is an example to illustrate how they affect the search quality.
Github commit “3eb66fb19ca2aa3d9dce53661f3233b6c 9d3f974”.
Figure 1 shows the Github commit1 of the method “IndexFiles.java”. Two versions of “IndexFiles” before and after the code change are
If deleted terms of If deleted terms of If new terms of
This example shows the significance of the changed terms of source code. However, it is not enough. We have to understand why the changed terms occurred. As they often occur together with their dependent terms, we think the dependent terms are good indicators to explain why changes occurred, i.e., changed terms could be triggered by their dependent terms.
Two versions of changed method.
Suppose that a piece of code snippet is changed into version1 and version2 as shown in Fig. 2. Versioin1 has changed terms “init1, cal1” and their dependent terms “if, while”. Versioin2 has changed terms “init2, cal2” and their dependent terms “while, if”. If we infer changed terms based on the traditional occurrence frequencies of dependent terms, we can’t determine if the change terms are “init1, cal1” or “init2, cal2”, because the occurrence frequencies of their dependent terms (“if, while” and “while, if”) are identical. However, the semantic information hidden deeply in source code is different [4]. For version1, the change sequence, containing changed terms and their dependent terms in sequence, is [
In this paper, we propose a novel QE technique with the semantics of change sequences (QESC). It not only captures which changes occurred from Github commits, but also understands why changes occurred with DBN. Therefore, it adds relevant terms to a query and exclude irrelevant terms in a query.
QESC contains two ends. The back end (Fig. 3I) generates sequences to capture which changes occurred, and build an inference to understand why changes occurred. The front end (Fig. 3II) retrieves method-level results to obtain changes semantically similar to the query.
Infrastructures of QESC.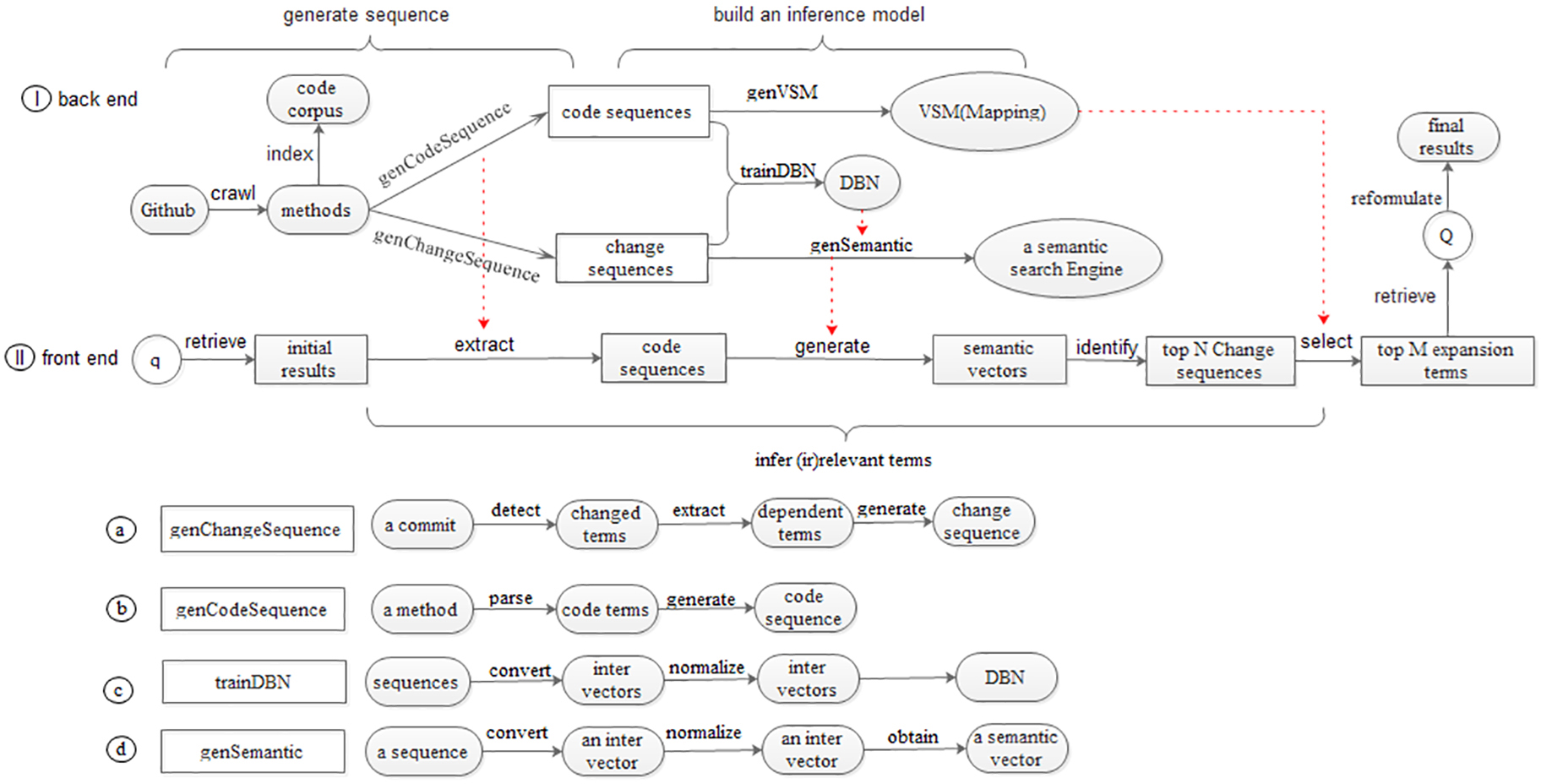
Code corpus and change commits
As shown in Fig. 3I, we crawl and parse 590,321 methods from 625 open source projects on GitHub. For each method, we extract code terms with Java Development Tools (JDT2), and convert them into a bag of index words with the text pre-process techniques [5] (e.g., standard tokenization, stop term removal, identifier splitting and stemming). To build a code corpus with Lucene 2.9.1,3 we index all methods as documents containing two fields: index words and method body. On receiving a query, the search engine calculates BM25 textual similarity scores [6] between a query and the index words. According to the scores, query results are ranked in descending order.
For each method in the code corpus, the change commits could be obtained from Github. In the split view, the commit is in the form of the commit (
Change sequences
From the commits of each method, we generate change sequences containing changed terms
<label> represents the textual information of AST nodes limited to three types: 1) nodes of method invocations and class instance creations; 2) declaration nodes, i.e., method declarations, type declarations, and enum declarations, and 3) control-or data-flow nodes such as while statements, catch clauses, if statements, throw statements, etc. Control-flow nodes are recorded as their statement types, e.g., an if statement is simply recorded as if. <role> has two options that decide if this term is changed or dependent. <operation> has three operations deciding if the term is unchanged, new or deleted in the code change.
In Fig. 3I we describe a function genChangeSequence that inputs a commit of a method, outputting change sequences. The details are as shown in Fig. 3a. It contains three steps: detecting changed terms, extracting dependent terms and generate change sequences.
To detect
Code sequences
In Fig. 3I we describe a function called genCodeSequence that inputs a method, outputting a code sequence. The details are as shown in Fig. 3b. It parses three types of code terms from each method in the code corpus, just like genChangeSequence, and put them in sequence to generate the code sequence. As a result, the roles and the operations of all terms are “dependent” and “unchanged”, respectively. Notably in the code sequence all code terms are dependent while in the change sequence some are changed, some are dependent.
Build an inference model
After obtaining the change and the code sequences, we convert them into vectors of terms, and input these vectors to a deep learning algorithm [8], namely DBN [9], train and learn semantics of sequences automatically. Finally, we build an inference model to infer the fine-grained changes.
Map terms
Since DBN requires input data in the form of integer vectors, we build a mapping between integers and terms, converting the change and the code sequences to integer vectors.
In addition, DBN also requires the lengths of the input vectors must be the same. Since our integer vectors may have different lengths, we append 0 to the integer vectors, making all lengths consistent and equal to the length of the longest vector. Adding zeros does not affect the results, and it is simply a representation transformation making the vectors acceptable by DBN.
To achieve the mapping, in Fig. 3I we describe a function called genVSM that inputs all code sequences, outputting a Vector Space Model (VSM) that not only allocates a unique integer identifier for each non-duplicated term in a code sequence, but also calculates the TFIDF value given a term. TF-IDF is often used to determine the importance of a term for a particular document in the corpus [10].
Train DBN and generate semantics
In Fig. 3I we describe a function called trainDBN which accepts sequences as input and outputs a trained DBN. The details are as shown in Fig. 3c. First we convert the change and the code sequences to integer vectors based on the mapping. However, DBN requires the values of integer vectors ranging from 0 to 1, while data in the integer vectors can have any integer values. To satisfy the input range requirement, we normalize the values in the integer vectors of the sequences by using min-max normalization [11]. With the normalized integer vectors we train DBN while tuning 3 parameters: 1) the number of hidden layers, 2) the number of nodes in each hidden layer, and 3) the number of training iterations. We show how to tune these parameters in Section 3.3.
After training a DBN, in Fig. 3I we also describe a function called genSemantic that inputs a sequence and a trained DBN, outputting a semantic vector as the semantics of the sequence. The details are as shown in Fig. 3d. We map a sequence to an integer vector, normalize it, and feed them into the DBN, obtaining semantics of sequences from the output layer of the DBN. Here, as shown in Fig. 3I, we invoke genSemantic to generate semantic vectors of all change sequences, storing them in a semantic search engine.
Retrieve query results
We introduce a two-pass retrieval approach to retrieve query results.
First-pass retrieval: On receiving a query
Inferring changed terms: Given each initial result, we invoke genCodeSequence to extract its code sequence (see Section 2.1.3). Then we invoke genSemantic to generate its semantic vector (see Section 2.2.2). Next we compare the semantic vector of the initial result against the semantic vectors of all change sequences in the semantic search engine based on the cosine similarity, identifying top-
Second-pass retrieval: With the selected changed terms we reformulate the query. If the <operation> of a term is “new”, we see it as relevant term and expand a query with its <label>. If the <operation> of a term is “deleted”, we see it as irrelevant term and remove its <label> in a query. With the reformulated query
As shown in Fig. 3II, we describe a function called querySearch that inputs a query, outputting a ranked list of the most relevant query results.
Evaluation
Preliminary
Queries generation strategy
To obtain a large number of queries, we propose an artificial queries generation strategy (GenQueries) that inputs a method-level code snippet
Q&R pair generation strategy
To create a large number of benchmark dataset, we propose an artificial Q&R pairs generation strategy (GenQRPair) that inputs a query, a search mode and a ranking mode, outputting a Q&R pair in the form of (
For the first step, there are many search modes, such as “Manual”, “None”, “SC”, “CC”, “API” or “CK”.
Manual: a query is performed manually;
None: The search engine performs a query without QE methods;
SC: It inputs a query into querySearch, outputting query results (see Section 2.3).
CC, API or CK: It expands a query with code changes, APIs or crowd knowledge, outputting query results.
For the second step, there are many ranking modes, such as “Manual” or “AutoLabel”.
Manual: the query results are ranked manually;
AutoLabel: the query results are ranked with the automatic Labeling strategy (see Section 3.1.3).
Automatic labeling strategy
To determine whether 2 pieces of code snippets are relevant or not, we propose an automatic labeling strategy (AutoLabel) that inputs 2 pieces of code snippets
where matchingNodes(
2) Based on the similarity score, label the relevance rating with Four-level Likert scale [6], including most relevant, relevant, irrelevant, most irrelevant.
Given a Q&R pair, in the form of (
These metrics are
where
NDCG measures the ranking capability of the search algorithm. The algorithm is more relevant when there are more relevant results in the higher positions in the hit list. It is calculated as:
where NDCG@K is DCG@K normalized by IDCG@K. IDCG@K is the ideal DCG@K. Results are sorted by the relevance scores.
Code corpus
Following the steps in Section 2.1.1, 590,321 method-level code snippets from the 625 open-source projects on Github are indexed. The 625 projects include 6 deeplearning4j libraries,7 8 popular libraries from Anh’s work [8], 295 popular android open-source java projects,8 173 Google Samples labeled with the “java” tag,9 143 Java API examples.10
Benchmark datasets
In the code corpus, all code snippets are sorted in the chronological order. We make 50% most recent code snippets as benchmark dataset. Table 1 shows 1) as a training set, the oldest 60% in the dataset are used for generating VSM and training DBN; 2) as a tuning set, the older 30% are used for generating 265,644 artificial Q&R pairs, tuning 3 parameters of DBN; 3) as a testing set, the newest 10% are used for generating 88,548 artificial Q&R pairs. This is how it happened. Given each code snippet
Benchmark dataset
Benchmark dataset
Note that some may not convince such artificial Q&R pairs in two aspects as follows:
They think artificial queries generated from source code couldn’t reflect the real-word situation. To make such queries close to the real queries, we perform the random sub-selection, increase the number of such sub-selections and even average the results of the testing set to get one representative prediction-quality measure (see Section 3.1.1). Especially, we add irrelevant terms (i.e., changed terms with the <operation> marked “deleted”) to the artificial queries. As Proksch et al. [12] reported in 2016, real queries don’t achieve the accurate code search because they contain irrelevant terms that were missing, changed, or got removed in the code change. Besides, a large number of artificial queries could result in valid statistics results to reflect the real-world situations to some extent. Despite a few corner cases, they make up only a small percentage without any impact on measure results.
They think it is not reasonable to rank artificial query results with AutoLabel that implies the relevance score between a query and query results is calculated just with the code term similarity between query results and the original code snippet that generates a query (see Section 3.1.3). Actually, it is reasonable. The underlying idea behind it is that if a piece of code snippet cannot be found with the artificial queries generated by itself, it won’t be found with other queries either easily.
Although we can invoke trainDBN to train DBN (see Section 2.2.2), many DBN applications [13, 14, 15] report that an effective DBN needs well-tuned parameters, i.e., the number of hidden layers, the number of nodes in each hidden layer, and the number of iterations. It implies we need to tune three parameters by conducting experiments with different specific values of the parameters.
Given an experiment, we invoke trainDBN to train DBN with respect to the specific values of the 3 parameters on the training set. Then we invoke genSemantic to generate semantic vectors of all change sequences, storing them in a semantic search engine (see Section 2.2.2). Next we invoke AE that inputs each Q&R pair in the tuning set, the search mode of “SC”, the ranking mode of “AutoLabel”, outputting two metric values (see Section 3.1.4). Based on the values we evaluate the specific values of the parameters. About how to set different values of three parameters, we have two steps as follows.
Step 1: Setting the number of hidden layers and the number of nodes in each layer
Since the number of hidden layers and the number of nodes in each hidden layer interact with each other, we tune these two parameters together. For the number of hidden layers, we experiment with 8 discrete values include 10, 20, 50, 100, 200, 500, 800, and 1,000. For the number of nodes in each hidden layer, we experiment with eight discrete values include 20, 50, 100, 200, 300, 500, 800, and 1,000. When we evaluate these two parameters, we set the number of iterations to 50 and keep it constant. By repeatedly conducting experiments with different values of the parameters, as a result, we choose the number of hidden layers as 10 and the number of nodes in each hidden layer as 100. Thus, the dimension of the semantic vector is 100.
Step 2: Setting the number of iterations
The number of iterations is another important parameter for building an effective DBN. During the training process, DBN adjusts weights to narrow down error rate between reconstructed input data and original input data in each iteration. In general, the bigger the number of iterations, the lower the error rate. However, there is a trade-off between the number of iterations and the time cost. To balance the number of iterations and the time cost, we conduct experiments with 10 discrete values for the number of iterations. The values range from 1 to 1,000. We use error rate to evaluate this parameter. By repeatedly conducting experiments with different values of the parameters, as a result, we set the number of iterations to 200, with which the average error rate is about 0.134 and the time cost is about 23 seconds.
Setup
QESC
For all code snippets in the training set, according to the name of each method-level code snippet, we extract their Github commits. Then we invoke genChangeSequence and genCodeSequence to extract their change sequences (see Section 2.1.2) and code sequences (see Section 2.1.3), respectively. Based on these sequences, we invoke genVSM to generate VSM containing a mapping (see Section 2.2.1). With the code and the change sequences, we train and tune DBN as Section 3.3 said. After preparing VSM, the trained DBN with the best specific values of the parameters, we invoke querySearch that inputs a query, outputting query results (see Section 2.3). Actually, this is the search mode of “SC” described in Section 3.1.2.
QECC
In order to evaluate whether DBN, a deep learning, is useful for code search or not, we make QECC (omitting DBN) to compare with QESC (using DBN). Actually, QECC is also proposed by us in 2018 [16]. It is similar to QESC in terms of principle, but the inference model is different. The former leverages a statistical method while the latter leverages a deep learning.
First, QESC trains DBN that considers the semantics of the change sequence (see Section 2.1.2). However, QECC trains a
Second, QESC infers expansion terms for a query based the semantic similarity between initial results and each change sequence (see Section 2.3). QECC infers expansion terms based on
CodeHow
According to the name of each method in the code corpus, we extracted API name and description (i.e., FQN, summary and remarks) from MSDN and other online documentations11 (i.e., “Workbench User Guide”, “Java Development User Guide”, “PDE Guide”, “Platform Plug-in Developer Guide” and “JDT Plug-in Developer Guide”). After indexing them, we implement CodeHow that identifies the top 5 of relevant APIs that match a query: 1) compute the similarity between the API name and the query as well as the similarity between the description and the query; 2) combine two similarity values and 3) return the potentially relevant APIs. With the identified APIs and the original query it generates Boolean query expressions and retrieve query results with Extended Boolean model (EBM) [17]. Actually, this is the search mode of “API” described in Section 3.1.2.
QECK
According to the name of each method in the code corpus, we collected the questions with the “android, java” tags posted by users and the accepted answer with “AcceptedAnswer” from the Stack Exchange Data Dump,12 and generated Q&A pairs consisting of words and SO score. The words are the text in question and answer. The SO score is a weighted mean value between the individual scores of the question and the answer voted by crowd. After indexing Q&A pairs, we implement QECK that identifies the top 5 of relevant Q&A pairs that match a query: 1) compute SO score and Lucene score that is the similarity between the words of Q&A pair and the query; 2) combine 2 similarity values and 3) return the potentially relevant Q&A pairs as Pseudo Relevance Feedback (PRF) documents. From these documents we extract the top 9 of the software specific words with the high weighting of TF-IDF. With the identified words we expand the original query and retrieve query results with BM25. Actually, this is the search mode of “CK” described in Section 3.1.2.
Results and analysis
Following the steps in Section 3.4, we implement QESC, QECC, CodeHow and QECK, conducting experiments to answer three research questions (RQs). For drawing confident conclusions whether our approach is really effective, we conduct a statistical test to compare the mean values of two metrics in the experiments. Specifically, we conduct the 2-sided Wilcoxon’s signed rank test between two results. When comparing each pair of results, the primary null hypothesis is that there is no statistical difference in the performance between two results. Here, we employ the 95 percent confidence level (i.e., the
RQ1:
Is QESC better than the state-of-the-art QE methods when facing the queries that none has executed?
We employ AE (see Section 3.1.4) that accepts each Q&R pair in the artificial testing set, the search mode of “SC” for QESC, “API” for CodeHow, “CK” for QECK, and the ranking mode of “AutoLabel” as input, outputting the values of two metrics. Based on the values we compare QESC against CodeHow and QECK.
From Table 2, we can see all
Mean of two metrics of three methods
Mean of two metrics of three methods
The “
This is a fair comparison because none of QESC, CodeHow and QECK has ever executed these 88,548 artificial queries. The reasonable results show QESC is better than others. Take
Three expansion queries generated by CodeHow, QECK and QESC
Table 3 lists how to expand a query to recommend
This example illustrates 1) QESC can exclude the irrelevant terms while CodeHow and QECK cannot; 2) QESC adds relevant terms while CodeHow and QECK would add irrelevant terms. This is because the terms provided by QESC originate from the inside of the method while the terms provided by CodeHow and QECK originate from the outside of the method, such as MSDN and Stack Overflow. It explains why QESC is better than CodeHow and QECK.
RQ2:
Is the DBN, a deep learning, effective?
Answers to this research question will shed light on whether DBN, a deep learning, is useful for code search or not. Thus we compare QESC (using DBN) against QECC (omitting DBN). We employ AE that accepts each Q&R pair in the artificial testing set, the search mode of “SC” for QESC, “CC” for QECC, and the ranking mode of “AutoLabel” as input, outputting the values of two metrics. Based on the values we compare QESC against QECC.
The performance of the baseline QESR, vs. the performance of the QECC
The “
From Table 4, we can see all
Although QESC is effective, some methods are still difficult to find. For example, some methods have only a few changed terms to expand, which do not work in QE. For another example, some methods have no changed terms to expand. Maybe the methods have no change commits on Github as they have never evolved. Maybe the methods have change commits but these commits are not popular and omitted directly, such as the method “openDirectory”. When we judge what kind of commits could be collected, we consider only the “Star” but not time interval which cannot reflect the attention effectively. Some new commits are not always cool. Instead, the “Star” can reflect the attention. The more attention the change accepts, the more people are likely to make the change. In this paper, we collect the commits with “Star” greater than the threshold
Related work
Recently, many deep learning methods have been proposed [18] applied deep convolutional neural networks into image-net classification [19] focused on diagnosing gear faults in induction machine systems [20] put emphasis on LSTM recurrent networks itself. Therefore, we use deep learning for solving the problem of code search in software engineering.
In 2018, we proposed a novel QE technique with code changes (QECC) [16]. Now, by employing DBN a deep learning, we propose a novel QE technique with the semantics of change sequences (QESC). Although they apply the regularity of code changes to QE methods, there are five differences.
The original intention is different. Code changes in QECC are used to infer users’ coding intent (i.e., what users want). However, those in QESC are used to avoid the over-expansion (i.e., expand a query with irrelevant terms).
The effect of QE is different. QECC only add the expansion terms that represent user needs. However, QESC not only add relevant expansion terms, but also exclude irrelevant ones in the original query.
The training data is different. Although both of them need to detect changed terms and extract dependent terms, QECC exploits (changes, contexts) pairs while QESC generates code sequences. In a pair, changes are separated from contexts. A code change and a change context are defined as a triplet of (<operation kind>, <AST node type>, <label>) and a tuple of (<AST node type>, <label>, <change>, <distance>), respectively. In a code sequence, changes and contexts are both put together in order. They are uniformly defined as a triplet of (<label>, <role>, <operation>). In addition, for the node edits, QECC considers only inserts, updates and moves. Beside these, QESC also considers deletes.
The training method is different. QECC trains a statistical word alignment model Pr (changes|contexts) by applying a machine learning (ML) algorithm called expectation maximization (EM) algorithm. However, QESC trains DBN model by applying a deep learning algorithm. As a result, QECC only capture which changes occurred while QESC also understand why changes occurred by learning the semantics of code sequences. Faced with “if, while” and “while, if”, only QESC could distinguish them. QECC can’t because the occurrence frequencies of “if, while” and “while, if” are identical.
The inferring of changes is different. Give initial results, QECC extracts code terms from them, seeing them as dependent terms to infer changed terms with Pr (changes|contexts). In the same case, QESC converts them into semantic vectors with DBN, inferring the changes semantically similar to them.
Conclusion
We propose QESC to apply the change sequences to QE methods. It expands the query with relevant terms and remove irrelevant terms in the query.
Footnotes