
Abstract
Mexico’s National Institute of Statistics and Geography (INEGI) is exploring new opportunities to improve its information search service, with the aim of increasing the accessibility of official statistical data. The upgraded search engine will include a new component that offers more sophisticated search capabilities. These include the ability to conduct intelligent searches that do not require an exact match of the search text, as well as the expansion of searches using related ad-hoc terms. Additionally, the new component will provide feedback through the most appropriate relations. To achieve this, the system will utilize neural network-based distributional word representation systems to identify relationships between related terms. The vector spaces and representation will be manipulated to keep connections within the most relevant vocabulary for the institute’s type of searches. The usability testing department at the institute conducted blind pilot tests to compare the quality reported by users with and without the new enhancements. Although the evaluation survey showed significant improvements in the search engine’s performance, the tool presented is just the first step towards a system that allows continuous interaction and feedback with users to improve the quality of the responses presented. This strategy is not currently implemented by the institute, making this an immediate and easy-to-replicate approach for obtaining useful interactions with users.
Introduction
Official statistical institutions not only produce reliable statistics, but they also have the crucial task of disseminating and making this information accessible to the public. This holds true for Mexico’s statistics institute (INEGI) as well. It is important to ensure that the statistics produced are “fit for use”, taking into account that different users have different needs and preferences for accessing data. One of the most popular ways for users to obtain statistical information is by using the search engine on the official website, which serves as a primary entry point and is therefore essential for dissemination purposes. However, the economic statistics system is complex and includes many vague or overlapping terms, definitions, metadata, and categories, making it challenging for non-expert users to locate relevant data [1].
Fake news has become a widespread issue due to the rapid growth of data creation and the abundance of technology and media for transmitting information. As a result, many sources other than official statistical agencies produce data without adhering to the quality requirements demanded of statistical institutes. Communication moves at a breakneck pace in the current world, and social networks have become common tools for information transfer. Official statistical programs struggle to keep up with the pace of dissemination necessary to reach all those interested in the data. However, this task is essential for institutes to maintain trust in official statistics. It is necessary for producers to take a proactive role in satisfying not only the content needs of users but also ensuring easy access to the statistics generated [2]. For this reason, changes are being made to prevent leaving anyone behind, following the philosophy of the Sustainable Development Goals (SDGs) [1].
According to Saebo et al. [2], coherence, accessibility, and clarity are the most crucial quality dimensions that official statistics institutes should improve. Site search engines contribute significantly to these three qualities.
Background
Information Retrieval (IR) is a fundamental task in many applications, including the deployment of digital libraries, web search, and specialized information query. In the case of official statistical information query, the role of search engines is particularly important. Essentially, an information retrieval system seeks to provide users with relevant sources of information for a given query. To achieve this, information retrieval systems use various tools, such as geographic location, history of commonly used queries, and context of the user’s searches.
Guo et al. [3] classify the most important applications of IR as ad-hoc, question answering, community question answering, and automatic conversation. Our problem falls into the ad-hoc category, in which users have a specific piece of information they are searching for from a query, and the system offers documents that are likely to contain relevant information for the user. Specialized tools like Lucene and Anserini can be used to solve these types of tasks [4, 5].
Deep learning models have been successfully employed for ranking results within the IR task [3], which aims to measure the significance of a document for a given request. Recently, deep neural networks have made remarkable advancements in various areas, such as speech recognition [6], computer vision [7], and natural language processing (NLP) [8, 9, 10]. These methods have resulted in effective distributional systems that abstract the content of words into vector representations.
However, it is essential to bear in mind that the concept of document “relevance” to a query is somewhat ambiguous and difficult to assess even for a human expert in the field. This is because it is based on the cognitive process of the information seeker, which is highly dynamic and subject to change based on various factors, such as geographic area, time and date, and even the particular situation of the user.
Current procedure
In 2020, an INEGI opinion survey showed that 54% of users were able to find the information they were looking for on the site. This is an improvement from the 49% indicator recorded in 2017, when an earlier version without a search engine was available to the public. However, the bounce rate, which refers to the percentage of users who leave the site shortly after viewing a single web page, was 69% in 2019. These metrics suggest that there are still opportunities to improve information accessibility.
Currently, the site’s search engine employs a keyword-based approach that is supplemented by term expansion from thesauri. This type of search engine is effective when users already know how to structure their queries to find the information they need. For instance, it makes it easy for users to locate the Uniform Resource Locator (URL) of an Information Program they are familiar with by entering the program’s name, acronym, or a portion thereof. However, natural language queries often fail to produce the expected results or any results at all.
INEGI has committed to following several metadata standards, including the Statistical Data and Metadata Exchange (SDMX) framework, which focuses on human understanding through descriptive text. However, this framework does not facilitate information dissemination or access for users who do not have a deep understanding of these frameworks, and much information is not adequately framed due to the cost of maintenance [1].
Collections are available for training and evaluating IR systems for ad-hoc information retrieval tasks, such as the resources provided by the Text REtrieval Conference (TREC) [11, 12, 13]. However, one common feature of such corpora is that documents typically contain a considerable amount of text (at least several paragraphs) that includes relevant information. Zhao and Callan’s work [14] clearly demonstrates the importance of key terms appearing in a document, terms that are expected to be present within the documents, a characteristic that can be largely assumed when working with relatively long documents.
The situation is different for INEGI and other search engines that operate in the domain of official statistics. While the need for information is also ad-hoc, the relevant data is usually in tabular form, resembling a relational database more than a document database. The search engine often has access to nothing more than the resource title, and occasionally a brief description in the metadata. The main challenge with this kind of information retrieval is that the expressions and vocabularies used in the databases are very different from the way users search for the data. Additionally, there is very little interconnection within the consulted documents and the queries themselves.
As a result, the outputs of systems like Lucene or Anserini [4, 5] are not always applicable to this type of application. These systems have not been successful in producing good results for INEGI’s use case, which has prompted the search for a customized solution.
Related work
Full process of the proposed method of query expansion via condensed word-embedding. The dotted line indicates both the data and the flow followed for obtaining a word embeddings model, while the solid lines indicate the data and the flow for obtaining the model for query expansion.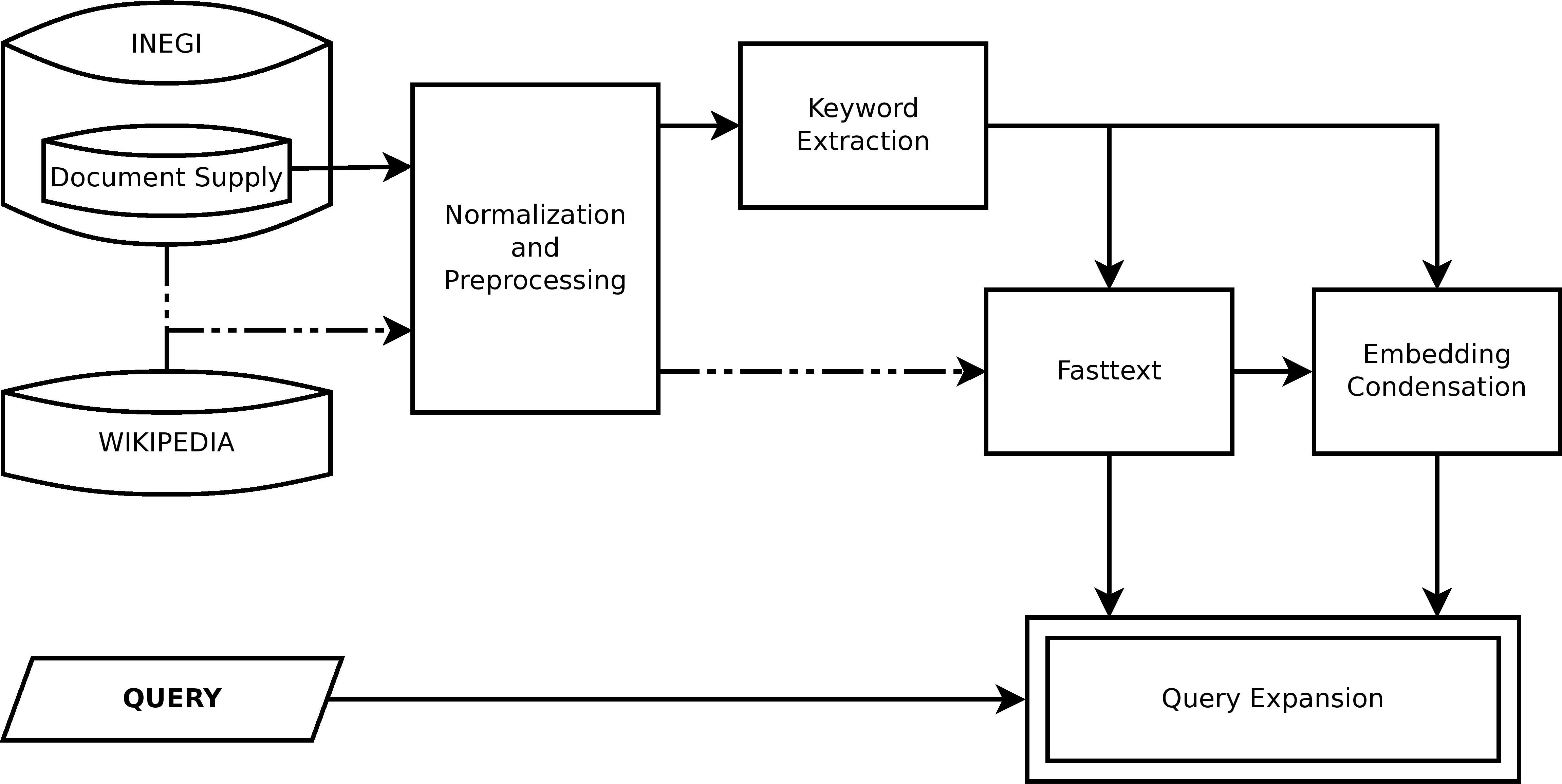
Query expansion is the process of adding terms to a user’s search query in order to improve the likelihood of finding relevant search results. Automatic query expansion involves identifying relevant relationships between words to expand the query’s vocabulary.
In works such as Xu and Croft [15], the issue of mismatched words between information queries and documents is explored. Their approach involves using the same documents available to the user as a source of information to identify additional relationships between words that can be added to the query. This underscores the importance of limiting the search vocabulary to the vocabulary of the information available, which is similar to training specialized embeddings that focus on contextual similarity relationships within the text.
The search for relationships and new terms for query expansion has been explored using thesauri, synonyms, statistical and co-occurrence-based techniques, as discussed in Section 3[16, 17, 15, 18]. While INEGI has already implemented some of these strategies with good results, the use of thesauri is limited by their coverage. In general, statistical expansion has shown more promising results compared to synonymic expansion, due to better resource coverage. However, lexical resources can still be useful for index creation and synonymic expansion in well-defined domains, such as geographic information [17].
The field of user search is incorporating NLP and computational learning methods for semantic characterization of search parameters and information retrieval, and statistical offices are keeping up with these advancements. Advanced projects have already developed chatbots that process statistical information requests and provide on-the-fly results [19]. Other national statistical offices have proven the effectiveness of applying these techniques to search for statistical and geographic information, and their implementation could significantly improve the accessibility of information for INEGI’s users.
Semantic similarity is a branch of computational linguistics that examines the relationships between words and their meanings within a particular context. It has been observed that words that appear in similar contexts tend to have similar meanings. The distributional hypothesis, which states that synonymous words tend to occur in the same environment and share contexts with other words, was first proposed in the 1950s [20].
In recent years, with the rise of Artificial Intelligence and Machine Learning, models that analyze the semantic similarities between words have become increasingly popular. The most successful models include Word2vec [21], GloVe [22], and FastText [23], all of which use word embeddings.
FastText, proposed by Facebook, is unique in that it can generate representations for words that were not previously seen by the training algorithm. FastText has been successfully used in tasks such as Hierarchical Text Classification [24], identifying corresponding activities in process modeling tasks [25], and multi-source social media text classification [26].
Neural networks have also been used for Information Retrieval, particularly for ranking the results of a query. Interestingly, one of the major advantages of neural networks for result ranking is their ability to obtain dense representations that can connect vocabulary words that are different from those in the query [18].
As previously mentioned, query expansion involves adding terms to a user’s query to increase the likelihood of finding relevant results. The proposed method aims to achieve this expansion through a condensed word embedding that focuses on the most important information related to the keywords of interest.
A general diagram of the proposed process is depicted in Fig. 1. In the subsequent sections, each of the steps involved in the method will be described in detail:
Normalization and pre-processing The keyword extraction and embeddings building Query expansion
Normalization
As depicted in Fig. 1, the pre-processing step involved in constructing condensed word-embeddings requires relevant data input specific to the intended use of the information retrieval (IR) system. In our study, we focus on retrieving official statistical information, and thus, we seek to establish the primary source of relationships in all the available information from INEGI.
However, the quantity of data solely available from this source is limited and of a technical nature. This results in a restricted vocabulary, which in turn hinders effective term expansion. In order to increase the vocabulary size and thereby improve the term expansion, we augment the data set with the Spanish Wikipedia.1 Wikipedia is an encyclopedia that is collaboratively edited and freely available. Its encyclopedic nature provides access to specialized terms, while its collaborative nature incorporates colloquial terms. This unique combination makes Wikipedia an attractive option for connecting words in the construction of embedding models, beyond that, it has also a significant amount of data to generally support the model, in total 3.6 GB of just text was extracted. We combine the Wikipedia full dump from January 2020 with all textual information available from INEGI to create word-embeddings that can leverage both INEGI’s specialized and statistical nature and Wikipedia’s colloquial vocabulary.
As depicted in Fig. 1, both sources of information undergo a normalization and pre-processing stage before obtaining a word-embedding. The dotted line in the diagram represents this common path. Additionally, the diagram shows the normalization of a subset of the INEGI database that will be offered to the user in response to a query. While the pre-processing executed is the same for both cases, the results follow different paths. The bulk of the data is used to train the fasttext model, while the subset of the offer is used for later keyword extraction, condensation of the embeddings model, and final query expansion.
As there are multiple sources of information, such as Wikipedia and several internal INEGI collections, it is crucial to normalize all obtained data. For Wikipedia, we extracted plain text and removed all markup formatting and structure using the wikiextractor tool.2 We also transformed the entire text collection to lowercase and used UTF-8 encoding. Additionally, we utilized the Freeling library [27] with Spanish configuration to segment sentences and tokens, identify multi-word terms, and filter out numerical expressions and dates.
Ad-hoc space vector
The core of our query expansion strategy is a modified version of word embedding that is adapted and restricted to the target information (the supply) in order to narrow down the relationships it is able to find.
To train a custom word embedding for the context of the statistical information, we use the data set from all normalized sources as seen in Section 5.1 (following the dotted line in the diagram of Fig. 1). We use version 0.9.2 of the original fastText implementation developed by Facebook,3 with the parameters of 50 epochs and an embedding dimension of 300.
Given the nature of the task to be solved (IR), the end system expects to obtain a query from a small number of words from the end user. There is no restriction on either the social context of the user or the nature of their query, so a wide variety of both vocabulary and word spelling variations can be expected with little context to work with. With this in mind, we propose the use of Fasttext[23], an embeddings model that focuses on obtaining word-level vector representations, and which also has the ability to handle sub-word information, a fundamental feature to allow for the written variation and small differences that can be found between the training vocabulary and user queries.
While a complete fasttext model gives us the possibility to search for words related to a given term, there will be a logical problem when trying to apply this search in a limited context such as INEGI’s data supply, since it is a general model with general relations. The related words for a consulted term can expand into different areas or domains that are not of interest for a query expansion, and that could even cause confusion and detract from the user’s experience.
For this reason, we propose to use a second model that is specially built for the expansion, which is an ad-hoc condensed version of the first model focusing only on domain-relevant terms. Hence, the Keyword Extraction module shown in the diagram in Fig. 1 takes care of the search for the most important terms that can be found in the INEGI information supply. That is, if the entire vocabulary of the training texts is located within the original embedding vector space, the objective of the ad-hoc vector space is to reduce this vocabulary, so that only relevant terms for the search engine remain in the condensed embedding.
Our expansion strategy involves distinguishing relevant terms for the search engine, and the method proposed for doing so is straightforward. We extract all content words from the headings of the documents in the data supply. Metadata from all the pages that the search engine is able to display is utilized to detect every available title. We assume that if a word is found in a title, it is a keyword for that output. Of course, titles also contain unimportant words, so only content words are taken into account, a process that is carried out with the help of Freeling [27].
To find the closest terms, as is done with any other embedding, our extracted keywords must be located in a vector space. In addition, to take advantage of the relations found with the complete corpus, our keywords must be located in the same vector space as the complete model, without the rest of the vocabulary being present.
To achieve this, we propose filtering out all elements from the original fasttext model that are not part of the keywords found in the titles. The gensim library was used for this process, as it can work with several word embedding models, including fasttext. In particular, the “FastText” module in gensim allows for the generation of a model with its vocabulary explicitly assigned. The algorithm for this process is as follows:
Load the fasttext model that was trained with the complete corpus with gensim. Extract the embeddings matrix from that model. Traverse the entire matrix and remove the vectors of all the elements that are not part of the relevant terms. Generate a new model with gensim FastText. Initialize the new model with the matrix resulting from step 3. Assign the vocabulary to the new model using only the keywords.
Demographic profile of the participants surveyed for the evaluation of the new version of the search engine. From left to right, the distribution by gender, age and educational level is shown.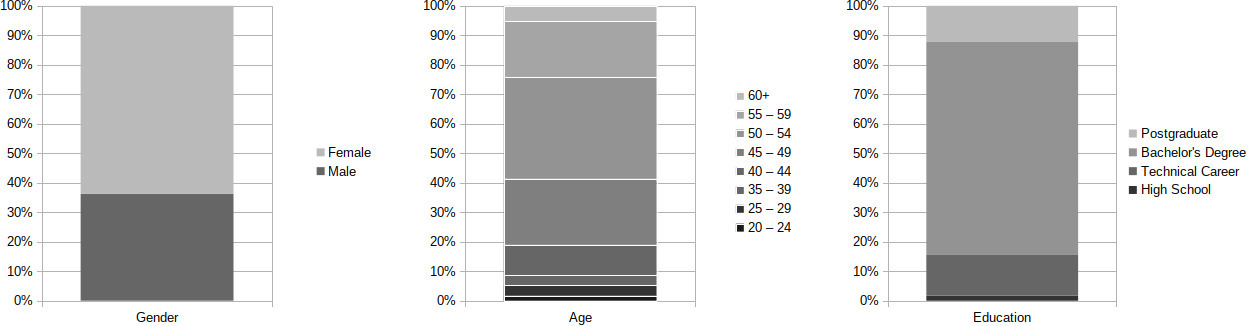
Since the model is not retrained, this process allows maintaining the same “positions” of the vocabulary of interest within the vector space with respect to the rest of the words, even if those words are no longer found within the model, but this equivalence is necessary for the next part of the search engine expansion process.
The query expansion process, as illustrated in Fig. 1, requires three elements to be executed:
The original fasttext model The condensed model The query
Given that the condensed model includes the terms from titles that we consider significant, the key now is to identify the most analogous terms between those and the words in the query. The first step is to obtain the query’s vectors, which is a straightforward process since word embeddings are specifically designed to vectorize words. Moreover, Fasttext has the advantage of generating vectors for previously unseen words during training.
To obtain the vector of the query terms, we need to use the model trained on the entire corpus, as it contains the largest number of words. If the query matches any word in the model’s vocabulary, the vector can be obtained directly. However, even if there is no match, the complete model is still the best source of sub-word information to build an embedding for an unknown word.
Once the query vector is obtained, we can then use the condensed model. The “FastText” module of gensim provides an effective function for this task, called “similar_by_vector.” It helps to identify words that are most similar to a vector within the space, rather than terms that are most similar to another word. Since the vector spaces are the same, we can use the vector from one model to query the other.
By doing so, we can obtain the most similar terms, but only considering the ones previously identified as keywords. These similar terms are the ones recommended by the system for query expansion.
Comparing search engines
Comparatives of the search engine with expanded search terms. The first graph show the aggregated results, while the rest of graphs show the result for specific types of queries.
INEGI comprises several independent departments that work collaboratively to execute the institution’s projects. This independence reinforces the robustness, reliability, and expertise of each department’s processes. The Usability Management Department is responsible for developing the evaluation methodology for prototypes, as well as conducting the evaluation prior to their release for use by the general public.
The evaluation methodology was conducted from November 19 to 26, 2021. The sample of users for the tests was drawn from the institute itself, specifically from the nationwide staff that provides customer service to users who use the data offered by INEGI on a daily basis and are familiar with our users’ needs regarding the most common queries and information searches. In terms of the participants’ demographic profile, we had 21 men and 37 women, mostly aged between 45 to 59 years old and with an average education level of a bachelor’s degree. Figure 2 provides a detailed breakdown of the respondents’ characteristics.
The tests were conducted through the Teams4 platform, with a moderator from the Usability Management Department interacting live with the participants to direct the thematic of the queries, which the users could generate organically. Additionally, they were asked to complete a Google form5 to record their scores and their perceptions of the responsiveness of the search engine version they were interacting with. The 58 participants were randomly assigned to two groups of 29 each, with one group using the Search Engine and the other group using the Augmented Vocabulary. They then provided their perceptions of the findings for 10 queries, choosing one of four alternatives:
Matches expectations Contains in part what is expected Does not match expectations Does not offer information
Figure 3 shows the comparative results between the two versions of the search engine. For a general aggregated result, Fig. 3a shows a significant increase of about 53% in the “Matches expectations” category, where the user obtains results that match what is expected. This increase is also seen in the “Does not match expectations” and “Does not offer information” categories, with decreases of 26% and 49%, respectively, when including the auxiliary vocabulary in the search engine.
To determine the statistical significance of the change, a
As the main objective of adding this auxiliary search tool is to improve the user experience, we conducted an additional binary statistical test: Fisher’s exact test with an alternative hypothesis of greater positive results. Two of the possible answers were considered negative, “Does not match expectations” and “Does not offer information,” and two were considered positive, “Matches expectations” and “Contains in part what is expected.” A
By analyzing the five types of searches that were conducted for the perception tests, we can also observe a more detailed comparison. The queries were categorized based on their context of security, economic indicators, health, economic activities, and a free search. Participants were instructed to use terms that relate to these contexts, such as “Feminicides”, “Census”, “Comorbidity” or “DENUE”.6
The figure demonstrates the comparison of the responses for the five contexts, with and without the augmented vocabulary. Applying the augmented vocabulary, we achieve a much more uniform distribution across all categories, with most of the responses falling into the “Matches expectations” category and very few in the “Does not offer information” category. Once again, we can use statistical tests to examine the impact of changes in topic on search behavior and the effectiveness of the augmented vocabulary. In each of the subsets, we use the same pair of statistical tests as in the general case: a
Figure 3b presents the results for the security queries, and a
For searches related to economic indicators, we obtained a
The results for health-related searches are presented in Fig. 3d. Here, we find another favorable case where the
Continuing with the searches related to economic activities, presented in Fig. 3e, we found that the
The same is true for the last category, presented in Fig. 3f, where the queries had no relationship, and participants had complete freedom. We obtained a significant difference between the distributions with a
Finally, the participants were asked to evaluate the entire search engine and provide an overall rating, with and without the enhanced vocabulary tool. An increase in the final evaluation was observed, from 6.9 without the expansion tool to 8.2 after including it. This difference is statistically significant, as a Student’s
Mexico’s statistics institute is exploring new opportunities to improve the information search service it offers to the public to enhance the dissemination of official statistical information. This new service component has been added on top of the current search engine to achieve greater outreach.
The new component has proven to be significantly better than the previous one. During blind testing, participants found that the new component generated more relevant results and reduced the number of unmatching or empty results. The overall performance rating improved from 6.9 to 8.2 with the expanded version. By filtering the most relevant vocabulary available and using it to create a condensed version of the space vector, the new system is capable of searching expansions within ad-hoc terms related to the initial search.
The new query expansion utilizes sub-word information embedded in the FastText model to offer more intelligent searches where an exact text match is not necessary. It is noteworthy that statistical tests proved significant differences in the performance of the new tool regarding the context in which queries were made. The health context provided the best results, while the lowest gains were seen in the security context. This information is useful in directing future research to explore the reasons for this discrepancy and seek targeted improvements.
Finally, users interact with the new component by providing feedback as they select the most relevant terms for expansion to continue their search. A quality compatible with future work that seeks to implement strategies that allow for immediate feedback in order to find better relationships between terms. As Hancock [1] noted, users demand models and structures in data that reflect the real world when searching for information. Although semantic web or other alternatives such as the analysis of search patterns could achieve this, their timeliness and cost may significantly limit them. With this proposal, the goal is to maximize available resources and take the first step towards a system that continuously interacts with and receives feedback from users. This approach facilitates a continuous improvement in the quality of the responses presented, following the philosophy of the Sustainable Development Goals and leaving no one behind.
Footnotes
DENUE refers to the Spanish acronym for the directory of economic units at the national level, an essential tool that the institute provides to the public.
Acknowledgments
We would like to express our gratitude to the Usability Management Department under the General Directorate of Dissemination and Public Information Service (Dirección General Adjunta de Difusión y Servicio Público de Información) for their invaluable support in the validation tests and results.