
Abstract
The attributes influencing the decision-making process in planning transportation of goods from selected facilities locations in disaster zones are considered. Experts evaluate each candidate for humanitarian aid distribution centers (HADCs) (service centers) against each uncertainty factor in q-rung orthopair fuzzy sets (q-ROFS). For representation of experts’ knowledge in the input data for planning emergency service facilities locations a q-rung orthopair fuzzy TOPSIS (Technique for Order Preference by Similarity to Ideal Solution) approach is developed. Based on the offered fuzzy TOPSIS aggregation a new innovative objective function is introduced which maximizes a candidate HADC’s selection index and reduces HADCs opening risks in disaster zones. The HADCs location and goods transportation problem is reduced to the bi-criteria problem of partitioning the set of customers by the set of service centers: 1) Minimization of opened HADCs and goods transportation total costs; 2) Maximization of HADCs selection index. Partitioning type transportation constraints are also constructed. Our approach for solving the constructed bi-criteria partitioning problem consists of two phases. In the first phase, based on the covering’s matrix, we generate a new matrix with columns allowing to find all possible partitioning of the demand points with the opened HADCs. In the second phase, using the generated matrix and our exact algorithm we find the partitioning –allocations of the HADCs to the centers corresponded to the Pareto-optimal solutions. The constructed model is illustrated with a numerical example.
Keywords
Introduction
Decision-making in the context of humanitarian aid distribution requires careful trade-offs between a number of conflicting objectives [5, 13]. Opening many HADCs would allow reducing transportation duration (which is composed of transportation time, docking, loading and unloading time of vehicles) of needed products from the distribution centers to the demand points. However, opening many HADCs would also require considerable human and material resources to operate them, which may be not appreciated and sometimes even impossible. In practice, nobody wants to bring more people (e.g., drivers, policemen, technicians) into the disaster zone than necessary because more people would require more food and water and would increase the need for coordination, as well as the potential risk to these people’s lives. On the other hand, opening a too small number of HADCs may result in insufficient capacities to meet people demand and thus leading to excessive non-covered (unsatisfied) demand.
Solution of location selection problem for HADCs is vital in minimizing of vehicle movement times and other traffic congestion arising from facility movement in extreme environment in disaster zones [1, 17]. In recent years, transport activity has grown tremendously and this has undoubtedly affected the travel and living conditions in difficult and extreme zones. It is clear that the location selection planning for HADCs in extreme environment is a complex decision that involves consideration of multiple attributes like maximum customer coverage, minimum service costs, least impacts on geographical points’ residents and the environment, and conformance to freight regulations of these points and others.
Timely servicing from HADC to the points of demand (for example, critically important objects of infrastructure) in extreme situations is a key problem of the service management system. Scientific studies in this direction are concentrated on the problems of decision making by distribution networks, which are known as a Vehicle Routing Problem (VRP) and a Facility Location/Transportation Problem (FLTP) [1, 13].
It should be noted that in the survey of literature the fuzzy approaches in VRP ([20–22]) and in FLTP ([6, 23–25]) for extreme situations practically do not exist, or they are practically on the beginning stage of development. The fuzzy multi-objective optimization problem [19, 23–26] and in our case fuzzy FLTP (FFLTP) [12, 32] simulation is very urgent, since the objective data of the model parameters do not always exist in the process of emergency. Therefore, our approach must be more feasible and reliable in the investigation of emergency service management [1, 19]. In our model, we mainly concentrate on a detailed realization of bi-objective emergency location and transportation problem under fuzzy (more exactly q-rung orthopair fuzzy [28]) information. We use q-rung orthopair fuzzy sets approach because this is much more convenient in describing and evaluations experts’ knowledge [27–29]. We also use fuzzy TOPSIS approach for evaluation candidate HADCs selection indexes. In our optimization model, based on the selection indexes we create new type objective function which determines risks of HADCs’ opening in a disaster region [8]. The TOPSIS approach was chosen for one simple reason. From the heuristic approaches developed in recent years that identify alternatives in decision-making models, the TOPSIS approach is characterized by stable, sustainable results and a fairly simple execution scheme. Besides, it is a practical and useful technique for ranking and selection from a number of externally determined alternatives through distance measures.
In Section 2 we give some preliminary concepts on q-rung orthopair fuzzy set theory. Multi-criteria decision making TOPSIS approach [15] for determining the index of selection of candidate HADC under the q- rung orthopair fuzzy information is developed in Section 3. The objective/subjective input data of the constructed model are described in Section 4. In Section 5, on the basis of the constructed fuzzy TOPSIS aggregation we formulate a new criterion –maximization of service centers’ selection index. Based on this criterion and the second criterion –minimization of the total cost of opened service centers a multi-objective facility location-selection partitioning problem with transportation constraints is constructed in Section 5. In Section 6, an exact approach to the solution of a bi-objective partitioning type problem is developed. In Section 7, a numerical example for illustration of the created model is given. A comparative analysis with respect to other methods is presented in Section 8. The main conclusions are given in Section 9.
Preliminary concepts
Intuitionistic fuzzy sets (IFS) were introduced by Atanassov [3] as a generalization of Zadeh’s fuzzy sets (FS) [31]. Since to each element of IFS is assigned a membership degree ξ, a non-membership degree ζ and a hesitancy degree 1 - ξ - ζ, IFS is more powerful in handling uncertainty and imprecision than FS. IFS theory was widely studied and applied in many different directions of research. But an intuitionistic fuzzy number (IFN) (ξ, ζ) has a significant limitation - the sum of the degrees of membership and non-membership should be equal or less than 1. Sometimes, a decision maker (DM) may provide such data for an attribute that the sum of aforementioned degrees is greater than 1 (ξ + ζ > 1). Yager in [27] presented the concept of the Pythagorean fuzzy set (PFS) as an extension of IFS, where the pair of a Pythagorean fuzzy number (PFN) (ξ, ζ) has a less significant restriction - a square sum of the degrees of membership and non-membership is equal or less than 1 (ξ2 + ζ2 ⩽ 1). In general, for practical problems, the models with PFSs outperform those with IFSs. Therefore, PFSs are more flexible in dealing with uncertain information and solve complex decision-making problems. PFNs have much less, but significant restriction. When the evaluation psychology of a DM is too complicated and contradictory for complex decision making, the attribute’s corresponding information is still difficult to express with PFNs. Recently, again Yager found a solution to this issue in [28]. He proposed a concept of a q-rung orthopair fuzzy set (q-ROFS), where q ⩾ 1 and the sum of the qth power of the degrees of membership and non-membership cannot be greater than 1. For a q-rung orthopair fuzzy number (q-ROFN) we have ξ q + ζ q ⩽ 1. It is obvious that the q-ROFSs are more general than IFSs and PFSs. The IFSs and PFSs are the particular subcases of the q-ROFSs when q = 1 and q = 2, respectively. Therefore, q-ROFNs are much more convenient in describing DM’s evaluation information than IFNs and PFNs [29].
Hes q (x) = (1 - ((ξ A (x)) q + (ζ A (x)) q ) 1/q is called a hesitancy associated with a q- rung orthopair membership grades and Str q (x) = ((ξ A (x)) q + (ζ A (x)) q ) 1/q is called a strength of commitment viewed at rung q.
In [28] Yager showed that Attanassov’s intuitionistic fuzzy sets [10] are q = 1 -rung orthopair and Yager’s Pythagorean fuzzy sets ([27]) are q = 2 rung orthopair fuzzy sets. For convenience, the authors for every x ∈ X called α =〈 x, ξ α (x) , ζ α (x) 〉 a q-rung orthothair fuzzy number (q-ROFN) denoted by α = (ξ α , ζ α ).
Let us denote by L the lattice of non-empty intervals L ={ [a ; b]/(a, b) ∈ [0, 1] 2, a ⩽ b }. The partial order relation ⩽L is defined as [a ; b] ⩽ L [c ; d] ⇔a ⩽ c and b ⩽ d. The top and bottom elements are 1 L = [1; 1] and 0 L = [0; 0], respectively. For the lattice of all q-ROFNs the corresponding partial order relation ⩽Lq-ROFNs is defined as:
The top and bottom elements are 1Lq-ROFNs = (1 ; 0) and 0Lq-ROFNs = (0 ; 1), respectively.
a) A score function Sc of α is defined as
b) An accuracy function Acof α is defined as follows:
Based on these definitions a comparison method of q-ROFNs (total order relation ⩽ t on the lattice Lq-ROFNs) is defined:
If Score (α) > Score (β), then β <
t
α; If Score (α) = Score (β), then If Accuracy (α) > Accuracy (β), then β <
t
α; If Accuracy (α) = Accuracy (β), then β =
t
α.
On the lattice Lq-ROFNs the following basic operations can be defined:
α
c
= (ζ
α
, ξ
α
);
Min (α1, α2) = (max(ξ
α
1
, ξ
α
2
) , min(ξ
α
1
, ξ
α
2
)) ; Max (α1, α2) = (min(ξ
α
1
, ξ
α
2
) , max(ξ
α
1
, ξ
α
2
)) ;
We define the distance between q-rung orthopair fuzzy numbers α1, α2 ∈ Lq-ROFNs as follows:
It is not difficult to prove that this measure satisfies all properties of a distance function.
TOPSIS approach for determination of a candidate HADC’s selection index under q- rung orthopair fuzzy information
Multi-attribute decision making (MADM) aims at finding an optimal alternative that has the highest degree of satisfaction from a set of feasible alternatives characterized with multiple criteria, and these kinds of MADM problems arise in many real-world situations [14, 32]. Technique for the TOPSIS developed by Hwang and Yoon [15] is one of the most useful distance measures based classical approaches to multi-criteria/multi-attribute decision making (MCDM/MADM) problems. It is a practical and useful technique for ranking and selection from a number of externally determined alternatives through distance measures. The basic principle used in the TOPSIS is that the chosen alternative should have the shortest distance from positive-ideal solution (PIS) and farthest from the negative-ideal solution (NIS).
Fuzzy TOPSIS approaches for facility location selection problem for different fuzzy environments are developed in [6, 30] and others. In this work we consider a new model of FFLTP based on the q-rung orthopair fuzzy TOPSIS approach for the optimal selection of facility location centers. This Section first introduces the MADM problem under q-rung orthopair fuzzy environment. Then, an effective decision-making approach is proposed for dealing with such MADM problems. At length, an algorithm of the proposed method is presented.
We focus on a multi-attribute decision making approach for location planning of service centers under uncertain and extreme environment. We develop a fuzzy multi-attribute decision making approach for the service center location selection problem for which a fuzzy TOPSIS approach is used.
The formation of expert’s input data for the centers’ selection problem is an important task. To decide on the location of service centers, it is assumed that a set of candidate centers (sites) (CCs) already exists. This set is denoted by CC = {cc1, cc2, . . . , cc
m
}, where we can locate service centers, and let X = {x1, x2, . . . , x
n
} be a set of all attributes (transformed in benefit attributes) which define CC’s selection. For example: ”access by public and special transport modes to the candidate site”, “security of the candidate site from accidents, theft and vandalism”, ” connectivity of the location with other modes of transport (highways, railways, seaports, airports, etc.)”, ”costs of vehicle resources, required products and etc. for the location of a candidate site”, “impact of the candidate site location on the environment, such as important objects of Critical Infrastructure, air pollution and others”, ” proximity of the candidate site location from the central locations”, ” proximity of the candidate site location from customers”, “availability of raw materials and labor resources in the candidate site”, ”ability to conform to sustainable freight regulations imposed by managers for e.g. restricted delivery hours, special delivery zones”, ”ability to increase size to accommodate growing customers” and others. Let W = {w1, w2, . . . , w
n
} be the weights of attributes. For each expert ex
k
from invited group of experts (service dispatchers and so on) Ex = {ex1, ex2, . . . , ex
t
}, let
The proposed framework of location planning for candidate sites comprises the following steps:
Step 1: Selection of location attributes. Involves the selection of location attributes for evaluating potential locations for candidate sites. These attributes are obtained from discussion with experts and members of the city transportation group. In our case: 1. ” post disaster access by public and special transport modes to the candidate site”; 2. ” post disaster security of the candidate site from accidents, theft and vandalism”; 3. ” post disaster connectivity of the location with other modes of transport (highways, railways, seaport, airport etc.)”; 4. ” costs in vehicle resources, required products and etc. for the location of CCs in candidate site”; 5. “impact of the candidate site on the environment, such as important objects of Critical Infrastructure and others. The fourth attribute is cost type and the others are benefit types. As mentioned above, cost type evaluation data must be transformed in the benefit forms.
Step 2: Selection of candidate location sites. Involves selection of potential locations for implementing service centers. The decision makers use their knowledge, prior experience in transportation or other aspects of the geographical area of extreme events and the presence of sustainable freight regulations to identify candidate locations for implementing service centers. For example, if certain areas are restricted for delivery by municipal administration, then these areas are barred from being considered as potential locations for implementing urban service centers. Ideally, the potential locations are those that cater for the interest of all city stakeholders, which are city residents, logistics operators, municipal administrations, etc.
Step 3: Assignment of ratings to the attributes with respect to the candidate sites. Let
Step 4: Establishing an overall q- rung for all expert evaluations:
Step 5: Computation of the q-ROF decision matrix for the attributes and the candidate sites. Let the ratings of all experts be described by positive numbers ω
k
, ω
k
> 0, k = 1, . . . , t. If ratings of the attributes evaluated by the k-th expert are
Construct the q = q0- rung fuzzy decision matrix {α ij } and calculate Score and Accuracy functions values (Definition 2) of elements α ij .
Step 6: Identification of q-rung orthopair fuzzy positive ideal solution (PIS) and negative ideal solution (NIS). TOPSIS approach starts with the definition of the q-rung orthopair fuzzy PIS and the q-rung orthopair fuzzy NIS. Using formulas 4-5 of the Definition 4 the PIS is defined as a q = q0-rung orthopair fuzzy set on attributes
Step 7. Calculation of distances between the alternative candidate location sites and the q-rung orthopair fuzzy PIS, as well as q-rung orthopair fuzzy NIS, respectively.
Then, we proceed to calculate the distances between each alternative and q-rung orthopair fuzzy PIS and NIS. Using the equation of distance defined in Section 2, we define distances between the alternative cc
i
and the q = q0-rung orthopair fuzzy PIS and NIS, as a weighted sum of distances between extreme and evaluated q-ROFNs:
Step 8. Calculation o f the revised closeness or TOPSIS aggregation as a site’s selection index for every alternative. In general, the bigger D (cc
i
, cc-) and the smaller D (cc
i
, cc+) the better the alternative cs
i
for the selection (opening of HADC). In the classical TOPSIS method, authors usually need to calculate the relative closeness (RC) of the alternative cc
i
. We define candidate site’s selection index as RC with respect to q = q0-rung orthopair PIS cc-as bellow:
Expert cannot always provide evaluations in the form of exact numbers. Often, it is convenient for them to provide evaluations in linguistic variables using natural language. They often use terms such as “very high”, “high”, “medium”, etc. The model we have built can take similar evaluation as an input and translate them into fuzzy concepts (e.g., in triangular fuzzy numbers).
As we have noted, imprecision and uncertainty arise from the extreme situations while moving from centers to customers (see Fig. 1). Imprecision is mainly reflected in growth of inaccuracies of travel times –deviations from the average times required to deliver goods to customers in normal situations. For example, if in a normal situation it takes 20-minute to move between certain points, the expert can evaluate the movement time between the same points in the extreme situation as “about 25 minutes, ± 10 minutes”, which can be written as triangular fuzzy number (15, 25, 35) [9]. As regards the uncertainty, in extreme and uncertain environment, the possibility of movement between specific points is questioned because of lack of complete information about road conditions or because of having information about some damages on the roads. We use a possibility measure [9] to describe the feasibility of movement between points. However, due to the specifics of our problem, we consider not only the possibility of movement, but the possibility of movement in τtime. Let us assume that DP = {dp1, dp2, . . . , dp p } is the set of all demand points (customers). Therefore, for each candidate center CC j (j-th HADC), we will define DP j –a set of the customers, for which the goods can be supplied in time τ:

Facility location network.
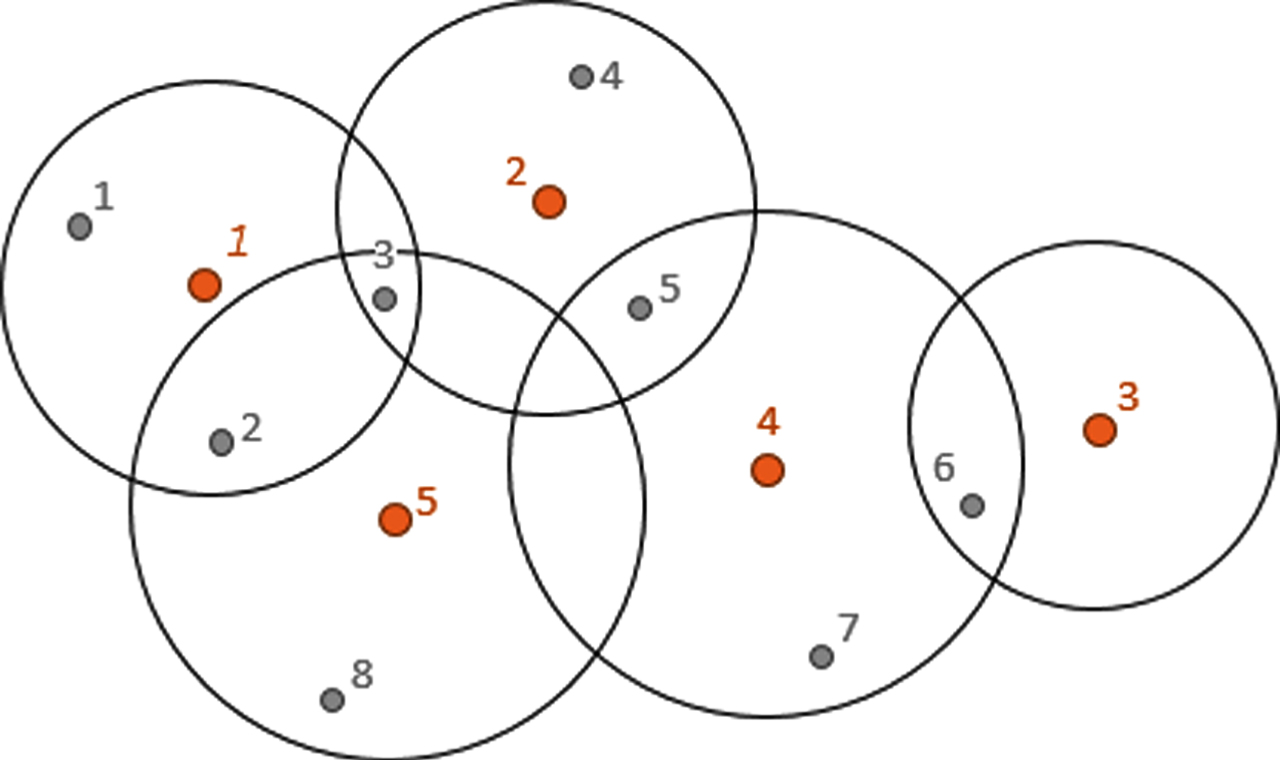
Map of coverings.
The formation of expert’s input data for attributes is an important task of the centers’ selection problem. The expert e
k
has to construct a binary fuzzy relation
First, let us clarify what is a solution of our model. The solution must allocate (assign) each customer to a single candidate center, that means that this candidate center has to be opened, and the goods will be delivered from this center to the customers allocated to it. The distribution of customers to the centers should be done in such a way that the costs would be minimal and the reliability of goods delivery would be high.
In our model we make some assumptions, namely, we suppose that the model deals with distribution of uniform goods, and each customer is serviced only by one center. For the example of delivering humanitarian aid, we can assume that this aid (e.g., food or various items) is packed in homogeneous boxes - in humanitarian packages and is delivered to customers in this form. For example, one customer may need 31 boxes, another 53. We also assume that all customers must be fully serviced and, at the same time, each customer must be serviced only from one center, because in emergency situations often there is no time for coordination between the centers to plan customers’ service from multiple centers.
Obviously, to find optimal solutions is not a trivial task, since it requires considering a very large number of combinations –different allocations of customers to the centers. For analysis of the number of such combinations, one may look at the map of coverings, which can easily be described by so called coverings matrix A–rows of which correspond to the customers and columns of which correspond to the candidate centers (see Fig. 2’):
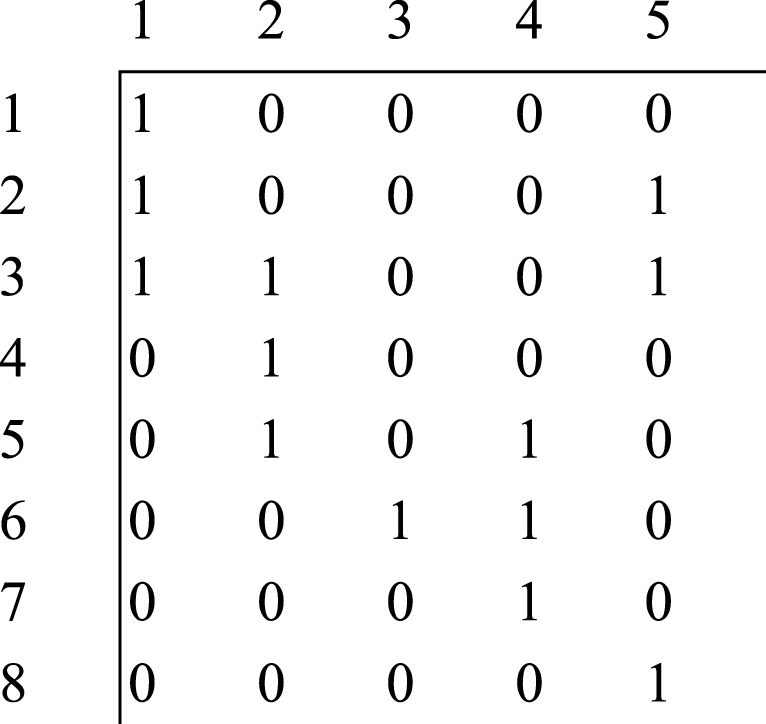
Coverings matrix A.
Generated matrix A’.
Based on the map of coverings (and on the corresponding matrix), we can easily determine the number of partitionings (of customers by centers) –the number of different allocations. Our goal is to select the optimal one(s) out of these allocations. By the well-known principle of multiplication of combinatorics for the computation of variants’ numbers, the number of allocations is equal to the product of numbers of 1 s in each row (not considering customers’ demands and candidate centers capacities). In our example, the number of allocations will be 1 x 2 x 3 x 1 x 2 x 2 x 1 x 1 = 24.
Let us denote the matrix of coverings by
In order to avoid generating all partitionings, calculating the values of objective functions and selecting Pareto optimal solutions out of them, we propose an approach, which allows us to find Pareto optimal solutions without performing exhaustive search.
Now we present the model in more formal way. The objective data for the model is: p –Number of demand points (customers); DP = {dp
i
}–Set of demand points, d
i
–Demand of i-th demand point, m–Number of candidate centers (HADCs); CC = {cc
j
} –Set of candidates (potential) centers, C
j
–Capacity of j-th center, P
j
–Cost of opening j-th center; μ
ij
–Cost of transporting (d
i
goods) from j-th center to i-th demand point; τ –Maximum allowed time to deliver goods to demand points;
The subjective (expert) data for the model is:
γ = {γ
j
} , γ
j
∈ [0, 1]–Centers’ selection indexes,
Variables: r
j
∈ {0 ; 1} :1- if j-th HADC is opened, else 0; x
ij
∈ {0 ; 1} :1- if i-th customer’s d
i
demand is fully satisfied by j-th HADC, else 0 (when i-th customer is not serviced from j-th HADC);
It is obvious, that
Based on above judgment we create the following bi-criteria problem of partitioning, where the first objective function is of transportation type and the second objective function is of facility location type.
Objective functions:
Constraints:
For the capacities of the HADCs (a constraint of transportation type):
For the selection indexes of the HADCs (a constraint of facility location type):
Here
For single customer being fully satisfied from single HADC:
Finally, for the HADCs location and goods transportation problem a bi-criteria Boolean problem (3)-(7) is constructed.
Our approach for solving the constructed bi-criteria Boolean problem (3)-(7) consists of two stages. In the first stage, based on the covering’s matrix A, we generate a new matrix A′, columns of which allow us to find all possible partitionings of the customers relative the centers. Some constraints are also taken into consideration while generating the matrix A′. In the second stage, using the matrixA′ and the exact algorithm constructed by the authors of this work we find the partitionings –allocations of the demand points to the potential centers - which correspond to the Pareto-optimal solutions ([10]). Let us discuss each of the stages in details:
Stage I: Based on matrix A of covering, we generate a new matrix
The principle of generating the columns of the matrix A′is as follows: based on the matrix A, we generate all possible columns, which can serve as a column for partitioning matrix. This means that any of 1s in the column of the matrix A can become 0, maybe several of 1 s, but not all of them together (having this kind of columns in the matrix doesn’t make any sense). In the case of the example which was presented above, the first column will generate following columns:
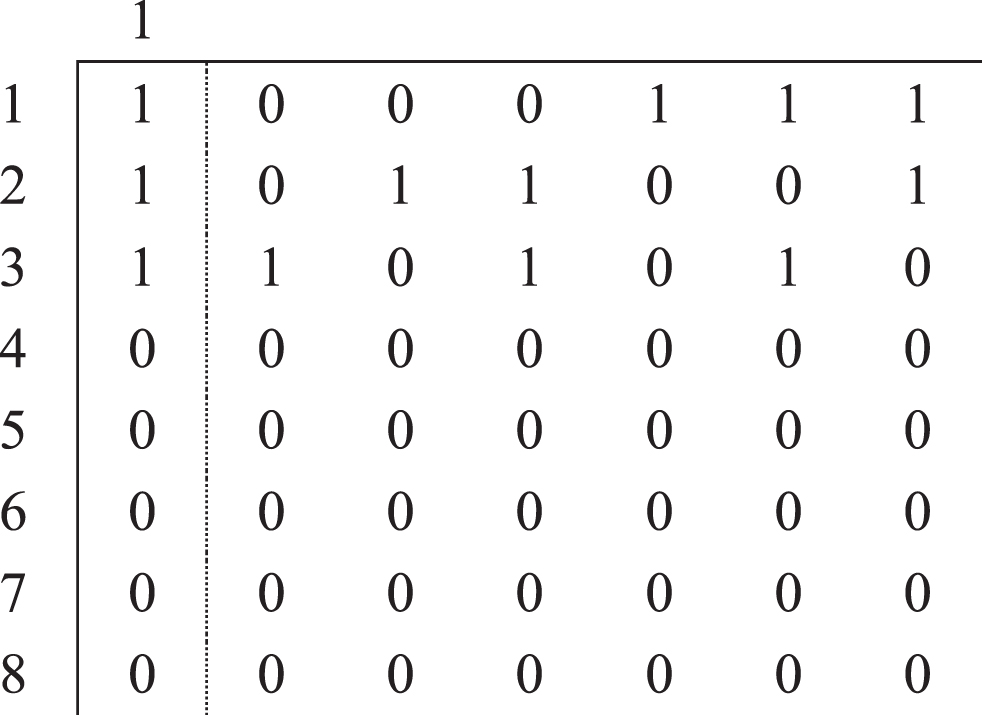
As we can see in generated columns zeros are unchanged in the rows 4 - 8, which is logical since the service center (HADC) corresponding to the first column can’t cover these customers (in τ time).
While generating the columns of matrix A′ we can additionally take into consideration the following factor: if the matrix A had single 1 in some row, it can’t become 0. Therefore, in generated columns 1 s must be unchanged in the corresponding row. To say the same in simpler words, if a specific customer is covered only by one HADC, this customer will be covered by this single HADC in every partition. In the example given above, we have single 1 in the first row (in the first column), thus the first column of the matrix A will not generate the columns which were listed above, but only following three columns (not including itself):
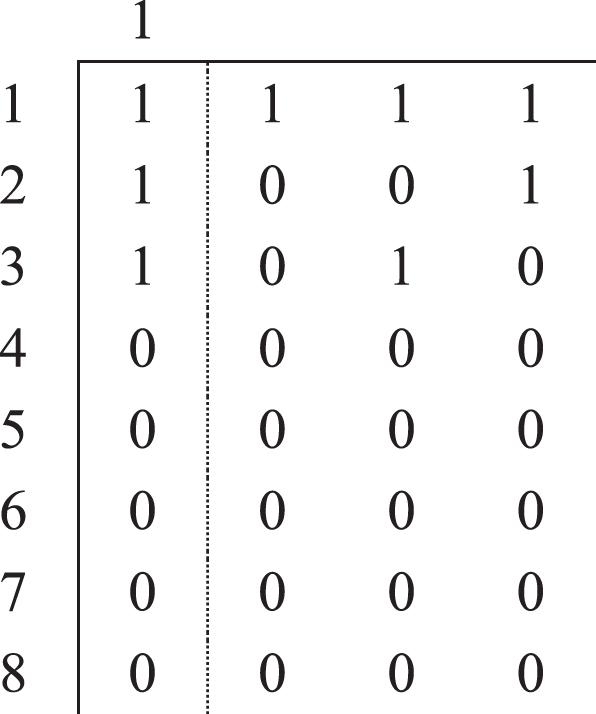
Finally, the matrix Agives us the following A′matrix:
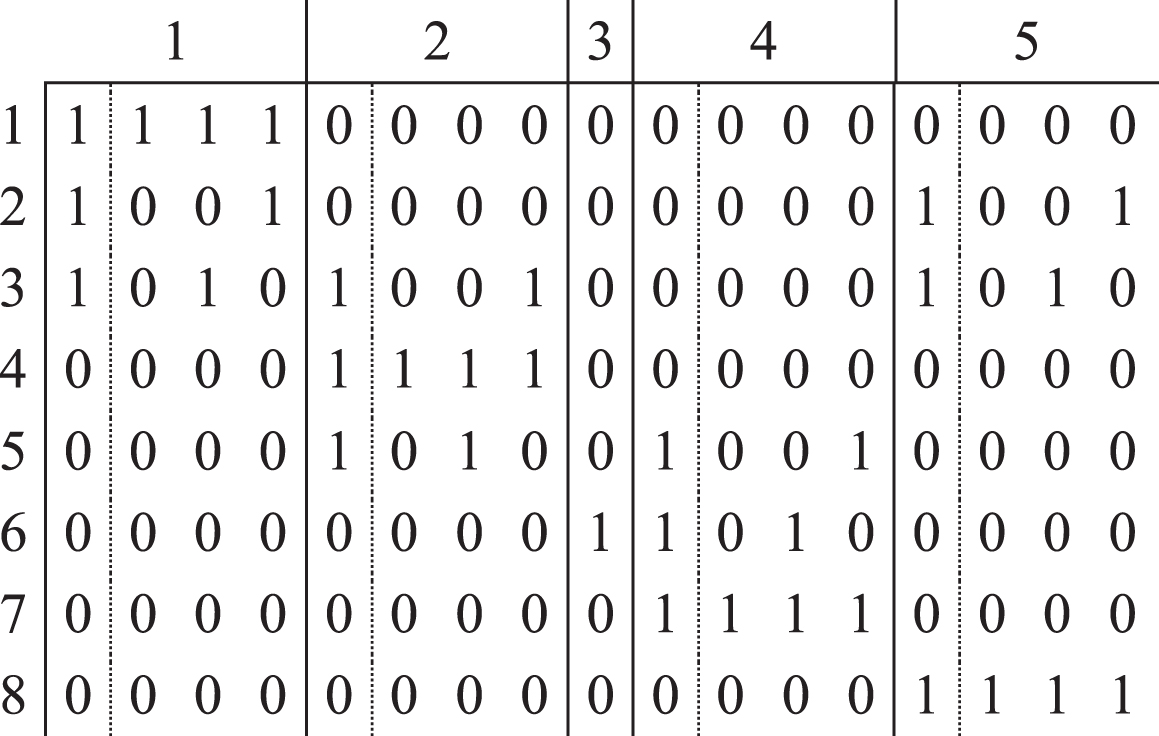
The columns of the matrix A′are grouped by the columns of the matrix A.
While generating the columns of the matrix A′ we can also take into consideration C
j
(
Let s be the number of columns (after filtration) of the matrix A′ and s
j
be the number of columns in j-th column of the matrix A′. Obviously,
Stage II: We perform conversion of the variables, constraints and objective functions of the initial problem to the terms of the matrix A′ and execute our exact algorithm of bicriteria partitioning. As a result, we find the partitionings –allocations of the customers to the HADCs –which will be the Pareto optimal solutions.
Our algorithm of bi-criteria partitioning is based on the extended algorithm [20] of Dancing Links technique and DLX algorithm proposed by D. Knuth [16]. Also, the algorithm implements the epsilon-constraint method for multi-criteria optimization problems [4, 10]. Due to dynamic programming techniques the algorithm effectively uses RAM and, therefore, is characterized with high performance, it can also run-in parallel mode and handle problems of large dimensions. The most important point is that the algorithm finds exact Pareto front –all Pareto optimal solutions. The algorithm can solve in several seconds the problems having approximately 100×1000 dimensions. These dimensions are sufficient for dealing with absolutely most real-life problems, presented in this work.
Let us formulate the bi-criteria partitioning problem in terms of the matrix A′. Let’s introduce a Boolean variable z
l
∈ {0 ; 1} , z = (z1, z1, . . . , z
s
) z
l
= 1–if the l-th column of the matrix A′is included in the solution, else 0,
Objective functions will have the form:
With partitioning constraints:
Indeed, l takes values from 1 to s (
In the k-th group
As for the constraints, the HADCs capacity constraints are already taken into consideration during the generating process of the matrix A′and solving the partitioning problem for the rows and columns of the matrix A′ automatically means satisfying the second constraint –any customer must be fully satisfied from the single HADC.
If we execute our exact algorithm on the matrix A′to solve the problem (8) - (10), we find the partitionings, which correspond to the Pareto optimal solutions. Each of them will have the form of a matrix, rows of which corresponds to the customers and columns represent the subset of the columns of the matrix A′.
If we analyze the matrixA′, we can notice, that the following proposition is true (without proof):
Indeed, in each column group contains all possible coverings of customers by specific HADC (we mean the customers, which can be covered by the HADC in τ time). While searching the minimal partitioning, if we find out that the specific HADC covers for example pnumber of customers, from the column group corresponding to this HADC, the algorithm will always choose the column which contains pnumber of 1 s and will not choose the separate columns (from the same column group), union of which is identical of the above mentioned column (containing pnumber of 1 s). Note: the columns with intersecting 1 s can’t be included in the partitioning solution.
As a summary, we can note that our approach for solving (8)-(10) bi-criteria problem is better than exhaustive search approach, because based on the matrix A′it generates only the admissible (satisfying the constraints) and interesting (not worse that already identified in previous steps of the algorithm) partitionings. Main results’ support software is designed, including authors’ algorithm [20] based on D. Knuth’s “DLX” algorithm.
To illustrate the model, we have described, and the approach to its solution, let us consider a small dimensional example. Suppose we have p = 8 demand points and m = 5 potential locations where humanitarian aid distribution centers can be opened (Fig. 2). The data of moving fuzzy times between demand points and candidate centers are omitted here, because Fig. 2 defines Map of coverings for some time τ. We use only five main attributes (n = 5) defined above by short names: x1 =”Accessibility”, x2 =”Security”, x3 =“Connectivity to multimodal transport”, x4 =”Costs”, x5 =”Proximity to customers”. The fourth attribute is cost type and the others are benefit types. As mentioned above, cost type evaluation data must be transformed in the benefit forms.
Suppose the experts generated the attributes weights as values of overall importance based on the consensus: w1 = 0.25 ; w2 = 0.15 ; w3 = 0.25 ; w4 = 0.20 ; w5 = 0.15. Let three experts have equal ratings {ω
j
= 1/3}, and assume that each expert ex
k
(k = 1, 2, 3) presented the q-rung orthopair fuzzy ratings
Using formula (1) experts’ evaluations are aggregated in decision making matrix {α ij } (Table 4).
Appraisal matrix by expert-1
Appraisal matrix by expert-1
Appraisal matrix by expert-2
Appraisal matrix by expert-3
Accumulated q = q0 = 4-rung orthopair fuzzy decision matrix {α ij }
After application of the steps of Fuzzy TOPSIS algorithm for evaluation of candidate centers selection indexes the following estimation are obtained (calculating results of Section 3 are omitted because of large number of calculations): γ = {γ j } = {0.28, 0.56, 0.14, 0.30, 0.33}.
Below is given the specific numerical data relevant to the optimization problem.
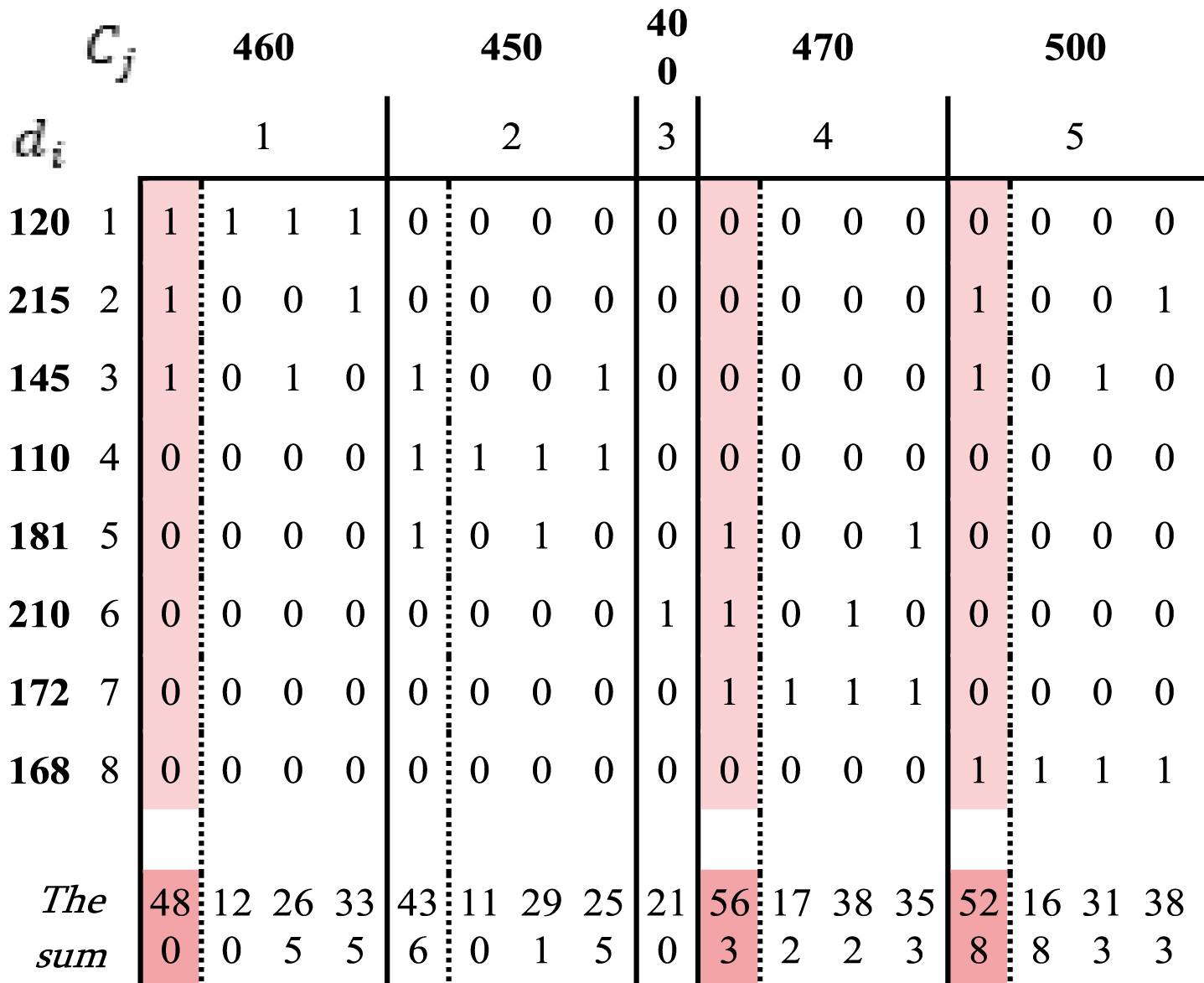
Demand points requirements vector: D = {d i } = {120, 215, 145, 110, 181, 210, 172, 168}; Candidate centers capacities vector: C = {C j } = {460, 450, 400, 470, 500};
Candidate centers opening costs vector: P = {P j } = {1100, 1000, 800, 1200, 900} ;
Transportation costs matrix M = ||μ ij ||:

To solve the problem, in accordance with Phase I of the above considered methodology, let us generate the matrix A’ based on the matrix A of coverings and remove from it those columns that violate the capacity constraints of the centers (Fig. 3, columns to be removed are marked with a different color).
Finally, we obtain

Generated matrix A’ with objectives.
According to the Stage II of our approach, let us apply on matrix A′ the exact bicriteria partitioning algorithm [20, 21] which is worked out by the authors of this paper. As a result, we obtain two partitionings which correspond to the optimal solutions:
Solution 1: CC13, CC21, CC31, CC41, CC51
Total cost: 8575; Total selection ranking index: 0.36 (= 1 - 0.64);
Solution 2: CC13, CC21, CC42, CC51
Total cost: 8882; Total selection ranking index: 0.56 (= 1 –0.44);
Solution 2: A geometric interpretation see in Fig. 5.
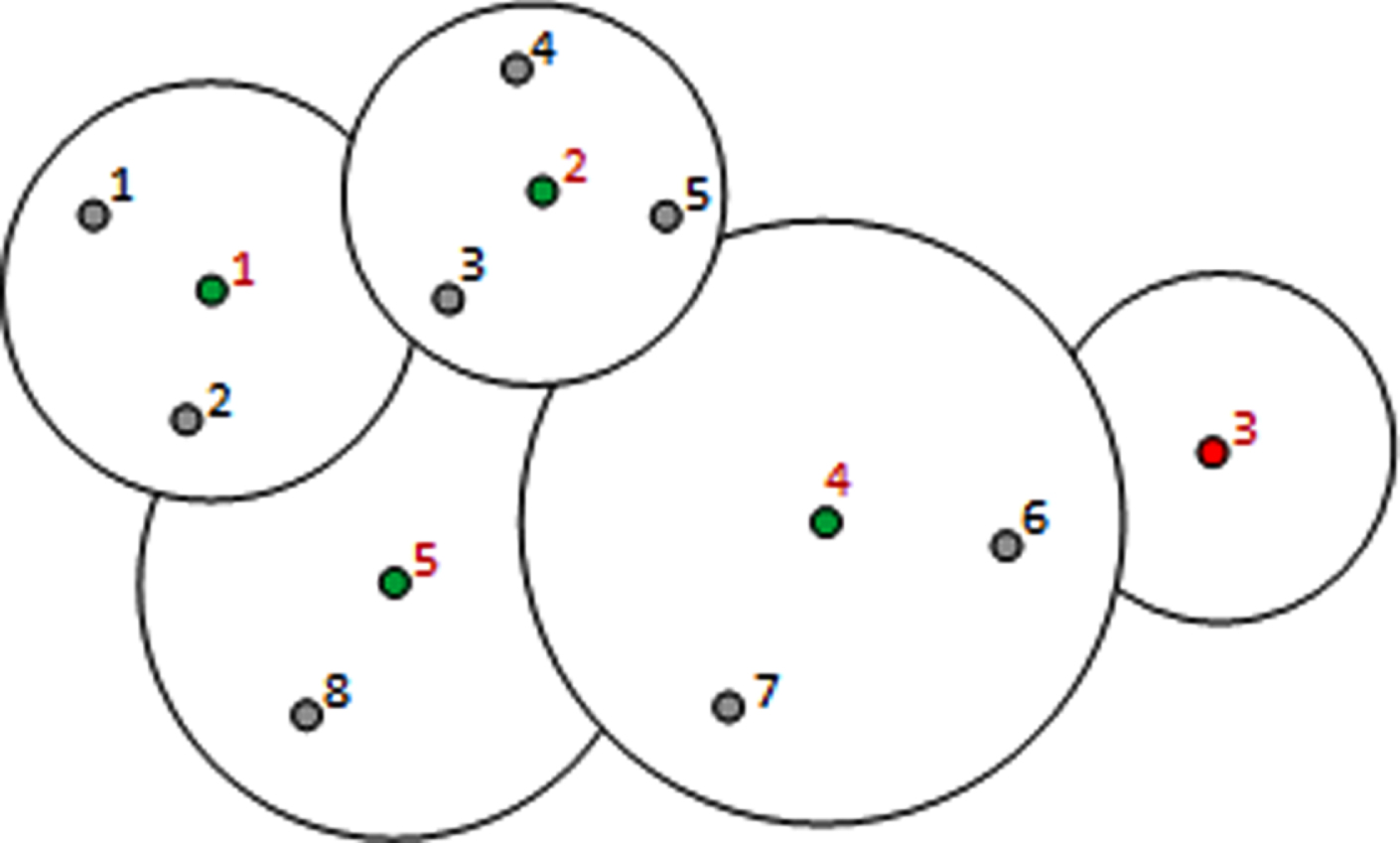
Geometric interpretation of partitioning.
As for interpreting solutions based on matrix A′ and translating into the initial problem terms, it is a simple task, since the columns (cc ij ) in the solution give information about which centers (cc i ) should be opened as well as which customer (demand point) should belong to which center (for this column in rows of such as demand points ‘1’ are inserted). For example, if we consider the second solution, it turns out that the third potential center should not open and the assignments should be as follows (see Fig. 4. The centers that should open are reddened).
Given the essence of Pareto-optimality, as we can see, the first solution has the better value of total cost than the second. However, the second solution has a higher reliability because the total selection ranking index of the centers is better.
The new model of FFLTP presented in this article is distinguished by the fact that by the new objective function we minimize the risks of opening of HADCs. The coefficients of the new objective function are the selection indices of HADCs. To evaluate the latter, we used the distinctive and popular heuristic method of ranking alternatives in decision-making models - TOPSIS. Of course, other methods (VIKOR (an acronym in Serbian for multicriteria optimization and compromise solution), AHP (Analytic Hierarchy Process), TODIM (an acronym in Portuguese for interactive multi-criteria decision making), etc.) or their combinations can also be used, and this represents the degree of freedom of approach we offer. It all depends on the preferences of the user. Why did we use TOPSIS and not another approach? The TOPSIS approach was chosen for one simple reason. From the heuristic approaches developed in recent years that identify alternatives in decision-making models, the TOPSIS approach is characterized by stable, sustainable results and a fairly simple execution scheme. Besides, it is a practical and useful technique for ranking and selection from a number of externally determined alternatives through distance measures.
When the optimization model is already built as a bi-criteria Boolean optimization problem, the next step is to look for optimal ways to solve it. Since due to the specifics of the problem we are not dealing with large dimensions of the problem, therefore exact methods of solving have no alternative. The main finding of this paper is that the constructed model can be reduced by simple transformations to the problem of bicriteria partitioning, for which we have developed an epsilon-constraint approach for the identification of Pareto solutions [20, 21]. As a result, there are several well-known algorithmic methods for solving each scaled problem [7, 11]. However, all these algorithms would give the same result overall - the Pareto solution front. We have chosen a method based on D. Knut algorithm [16], the parallelized variation of which has been developed in our early works [20, 21].
From the above reasoning, we see that the problem-solving scheme presented in this article is competitive with other methods since, on the one hand, due to the first paragraph of the current section, we are free in choosing a heuristic approach to the evaluation of selection indices and it depends on the user, and on the other hand, due to the second paragraph of this section, only exact approaches are expedient and we have chosen a well-proven fast algorithm for us. However, using another exact algorithm would give us the same Pareto solutions.
Conclusions
A q-rung orthopair fuzzy TOPSIS approach for formation and representation of expert’s knowledge on the parameters of emergency service facility location planning is developed. In this approach, we propose a score function-based comparison method to identify the q-rung orthopair fuzzy positive ideal solution and the q-rung orthopair fuzzy negative ideal solution. Based on the constructed fuzzy TOPSIS aggregation a new innovative objective function is formulated. Constructed criterion maximizes selected service centers’ index and reduces HADCs opening risks. Bi-objective facility location-selection/transportation partitioning problem is constructed. We constructed innovative two stage approach for solving the constructed bi-criteria partitioning problem. In the first stage we create algorithm, based on which the coverings matrix is transformed into a new matrix. Columns of transformed matrix allow us to find all possible partitionings of the HADCs with the service centers. In the second stage, using the transformed matrix and our exact algorithm [18, 19] we find the partitionings –allocations of the HADCs to the centers which correspond to the Pareto-optimal solutions. For illustration of constructed model, a numerical example is considered. From the practical point of view, more detailed and deep constraints will be considered in our future FFLTP’s models.
Footnotes
Acknowledgments
This work was supported by Shota Rustaveli National Science Foundation of Georgia (SRNSFG) [FR-18-466].