
Abstract
The hypotactic structural relation between clauses plays an important role in improving the discourse coherence of document-level translation. However, the standard neural machine translation (NMT) models do not explicitly model the hypotactic relationship between clauses, which usually leads to structurally incorrect translations of long and complex sentences. This problem is particularly noticeable on Chinese-to-English translation task of complex sentences due to the grammatical form distinction between English and Chinese. English is rich in grammatical form (e.g. verb morphological changes and subordinating conjunctions) while Chinese is poor in grammatical form. These linguistic phenomena make it a challenge for NMT to learn the hypotactic structure knowledge from Chinese as well as the structure alignment between Chinese and English. To address these issues, we propose to model the hypotactic structure for Chinese-to-English complex sentence translation by introducing hypotactic structure knowledge. Specifically, we annotate and build a hypotactic structure aligned parallel corpus that provides rich hypotactic structure knowledge for NMT. Moreover, we further propose a structure-infused neural framework to combine the hypotactic structure knowledge with the NMT model through two integrating strategies. In particular, we introduce a specific structure-aware loss to encourage the NMT model to better learn the structure knowledge. Experimental results on WMT17, WMT18 and WMT19 Chinese-to-English translation tasks demonstrate the effectiveness of the proposed methods.
Keywords
Introduction
The hypotactic structural relation defines an interdependency relation between clauses and mainly makes up the logic of natural language [1]. It plays an important role in improving the discourse coherence of machine translation [2]. In recent years the neural machine translation (NMT) systems, adopting an encoder-decoder framework to model source sentences and target sentences in a sequence-to-sequence (Seq2Seq) learning fashion, have achieved substantial progress [3–8]. However, the NMT systems often ignore the hypotactic structural relation between clauses when translating a complex sentence. As a result, NMT can often generate correct translations of isolated clauses, but being put together in a complex sentence, these translations end up being incoherent and independent with each other.
The above problem is particularly salient in Chinese-to-English complex sentence translation, owing to the distinct grammar forms of the two languages. English is rich in grammatical form (e.g. verb morphological changes and subordinating conjunctions such as “since”, “when”, and “although”) that serve as crucial clues to instruct a NMT model to learn the hypotactic relation between clauses. On the other hand, Chinese is poor in grammatical form and lacks the explicit logical connectives between clauses [9], which poses a major challenge for learning the hypo-tactic relation in an end-to-end way. As illustrated in Fig. 1, we compare the reference provided by a human translator and the result of Google NMT system. In the reference, the first, third and fourth clauses are subordinate clauses, and the second and fifth clauses are main clauses. These clauses make up the hypotactic structural relationship (interdependency) indicated by the subordinating conjunction “although”. However, it is observed that the NMT system can hardly capture such relation. In the machine translation’s output, all of the five clauses are wrongly generated as a parallel structural relationship (independency) revealed by the conjunction “and” and “but”. This indicates that the NMT system still faces challenges in how to learn the implicit hypotactic structure knowledge from Chinese sentences as well as the structure alignment between Chinese and English. 1 .

An example of Chinese-to-English complex sentence translation where a Chinese complex sentence is translated as multiple English clauses. The numbers express the order of clauses and “/” indicates the boundaries of clauses. In both of the translation versions, the sentences in italics are subordinate clauses and the rest are main clauses. This example shows that NMT is still weak in dealing with the hypotactic structural relation of complex sentence from Chinese to English.
To address the above issues, (1) we identify the hypotactic structure and annotate a hypotactic structure aligned parallel corpus in Chinese-to-English translation, to provide rich hypotactic structure knowledge for NMT. Our motivation is that the explicit alignment knowledge of hypotactic structure is beneficial for modeling the main and subordinate clauses, and therefore to improve the translation of complex sentences. Specifically, we annotate all the clauses involved in hypotactic relationship with “main” or “subordinate” clause labels in Chinese-English parallel complex sentence pairs. Each labeled complex sentence consisting of multiple clauses is treated as a document and provides larger context information as well as hypotactic structure information for the NMT model. By doing so, our corpus provides fine-grained alignment at clause level. Compared with general parallel corpus for NMT, our corpus can encourage the NMT model to better capture clause relations as well as the alignment across two languages. (2) Moreover, to combine the hypotactic structure knowledge with the NMT model, we propose a structure-infused neural framework using two integrating strategies. One is using a gated fusion mechanism for integrating the label embedding of hypotactic structure; the other is using an explicit label-infused mechanism for integrating the labeled connectives of hypotactic structure. In particular, we introduce a specific structure-aware loss to encourage NMT to better exploit the integrated structure knowledge during training.
Experimental results on WMT17, WMT18 and WMT19 Chinese-to-English translation tasks show that integrating bilingual alignment knowledge of the hypotactic structure is beneficial for improving translation performance. Our best model achieves an average improvement over the baseline Transformer by 1.18 BLEU points on three tasks. In particular, extensive analyses illustrate the proposed method can significantly enhance the translation of main and subordinate clauses, and therefore improve discourse coherence. Meanwhile, the proposed method can also enhance the translation adequacy via fine-grained clause alignment learning.
The key contributions of this work are summarized as follows: We point out the translation problem of hypotactic structure on the Chinese-to-English translation task of complex sentences, and propose to address this problem by annotating hypotactic structure knowledge and integrating the structure knowledge into the NMT model. We create a hypotactic structure aligned Chinese-English parallel corpus which provides rich hypotactic structure knowledge and fine-grained alignment at clause level for NMT. We propose two strategies to integrate the structure knowledge into NMT and introduce a specific structure-aware loss to encourage the NMT model to better learn the integrated structure knowledge. Extensive experiments and analyses demonstrate that the proposed approach can significantly improve the translation quality of complex sentences in discourse, and therefore enhance the coherence of translations.
In this work, our research focuses on the hypotactic structure problem on the Chinese-to-English translation task of complex sentences, and it is related to cross-sentence context, discourse coherence and the training data in NMT. We discuss these topics in the following sections.
Context-aware NMT
Traditional NMT models [4, 7] focus on improving the translation quality of individual sentences, while such methods often show degraded performance in translating multiple sentences. To overcome the weaknesses of sentence-level NMT, researchers have made effective efforts in context-aware NMT. These works mainly included building additional encoder based on RNN [10–14] to capture larger context. In addition, some works modeled the cross-sentence context by combining hierarchical attention mechanism [15, 16]. In summary, these NMT systems are designed to allow extra-sentential context as their input. However, one limitation of these methods is that they assume all the discourse structure knowledge can be learned automatically by the NMT model from larger context, ignoring the influence of linguistic phenomena (such as the implicit hypotactic relationship in Chinese) on the NMT model. Similar to these methods, we aim to capture more discourse structure information from larger context e.g. complex sentences that contain multiple clauses. Different from these methods, we focus on the semantic relevance and structure dependency between clauses rather than only larger context for translation. We annotate hypotactic structure knowledge and propose a structure-infused neural model to integrate the structure knowledge into the NMT model, which overcomes the shortcoming of exiting parallel data caused by the lack of structure knowledge in Chinese-English translation process.
Coherence-aware NMT
In recent years, modeling the discourse coherence of translations has attracted more attention. To improve the discourse coherence of translations, Born et al. [17] integrated the graph-based coherence representation into a statistical machine translation system. Kuang et al. [18] introduced a cache-based approach to model discourse coherence for NMT by capturing cross-sentence information either from recently translated sentences or the entire document. Xiong et al. [19] proposed a two-pass decoder translation model to improve the coherence of translations. Similar to these methods, we take the semantic relevance and links among sentences into account. The difference is that we extract the hypotactic structure knowledge from complex sentences and use the structure knowledge to enhance discourse coherence of translations.
Training data for NMT
The current NMT models, both sentence-level models [4, 7] and document-level models [10–14, 19], are all trained based on parallel corpus that consists of sentence pairs. Such corpus is aligned at sentence level or document level. While the corpus that we created is aligned at fine-grained clause level, and the hypotactic structure is marked in the corpus. Therefore, our corpus can provide more structure information and help the NMT model align better in the hypotactic structure of English and Chinese.
Background
NMT uses an encoder-decoder framework with attention mechanism to optimize the translation probability of a target sentence y = (y1, ⋯ , y
N
) given its corresponding source sentence x = (x1, ⋯ , x
M
):
where θ denotes a set of tunable model parameters and y<n expresses a partial translation. Some neural structures are widely used in NMT, such as Recurrent Neural Network (RNN) [20] and self-attention network (Transformer) [7]. In this work, we perform experiments on both RNN-based NMT and Transformer-based NMT.
Transformer adds the positional encodings to the source as well as target embedding, allowing the NMT to capture the sequentiality of the source sentence without using recurrence structure. The positional encodings are calculated based on the position (pos) and the dimension (i) as follows:
In self-attention sub-layer, Transformer generates a context vector of the current word by considering other words in the same sequence. Given an input sequence x=(x1, . . . , x
M
), where x
i
∈ R
d
x
, each attention head calculates a new context sequence z=(z1, . . . , z
M
) of the same length, where z
i
∈ R
d
z
and it is computed as follows:
To address the discourse phenomenon of the main and subordinate clauses translations, we construct a bilingual parallel corpus with Chinese-to-English complex sentence pairs aligned in the hypotactic structure. The construction process mainly includes: (1) the recognition of Chinese and English clauses, (2) the alignment of Chinese and English clauses, (3) the recognition and annotation of English main and subordinate clauses, and (4) the annotation of Chinese main and subordinate clauses.
In this work, we define a tagged main clause set as
Annotation principles for hypotactic structure alignment
(1)

An example of alignment between Chinese and English clauses. The Chinese and English paragraphs have been divided into clauses marked with sequence numbers. Among them the clauses marked with * are subordinate clauses, and those unmarked are main clauses.
Z1-E1, Z2-E2, Z3-E3, Z4-E5, Z5-E6, Z6-E4, Z7-E7.
(2)
*Z1-*E1, Z2-E2, *Z3-*E3, *Z4-*E5, *Z5-*E6, Z6-E4, *Z7-*E7.
We design an automatic construction method for our Chinese-English parallel corpus aligned in the hypotactic structure based on the above annotation principles (see Section 4.1). The construction process is illustrated in Fig. 3.
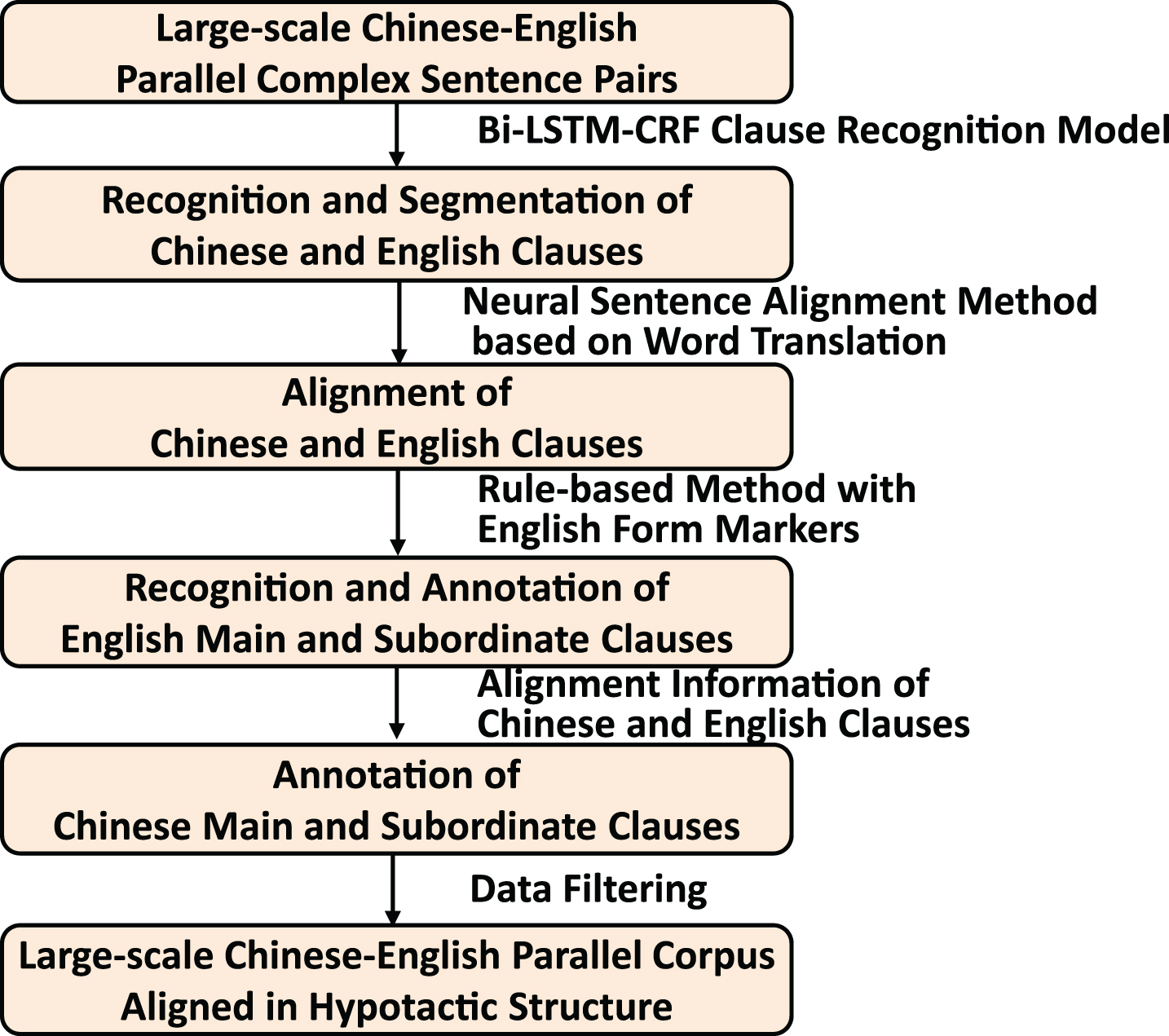
The construction process of the Chinese-English hypotactic structure aligned parallel corpus.
Statistically, the annotated corpus contains 1 M sentence pairs, 1.75 M clause pairs, 0.5 M main clause pairs and 1.25 M subordinate clause pairs, and the English-Chinese clause alignment results achieve the accuracy at P 88.3, R 89.4, and F1 88.8.
The final annotation results are shown in the following example of sentence pair:
 IFS/0 -210908/If - 03 . eps EN: <S-start> <1>Because the development and opening up of Pudong is a cross-century project to revitalize Shang-hai and build a modern economy, trade and financial center, <S-end> <M-start> <2> there are a lot of new situations and new problems that have never been en-countered before. <M-end> end tabbing
IFS/0 -210908/If - 03 . eps EN: <S-start> <1>Because the development and opening up of Pudong is a cross-century project to revitalize Shang-hai and build a modern economy, trade and financial center, <S-end> <M-start> <2> there are a lot of new situations and new problems that have never been en-countered before. <M-end> end tabbing
These hypotactic structure labels annotated in our corpus can guide the NMT model to learn rich hypotactic structure knowledge. Moreover, our corpus provides fine-grained alignment at clause level with clause alignment labels, which can encourage the NMT model to capture key context information through clause alignment learning.
In the following sections, we will explore how to integrate the alignment knowledge of the hypotactic structure into NMT and how to make the model learn such knowledge effectively.
In this part, we explore how to integrate the annotated hypotactic structure knowledge into NMT model. To better combine the structure knowledge with NMT model, we propose a structure-infused neural framework. The overall architecture is shown in Fig. 4(a). Specially, we design different structure information fusion layers for encoder and decoder on top of the Transformer-based NMT model. Further, we introduce two strategies to incorporate the annotated structure labels into the NMT encoder and decoder respectively. In particular, a specific structure-aware loss is added to the original loss for guiding the NMT model to better learn such structure knowledge during training.
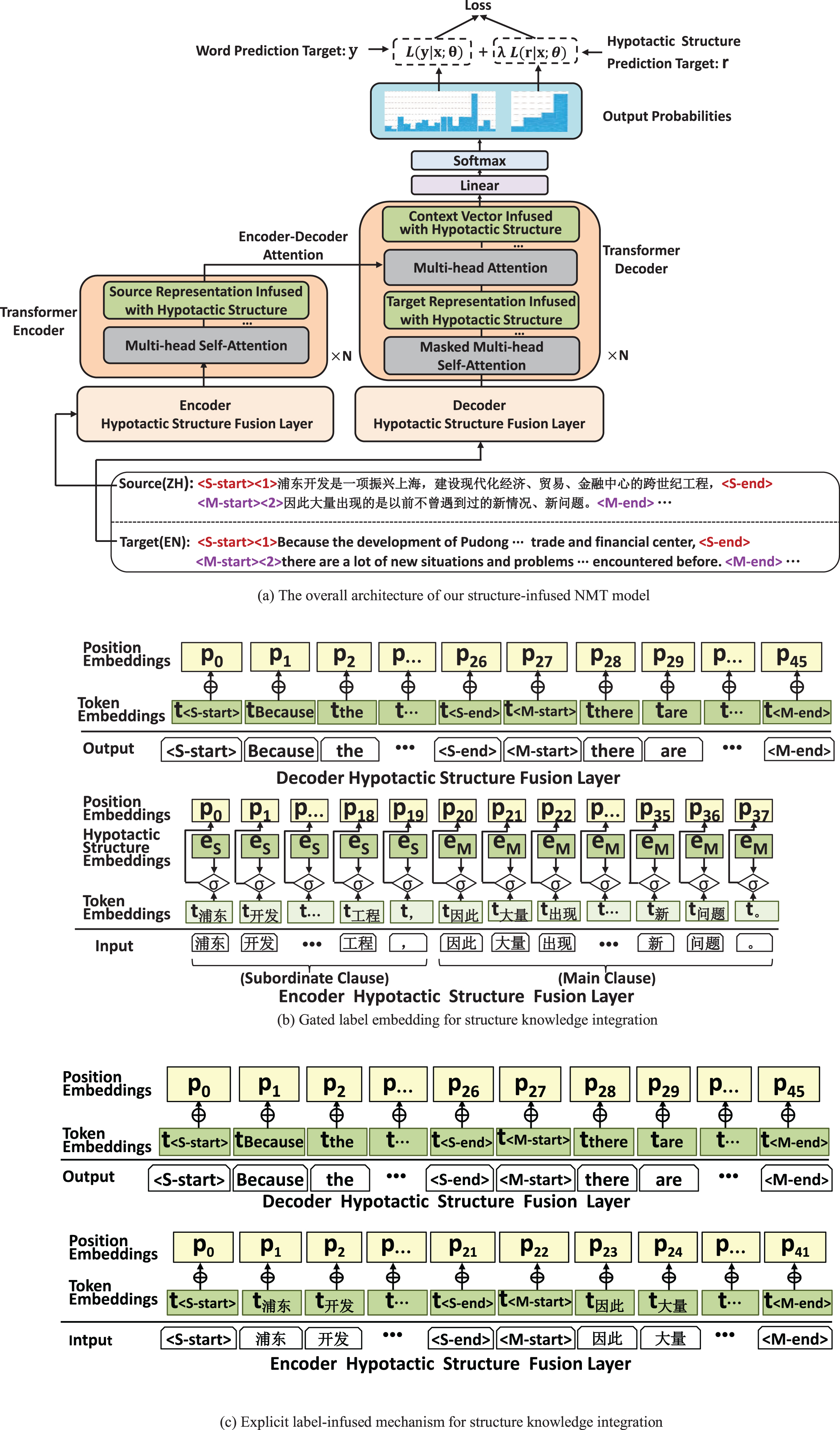
The proposed structure-infused NMT framework. (a) The overall model architecture integrating Chinese-English hypotactic structure alignment knowledge into NMT; (b) the proposed structure knowledge integration strategy using gated label embedding of the hypotactic structure; and (c) the proposed structure knowledge integration strategy using explicit label-infused mechanism of the hypotactic structure.
Formally, we define the source and target sentences as
In this integration strategy, we incorporate the hypotactic structure knowledge into NMT with a gated fusion mechanism.
As shown in Fig. 4(b), given a source Chinese sentence x tagged with structure labels, it is first summarized by our encoder structure fusion layer. Inspired by the work of Devlin et al. [32], for each token within the scope of subordinate clause labels <S-start>and <S-end>, we infuse a subordinate structure embedding e S . Similarly, for each token within the scope of main clause labels <M-start>and <M-end>, we infuse a main structure embedding e M . Concretely, for a given token, its input representation is performed by adding the corresponding token embedding t i , the main or subordinate structure embedding e i and position embedding p i . Here, e i is specifically expressed as e S or e M depending on the token’s corresponding structure label.
We introduce a gating operation [33] to regulate the weights between token embedding t
i
and the structure embedding s
i
. The intuition is that different tokens require different amount of semantic influence at discourse structure level:
Then, the representation h
i
of a source word is fed into the encoder for learning contextual token representation. The encoder consists of a stack of
Specifically, we generate the target representation by summing the token embedding and the position embedding of each token at our decoder hypotactic structure fusion layer. As shown in Fig. 4(b), the target representation is denoted as follows:
Similarly, the decoder consists of a stack of
where K
N
and V
N
are transformed from the N-th layer of the encoder, Att (·) denotes the multi-head attention between the encoder and the decoder. Then the n-th layer of the decoder output is computed as follows:
Finally, the decoder top layer output L
N
enhanced by the context vector based on the discourse structure knowledge is used to predict the next target word and improve the translation coherence of the complex sentences:
The annotated hypotactic structure knowledge is integrated into NMT by performing such strategy.
In this integration strategy, we use the same way that is proposed at the target side in Section 5.1 to integrate the structure labels into NMT at both the source and target sides with an explicit label-infused mechanism. We view hypotactic structure labels in both the source and target sentences as specific discourse conjunctions that connect the main clause and the subordinate clause. These structure labels contribute a formal explicit representation of the hypotactic structure at the lexical level. As shown in Fig. 4(c), these tag tokens are first mapped and fed into the encoder or decoder with other tokens. Then, they are used to help NMT learn the source representation or the target representation that contains rich discourse structure information through a multi-head self-attention sub-layer. Finally, the context vector is computed to predict the next target word y i at the time-step i.
Note that all the source sentences and target sentences are divided into the simple and complex sentences. Among them, the complex sentences annotated with discourse structure knowledge are fed into NMT using the above two strategies, while the simple sentences are fed into NMT using traditional method without special treatment.
Target structure-aware loss
In the above two integration methods, the target sentences contain a large number of structure labels. We treat these structure labels as linguistic conjunctions and they make an important contribution to the representations of the hypotactic structure of complex sentences. To better use the structure labels, we introduce a specific structure-aware loss to supervise the predictions of the structure labels. The introduced loss is sensitive to the hypotactic structure and can encourage the NMT model to learn more discourse structure knowledge. As shown in Fig. 4(a), the entire loss is conducted by summing the original loss and the specific structure-aware loss.
Considering the long-tailed recognition problem when learning from the imbalanced data (i.e., structure labels) [34], we introduce a re-weighting coefficient λ to regulate the weights [35]. Formally, the final training objective is denoted as follows:
In this work, we introduce four NMT models based on our annotated parallel corpus and the above two integration strategies: (1)
Experiments
Setup
The statistics of training, development and test sets in number of sentence pairs and words
The statistics of training, development and test sets in number of sentence pairs and words
Table 2 shows results of the proposed approach over the implemented RNNSearch and Transformer models in terms of BLEU metric. Clearly, the translation performance of our models outperformed their corresponding baseline systems in all cases.
Results on ZH-EN translation tasks. Our four models that integrate the hypotactic structure alignment knowledge into NMT are implemented on top of RNNSearch and Transformer respectively, and these two strong translation models are our baselines. †† represents a significant improvement over the baseline model
Results on ZH-EN translation tasks. Our four models that integrate the hypotactic structure alignment knowledge into NMT are implemented on top of RNNSearch and Transformer respectively, and these two strong translation models are our baselines. †† represents a significant improvement over the baseline model
Among all the proposed models, COStructure performed better than GEMStructure. This shows that the explicit label-infused mechanism of the hypotactic structure affects the NMT model more than the gated label embedding infusion mechanism of the hypotactic structure. The COStructure combined with the structure-aware loss (COStrucLoss) achieved the best translation performance, outperforming the strong baseline system RNNSearch and the state-of-the-art Transformer by 2.62 BLEU points and 1.18 BLEU points respectively on average. This indicates that the knowledge integration and the knowledge learning methods can be used together to further enhance the translation models on both the source and target sides.
Experimental results demonstrated the effectiveness of our method in terms of BLEU scores. However, the n-gram BLEU score is poorly adapted to evaluating discourse phenomena [12]. We will further analyze the influence of our methods on the Chinese-to-English translations of main and subordinate clauses with human evaluation.
We used sign-test [42] to calculate the statistical significance of our results. We randomly selected 120 complex sentences from the test set, and we counted how many errors based on the hypotactic structure are: 1) generated by the NMT baseline model (Total); 2) fixed by our method (Fixed); and 3) newly produced (New). As shown on Table 3, we observed that 70 complex sentences were translated as the inappropriate main and subordinate clauses, and our model corrected about 66 percent of the errors. However, we also observed that our method generated seven new errors, and we analyzed the reason that we inevitably incorporated a small amount of noisy data into NMT when integrating structure knowledge into the NMT model. We would like to explore how to make full use of the annotated structure labels and reduce the influence of the incorporated noisy data on NMT in the future work.
Translation error statistics of the hypotactic structure
Translation error statistics of the hypotactic structure
In brief, statistics show that our method can effectively help NMT learn the correct hypotactic structure and improve the translations of the main and subordinate clauses at document level.
To further analyze the influence of the proposed method on the translations of the main and subordinate clauses, we conducted a visualization analysis of the attention weight and alignment matrices. First, given the source complex sentence, we compared its translation results generated by the baseline Transformer and our best COStrucLoss model respectively. Then, we computed the attention distribution of each current target word aligned with tokens in the source sequence. The attention distribution is calculated by averaging the attention score of each multi-head attention head (8 heads in total) in the top layer (6 layers in total) of the encoder and decoder. And the attention scores are computed through a multi-head attention layer (please refer to Equation (8)).
The attention weights and alignment matrices are visualized in Fig. 5. We observe that our model generated a more clear alignment path in both the main clause (see the purple dashed box) and the subordinate clause (see the red dashed box) compared with the baseline model. In the subordinate clause, the omission of the conjunction “epsfboxG :/Tex/IOSPRESS/IFS/0 -210908/IF - 04 . eps” (“so”) at the beginning of the source Chinese subordinate clause led to the incorrect translations at discourse structure level. The baseline model missed the conjunction “so” and did not produce the correct English subordinate clauses. Moreover, since the Chinese token “epsfboxG :/Tex/IOSPRESS/IFS/0 -210908/IF - 05 . epsepsfboxG :/Tex/IOSPRESS/IFS/0 -210908/IF - 06 . eps” (“difficult”) and the English token “difficult” were not aligned, an incorrect target word “repulsive” was generated by the baseline model. In contrast, our model addressed these issues relying on the guidance of the bilingual structure alignment labels and correctly predicted the conjunction “so” and the subsequent subordinate clause. This indicates that our method based on the structure alignment learning can help NMT learn rich alignment knowledge at both sentence level and discourse level. Meanwhile, such alignment learning also effectively improves the translation accuracy.
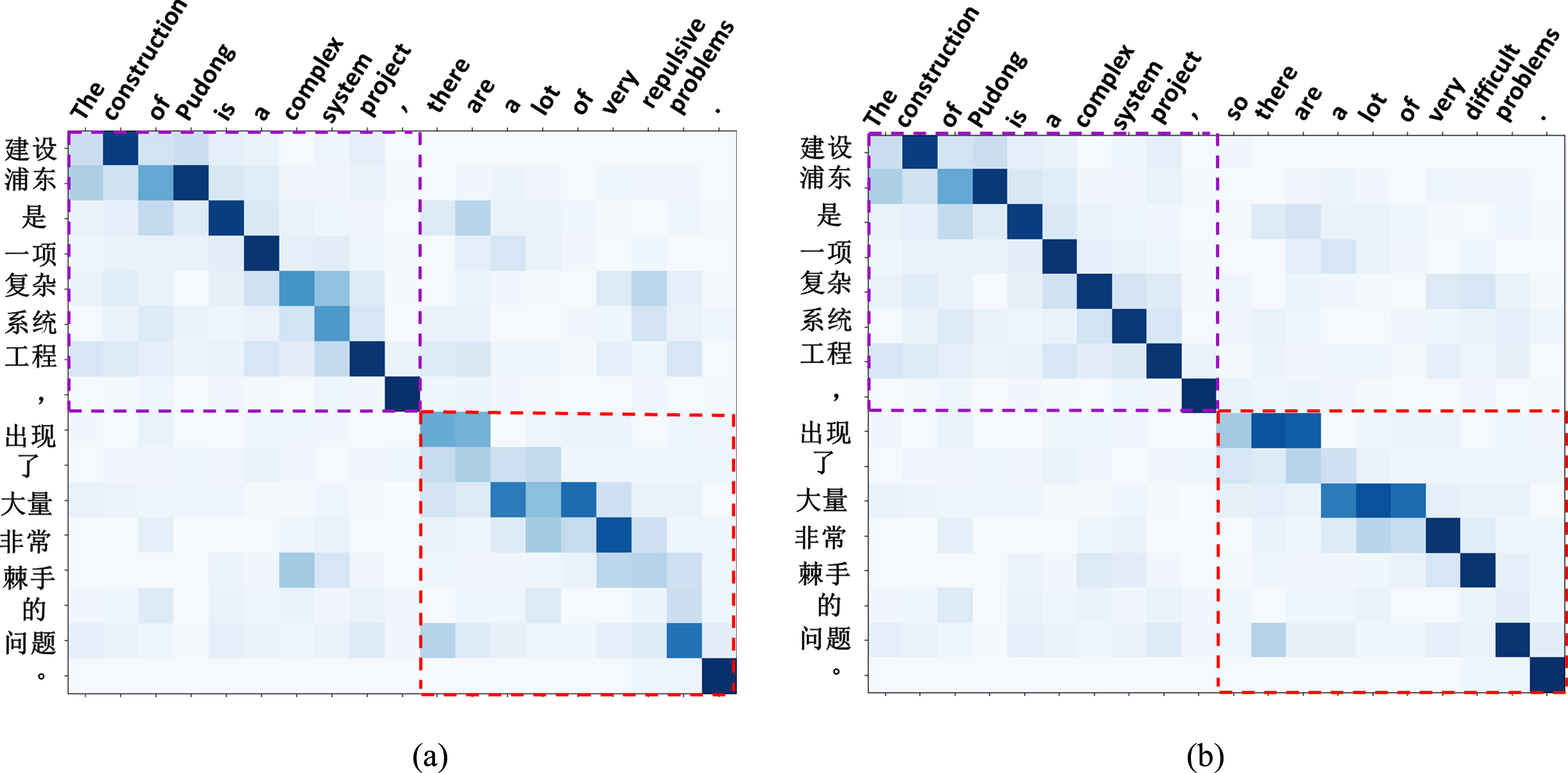
The visualization of the attention weight and alignment matrices. (a) Generated by the baseline Transformer; and (b) generated by our +COStrucLoss model. The alignment of the subordinate clause is shown in the red dashed box, and the alignment of the main clause is shown in the purple dashed box.
To further verify the effectiveness of our method for translating hypotactic structure on complex sentences, we evaluated the accuracy of structure label generation in inference step of NMT. Specifically, we first randomly sampled 200 sentence pairs from the test sets newstest-2017 and newstest-2019 respectively and we manually annotated the total 400 sentence pairs with hypotactic structure labels. Then we decoded the source sentences with our COStrucLoss NMT model and generated translations that contain hypotactic structure labels. Finally, we calculated the accuracy of structure label generation in inference step by comparing the target structure label generated by NMT with the target structure label annotated by human. The result is shown in Table 4. The accuracy of label generation reaches 95.2%in inference step over the above test data. This indicates that the proposed model can better capture the hypotactic structure information of complex sentences from our annotated data and thus improve the translation performance.
The accuracy of structure labels generation in inference step
The accuracy of structure labels generation in inference step
Figure 6 shows the BLEU scores of the GEM-StruLoss model and the COStrucLoss model on the same Chinese-English test set with different hyper-parameter λ. We observed that when λ increased from 0 to 0.3, the above two models got improvements by 0.5 and 0.6 BLEU points over the GEMStructure and COStructure models respectively. This indicates that the introduced structure-aware loss is helpful for the NMT model to learn bilingual alignment knowledge and improve translation results. While we can see larger λ decrease the BLEU scores subsequently, suggesting that excessive attention to structure alignment labels may damage the NMT model. Thus we set λ to 0.3 to regulate the structure aware loss for better training the NMT model and encouraging it to learn more translation knowledge of discourse structure from our annotated structure aligned corpus.

BLEU scores of the GEMStruLoss model and the COStrucLoss model on the same
We use an example of document-level translation to illustrate how the structure alignment knowledge improves NMT (see Fig. 7). We can see that a major translation error made by the baseline system is the wrong translation of the hypotactic structure. The reason is that the baseline system cannot identify the semantic relevance between multiple Chinese clauses. That is, it cannot differentiate between the main clause and the subordinate clause among Chinese clauses, which always leads to the inappropriate translations at discourse structure level. For example, the source clause

An example of document-level translation (
Another translation problem of the baseline is inadequate translation that is also a challenge for document-level machine translation. When translating a document, a larger cross-sentence context needs to be considered, which always leads to the omission of some translation terms in NMT. As shown in Fig. 7, two terms (“in a timely manner” and “demolition”) were missed by the baseline system, but retrieved by our model in clause
In this paper, we focused on the semantic relevance between clauses and explored the influence of hypotactic structure knowledge on improving Chinese-to-English machine translation. First, we created a hypotactic structure aligned Chinese-English parallel corpus that provides NMT with rich hypotactic structure knowledge and fine-grained alignment at clause level. The annotated datasets will be released for helping to learn a better NMT model on Chinese-English complex sentence translation. Then we proposed a structure-infused neural model with two strategies to incorporate the tagged hypotactic structure knowledge into NMT. In particular, we introduced a specific structure-aware loss to guide the NMT model to better learn the structure alignment knowledge. Experimental results on WMT17, WMT18 and WMT19 Chinese-to-English translation tasks have demonstrated that incorporating the tagged discourse structure knowledge is beneficial for NMT as measured with BLEU. Further analyses illustrate that the proposed NMT model can capture the structure knowledge and significantly improve the translations of complex sentences, and therefore improve the discourse coherence of the translations. Meanwhile, the proposed method can also enhance the translation adequacy through fine-grained clause alignment learning.
In the future, we would like to investigate how to encourage the NMT model to learn more discourse alignment knowledge from our structurally aligned training corpus and reduce the influence of the incorporated noisy data on NMT. We will also study the method of automatically evaluating the document-level translation performance of the main and subordinate clauses on Chinese-to-English task.
Footnotes
Acknowledgments
The research work descried in this paper has been supported by the National Key R&D Program of China (2020AAA0108001), the National Nature Science Foundation of China (No. 61976015, 61976016, 61876198 and 61370130) and Guangdong Basic and Applied Basic Research Foundation (2020A1515011 056). The authors would like to thank the anonymous reviewers for their valuable comments and suggestions to improve this paper.
This Chinese complex sentence is an excerpt from Jia Pingwa’s novel Turbulence.