
Abstract
With the development of convolutional neural networks, aiming at the problem of low efficiency and low accuracy in the process of wood species recognition, a recognition method using an improved convolutional neural network is proposed in this article. First, a large-scale wood dataset was constructed based on the WOOD-AUTH dataset and the data collected. Then, a new model named W_IMCNN was constructed based on Inception and mobilenetV3 networks for wood species identification. Experimental results showed that compared with other models, the proposed model had better recognition performance, such as shorter training time and higher recognition accuracy. In the data set constructed by us, the accuracy of the test set reaches 96.4%. We used WOOD-AUTH dataset to evaluate the model, and the recognition accuracy reached 98.8%. Compared with state-of-the-art methods, the effectiveness of the W_IMCNN were confirmed.
Introduction
As we all know, wood is an important material in national production and life. As a renewable resource, it is widely used in the fields of building materials manufacturing [1], energy [2] and furniture manufacturing [3] and other fields. Due to the different structures and compositions of wood, the use and value of wood vary greatly. Therefore, it is important for wood classification in many industries. For example, in the furniture market, it can prevent illegal businesses to use forged means to shoddy. In the construction industry, it is necessary to identify the hardness and other properties of wood through wood classification to use wood reasonably. In trade contacts, it is also necessary to prevent the smuggling of precious timber hidden in ordinary timber. The traditional wood identification process is time-consuming and labor-intensive. According to the relevant wood identification standards, the macroscopic characteristics of wood (name, structure, and resin path) are identified by observing the color, texture, and other physical properties of wood magnified by 10 times magnifier [4]. Therefore, it is very important to develop an automatic identification method for wood. With the development of computers, methods such as machine learning [5] and neural network models [6] have been used to classify and identify wood, which can not only reduce the cost of hiring and training human experts, but also improve the efficiency of wood classification.
In recent years, spectral analysis and computer vision techniques have been used for identified wood by some researchers [7, 8], which have helped improve the accuracy and efficiency of wood recognition. For example, Peng Zhao, Jun Cao et al. [9] developed a novel wood recognition scheme based on wood surface spectral features with an accuracy rate of 95%. Silvana Nisgoski et al. [10] proposed a method based on near-infrared spectral data and artificial neural network for the identification of four kinds of wood. Braga JWB et al. [11] reliably identified four species of wood using near-infrared spectroscopy. Hao Yong, Shang Qing Yuan et al. [12] based on near-infrared spectroscopy, combined with principal component analysis (PCA) and partial least squares discrimination analysis (PLSDA) and other technologies, identified 58 species of wood with an accuracy of 100%. Although the accuracy of spectral detection is high, wood would be damaged when samples are collected, and it need to be carried out under specific conditions, which cannot meet the requirements of real-time detection. Moreover, the spectral instrument is expensive and could only be used as an experimental equipment, which cannot meet the needs of people in their daily life. Computer vision technology is also widely used in wood classification. For example, Ibrahim I Khairuddin ASM et al. [13] extracted the wood texture information and classified it using a neural network classifier. The classification of 30 kinds of were realized and obtained good results. In Deivison Venicio Souza et al. [14] 46 species of Brazilian timber were employed, and the combined use of the feature extractor known as the Local Binary Pattern (LBP) along with the support vector machine (SVM) classifier ensured a good result. Panagiotis Barmpout et al. [15] presented a novel approach for automated wood species recognition through multidimensional texture analysis. And the experimental results reached 91.47%. Mohd Iz’aan Paiz Zamri et al. [16] had realized the classification of wood by extracting the texture features of wood images, and the accuracy rate is above 90%.
Although the identification accuracy of the above research methods for wood has reached more than 90%, the extraction of wood image features needs to be done manually. It takes a lot of time to preprocess the image and select the effective feature. Deep learning, represented by convolutional neural networks (CNN), can automatically extract image features and make probability prediction to get the final classification results. At present, CNNs have been widely used in the field of image detection [17–21]. A study reported in Yin Shen et al. [22] used CNN to detect impurities in wheat samples. Jianwu Li et al. [23] proposed a novel method for inpainting and recognizing occluded offline handwritten Chinese characters based on CNNs. de Geus AR et al. [24] realized classification of wood timber microscope images with an accuracy of 98.7%. The existing CNNs can achieve wood images feature extraction, but the training speed is slow and the number of participants is large. Therefore, it is necessary to improve the existing CNN network to get a more accurate and faster classification method.
The main contributions of this paper could be summarized as follows: A data set of wood images was constructed. This data set consisted of 45,832 images of 16 species. These data sets can be used for automatic recognition and testing of wood images. A new identification method of wood species named W_IMCNN was proposed. According to the data characteristics, we used Adam optimization algorithm to improve the training precision of the model. Experimental results showed that compared with other models, W_IMCNN had obvious advantages in recognition accuracy and training time.
The rest of the paper has been organized as follows: Sect.2 describes source of relevant data and some pretreatment methods for the dataset, and Sect.3 presents the theoretical details of the W_IMCNN model. Results are provided in Sect.4, and conclusions and future work are discussed in Sect.5.
Materials
Dataset description
In this article, we mainly used Barmpoutis’ wood species data set [15] named WOOD-AUTH. Wood images of WOOD-AUTH dataset were obtained at the Laboratory of Wood Technology of Forestry and Natural Environment School of Aristotle University of Thessaloniki, Greece They were taken with a 24 megapixels Nikon D3300 digital camera from a distance of 15–20 cm. There were 8544 wood images from cross, radial and tangential wood sections. On this basis, we added four types of wood data. Supplementary data sets were collected from a wood processing plant in Jiulongpo, Chongqing. Under fluorescent lamp conditions, a mobile phone (Honour 30, camera 40 megapixels) was used to shoot at 15–20 cm above the wood, and a total of 2914 pictures of Quercus spp, Juglans nigra, Hymenaea cunrbaril and Fraxinus mandshurica were obtained. Some of the sample images are displayed in Fig. 1.

Sample wood species dataset (a) Fagus sylvatica, (b) Juglans regia, (c) Castanea sativa, (d) Quercus cerris, (e) Alnus glutinosa, (f) Fraxinus ornus, (g) Picea abies, (h) Pinus sylvestris, (i)Ailanthus altissima, (j) Robinia pseudoacacia, (k) Cupressus sempervirens, (l) Platanus orientalis, (m) Quercus spp, (n) Juglans nigra, (o) Hymenaea cunrbaril L., (p) Fraxinus mandshurica.).
CNN requires images of fixed dimensions, so all images were adjusted to images of 224 pixels×224 pixels×3 channels. Then 11458 sample data were divided into training set, verification set and test set according to 6:2:2, among which 6869 images were in training set, 2298 images in verification set and 2291 images in test set. In deep learning, a large number of samples are required for training to obtain better performance. In order to improve the adaptability of the model on the test set, this study expanded the wood image. The original data set was expanded by four times through rotation, flipping and other operations. The final dataset included a total of 45832 images of wood. The details of the wood dataset were shown in Table 1. A sample of image enhancement was shown in Fig. 2.
The details of the wood dataset used in this study
The details of the wood dataset used in this study

Sample of image enhancement.
CNN is a kind of neural network, which has achieved good results in image classification in the past few years [26–29]. CNN can automatically extract features of image and speech information, which makes feature extraction more convenient. In the process of wood species identification, CNN has better performance than traditional feature extraction [30].
GoogLeNet model
Unlike other neural network improvements, GoogLeNet [25] introduces a new structure called Inception which increases the width of the network model. In the Inception module, it is common to start with a 1×1 convolution kernel to reduce the low channel count and aggregate the information. In this way, the computational force is effectively utilized, and the computational force is widened from deep to wide, so as to avoid the problem of gradient disappearance or gradient explosion caused by too deep network. The Inception module [25] is shown in Fig. 3.
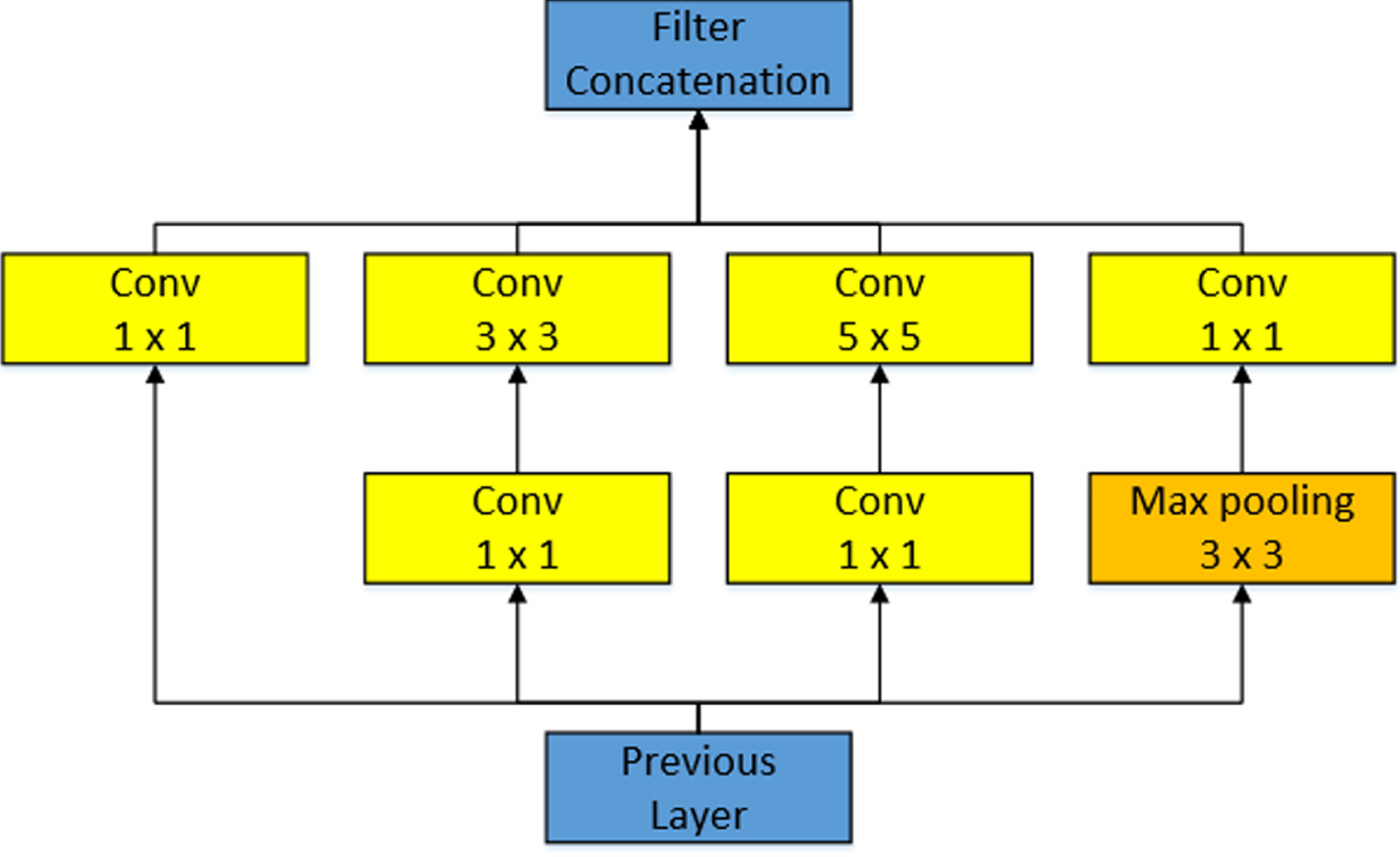
The Inception module diagram.
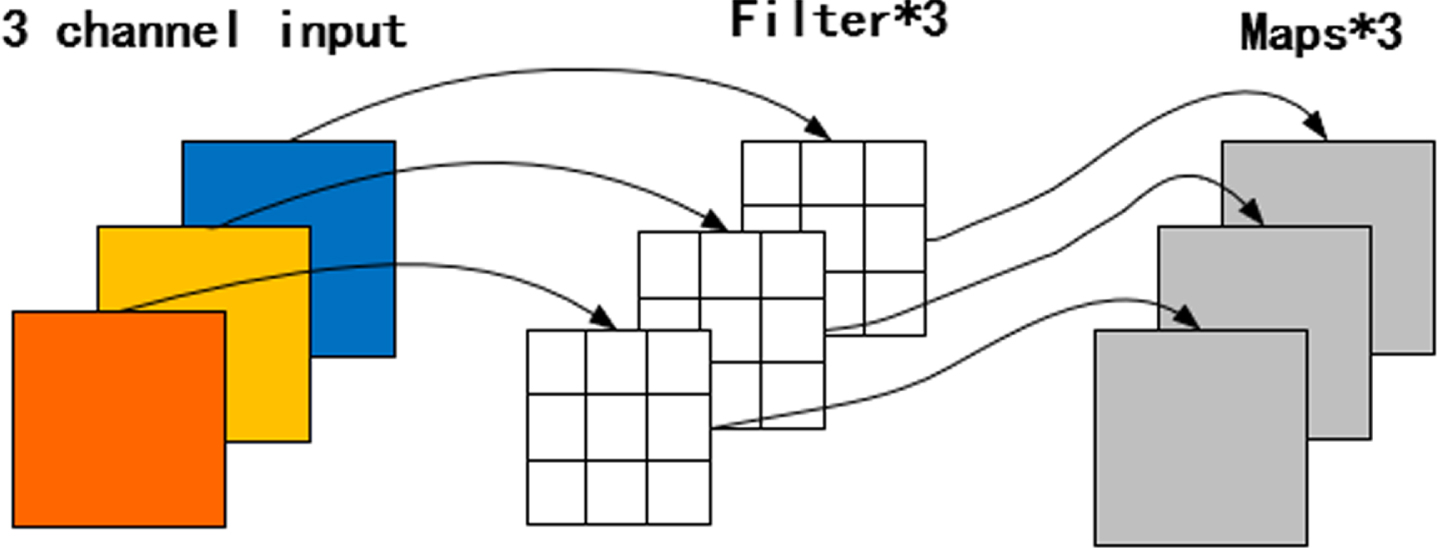
The work way of DW convolution.
The structure has four branches. Each branch is composed of 1 × 1 convolution, 3 × 3 convolution, 5 × 5 convolution and 3 × 3 max pooling respectively, which not only increases the width of the network, but also increases the applicability of the network to different scales. In the first branch, a 1 × 1 convolution is used. The 1 × 1 convolution is an excellent structure that can organize information across channels to improve the expressiveness of the network. At the same time, it can also increase and decrease the dimension of the output channel. In the second branch, a convolution of 1 × 1 is used first, and then a convolution of 3 × 3 is connected, which is equivalent to two feature transformations. The third branch is similar in structure to the second category, except that the 3 × 3 convolution is replaced by a 5 × 5 convolution. In the last branch, a 3 × 3 maximum pooling is performed, followed by a 1 × 1 convolution. Finally, the results of the four branches are combined in the output channel through an aggregation operation.
Mobilenetv3 [31] focuses on lightweight CNN networks in mobile terminals or embedded devices. Compared with traditional CNNS, Mobilenetv3 greatly reduced model parameters and computation on the premise of slightly reduced accuracy. This was mainly because depth wise (DW) convolution was used instead of standard convolution in MobileNetv3 networks. The characteristic of DW convolution was that one convolution kernel was only responsible for one feature channel, so the number of convolution kernels was equal to the number of channels in the previous feature layer. Since DW convolution cannot extend feature layers and cannot utilize feature information of the same spatial position in different channels, a convolution with a size of 1×1 is generally added after DW convolution to change feature dimensions and generate new feature layers by weighted combination of feature layers.
W_IMCNN architecture
In this paper, we propose a new CNN model for wood species identification based on Inception and MobilenetV3 network. Therefore, we call this model W_IMCNN, and its structure is shown in Fig. 5.
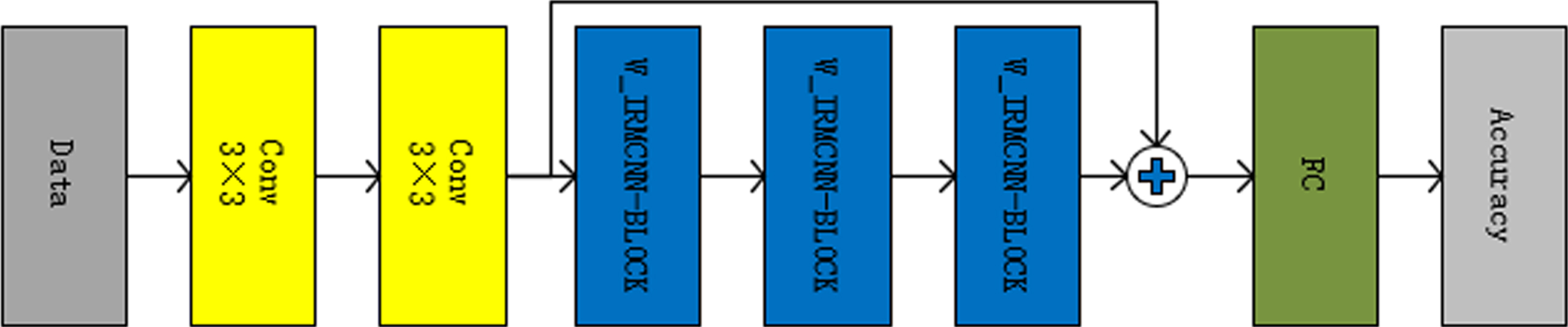
The structure of W_IMCNN.
The main objective of this model is to improve recognition performance of the model by using fewer computational parameters and less training time compared with other deep learning methods. In this model, the W_IMCNN unit used are modified based on Inception. The improvement of the model is mainly carried out from the following aspects: In order to reduce the number of parameters in the network model and not change the receptive field in the process of convolution, multiple 3×3 convolution kernels were used in this paper to replace the 5×5 and 7×7 convolution kernels in the network model. This operation not only reduces the training parameters of the network but also improves the training speed of the model. In order to improve the convergence speed of the network and the classification accuracy after network convergence, DW convolution was used to replace the 3×3 convolution in the inception module branch. And BN layer operation is added after DW convolution to standardize the input features. The working process of BN layer [32] is as follows:
Values of X over a mini-batch:
Then the mean and variance of the mini-batch:
Calculate the normalized input value
Where γ and β are parameters to be learned. In order to make full use of the information of the underlying characteristics, different network models were usually constructed through the layer connection method such as Resnet, Mobilenetv3 and other network models. Therefore, in this paper, the input and output parts of W_IRMCNN-unit are connected using the jump layer connection. The resulting W_IMCNN-block module is shown in Fig. 6.
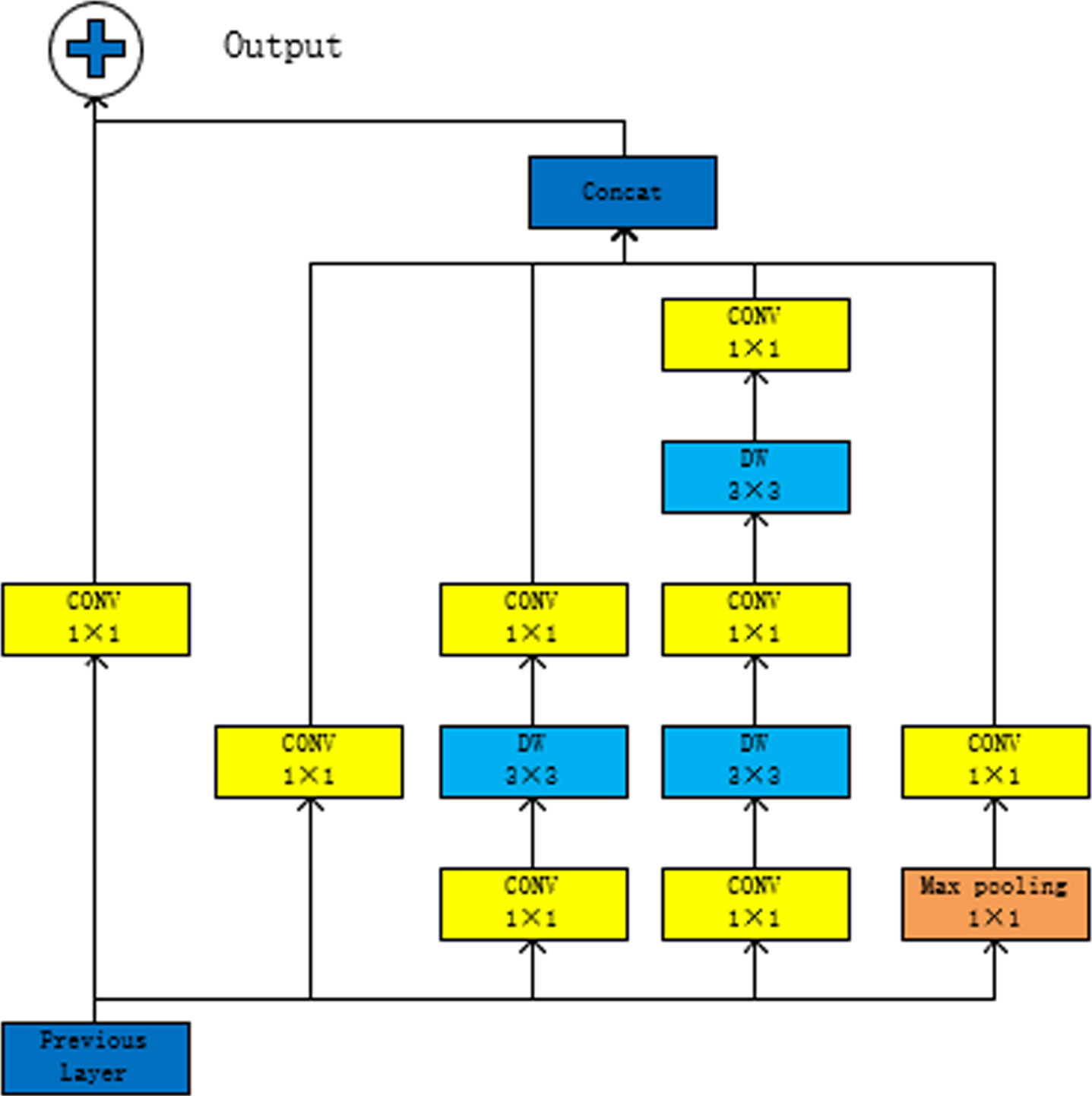
W_IMCNN block.
The convolution layer is the core layer of CNN. Multiple convolution kernels are generally used to extract different feature information of the input layer. In W_IRMCNN network, the convolution process is as follows [22]:
Here, l represents the lth convolutional layer,
In the W_IRMCNN-unit module, the output of each branch can be expressed as y1×1 (x), y3×3 (x), y5×5 (x),
Here ⊕ represents the splicing of dimensions of feature graphs obtained from different branches. Then the output of W_IMCNN-unit were added to the input of W_IMCNN-block. The residual operation of the W_IMCNN-block can be expressed by the following equation [34].
Here xl+1 refers to the output of W_IMCNN-block, and x represents the input samples of the W_IMCNN-block. The input characteristics of the first W_IMCNN-block were added to the output characteristics of the last W_IMCNN-block and pooled. Finally, fully connected layers was used at the end of the network structure to predict the classification probability. And its formula is shown as follows [22].
In Formula (9), W stands for weight, b denotes bias.
Related parameters of the W_IMCNN
Learning rate and adam optimization algorithm
Learning rate is an important hyperparameter in deep learning. Appropriate learning rate can make the loss function converge to the minimum value in a short time. In this paper, four groups of learning rate, namely 0.01, 0.001, 0.0001 and 0.0002, were selected. After repeated comparison of the models, the learning rate was finally set as 0.0002. Batch size also affects the performance and training speed of the model. In order to adapt to the computing capacity of the equipment, we set batch size to 32.
In this paper, Adam optimization algorithm was used to train the network. Adam combined the optimal performance of AdaGrad and RMSProp algorithm, and also provided a solution to the problems of noise and sparse gradient. And the process of adjusting Adam parameters was relatively simple. The formulas of this algorithm are given below [35].
In Formula (2), f
t
(θ
t
) represents stochastic objective function with parameters, θ is parameter vector, g
t
represents the gradient of f
t
(θ
t
) with respect to θ.
In Formulas (3) and (4), β1 and β2 denote exponential decay rates for the moment estimates, where m
t
and v
t
respectively represented the first moment vector and the second moment vector
Here,
Here, θ t represented the updated parameter, α was learning rate, and ɛ was a small constant with a stable value.
In the training process of the model, we used the Cross Entropy function to calculate the loss [20], and its calculation formula is as follows.
In Formula (8), W stands for weight, b denotes bias,
The W_IMCNN model proposed had been evaluated using two datasets: the dataset collected in this paper and wood-Auth. the datasets statistics were provided in Table 1. The hardware environment of this experiment was configured as Intel(R) Core (TM) i5-8400 CPU, the main frequency was 2.81 GHz, the running memory was 8 G, the GPU was NVIDIA GTX1060, 3 G. The software environment was CUDA Toolkit 10.0, CUDNN V 7.4.1.5; Python 3.6.1; Torch 1.9.0.
AlexNet, MobileNetV3, ResNet34, GoogLeNet, and W_IMCNN were used for comparison. In this paper, we iterated 100 epochs in the training set to update parameters, used the validation set to check whether the network model had been fitted. We adopted an early stopping strategy to monitor the validation set accuracy for the last 20 epochs. If the validation set accuracy did not improve, we stopped the training. And finally, we used the test set to obtain the recognition accuracy of the model.
Experiments on the data set constructed in this paper
In this experiment, the data we used were shown in Table 1 including 16 categories. The recognition performance of each model was shown in Table 3. After analysis and comparison, it was found that the parameter number of W_IMCNN model was the smallest, which was only 4.3 M. The training time was also greatly reduced compared to other models except AlexNet model. The model also had the highest recognition accuracy, which reached 96.4%. The validation accuracy of each model was shown in the Fig. 7, and the proposed W_IMCNN showed better recognition performance.
Comparison of recognition performance of each model on the data set constructed
Comparison of recognition performance of each model on the data set constructed
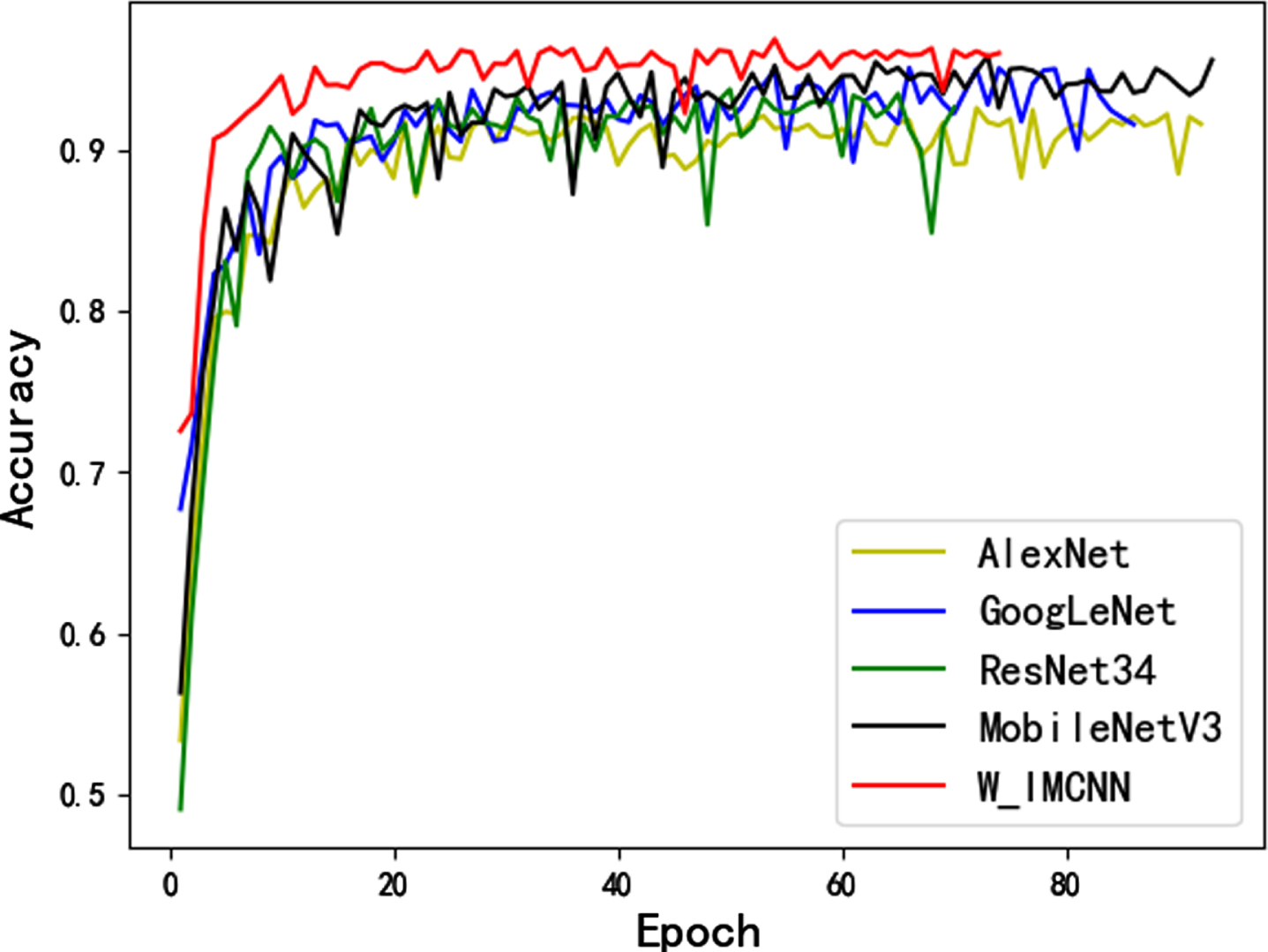
Validation accuracy on the data set constructed.
Where training time represents the time used for each training epoch.
In this experiment, we used a Wood-Auth dataset with 8,544 image data in 12 categories, but this data set had been enhanced in this paper. These were the first 12 types of data images we showed in Table 1. The recognition results were shown in the Table 4 and the validation accuracy of each model on WOOD-AUTH datasets was shown in the Fig. 8. After analyzing and comparing the data in the table, we found that W_IMCNN still had a good recognition effect, and the recognition accuracy of the test set reached 98.8%, higher than all other models. After network convergence, the recognition accuracy of validation set was stable and the recognition accuracy was the highest.
Comparison of recognition performance of each model on WOOD-AUTH datasets
Comparison of recognition performance of each model on WOOD-AUTH datasets
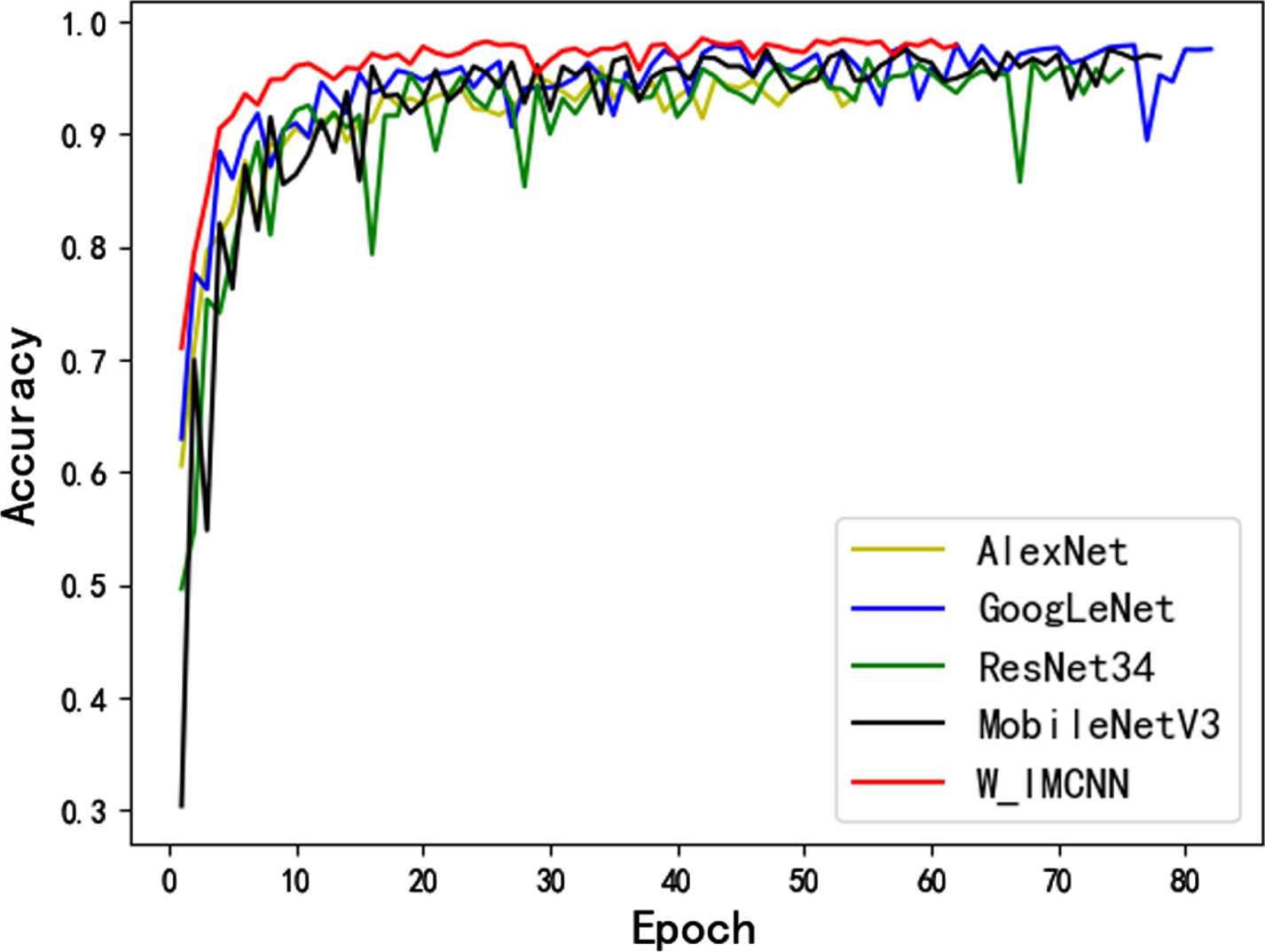
Validation accuracy on WOOD-AUTH datasets.
In this study, we proposed W_IMCNN for wood species recognition based on Inception and MobilenetV3 network construction. Our aim was to reduce the size of the model as much as possible, reduce the training time and improve the recognition accuracy of the model. Experimental results on the test set showed that the W_IMCNN proposed in this paper had the best recognition performance compared with other networks. The model size is only 4.3 M, and the network model could be deployed to mobile equipment for rapid detection of wood species. In addition, wood-Auth data sets were used for evaluation. In this dataset, W_IMCNN also achieves the best recognition performance.
Most of the images collected in this paper were obtained under ideal conditions. Therefore, in the following study, we aim to obtain wood image data taken under different conditions as much as possible and conduct a deeper study on the network model to realize the recognition of wood image types in different environments and under different lighting conditions.
Disclosures
The authors declare no conflicts of interest associated with this paper.