
Abstract
Python is a concise language which can be used to build lightweight tools or dynamic object-orientated applications. The various attributes of Python have made it attractive to numerous malware authors. Attackers often embed malicious shell commands into Python scripts for illegal operations. However, traditional static analysis methods are not feasible to detect this kind of attack because they focus on common features and failure in finding those malicious commands. On the other hand, dynamic analysis is not optimal in this case for its time-consuming and inefficient. In this paper, we propose PyComm, a model for detecting malicious commands in Python scripts with multidimensional features based on machine learning, which considers both 12 statistical features and string sequences of Python source code. Meanwhile, three comparison experiments are designed to evaluate the validity of proposed method. Experimental results show that presented model has achieved an excellent performance based on those practical features and random forest (RF) algorithm, obtained an accuracy of 0.955 with a recall of 0.943.
Introduction
With the development of science and technology, the Internet has been gaining popularity at a fantastic rate, bringing us incomparable convenience in our daily life and work. As a concise programming language with simple grammar, Python can be used to make dynamic object-orientated applications. In particular, Python language experienced a considerable boost when Django 1 and Flask 2 came along as it has made easier for users to create Python applications.
The properties of low learning threshold, ease of use, rapid development, and massive library collection have made Python attractive for millions of developers, including malware authors. According to a report from Imperva, when they checked the websites which were protected by them, more than 77% sites were attacked by Python-based tools [20]. As with everything, criminals have found a nefarious method to apply it. They often embed malicious shell commands in Python scripts to perform illegal operations such as privilege escalation, backdoor installation, account manipulation, and malware downloading.
Traditional detection techniques based on regular expression have problems of low accuracy and difficulties in dealing with changes. Those methods based on common features and machine learning are hard to capture the malicious command. Meanwhile, it comes with many challenges to detect those malicious commands in Python scripts. First, due to the flexibility of Python language, criminals may evade detection in different ways. The bypass methods of Python are summarized in Table 1. Commands may be divided into multiple short strings and finally spliced using the ’+’ operator, or may be base64-encoded and then decoded using Python’s built-in base64 module. Sometimes, attackers tend to obfuscate malicious commands by using Python string manipulations, such as “join()", “reverse()", slice operators, etc. And there are many unusual import methods, such as importing from built-in modules, importing by inheritance, or importing from original module path. What’s more, there are copious obfuscation or encryption tools available on the market, such as ASTObfuscate 3 , pyobfuscate 4 and PyArmor 5 , etc. Second, although a system-calling function like “os.system()” is often required to execute a command, it is difficult to extract entire function arguments from a complicated Python script. Meanwhile, it is also possible for an attacker to encapsulate such system call functions and rename them. Third, strings in Python scripts may have a lot of non-command text or garbled information, which is too intrusive for us to extract pure command text for analysis. To overcome those challenges, in this paper, we present PyComm, a model based on the RF [16] algorithm, which combined with statistical features and string information that can detect malicious or even obfuscated commands in Python script.
Bypass methods
Bypass methods
The contributions of this paper are summarized as follows: This paper introduces two sets of features to find malicious commands in Python files. These features can be summarized as 12 statistical features and word features of string sequences. Experiments show that the combination of two sets of features has better performance than using one single group. This paper designs an automatic malicious commands detection model of Python scripts, which based on multidimensional features and the RF algorithm. To our knowledge, we are the first team to detect malicious commands in Python scripts from the static analysis level. To prove the effectiveness of the model, this paper compares receiver operating characteristic (ROC) curves [8] of four machine learning algorithms. The experimental results show that the area under ROC (AUC) [18] value of the proposed model is 0.99, which means it has the best detection performance.
The rest parts of this paper are organized as follows. Section 2 provides the background of shell commands and gives a brief overview of the recent related work about malicious scripts and malicious commands detection methods. Section 3 presents the framework of our detection model and describes each part in detail. In Section 4, a series of experiments are carried out and the experimental results are analyzed. And then four prevention methods are given to defense this kind of attack in Section 5. Finally, conclusions are presented in Section 6.
Background
Shell is a command-line user interface through which users interact with the operating system. As early computers did not have a graphical interface, programmers used shell to run programs and configure computers. Besides, shell is still used wildly today because visual interfaces are expensive to develop and cannot manage everything of the OS. All the commands inside the shell are actually programs. By using shell commands, we can operate files, user accounts, networks, and other resources of the operating system. However, criminals often embed malicious commands in Python scripts to perform illegal operations. For example, the phishing Python package “pyscrapy", which uses a similar name to the popular crawler library “scrapy", has malicious commands in “setup.py” file which leads to remote access trojans download and triggered automatically on the target host [3]. The code fragment of "setup.py” is shown in Listing 1. In this paper, we focus on UNIX-like shell commands and there are five common types of malicious commands: (1) Reverse a shell. (2) Access to sensitive information. (3) Upload or download files. Attackers may download malicious scripts from the Internet and execute them on the victim’s computer or upload local files to the attacker’s website, causing sensitive information leakage. (4) Add an account, delete an account, add a group, and other account operations. (5) Implant the attacker’s public key to achieve free login. The corresponding examples are listed in Table 2.
Example of malicious commands
Example of malicious commands
In this part, we firstly introduce three different types of malicious script detection methods: static analysis, dynamic analysis, and combination of static analysis and dynamic analysis. At last, we shortly summarize the recent work of malicious command detection.
Static analysis method
Static analysis provides an understanding of the code structure and mostly focuses on the static features of the detection targets. NeoPI [1] extract five kinds of statistical features, including entropy, longest word, index of coincidence, signature and compression to search for potential malicious code which is confused or encoded. But it only did quantitative testing and did not evaluate the scripts qualitatively. Nowadays, machine learning techniques are also applied in malicious script detection, improved detection accuracy and efficiency. Zhang et al. [34] used the opcode bi-gram model to extract the features, compared with different machine learning algorithms, finally found that the model combination of Naive Bayes classifiers and opcode sequence has the best effect. Then, they designed an ensemble learning classifier to further improve the accuracy. Guo et al. [24] proposed a model based on convolutional neural network to detect and identify the malicious scripts by analyzing PHP opcodes which are converted from PHP source files. Some researchers also used abstract syntax tree to obtain semantic information from malicious code, which could detect common obfuscated code in a certain degree. For example, Fass et al. [12] proposed JStap, a modular static detection system, which extends the detection capability of existing lexical and AST-based pipelines by leveraging control and data flow information. Fang et al. [11] proposed a detection model combination of syntactic unit sequences converted from abstract syntax tree and Bi-LSTM network with attention mechanism. In a word, these detection works based on static methods are mainly focused on using machine learning methods and processing the original code.
Dynamic analysis method
Dynamic analysis methods extract behavioral features by executing codes in a real or virtual environments. Gorji et al. [14] detect obfuscated JavaScript malware by matching the sequence of the web page’s intercepted function calls with the behavioral signatures set. This set is generated by loading a list of malicious web pages in a real web browser, collecting a sequence of predictive function calls using internal function debugging for each of pages and then grouping similar sequences into the same cluster based on the normalized Levenshtein distance (NLD) metric for each cluster. Hu et al. [17] proposed JSForce which can overcome the problems such as limited code coverage and incomplete environment setup. By forcing the JavaScript snippets to execute through different code paths, JSForce catches the exploitation code regardless of the result of the fingerprinting statement. Then JSForce will invoke the callback function passed to setTimeout to trigger the time bomb malware. Zhang et al. [33] propose a Webshell traffic detection model combining the characteristics of convolutional neural network and long short-term memory network and a character-level traffic content feature transformation method. Their experiment result indicates that the model has a high precision rate and recall rate, and the generalization ability can be guaranteed.
Combination analysis method
Static detection methods are based on signatures, which obfuscated malicious code can easily evade by changing the appearance of source code. Dynamic detection methods often require specific execution environments and cause a long detection time. Therefore, some researchers proposed combination analysis methods. Starov et al. [30] use static and dynamic methods to analyze WebShell, and find the visible and invisible characteristics of commonly used malicious shells, such as concealment, authentication mechanism, and interface characteristics. The experiment sets up honeypots to quantitatively analyze the shell’s third-party attackers. GuruWS [22] is a hybrid platform for detecting malicious web shells and application vulnerabilities. GuruWS choose taint analysis and pattern matching methods for malicious web shell detection.
Malicious command detection
Traditional malicious command detection methods are mostly based on pure command text. Danny Hendler et al. [15] use several novel deep learning classifiers combined with a natural language processing (NLP) classifier to detect malicious Powershell [6] commands. They finally find the character-level convolutional neural networks (CNN) classifier has the best performance. Their result shows that the CNN classifier can detect some obfuscated commands which are not captured in a single NLP classifier. Before long, they proposed a new method by using contextual embeddings [27]. They collected a large number of real datasets from AMSI [23] and divided them into unlabeled datasets and labeled datasets. The unlabeled Powershell scripts are pre-trained for better representation of text characteristics. Finally, the embedding of word-level token and one-key encoding at the character-level were combined to provide input representation to the deep learning model, enabling it to learn features based on the combination of signals from the two levels. Pierre Dumont et al. [10] focused on commands executed in the UNIX-like shell of a system, using kNN and N-gram to distinguish the malicious and benign shell sessions based on commands that appeared in shell sessions. SEA dataset [28] is the most widely used dataset in the field of malicious command detection, which was published by Schonlau et al. It is often used in the research of internal pretenders’ threat detection [7, 19]. Nevertheless, the SEA dataset only has the command sequence and does not contain information such as parameters after the command. For the same command, different arguments can have the opposite effect. For example, the “cat” command can be used to view the contents of a file. However, a “cat” command with a general file or a sensitive file has different threats.
Neither of the above methods can be used directly for malicious command detection in Python scripts. Traditional static analysis methods do not or only concern about string sequence, which cannot find the malicious commands or may lead to a high rate of false positive. Dynamic analysis methods have a high accuracy and recall, but they are time-consuming and inefficient, and might be exploited by executing the malicious scripts in a detector. Therefore, we propose a static analysis method that focuses on statistical features and string sequence. The detailed information will be described in the next section.
Listing 1: Code fragment with malicious commands of phishing module “pyscrapy”.

Framework
In this part, we describe each part of our proposed model PyComm in detail. It is composed of several modules, which are data analyzer, feature extractor and classifier. As shown in Fig. 1, first of all, we parse the source code to an abstract syntax tree (AST) [31], which presents a syntax structure of the programming language in a tree by using the built-in AST module in Python and help to extract precise information. In order to improve detection results, we implemented a string value preprocessor whose main goals are to perform command decoding and string normalization. After that, walk through the nodes of the abstract syntax tree to extract the rest features. The specific feature information will be described in the following part. Before training, in order to balance the benign and malicious samples, we oversampled the malicious samples using synthetic minority oversampling technique (SMOTE) [4] algorithm, making the ratio of positive and negative samples after sampling reach 1:1. Finally, all the above features would be combined and put into the RF classifier for training and prediction.
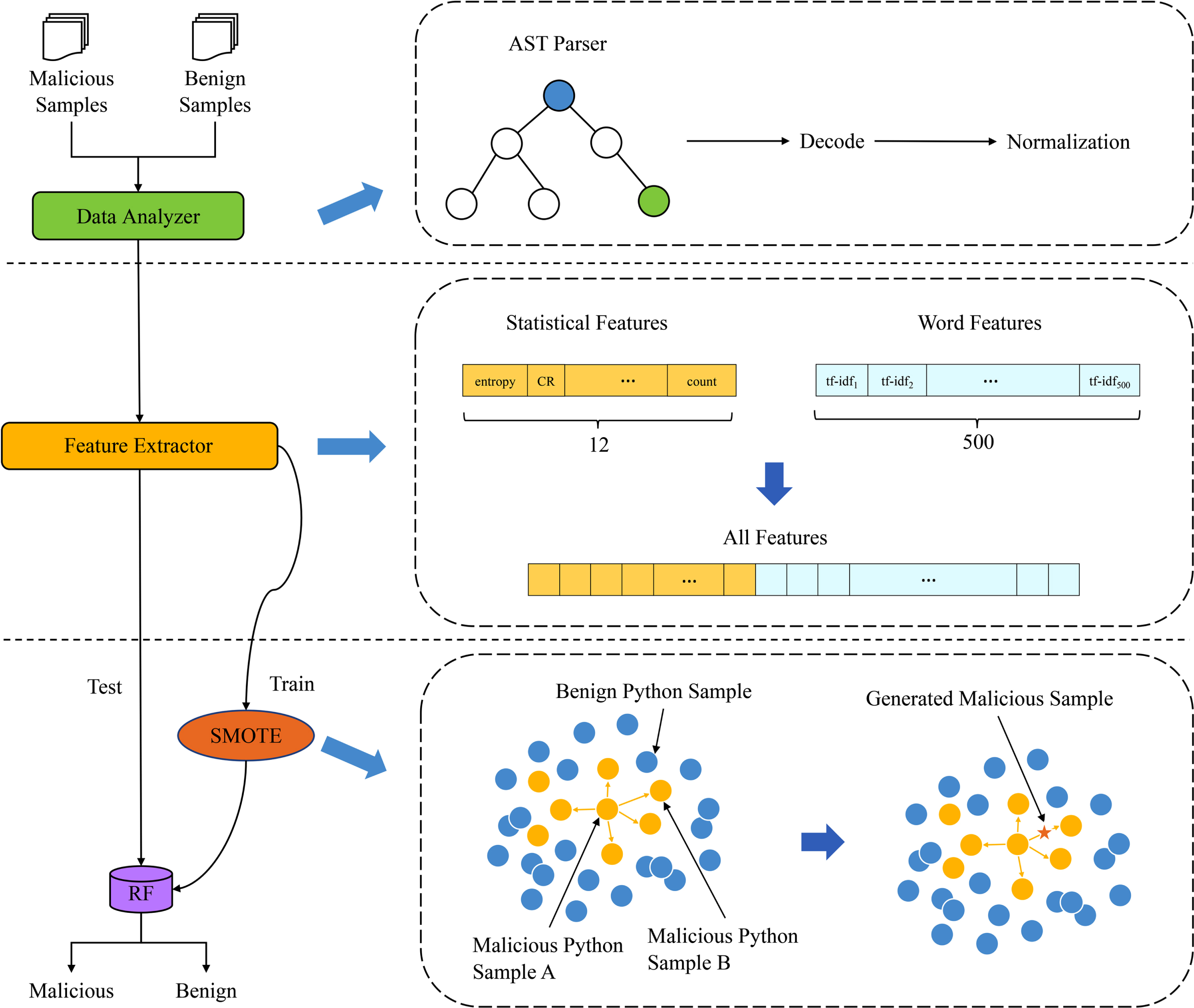
The framework of the proposed model PyComm.
To apply detection on “cleartext", we make a string value preprocessor for decoding commands with base-64 or hexadecimal encoding, and normalization. The preprocessor normalizes string values by replacing all IP addresses with “0.0.0.0” and all other numbers with zero. We also observed that shell command is case-insensitive, so the preprocessor converts all letters in the string to the lowercase for better word collection. Figure 2 shows the pre-processing exapmle of malicious code file.

The comparison of malicious scripts before and after processing.
In this part, we make a detailed introduction of selected features in our experiment. First of all, we extracted statistical features of Python scripts, such as information entropy, compression rate, sensitive directory count, etc. Combined with these statistical features, we gained a 12-dimensional feature vector.
However, through collecting the above features, we may not get a prominent model due to the low dimension of our feature vector. Besides, commands usually appear in the string of the code. Therefore, we extracted the string sequence from each Python script, which will give us more information.
Statistical features
We have extracted 12 statistical features from Python scripts, as shown in Table 3. These features can be divided into four categories: static obfuscated features, function features, import module features, and file features.
The detail of statistical features
The detail of statistical features
Information Entropy. It was proposed by Claude Shannon, the father of information theory, to reflect the uncertainty and confusion of information [29]. In general, the higher the entropy of the code, the more confusing the code is. The formula for calculating information entropy is as follow:
Data Compression. It is the process of representing information with fewer data bits according to a specific encoding mechanism. To bypass the detection, attackers may use some encoding mechanism to convert the code into an incomprehensible character representation. By calculating the compression rate, we can better identify malicious scripts. The compression ratio represents the ratio of the file size after compression to the size before compression. The calculation formula is as follow:.
String Manipulation. As shown in Table 2 above, an attacker might use different string manipulation functions to slice up the malicious command and combine these fragments in a certain way, or convert commands to illegible content. If there are more than three string manipulation functions appearing in the code, the script is considered likely to be malicious.
For UNIX commands, it is more appropriate to consider meaningful groups of commands rather than individual instructions. Due to the similarity of commands, the frequency of high command sequence should be given a lower weight in most cases. In fact, high frequency in a single script but the low frequency in other scripts, or not appear, should be given greater weight, which helps to distinguish the malicious and normal command sequences.
Therefore, we firstly extract the string sequences based on bag of words (BOW) model and N-gram. Then, we calculate the TF-IDF [21] value of each N-gram and finally get the word feature vector of 500 dimensions. BOW: The BOW model is used to count the number of a word appears in a document. This method does not consider the order in which the words appear but treats each word that appears in the training text as a separate list of characteristics. N-gram: N-gram is the most basic and essential method in natural language processing. It has been successfully applied in malicious code detection [5, 26]. N-gram uses a sequence of commands as a phrase that represents information different from a single element. When used in combination with a single command, it can gain more expressive power than when using a single word alone. TF-IDF: TF-IDF (Term Frequency-Inverse Document Frequency) belongs to the category of numerical statistics. Using TF-IDF, we can learn the importance of a word to a document in a dataset. Specifically, it refers to the times of a particular word appears in the dataset and its importance in the document. TF-IDF has two parts, term frequency (TF) and inverse document frequency (IDF). TF represents the frequency of each word in a document or dataset. IDF describes the importance of a word to the document. The more a word appears, the higher its TF will be. However, this word may not carry so much information, so we need to give them weights to determine the importance of each word. Their definitions are shown in formula (3)-(5):
Where, ni,j is the frequency that word
i
appears in file d
j
; the denominator is the sum of all the words occur in the file d
j
; D is the total number of documents in the corpus, and |j : t
i
∈ d
j
| represents the number of files containing the word t
i
.
In order to solve the problem of data imbalance, SMOTE algorithm is used to over-sample a few data (malicious samples). SMOTE is an over-sampling algorithm and the main idea is to synthesize the new minority sample according to the distance in “feature space". The specific realization is to randomly select a sample B’s feature vector from the nearest neighbors of sample A’s feature vector and then select a point on the line between A and B as the newly synthesized minority sample. The algorithm is as follows. For each sample A in the minority class, the Euclidean distance is used as the standard to calculate the distance from it to all samples in the minority class sample set and then get K nearest neighbors. A sampling ratio was set according to the sample imbalance ratio to determine the sampling multiplier N. For each minority sample A, several samples were randomly selected from its K-nearest neighbors, assuming that the selected nearest neighbor was B. For each randomly selected nearest neighbor B, the new sample C is constructed with the original sample A respectively, according to the following formula (6).
The lower right of Figure 1 shows the comparison of original dataset and after dataset oversampled by SMOTE algorithm. The blue circles indicate benign python samples, the yellow circles indicate malicious python samples, and the orange pentagon refers to the generated new sample by using SMOTE algorithm.
Overfitting is easy to occur when unbalanced data is oversampled and converted into balanced data. Simultaneously, a single classifier has the bottleneck problem of performance improvement, so ensemble learning [9] is chosen to improve model accuracy and generalization ability. RF algorithm is an ensemble learning method based on the decision tree [25], first proposed by Tin Kam Ho [16] and then improved by Leo Breiman [2], which can process high latitude data and has good tolerance to noise and outliers. It is a model composed of multiple decision trees. This model is different from the general situation where a decision tree is used as a base learner, and bagging is combined to build a classifier. Instead, data samples and feature subsets are extracted in a random way to build a decision tree. The final results are obtained by averaging the prediction of each decision tree.
Experiment and evaluation
In this section, we describe the process of our experiment in detail. Firstly, we collect samples from the Internet and randomly divided the entire dataset into a training set and a test set as 7:3. In order to avoid acquiring lexical information on the test set, we only collect the grams on the training set. Then, we extract 12 statistical features and word features from samples. To solve the problem of data imbalance, we use SMOTE algorithm to oversample the malicious samples in the training set. Next, we put all the features into the RF model for training and prediction. This process is repeated ten times to get the final mean results. Finally, we make three comparison experiments to evaluate the performance of our detection model.
Dataset and experimental environment
To train and evaluate our classifier, we needed data from both benign scripts and malicious scripts with commands. The benign Python scripts for this experiment were from the top 100 Python projects of Github. The malicious samples came from open platforms, which are Vx-Heavens 6 , Github and Malshare 7 . A total of 1651 samples were obtained, among which 1330 were normal samples and 321 were malicious samples. In our dataset preparation, we labeled the benign Python script as 0 and the malicious Python script as 1.
Evaluation indicators
The research we study in this paper is a binary classification problem. Therefore it will have the following four situations. If a sample is actually malicious and the prediction is malicious, it will be classified as true positive (TP). If a sample is benign but the prediction is malicious, it will be classified as false positive (FP). Correspondingly, if a sample is actually benign and the prediction is benign, we call it true negative (TN), and if it is actually malicious but the prediction is benign, we call it false negative (FN). The above four values can be represented by a confusion matrix as shown in Table 4.
Confusion matrix
Confusion matrix
To measure the performance of our detection model in the experiment, six indicators were selected, which are accuracy rate, precision rate, recall rate, F1-score, ROC curve and AUC (Area Under Curve) score. Accuracy rate refers to the percentage of all predictions that are correct (including positive or negative samples). Precision rate is the proportion of positive identifications which are actually correct. Recall is the actual positives which are identified correctly. F1-score conveys the balance between the precision and the recall. ROC reflects the relationship between true positive rate (TPR) and false positive rate (FPR). The definitions of TPR and FPR are as follows:
The vertical axis of ROC corresponds to TPR, and the horizontal axis corresponds to FPR. AUC can be calculated by summing the areas of each part under the ROC curve. Assume that the coordinates of ROC curve are {(x1, y1) , (x2, y2) , . . . , (x
m
, y
m
)}, where m is the number of samples. In general, the higher the value of AUC, the better the classification effect of the model. The calculating formulas of these indicators are as follows:
Because of the unbalanced samples and the noises in the string content, in order to get the command related words effectively, we extract the frequency of the top 10000 phrases and then TF-IDF values are calculated respectively, which will be a 10000-dimensional TF-IDF vector. After that, we use the principal component analysis (PCA) algorithm [32] for its dimension reduction, finally get a 500-dimensional TF-IDF vector.
PCA is a feature selection method, which is often used in static analysis to achieve dimensionality reduction of sample data. PCA projects the original data under a new coordinate system through a linear transformation and expresses the data by the maximum linearly independent group in the new space, and the spatial coordinates of the eigenvalues of this linearly independent group are the features selected by the PCA.
In addition, for most machine learning algorithms and optimization algorithms, feature scaling is a key step in feature preprocessing. For the 12 statistical features, the difference between the value ranges of different features may be large, which may cause the influence of other features on the results to be ignored. Therefore, feature scaling is adopted to solve such problems. By standardizing the feature columns, the mean value of the feature columns can be set to be 0 and the variance to be 1, so that the values of the feature columns are in a standard normal distribution, which contributes to preserving the useful information contained in the outliers and making the algorithm less affected by these values.
At the same time, the performance of the model is often significantly different with disparate parameter configurations. There are two critical parameters in the RF algorithm, which are “n_estimators” and “max_depth” respectively. “n_estimators” indicates the maximum number of weak learners. In general, if the "n_estimators” is too low, the model may be underfitting. However, If “n_estimators” is too high, the calculation amount will also increase. After “n_estimators” reach a certain number, the model improvement obtained by increasing “n_estimators” will be minimal. "max_depth” indicates the max depth of the decision tree. In other words, this value represents the maximum number of features used by a single decision tree. If this value is too small, it is easy to be under-fitting. If this value is too large, it is easy to over-fitting. So it is essential to find appropriate values of "n_estimators” and “max_depth” respectively. To get the best performance of our model, we use GridSearch to find the most appropriate parameters. { 10,20,30,40,50,60,70,80,90,100 } was prepared for “n_estimators", and {5,6,7,8,9,10,11,12,13,14,15 } was prepared for “max_depth". Finally, the optimal value of "n_estimators” is 80, and the optimal value of “max_depth” is 10.
Table 5 presents the final results of our model. The accuracy is 0.955, the precision rate is 0.918, the recall rate is 0.943 and the F1-score is 0.930.
Accuracy, precision, recall and F1-score of the proposed model
Accuracy, precision, recall and F1-score of the proposed model
In order to verify the validity of the model proposed in this paper, the following three experiments were designed. Moreover, it is hard to make a comparison experiments with existing research methods since we are the first team to detect the malicious commands in Python scripts.
Experiment 1: the influence of different N-gram
In the experiment, we set the value of N-gram as (1,2), which means the word frequencies of 1-gram and 2-gram were counted simultaneously. In order to evaluate the influence of the parameter N in N-gram on the detection performance, Table 6 shows the case where the value of N is changed for the RF algorithm. In this paper, 1-gram, 2-gram, and (1,2)-gram were selected for analysis and comparison. 1-gram represents the use of only a single command as a feature, equal to using only the BOW model. 2-gram means to select only two continuous commands. (1,2)-gram means to combine 1-gram and 2-gram as features. As shown in Table 6, the effect of using only the 1-gram feature is better than that of only using the 2-gram feature, indicating that the contribution of a single command feature to reflecting the difference of different user behaviors is higher than that of using two consecutive commands. Therefore, many existing detection methods that only apply BOW also achieve good detection results. Moreover, Table 6 shows that combining 1-gram and 2-gram as features is more effective than using one of them alone. Selecting reasonable N values and using N-gram under different N values are helpful to improve the performance of the model. However, the higher the value of N is, the result may become worse. It is found that the detection accuracy will not increase significantly when N>3 continues to increase. The reason is that features such as 4-gram, 5-gram, and 6-gram are less likely to appear in the command sequence. And the detection performance of extracting these features does not improve significantly but increases the training time.
The influence of different N-gram
The influence of different N-gram
As described in Section 3 above, we divided the features into two groups, one is statistical features, and the other is word features. To verify the effectiveness of the features we selected, we tested the detection performance of statistical features only, word features only, and the combination of the two groups, respectively. Table 7 shows the final results. To a certain extent, the results of using only statistical features reflect the effect of traditional detection methods based on common features. Correspondingly, the results of using only word features symbolize the performance of traditional command detection methods, which focus on pure string analysis. The accuracy of the results using only statistical features reaches 90%, which is higher than the results using only word features, indicating that it is effective to extract some common features of malicious scripts for detection. However, some scripts do not have this distinctive feature and are difficult to be captured by traditional detection methods, such as Listing 1, whose maliciousness is reflected in the parameters of os.system(). As shown in the results, although the recall of pure string analysis method is slightly higher than that of statistical features, it has a low accuracy and precision rate. However, the combination of two feature groups is more effective than using only one feature group, whose accuracy and recall rates increased by more than 10 points, suggesting that combining the two groups of features is very effective and the strings sequence in the source code also contains much useful information that can be used to detect malicious commands in Python scripts.
The influence of different feature selections
The influence of different feature selections
We designed this comparing experiment to show the advantages of the selected method in this paper. We selected three algorithms as the counterparts of RF, which are support vector machine (SVM), logistic regression (LR), and naive bayes (NB). Then these machine learning algorithms are used to train four models on the same data set. Figure 3 shows the ROC curves of the above four algorithms, where the performance of the NB model is the worst, with the AUC of 0.90. The ROC curves of SVM model is similar to that of the LR model and they have the same AUC of 0.96. By contrast, the graph shows that the performance of the RF model is the best, achieving the AUC of 0.99. Table 5 gives test results of other indicators of RF model.
The above experimental results prove that our final model has a high detection performance and a great generalization ability.
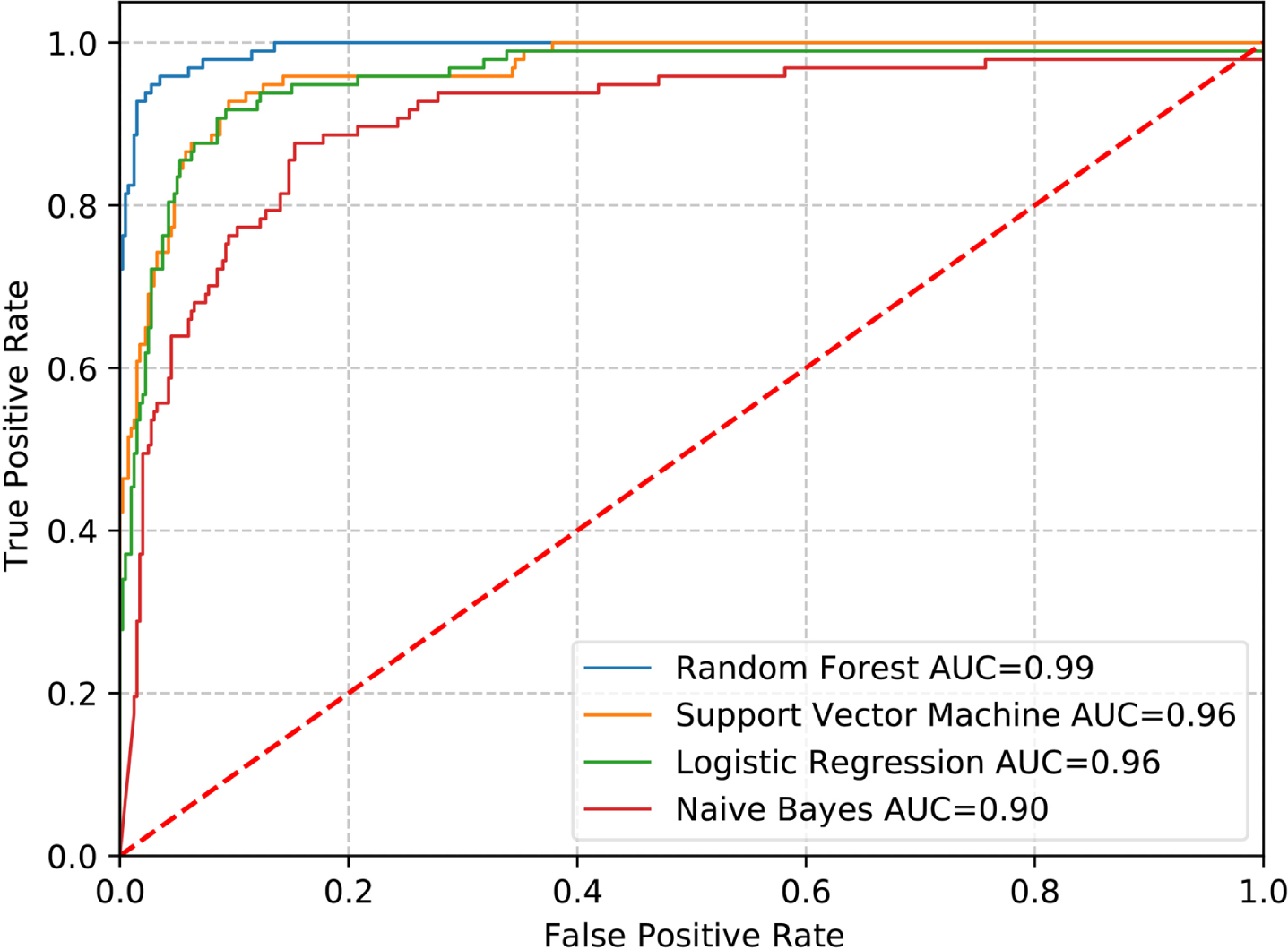
ROC curves for different classification algorithms.
The root cause that enables malicious command injection is lack of proper parameter preprocessing, which allows attackers to add additional commands. This can be prevented by the following methods: Do input validation or escape untrusted user input. This scheme is found in many PHP anti-injection methods, where special characters are escaped or filtered. Use structured mechanisms to separate data and commands, which can help provide the relevant quoting and encoding. Use some safe modules such as “safe_eval", which provides secure transformations for serialization operations, performs lexical analysis of eval data to ensure that it does not contain illegal parameters, and run “eval()” in isolated, secure environments. In addition, run with restricted permissions. The script should run with the minimum permissions required to complete the necessary tasks.
Conclusion
In this paper, we introduced a popular attack method which implements by embedding malicious commands in Python scripts. And then we listed five common types of malicious commands and the challenges faced by traditional detection. In order to solve the problem that the traditional static detection method is difficult to detect the malicious commands embedded in Python scripts, this paper proposed PyComm, a detection model based on multidimensional features and machine learning. By extracting the statistical features and word features of string sequence, we adopted RF algorithm to train an effective model. We conducted three groups of comparative experiments. The experimental results show that our model achieves an excellent performance, with an accuracy of 0.955 and a recall of 0.943, which prove that the string in scripts contains much useful information for malicious command detection. Finally, we gave four prevention methods for Python developers.
We see potential future work particularly in two directions: (1) At present, the size of the dataset is not very large for it is difficult to collect samples in the security field. If we get more data in the future, it is a good trial to apply some deep learning methods. (2) How to extract purer parameter information? All the parameters and strings in the script are obtained, which leads to a large noise. In fact, only a small part are the content of malicious command execution. In the near future, we intend to reduce the noise and obtain more accurate parameter information.