
Abstract
Impreciseness and uncertainty are the fabrics that make life interesting. For decades, human beings have developed strategies to cope with uncertainties and automate them. In personnel selection for the I.T. field, selectors often find it very difficult to select candidates by going through a set of resumes containing similar kinds of skills. Hence the selection task becomes a fuzzy decision making with the uncertainty involved. A combination of fuzzy clustering and Interval Type-2 fuzzy sets (IT2FS) is proposed in such scenarios. An experiment is conducted over a resume dataset containing fifteen hundred resumes for a particular job description. Firstly, Fuzzy C-means clustering (FCM) is applied for selective clustering, while decision-making under uncertainty is carried through IT2FS. The candidates in the selected cluster are given a score for ranking as per the skillset criteria. The final decision for shortlisting the resumes is carried through IT2FS. The model shows an average accuracy of 88.2% with an F1-score of 0.76 compared to (K-means + IT2FS) model with an F1-score of 0.72. Thus, the proposed model performs better while decision-making under uncertainty.
Keywords
Introduction
Personnel selection is a process to precisely select candidates with some skill, knowledge, and experience for the desired performance in a specified job [32]. In the hiring process, the selector searches for candidates who have the required professional skills and are suitable enough for their organisation. The process involves resume shortlisting followed by a technical interview round. Often the candidate’s skills do not precisely match the skills needed for the job. Apart from that, they may possess some other skills that may be indirectly crucial for organisational growth. Therefore selector gives weightage both to required professional skills and also to other skills. It provides some scope to the candidates to get shortlisted where they may be missing some required professional skills. These constitute the boundary cases and are hence regarded as uncertain cases. Now it is up to the selector to select the number of uncertain cases. For example, let us assume that a selector is looking for a resume with the required professional skill be: “Java programmer”,“Android”, while the skills mentioned in the candidates resume be: “Object-oriented programming”, “Team player”. In this case, the exact required skill does not match that of the candidates resume but still resume is not irrelevant as the candidate knows the Object-oriented concept (over which Java is based). Apart from that, the candidate has experience working with the team. Hence these skills are also given some weightage for selection, as the candidate seems to have a skill that is helpful in the organisation working culture.
A selector also receives hundreds of resumes for the interview process. It is challenging for him to go through all resumes manually; hence he may choose some starting candidate satisfying most of the requirements and interview them. The major drawback of this approach is that the work becomes very tedious and may leave out many suitable candidates for the post.
The paper provides a solution to semi-automate selecting the most appropriate resumes involving uncertain cases for the interview process. It reduces the burden of the segregating resume and helps the selector give more focus on the interview. A methodology such as selective clustering segregates the eligible resumes from a large set of applications. The fuzziness factor is a must in such models for incorporating the imprecision involved in the job requirement. Some standard information retrieval methods like TF-IDF (Term Frequency-Inverse Document Frequency) [29], LDA (Latent Dirichlet Algorithm) [37] and K-means algorithm are often used to segregate documents. These methods are used to find the similarity of the resume to the skill requirement, or they form a crisp cluster. Overall, these techniques do not help capture the imprecision and uncertainty involved in such human decision making.
The dataset
1
contains collections of approximately 1500 resumes for personnel selection downloaded from the Kaggle website
2
The following are the list of attributes in an applicant’s resume: Title: [“Seeking innovative and challenging career assignment in an organisation”, “Looking for Job as a Java developer”, etc.] City: [“Pune”, “Hyderabad”, etc.] State: [“Haryana”, “Telangana”, etc.] Description: [“Looking for a challenging career demanding best of my professional skills”, etc.] Work experiences: [{0: [{‘wtitle’: ‘Java Developer’}, {‘wcompany’: ‘Divergent software labs indore ’},{‘wduration’: ‘January 2018 to Present’}], etc.] Education: [{0: [{‘e_title’: “B.Tech.”}, {‘e_school’: ‘Calicut University’}, etc.] Skills: [‘Git’, ‘Maven’, ‘Java’, ‘Jenkins’,etc.] Links: [‘https://github.com/...’, etc] Certificates: [{0: [{‘c_title’: ‘Java Developer’}, {‘c_duration’: ‘June 2019 to Present’}], etc.] Additional information: [“Operating Systems”, “Version Control”, etc.]
All of these ten attributes contain the textual biodata of an applicant. However, some are non-useful attributes in the current process (such as links, city, state) because the selector mostly wants resumes to be segregated based on the skill, knowledge, and experience and not based on city or state. Further preprocessing includes removing noises such as special characters (example: hashtags, punctuation), dates, links, etc.
In order to deal with these boundary-cases (uncertain cases), the FCM (Fuzzy C-means) and IT2FS (Interval Type-2 fuzzy sets) are used in the proposed methodology. The FCM is applied over the preprocessed dataset to create two clusters: one containing the eligible resumes to the requirement and the other containing non-eligible resumes. The IT2FS gives the control to the selector to decide how many boundary cases (uncertain cases) will pass from the eligible resumes. If a selector is very strict on the requirement, he can choose the lower range of IT2FS output, while if the selector is quite flexible on the requirement, he can opt for a upper range of IT2FS. In the default settings, the mid-value of IT2FS is chosen for filtering. Therefore the inclusion of IT2FS provides an advantage to deal with uncertain cases. Hence it gives a chance to candidates to get shortlisted for the interview if they may be missing some required skills.
Literature review
Decision-making is involved in every aspect of our life. The decision-making process gets complicated when processing the adjective words like “good”, “cheap”, etc. These words are not only imprecise [40] but also carry two aspects of uncertainties with them: Intra-level uncertainty and inter-level uncertainty [21]. These uncertainties cannot be represented using Type-1 fuzzy sets, as they can only represent imprecision. Hence higher-order fuzzy sets (such as IT2FS) are used to capture the uncertainty involved with imprecision [22].
Personnel selection is a decision-making problem involving uncertainty. In order to solve this personnel selection problem, the literature review carried has been divided to cover the following two aspects: The first part of the literature presents applications involving clustering and classification, where uncertainty is tackled through IT2FS, while the second part presents decision-making approaches applied in personnel selection.
The concept of Computing with words (CWW) was introduced by Zadeh [41]. It is a methodology where the computation is performed using words drawn from the human language. The idea is taken from observing the human way of performing several mental tasks without involving measurements. In daily conversation, humans prefer to use words rather than talking in numbers. These words are imprecise and also carry uncertainty with them. These IT2FS models can represent linguistic words by capturing both imprecision and uncertainty [21, 24]. Mishra et al. [25] used the IT2FS model to perform CWW for decision-making, where the system suggests the suitability of a restaurant based on the subjective importance given to selection criteria (such as cost, price range and time). Similarly, IT2FS finds application in the following classification task where it inherently incorporates a tolerance range when deciding [30, 34].
Sharma et al. [33] used IT2FS for the classification of vehicles. Attributes such as vehicle body length, chassis height, wheelbase, ground clearance were taken. The type-2 fuzzy system outperformed the adaptive neuro-fuzzy inference system on this task. Chumklin et al. [8] detected micro-calcification in mammograms using an interval type-2 fuzzy system. Similarly, Phong et al. [26] used type-2 Takagi Sugeno Kang (TSK) fuzzy systems for electrocardiogram (ECG) arrhythmic classification. The parameters of the type-2 TSK fuzzy classifier are computed using fuzzy C-mean clustering and back-propagation. An improved clustering method using the IT2FS method was proposed by Zhang et al. [42], where FCM algorithms extract fuzzy rules from IT2FS systems. The algorithm is based on the distance between interval data. Mendoza [23] presented IT2FS logic along with a modular neural network for face recognition. The response was integrated into multi-net neural systems for improvement. IT2FS, in combination with SVM, has also been used for pattern recognition, as shown by Herman et al. [15] in recognition of motor imagery related to EEG. Choi et al. [7] performed pattern recognition using IT2FS and applied heuristic and histogram methods on the image. Similarly, Melin et al. [20] presented a brief review of classification and pattern recognition applications using IT2FS. Hwang et al. [16] used the IT2FS approach to C-means clustering for text data, while, Tunali et al. [35] extended the implementation to various fields. The IT2FS combined with TOPSIS has been used to deal with uncertain situation in evaluating real-time risk status of metro station [28]. This approach has been utilized to evaluate the subway station’s operational risk assessment [43].
Mehtap Dursun et al. [10] provide a decision-making framework for personnel selection involving fuzzy techniques [36]. They used a fuzzy multi-criteria decision making (f-MCDM) algorithm where multiple fuzzy selection criteria are applied. The result is presented in an order based on the similarity to the ideal solution. The proposed method performed well in capturing both numerical and linguistic information in decision-making. Deliktas et al. [9] experimented MCDM with a fuzzy TOPSIS approach for selecting industrial engineering candidates in a manufacturing environment. Due to fewer candidates, pairwise comparison matrices have controlled consistencies and obtained a crisp value for each candidate. Both the weight of decision-makers and weights of selection criteria are taken into account to analyse the performance values.
Bogdanovic et al. [4] used MCDM to evaluate and select the most suitable employees in an organization. The objective followed is to minimize the subjectivism of decision-makers due to their dominance in the field. As a result, they reduced employers from five to three and reorganized the department by obtaining the final ranking. Its result presented that managerial problems can also be solved successfully by this integrated method. Golec et al. [12] presented a general hierarchical framework for the selection and evaluation of an employee, and it uses the competency-based fuzzy model to match a particular job to an employee. The linguistic evaluation was computed on features such as communications skills, interpersonal skills, technical skills, management skills, decision-making ability and self-motivation [24].
Boran et al. [5] carried out personnel selection as a group decision-making problem [17] using TOPSIS method as an extension to the intuitionistic fuzzy set (IFS), which is characterized by a membership function, non-membership function, and hesitation margin to deal with vagueness. Efe et al. [11] also used the TOPSIS method for personnel selection which was extended by the use of interval type-2 trapezoidal fuzzy number. IT2F numbers represented the linguistic terms given by the decision-makers. This evaluation is applied in an assembly line of a textile firm after determining the closeness coefficient of each personnel. Balezentis et al. [2] extended the fuzzy MULTIMOORA (Multi-Objective Optimization by Ratio Analysis) for linguistic reasoning under group decision-making. It considers eight qualitative attributes in the linguistic form and aggregates the decision-makers subjective evaluation, giving a robust method of personnel selection. Hesitant fuzzy linguistic terms were proposed to capture richness in linguistic variation. It provides control in situations where a set of values are possible from the fuzzy membership function [31]. Chen et al. [6] represented 366 linguistic terms using hesitant fuzzy sets in the MCDM approach, while Liu et al. [19] incorporated T2FS with hesitant fuzzy linguistics terms. Afshari et al. [1] introduced a hybrid approach to personnel selection using an expert system involving fuzzy linguistic variables combined with operational research. Dahooie et al. [14] particularly proposed a model for personnel selection in the IT industry. SWARA and ARAS-G decision-making methods were used to select the best candidate for an IT department.
In the proposed method for personnel selection, FCM clustering is performed after pre-processing and vectorising the data. Following Bezdek et al. [3] model, the clustering model used Euclidean distance for distance measurement. The attributes of the model are chosen based on the generalised view presented in Wu et al. [39]. The next phase of the proposed method uses the IT2FS model for final decision-making in personnel selection. The model used a Gaussian membership function with uncertain means to represent the uncertainty of the linguistic term. The expert was consulted to construct both the membership function and the decision-table (i.e. rule-based) for the model. The theoretical design of IT2FS is followed as suggested by Liang et al. [18] using its python toolkit made available by Haghrah et al. [13].
The paper is organised as follows: Section 3 presents a step-by-step methodology for the personnel selection, starting from preprocessing resumes, then followed by clustering and shortlisting candidates for the interview round. Section 4 shows the performance of the model corresponding to evaluation metrics like average accuracy and F1 score. Finally, the paper concludes in Section 5.
Methodology
The I.T. resume dataset contains 1500 resumes. Each row presents the resume information of a candidate, whereas the column represents the attributes of the resume. The candidate’s data attributes are merged and then passed to preprocessing step 3 . Fig. 1 presents the dataflow diagram of the model.

Dataflow diagram of the model.
Remove the hyperlinks, symbols, punctuators, brackets, etc. Remove the stop words(a, an, the, etc.) as they are very common to any text documents and do not have any significance in processing documents. Convert the resume in lowercase. Further lemmatization is applied to convert the word to its root form.
The cleaned data is represented using a Term-Document matrix of vector space model, where each word is a dimension. The vector corresponding to a resume is an array containing the frequency of each word in the resume.
The total number of unique words in the resumes forms the vocabulary of the resume dataset. There are approximately thirteen thousand unique words in the vocabulary, making it too large to assign each word a separate column. Therefore columns containing a significantly less number of entries are dropped. For that, a threshold value from the mean and median corresponding to the frequency of each word is chosen. Words with a frequency less than the threshold are removed as they don’t significantly lose the information.
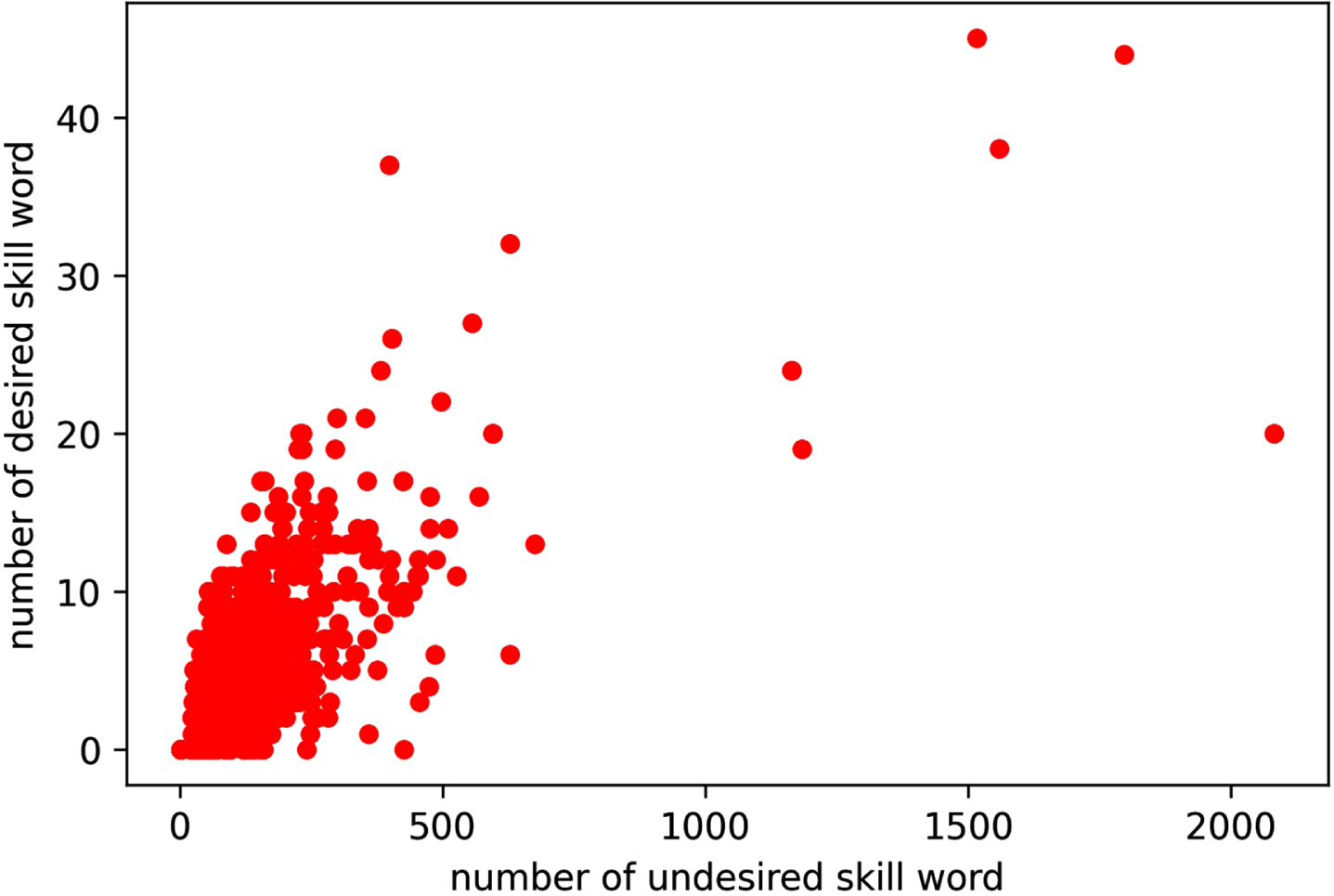
Resumes data frame representation after vectorisation.
Each resume is a data point in the graph showing a combination of desired and undesired skill sets. It is apparent from Fig. 2 that the number of desired skill words will be much less than other skill words in the resume. A weight is applied to skill sets in the resume for scaling. The scaling weight factor is computed as the percentage of desired skill words in the resume, giving more weightage to the resume with a higher percentage of these words. The scaled version of the graph is shown in Fig. 3.
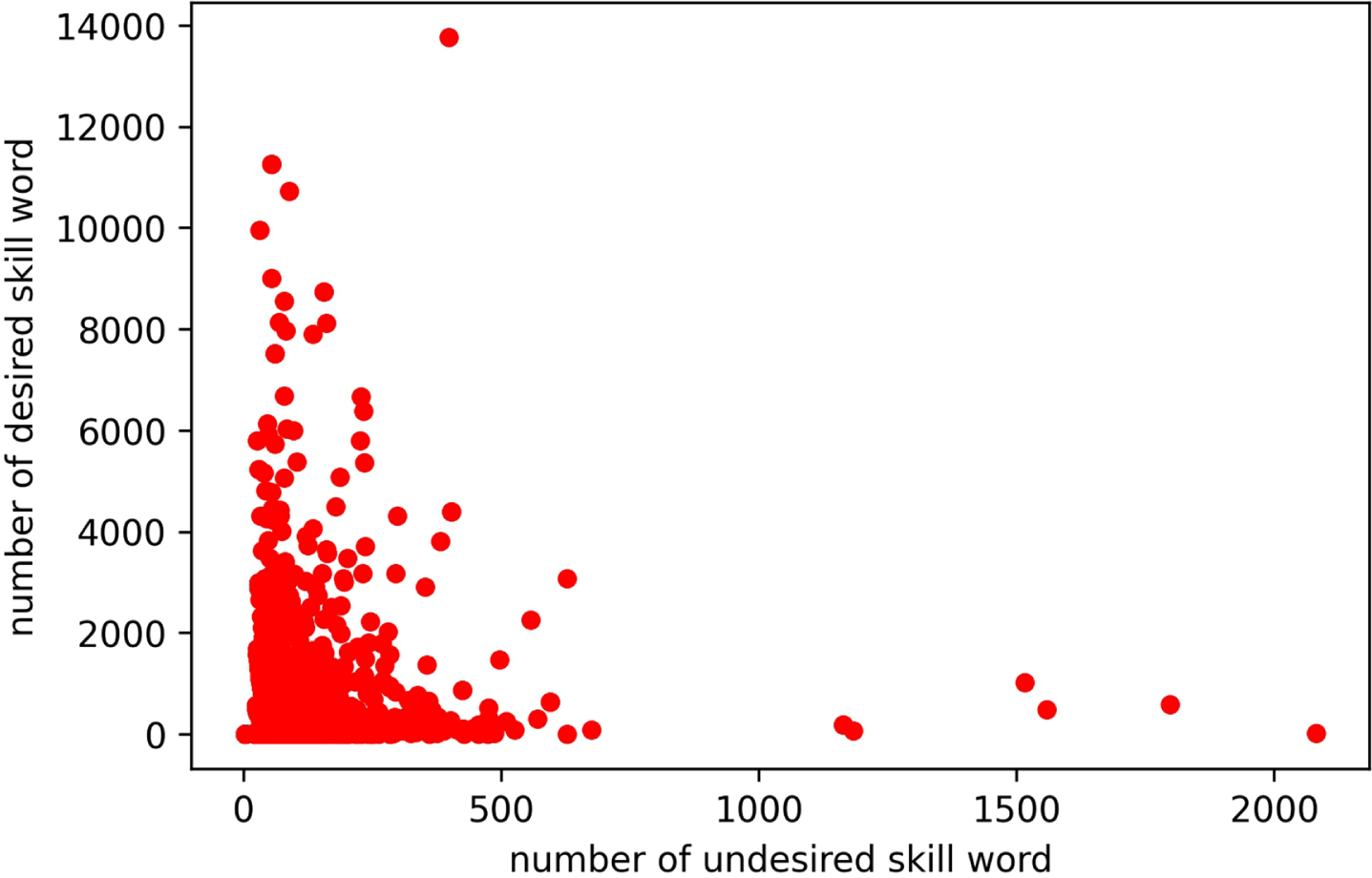
Resumes data frame representation after applying weights to desired and undesired skill words.
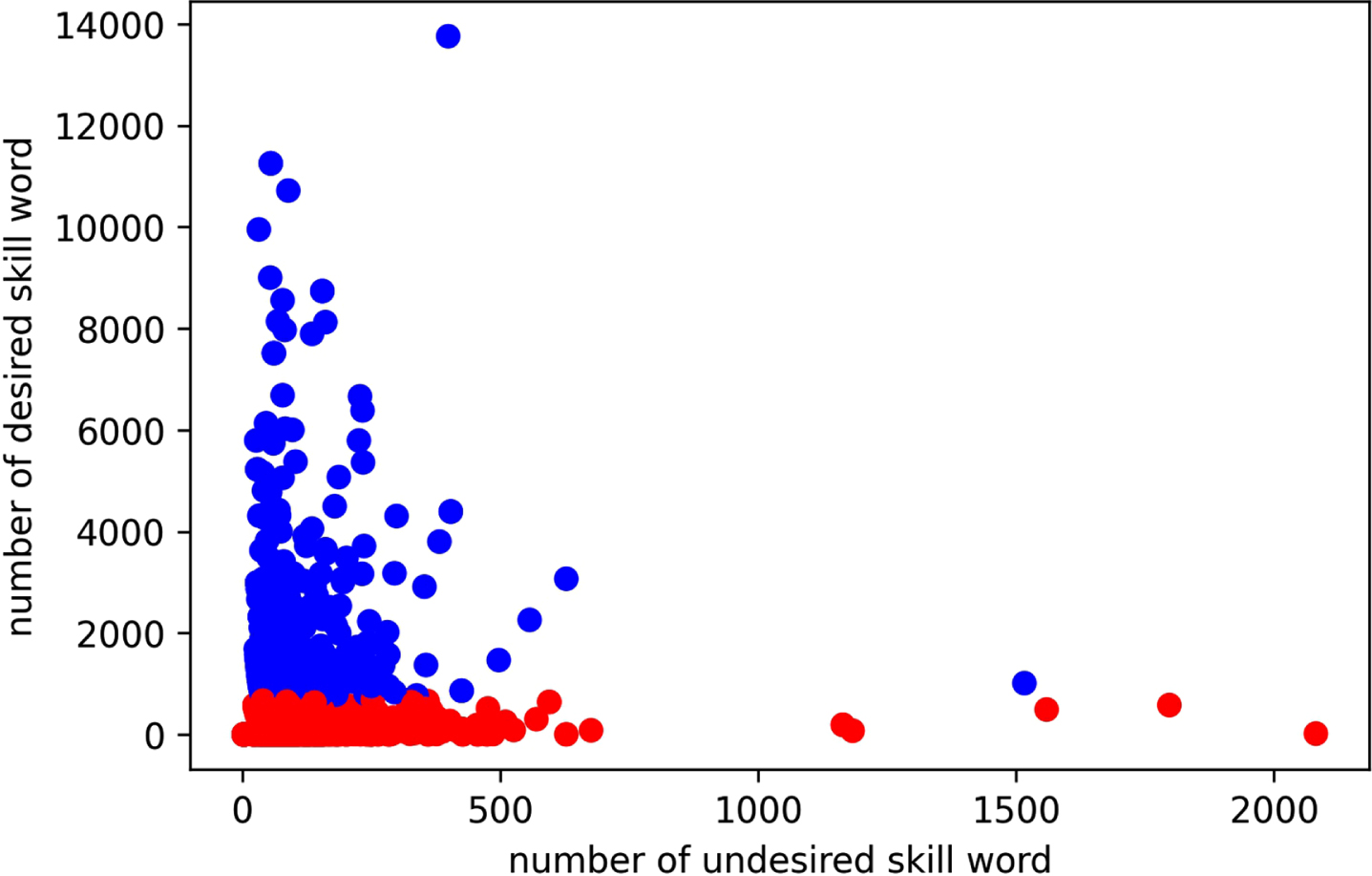
Resumes data frame representation after FCM where value of fuzzifier parameter=2.
All the non-eligible resume data points are discarded while the eligible resumes data point flows to the next module: ‘Filtering and selection module’ as shown in Fig. 1. Two new columns are computed and added to the data frame of the eligible candidate resume: (i) The percentage of the desired words and (ii) The percentage of the undesired words in the filtered data. In the filtering and selection module, IT2FS roles come into the picture.
In order to handle the uncertainty factor, a decision table (Table 1) consisting of two input linguistic variables (IT2FS membership function) and an output linguistic variable (IT2FS membership function) is used. The input linguistic variables have three possible linguistic values (i.e. Low, Medium and High), while the output linguistic variable supports five linguistic values (i.e. Very Low, Low, Moderate, High and Very High). Each linguistic variable is represented as an IT2FS membership function, particularly Gaussian MF with uncertain means, as shown in Fig. 5.
Decision Table: Input-Output fuzzy inference rules
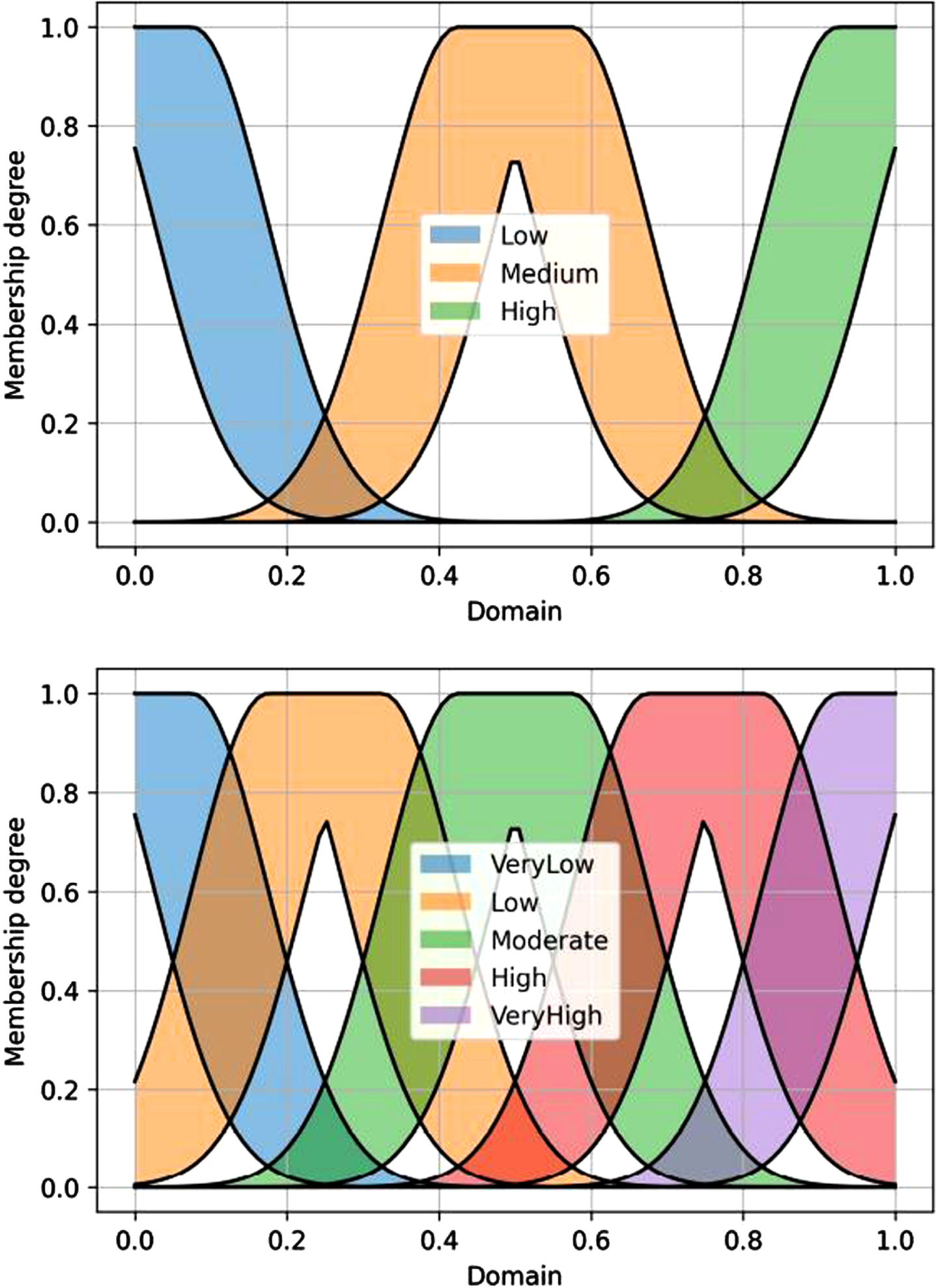
Gaussian MF with uncertain mean used as input and output membership function.
The decision table is looked up three times with two different input pairs combination as follows: input1: percentage of the desired skill words; input2: selector’s decided weightage for the desired skill words in the range of 0 to 1; to get output1: an output interval range corresponding to skill words (as shown in Fig. 6). input1: percentage of the undesired skill words; input2: selector’s decided weightage for the undesired skilled words in the range of 0 to 1; to get output2: an output interval range corresponding to undesired skill words. input1: cutoff ratio (i.e. ratio of filtered candidates to the total candidate during clustering); input2: selector’s decided weightage for the cutoff ratio in the range of 0 to 1; to get output3: an output interval range corresponding to cutoff ratio.

A Data flow of selector weightage for desired word in IT2fs model.
Following the Mamdani method [27], the input and their corresponding weights are passed to the decision table to obtain the corresponding IT2FS output (output1, output2, output3). On the application of KM algorithm [38] to each output gives a range for the output (i.e., [min. value, max. value]).
Output1 (i.e. IT2FS output corresponding to desired skill words) and output2 (i.e. IT2FS output corresponding to undesired skill words) are added to provide a score to each candidate resume (i.e., [min. score, max. score]), resulting in the candidates’ score list. This list is arranged in decreasing order of the maximum scores. Output3 (cutoff interval) is now applied on this list to finally obtain the percentage of the candidates shortlisted for the interview round from the candidates’ score list (i.e., [min. fraction of qualified candidates, max. fraction of qualified candidates]).
Now in this section, the experiment results are presented to give a view of fuzzy text clustering with IT2FS application in personnel selection. Three cases are evaluated depending on the number of skills that a selector has given for shortlisting are as follows:
Firstly, the expert labelled all the 1500 resumes as qualified or not qualified for each of the three cases. The result of the model for each case is presented in the confusion matrix, as shown in Table 2.
Confusion matrix of the model, where TP=True-postive, TN=True-negative, FP=False-postive, FN=False-negative
Confusion matrix of the model, where TP=True-postive, TN=True-negative, FP=False-postive, FN=False-negative
It clearly shows that the model does not give a significant result whenever the required skill set is significantly less and much restricted. At the same point, whenever the required skill set is extensive and little diversified, the result is outstanding. The proposed model shows an average accuracy of 88.2 %, whereas an average F1 score of 0.76 (Table 3).
Result analysis of the model
The result of the model (FCM + IT2FS) is compared with the (K-means + IT2FS). The proposed method shows an F1 score of 0.76 to a later model with F1 score of 0.72. It has been observed that the (FCM+IT2FS) shows a better result compared to (K-means +IT2FS) because FCM is able to allow a large number of boundary cases (uncertain cases) to pass while the K-means perform more strictly over the boundary cases.
Finally, the results of IT2FS is compared to T1FS for each case in Table 4. Considering the Case-1 in the experiment, the cutoff ratio that came after clustering is 0.26, while the weightage given by the selector to cutoff ratio is 0.2. Table 4 shows that the IT2FS returns an interval range of [0.08, 0.62], indicating the minimum and maximum fraction of candidates that can be shortlisted for the interview from the eligible candidates’ score list, whereas the T1FS presents a single discrete value of 23%. Thus, IT2FS provides a qualified range of candidates from score list (i.e. for Case-1 [8%,62% ]). Hence, it gives control to the selector to choose the number of resumes from the given range of shortlisted resumes.
Interval type-2 and type-1 result comparison where CR = cutoff ratio and wCR=selector weightage for cutoff ratio
In personnel selection, selectors are interested in candidates with the required professional skills and also give some weightage to other skills. Thus, it allows a candidate to get shortlisted for an interview if he may be missing some skills. These constitute the boundary cases, and hence they are regarded as cases with uncertainty. In order to deal with these boundary-cases (uncertain cases), the FCM and IT2FS are used in the proposed methodology. The FCM algorithm is applied over the preprocessed dataset to create two clusters: eligible and non-eligible resumes to the requirement. The IT2FS gives the control to the selector to decide how many boundary cases (uncertain cases) will pass from the eligible resume. The experimental results give an accuracy of 88.2% and an F1 score of 0.76.
The result comparison of our proposed model FCM + IT2FS is compared with K-means + IT2FS. Our proposed method shows an F1 score of 0.76 to a later model F1 score of 0.72. It indicates that our model is better at dealing with uncertain cases. Thus, it provides some scope to the candidates to get shortlisted where they may be missing some required professional skills. The experiment also presented that using IT2FS provides a range for the selected number of resumes despite some fixed values obtained using T1FS. It gives control to the selector to choose the number of resumes from the given range of shortlisted resumes. Hence, the model provides flexibility to selectors when dealing with uncertainty. Semi-automating the shortlisting of resumes also helps the selector to focus more on the interview task. From the application point of view, this approach can be further extended to another domain for personnel selection. In the colleges, this technique can be used to select SOPs (Statement-of-Purpose) received for their various academic programmes.