
Abstract
In recent years, speech processing resides a major application in the domain of signal processing. Due to the audibility loss of some speech signals, people with hearing impairment have difficulty in understanding speech, which reintroduces a crucial role in speech recognition. Automatic Speech Recognition (ASR) development is a major challenge in research in the case of noise, domain, vocabulary size, and language and speaker variability. Speech recognition system design needs careful attention to challenges or issues like performance and database evaluation, feature extraction methods, speech representations and speech classes. In this paper, HDF-DNN model has been proposed with the hybridization of discriminant fuzzy function and deep neural network for speech recognition. Initially, the speech signals are pre-processed to eliminate the unwanted noise and the features are extracted using Mel Frequency Cepstral Coefficient (MFCC). A hybrid Deep Neural Network and Discriminant Fuzzy Logic is used for assisting hearing-impaired listeners with enhanced speech intelligibility. Both DNN and DF have some problems with parameters to address this problem, Enhanced Modularity function-based Bat Algorithm (EMBA) is used as a powerful optimization tool. The experimental results show that the proposed automatic speech recognition-based hybrid deep learning model is effectively-identifies speech recognition more than the MFCC-CNN, CSVM and Deep auto encoder techniques. The proposed method improves the overall accuracy of 8.31%, 9.71% and 10.25% better than, MFCC-CNN, CSVM and Deep auto encoder respectively.
Keywords
Introduction
Automatic speech recognition (ASR) consists of automatically transcribing voice into text [1]. The human voice (discourse signal) contains various sorts of data making it a solid contender for confirmation. An individual can be recognized by a discourse signal they have expressed. By utilizing a discourse signal predominantly three sorts of acknowledgement are performed; discourse acknowledgement (what is spoken), speaker acknowledgement (who is communicating) and language distinguishing proof (recognizing the communicated in language by the speaker). It is important to study the effects of these types and related techniques on ASR vigor as one of the key areas of research. Programmed discourse acknowledgement is the way toward changing over the human voice into its relating succession of words or other etymological elements by methods for applying various calculations in the entire procedure.
Despite this, Hearing Impaired Listeners [2] typically complain of poor speech recognition in background noise. This challenge can be very incapacitating and continues despite extensive endeavors to improve hearing innovation. The essential restriction coming about because of sensor neural hearing impedance of cochlear source includes raised audiometric edges and coming about constrained discernibility. In any case, diminished discernibility shapes just a part of the Hearing-Impaired Listener’s [3] assortment of confinements. Various discourse preparation techniques are employed to transform ambiguous discourse signals into highlight vectors [4–6]. The discourse acknowledgement process is separated into a few stages.
Signal characteristics like zero-crossing strength across various frequency ranges and the total energy are computed by splitting speech signal into an equally spaced block in this step. With phoneme, every block is combined using these characteristic feature vectors for producing phonemes string [7–9]. Frequency filter bank, fast Fourier transform (FFT) [10] and Linear predictive coding method is used for applying spectrum analysis on every block in this step, the decision process is performed in this step. Distinguishing features are there in every phenomenon and narrow field [11, 12]. Decision process performance is enhanced using this step for producing a high success rate of proposed algorithms. An algorithm is constructed for every vocabulary word and against every algorithm, compared phonemes string [13].
Computation of words spoken by pattern matching and speech’s acoustic signal is the major objective of ASR. For this, in a computer, there is a need to store acoustic and language model sets which represent actual patterns. Variation in speaking rate stimulate various existing method to model speaking rate variations spectral effects and it causes significant degradation performance in automatic speech recognition [14]. Speech signals can be recognized using various machine learning techniques [15, 16]. However, with audibility loss of some speech signals, people with hearing impairment have difficulty in understanding speech, which reintroduces a crucial role in speech recognition. Additionally, increases in speech intelligibility for human listeners have remained elusive for decades. Owing to the development of deep learning in many fields, the proposed method utilize a hybrid deep learning technique for providing a robust automatic speech recognition system. The major contributions of the proposed model are: Initially, the speech signals are pre-processed using Least Mean Square adaptive filter for the removal of unwanted noise in the signal. Mel Frequency Cepstral Coefficient (MFCC) is used for extracting the features from noise-removed signals. A novel hybrid Discriminant Fuzzy Function-based Deep Neural Network is used for assisting hearing-impaired listeners with enhanced speech intelligibility. Enhanced Modularity function-based Bat Algorithm (EMBA) is employed as a powerful optimization model for computing the best number of MFs for every input and learning rate and momentum coefficient’s better rate. The efficiency of the proposed framework is estimated using precision, recall, f measure, accuracy, and error rate.
The remaining of this research was divided into the following sections: discussion about different related research methods is presented in section 2, the proposed automatic speaker recognition method is explained in section 3, proposed hybrid deep learning model’s performance evaluation is discussed in section 4 and Section 5 encloses with conclusion and future work.
Literature review
In speech recognition system, recent advancement is described in this section and also reviewed robust technique for developing an automatic speech recognition system and its application in various fields.
In 2014, T May and T Dau [17] proposed that the variations in spectrum-temporal noise during testing and training determine segregation performance. Integrating spectro-temporal features does not increase the feature space’s dimensionality.
In 2015 Miao, et al. [18] proposed the Eesen framework for developing end-to-end Automatic Speech Recognition systems. Eesen uses deep RNNs as acoustic models and CTC as a training objective function. Comparing Eesen’s performance to traditional hybrid DNN systems, studies show it achieves equivalent word error rates (WERs) and significantly speeds up decoding.
In 2016, Agarwalla et al. [19] proposed using machine learning (ML) techniques to extract relevant samples from big data and use them for Automatic Speech Recognition (ASR) based on soft computing techniques tailored for Assamese speech with dialectal differences. The FD-DNN-SE has been found to perform well among ML-based techniques after a large number of experiments.
In 2018, Rahmani, et al. [20] proposed deep autoencoders to generate effective bimodal features from audio and visual input streams. The proposed structures are compared with professional phoneme recognition baselines in various loud audio situations.
In 2019, Park, et al. [21] proposed SpecAug-ment, a straightforward method of enhancing voice recognition data. In SpecAugment, the filter bank coefficients of a neural network are directly applied to the feature inputs of the neural network. In SpecAugment, the over-fitting problem is transformed into an under-fitting problem, so larger networks and long training periods improve performance.
In 2019, Passricha and Aggarwal [22] proved the proposed CSVM for voice problems using CNNs switched from softmax layers to SVMs. In CSVMs, both SVMs and CNNs are combined to enhance the performance of segmental recurrent neural networks.
In 2020, Passricha and Aggarwal [23] developed a hybrid CNN-BLSTM architecture to improve continuous voice recognition. In general, the proposed architecture outperformed the most efficient CNN system and a DNN system by 5.8% and 10%, respectively. Compared to the baseline CNN-BLSTM system, the hybrid system showed comparable performance and computational efficiency.
In 2021, Yang, C.H.H., et al., proposed a decentralised feature extraction method based on quantum convolutional neural networks (QCNNs) for automatic speech recognition. Quantum-based DNN models provide competitive recognition results with a steady performance for spoken-term recognition compared to conventional DNN-based AM models.
In 2021, Sukvichai, et al. [25] proposed automatic speech recognition (ASR) using MFCC and CNN. MFCC images will be treated as standard images that CNN will use for object detection to find Thai keywords. They chose the You Only Look Once (YOLO) word localization and classification algorithm because of its accuracy and performance. This results in a fast and accurate ASR system which uses MFCCs and CNNs. There is approximately 82% of times when the report is accurate.
In 2021, Al-Taai, R.Y.L., and Wu, X presented a new strategy to improve hearing for the hearing impaired by blending two stages: (1) dividing the signal into eight distinct bands, each of which analyzes the speech signal’s frequency; (2) creating several deep denoising autoencoder networks that each work on a particular enhancement task and adapt to a segment of training data. The trial results demonstrated that the suggested strategy was more comprehensible and produced superior quality compared to three and five layers.
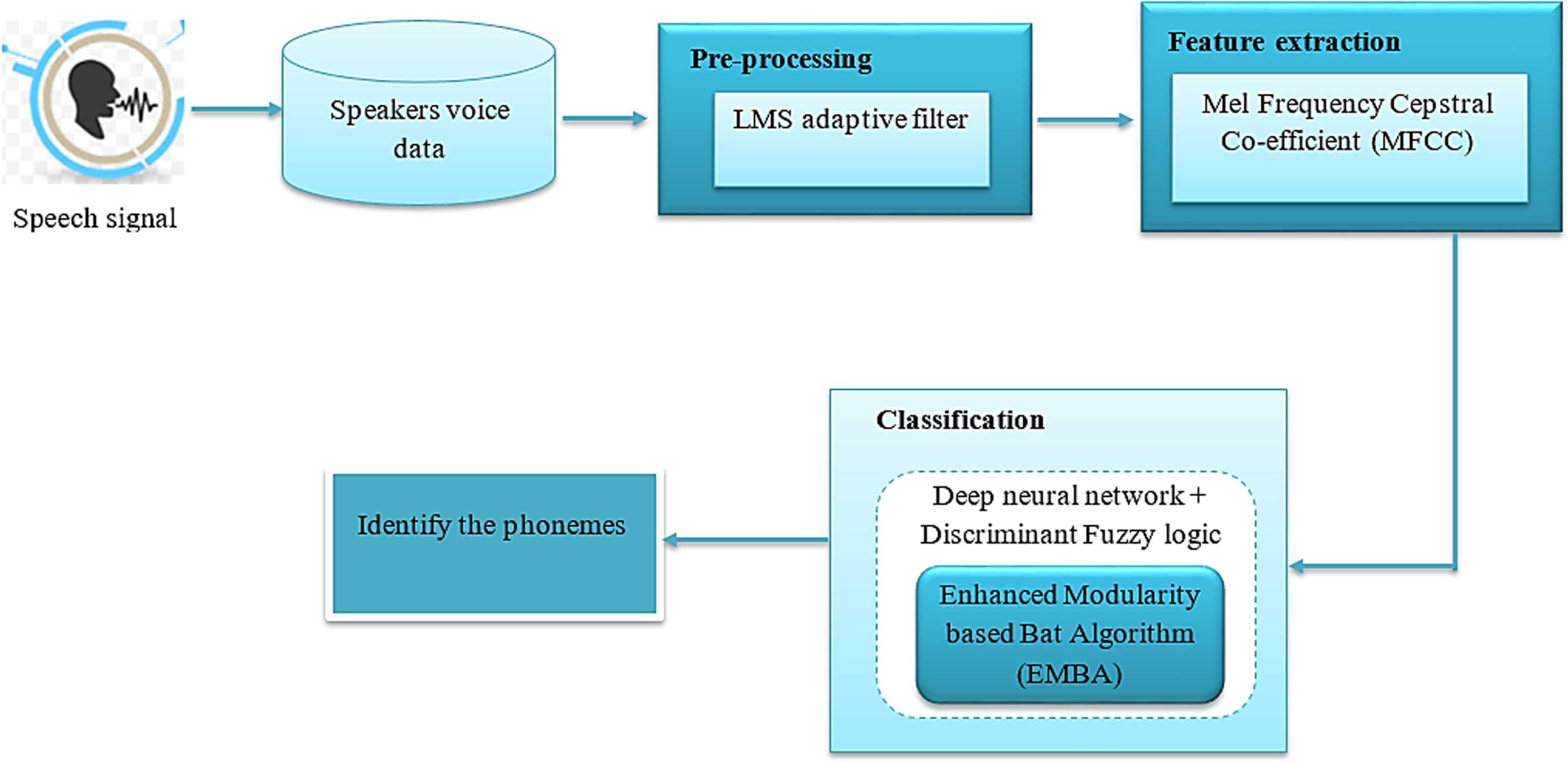
The overall process of the proposed Automatic Speech Recognition.
A review of all parameters having relation to the speech recognition system is covered in this work. For automatic speaker recognition, HDF-DNN is proposed in this work, the proposed method can be extended to any language type using this review and better performance can be achieved when compared with existing works.
To produce better speech recognition method performance, a technique is presented in this research work. Speech signals are handled using this technique for accessing data from any place and at any time. The proposed system is to uses “learning” algorithms that aim to learn the features, without any assumptions. The major aim is to propose a hybrid deep learning model for aspects of improved recognition rate which require careful tuning. In this work, to deal with additive noise proposed an LMS adaptive filter pre-processing algorithm at the initial stage. Secondly, Mel Frequency Cepstral Coefficient (MFCC) features are extracted from noise-removed signals.
A hybrid speech enhancement method based on deep learning is proposed at last for assisting hearing-impaired listeners with enhanced speech intelligibility. From corrupted speech signal features, the Discriminant Fuzzy function (DF) is learned for achieving enhancement. Both DNN and Discriminant Fuzzy which have some problems with parameter tuning directly affect the performance. To address this problem, Enhanced Modularity function-based Bat Algorithm (EMBA) is used as a powerful optimization tool for computing the best number of MFs for every input and learning rate and momentum coefficient’s better rate.
Preprocessing using LMS adaptive filter
In real-world voice communication systems, the optimal settings for the adaptive filter using the LMS algorithm generally affect the suppression of additive noise in the speech signal. An iterative procedure is incorporated in the least Mean Square (LMS). In the gradient vector’s negative direction, weight vectors are corrected in successive iterations for minimizing mean square error. LMS algorithm is relatively simple when compared with other algorithms. Matrix inversion and correlation function computation are not needed in this LMS algorithm. The corrupted signal is passed through a filter for suppressing noise. Signals are left without any changes. This is the basic concept of the adaptive noise cancellation algorithm.
Prior knowledge about noise characteristics or signals is not required in this process and it is an adaptive one [27]. Real-time data processing is done using this adaptive filter, where filtering is performed adaptively. According to the input signal, filter weights are updated adaptively. The weight update algorithm plays a major role in designing these kinds of adaptive filers. Weight update is performed in this work using the LMS algorithm and according to the input signal; it has an adaptive step-size parameter.
LMS adaptive filter output is represented as,
Where
Effective recognition performance can be generated by fetching acoustic signals most parametric depiction. The performance of the next stages are depending on the performance of this stage. Human hearing perceptions form the base for MFCC, frequencies above 1 kHz, cannot be perceived by humans. It can also be stated as the human ear’s known variation in critical bandwidth with frequency forms the base for this MFCC [28]. There are two filter classes in MFCC and at frequencies below 1000 Hz, they are linearly spaced and at frequencies above 1000 Hz, they will be spaced logarithmically. In the speech, phonetics’ important characteristics can be captured using subjective pitch which is present on Mel Frequency Scale. Figure 2 illustrates the MFCC’s overall process. Human ear behaviour mimicking is a major purpose of MFCC. In addition to speech waveform variation, MFCC is less susceptible to the following variations. Major steps involved in MFCC are, Pre-emphasizing, blocking of the frame, windowing, Discrete Fourier Transform, Mel-Frequency warping and DCT.

Mel-frequency cepstrum coefficients processor (MFCC) basic structure.
Humans can hear about 20–20,000 Hz frequencies. Low frequencies correspond to the frequencies below 1000 Hz and high frequencies are above 1000 Hz. In voice signals, the majority of information occupies high frequency when compared with low frequency. So, for enhancing the overall SNR ratio, speech signal high-frequency components are boosted by about 20 dB/ decade in the initial stages. Effective resume of major information by voice is enabled using this process and in the frequency domain, spectral distortion is reduced.
Frame blocking
The N sample frames are formed by blocking the continuous input signal in this step. The separation between adjacent frames is given by M (M < N). The first N sample is there in the first frame. After M samples space from the first frame, the second frame will start and overlap it with N –M samples. After 2M samples space from the first frame, the third frame starts and after M samples from the second frame and overlaps it by N –2M samples. Until accounting for all speech signals in one or more frames, this process will be continued.
Windowing
At the start and end of every frame, signal discontinuities are minimized by windowing every individual frame in the next processing step. The window is used for tapering signal value to zero at the start and end of every frame. In most cases, hamming windows are used. The mathematical definition of the Hamming window is defined as follows:
Most of the data at the frame’s boundaries become negligible after being multiplied by a window, which results in a loss of information there. This indicates that the center data of subsequent frames includes the margins of the present frame.
Fast Fourier Transform is the next processing step. Every frame with N samples is converted into a frequency domain from the time domain. Discrete Fourier Transform (DFT) can be implemented using the FFT algorithm in a fast manner and on N samples set {X
k
}, it is defined as,
The power spectrum is then calculated without the negative frequency component.
The linear scale frequencies (Hz) of each frame are distorted into Mel scale frequencies using a bank of filters in the Mel scale. In Mel-frequency, frequencies are linearly spaced below 1000 Hz and logarithmically spaced above 1000 Hz. Several triangular bandpass filters in the Mel filter bank overlap and are dispersed throughout the signal spectrum. Using the following equation (6), the linear frequency scale and Mel frequency scale are warped.
A scale termed as ‘Mel’ scale, measured the subjective pitch of every tone having an actual frequency f, which is measured in Hz.
DCT was the final stage of the core MFCC feature extraction procedure. The fundamental idea behind DCT was to embellish the Mel spectrum to create an accurate depiction of the local spectral features. To create an accurate representation of the sound spectral, DCT was used to calculate the spectrum. The Mel-frequency Cepstrum Coefficient was used to describe the outcome (MFCC).
Note that, from DCT, the first component,
Noisy speech signals can be enhanced successfully using Deep Neural Networks (DNN). From corrupted speech signal features, the Discriminant Fuzzy function (DF) is learned for achieving enhancement concerning reference clear signal. Additional side-channel information which is more robust against extracted features is provided for enhancing predicted feature quality. Fully connected layer features, which process audio signals [29] and Convolution Neural Network (CNN) features, which process visual cues are integrated into this proposed hybrid architecture using the Discriminant Fuzzy function (DF). Unsupervised operation of Deep Learning is allowed for extending these lessons further and for selecting desirable features, which are defined in fuzzy-inference systems. With the unavailability of hand-labelled data, using Deep Learning’s useful information, a robust system can be developed. A Fuzzy-inference system then is used for interpreting these features and for a selected classification label, the explanation is offered using it.
Deep learning and fuzzy logic system
Handcrafted features are not required in deep learning methods inclusive of CNN, as it is needed in fuzzy-logic counterparts. But it requires labelled data and predefined structures. On their own, they can learn features. Extraction and interpretation of network learned feature is another major challenge in Deep Learning [30]. A Classification label is not providing necessary information. So, it is required to make use of high-level features, which are network generated. For two reasons, these generated features are mainly used. Firstly, an unsupervised system is used for generating these features, which eliminates the need for handcrafted labelling.
Hand labelling data problem is a major obstacle in DL system development. It is difficult to generate a huge amount of training examples. In a DL system, the ability of computing specific neurons corresponding to a particular requested feature will make analysts pull out feature arrays and hook them into the network. An analyst can directly exploit these features or it may be given to a fuzzy inference system. Here, classification labels are generated by grouping them automatically with the use of rule-based mechanisms. Structures based on rules are generated using a fuzzy inference process. From DL, generated features can be biased using the creation of these rules by providing feedback to the system. If-then statements are used for approximating complex non-linear problems in fuzzy inference systems. Subjective information can be used for biasing systems based on the structured rule. Opportunity is created using this for providing expert information to the system for enhancing results of classification or for modifying system behaviour. For autonomous systems, learning can be speeded up using this feedback bias with stability maintenance.
Hybrid–Discriminant Fuzzy Function-based Deep Neural Network (HDF-DNN)
Deep learning algorithms can incorporate fuzzy logic using extension principal using this development. Fuzzy aggregation is enabled using fuzzy logic introduction. It is responsible for handling incomplete information of every modality and data collection granularity. Every modality value can be evaluated subjectively using this mechanism. Deep-leaning architectures are percolated with fuzzy arithmetic. Symbolic representations can be formed by translating User-provided linguistic statements. A neural network can be initialized using these representations. This may affect the parameters like layer count in overall neural network architecture and neuron count in every layer. A fuzzy inference block is derived from the neural network. Fuzzy rules are given as an additional input and on input data, for incorporating expert knowledge, these rules can be adjusted. Fuzzy system behavior can be explained using these rules which is a major benefit of this system. From numerical data, fuzzy rules cannot be extracted using this expert knowledge.
Input pattern which is given by fuzzy inference block is analyzed by learning algorithm block. Through the system, propagated the adjusted weights of the system and predictors behavior are adjusted automatically and overtime, update of system is allowed. Figure 3 shows the proposed method’s hybrid model. From data, direct representations of features are created using deep learning feature generation at the initial stage. Unlabeled data is used for training deep learning systems at the initial stages and these methods are used for extracting desirable features. Fuzzy-inference systems are integrated with these features after getting extracted using a deep learning system. From subjective information and deep learning, detected features are incorporated into this system as a system biasing technique. For classification purposes, these two pieces can be used collectively. This enables the system to report specific features and results of classification and also makes rules which are activated for arriving conclusion of the system. In addition, further biasing of the system is done in the feedback form.
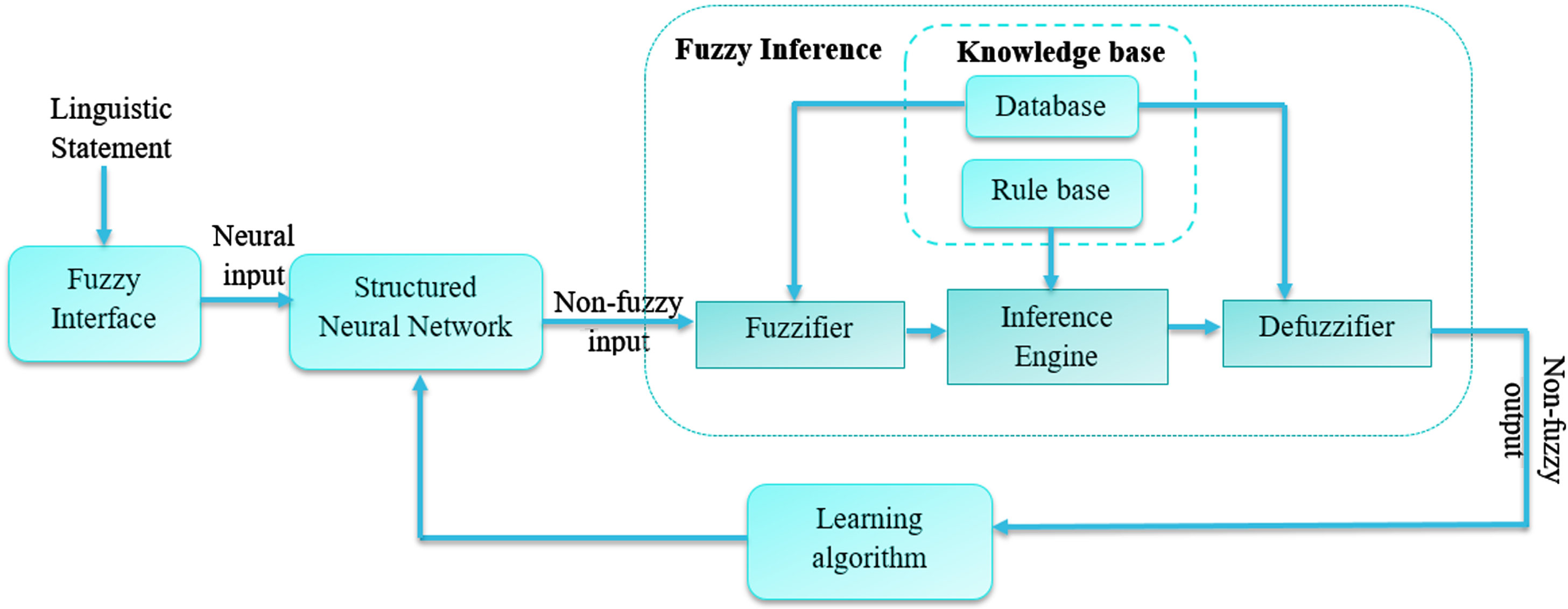
A hybrid model for speech recognition detection.
Suppose that rules have three fuzzy if-then rules of Takagi and Sugeno’s type.
Rule 1: If x is A1, y is B1, and z is C1 then f1 = p1x+q1y+t1z+r1,
Rule 2: If x is A2, y is B2 and z is C2 then f2 = p2x+q2y+t2z+r2,
Rule 3: If x is A3, y is B3 and z is C3 then f3 = p3x+q3y+t3z+r3,
Layer 1: Adaptive node is included with a function
Where proper parameters of Discriminant Fuzzy function (DF) are called as μ Ai (x), μ Bi (x) and μ ci (x) and fuzzy set A = (A1, A2, B1, B2orC1, C2)’s membership grade is represented as O1,i and the degree at which given input x satisfies the quantifier is indicated by this. This layer is termed “Premise Parameters”.
Any kind of appropriate parameterized Discriminant Fuzzy function (DF) like generalized “bell function” can be used as membership function of A,
Where the set of parameters is represented as {a i , b, c i }. Based on the variations in these parameters, there will be a change in bell function and for fuzzy set, different Discriminant Fuzzy function (DF) forms are shown it subsequently. This kind of membership function is used in this study.
Layer 2: In this layer, all nodes are fixed one and all incoming signals product corresponds to the output of this layer.
Rule’s “Firing Strength” is represented by every output node.
Layer 3: Fixed node is included in this layer and labelled as N which performs a normalization function:
These layer outputs are termed “Normalized Firing Strengths”.
Layer 4: Adaptive nodes are included in this layer:
Multiplication of DNN output and third layer’s Normalized Firing Strength corresponds to every node of this layer and it is termed as “Consequent Parameters”.
Layer 5: Single node is included in this layer and labelled as S and performs a summation function. All incoming signal summation is computed as the DNN network’s overall output.
In fuzzy modelling, the major difficulty is to decide on fuzzy MF parameters and this is because the majority of parameters are selected based on the trial and error method or experience of the user. So, for minimizing the error and process automation, computational methods like DL can be utilized. Here fuzzy inference system (FIS) is constructed by utilizing HDF-DNN. In this work, the BP algorithm is used for adjusting membership parameters of the Discriminant Fuzzy function (DF). Among data, the spatial relationship can be captured using fuzzy system ad grades are estimated effectively at last. FL parameters are optimized using DNN because they may be trapped with local minima. The effective learning algorithm is there in DNN and computation of proper FL parameters is assisted using it. In FL and DNN, there exist a few parameters, which are having a greater effect on performance in an indirect way. Enhanced Modularity function-based Bat Algorithm (EMBA) is utilized here for resolving this problem. It is a powerful optimization technique. For every input, better MFs counts are computed using it along with computation momentum coefficient and learning rate. The next section describes more details about the combination of EMBA and HDFDNN.
Bats foraging behavior is simulated in a new swarm intelligence optimization algorithm called Bat Algorithm (BA). Advanced echolocation capability of the bat is used in its principle. Echolocation is a sonar type. Short and loud pulse sound is emitted by bats mainly by small bats. In a short period, if sound hits an object, the echo will be returned to the ears. In this way, the prey position is detected by bats after receiving the echoes. Bat algorithm’s biological mechanism is described in the following for simulating bats for the ageing process [31]. To detect distances, echolocation is adapted by all bats and there will be difficulty in the identification process of prey and obstacles. Prey is searched by bats with velocity V i at position X i , according to fixed frequency f min , loudness A0 and variable-length waves λ. Based on the distance between bat and prey, the pulse wavelength of bats is adjusted. Also adjusted the transmission r ∈ (0, 1) frequency, if the prey is close to batting. In the searching process, from maximum value A0 to minimum value Amin, loudness is changed.
Existing algorithms advantages with interesting features are included in the development of BA which is inspired by miniature bat echolocation behavior. Randomly, a set of solutions are generated using this algorithm using these assumptions and the optimum solution is computed using loop search. Adopted the local search in this period. Using random flight, generated the local solution around the optimum solution. With d-dimension foraging space of bats, at t –1 moment, bat i’s position is represented as
Where f
min
represents bat generated sound waves minimum frequency and f
max
represents maximum frequency. Random number with uniform distribution is represented as β with the values 0 and 1. In [f
min
, f
max
] range, there will be a uniform distribution of emitted sound waves of bats in the initial setting process. Expression (17) is used for computing corresponding frequency and expressions (18) and (19), local search is done. Based on the optimum solution, the bat will walk randomly and the following expression is used for generating a new solution.
Where a random number is represented as ɛ and it lies between –1 to 1. Randomly, from current optimum solutions, the selected solution is represented as X
old
, at t number of iterations, average loudness produced by a bat is represented as A(t). Described the update rule by analyzing bat pulse emission rate r
i
and loudness A
i
as Bat will reduce its pulse emission response while increasing pulse emission rate if it is aware of prey presence. Using the following expression, updated bat launch pulse rate r
i
and loudness A
i
.
Where the initial rate is represented as r0 and initial loudness is represented as A0, and they are selected randomly. Constants are represented as α and y (0 < α< 1, γ> 0).
Randomly, the best features are selected in the feature selection process, which is incorporated into this algorithm. From the database, appropriate features are selected by proposing a bat optimization algorithm. Dataset features are optimized in this algorithm of optimization for enhancing final results accuracy. Prey and mates of micro-bats are identified using a practice called echolocation in general. From 20 Hz to 150 Hz, sound pulses are generated by bats for detecting their destination and obstacles in their travelling path. On sound pulses reception, echo is reflected by prey or obstacles.
Based on the signal strength of the echo received, the bat determines whether it came from prey or an obstacle. Objects’ distance and location can also be calculated based on the strength of the signals. This same approach is used for selecting key features for the dataset based on the types of characteristics, and removing unwanted features by treating them as roadblocks. As shown in Fig. 4, EMBA can be used to select the best attributes for pharmacological side effects.
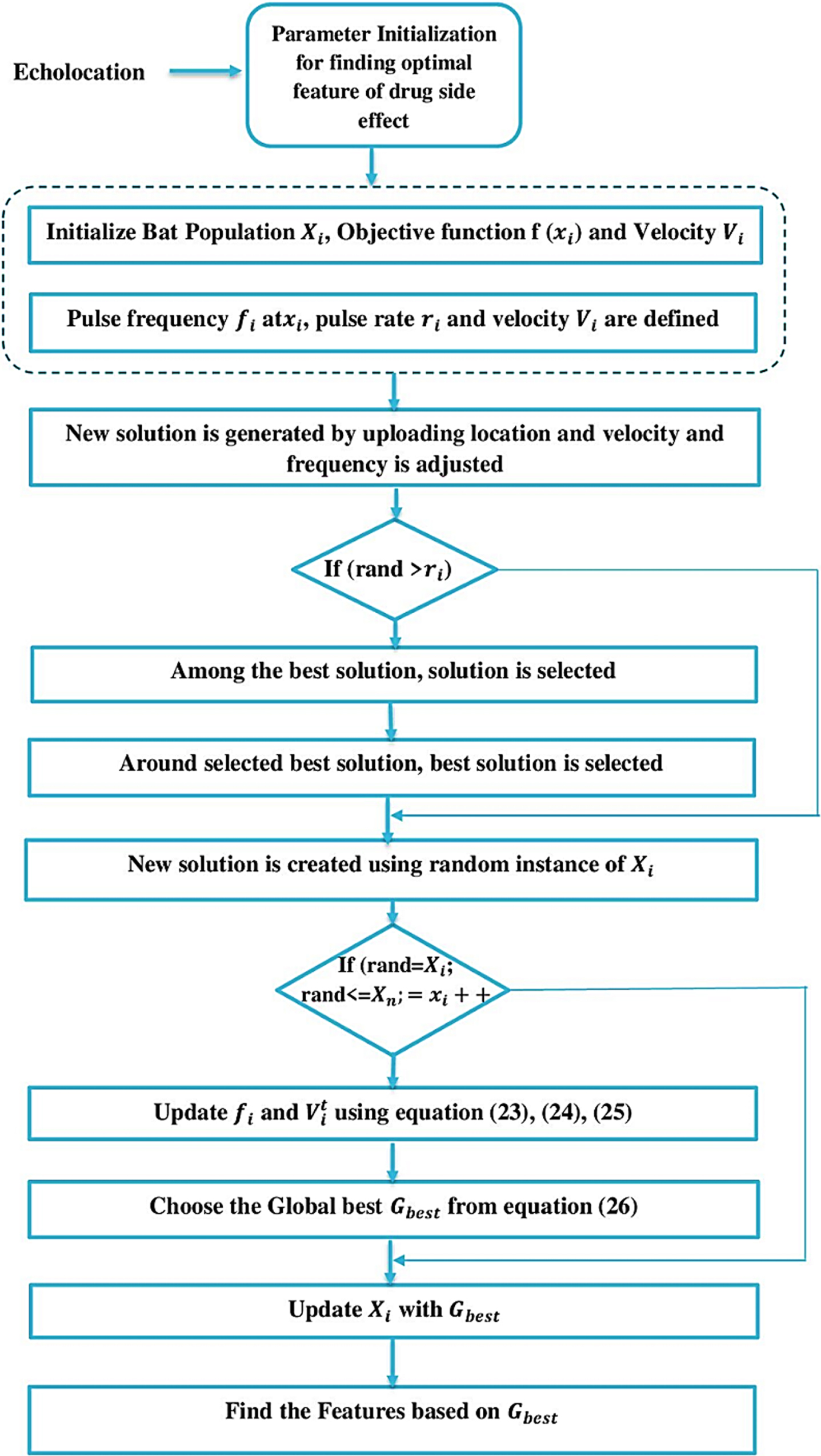
Proposed enhanced modularity function-based Bat Algorithm.
Each data point consists of a frequency (f
i
) and velocity (V
i
) in the enhanced bat algorithm, which uses the dataset as its initial bat population. Using the following equations, we estimate frequency and velocity, and they are updated continuously.
Where, δ0 and μ are constants and k is the current generation. G current represents the present global solution and δ denotes the Modularity function that ranges between 0 and 1.
Using random walks within the dataset, the most effective answers are then found. The random best solutions are discovered by a straightforward random sampling technique to extract the dominant features from the full dataset, which contains a great deal of data. By using the resampling approach, the features are ranked and grouped according to their similarity. To determine the most effective order, ranking solutions are compared against the current solution. To update the solutions, the following equation is used:
Where, random number is represented as ɛ and which lies between –1 to 1 and Si signifies similar features. Figure 4 shows the Proposed enhanced Modularity Function Based Bat Algorithm.
Performance comparison table for proposed and existing recognition techniques
This section presents a research work for understanding speech recognition analysis which is carried out using the technique of Hybrid Discriminant Fuzzy function based Deep Neural Network (HDF-DNN) for hearing-Impaired Listeners (HIL). With the help of this method, the speech signal set is assessed, determining the most suitable parameters for carrying out the speech recognition process. This technique is adopted for carrying out the classification of the non-relevant attributes, thereafter building the equation for the speech recognition which is further utilized for the speech recognition process of classification using HDF-DNN yielding high-performance accuracy. Using software such as Matlab, decisions can be made and desirable outputs have been derived that aid in handling complex situations. For the comparison, the external quality metrics like F-measure, Recall, Precision and Accuracy are adapted in this proposed work.
It is calculated by dividing the number of Positive samples that were classified correctly by the number of Positive samples that were classified incorrectly. As a result of the precision, a model can accurately assess whether a sample is classified as positive or negative.
The ratio between correctly identified positive observations and overall observations defines recall. It is used to evaluate the quality of speech accurately identified as true positives. The recall is estimated as,
Recall and precision’s weighted average defines the F1 score. False negatives and false positives are included in it.
Based on positives and negatives, computed an accuracy value as,
A precision comparison of existing and proposed HDF-DNN is shown in Fig. 5. Proposed HDF-DNN has the maximum precision value of 89.57%, whereas existing models like MFCC-CNN have 86.25%, CSVM has 82.75% and Deep autoencoder has 79.24%. It shows that a low error rate is produced by the proposed method and it is an effective one.
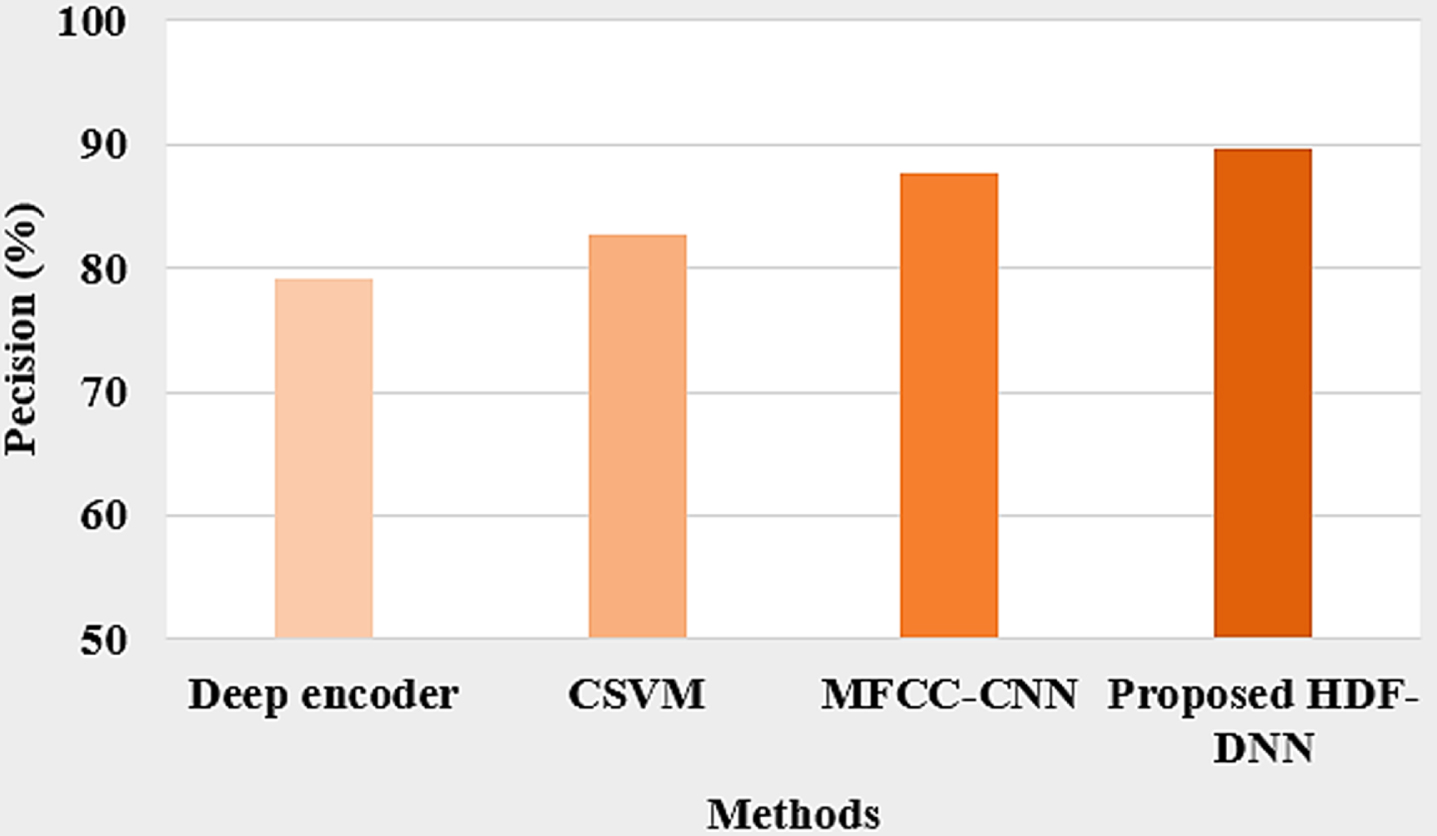
Precision comparison with different methods.
Recall value comparison of existing and proposed HDF-DNN is shown in Fig. 6. Proposed HDF-DNN has a maximum value of 91.57%, whereas, existing models like MFCC-CNN have 84.67%, CSVM has 81.42 % and Deep autoencoder has 78.47%. It shows that a high recall value is produced by the proposed method and it is an effective one.

Recall comparison with different methods.
F-measure comparison of existing and proposed HDF-DNN is shown in Fig. 7. Proposed HDF-DNN has a maximum value of 90.57%, whereas existing models like MFCC-CNN have 85.87%, CSVM has 80.23% and Deep autoencoder has 80.02%. It shows that a high value of f-measure is produced by the proposed method and it is an effective one.
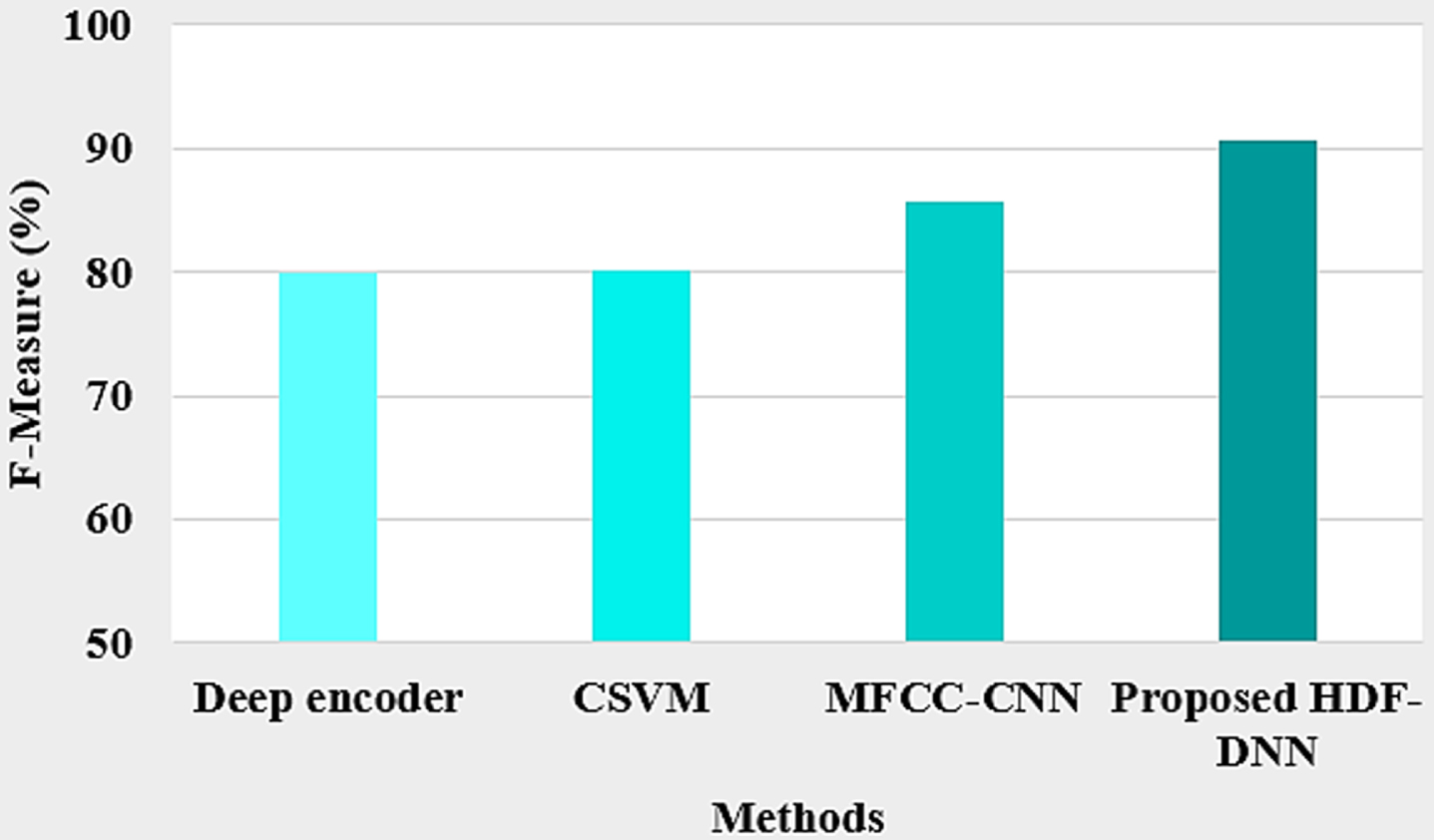
F-measure comparison with different methods.
Accuracy comparison of existing and proposed HDF-DNN is shown in Fig. 8. Proposed HDF-DNN has maximum accuracy of 90.25%, whereas existing models like MFCC-CNN have 82.75%, CSVM has 81.48% and Deep autoencoder has 80.92%. It shows that a highly accurate result is produced by the proposed method and it is an effective one.
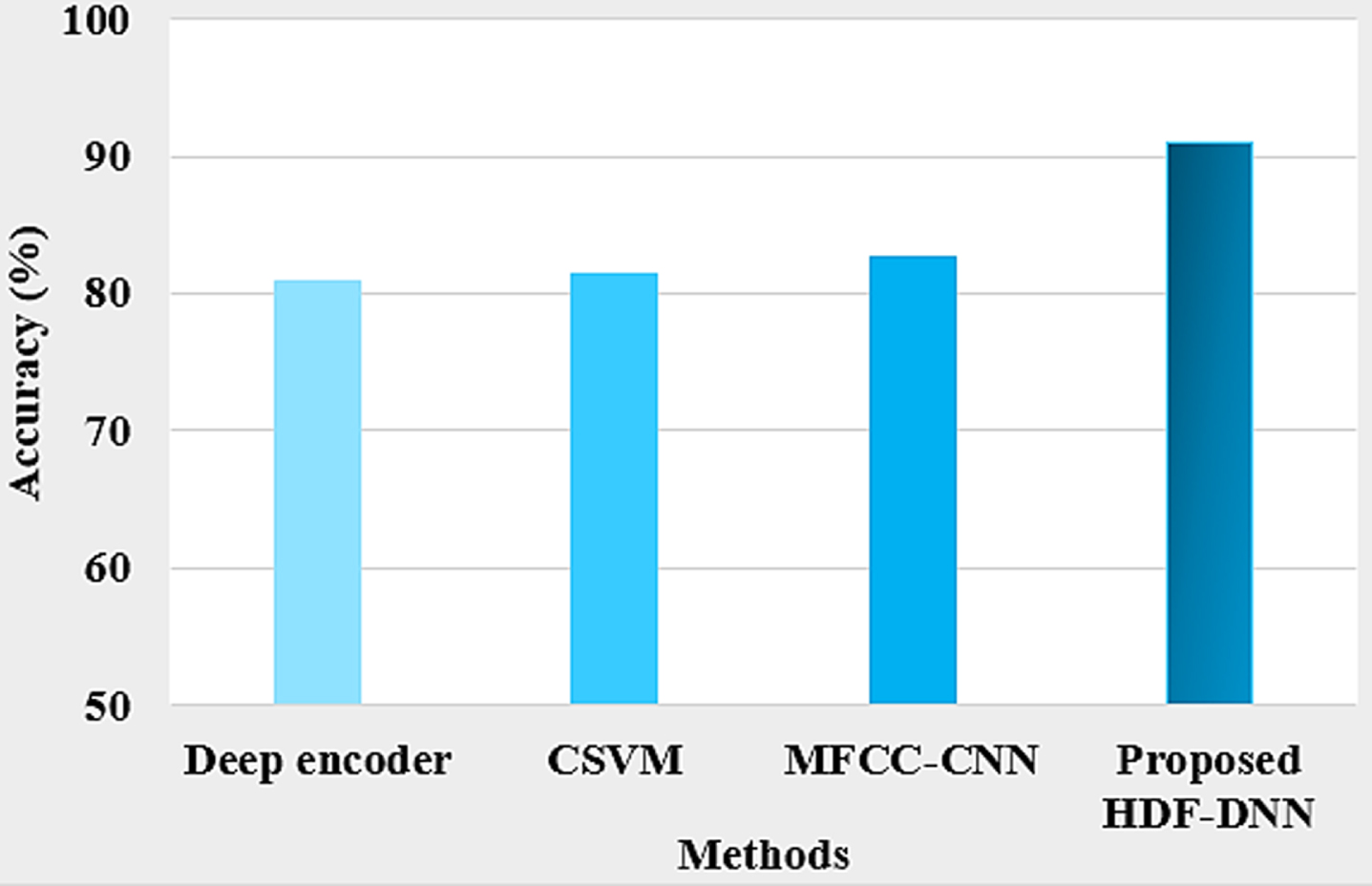
Accuracy comparison with different methods.
Error rate comparison of existing and proposed HDF-DNN is shown in Fig. 9. Proposed HDF-DNN has a minimum error rate of 9.75%, whereas existing models like MFCC-CNN have 13.81%, CSVM has 15.35% and Deep autoencoder has 17.09%. The overall performance chart is depicted in Fig. 10. It shows that a low error rate is produced by the proposed method and it is an effective one.
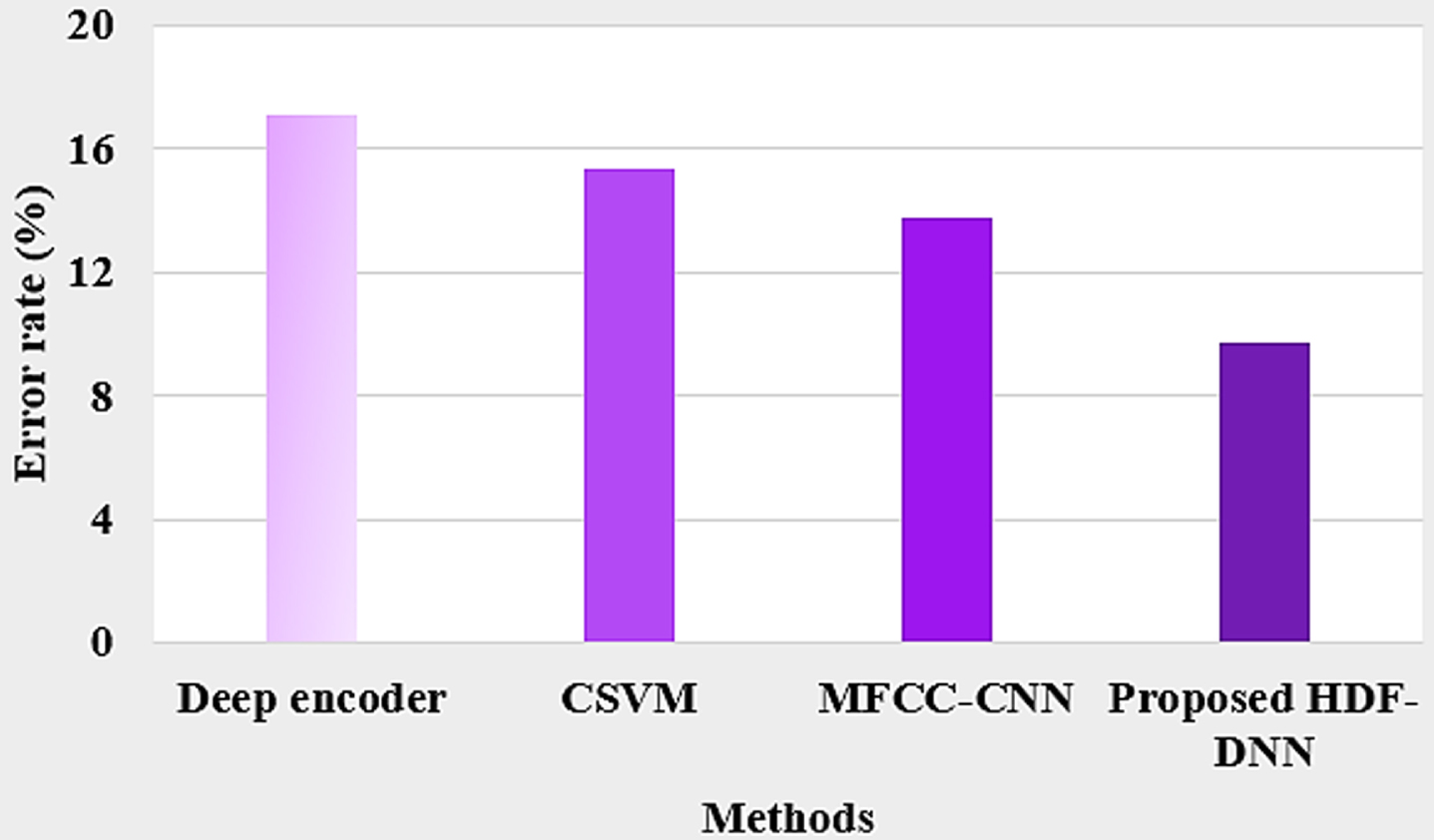
Error rate comparison with different methods.
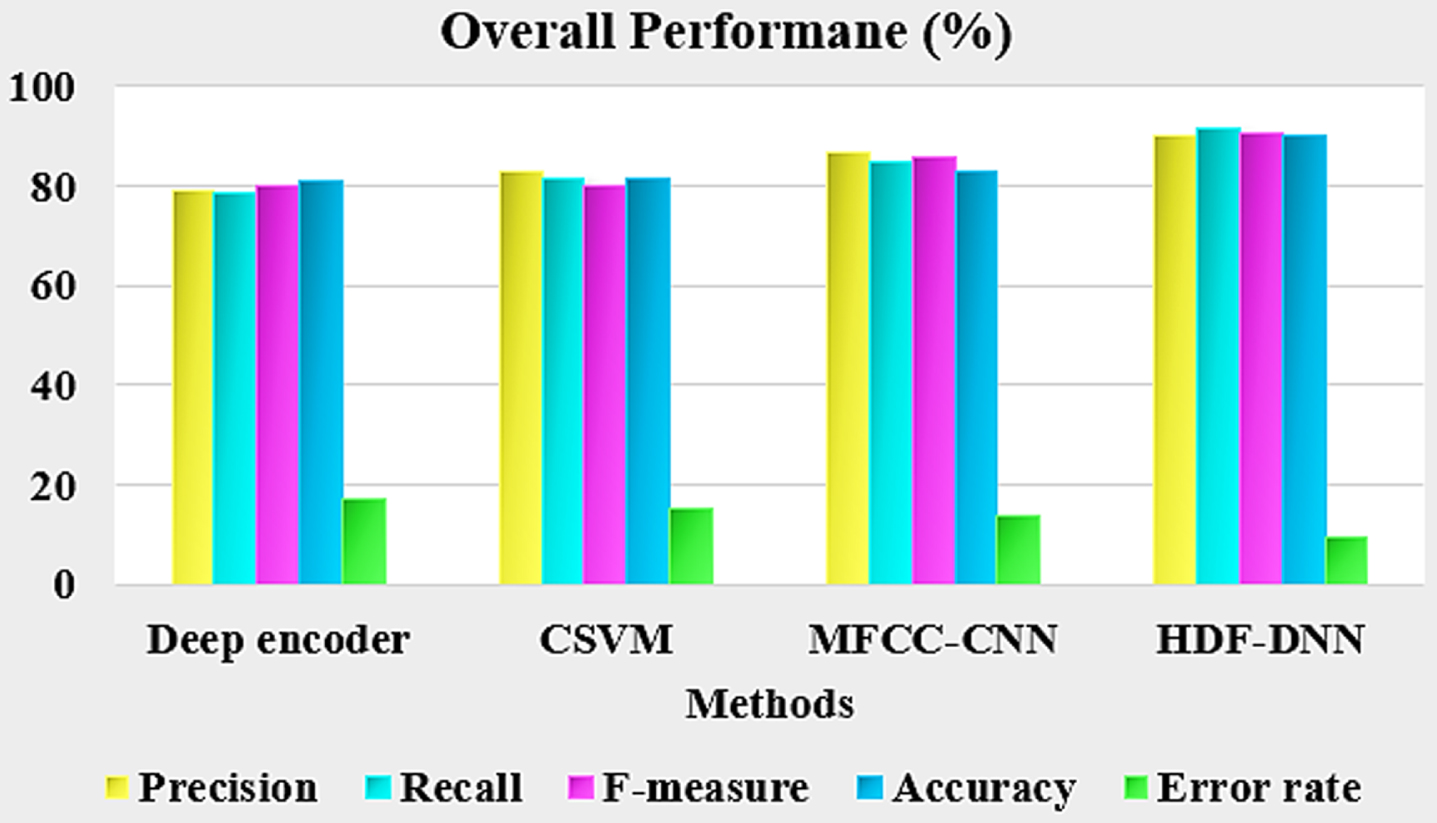
Overall performance chart.
In this work, the hybrid deep neural network and discriminant fuzzy function has been proposed for recognizing speech very effectively. Before feature extraction, on speech signal, LMS adaptive filter preprocessing algorithm is applied for enhancing recognition accuracy and for making the system highly robust against noise. For feature extraction, MFCCs are used to enhance the recognition rate effectively. In a clean environment, better performance is exhibited using MFCCs. Finally, a Discriminant fuzzy function-based Deep neural network is used for recognizing the given speech signal. Both DNN and Discriminant Fuzzy Logic have some problems with parameters, to address this problem Enhanced Modularity function-based Bat Algorithm (EMBA) is used as a powerful optimization tool. Based on experimental results, the valuable benefits of the HDF-DNN approach are highly appropriate for these requirements and produce improvised recognition output. The proposed method improves the overall accuracy of 8.31%, 9.71% and 10.25% better than, MFCC-CNN, CSVM and Deep auto-encoder respectively. The experimental results show that the proposed model effectively-identifies speech recognition compared to other existing techniques. In future, the advanced deep learning network will be used to improve the prediction accuracy for speech recognition by using a large amount of dataset.
Footnotes
Acknowledgment
The author with a deep sense of gratitude would thank the supervisor for his guidance and constant support rendered during this research
Funding
This research did not receive any specific grant from funding agencies in the public, commercial, or not-for-profit sectors.