
Abstract
In the era of big data for exploring attribute reduction/rough set-based feature selection related problems, to design efficient strategies for deriving reducts and then reduce the dimensions of data, two fundamental perspectives of Granular Computing may be taken into account: breaking up the whole into pieces and gathering parts into a whole. From this point of view, a novel strategy named label-specific guidance is introduced into the process of searching reduct. Given a formal description of attribute reduction, by considering the corresponding constraint, we divide it into several label-specific based constraints. Consequently, a sequence of these label-specific based constraints can be obtained, it follows that the reduct related to the previous label-specific based constraint may have guidance on the computation of that related to the subsequent label-specific based constraint. The thinking of this label-specific guidance runs through the whole process of searching reduct until the reduct over the whole universe is derived. Compared with five state-of-the-art algorithms over 20 data sets, the experimental results demonstrate that our proposed acceleration strategy can not only significantly accelerate the process of searching reduct but also offer justifiable performance in the task of classification. This study suggests a new trend concerning the problem of quickly deriving reduct.
Introduction
Feature selection [1, 24], an essential mechanism for data pre-processing, has been not only received extensive attention but also widely employed in various practical problems such as data sketching, rule generation, and so on. The core of feature selection is to select a subset of features, which satisfies the given constraint, while retaining a suitably high accuracy in representing the raw features [23].
Presently, the concept of attribute reduction [4, 37] rooted in the rough set theory [33] has been demonstrated to be of great value in reducing the dimensions of data with clear semantic explanations. For such a reason, attribute reduction has been widely accepted as a substantial tool for realizing feature selection. Since attribute reduction is a rough set-based feature selection, the corresponding constraint in attribute reduction is closely related to the measure derived from rough set model. In other words, different rough set models or measures may be helpful in configuring different forms of attribute reduction. This is the reason why attribute reduction is with strong adaptability.
Following the above discussions, an open problem is how to search the corresponding subset of conditional attributes which satisfies the given constraint in attribute reduction. Such subset is referred to as the reduct in rough set theory. Up to now, discernibility matrix [8, 41] and heuristic-based searching [11, 54] are two well-known approaches. Nevertheless, it should be pointed out that though the discernibility matrix can achieve all reducts, such an approach is quite time-consuming. Compared with the discernibility matrix, heuristic-based searching has been attracted more attention. Such an approach can quickly achieve one attribute reduction of problem solving because the heuristic information is involved in the process of searching reduct.
Among various heuristic-based searchings, forward greedy searching is especially popular. The main reasons can be attributed to the following two phases: 1) such a searching can be easily improved because of its simple structure; 2) such a searching can be employed to quickly select the candidate conditional attributes to the reduct. However, it’s worth noting that the forward greedy searching is still strenuous if the volume or the scale of the data is huge, especially in the era of big data. Therefore, many researchers have devoted themselves to designing various acceleration methods for further improving the efficiency of forward greedy searching. For example, Qian et al. [35] have proposed the framework with the name of positive approximation, which can gradually reduce the volume of samples in the process of searching reduct; Liu et al. [26] have introduced a mechanism named bucket into the computation of distances among samples, which employed a hash function for significantly reducing the unnecessary computations; Chen et al. [3] have developed the concept of attribute group, which is helpful in reducing the times of evaluating candidate conditional attributes; Rao et al. [38] have introduced the similarity/dissimilarity among conditional attributes into the process of searching reduct, which aims to select two or more candidate conditional attributes for each iteration. Meanwhile, to explore the difference of the existing attribute reduction methods, Li et al. [18] have introduced the relationships among the consistencies into the comparison of attribute reduction methods in formal decision contexts [19, 21], the results of the comparison can be employed to help users to select the appropriate attribute reduction method for achieving their requirements.
Through a careful reviewing of the previous studies, we observe that most of the existing acceleration methods of forward greedy searching pay attention to the sample or the attribute, few of them have made the best use of the information provided by the labels. With a thorough consideration about the role of the label, it is not difficult to observe the following facts: 1) the label provides us with a local view for exploring attribute reduction related problem, i.e., label-specific [43, 51] based reduct; 2) the differences among different label-specific based reducts can be quantitatively described, and then the inherent relationships among different labels may be characterized by these reducts; 3) different label-specific based reducts can be further fused for improving the performances of the subsequent learning tasks.
To sum up, by considering the advantages of the label, a new strategy called label-specific guidance will be proposed in this paper. On the one hand, although the labels in data are employed in supervised approaches in previous research [3, 38], these approaches only concerned with the labels in data from the perspective of measure, the hierarchy among the labels are less considered. Therefore, we can take the labels in data into consideration to divide the whole data into several pieces. On the other hand, the guidance thinking may be constructed to choose appropriate conditional attributes because of the hierarchy among the labels. For each piece of the data, the reduct related to the previous piece can be employed to guide the computation of the reduct related to the subsequent piece. Ultimately, with this guidance thinking, the reduct over the whole universe can be naturally obtained. In such a strategy, we can accelerate the process of searching reduct.
Therefore, the main contributions of our studies contain two aspects. 1) The principles of breaking up the whole into pieces and gathering parts into a whole in Granular Computing [9, 47] are introduced into the process of forward greedy searching. The reduct related to the pieces can be employed to guide the generation of the reduct related to the whole, which can effectively reduce the time consumption during the period of deriving reduct. 2) A complex problem can be divided into several simple problems the information provided by the labels, which can greatly improve the efficiency of problem solving. In the context of this paper, the solutions of the several simple problems will eventually be combined into the solution of the original complex problem while keeping the distribution of the raw data unchanged.
The rest of this paper is organized as follows. Section 2 will review the basic notions related to some measures and two general expressions of attribute reduction in the rough set model. In Section 3, our proposed acceleration strategy, i.e., label-specific guidance for efficiently searching reduct will be illustrated in detail. In Section 4, comparative experimental results will be conducted, as well as the corresponding analyses. In Section 5, conclusions and future perspectives will conclude the whole paper.
Preliminaries
Measures
In the field of the rough set theory, a decision system can be given by a 3-tuple such that
Generally speaking, one of the fundamental motivations of the rough set theory is to quantitatively characterize the uncertainty in data. Therefore, given a decision system
Following Eq. (1), two different perspectives can be employed to design various measures for characterizing the uncertainties: 1) if the whole universe is employed, then ρ (U, AT) can be regarded as a measure based on the global perspective; 2) if ∀X ⊂ U is used, then ρ (X, AT) can be considered as a measure based on the local perspective [46].
It is not difficult to observe that the difference between the above two perspectives lies in the volume of samples. In the initial stage of exploring the rough set theory, the global perspective dominates the characterization of uncertainty. In recent years, because of the diversities of practical requirements in the era of big data, it has been demonstrated that the local perspective is superior to the global one [23]. Interestingly, the information provided by the label attribute can be naturally employed for conducting the local perspective related studies.
G nsidering the label attribute in
Presently, following the above two perspectives to characterize uncertainties, various measures have been proposed. Most of the measures can be divided into the following two categories. The higher the value of the measure calculated by using ρ, the less the degree of uncertainty is revealed. For example, approximation quality is such a type of measure. In this case, ρ (U, AT) denotes the approximation quality obtained over the whole universe while ρ (X
j
, AT) is the label-specific approximation quality obtained over a specific class X
j
[45]. The lower the value of the measure calculated by using ρ, the less the degree of uncertainty is revealed. For instance, conditional entropy is such a type of measure. In this situation, ρ (U, AT) denotes the conditional entropy acquired over the whole universe while ρ (X
j
, AT) is the label-specific conditional entropy acquired over a specific class X
j
[40].
As one of the most important ways to realize feature selection, attribute reduction has witnessed great success in the developments of both rough set and dimension reduction. Different from popular feature selection techniques, attribute reduction in the rough set theory is not only effective in removing irrelevant or redundant conditional attributes but also equipped with clear semantic explanations. It should be pointed out that these semantic explanations are closely related to the constraints defined in attribute reduction. For example, it can minimize the delayed decision [7, 39]/misclassification costs [16, 32], preserve the regions of approximations related to various rough sets [31], improve the generalization performances of classifiers [34], and so on.
Through a comprehensive review of the previous research, Yao [49] pointed out that most of the definitions of attribute reduction possess a similar structure, then he give the formal description of the similar structure as follows.
A satisfies the constraint ∀A′ ⊂ A, A′ does not satisfy the constraint
A satisfies the constraint ∀A′ ⊂ A, A′ does not satisfy the constraint
Obviously, the difference between Def. 1 and Def. 2 lies in the forms of the constraint. The constraint
In what follows, how to derive the reduct is an urgent problem. The following Algorithm 1 shows the detailed process of forward greedy searching, which has been widely employed for deriving reduct.
Algorithm 1 contains two main phases. The first phase is to add appropriate conditional attributes into the potential reduct, and the second phase is to remove redundant conditional attributes from the potential reduct. Therefore, such two phases are consistent with the conditions shown in Def. 1. Furthermore, it is not difficult to calculate the time complexity and the space complexity of Algorithm 1 are
Algorithm 1 is employed to derive reduct in Def. 1, it can also be easily modified to derive label-specific based reduct if the measure ρ (U, AT) is replaced by ρ (X
j
, AT). In such a case, the space complexity of Def. 2 is the same with that of Def. 1, but the corresponding time complexity in Def. 2 is
Label-specific guidance
Though forward greedy searching has been successfully applied to derive reduct, various methods for further improving the efficiency of forward greedy searching have also been exploited [3, 38]. Without loss of generality, most of these methods can be divided into the following two perspectives. Sample based perspective. In such a perspective, the efficiency of deriving reduct depends heavily on the volume of data. Therefore, with the increasing number of samples in data, the process of deriving reduct may be time-consuming. From this point of view, by exploring the monotonic structure of the mapping ρ, Qian et al. [35] have designed a framework with the name of positive approximation. The positive approximation can gradually reduce the size of the samples for quickly evaluating candidate conditional attributes. Such a framework can also be regarded as one of the representative accelerators for speeding up the process of forward greedy searching. Furthermore, Liu et al. [26] have deemed that the computation of similarities among samples costs too much, thus the hash mapping was introduced into the quick calculation of similarities, which also aims to derive reduct efficiently. Attribute based perspective. In such a perspective, the efficiency of deriving reduct depends heavily on the dimensions of data. Therefore, with the increasing number of conditional attributes in data, the process of deriving reduct is possible to be inefficient when facing some real-time tasks such as online feature selection [10, 53], streaming feature selection [27, 52], and so on. In view of this, Chen et al. [3] have pointed out a mechanism named attribute group. In such a mechanism, conditional attributes are partitioned into several groups, we only need to evaluate the conditional attributes out of those groups which contain at least one conditional attribute in the potential reduct. In what follows, the times required for evaluating candidate conditional attributes can be reduced, and then the process of deriving reduct is accelerated further. Moreover, by considering the dissimilarity among conditional attributes, Rao et al. [38] have designed a new accelerator. Different from the attribute group, the dissimilarity based mechanism was employed to determine more than one appropriate conditional attribute for each iteration of selecting conditional attributes. It follows that the required iterations for constructing reduct may also be reduced, and then the corresponding elapsed time can be saved.
From discussions above, though both the perspectives of sample and attribute have been explored for speeding up the calculations of reducts, little attention has been paid to the information provided by the label.
It should be pointed out that based on the perspective of the label, some superiorities may emerge [2, 42]. For example, the label provides us with a local view for reviewing the attribute reduction related problems. It follows that the inherent relationships among labels can be clearly characterized by the selected conditional attributes; the label-specific based reduct [43, 51] is derived over different labels, these reducts can be further fused for improving the performances of the subsequent learning tasks, e.g., accuracy and the stability of classification [45].
Though the essential thinking of label-specific is valuable, most of the previous computations of different label-specific based reducts are independent [5, 40]. Immediately, such computations may be either serial or parallel. Nevertheless, both of them do not fully take the overlaps among different label-specific based reducts into account, and the computing power may be wasted. From this point of view, a new strategy called label-specific guidance will be proposed in this paper for deriving reduct, the following Fig. 1 shows the details of our strategy.
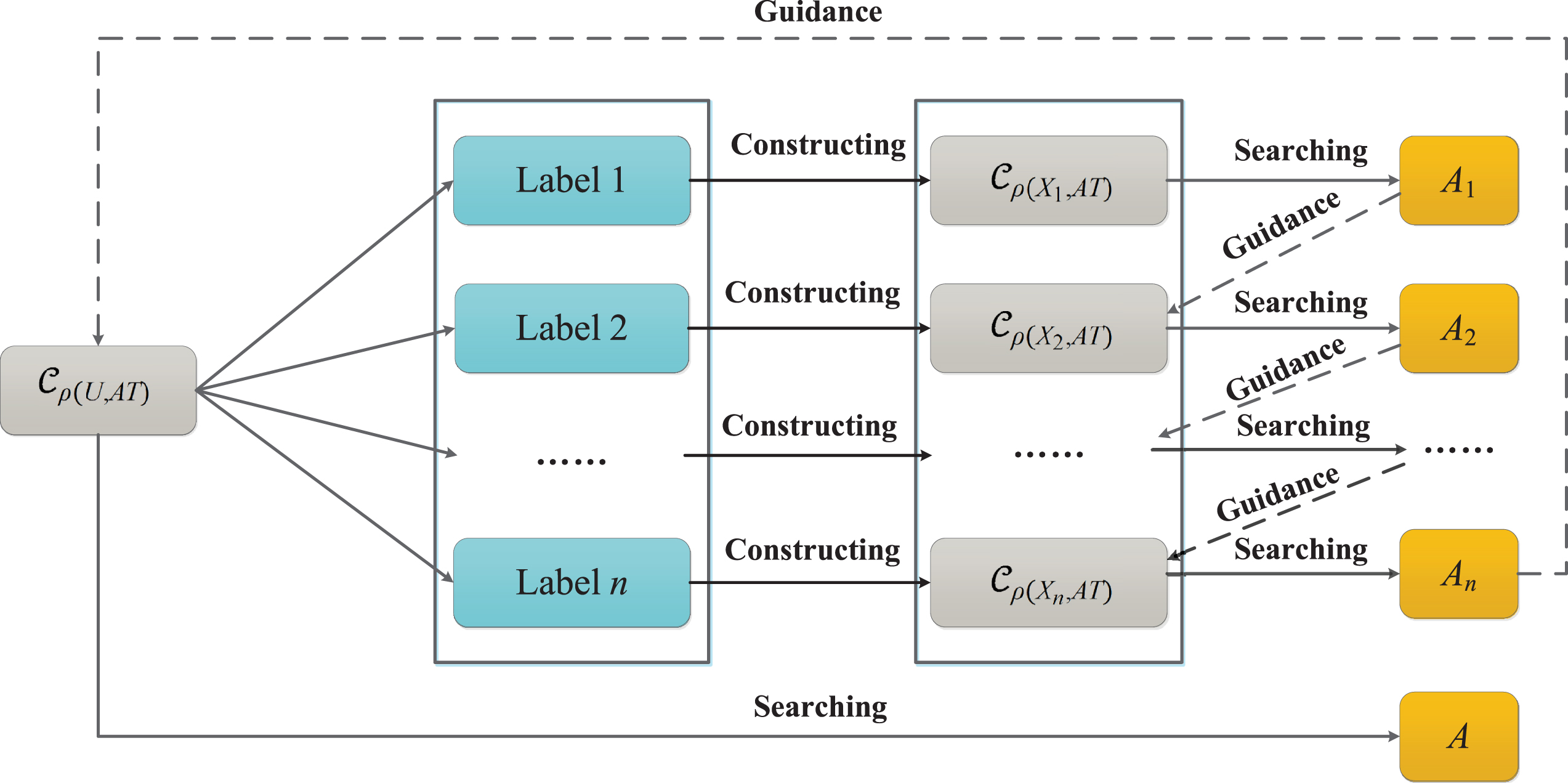
The process of label-specific guidance for searching reduct.
In Fig. 1, the detailed steps of label-specific guidance for searching reduct will be designed as follows: Obtain ℙ based on the label attribute L; ∀X
j
∈ ℙ, compute ρ (X
j
, AT), and then sort them to derive a sequence of different disjoint classes such that X1, X2, ⋯ , X
n
; For X1, search the Let A2 = A1, if A2 is not the ...... Let A
n
= An-1, if A
n
is not the Let A = A
n
, if A is not the
The above steps divide the whole process of deriving reduct over the universe into two main phases: 1) for the j-th label (1 ≤ j ≤ n), calculate the
To formally express our strategy, the following Algorithm 2 will be designed.
X1, X2, ⋯ , X n ;
AT - A};
Following Algorithm 2, the label-specific guidance searching divides
Therefore, the time complexity of Algorithm 2 is
The space complexity of Algorithm 2 is
It is not difficult to observe that even though the space complexity of Algorithm 2 is the same with that of Algorithm 1, but the time complexity is much less than that of Algorithm 1. Therefore, our proposed Algorithm 2 can accelerate the process of deriving reduct in theory.
Data sets
To demonstrate the effectiveness of our proposed strategy, 20 UCI data sets have been selected to conduct the experiments. The details of the data sets are shown in the following Table 1.
The detailed description of data sets
The detailed description of data sets
All the experiments have been conducted on a personal computer with Windows 10, Intel Core i7-10710U CPU(1.61GHz), and 16 GB memory. The programming language is MATLAB R2016a.
In this section, the model used for deriving reduct is the neighborhood rough set [12, 44]. Therefore, 20 different radii, i.e., 0.01, 0.02, 0.03,⋯, 0.2, which were recommended by Ref. [26], have been used for constructing neighborhoods. Moreover, approximation quality [25] and conditional entropy [6, 50] are employed to define attribute reduction. Finally, for each radius, the 5-fold cross-validation is employed to derive reduct.
To demonstrate the superiorities of our proposed acceleration strategy, the following five state-of-the-art algorithms have also been reproduced:
Comparisons of the elapsed time
In this subsection, the elapsed time for deriving reducts w.r.t. the approximation quality and the conditional entropy by different algorithms will be compared. The detailed results are shown in the following Figs. 2 and 3, respectively.

The elapsed time of deriving reducts w.r.t. the approximation quality.

The elapsed time of deriving reducts w.r.t. the conditional entropy.
In Figs. 2 and 3, each subgraph contains six different colors’ lines, corresponding to the changes of the elapsed time of deriving reducts by six different strategies, respectively. It should be pointed out that the purple line corresponds to the elapsed time of deriving reducts by our strategy. Notably, in most subgraphs of Fig. 3, the top of the ordinate axis are greater than t(t represents a critical value of time consumption), which express that the time consumption of the attribute reduction method is much greater than t.
With a deep investigation of Figs. 2 and 3, it is not difficult to observe that the purple line significantly is lower than other colors’ lines. In other words, the process of deriving reducts by our proposed searching strategy requires less time-consuming. Taking the “Forest Fires(ID: 5)” data set as an example, if δ=0.1 and the measure of approximation quality is used, then the elapsed time of generating reducts by FGSAR, AGAR, DBSAR, PAAR, MGAR are 5.4677, 3.7705, 3.1739, 2.5609 and 6.4418 seconds, respectively. However, our strategy only needs 0.9129 seconds. Without loss of generality, our strategy can effectively compress the space of both attribute and sample by using labels’ information, then the efficiency of generating reduct can be significantly improved.
The values of the speed-up ratio will also be presented in the following Tables 2 and 3.
The speed-up ratio for comparing elapsed time of deriving reduct w.r.t. approximation quality
The speed-up ratio for comparing elapsed time of deriving reduct w.r.t. conditional entropy
Following Tables 2 and 3, it is not difficult to reveal that most of the values of the speed-up ratio are much greater than 1, that is, our proposed searching strategy ranks first over the six algorithms if the time efficiency of the algorithm is considered.
Moreover, by the average values of the speed-up ratio, it is not difficult to observe that no matter which measure is used, the speed-up ratio of MGAR v.s. Proposed is greater than that of FGSAR v.s. Proposed, the speed-up ratio of FGSAR v.s. Proposed is greater than that of AGAR v.s. Proposed, the speed-up ratio of AGAR v.s. Proposed is greater than that of PAAR v.s. Proposed. In other words, Proposed is faster than PAAR, PAAR is faster than AGAR, AGAR is faster than FGSAR and FGSAR is faster than MGAR.
Besides the time consumptions and speed-up ratios, to further compare the six algorithms from the viewpoint of statistics, the Wilcoxon signed rank test is employed, in which the significance level is appointed as 0.05. That is to say, if the returned p-value is lower than 0.05, then it indicates that these algorithms perform significantly different; otherwise, these algorithms perform similarly. The detailed results are shown in the following Tables 4 and 5.
The p-values for comparing elapsed time of deriving reduct w.r.t. approximation quality
The p-values for comparing elapsed time of deriving reduct w.r.t. conditional entropy
In Tables 4 and 5, the p-value of MGAR V.S. Proposed is the same because the value has reached the minimum in Matlab. With a careful investigation of Tables 4 and 5, it is not difficult to find that all obtained p-values are much less than 0.05, which implies that our proposed searching strategy performs significantly different from other strategies in time consumption. By combining with what have been observed in Figs. 2 and 3, our strategy is obviously superior to other accelerators in time efficiency.
In this subsection, the classification accuracies related to the reducts derived by six algorithms will be compared. Notably, since 20 radii have been employed to derive reducts, the results shown in this subsection are the maximal accuracies related to the reducts of 20 radii. Furthermore, KNN, SVM classifiers are employed to conduct classification accuracies and the detailed results will be shown in the following Tables 6-9.
The classification accuracies based on approximation quality based reduct over KNN classifier
The classification accuracies based on approximation quality based reduct over KNN classifier
The classification accuracies based on conditional entropy based reduct over KNN classifier
The classification accuracies based on approximation quality based reduct over SVM classifier
The classification accuracies based on conditional entropy based reduct over SVM classifier
Through carefully observing Tabs. 6-9, it is not difficult to reveal that no matter which classifier or measure is employed, the reducts derived by our strategy will not lead to poorer classification accuracies compared with other strategies.
In this paper, we developed label-specific guidance for accelerating the process of deriving reduct in the rough set theory. Different from previous popular accelerators, our strategy takes two main ideas of Granular Computing into account: 1) the whole universe is divided into several disjoint groups for obtaining the local perspectives, which implies the main idea of breaking up the whole into pieces; 2) the guidance thinking is introduced into the searching of appropriate conditional attributes, which implies the main idea of gathering parts into a whole. It follows that such type of the guidance strategy is of great value in improving the efficiency of deriving reduct.
The following topics will deserve our further investigation. Other effective measures such as conditional discrimination index and neighborhood decision error rate may be further employed for verifying the effectiveness of our acceleration searching strategy. The acceleration searching strategy proposed in this paper is only designed based on the data with single label, the situation with multiple labels need to be further explored.
Footnotes
Acknowledgment
This work is supported by the Natural Science Foundation of China (Nos. 62076111, 61906078, 62006099, 62006128), Nature Science Foundation of Jiangsu, China (No. BK20191457), Open Project Foundation of Intelligent Information Processing Key Laboratory of Shanxi Province (No. CICIP2020004) and the Key Laboratory of Oceanographic Big Data Mining & Application of Zhejiang Province (No. OBDMA202002).