
Abstract
High utility quantitative itemsets (HUQI) mining is a new research topic in the field of data mining. It not only provides high utility itemset (HUI), but also provides quantitative information of individual item in the itemset. HUQI can provide decision makers with information about items and their purchase quantities. However, the currently proposed HUQI mining algorithms assume that the datasets are static. In order to solve this problem, an incremental quantitative utility list (IQUL) data structure is proposed to store item information, including item name, item number, transaction weight utility of item, each entry in the list stores the transaction identifier, the utility of the original data, the remaining utility, the utility of the incremental data, the remaining utility, and the sum of the utility and the remaining utility. When data is inserted, the item information will be updated. Based on IQUL, an incrementally updating HUQI (IHUQI) mining algorithm is proposed to mine HUQI on incremental update data. A large number of experiments on real datasets show that the IHUQI algorithm can effectively mine HUQI Experimental results show better performance on sparse datasets.
Keywords
Introduction
Frequent itemsets mining (FIM) [1] is used to discover frequent itemsets in transaction databases. However, frequent itemsets can only find itemsets with more purchases by users, and the profits of itemsets are not considered. To mine itemsets with higher profits, the researchers further proposed high utility itemsets mining (HUIM) algorithm [2]. Utility mining is to discover high utility itemsets (HUI). The internal utility and external utility are set for each item to mine HUI. In addition, researchers have proposed a variety of expansion modes for HUI to obtain more accurate information, including closed HUI [3], average HUI [4], and HUI with negative utilities. [5], top-k HUI [6] and other mining algorithms.
Although these HUI can find interesting itemsets, they ignore the quantity attribute of items in the HUI. HUI may not always be high income products, because purchased quantity of items will also affect the income of items. Quantitative of items can provides more useful and accurate information in many applications. Thus, high utility quantitative association rules (HUQA) mining algorithm [7] is proposed. In the framework of HUQI, an item may have different quantities in the database, and each item carrying a different quantity is regarded as a quantitative item, denoted as q—item. The itemsets composed of q—item are integrated into a q—itemset. If the utility of a q—itemset is not lower than the user specified minimum utility threshold, the itemsets are called HUQIs. For example, the HUQIM algorithm can find a HUQI “yogurt: 3, bread: 2, jelly: 6”, indicating that buying 2 breads, 3 yogurts and 6 jellies will generate high profits. HUQIM algorithm can also find itemsets that include a range of quantities. For example, “Cheese: 3–6, Juice: 5–7” means that buying 3–6 pieces of cheese and 5–7 bottles of juice can generate high profits. Due to the quantity of information provided, the itemsets discovered by HUQIM algorithms are more informative than the itemsets discovered by HUIM algorithms. This information can help decision-makers make more accurate decisions. The currently proposed HUQIM algorithms are only used for static datasets mining.
In real-world application, however, data have been incrementally generated due to new purchases from customers. Transactions in datasets are not always static. Therefore, it is desired to developed an efficient incremental mining algorithm to update the HUQI on dynamic datasets. But there is no algorithm for mining HUQI on incremental datasets. Therefore, this paper proposes an algorithm for mining HUQI on incremental data.
The main contributions of this article include 3 aspects: A novel data structure named IQUL is proposed to store items information which contains 7 parameters and can update the information of items when new data is inserted; Proposed IHUQI mining algorithm based on IQUL to mine HUQI in incremental datasets; To evaluate the proposed IHUQI algorithm, extensive experiments were conducted on different datasets. Experimental results show that the IHUQI algorithm performs better on sparse datasets.
Related work
This section mainly introduces the research results of HUIM algorithms, from three perspectives: HUIM algorithms, incremental HUIM algorithms, and HUQIM algorithms.
High utility quantitative itemsets mining algorithms
HUIs can only provide interesting itemsets, ignoring the quantity information of a single item. In order to consider the relationship of items and the quantity of items, Li et al. [8] proposed the VHUQI (Vertical mining of HUQI) vertical mining algorithm, which converts the horizontal datasets into a utility list structure to accelerate the mining process. The utility list is used to store the utility information of the q-itemsets in the dataset, and the k-support bound is used to estimate the pruning search space. Li et al. proposed the HUQI-Miner algorithm [9]. The algorithm uses the utility list structure to directly calculate the utility of the q-itemsets in the memory, and uses the transaction weighting utility and ER pruning technology to reduce the number of candidates q-itemsets. Nouioua et al. [10] proposed FHUQI-Miner (Faster HUQIM). This algorithm proposes two new pruning strategies EQCPS and RQCPS. The proposed strategy can greatly reduce the number of connection operations in the search process and improve the running time of the algorithm, but the algorithm is more effective on sparse datasets.
Incremental high utility itemsets mining algorithms
With the advent of the era of big data, new data is generated at all times. Since static approach have to rescan the dataset and perform mining operation again, which is very time consuming. Therefore, developing efficient algorithm to process incremental data is desired. Yun et al. [11] proposed list based incremental high utility pattern (LIHUP). It scans the dataset once to build utility list to store utility information and have no candidate. Yun et al. [12] proposed indexed list based incremental high utility pattern mining (IIHUM) algorithm, only one scanning of datasets. Kim et al. [13] proposed incremental mining of high average utility itemsets (IMHAUI) based on tree structure. Dam et al. [14] proposed the first approach which is IncCHUI to mine CHUIs from incremental datasets. Wang et al. [15] proposed IncUSP-Miner+ algorithm to mine high utility sequence patterns (HUSPs) incrementally. This algorithm uses a tighter upper bound of the utility and the candidate pattern tree to reduce redundant computations. These algorithms are designed to process HUI related problems, and do not provide information about the number of items.
Problem definition
This section mainly introduces the basic concepts of HUQIM, and the combination method of generating Rq—itemsets.
Preliminary knowledge
Let I denote the set of item i, that I = {i1, i2, . . . , i m } is a set of items, D = {T1, T2, . . . , T n } is a quantitative transaction dataset, where the items in each transaction T i are a subset of I. Itemset X is a subset of I. The number of items i p in the transaction T q is represented by n (i p , T q ). The external utility s (i p ) is the unit value of the item i p (for example, profit). The utility of the item i p in the transaction T q , represented by u (i p , T q ), u (i p , T q ) = n (i p , T q ) × s (i p ) is defined as the product of the internal utility and the external utility.
Table 1 gives an example of a quantitative transaction database D. T1 to T4 represent the original dataset D1, T5 and T6 represent the incremental dataset D2, T7 and T8 represent the incremental dataset D3. In addition, Table 2 shows the external utility of D. Taking item a as an example, in Table 2, it can be seen that the profit of item a is 5. The number of items a in T1 is 2, and the utility of item a in T1 is 10.
Sample dataset
Sample dataset
External utility values
Quantitative items include exact quantitative items and range quantitative items, collectively referred to as quantitative items, denoted as: q—item [7].
For example, u ((a, 2) , T1) =2 × 5 =10, u ((a, 1, 2) , T3) = u ((a, 1) , T3) + u ((a, 2) , T3) =5 + 0 =5.
For example:
u ([(a, 1, 2) (b, 3, 4)] , T3) = u ((a, 1, 2) , T3) + u ((b, 3, 4) , T3) =5 + 21 = 26.
For example:
TU (T1) = u ((a, 2) , T1) + u ((b, 4) , T1) + u ((e, 6) , T1) + u ((f, 4) , T1) =10 + 28 + 6 +12 = 56.
For example, the utility of the whole dataset shown in Table 1 is σ = TU (T1)+ TU (T2) + TU (T3) + TU (T4) + TU (T5) + TU (T6)+ TU (T7) + TU (T8) =56 + 9 +34 + 41 + 17 + 25 + 8 +42 = 232.
This section introduces two combination methods, namely Combine_All [9] and Combine_Min [23] methods.
The Combine_All method combines candidates q—item, candidates q—itemset and Rq—itemset outputs all possible high utility Rq—itemset. Suppose there are 6 candidate itemsets {[(a, 2), (b, 4), (d, 3)], [(a, 2), (b, 4) (c, 1)], [(a, 2), (b, 4) (c, 2)], [(a, 2), (b, 4) (c, 3)], [(a, 2), (b, 4) (c, 4)], [(a,2 ), (b, 4) (c, 5)]}, and qrc set to 4, The process of method combination candidates using Combine_All method is shown in Fig. 1.
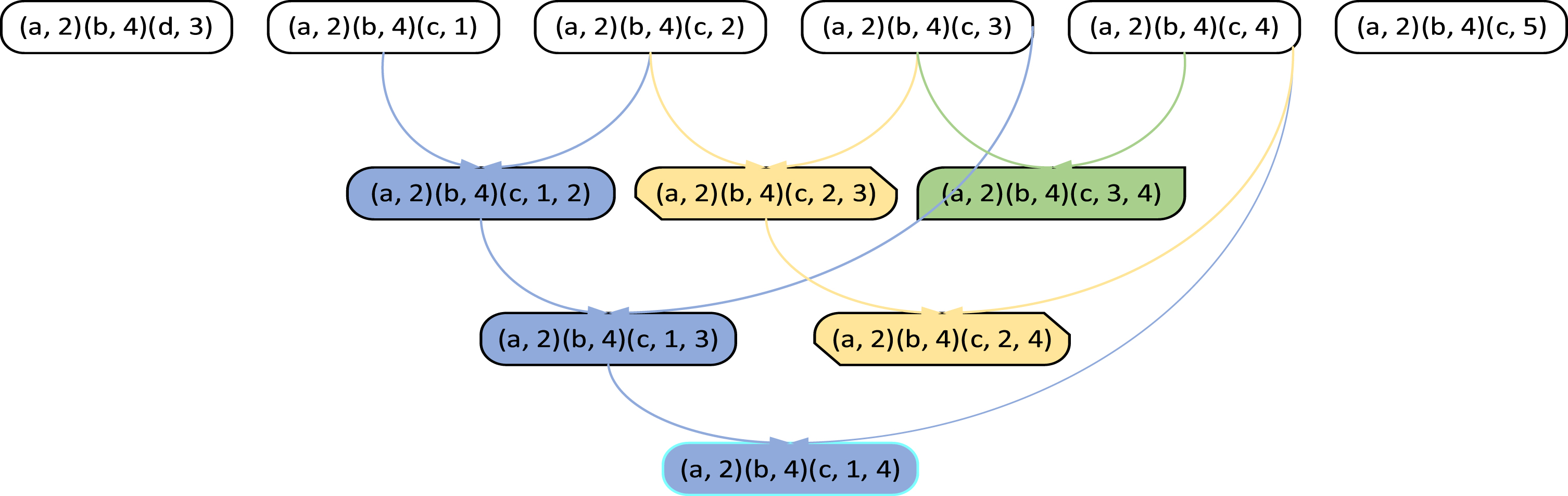
Combine process.
The Combine_Min method only outputs the high utility of the minimum interval Rq—itemset. The Combine_Min method uses the same traversal process as Combine_All methods, but after generating the range HUQI, the Combine_Min method will immediately stop combining the current one with the rest and pass it directly to the next candidate q—itemset. As shown in the example in Fig. 1, if the generated [(a, 2), (b, 4), (c, 1, 2)] is HUQI, the Combine_Min method will directly move to the next q—itemset [(a, 2), (b, 4), (c, 2)] and [(a, 2), (b, 4), (c, 3)] generate [(a,2), (b,4), (c, 2, 3)].
In this section, an incremental quantitative utility list IQUL and an incrementally updated HUQI mining algorithm IHUQI are proposed. The algorithm uses the utility information stored in IQUL to mine HUQI. This section first introduces the IQUL structure, and then introduces the IHUQI algorithm.
Algorithm description: The first step is to scan the database and calculate the TWU of q—item, because there is incremental data, the q—item in original dataset is not HUQI, and it will become HUQI later when the incremental data is added, so it is necessary to construct a IQUL and TQCS structure for each q—item. The second step is to check which of the HUQI H, candidate itemsets C, or explored itemsets E belongs. Then, use a combination method to combine the candidate itemsets to get the initial Rq—item which is HR, and then merge H, E and HR into Qis. The third step is to call the mining algorithm to mine HUQIs recursively.
Incremental quantitative utility list structure IQUL
IHUQI uses IQUL to store the utility information of original data and incremental data. The item information stored by IQUL includes q—item, TWU of q—item, IutilD, RutilD, IutilDP, RutilDP. Where IutilD and IutilDP represents the utility of the itemset in the transaction in the original dataset and the incremental data. RutilD and RutilDP represents the remaining utility of the itemset in the transaction in the original dataset and the incremental data. IQUL will also store the utility sum of the itemset, including SumItuilD, SumRtuilD, SumItuilDP, SumRtuilDP, which respectively represent the sum of IutilD the sum and the sum of RutilD in the original dataset; and the sum of IutilDP and the sum of RutilDP in the incremental data.
Taking q—item (a, 2) in the dataset as an example, the IQUL is shown in Fig. 2. When scanning the dataset D1, the dataset is regarded as an incremental dataset, and only T1 contains (a, 2) in D1. The utility information of q—item scanned dataset is stored in IQUL. When inserting a dataset D2, the utility information IutilDP and RutilDP in the dataset D1 will be passed to IutilD and RutilD, and will be used as the original dataset, and then the dataset D2 will be scanned to store its utility information. When the dataset D3 is inserted, the utility information of the dataset D2 is added to the utility information in the original dataset, and then the incremental utility information is added.

IQUL of (a, 2).
This section introduces the proposed IHUQI algorithm. The proposed algorithm follows the procedures similar to FHUQI-Miner and VHUQI. IHUQI will input 4 parameters: (1) transaction dataset D, incremental transaction dataset DP (internal utility) and transaction profit dataset D_profit (external utility), (2) minimum utility threshold θ, (3) combined method (CM), (4) Quantitative correlation coefficient (qrc). The output is HUQIs. The specific process is shown in Algorithm 1.
The IHUQI algorithm is mainly divided into three steps: Construct the IQUL of q—item (1–3 lines). First scan the transaction dataset D and the transaction profit dataset to calculate the initial TWU of q—item, and store the q—item in P*. Then the second dataset scan is performed. In addition, q—item in each transaction is reordered according ≺, and create the utility list and TQCS structure of the transaction dataset. Find the initial Rq—item (lines 4–9). IHUQI first checks the utility of q—item, for each item x, if u (x) ≥ θ, x is output as a HUQI, and put it into the set H which containing HUQIs. Otherwise, IHUQI performs two judgments: (1) If θ/qrc ≤ u (x) ≤ θ, x put it into the set C, which contains candidates q - itemsets that can be combined to form high utility Rq—itemsets. ② If u (x) + UL (x) . SumRutil ≥ θ, x is put into the set E, the set contains all the q—itemsets that should be explored, because one or more of their extensions may be high utility. If the set C is not empty, call the CM to generate HR and UL (HR). HR is the high utility Rq—itemsets generated by calling the CM to combine the candidates in C, and UL (HR) is the corresponding IQUL of HR. Then IHUQI created Qis, Qis is composed of H, E and HR. The items in Qis are sorted according ≺. IHUQI calls the mining algorithm (10 lines) to mine HUQIs. The mining process algorithm is described in Algorithm 2.
Recursive mining search will input 7 parameters: (1) prefix itemset P, (2) set of Qis, (3) IQUL of items in Qis UL (QIs), (4) set of itemset P*, (5) quantitative correlation coefficient (qrc), (6) Combination method CM, (7) Minimum utility threshold θ.
When the algorithm is called for the first time, the prefix P of q—item is ∅, which contains Eq—item and Rq—item identified in Algorithm 1. The specific operation of the mining algorithm is as follows: For each extension Px of P, among them x ∈ Qis, the algorithm traverse all the extensions Py of P, among them y∈ P * and according x ≺ y to explore the expansion of Pxy, which are reflected in the first 1–3 of the algorithm 2.
For each extension Pxy, the algorithm performs a pruning check based on the TQCS structure to decide whether to extend q—itemset Pxy or pruning this directly without spending time creating a IQUL for it. There are two situations: Both q—item x and y are Eq—item. The algorithm searches for tuples (x, y, c) in the TQCS structure. If c = ∅ or c < θ/qrc, the algorithm will be passed directly to the next extension Py without constructing UL (Pxy). Because q—itemset Pxy and all its extensions are LUQI, it is reflected in the 4–9 lines of Algorithm 2. If x is Rq—item, the algorithm looks for the tuples of each contained in the TQCS structure. If the sum obtained is less than, the algorithm prunes the combination instead of constructing its IQUL. Corresponding to the line 10–13 of Algorithm 2.
For these two cases, if TWU (xy) ≥ θ/qrc, then the algorithm performs the concatenation operation through UL (P), UL (Px) and UL (Py) to build UL (Pxy).
Based on UL (Pxy), pruning Pxy if Pxy is no hope, the algorithm will be passed directly to another extension Py. Otherwise, the extension Pxy is put into a promising new list P*, and the algorithm performs similar judgments as in Algorithm 1 to check whether it belongs to H (lines 17–20), E (lines 22–24), and C (line 25–27 line).
After traversing all the extensions Py, the combined operation CM is performed to extract the high utility Rq - itemset (HR), which is reflected in line 31 of Algorithm 2. Then, the new set Qis is formed by the union of H, E, and HR. Then the recursive mining search algorithm uses the new prefix Px and the new Qis and P* is called recursively together with the prefix Px.
Case analysis
In this section, an example will be given to illustrate the proposed IHUQI algorithm. The original database D1 is in Table 1, and the incremental data is D2, D3. Using Combine_All method, the qrc is 3, and the minimum utility threshold is 40.
First, scan the dataset to calculate different TWU of q—item, and the TWU of q—item is shown in Table 3. Then perform the second dataset scan to construct the IQUL and TQCS structure, and the TQCS structure of q—item is shown in Table 4.
TWU of q-item
TWU of q-item
TQCS structure
After that, the data in the dataset is sorted in descending order according to their utility, and after sorting P* = {(b, 4), (b, 3), (f, 4), (a, 2), (e, 7), (c, 2), (e, 6), (a, 1), (d, 2), (c, 1), (e, 3), (f, 1)}, then according to the utility of q—item in P*, according to its utility in IQUL are put into the HUQI set (H), candidate q—itemsets (C) or explored set (E) respectively. After traversing all q—item in P*, since all items in P* are LUQI, the set H is empty, C= {(b, 3), E= (b, 4)}. After that, IHUQI use the Combine_All method to find Rq—itemset from the set C, calculate its utility and output HR, because the set C contains only one q—item so it does not produce Rq—itemset HR, that is HR =∅. After the combination process, the set H, HR and E constitute a set Qis, which is Qis= {(b,4)} in this dataset. Finally, the algorithm calls the mining algorithm, from the first q—item to the last q—item in the set Qis. In this process, the algorithm first uses EQCPS [23] and RQCPS [23] for pruning to avoid generating unnecessary itemsets, and then performs connection operations to generate larger itemset. In the dataset D1 Px = (b, 4) and all Py, y∈ P * is used to expand. (b, 4) is first extended with (b, 3). It can be seen from Table 4 that there is no such entry (a, b, c) ∈ TQCS, that is A = (b, 4), B = (b, 3), and C ≥ (θ/qrc). Therefore, the itemset [(b, 4), (b, 3)] is ignored and no longer produces a IQUL of [(b, 4), (b, 3)]. The algorithm will proceed to the next Py, y∈ P * which is Py = (f, 4). It can be seen TWU [(b, 4) , (f, 4)] =6 ≥ (θ/qrc) from Table 4. Therefore, q—item (b, 4) and (f, 4) are connected to form [(b, 4), (f, 4)] and IQUL of [(b, 4), (f, 4)]. Then put it into P* and check its utility to determine which set of HUQI (H), set for combination (C) or explored itemset (E). Since u([(b, 4),(f, 4)]) = 40, q—itemset [(b, 4), (f, 4)] is output to the set H. The algorithm continues to expand recursively, after traversing all expansions H= {(f, 4)}, C= {(a, 2), (e, 7), (c, 2), (e, 6)}, E= {(f, 4), (a, 2), (e, 7)}, the HR is formed by combining operations for q—item in C, and the final result is QIs= {(f, 4),(a, 2),(e, 7),(e, 6, 7)}. In addition, a new promising list is formed P*= {(f, 4), (a, 2), (e, 6, 7), (e, 7), (c, 2), (e, 6)). Then the algorithm is called recursively to explore larger q—itemsets, until all HUQIs are found.
When incremental data is inserted, scan the incremental dataset to calculate TWU of q - item, construct its IQUL and TQCS structure. For items that exist in the original dataset D1, their utility will be updated in the original IQUL. If the original dataset D1 does not exist, a new IQUL will be created. Then call CM to generate the Rq—item. In Table 1, it will generate Rq—item(b, 2, 3) and its corresponding IQUL. It will do the same operation as before, when the dataset D3 is inserted. It generated Rq—item (a, 2, 3), (b, 2, 3) and their corresponding IQULs. The detailed process is shown in Fig. 3. Finally, call the mining operation to mine all HUQIs.

Construction of IQUL and combination process.
In this subsection, time complexity of the proposed method IHUQI is discussed for the following two aspect: IQUL construction or update, and pattern mining. Let M
o
and M
i
be the number of transactions in the original and increased databases composed of N
q
q—items, respectively. The algorithm first scans the original data or incremental data to calculate the TWU of q—items. The time complexity is O (M
o
N
q
) or O (M
i
N
q
), respectively. Then perform a second scan to build the utility list and TQCS structure. Before constructing IQUL, transactions need to be sorted according to TWU. The time complexity of this process is O (M
o
N
q
log (M
o
N
q
)) or O (M
i
N
q
log (M
i
N
q
)). The time consumption to construct TQCS is
The mining part is composed of join operations and combined operations. The worst case of the mining process is that no patterns are deleted, and two IQULs need to be joined to expand into a larger itemset. There are N
q
items that need to be connected. The number of expansion patterns is O (2
N
q
- N
q
). The time complexity of the join operation is
Experimental results
In this section, the algorithm VHUQI is used to evaluate the performance of the proposed algorithm IHUQI, and the comparison algorithm is the HUQI mining algorithm on static data. In the evaluation experiment, all algorithms are implemented in Java language.
The experimental running environment is 3.00 GHz CPU, 256 GB memory, and the operating platform is Win10 Professional Edition. Five different types of real datasets Connect, Retail, Pumsb, BMS and BMS2 are used to evaluate the performance of the algorithm. All datasets are obtained from SPMF [16]. The characteristics of these datasets are shown in Table 5, describing the number of transactions in the datasets, the number of different items, the average transaction length, and the type of the datasets. The datasets include dense and sparse datasets, which are commonly used as benchmark datasets in the HUIM literature. The experiments divide the datasets into five batches and insert them incrementally, using the Combine_All combination method, except that the Connect dataset qrc is set to 4, and the qrc of the rest datasets are set to 3.
Dataset characteristics used in the experiment
Dataset characteristics used in the experiment
This section conducts experiments on the effectiveness of IHUQI. Two datasets are selected, the sparse datasets Retail and the dense datasets Connect to illustrate the incremental mining results. The two datasets are mining HUQI incrementally when the minimum utility threshold is 0.05% and 2.9% respectively, and the data is divided into 5 batches, 10 batches, and 15 batches. The mining results are shown in Fig. 4 and Fig. 5. It can be seen in Fig. 4 that as the batches are added, the extracted HUQI is also increasing.

HUQI on Connect.

HUQI on Retail.
When the minimum utility threshold is 2.9% on the Connect dataset, the number of HUQIs that meet the condition in the first few batches is 0. With the insertion of batches, the number of HUQIs that meet the condition continues to increase. On the Retail dataset, the first batch has HUQI that meets the minimum utility threshold. With the addition of batches, the mined HUQI keeps increasing. It can be seen that the final number of HUQI mined by different batches is equal. It can be seen that IHUQI can effectively update HUQI incrementally.
Figure 6 shows the experimental results of VHUQI and IHUQI on the BMS2 and Retail datasets. As the size of the dataset increases, the running time changes.

Running with different dataset size.
The minimum utility threshold of the BMS2 dataset is set to 0.05%, and the running time of VHUQI and IHUQI both increase with the increase of the size of the dataset. The reason is that the HUQI that meets the conditions must be extracted from a larger number of transactions. IHUQI has better performance in terms of database size increase. It can be seen that as the dataset size increases, the running time gap between IHUQI and VHUQI becomes larger. The minimum utility threshold of the Retail dataset is set to 0.01%. As the size of the dataset increases, the running time of the algorithm increases, and the difference in running time between the two algorithms gradually increases. Compared with the VHUQI algorithm on static data, IHUQI can process incremental data and effectively mining HUQI.
Figure 7 to Figure 11 show the running time comparison between the comparison algorithm VHUQI and IHUQI algorithm as the minimum utility threshold increases. With the increase of the minimum utility threshold, the running time gradually decreases, because with the increase of the minimum utility threshold, the itemsets that meet the conditions will be reduced, and the IQUL that needs to be constructed will be correspondingly reduced. In addition, the time consumed in the mining process will be further reduce. It can be seen that the IHUQI algorithm is faster than the VHUQI algorithm on the BMS dataset and the BMS2 dataset. The reason is that the proposed TQCS structure and the pruning strategy used can effectively improve the mining efficiency. On the Retail dataset, IHUQI is still better than VHUQI when the minimum utility threshold is small, and when the minimum utility threshold is large and the resulting HUQI is less, VHUQI is better than IHUQI, but the time difference is small. The reason is that although Retail dataset is a sparse dataset, it contains a large number of q-items. Besides, in the incremental mining process of IHUQI, it will generate data related to the original dataset, which needs to be recombined, which consumes a certain amount of time. On the Connect dataset, when the minimum utility threshold is small, the IHUQI algorithm is better than VHUQI, but on the Pumsb dataset, VHUQI is better than IHUQI, but the running time is not much different. The dense dataset contains long transactions and also contains a large number of HUQIs when the minimum utility threshold is small. In general, the running time of IHUQI on sparse datasets is better than VHUQI. On dense datasets, the running times of the two algorithms are similar. The reason is that the similarity between transactions in the sparse dataset is small. It is found that HUQIs are not similar to each other, and the combination is pruned according to the pruning strategy, reducing the running time.
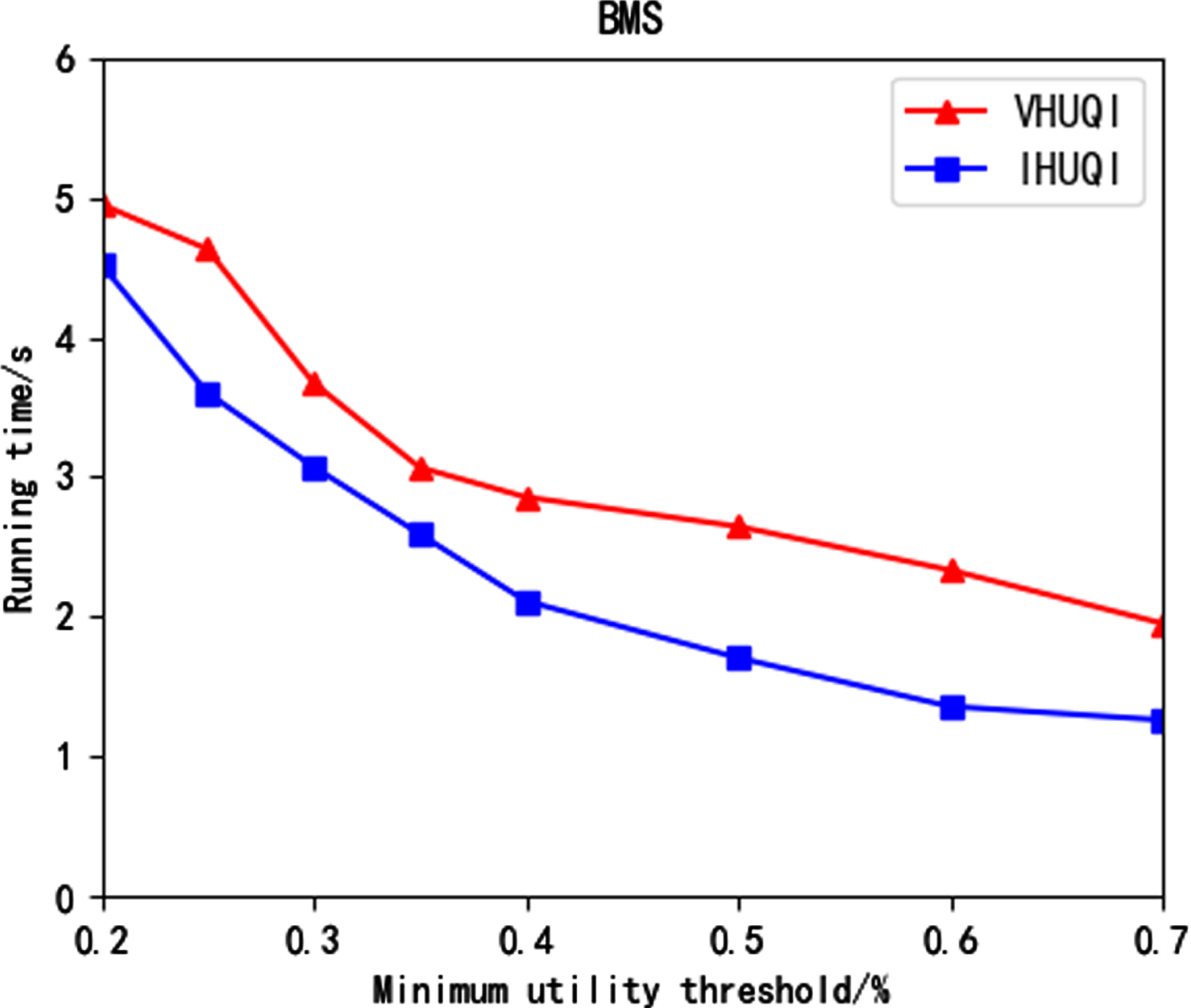
Running time on BMS.
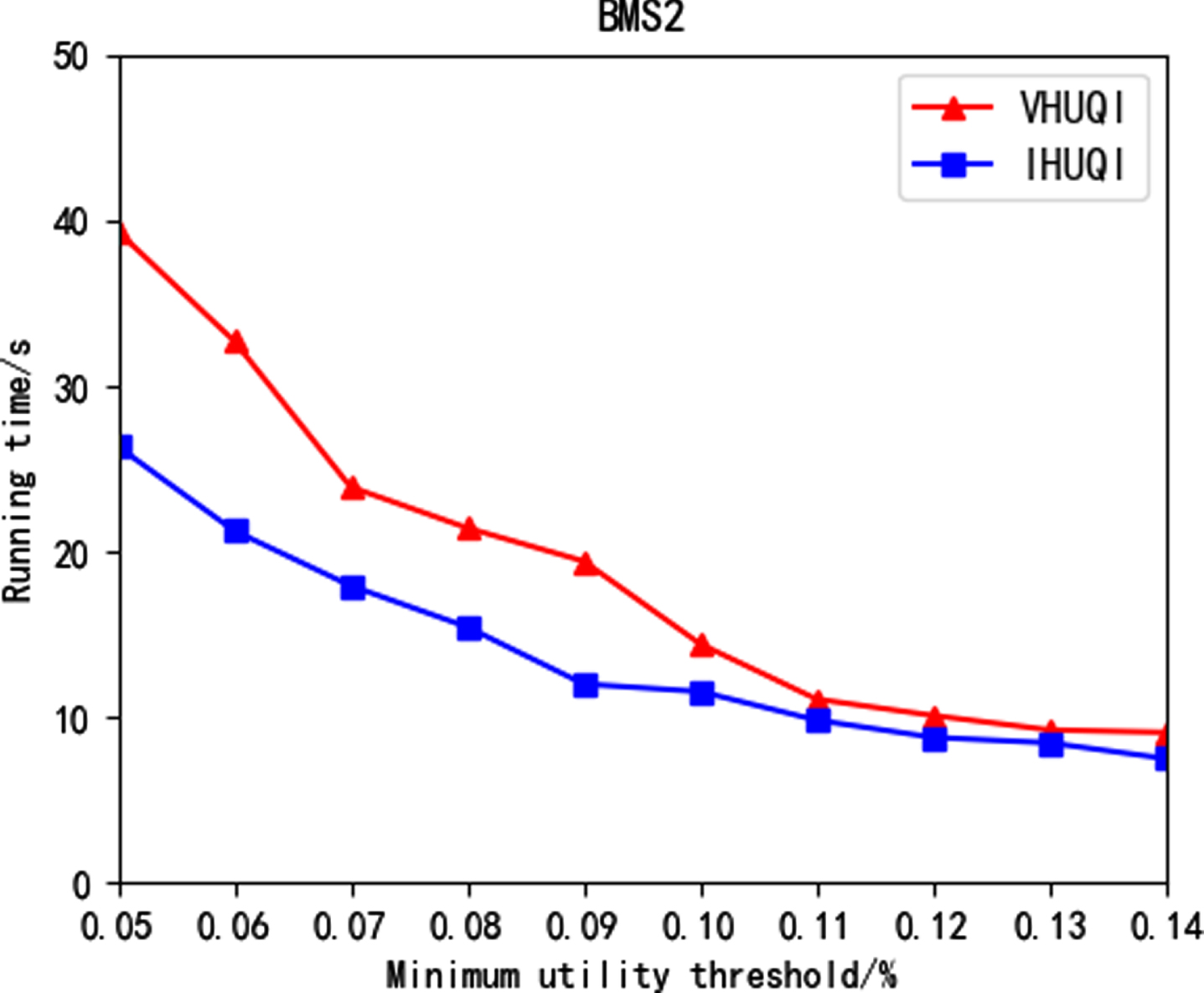
Running time on BMS2.
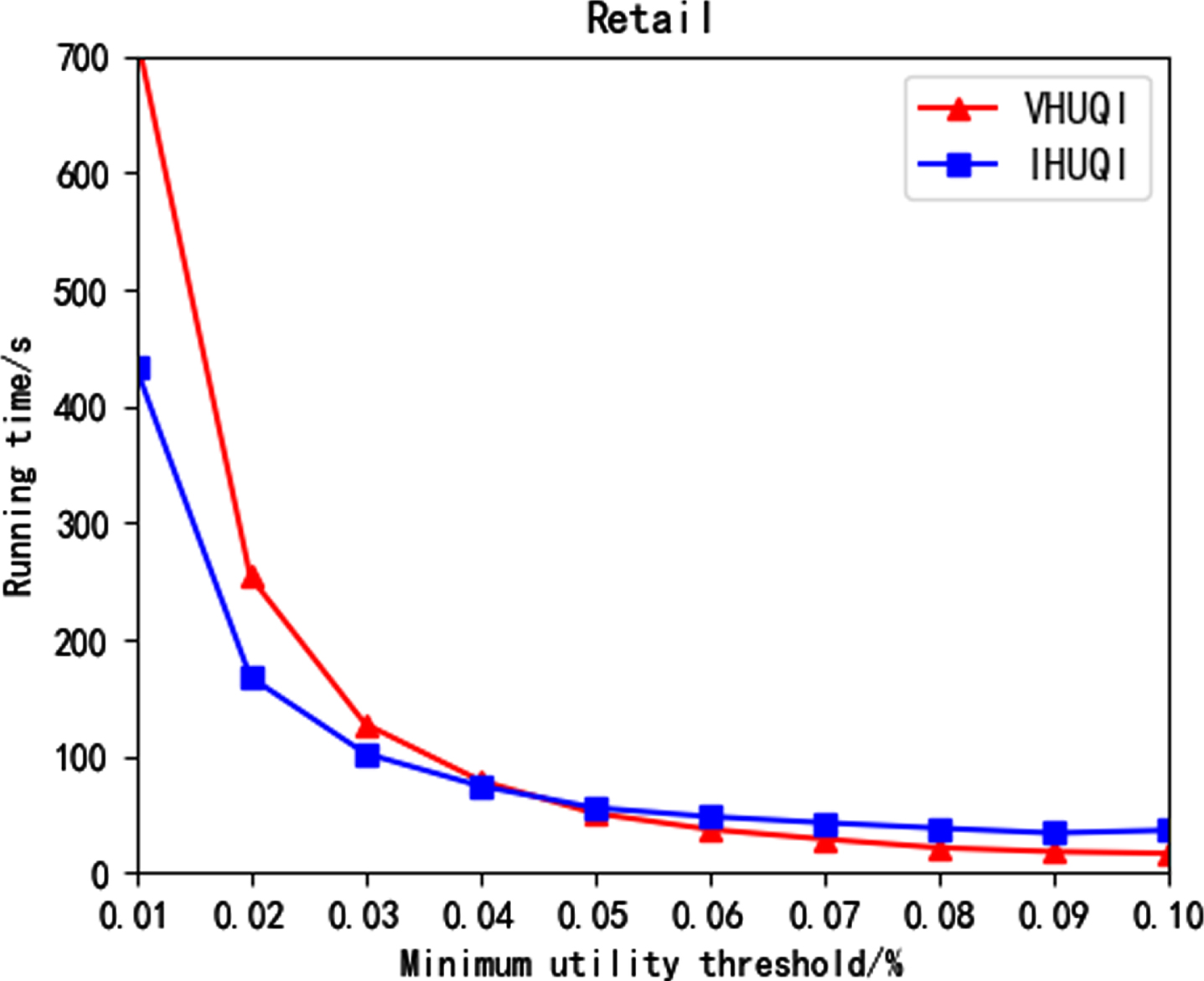
Running time on Retail.
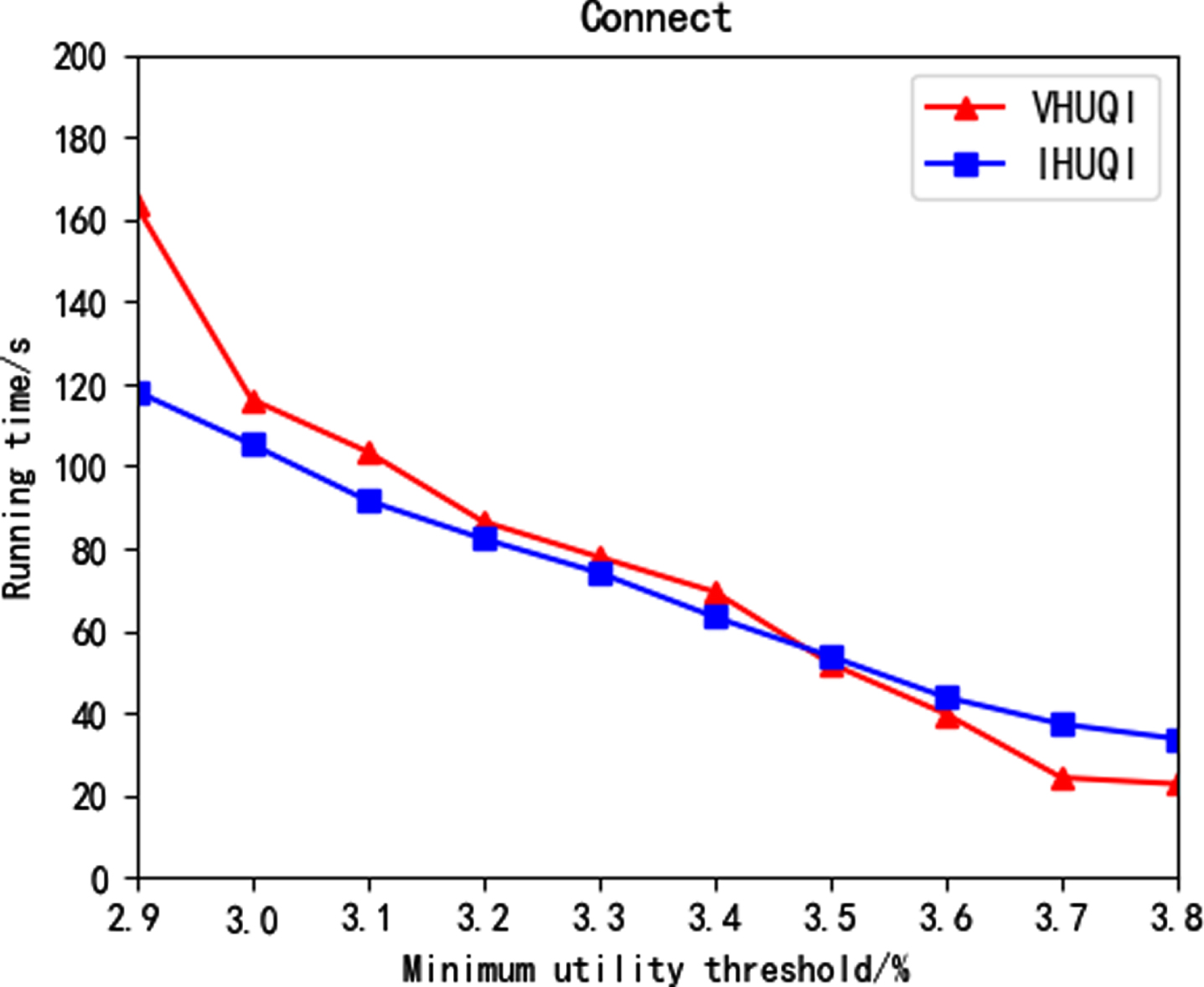
Running time on Connect.
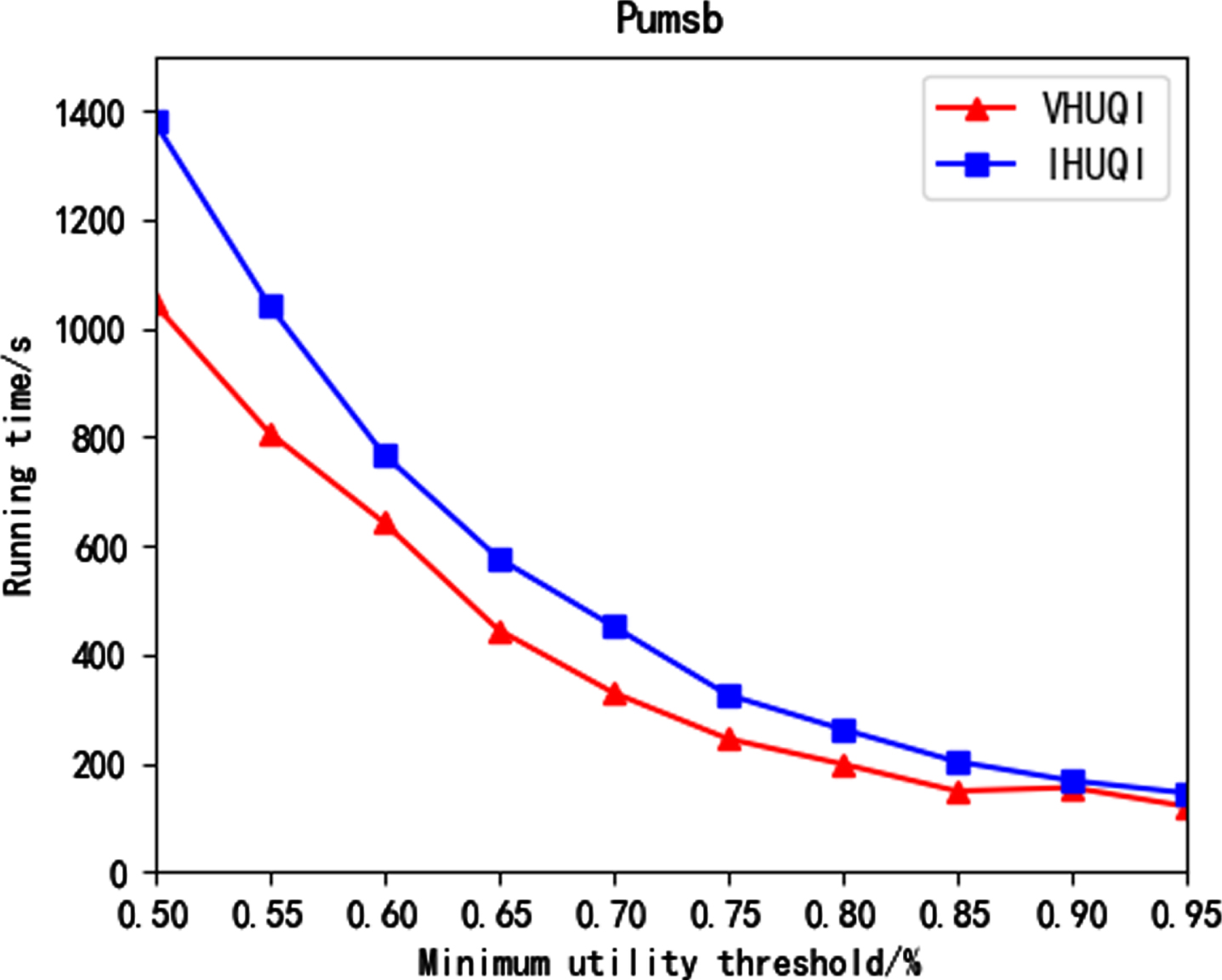
Running time on Pumsb.
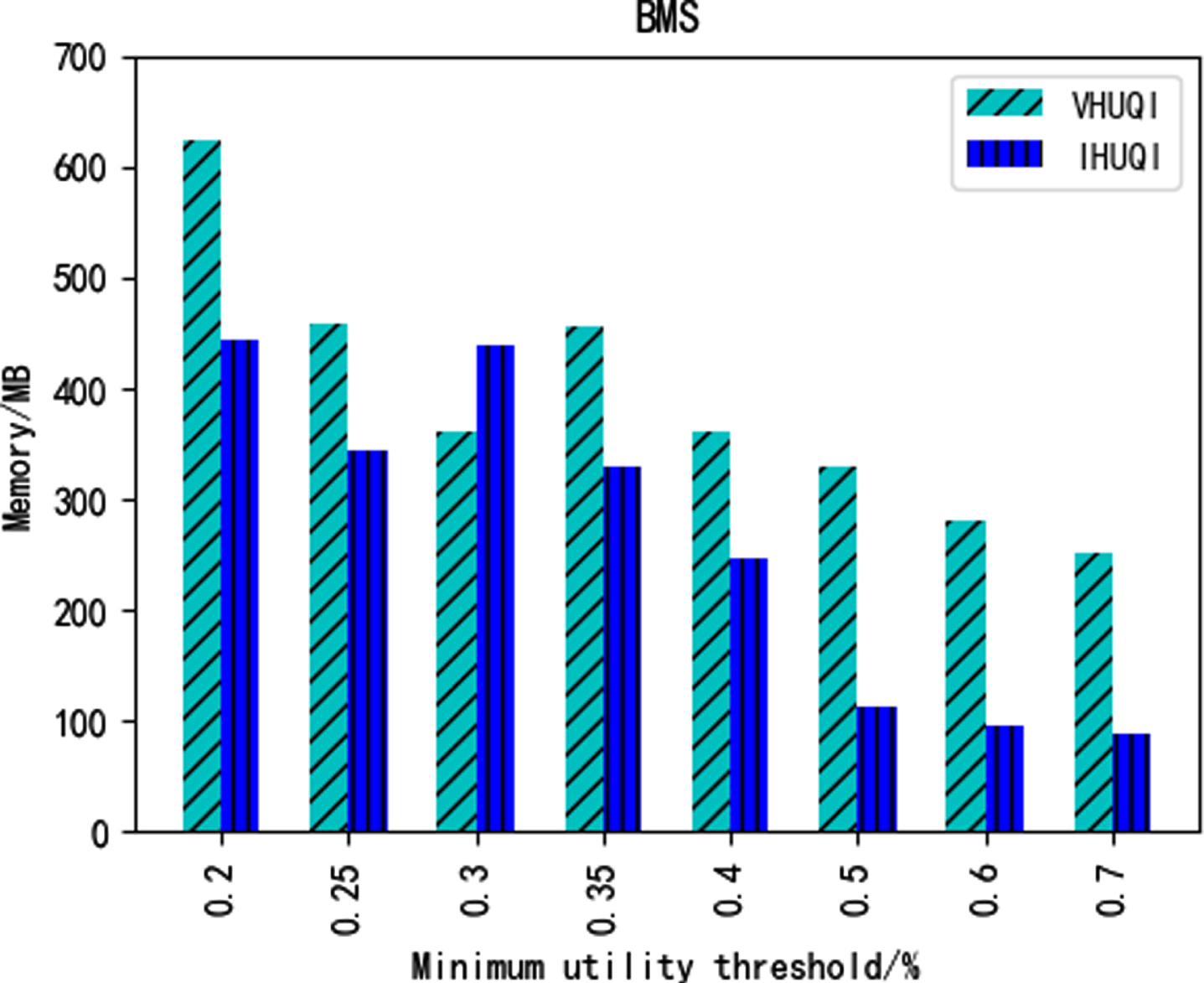
Memory consumption on BMS.
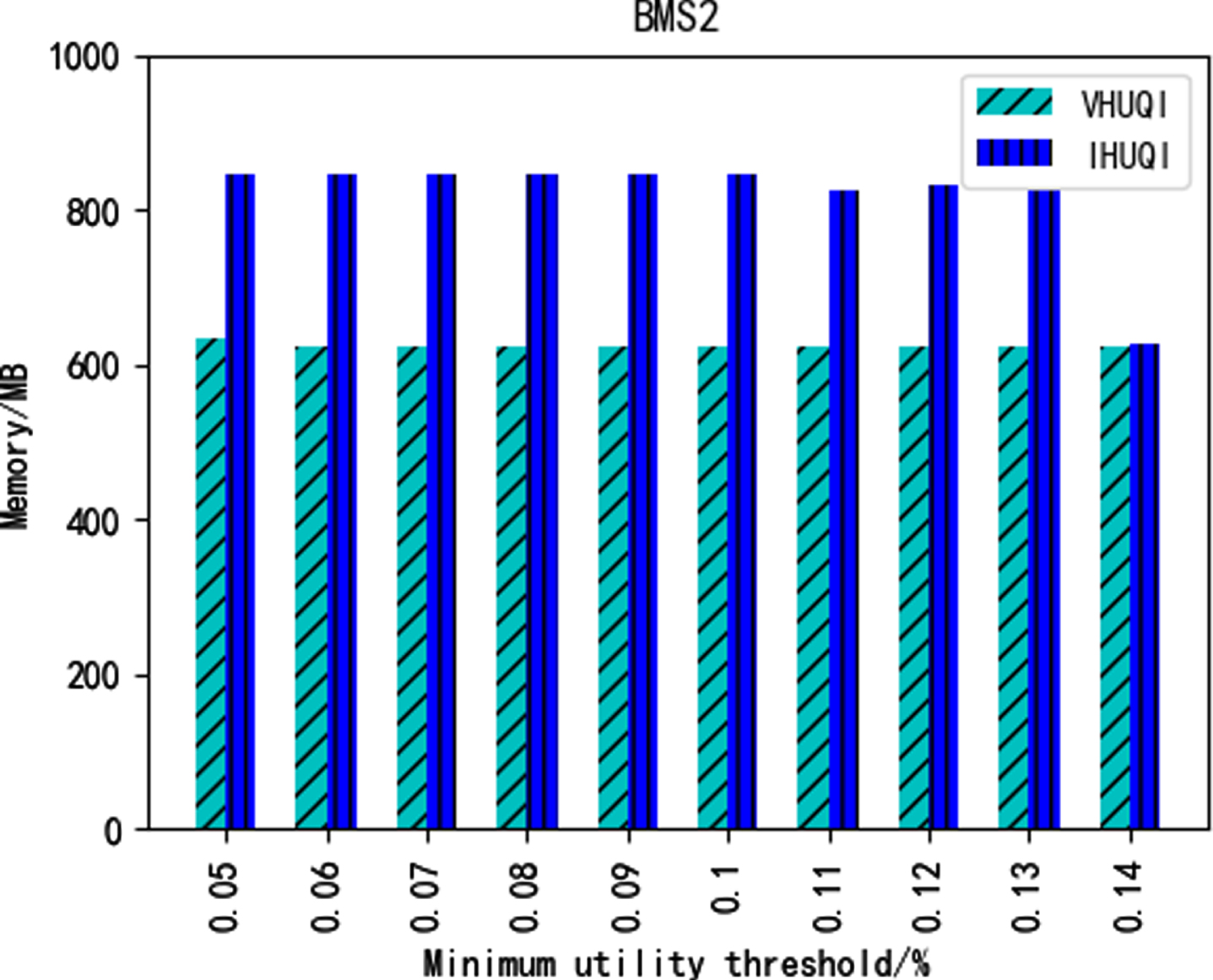
Memory consumption on BMS2.
Figures 12–16 show the comparison of memory consumption between the IHUQI algorithm and the comparison algorithm VHUQI algorithm as the minimum utility threshold increases. When the minimum utility threshold of the BMS dataset and Retail dataset is relatively small, the memory consumption of IHUQI is better than VHUQI. On the dense dataset Connect, the memory consumption of IHUQI algorithm is better than VHUQI. The memory consumption of the Pumsb dataset on the IHUQI algorithm is greater than VHUQI. The reason is that the IHUQI algorithm stores TQCS structures compare with VHUQI algorithm and increases the memory. In addition, the number of HUQI in the dense dataset is relatively large, but the different items are relatively small, resulting in a large number of candidates itemsets, and the pruning strategy used cannot effectively reduce the number of candidates itemsets.
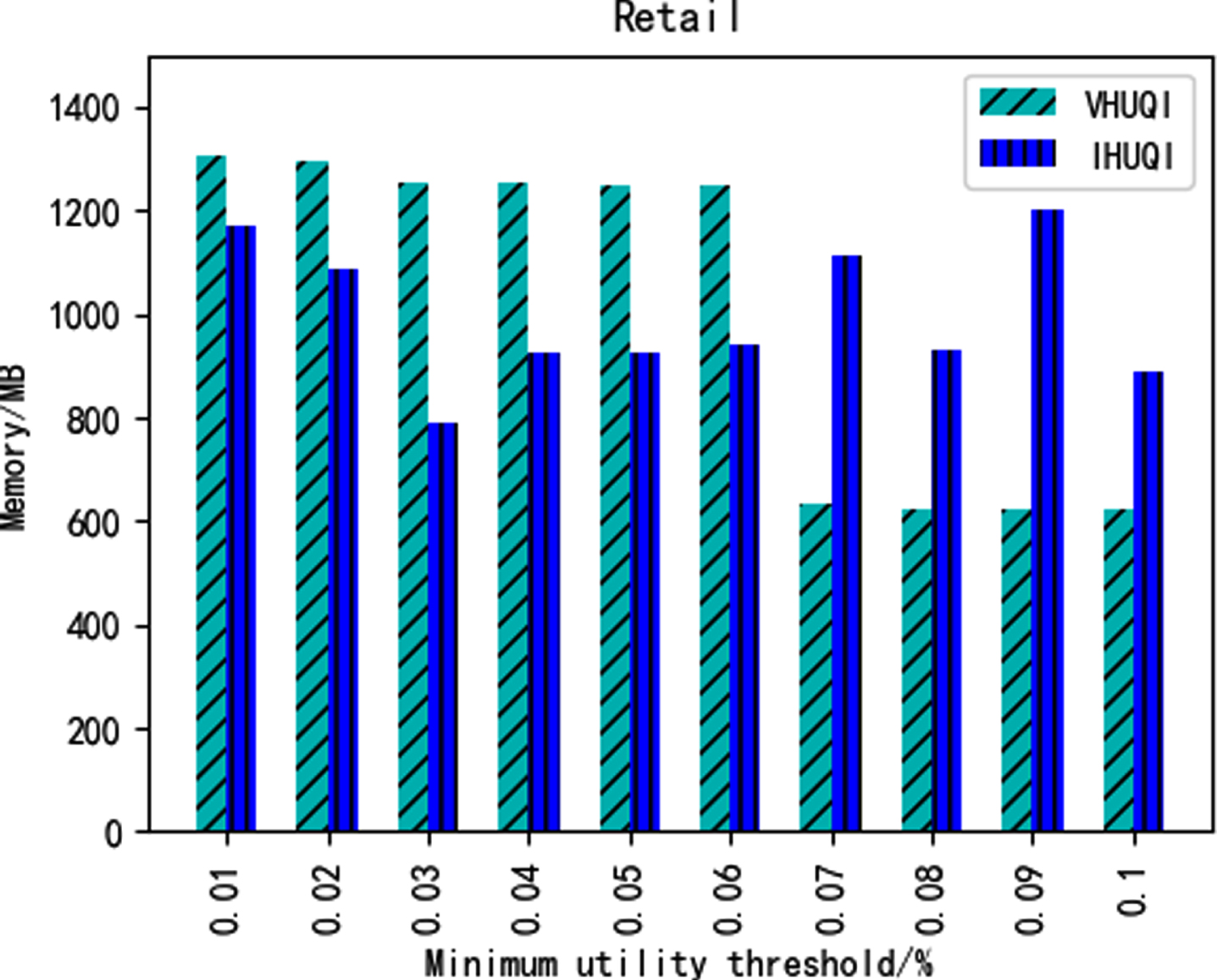
Memory consumption on Retail.
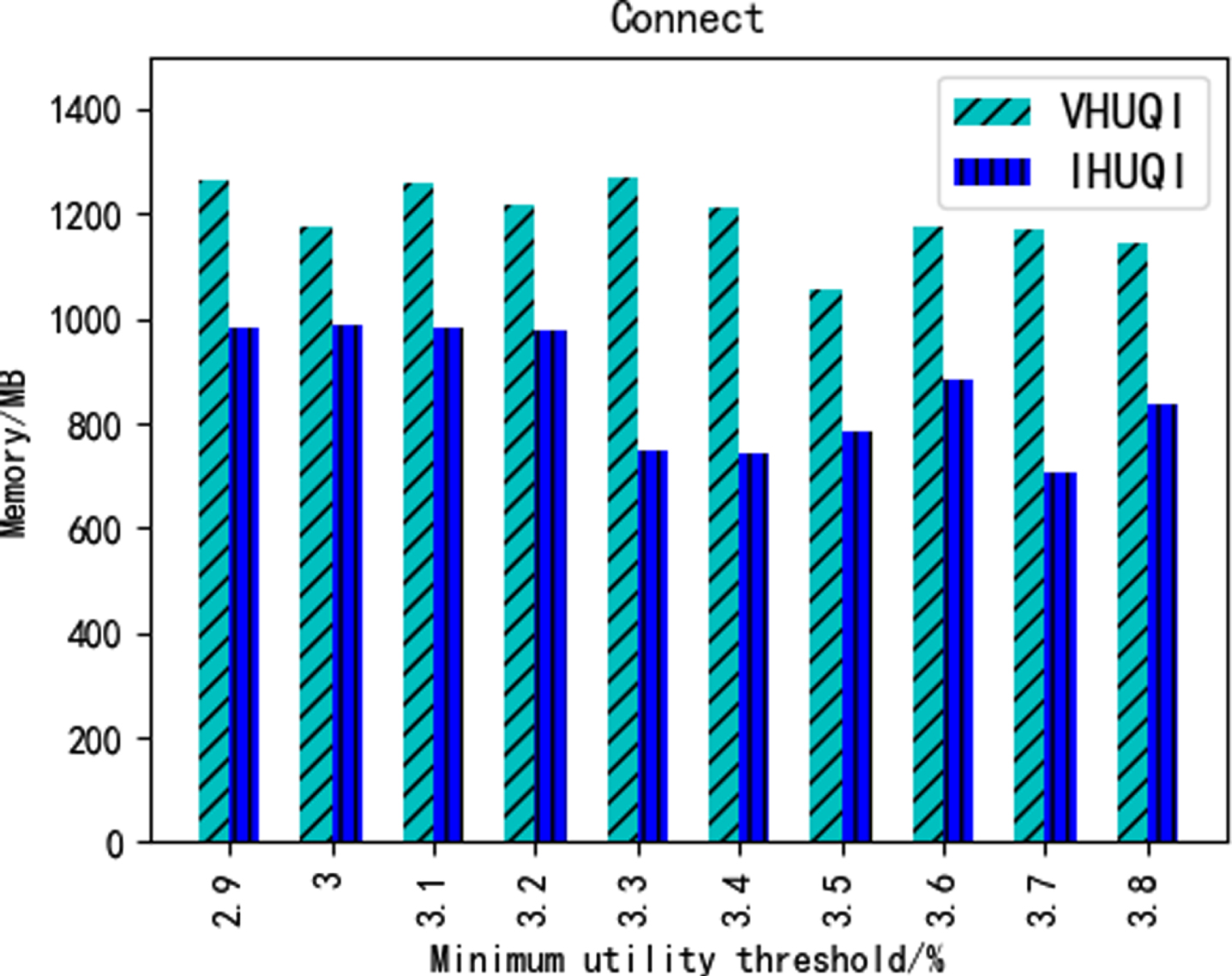
Memory consumption on Connect.
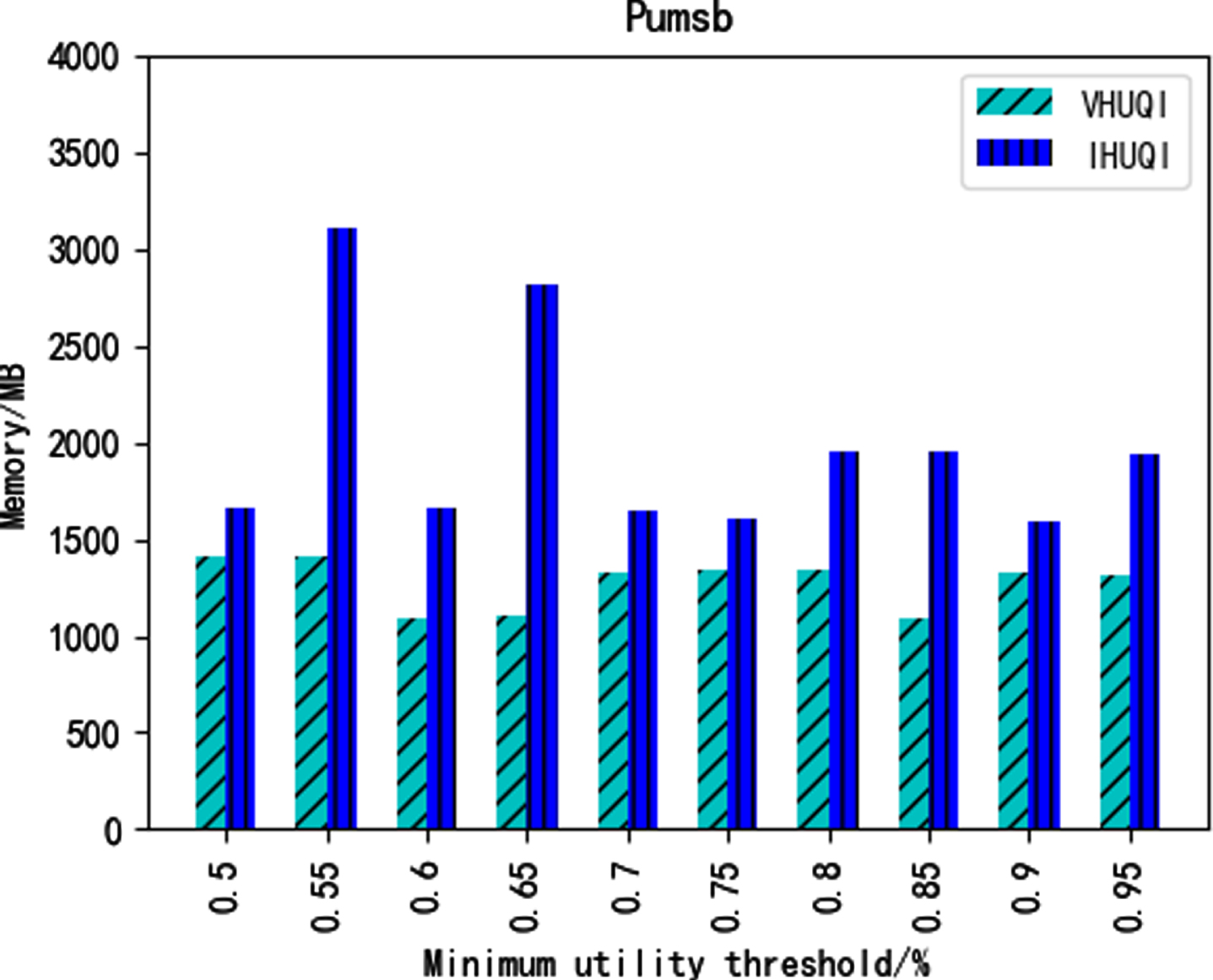
Memory consumption on Pumsb.
Mining HUQIs on incremental data needs to consider newly added transactions compared with mining HUQIs on static data, which is more complicated. The proposed IHUQI algorithm can mine HUQIs incrementally and has better results on sparse datasets.
This paper proposes an incremental updating HUQIM algorithm IHUQI, which uses IQUL to store utility information. When new data is inserted, it updates IQUL of the original item. If a new item appears, a new IQUL is constructed. A large number of experiments have been carried out to show that the proposed algorithm can effectively mine HUQIs on incremental data; as the size of the dataset increases, the running time gap between IHUQI and VHUQI increases; IHUQI performs better on sparse datasets.
Footnotes
Acknowledgments
This work was supported by the National Nature Science Foundation of China (62062004, 61862001), the Ningxia Natural Science Foundation Project (2020AAC03216).