
Abstract
Privacy-preserving utility itemset mining is the process of hiding sensitive-high utility itemsets (SHUIs) appearing in original database such that they will not be discovered in the sanitized database. The purpose of SHUI hiding algorithm is to conceal the set of SHUIs while minimizing the side effects which caused by data distortion process. In this paper, a novel algorithm, named EHSHUI (An Efficient Algorithm for Hiding Sensitive-high utility Itemsets), is proposed to minimize the side effects of the sanitization process. The proposed algorithm includes three heuristic steps: (1) The transaction on which the SHUI achieves maximal utility among transactions containing it is specified as victim transaction; (2) The item that causes minimal impacts on non-SHUIs is selected as victim item; and (3) An exactly number of utility is calculated for reducing internal utility of victim item from victim transaction. This strategy exactly identifies item and transaction for data modification such that it minimizes the impacts on non-SHUIs, data distortions, and the time to access database. The experiment results illustrate that the proposed algorithm achieves higher performance and lower side effects than the state-of-the-art.
Keywords
Introduction
With the development of the data storage technology and the use of internet applications, data mining becomes extremely important issue of computer science. Data mining techniques, especially pattern mining [4, 18, 25, 3, 5, 8, 12, 21] and association rule mining [1, 2, 16, 24], aim to discover useful knowledge implicit inside the database. Because of the popular application, the frequent itemset mining has been a classical problem of pattern mining and currently applied in many fields. Its purpose is to discover itemsets satisfied a given minimal support threshold from a given database. Although it has proven very useful in many applications, it is limited because the role of data items in database has not been considered [2]. The reality has proven that itemset mining becomes meaningful if the value of data items is concurrently discovered with their frequency. For example, in a sale database, in each transaction the quantity of each item sold is stored, and their profit is concerned.
In order to overcome the limitation of frequent itemset mining, a novel pattern mining method has been proposed to mine itemsets associated with their quantity and profits. It has been known as high utility itemset (HUI) mining. Yao et al. [26] proposed the novel approach to discover high utility itemsets. Many more efficient algorithms [25, 5, 8, 12, 21, 13, 6, 29, 20] based on the approach proposed in [26] have been published.
These days, sharing data provides mutual benefits for collaborating organizations but increases the risk of sensitive knowledge leakage. High utility itemset mining techniques have allowed regimented discovery of knowledge from huge databases. The knowledge for supporting the decision making is said to be sensitive knowledge, which can be referred from sensitive-high utility itemsets (SHUIs). However, sharing data for mining may cause the possibility of revealing sensitive knowledge [15, 9]. The need of privacy [7] prompted the growth of privacy-preserving high utility mining techniques. To deal with privacy concerns, SHUI hiding algorithm has been proposed to sanitize the original database in such a way that the sensitive knowledge are concealed. The aim of the algorithm is to modify data item in the specific transactions in order to reduce the utility of SHUIs to under minimal utility threshold. Therefore, SHUIs cannot be discovered from the sanitized database by unauthorized users at the same minimal utility threshold. This process usually cause the side effects, such as non-SHUIs lost by hiding process or similarity between original database and sanitized database, etc.
The target of SHUI hiding algorithm is to hide every SHUI with minimal side effects. The performance of SHUI hiding algorithm depends on the strategy for specifying victim transaction and victim item for data modification. Yeh et al. [27] were the first authors who proposed a methodology for hiding SHUIs including HHUIF (Hiding High Utility Item First) and MSICF (Maximum Sensitive Itemsets Conflict First) algorithms. The technique used in [27] is to reduce internal utility of a victim item from a victim transaction to decrease utility of SHUI under minimal utility threshold. Relying on this idea, more efficient algorithms [17, 10, 11, 19] were then proposed. In these algorithms, the authors proposed heuristic strategies to find victim item based on its utility. The item having higher utility amongst sensitive items was selected for modification. This strategy failed in evaluating exactly number of non-SHUIs and that would be lost by sanitization process. Thus, the specified victim item is not the best one for minimizing the side effects.
This paper proposed an heuristic algorithm for hiding SHUIs by exactly specifying victim transaction and victim item for data modification. The victim item was specified in such a way that it requires single modification at victim transaction and modifies that causes the least impacts to non-SHUIs. Two theorems were proposed to exactly compute minimal utility value needed to be reduced from victim item. The experiment results showed that the proposed algorithm is better than the previous algorithms proposed in [27, 11]. The remaining contents are organized as follows: Section 2 introduces the related works, Section 3 proposes hiding SHUIs algorithm named EHSHUI, Section 4 describes the experimental results, and the last section is conclusion.
Related works
High utility itemset mining
HUI mining algorithm aims at discovering itemsets having utility no less than a minimal utility threshold given by user with low CPU-time. The first HUI mining model was proposed by Yao et al. [26], the authors defined two units to measure utility level of itemset. They are internal utility (transaction utility) and external utility. Liu et al. proposed a HUI mining algrorithm including two phases [14]. In the first phase, the authors applied closure property named TWU (Transaction-Weighted-Utilization) to prune searching space when generating candidate itemsets. The second phase specified HUIs from candidate itemsets. Two-phase method was then improved in the better algorithms in [5, 22, 21]. However, the set of high TWU itemsets is greater than the set of high utility itemsets. Consequently, the large searching space caused high complexity of running time in the proposed algorithms.
To overcome the drawback, Liu et al. [12] proposed a new data structure named utility-list and HUI-Miner algorithm to mine HUIs without generating candidate itemsets. The experiment result showed that HUI-Miner algorithm was better than Two-phase algorithms. Using the same idea as HUI-Miner, Fournier-Viger et al. [6] proposed FHM algorithm. By analyzing the relationship of items which concurrently appeared in the same transactions, FHM restricted the join between utility-lists when calculating utility of itemsets. So, it required lower CPU-time than HUI-Miner algorithm.
Zida et al. [28] proposed EFIM (A Highly Efficient Algorithm for High-Utility Itemset Mining) algorithm. To prune searching space, the authors defined two upper bounds named sub-tree utility and local utility. In addition, a quick-caculation method, denoted by FUC (Fast Utility Counting), was applied to find upper bound of HUIs in linear time and space. Moreover, EFIM applies a projected database and transaction merging technique in order to minimize database scanning cost. The experiment indicated that EFIM was more efficient than previous algorithms.
In the remaining content of this section, we present the concerned concepts which were defined in [26, 13]:
.
(Transaction database): Let
Transaction dataset D
Transaction dataset D
External utility of transaction dataset D
For example,
.
(Item utility in a transaction): The utility of an item
For example,
.
(Itemset utility in a transaction): The utility of an itemset
For example,
.
(Itemset utility in database): The utility of an itemset
For example,
.
(High utility itemset): Given a minimum utility threshold
For example, Table 3 is a set of high utility itemsets mined from data set given in Tables 1 and 2 when setting the minimum utility threshold
The set HUIs mined from D with
.
(The utility of a transaction): The utility of a transaction
High utility itemsets discovered from a database are useful to the data owner. A high utility itemset can be used to support the decision making process is said to be a SHUI. In order to protect this sensitive information from being disclosed, the data owner has to preserve SHUIs from unauthorized miner when sharing data outside his/her company.
Hiding SHUI is a process that intercedes the internal utility value of some items in order to transfer an original database into a sanitized database in such a way that SHUIs are concealed from the sanitized database. Modifying database for hiding SHUIs causes side effects to HUIs and database. The algorithm causes lower side effects is the better one. Yeh et al. [27] defined three units to measure the performance of algorithms, including: Hiding Failure (HF); Missing Cost (MC) and Difference between the original and sanitized database (DIF).
The target of proposed algorithms is to hide SHUIs while minimizing the side effects. Yeh et al. [27] were the first authors who proposed heuristic algorithms for hiding SHUIs named HHUIF and MSICF. The main idea of both algorithms is to minimize side effects basing on selecting an appropriate victim item for database modification. The victim item specified by HHUIF is an item which has maximal utility among sensitive items in a SHUI while the victim item selected by MSICF is an item which has maximal frequency among sensitive items of all SHUIs. Although the proposed algorithms [27] achieve a good result in hiding SHUIs with low HF, they cause high MC and DIF because they do not specify exactly minimal utility value which need to be reduced for hiding SHUI. This leads to the case that a SHUI has already been hidden but data modification has been still continuing. Moreover, if utility of a SHUI is equal to minimal utility threshold then it cannot be hidden by algorithms. Selvaraj et al. [17] proposed an improvement named MHIS (Modified HHUIF algorithm with Item Selector). In case of existing more than one maximal-utility item in SHUI, MHIS gives priority to modify the item having higher frequency.
A novel method which hides SHUIs by adding pseudo transactions into database was proposed by Lin et al. [10]. The authors applied GA methodology to compute exactly number of additional transactions and set of items in each transaction. The experiment shows that it is more efficient than previous methods. However, this method creates new HUIs (ghost HUIs, the itemsets are non-HUIs in original database but are HUIs in the distorted database).
In 2016, Lin et al. [11] proposed two heuristic algorithms, including: MSU-MAU (Maximum Sensitive Utility-Maximum item Utility) and MSU-MIU (Maximum Sensitive Utility-Minimum item Utility). MSU-MAU assigns victim transaction to the transaction in which the SHUI achieves maximal utility and victim item to the item having maximal utility amongst sensitive items. MSU-MIU selects victim transaction as the same as MSU-MAU, but it assigns victim item to the item having minimal utility among sensitive items. Experiment results indicate that these algorithms achieve better performance than algorithms proposed in [27]. However, the drawback of algorithm proposed in [27] has not been solved by MSU-MAU and MSU-MIU.
In order to exactly measure the difference of database after sanitizing data, Lin et al. [11] defined three measuring units, including: Database structure similarity (DSS), Database utility similarity (DUS) and Itemsets utility similarity (IUS). These units are very important for evaluating transparency of sanitized database in comparison to the original database.
Given a database and a minimal utility threshold, the definitions about side effects for hiding SHUI algorithms which were proposed in [27, 11] are re-presented as follows:
.
(HF – Hiding Failure): Hiding Failure of a hiding SHUI algorithm is the ratio between SHUIs’ in sanitized database and SHUIs in original database, namely:
Because of database sanitization, some of non-sensitive high utility itemsets in the original database cannot be discovered from sanitized database. This effect is said to be missed cost and defined as Definition 8.
.
(MC – Missing Cost): Missing cost of a hiding SHUI algorithm is the level of non-sensitive high utility itemsets in the original database is mishidden by hiding process, and is defined as follows:
Let
.
(DSS – Database structure similarity): Database structure similarity is the difference about structure similarity of original database D and sanitized database D’, and is defined as follows:
.
(DUS – Database utility similarity): Database utility similarity is the utility similarity ratio between sanitized database and original database, and is defined as follows:
Where,
.
(IUS – Itemsets utility similarity): Itemsets utility similarity is similarity ratio between HUIs in sanitized database and HUIs in original database and is defined as follows:
Algorithm proposal
Sensitive-high utility itemset hiding strategy
.
(Sensitive high utility itemset): Let
We have
A sensitive high utility itemset
Let
.
(Victim item): The victim item, denoted by
.
(Victim transaction): The victim transaction, denoted by
The hiding process includes three steps: (1) Victim transaction specification:
There are two cases occurred at step (3): If
.
If
Let dec is a minimal internal utility of
.
If
Let
Specifying exactly SHUI for the first hiding contributes to reduce the side effects of hiding SHUI algorithm. In this paper, we give a priority to a SHUI which has maximal frequency amongs itemsets in SHUIs.
The frequency of a sensitive HUI
.
The frequency of
EHSHUI algorithm includes three main stages: Firstly, the algorithm specifies victim transaction containing SHUI Si where
FindVictimTransactionInputinputOutputoutput DSi: project database;
Algorithm 1: Scans for each transaction in DSi to find a transaction
FindVictimItemInputinputOutputoutput
Algorithm 2: If
If Otherwise, when
EHSHUI (Hiding sensitive-high utility itemsets)InputinputOutputoutput D: original database; HUIs: high utility itemsets; SHUIs: sensitive high utility itemsets;
Algorithm 3: First, the algorithm computes frequency of every SHUI:
At the next steps, the algorithm scans consequently
To generate a projection of database (DSi) including transactions which contains To specify difference utility ( While
To reduce internal utility of To remove
The EHSHUI algorithm is finished when every SHUI is hidden.
Experiment data and system description
The data sets description
The data sets description
The EHSSUI algorithm was executed with four databases, including:
One randomly generated databases: T1000_200_40 (The data is randomly generated by a Java program we build). Three real databases: retail, foodmart, and mushroom. They were published and available in [23]. These databases have been popular used for experiment of pattern mining and privacy preserving in pattern mining. The detail of databases is presented in Table 4.
System: CPU Core I5 2.4 GHz, RAM 8 GB, Windows 10.
Sets of sensitive-high itemsets: For each database, SHUIs are randomly selected from the set HUIs mined by FHM algorithm [6].
Miss cost with various sensitive itemsets.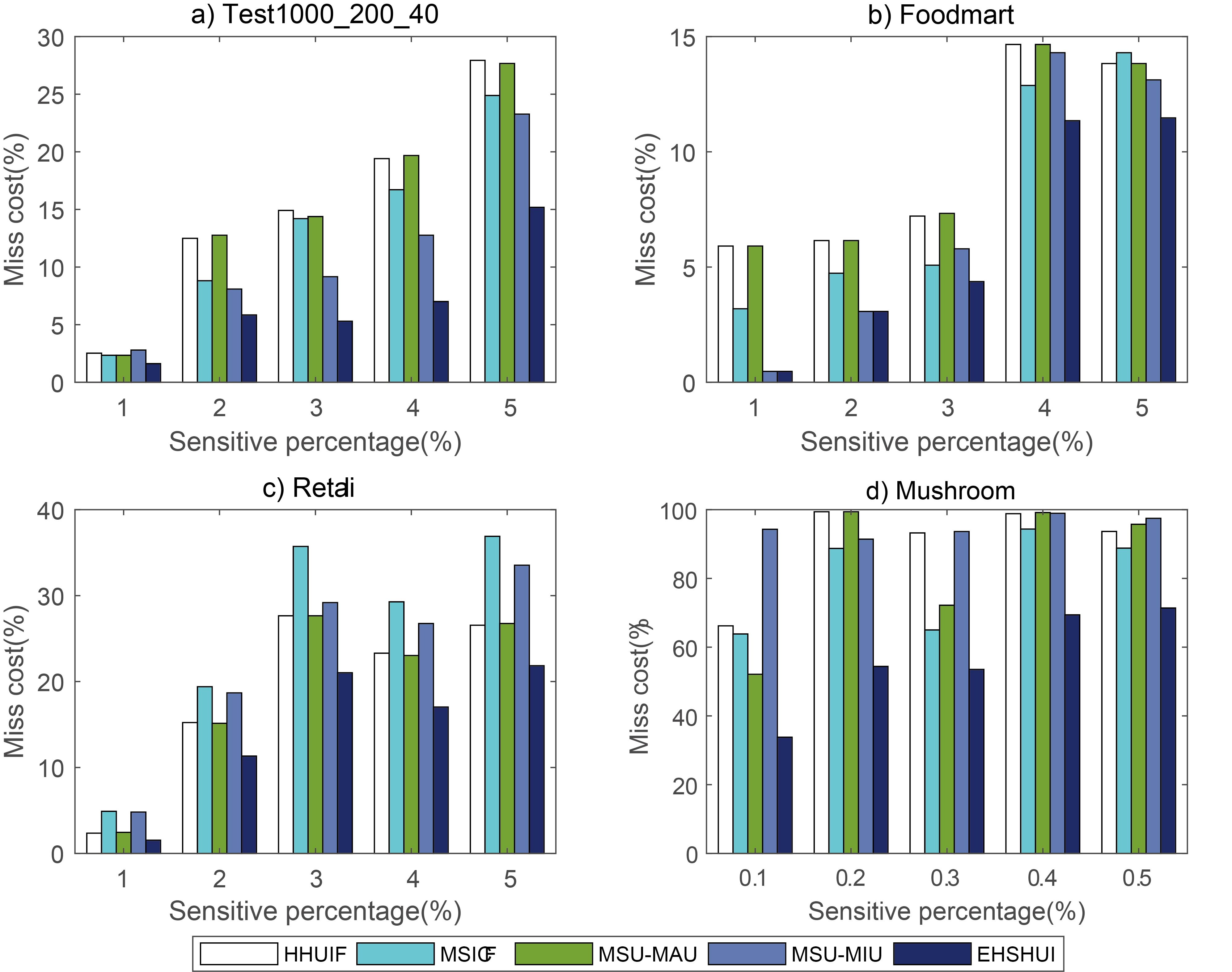
Runtime under various sensitive itemsets.
DSS under various sensitive itemsets.
DUS under various sensitive itemsets.
IUS under various sensitive itemsets.
The EHSHUI algorithm is compared to four previous algorithms including HHUIF, MSICF, MSU-MAU, and MSU-MIU proposed in [27, 11]. The results are demonstrated as follows:
Mising cost: Figure 1 depicts the miss cost was caused by hiding process. The experiment results indicates that EHSHUI achieves lower MC in comparison to HHUIF, MSICF, MSU-MAU, and MSU-MIU. This is because EHSHUI calculates exactly the minimal internal utility value for modifying victim item in victim transaction. The EHSHUI algorithm, therefore, overcomes the drawbacks of [27, 11] indicated in the related works. Run time: The results in Fig. 2 show that run time for experiment of EHSHUI, MSU-MAU, and MSU-MIU are much lower in comparision to HHUIF and MSCIF because EHSHUI, MSU-MAU, and MSU-MIU use project database to reduce database-scanning time when specifying victim transaction and victim item. Run time of EHSHUI is equal to or slightly higher than runtime of MSU-MAU and MSU-MIU because EHSHUI needs more time to evaluate minimal MC when comparing side effects amongs sensitive item modifications (this depends on the size of HUIs). Database structure similarity: In Fig. 3, the database structure similarity of EHSHUI in comparision to HHUIF, MSCIF, MSU-MAU, and MSU-MIU were plotted against the percent of SHUIs for the databases. From Fig. 3, it is obvious to see that EHSHUI causes less data distortion than the others. With increasing percent of SHUIs from 1% to 5% in Fig. 3, EHSHUI achieves DSS higher than the other algorithms. Database utility similarity: The results in Fig. 4 show that percent of utility similarity between sanitized database and original database caused by EHSHUI is higher than by HHUIF, MSCIF, MSU-MAU, and MSU-MIU. This indicates that EHSHUI is better than the others in minimizing DUS side effect for every experimental database Itemsets utility similarity: Itemset utility similarity between original database and sanitized database indicates the truthfulness of database. This means the algorithm creates higher IUS is the better one. The experiment result in Fig. 5 illustrates that IUS created by EHSHUI is more higher than other algorithms for every database and percent of SHUIs. The reason why EHSHUI achieved this result because it specifies exactly victim transaction and victim item.
Privacy-preserving data mining has raised its importance in today’s information analysis-based research and marketing. The aim of privacy-preserving HUI mining is to conceal some SHUI with an intention that it cannot be revealed with any HUI mining algorithm. The main idea of SHUI hiding algorithm is to hide every SHUI with lowest impacts on the number of HUI and to keep the quality of data intact. This paper proposes an heuristic algorithm for hiding SHUI named EHSHUI based on three heuristic steps. In the first step, the transaction on which SHUI
The finding from this study rise in the form of improving quality of collaboration between companies. First, hiding all of SHUIs guarantees the safe for sharing data without disclosing sensitive knowledge. Moreover, the higher quality of sanitized database motivate companies to share data and discover worthy knowledge from collaborated database.
The limitation should be pointed out which could also be addressed in future research. The running time of the proposed algorithm increases with the growth of HUIs. The reason is the time consuming by computation to specify number of impacted non-SHUIs for every sensitive items in the second step. Therefore, an improvement of the proposed algorithm should be recommended in the next work.