
Abstract
Falls particularly among the older population has always been a matter of concern. With the steady rise of small families, the elderly is very often left alone at home. Dedicated nurses or caretakers are quite expensive. Thus, intelligent monitoring systems with automatic fall detection systems installed at home or nursing homes could be a game changer in such applications. In this paper, a simple yet effective fall detection system based on computer vision. Novelty of this paper is that it uses the Yolo v2 network on the depth videos for extracting the subject from cluttered background. The robust performance of the YOLOv2 network ensures accurate subject detection and removes the need for any complicated fall detection algorithm. Fall detection is carried out using subject’s height to width ratio and fall velocity. These parameters are simple and easy to calculate and yet provide effective results. The input data is captured using the Orbbec Astra 3D camera.
Introduction
One of the common issues among the elderly population is Fall. Often it leads to serious injuries and falls could also be due to some serious health issues like heart attack, blood pressure fluctuation etc. If the falls are not responded to quickly, it may even lead to death. Unintentional injuries due to fall causes the seventh most common causes of death among this category of population. Each year around 800000 patients are taken to hospitalization because of an injury caused by fall. And it is seen that one among five falls causes major injury like a broken bone or head injury [1, 2]. How long a person is fallen on ground is also important. It is always essential that the fallen person is attended to as soon as possible. The elderly has often greater chances of falling and since they are usually left alone at home a monitoring system that has automatic fall detection alarm would be of immense help in reducing fall related risks and reduce the cost of employing personal caregivers and nurses. Several researchers have explored various methods of fall detection. A concise survey on vision-based fall detection systems has been carried out in [3] covering the period from 2015 to 2019. In [4] the authors have discussed the various fall detection methods between the periods from 2005 to 2014. In [5, 6] it is reported that detection of fall and alarm system may be categorized into three categories: (i) sensor-based wearables, (ii) ambient sensor-based (iii) computer vision-based methods. Accelerometer sensors are used in sensor-based methods which are attached to the body of the subject [7, 8]. However, they are not always convenient to use as the subject may not be comfortable wearing them always. In case of ambient sensor-based systems, external sensors are embedded. Common sensors used are pressure, acoustic and electromyography sensors [9–11]. Accuracy of these systems are less and have higher false detection rates.
Computer vision [3] has grown in leaps and bounds over the years and consequently vision-based fall detection system have gained popularity. These methods work quietly in the background without disturbing the subject whatsoever and are very useful especially for the elderly left alone at home. Accuracy of vision-based devices in differentiating between falls and no fall situation is quite remarkable. They are a bit expensive to set up, but their reliability is much more than other methods. These approaches usually use RGB cameras. It is an established fact that depth images provide better performance than the RGB images because depth information is independent of the lighting conditions and provide the relative distance of the surfaces of scene objects from the sensor [3]
A lot of work has been done using the Microsoft Kinect sensor [12–15] but it is believed that it will go off the shelf soon, hence in this work, we decided to use the Orbbec Astra 3D Pro depth camera which is an alternative to the Microsoft Kinect. With the recent development of convolutional neural networks and deep neural network architectures, the detection results have improved dramatically with high-level feature extraction [16]. As reported in [18] deep learning has been used for an automatic logo detection where small patch of logos is used for training.
The human aspect ratio computation stated in [17] provides robust output but their algorithm works on RGB videos. The problem of appearance deformation occurs in fall detection since 2D grey, or color images are actually the projection of 3D targets. In order to deal with the problem, a fall detection meth-od based on analyzing the shape in depth images captured by the Orbbec Astra Pro camera is pro-posed in this paper. Also, depth cameras can be used within the personal space as it does not intrude privacy and hence can be used to monitor the places like bathrooms with highest probability of fall due to slippery floors. The authors in [12] uses only the velocity parameter for fall detection and has reported an accuracy of 93.94%. In [13] the authors used background subtraction method for subject detection and centroid of human body for fall detection.
In this paper we have incorporated human aspect ratio computation with the velocity parameter and obtained 100% accuracy. In [14] the authors per-formed fall detection considering only the height of the subject so had more false positives as the velocity was not considered. There are several object detection and background removal methods like SSD, R-CNN, fast R-CNN and YOLO. As a proposed method we have used the YOLO v2 algorithm for subject detection which is more robust in performance in comparison to background subtraction with the processing time per frame being less than a second. Also, YOLO is faster and more suitable for real time applications [19]. We have considered both the human aspect ratio and the velocity of the subject. The ratio of height over width of the human body along with the velocity of the fall is used to detect fall and no fall situation. Object detection is carried out to identify the human body. The detected subject is closely circumscribed by a rectangular box. The dimensions of the box will provide the height and width information of the subject approximately. If the subject is in upright position, and the height of bounding box is greater than that its width, then the ratio of height to width will be greater than one. When the subject falls, the width of the box is greater than that of its height, and the height to width ratio is less than one. The rate of change of the subject’s height to width ratio gives the velocity of the fall.
The depth data is used in the following ways: 1) the data is pre-processed, and frame extraction carried out. 2) The features are extracted from the depth data. 3) It is then fed to YOLOv2 object detector which detects the subject. 4) Upon the detection of subject, the height to width ratio of subjects bounding box (body ratio) and rate of change of height of the subject with respect to the origin (fall velocity) is calculated [20]. When the fall velocity exceeds a pre-determined threshold, and the body ratio becomes less than the predetermined threshold and remains so for minimum 30 frames then the system generates a fall detection alert.
In section 2 the proposed method has been discussed in detail. The results have been discussed in section 3 and section 4 includes conclusion and future scope.
Proposed method
Here a detailed discussion of fall detection is elaborated. Figure 1 shows the basic steps that have been followed. The human aspect ratio and velocity computation as proposed by [17] due to the simplicity and effectiveness of these parameters has been used. However, we have computed these parameters on the depth image data rather than RGB data. Also, instead of using background subtraction for subject detection we have used deep learning using the YOLOv2 network. We have used YOLO v2 for subject detection which provides superior results even in cluttered background.
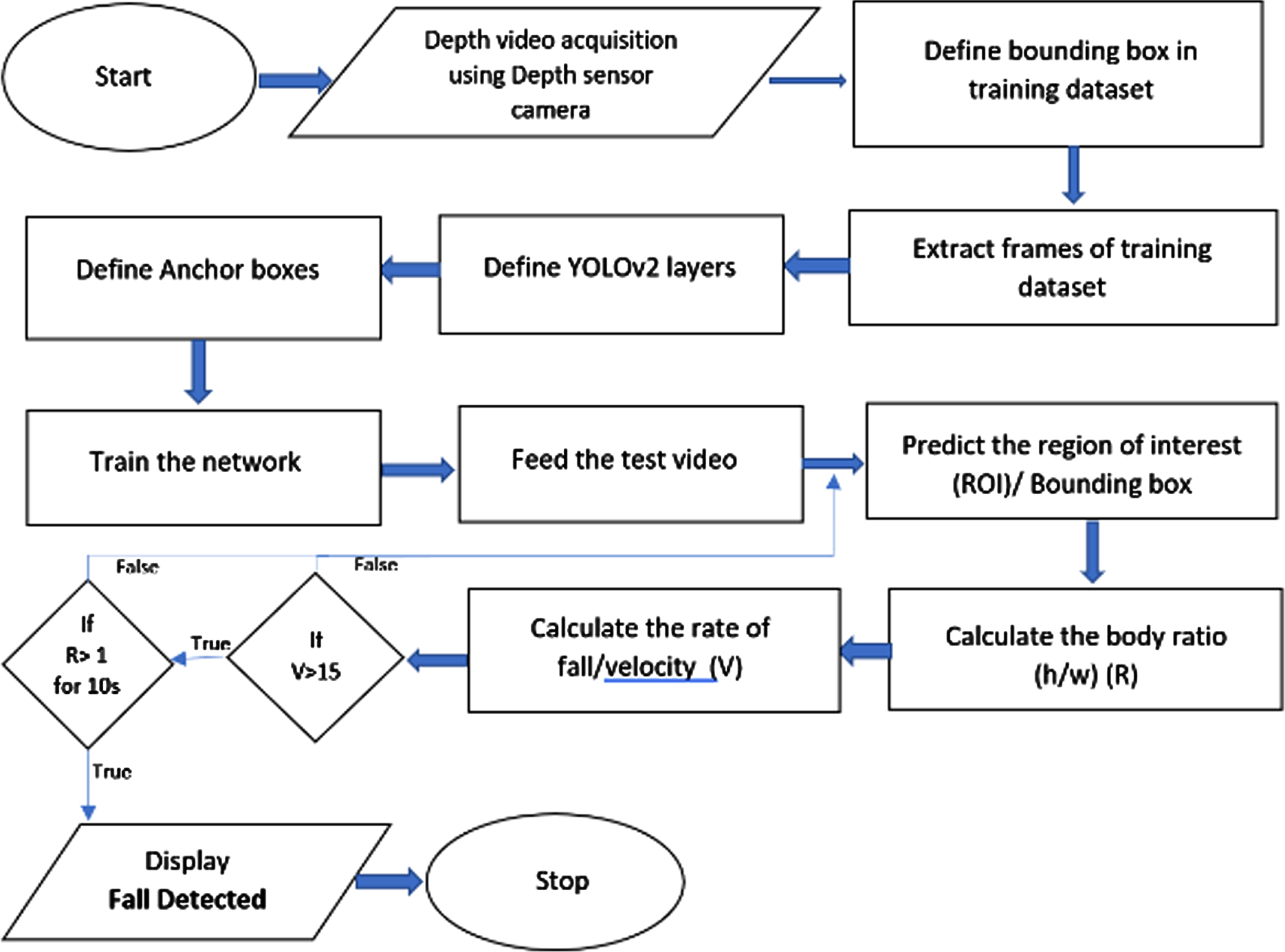
Steps followed in the proposed method.
– The camera used for data acquisition is Orbbec Astra Pro 3D camera. The Orbbec Astra has a depth sensor that provides depth videos of the scene. A 3 min long video has been recorded with a frame rate of 30 frames per second, doing various activities like walking, and sitting, bending, picking up objects and also falling. The video has been recorded in plain as well as cluttered background. Separate videos have been recorded for testing purpose. Some snapshots of the recorded videos have been showed in Fig. 2 below.

Snapshots of depth videos recorded for testing using the Orbbec Astra 3D depth camera.
The training and testing videos are processed for frame extraction and resized to 416*416*1. In the training dataset, bounding boxes are defined. It gives the knowledge of the subject. The bounding box contains information of centroid (x, y), width of the box and height of the box with respect to left bottom corner as origin. The location and bounding box information of the frames are fed to the YOLOv2 network for training. Followed by frame extraction. The layers of Yolo v2 network and anchor boxes are defined. In the testing videos, only frame extraction is done. It is then fed to the YOLOv2 network which predicts the bounding box.
Subject detection
The model used for detecting the subject is YOLOv2 (You Only Look Once), which is a very fast algorithm for detection and runs a deep learning Convolution Neural Network on the input image. Further producing the predicted output and generate the bounding box. YOLO is an open-source method of object detection. It is efficient in detecting objects in video and image. Single Shot Detector (SSD) is yet another method popularly used for object detection which also uses a convolutional network. Though SSD is more exact, but YOLO is faster and more accurate for small size objects [20]. Hence the YOLO method is selected for our work.
The YOLO method uses a combination of the Convolutional Neural network (CNN) layers, Batch normalization layers, ReLU layers and Maxpooling layers. The Convolutional layers are the major building blocks of the YOLO v2 network. The Convolution Neural Network is a Deep Learning process that allots weight and bias to objects in an input image and then distinguishes between them. It requires lesser preprocessing compared to other classification [23].
Appropriate filters help to extract features from the image like its edges. The first convolutional layer extracts low level features and as the layers are added the network adapts to extraction of high-level features.
In YOLO V3 boxes with height and width kept fixed, called the anchor boxes are used. Accuracy of object detection and speed of object detection will be affected by the choice of the initial anchor boxes. K-means clustering is basically used for finding good priors automatically from a dataset. The cluster rep-resents the sample distribution in each dataset that enables the network to get good predictions [20, 22].
The objective function of clustering is given by [24]:
‘box’ represents the sample or ground truth of the target, ‘centroid’ is the center of the cluster. nk is the numbers of samples in the kth cluster center. Total number of samples being ‘k’. The number of clusters being ‘n’ and the IOU box centroid (), is the intersection over Union of the clusters and the sample. The YOLO V3 evenly divides the clusters across scales and an appropriate scale for each anchor box is selected.
Batch normalization layer processes the inputs to a layer for each mini batch. The learning process is stabilized causing a reduction in the number of training epochs which is required to train the deep networks. The Rectified Linear Unit, or ReLU is the rectifier function used to increase the non-linearity in the images.
The Pooling layer helps to decrease the size of the convoluted layer. Reduction in dimensions will decrease the requirement of computational power. Also, it is useful for extraction of the dominant feature. These features are rotational and positional invariant which maintains the process of training of the model in an efficient manner.
Also, the pooling operation involves sliding a two-dimensional filter over each channel of feature map and summarizing the features lying within the region covered by the filter. The dimension of output obtained after a pooling layer for a feature map comprising of the dimensions nh x nw x nc, is:
n h = height of featue map
n w = width of featue map
n c = no . of channel in featue map
f = size of filter
s = stride length
The maximum element is selected in Max which the filter covers in the region of feature map. Hence after the max-pooling layer, there is an output which is a feature map that contains the most prominent feature from the earlier feature map. This layer also helps in noise reduction.
It divides the image in 13*13 matrix. The image is convoluted with anchor boxes. These anchor boxes predict the offsets and confidences of the detected subject. YOLO works well in multiple object detection with the help of these anchor boxes. Each object is associated with one grid cell. But if there is an overlap and one grid cell contains the center points of two different objects, anchor boxes help as they can be defined to have a longer grid cell vector and associate multiple classes with each grid cell. They have a defined aspect ratio, and they detect objects that nicely fit into a box with that ratio.
A box with greater confidence is retained while the rest is discarded. Figure 3. shows the generalized Yolo v2 network structure.

Yolo v2 detection network.
The designed network in this system, comprises of 25 layers. Complete details of the layers used have been shown in Fig. 4.

Layers of Yolo v2 network used.
The layers used in Yolo v2 are the combination of convolution layers, batch normalization layers, Relu layers and maxpool layers. The convolution layers are the major building blocks of the network. It primarily convolutes the image segments with the anchor boxes. Batch normalization layer processes the inputs to a layer for each mini batch. It stabilizes the learning process and reduces the number of training epochs required to train deep networks. The Rectified Linear Unit (ReLU) is the rectifier function needed to increase the non-linearity in our images. Maxpool layer reduces the spatial dimension of the input volume for next layers.
The parameters contained by a bounding box provided by the Yolo v2 network are the box height, box width and centroid. Using this data, we calculate the height to width ratio of the subject in the bounding box. When a person is in standing position, height is always greater than width. Hence, the calculated height to width ratio will be greater than 1. And in lying down position, the width is greater than the height. So, the ratio must be less than 1. Thus, the human aspect ratio will be an effective parameter that will help in detecting falls as stated in [17]
In [17] authors also calculated the ratio of effective area and rate of center of variation for detection of fall. The center variation rate equation was modified by us to compute the velocity of fall given by Equation 2. In our work the effective area ratio was not used as the human aspect ratio along with the velocity of fall gave satisfactory results. By calculating the rate of change of height of the subject per frame, we can estimate the velocity of the fall.
Where, height at frame (i-t) is the height of the subject from the origin, t is a constant which will decide the frame spacing, height at frame (i) is the height at the current frame from the origin. The velocity of fall will ensure that there is no false detection of fall when the subject bends down slowly to pick up some object or for any other reason. Falls are generally abrupt or sudden so the velocity of fall will be high when a person actually falls. The detection of fall is done when the thresholds are crossed. When the body ratio value is less than 1 for 300 frames and the rate of fall (velocity) exceeds a predetermined threshold then, the proposed system shows fall detected. The value of threshold for the rate of fall is fixed at 15 by trial-and-error approach. Since the videos have been recorded with frame rate of 30fps, to maintain a fallen down state of at least 10 s before the fall detection alarm is triggered, we have set the body ratio value to less than 1 for 300 frames. The number of frames could be changed from 300 to any other value depending on the fps of the video recorder.
Shows the results obtained on testing videos using the proposed system
The processor used for the experimental set up has the given configuration: Intel(R) Core™ i5- 7200U CPU @2.5 GHz, 2712 MHz, 2 cores, 4 logical processors, 8GB RAM. Time required for training the system was 19 hrs but the training was a onetime procedure. The proposed system has been tested on falls and other activities like sitting, lying, bending etc. which is done on a daily basis. From the experiments conducted the system has been able to accurately detect falls and distinguish between the fall and non-fall scenarios. Like when a person bends down from standing position or sitting to pick something up was not detected as a fall by the system. A snapshot of the training process is provided in Fig. 5. The test results were however obtained at instantaneous time.
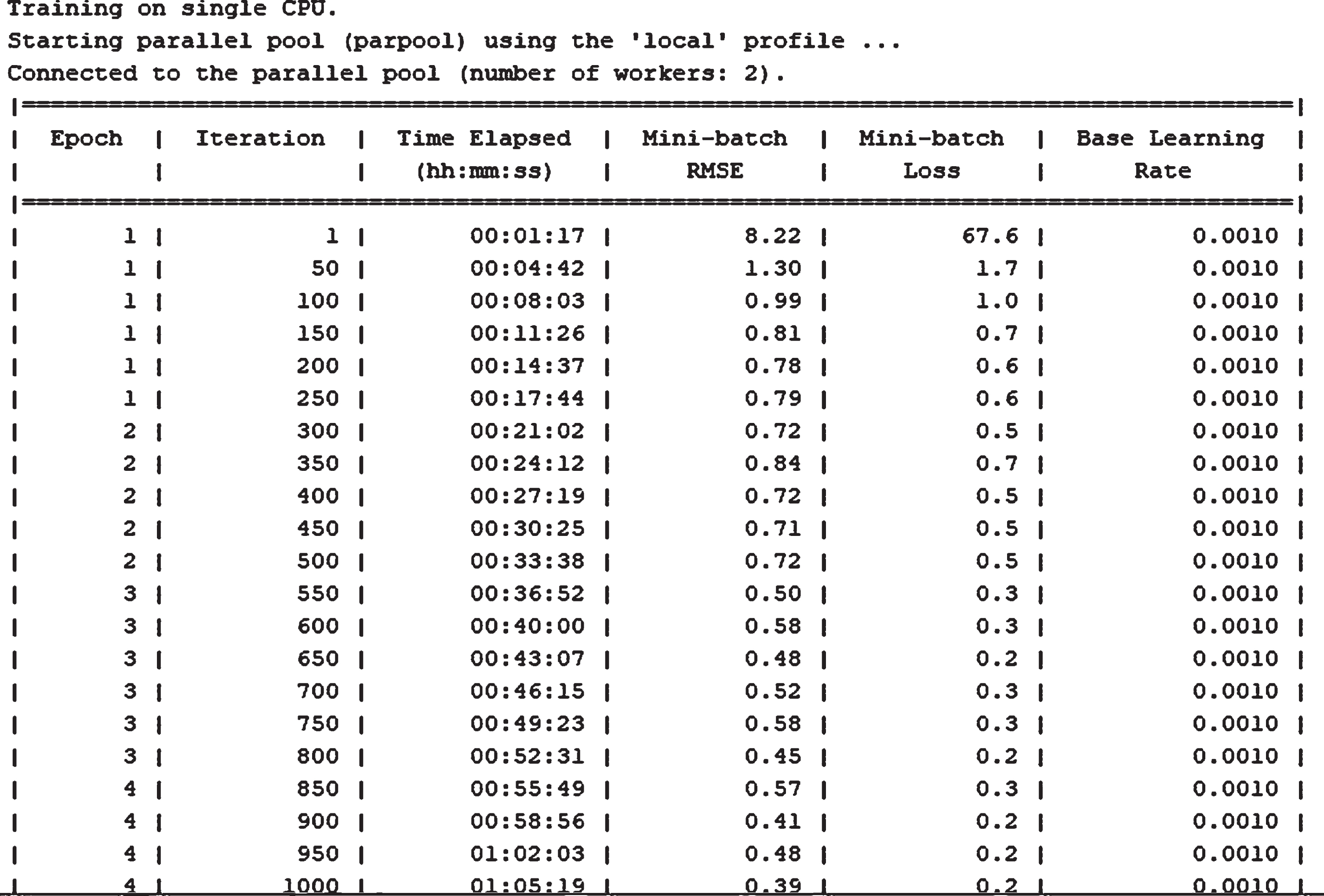
Snapshot of the training process of the Yolo v2 network.
The snapshots of the fall detection test results have been included in this section. Figure 6 shows detection of the human body by the Yolo v2 network. Figure 7 shows fall detected by the system.

Snapshots of human body detection.

Snapshots depicting fall detected.
Snapshots in Fig. 6 depicting human body detected but fall have not been detected as the subject has changed to sleeping position gradually and the rate of change of subject’s height in the frames is not abrupt. The graph depicting average precision of the fall detection results and the log average miss rate has been shown in Fig. 8.

Average precision error and log average miss rate.
Over 50,000 frames were checked. All the 50 falls were correctly detected and there were no false positive cases.
Here a fall detection system using real time is presented, using a single depth sensor camera. The algorithm used here to detect falls is simple and easily implementable.
Detection of subject is carried out using the Yolo v2 process and fall detection is determined using the subject’s body height to width ratio and the velocity of the fall. Several fall detection scenarios were tested in cluttered backgrounds, multiple subject scenarios, and partial occlusion scenarios. The proposed algorithm successfully detected all the fall cases without any false negatives. This shows that algorithms performance is promising, and we plan to test more situations as part of our future work like collisions and major occlusions.