
Abstract
In the recent time, enviromental sound classification has received much popularity. This area of research comes under domain of non-speech audio classification. In this work, we have proposed a dilated Convolutional Neural Network approch to classify urban sound. We have carried out feature extraction, data augmentation techniques to carry out our experimental strategy smoothly. We also found out the activation maps of each layers of dilated convolution neural network. An increamental dilation rate has exploited Overall we achieved 84.16% of accuracy from the proposed dilated convolutional method. The gradual increaments of dilation rate has exploited the worse effect of grindding and has lowered down the computational cost. Also, overall classification performance, precision, recall,overall truth and kappa value have been obtained from our proposed method. We have considered 10 fold cross validation for the implementation of the dilated CNN model.
Keywords
Introduction
Sound classification has become a popular methodology and has recently generated interests among sound experts specially those working on the application machine learning and deep learning towards sound classification. Moreover, environmental sound classification has recieved even more popularity among researchers [1–3]. The classification task can be found not only in human sound, rather it can also be found as application towards music classification [1] and speech recognition system [2]. However, the classification of environmental sound is different than classification of music or speech. First work related to CNN on ESC (Environmental Sound Classification) was conducted by Piczak [5]. It is true that creating a classification model for ESC with a high accuracy is a daunting task. Currently the versions of models that are in use for ESC have not focused so much on the use of hyper-parameters for example, not much works have been carried out to gather the feature that are locally available from an image through CNN (convolutional neural networks) [4]. In this work, we have tried to increase the dilation rate of the proposed CNN slowly so that feature extraction could be better than normal CNN. We therefore, have proposed a dilated convolutional neural network to do the job of classification of images names as mel-spectrogram. The sound files i.e the audio files are converted to a 2D vector format using the librosa package from Python. However, there are issues with the dilation rate as just increasing the dilation rate might add more sparseness of the kernel, which can affect small object detection. Henceforth we prefer to increase a slow but steady increment of dilation rate, which has helped us to reduce the sparsity of the dilated feature map [19]. This technique also has helped us to extract the more information from portion of the image that is under consideration. Zang et al. [39] have proposed a PSO(Particle Swarm Optimiztion) method with the use of pararameter optimization for sound classification. We have considered UrbanSound8k audio data for classification technique [25]. In the below,we have jot down the crucial points that can be considered as major contribution of our proposed work. To classify the audio files, we have proposed a dilated convolutional neural network. By increasing the dilation rate, a better accuracy has been achieved Each dilation layer’s activation maps have been obtained to show how the feature learning process has been progressed across the hidden layers. A well analysed discussion has been put forth, on why a small receptive field of conventional CNN might results poor classification accuracy in ESC. Finally the future directions and probable applications of our proposed method also have been discussed.
Related work
Initially, Piczak developed a CNN algorithm that was proposed to do a classification task on ESC; in this CNN two layers of convolution function have been used, then two max pooling layers and two layers that are fully connected layers(FC) also have been used. Also, ESC-10 and ESC-50 data sets have been developed by Piczak [5]. He experimented with these sets of sound related data for classification task with convolutional neural network. Piczak and later on others have obtained accuracy for ESC-10, ESC-50 and UrbanSound8k around 81.0%, 64.5% and 74% respectively [6–8]. Enhancing the performance of CNN technique which has been proposed by Salamon et al. [9] used the augmentation of data. In the data augmentation all normal steps are followed such data stretching, shifting the pitch and range compression and noise of backgroud. They have achieved accuracy of 74% for UrbanSound8k data set without excluding data augmentation. Another model proposed by Aytar et al. [10] named as SoundNet which totally depends on 1D CNN technique. A typical natural synchronization has been used for audio and video recognition by the authors in this work. For ESC-10 data set and ESC-50 data sets they obtained 92.1% and 74.1% accuracy. Further WaveMsNetmodel was proposed by Zhu et al. [10] and they have used variatioanl convolutional neural network and log mel features exctaction [11]. A multi-stream CNN based approach has been proposed by Li et al. [12] for ESC, where authors experimented with the audio signal which were raw. The input they have considered in this work is the coefficient of Short-Term Fourier Transform(STFT) and delta spectrograms. The overall multi-stream CNN have been made of CNN and densed layer. The classification accuracy that was obtain for ESC-10 was 93.7%. A dilated convolutional neural network was proposed by Chen et al. in the year of 2019, however the accuracy they achieved was 78.0. In this work authors have used convolution function instead of max pooling function [23]. Su et al. [13] have proposed model that was based on decision level fusion on two stream CNN, authors have achieved good accuracy of 97%. [13]. An attention-based residual neural network has been proposed by Tripathy and Mishra(2021) and improvements are upto 11.50% and 19.50% in terms accuracy as compared interms of accuracy for ESC-10 and DCASE 2019 Task-1(A) datasets respectively [14]. Mushtaq and Shun [15] have proposed a deep convolutional neural network (DCNN) with regularization. They have shown how to enhance the data using the basic audio features. Also, the experiements have been smiluated with ESC-10 data set and obtained accuracy is around 94.94%. Fan et al. [16] have proposed deep neural network based model for envriromnental sound classification, which they have claimed that it could be used for hearing app. Jangid and Nagpal (2022) have shown a sound classification method by proposing a convolutional neural network. The spectrogram that they have used is Mel frequency cepstral and with that they were successful to obtain the power spectrum of the sound wave. The validation accuracy was 89.5% on environmental sound classification and for urban sound they obtained approximately 96% accuracy [37]. Tripathi and Mishra (2022) have carried out an interesting work on the effect of advarsarial attacks on the performance of deep models. These deep models are obtained to classify the sound of environment. In this regards, authors have also prepared first Adversarial environmental sounds (Adv-ESC) and released it online [38]. Here in this work also we have experimented with UrbanSound8k sound only and the obtained a satisfactory accuracy.
Proposed method
CNNs are great at classifying 2D data. The audio files are converted to a 2D vector format using power based melspectrogram [17, 27]. Generally Convolution layers are coupled with MaxPooling layers in a way to generate feature maps and compress them to improve computation. Using dilated convolutions, we can specify the granularity of the feature maps without having the computational overhead of using larger convolutional filters for the layers. To develope a well generalize model, 10 fold cross validation has been used and the results have been combined to generate the confusion matrix. The use of convolutional neural network is widespread. A conventional convolutional neural network can be represented with D×D layers of convolution function as l * (D-1)+D. This representation is nothing but avoiding the pooling layers involvement and futher depicts that there is a linear increaments in-terms of the receptive field which is nothing but linear increments of the receptive field with l number of layers. However, unfortunately this linear increament is the reason of poor performacne of CNN. Consider H is a discrere function as below [17, 29],
Further assuming, Q
r
= [- r, r] 2 ∩ M2 and k : Q
r
→ R is filter of size (2r + 1) 2. The convolution operator * can be given as below also, Equation (2), where 1-D dilated convolution function has been introduced with the dilation rate l = l convolves input image P with kernel or filter k. This dilation rale can be increased slowly [18, 21],
The dilation factor l can be visible in Equation 2. A conventional CNN model formed when dilation factor l becomes 1. Another reason that we choose dilated convolutional neural network is that it can expand the kernel by putting in holes between the elements of the kernel. In this, the parameter named as dilation rate influences to widen the kernel. The thought of dilated convolution has been come from the decomposition of wavelet and it is also known as “atrous convolution” and “hole algorithm”. It helps to increase the receptive feild of the given neural network in exponential way so that the widened kernel can perform better with less cost while experimenting with image classification problem.
The data set urbanSound8k has been taken from (https://urbansounddataset.weebly.com/urbansound8k.html). It consists of of sound files (.wav format). We have used librosa package of python framework to process and convert the data set into the vector format. The data set has 8732 samples total, in which 6934 samples have the duration of 4 s of the audio data. Every recording have been re-sampled to 22050 Hz. Then normalization has applied to it and finally converted to power based melspectrogram. That has n_ftt of 2048 and it has hop_length of 512 [26].
Proposed dilated CNN
The model is an improvement over the basic CNN architecture with an additional dilation_rate parameter. Each input is vector of shape (128, 173, 1) generated from the melspectrogram. The architecture consists of alternating Convolution and MaxPooling layers. Applying a smaller filter allows the model to detect finer features. To detect coarser features, we generally make use of larger convolutional filters. To overcome the additional overhead of using larger filters, we can make use of the dilation_rate parameter. Four separate Convolution filters are designed with size 5×5 and the features are generated based entirely on the dilation_rate parameter. The layer Conv1 generates 128 feature maps with a 5×5 filter and dilation_rate of 4. The next two convolution layers, namely Conv2 and Conv3 generate 128 feature maps with a 5×5 filter and a smaller dilation_rate of 2. The final convolution layer Conv4 generates 128 feature maps with a 5×5 filter without and dilation that is dilation_rate 1. Between each pair of convolution layers, there is a MaxPooling layer. The function of the MaxPooling layer is the combine and compress the generated feature maps. The three MaxPooling layers, namely MaxPool1, MaxPool2 and MaxPool3 are designed with a kernel shape of 4×2 and 2×2 strides. Finally the results are flattened before adding a fully connected Dense layer of 64 nodes. To prevent the model from overfitting, a dropout of 25% is applied along with the ReLU activation function. Another fully connected Dense layer of 10 nodes is designed with a dropout of 25%. This combined with the softmax activation function, predicts the requires class of the input data. The model is trained using Adam optimizer with the aim of minimizing the categorical_crossentropy loss. The proposed algorithm of dilated convolutional neural network has been given below [16, 30–36].
Experiment and results
Data set
The UrbanSound8K dataset [5] is a collection of 8732 sound samples from www.freesound.org. Each sound excerpt is less than or equal to 4 s, drawn from the urban sound taxonomy the 10 classes are namely air_conditioner, car_horn, children_playing, dog_bark, drilling, enginge_idling, gun_shot, jackhammer, siren, and street_music [22].
Data Augmentation
For the UrbanSound8K dataset, simple augmentation techniques prove to be unsatisfactory given the size of the dataset, resulting in exponential increase in the training time and hardly any impact on the model accuracy. This is similar to the observation by Piczak [5] in the paper environmental sound classification with convolutional neural networks.
Parameterization
Convolutional neural networks have a number of tune-able hyper parameters, these include filter_size, padding, kernel_size and activation functions [28]. In case of dilated convolutions, an additional dilation_rate parameter is introduced. This parameter controls the granularity of the feature maps generated. Higher dilation rates correspond to coarse features and smaller dilation rates correspond to finer features. A disadvantage of using dilated CNN is that it suffers from a gridding phenomenon. This means that the generated feature maps do not cover the entire 2D input vector, leaving out a grid pattern. This can result in a loss of data and negativally impact the model accuracy. To overcome the gridding phenomenon, we make use of dilation rates in a decreasing sequence. This corresponds to the first few layers focusing on the coarse features and the subsequent layers focusing on the finer features. Due to the large size of the dataset, the testing and tuning of the hyper parameters was done only based on a single fold. The parameters, resulting in the best accuracy where then used to train and validate the model on the other 9 folds. In 10 fold cross validation we have splitted the data into 10 equal parts. Every time the algorithm of dilated CNN excecutes one part of the dataset is used as training set and remaining 9 parts are used training dataset.

Class wise confusion matrix.
In the below Table 1 we have shown the obtained results of our proposed method which shows the overall accuracy,user accuracy,producer accuracy,overall truth,overall accuracy and Kappa values.
Accuracy of the proposed model
The activation maps of each hidden layer have been shown in the Fig. 2. It can be noticed from the Fig-2, that layer 1 and layer 2 concentrated on coarse features for example shape of the images or any outlier locations. It can also be seen that granuality features of the images decreases. The features of the granuality are generated from the last layer which signifies that the focus is on the tiny section of the of the images of the spectrogram [5].
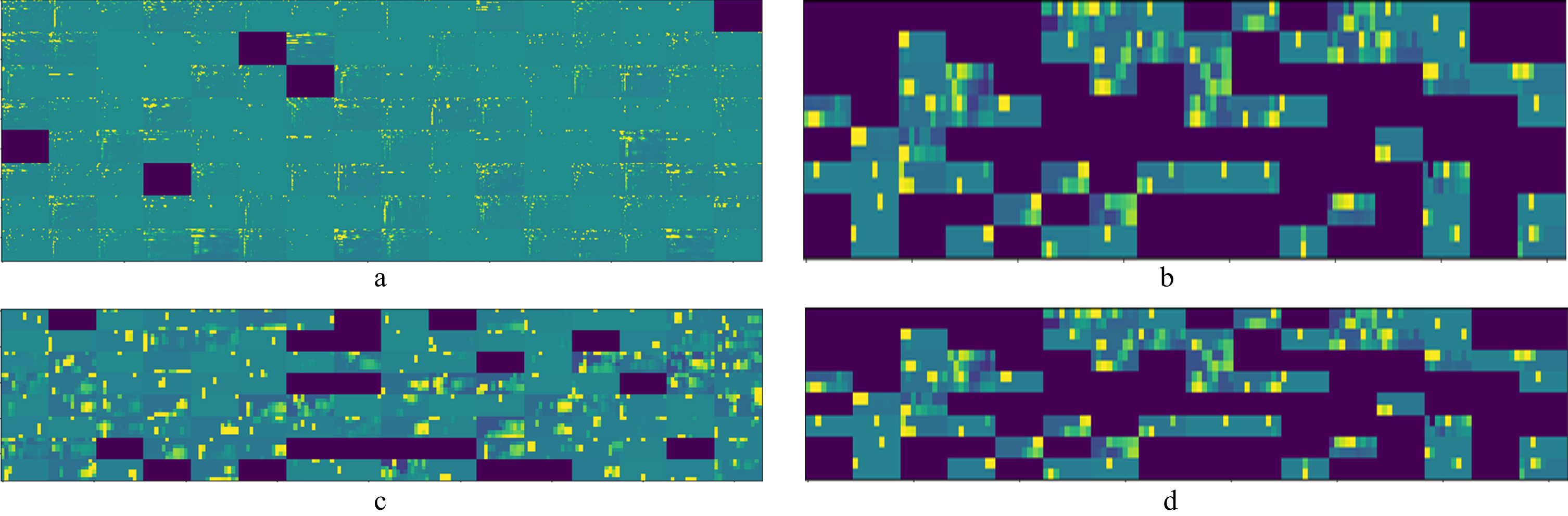
Activatino maps for various layers of the Dilated Con volution Neural Network. a. Activation map of layer 1. b. Activation map of layer 2. c. Activation map Layer 3. d. Activation map Layer 4.
This paper has shown a proposed new technique namely dilated convolutional neural network for classification of environmental sound classification. We have carrioed out data augmentation, feature extraction and classification have been carried out. However,the limitation of our proposed work has been the data augmentation process as that surely might improve the overall performance. The data augmentation technique can be further enhanced with the help of background noise insertion, and pitch shifting. We have used mel-spectrograms but in future we will try to incorporate with other technique instead of mel-spectrograms. We have checked our proposed model with urbanSound8K data set. We have obtained accuracy of 84.16% overall. It is also worth mentioning that the feature selection steps have been carried out in most efficient way. All hidden layers’ activation maps have been shown and that demonstrate the validity of our work. However, we want to invesigate various advanced pretrained models of convolutional neural networks and want to predict the other data sets also.
Copyright
Authors submitting a manuscript do so in the un-derstanding that they have read and agreed to the terms of the IOS Press Author Copyright Agreement posted in the ‘Authors Corner’ on www.iospress.nl.