
Abstract
Machine learning algorithms have been used in diverse areas among applications, including healthcare. However, to fit an effective and optimal machine learning model, the hyperparameters need to be tuned. This process is commonly referred to as Hyperparameter Optimization and comprises several approaches. We combined three Hyperparameter Optimization techniques (Bayesian Optimization, Particle Swarm Optimization, and Genetic Algorithm) with three classifiers (Random Forest, Support Vector Machine, and XGBoost) to identify the best combination of hyperparameters that maximize model performance. We use the Framingham dataset to test the proposal. For classifier performance, the Support Vector Machine obtained the best result in recall (96.40%) and F-score (93.86%), while XGBoost obtained the best result in precision (96.30%) and specificity (96.36%). In the accuracy metric, both classifiers achieved 95%. Bayesian optimization had the best results in terms of accuracy, precision, specificity, and F-score metrics. Both Particle Swarm Optimization and Genetic Algorithm obtained the best result in the recall metric.
Keywords
Introduction
Building an effective machine learning model is a complex and time-consuming process that involves determining the appropriate algorithm and obtaining an optimal model architecture by tuning its hyperparameters (variables used to set up a machine learning model) [1]. There are two types of parameters: those that can be initialized and updated through the training process (e.g. the weights of neurons in neural networks) are called model parameters. The others, called hyperparameters, cannot be estimated directly from training and must be set before training a machine learning model because they define the model architecture [2].
It is frequent to use default hyperparameter values when building machine learning models. However, these default configurations may not be optimal for domain-specific data sets. It is necessary to evaluate models with different combinations of hyperparameter values to obtain an optimal machine learning model. This process, which aims to design an ideal model architecture with an optimal hyperparameter configuration, is commonly referred to as Hyperparameter Optimization (HPO) [3]. The goal of HPO is to automate the hyperparameter tuning process and enable users to effectively apply machine learning models to real-world problems [1]. Another advantage is improving the classifier’s performance compared to those models built with default values or manual hyperparameter tuning. HPO is relevant when working with large and complex data sets. Because the right choice of hyperparameters can make the difference between a poorly performing model and a highly accurate and generalizable one [3]. Model performance is directly affected by the best choice of hyperparameters.
Heart and chronic respiratory diseases provoke each year 19 million deaths around the world [4]; particularly in México, heart disease is the first cause of death [5]. Therefore, it is necessary to address the cause of this disease because of the high rate of deaths. For this purpose, Machine learning has been used to predict cardiovascular risk diseases using several models. Each model has different hyperparameters that are required to be tuned to improve its performance, and according to Yang and Shami [3], the best selection of hyperparameters has a direct impact on the model performance.
The experiments described in this paper were conducted using different optimization approaches to identify the best combination of hyperparameters that maximizes model performance as a function of the data available for training. These approaches were applied to three machine learning algorithms: Random Forest (RF), Support Vector Machine (SVM), and XGBoost. The approach proposed in this paper may be subjective and does not guarantee the discovery of the best configuration. This is due to the nature of optimization methods (approximate methods), so there is no absolute guarantee of finding the “optimal” hyperparameter configuration.
The main contribution of this paper is to establish an experimental methodology to contrast different models based on machine learning algorithms. We combine three Hyperparameter Optimization techniques (Bayesian Optimization, Particle Swarm Optimization, and Genetic Algorithm) with three classifiers (RF, SVM and XGBoost) to identify the best combination of hyperparameters that maximize model performance. The approach is applied to Cardiovascular Risk Prediction.
The remainder of this paper is organized as follows. Section II presents the related work, while Section III describes the hyperparameter optimization process, the approaches, and the strategies followed. Section IV analyzes the most influential hyperparameters in RF, SVM, and XGBoost classifiers. The proposed methodology is detailed in Section V. Section VI discusses the results. Finally, Section VII concludes this work.
Literature review
The related works have been divided into four categories: optimization theory in machine learning, default hyperparameter configuration, hyperparameter configuration based on user experience, and hyperparameter optimization approaches. In the subsections below, we briefly describe the most important works.
Optimization theory in machine learning
Yang and Shami [3] compare eight hyperparameter optimization techniques in combination with the classifiers kNN, SVM, and RF for two datasets. But, they only focus on accuracy, the mean squared error, and computational time. Kotthoff et al. [6] built the tool Auto-WEKA to select the best machine learning classifier and the optimal hyperparameter optimization for a given data set. However, in some cases, they gave a very large time budget in CPU time, meaning that often it would be infeasible to use in practice.
Default hyperparameter configuration
Guarneros-Nolasco et al. [7] analyze the performance of ten machine learning algorithms focusing only on the accuracy metric. They identify the top two and top four attributes. Uddin et al. [8] compare 48 articles among diverse machine learning classifiers for disease prediction. They summarized the advantages and limitations of seven machine learning classifiers.
Hyperparameter configuration based on user experience
Reddy et al. [9] trained ten machine learning classifiers for heart disease risk prediction using the full set of attributes of the Cleveland dataset and the optimal attribute sets obtained from three attribute evaluators. They only tuned the hyperparameter number of the nearest neighbor in the instance-based (IBk) classifier on the full attribute set and the optimal set obtained from attribute evaluators. Gupta et al. [10] proposed a framework for heart disease diagnosis to obtaining the best combination of feature set, classifier, and tuned hyperparameter for accurate classification of heart disease diagnosis. Li et al. [11] proposed a system (FCMIM-SVM) to diagnose heart disease based on machine learning classifiers along a conditional mutual information feature selection algorithm (FCMIM). They focus on diverse feature selection methods.
Hyperparameter optimization approaches
Hashi and Zaman [12] use only the Cleveland dataset to apply the grid search approach for hyperparameter tunning focusing on the metrics accuracy, precision, recall, and F-score. Budholiya et al. [13] use XGBoost and Bayesian optimization for hyperparameter tuning on the Cleveland dataset. They also compared the results with another two classifiers. Gosh et al. [14] proposed a model using a combined dataset (UCI heart disease datasets) in combination with Grid search optimization and five classifiers. Finally, Valarmathi and Sheela [15] use three hyperparameter optimization techniques: grid search, randomized search, and genetic programming (TPOT classifier) along RF and XGBoost classifiers for the Cleveland dataset.
Although the works we mentioned have contributed significantly to cardiovascular risk prediction, our approach highlights two key aspects. First, our methodology uses advanced hyperparameter optimization techniques, as discussed in Section 6. Second, the robustness of our method is even more evident in its effective handling of imbalanced data, a critical aspect often overlooked in previous work.
Hiperparameter optimization in machine learning
The HPO process focuses on finding the best hyperparameter configuration for the algorithm learning process using optimization approaches. Each approach considers the hyperparameter configuration as an optimization problem, and the hyperparameters are the decision variables. The main goal is to maximize the algorithm’s performance while minimizing the prediction errors [16].
This process can be expressed in the Equation (1):

According to Probst et al. [18], let y be a target variable, a feature vector X, and an unknown distribution P on (X, y), from which a data set T of n observations has been sampled. An algorithm M learns the functional relationship between X and y by producing a prediction model f (X, θ), controlled by the k-dimensional hyperparameter configuration θ = (θ1, …, θ k ) from the hyperparameter search space Θ = Θ1 × … × Θ k . To measure the prediction performance pointwise between the true label y and its prediction f (X, θ), the loss function is defined as L (y, f (X, θ)).
The interest relies on estimating the expected risk of M, with respect to the θ on the new data, also sampled from P : R (θ) = E (L (y, f (X, θ)) |P). This mapping encodes, given a specific data distribution, a specific learning algorithm, and a specific performance measure, the numerical quality for any given hyperparameter configuration θ.
Given m different data distributions P1, P
m
, the Equation (2) shows the risk mapping of m hyperparameters.

Equation (3) defines the best hyperparameter configuration for the dataset j.

The mathematical expression of the L function varies depending on the objective function of the chosen machine learning algorithm, which usually corresponds to a performance metric such as accuracy, precision, recall, and f1-score [3].
The main goal of the HPO approach is to combine the values for the model hyperparameters to obtain the best score on the validation subset metric.
Bayesian optimization
Bayesian optimization (BO) is emerging as a powerful approach for globally identifying optimal solutions within complicated black-box functions that are non-convex, require resource-intensive evaluation, and lack an analytically solvable framework for computing derivatives [19]. By using observed data to anticipate the next evaluation point, BO demonstrates the ability to identify the optimal hyperparameter configuration within a modest number of iterative steps.
The goal of BO is to find the optimal configuration x* that maximizes the function value f (x) using an unknown objective function f. This configuration receives an input value x where the objective function is unknown. However, two elements to examine the function values sequentially for the input value candidates and find the optimal configuration that maximizes f (x) are needed and described below [20]: A surrogate model that performs probabilistic estimation of the nature of the unknown objective function based on the input values and function values explored so far. An acquisition function α (x) that derives the optimal input value x* based on the probabilistic estimation results so far.
We used Gaussian Processes (GP) as a surrogate model in this research. However, there are other alternatives for surrogate models, such as Random Forest and Tree-structured Parzen Estimators (TPE) [21]. GP provides models for Gaussian distributions, as well as several other random variables commonly used in statistics. The GP corresponding model is shown in Equation (4).

For BO approach, the function f is modeled as a GP with a mean function m and a covariance function k. When applying BO, it is commonly simplified m to zero, and the most choice used of k is the squared exponential kernel, as shown in Equation (5) [22].

Let D = {(x
i
, y
i
)} is the observations that contain N inputs x
i
and their corresponding function values
The predictive distribution is also a GP characterized by the mean and variance, as shown in Equations (6) and (7) [22].


The posterior mean and variance, computed using Equations (6) and (7) respectively, are employed to formulate an acquisition function denoted as α (x).
The Particle Swarm Optimization (PSO) algorithm [23] is a stochastic optimization technique inspired by the social behavior of swarms of various creatures such as insects, birds, and fish. Each particle (individual element of a swarm) symbolizes a potential solution and traverses the search space in search of optimal or near-optimal solutions. The algorithm uses a fitness function to evaluate the quality of the solution and guide it to efficiently explore the problem space [24].
Two fundamental attributes are critical to the behavior of each particle: its position and velocity in the problem search space [23]. Position represents a particular solution, while velocity governs the direction and magnitude of its motion within the solution space. Through iterative updates, the particles collaboratively explore and exploit the search space, ensuring that the PSO converges to favorable solutions for the given optimization problem. The equations used to update the position and velocity of particle i in the search space at iteration t are given in Equations (8) and (9), respectively.


The cognitive and social factors are represented by parameters c1 and c2. These factors define certain features that influence the determination of the best particle position (pbest) and the best global position (gbest), denoted by y
i
and
A fitness function f is employed, considering that the swarm is composed of n particles and is applied to a minimization task. The update of global and personal best values at iteration t is carried out using Equations (10) and (11), respectively.


Genetic algorithm (GA) is a stochastic search technique based on the mechanism of natural selection. The idea of GA as an algorithm inspired by evolutionary theory was introduced by John Holland in the 1960s and then developed by David E. Goldberg in the 1980s. This method starts with an initial set of solutions, called the population. Each member of the population is called a chromosome and represents a potential solution to the given problem. A chromosome consists of a sequence of symbols, typically but not exclusively represented as binary bits. These chromosomes go through successive iterations, called generations [25].
In GA, two key operations are used to generate a new generation of solutions. Two chromosomes of the current generation are combined through a crossover operation, which allows the transfer of genetic information between them. Then, to increase diversity and explore new avenues, changes are introduced to a chromosome through a mutation operation [3]. The next generation is derived from this intermediate population by i) selecting certain parents and offspring based on their fitness values and ii) excluding others to maintain a consistent population size. Chromosomes with higher fitness values are more likely to be selected. After several generations, the optimal or suboptimal solution is expected to converge, representing the best possible outcome for the given problem [25].
In setting up the evolutionary approach, we used the values for the crossover, mutation, and selection operators (namely uniform, random, and tournament, respectively). This choice was made based on the versatility and demonstrated robustness of these operators in different problems and scenarios. An efficient balance between exploration and exploitation in the hyperparameter search space is provided by the combination of uniform crossover, random mutation, and tournament selection.
Machine learning classifiers
In this section, we present the main machine learning algorithms. We also present the main set of hyperparameters that are directly related to the training of the algorithms.
Random forest
The Random Forest (RF) technique is an ensemble learning approach that uses bagging to merge many decision trees, each slightly different from the others [3]. The basic concept of RF is that individual trees provide reasonably accurate predictions but with the tendency to overfit specific data points. By generating a large number of trees, each of which out and overfits in different ways, the excessive overfitting can be mitigated by averaging the results.
Let X be a random subset of the observations, and m be a random subset of the features, where m ≤ p. The classification of a new observation x is done by voting on the individual trees in the forest.
The important hyperparameters (and their default values) include the number of trees (n_estimators = 100), the criterion used to measure the quality of node splitting (criterion = gini), the number of features used to train each tree (max_features = square root of total features), the maximum depth of each decision (max_depth = no depth limit), the minimum number of samples required to split an internal node (min_samples_split = 2), and the minimum number of instances required in a leaf node (min_samples_leaf = 2).
Support vector machine
The goal of the Support Vector Machine (SVM) algorithm is to find the most favorable hyperplane that effectively distinguishes samples belonging to different classes within a multidimensional space. SVM strives to identify the hyperplane that maximizes the margin between these classes, thereby improving its ability to handle new data points [18].
When there are classes that are non-linearly separable, it uses kernel functions to transform the data into a higher-dimensional space in which the classes can be distinguished. The algorithm classifies new instances based on their position relative to the hyperplane and accurately assigns them to the appropriate predefined classes.
Its hyperparameters include the regularization parameter C = 1.0, the type of decision boundary (kernel = rbf), the degree that determines the complexity of the polynomial decision function (degree = 3), the influence of each training example (gamma = automatic scaling), and the independent term in the polynomial kernel (coef0 = 0.0).
The function g (x) uses a kernel function to measure the similarity between two data points: x
i
and x
j
. The most common types of kernels are linear, polynomial, RFB, and sigmoidal, as shown in Equations (12)–(15), respectively [26]:



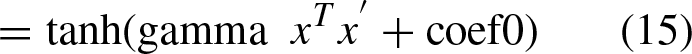
Extreme Gradient Boosting (XGBoost) generates sequential models and uses the boosting technique to combine simple, less accurate models into models that improve the accuracy of cases incorrectly predicted. The tuning process of each tree is performed using Stochastic Gradient Descent (SGD) [19]. The residual is estimated by fitting the data to a decision tree, and the second tree is fitted based on the residual from the previous step.
The objective function of XGBoost has a regularization concept that helps to select predictive functions and control the complexity of the model. By combining the loss function and the regularization term, the XGBoost objective function is obtained. The predictive power of the model is controlled by the loss function and the simplicity of the model is controlled by the regularization term.
Its hyperparameters include the number of trees (n_estimators = 100), the learning rate (learning_rate = 0.3), the model complexity controlled by gamma = 0, the fraction of instances considered for each tree (subsample = 1.0), the maximum depth of the trees (max_depth = 6), and the fraction of features considered for each tree (colsample_bytree = 1).
Materials and methods
This section presents information about the dataset used to train and evaluate cardiovascular risk prediction models. We also describe the dataset’s features, the preprocessing techniques used, and a detailed explanation of our proposed methodology.
Proposed methodology
The proposed solution to the problem presented in this paper is shown in Fig. 1. The first phase consists of data preprocessing, including the identification of distributions, treatment of missing and atypical data, and data normalization or standardization. Subset partitioning for training and testing is performed using K-fold cross-validation. The second phase focuses on finding optimal values for the hyperparameters using optimization approaches such as BO, PSO, and GA, prioritizing the ROC-AUC metric to evaluate the performance of the models. In the third phase, the models are evaluated and compared using performance metrics such as accuracy, precision, specificity, sensitivity, and f-score. Finally, in the fourth phase, the results of the generated optimization processes are analyzed, and the models with the best performance are selected, highlighting the optimization approaches used in the model.

Block diagram of the proposed methodology.
Assigning values to the parameters of the BO, PSO, and GA approaches can be challenging due to the complexity of these methods and the multidimensional nature of the search spaces [3]. In this regard, the parameter tuning process was carried out based on information gathered from technical literature and by conducting empirical experiments through trial and error. We considered the results of previous hyperparameter optimization studies in similar contexts and adapted these findings to our specific framework. The following are suggested initial values to refine and control the search process. BO: surrogate model = gaussian processes with a mean function m = 0 and covariance function k = squared exponential kernel. PSO: population size = 50; inertia weight constant w = [0.5 + (rand/2.0)]; learning factors c1 = 2.8 and c2 = 1.3. GA: population size = 50; crossover rate = 0.6; mutation rate = 0.10; number of generations = 10; tournament size = 3.
The Framingham dataset [27] used in this study includes examination data from the first 32 clinical examinations, selected ancillary data, and event follow-up information through 2018. It was originally established in 1948 under the U.S. Public Health Service and later transferred to the National Heart Institute, NIH, in 1949. The study recruited 5,209 men and women between the ages of 28 and 62 from Framingham, Massachusetts, making it the first prospective study of cardiovascular disease. The dataset provides valuable insights into the incidence, prevalence and familial patterns of cardiovascular disease (CVD) and its risk factors [28]. The dataset’s attributes are thoroughly examined and presented in the Table 1.
Description of variables of Framingham dataset

Description of variables of Framingham dataset
HS: High School, Gc: GED certificate, VT: Vocational Training, CD: College Degree.
Correlation analysis
Correlation analysis between variables is a relevant process in the preprocessing phase. By examining the correlations between variables, it is possible to identify any significant relationships that may enhance the understanding of the data. This process can help identify redundant variables [29].
There are various techniques for measuring correlation, and for this dataset we used the Spearman correlation method [30]. This approach is less sensitive to outliers and is more suitable for variables that do not have a normal distribution. The features that have a positive correlation are SysBP-DiaBP (0.78), SysBP-Age (0.39), and BMI-DiaBP (0.38).
Missing data analysis
The Framingham dataset has missing data for six features, representing 15% of the total data. Table 2 shows the percentage of missing data for each variable.
Percentages of missing data for each feature

Percentages of missing data for each feature
The analysis of the missing data patterns results is listed below: The pattern between cholesterol and glucose is present in 80% of the records (with missing data) marked as not at cardiovascular risk. The pattern between cigarettes per day and glucose is present in 100% of the records (with missing data) marked as not at cardiovascular risk. However, these individuals are smokers. The pattern between BMI and glucose is present in 50% of the records (with missing data) marked as cardiovascular risk. These individuals are non-smokers and have not had a stroke.
Missing data treatment
The missing data pattern we identified in each of the features is the type of Missing Completely at Random (MCAR) [31] since the absence of data is not related to any variable and is completely random. Therefore, a common treatment mechanism for these data is to impute the mean for the subset of quantitative variables, and for the qualitative variables we use the mode statistic [32].
Outlier treatment
All quantitative attributes in the Framingham dataset contain outliers, with the exception of age. For most attributes, the number of upper and lower outliers is high. Therefore, the Winsorization method [33] was applied to reduce the impact of these data by replacing 3% of the values above and 1% of the values below the respective thresholds. In the application, values above the upper threshold were replaced by that threshold, while values below the lower threshold were replaced by the lower threshold [34]. Programming this technique involved using conditional statements or functions to identify and replace outliers according to the set thresholds.
Minority class resampling strategy
Class imbalance refers to the situation where the classes of interest are disproportionately represented in a data set. This results in models that overfit the majority class. It is necessary to use specific performance evaluation metrics to assess this problem. We apply the Adaptive Synthetic Sampling (ADASYN) oversampling technique to address the class imbalance problem. ADASYN focuses on generating new synthetic samples for minority classes with the goal of balancing the class distribution in the data set. Unlike some oversampling methods, such as replicating existing instances, this technique focuses on instances that are more difficult to classify correctly [35]. The distribution was 3596 observations for class 0 and 644 for class 1. After applying ADASYN, both classes were resampled to 3596 instances.
Feature scaling
Medical data types are often discrete, so standardization is essential to converge their features. When variables have different scales, the interpretation of analyses and statistical models can be affected. We used the Robust Scaler technique to establish a unified scale for all quantitative variables. This technique removes the median and standardizes the data based on the quantile range (typically the Interquartile range or IQR). The IQR represents the range between the first quartile (25th percentile) and the third quartile (75th percentile). The centering and scaling process is performed on each feature using the appropriate statistics derived from the training set samples. The median and interquartile range are then preserved for later application to new data using the transform method.
Discussion and analysis of the experiments
In this section, we describe the results from the HPO approaches in our Machine Learning models. This analysis allows us to delve deeper into the performance improvements achieved and to understand the impact of optimal configurations on model quality.
Search space definition for each machine learning model
Specifying the search space for the hyperparameters of each machine learning model in detail is quite an extensive task due to the numerous variations, hyperparameters, and architectures that may be involved [6]. Table 3 shows the proposed search space for each HPO approach.
Search space of hyperparameters

Search space of hyperparameters
* L: linear, P: poly, R: rbf, S: sigmoid.
The Framingham dataset was divided into training and evaluation subsets. Approximately 6,972 records were used for the training phase, while 220 records were reserved for the evaluation phase. In addition, a 10-fold cross-validation approach was used to measure the effectiveness of the algorithms. The values of the confusion matrix of the model with HPO are shown in Table 4.
Confusion matrix of models training

Confusion matrix of models training
The results presented in Table 5 provide a detailed analysis of the performance of the classification models (RF, SVM, and XGBoost) under different HPO approaches. In the case of the RF model, the default configuration gave an accuracy of 90.00%. On the contrary, the SVM and XGBoost models gave 76.36% and 90.91%, respectively, under the same conditions. However, observing the optimization approaches, it is clear that the models benefited significantly from adjustments to their hyperparameters. For example, in the case of the RF model, the BO approach provided improvements, with an accuracy percentage of 92.27%, outperforming the default setting. For the SVM model, the use of BO proved to be very effective, achieving an accuracy of 95.00%. For XGBoost, the optimization with BO was excellent, increasing the accuracy to 95.00%.
Predictive model performance evaluated with test dataset

*Generations.
In terms of the precision metric, the SVM model shows good performance in all optimization approaches, reaching the highest precision of up to 95.45% with the BO approach. The XGBoost model also shows good classification ability, achieving an excellent precision of 96.30% when using BO. This improvement suggests that this optimization approach can help the model make more accurate decisions in identifying positive instances.
Regarding the specificity metric, the SVM model continues to lead in all configurations, with a maximum value of 95.41% with the BO approach. The XGBoost model also shows a better performance in terms of specificity, reaching 96.36% with the same optimization strategy. These results highlight the ability of both models to avoid misclassifying negative instances, which is essential in scenarios where false positives need to be minimized.
Finally, when evaluating the recall metric, it is important to highlight that the SVM model achieves the best percentages in several optimization approaches. Specifically, in the PSO and GA configurations, the SVM model achieves an outstanding recall value of 96.40%. This result highlights the SVM’s ability to identify and capture a large proportion of the positive instances in the dataset.
Initially, using the default configuration of the RF model, an accuracy of 90% was achieved. However, by applying the BO and GA approaches, hyperparameter combinations increased the accuracy to a remarkable 92.27%. Table 6 provides a comprehensive overview of the most salient hyperparameter combinations for the RF model across the four corresponding fitting approaches. These approaches use different numbers of estimators, a higher value for the maximum depth of estimators, and similar values for the minimum number of samples for node splitting and the minimum number of samples at leaf nodes. These results highlight the complex nature of the hyperparameter space and how different solutions can be equally effective in improving model performance.
Hyperparameter optimization results for RF model

Hyperparameter optimization results for RF model
In the case of the SVM model, an accuracy of 76.36% was obtained with the default configuration. However, after applying the BO and GA approaches, the accuracy obtained was 95% and 94.09%, respectively. Table 7 shows the hyperparameter settings used to obtain these results. The effectiveness in improving model performance is clearly demonstrated. They also show that the selection and proper adjustment of the hyperparameters c, gamma and coef0 to values higher than the default values leads to a significant increase in the classification capability of the model.
Hyperparameter optimization results for SVM model

Finally, the XGBoost model in its default configuration showed a performance with an accuracy of 90.91%. The implementation with the BO approach produced a combination with an accuracy of 95%, characterized by a high number of estimators, a reduced learning rate, and a more considerable maximum depth. Similarly, PSO produced a combination with 93.18% accuracy, and GA produced a combination with a robust performance of 94.09%, focused on the learning rate, maximum depth, and other relevant hyperparameters. It is worth noting that the best-performing models in the testing phase were obtained from the BO and GA approaches. Table 8 shows the most efficient hyperparameter combinations found for the XGBoost model in the training phase.
Hyperparameter optimization results for XGBoost model

This paper intends to show the effect of hyperparameter optimization in the Framingham dataset related to cardiovascular risk prediction. RF, SVM, and XGBoost classifiers are applied with four optimization mechanisms (default configuration, BO, PSO, and GA) in order to improve the ML model’s performance.
Following, we listed the best results by metric. For accuracy metric, SVM and XGboost with the BO approach achieved 95.00%. For precision metric, XGBoost with the BO approach obtained 96.30%. Similarly, with the specificity metric, XGBoost with the BO approach achieved 96.36%. For the recall metric, SVM with PSO and GA approaches obtained 96.40%. As for the last metric, F-score, SVM with the BO approach obtained 95.02%. Both BO and GA were the approaches that obtained the best results improving the accuracy, precision, specificity, recall, and F-score metrics compared to the default hyperparameters. However, when BO optimizes a function, it assumes that the input variables (hyperparameters) are continuous, because this method uses an acquisition function defined only in a continuous domain [22].