
Abstract
Spotting rumors from social media and intervening early has always been a daunting challenge. In recent years, Deep neural networks have begun to discover rumors by exploring the way of rumor propagation. The existing static graph models either only focus on the spatial structure information of rumor propagation or on time series propagation information but do not effectively combine them. This paper proposes the Static Spatiotemporal Model (SSM), which first extracts the textual semantic information and constructs undirected and directed propagation trees. Then obtains spatial structure information of rumor propagation through Graph Convolutional Network and extracts time series propagation information through the Recurrent Neural Network. The extracted spatiotemporal information is enhanced using different source node information hopping. Finally, SSM uses a weighted connection ensemble to rumor classification. Experimentally validated on datasets such as Weibo and Twitter, the results show that the proposed method outperforms several state-of-the-art static graph models. To better apply SSM in early detection and characterize early concepts, this paper presents a new data collection index for early detection, which can detect events that spread faster and have more significant influence in a targeted manner. The experimental results on the new indicators further verify the superiority of SSM as it can extract sufficient information in early detection or events with fewer participants.
Keywords
Introduction
Many complex systems in nature and society can be described as complex networks [1]. Social networks are one instance that is developing extremely rapidly, users in which have developed into a vast volume. More and more people are accessing information, expressing opinions, and gaining attention on social platforms. The characteristics of low cost, large scale, and convenient manufacture also make the spread of rumors unscrupulous, causing great harm to the country, society, and individuals. Therefore, for the potential panic and threat brought by rumors, methods, and models with better performance are urgently needed to detect rumors effectively in social media.
Rumor detection was first conducted through fact-checking sites. Still, this manual method is time-consuming and labor-intensive with low coverage and is increasingly unsuitable for rumor detection in the field of social networking. As a result, people began to explore automatic detection methods, and most of the initial automatic detection methods were based on traditional machine learning. Traditional machine learning methods, such as decision tree [2, 3], support vector machine [2–6], random forests [3, 7], logistic regression [7], naive Bayes [7], and traditional natural language processing [8], manually extracting features, such as user features, text content, metadata features, and dissemination structure feature to discover rumors, are time-consuming and labor-intensive and cannot extract deep features.
Recent automatic detection methods increasingly employ deep learning, which does not rely on manually extracted features. It is an end-to-end model and can extract deeper features to discover rumors with high accuracy. Some deep learning models focus on extracting deep semantic information of text content, such as Convolutional Neural Network (CNN) [9, 10], BERT pre-trained model [11], Long Short-Term Memory (LSTM) network [10, 12], Gated Recurrent Unit (GRU) [13] and so on. Rumors are usually deliberately written by imitating real news to mislead users, so to improve detection, the auxiliary information needs to be explored [14, 15]. Therefore, researchers begin to use increasingly models to explore the propagation information of rumors. RvNN [16], GRU [13, 17], ect. models can extract the time series propagation information of rumors, while Graph Convolutional Network (GCN) [18, 19] can extract the spatial structure information [20]. Temporal information focuses on the timing chain of deep propagation, while spatial information focuses on the surrounding neighbors of the source post, which we call spatial structure information. The spatiotemporal information has not been effectively combined for rumor discovery in the current static graph model. However, the depth propagation along the temporal relationship chain and the breadth diffusion within the community spatial structure are the two main characteristics of rumor propagation [18].
At the same time, the current early detection is not uniform for early concept characterization, and different standards are used for the collection of early data, such as the earliest stage [21], time window [18, 22], sample ratio, and number [16, 23] etc.
To simultaneously extract the spatial structure information and the time series propagation information of rumor propagation, this paper proposes a new static graph mixture model Static Spatiotemporal Model (SSM). The main contributions of this paper are listed as follows. A rumor detection model, SSM, is proposed. It can effectively integrate static spatiotemporal information and text information for rumor detection. Experimental results show that the model outperforms several state-of-the-art static graph models. Different from the experimental verification, combined with the data analysis, the rationality of using two layers instead of more layers to extract spatial structure information is analyzed in graph convolutional networks from the perspectives of spatial and frequency domains. A new data collection index is proposed for early detection. It can better apply SSM to early detection, characterize early concepts, and detect events that spread faster and have more significant influence in a targeted manner. The experimental results on the new indicators further verify the superiority of SSM. Two models are proposed based on SSM, Undirected SSM (UDSSM) and Directed SSM (DSSM), which combine the SSM model with the direction of spatial diffusion information. Experimental results on different datasets show that UDSSM has better detection performance, lower time complexity, and can extract much sufficient information in early detection or events with fewer users.
Related Work
This paper mainly introduces related work from two aspects: manual fact-checking and automatic detection methods.
Manual fact-checking
The initial rumor detection was done through fact-checking sites, mainly manual fact-checking. Manual fact-checking is the traditional way of fact-checking, either expert-based or crowdsourcing-based. Expert-based fact-checking is easy to manage and results in high accuracy, but it is expensive and limited in scale as the number of checks increases. Crowdsourcing-based fact-checking is easy to scale up but has low credibility and accuracy, as the cognitive biases and conflicting insights of the verifiers become a new hindrance. No matter which method is adopted, manual fact-checking is time-consuming and labor-intensive with low coverage. It has become increasingly unsuitable for the requirements of rumor detection in terms of scale, real-time, and accuracy.
Automatic detection method
Traditional Machine Learning
To make up for the lack of fact-checking, people began to explore automatic detection methods. People applied various machine learning algorithms to rumor detection and made many achievements. Traditional machine learning models train models by manually extracting user profiles, text content, tweet metadata, and dissemination structural features. Takahashi et al. [8] developed a system for detecting rumors from Twitter based on natural language processing techniques to extract text content features. Yang et al. [5] trained a support vector machine classifier for rumor detection based on attributes such as text content, user accounts, propagation features, and the newly proposed metadata features such as client information and location information. They proved the effectiveness of the newly proposed features. Kwon et al. [3] extracted three elements of time, structure, and language to train three classification models of the decision tree, random forest, and support vector machine. They proved the effectiveness and superiority of the selected features in detecting rumors. However, the methods mentioned above rely on feature engineering, i.e., hand-selecting elements, which is time-consuming and labor-intensive and cannot effectively extract deeper features.
Deep Learning
With the development of social networks, the number of users and tweets has increased, and the shallow features of rumors have become more and more blurred. The methods based on traditional machine learning have been unable to adapt to the detection of larger volumes of data, and people have begun to explore more effective ways for classification. People are increasingly favoring deep learning methods. The deep learning method does not rely on artificial features extraction, outputs end-to-end, and extracts deeper features. Indicators such as accuracy and recall are generally better than traditional machine learning algorithms.
Ma et al. [24] used a deep learning model (RNN) for rumor detection on Weibo for the first time and showed superior performance than traditional machine learning methods. Chen et al. [25] adopted Convolutional Neural Network (CNN) in SemEval-2017 task 8 for rumor short text classification. They ranked first in subtask B. Jin et al. [26] incorporated attention mechanism into RNN, based on multimodal features to detect rumors. However, the text content is highly counterfeit, and it is difficult for the proposed method to achieve higher accuracy by simply relying on the semantic features of the text. More research has begun to explore deep learning methods to learn deep structural features.
Ma et al. [16] were the first to deeply fuse structural and content semantic features based on a tree-like Recursive Neural Network (RvNN) for rumor detection. They propose two model variants, top-down and bottom-up, which achieve better results in both rumor classification and early detection. Chen et al. [23] incorporated a deep attention mechanism into an RNN to detect rumors, which could learn continuous hidden representations by capturing long-term correlations and contextual changes in post sequences. However, models such as RNN, LSTM, and GRU are more advantageous in extracting the time series propagation features along the chain. Still, they have shortcomings in obtaining the spatial diffusion features of the community structure. Bian et al. [18] used GCN to detect rumors for the first time. They aggregated the spatial structure information of rumor propagation from top-down and bottom-up directions and improved the accuracy again. Lotfi et al. [19] extracted the reply tree and user graph for each conversation using GCN to obtain information about users and how they interacted. They finally combined the outputs of the above two modules to detect rumors. Likewise, GCN cannot extract the time-series information of rumor propagation very well. Song et al. [27] proposed a rumor detection model based on a continuous-time dynamic diffusion network, which can effectively integrate spatiotemporal information and textual information, but the time complexity of the dynamic graph model is much higher.
The RNN is better at obtaining time-series propagation information. In comparison, the GCN is better at getting spatial structure information. But the current rumor detection model based on static propagation graphs does not effectively integrate these two kinds of information. Based on this idea, this paper proposes the Static Spatiotemporal Model (SSM) to more efficiently integrate the spatiotemporal information of rumor propagation, while avoiding the high time complexity of the dynamic graph model.
Problem Formulation
Let D = {c1, c2, …, c
i
, …, c
n
} be the rumor detection dataset, where
The purpose of rumor detection is to train a classifier to do F : D → Y, where Y is the set of labels y i for the datasets. In Weibo y i ∈ Y = {F, T}, F and T representing false and true rumors, respectively. But in Twitter y i ∈ Y = {N, F, T, U}, N, F, T and U representing non-rumors, false rumors, true rumors, and unverified, respectively.
As shown in Fig. 1, SSM contains three steps: Data Preprocessing, Information Extraction and Representation, and Information Aggregation and Classification. Firstly, SSM preprocesses the original data, extracts the textual semantic information of the post to construct the word vector, and constructs the undirected and directed propagation trees respectively. Then the spatial structure information of the local spread of rumors is extracted through a two-layer graph convolutional neural network. At the same time, a recurrent neural network is to extract the time-series propagation information of the stand change of the post. SSM skips the connection of source node information in different ways to avoid the loss and masking of crucial details and finally aggregates all the information in weighted connection ensemble for rumor classification. Next, introduce the four modules of the SSM: Propagation Graph Construction, GCN module, GRU module, and Aggregation Classification, respectively.
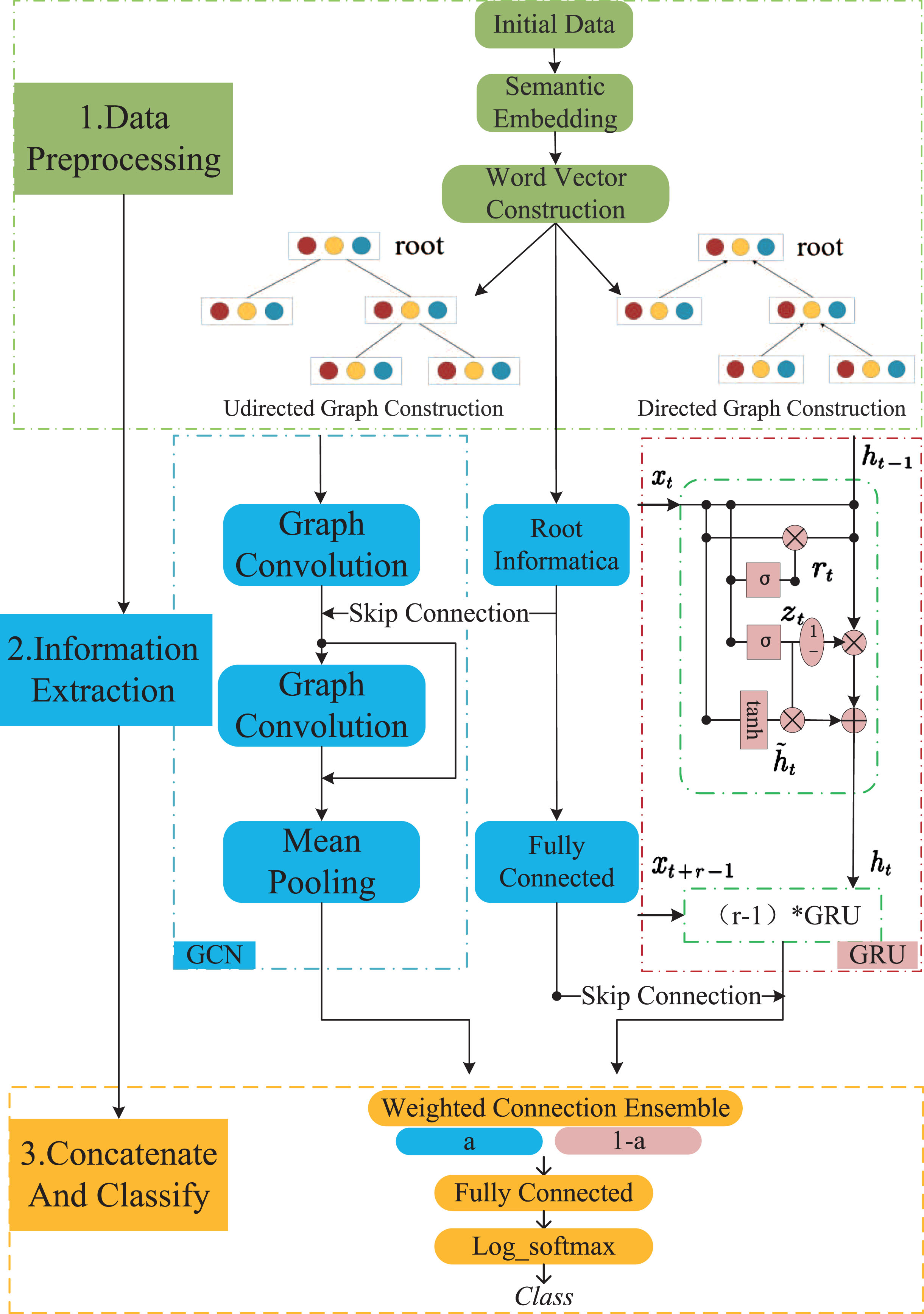
SSM framework.
SSM refers to the propagation tree constructed by Ma et al. [16] and Bian et al. [18]. In the propagation tree, nodes represent user tweets, and edges represent comments, replies, and retweets between tweets. SSM firstly encodes the word vector, extracts the semantic information of the text, and constructs different word vectors according to modules to construct the feature matrix of the nodes. Then the undirected and directed propagation graphs are built, respectively. It establishes the adjacency list from top-down and bottom-up directions, which indicates the path between nodes. The relationship of parent nodes and child nodes established by recursively querying the connection of the nodes also suggests the path between nodes. SSM constructs undirected propagation graphs by combining adjacency lists in the upper and lower directions to form a symmetric adjacency matrix.
GCN Module
SSM uses a two-layer graph convolutional network to extract the spatial structure information of rumor propagation. And it utilizes the skip connection of the upper-layer source node information to enhance critical text information of each graph convolutional layer. This section combines data analysis to analyze the rationality of using two graph convolution layers instead of more layers and the reason for using source node information for skip connections. First, we introduce the Graph Convolution Layer (GCL).
Graph Convolutional Layer (GCL)
As shown in Fig. 2, the forward pass of each GCL is as follows:
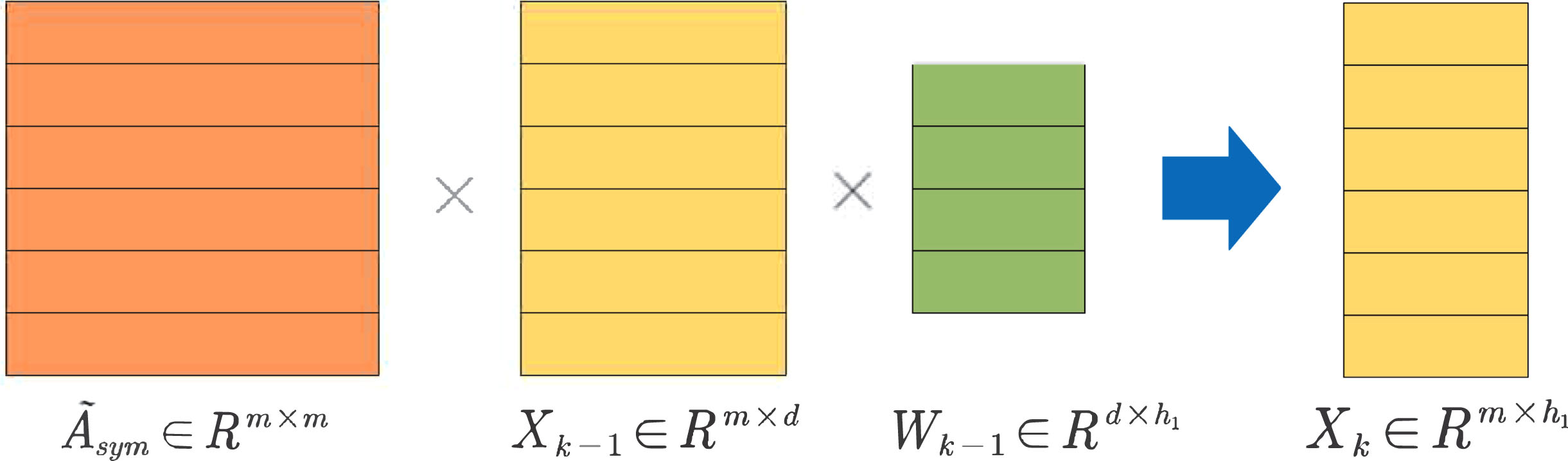
GCL affine transformation.
Recent literature generally uses two-layer GCN to obtain spatial structure information, and two-layer GCN is more effective than more layers [19]. Both Li et al. [28] and Xu [29] et al. pointed out that the GCN model cannot stack as deeply as the CNN model in vision tasks, using the effectiveness of multi-layer GCN drops dramatically. We analyze the rationality of using two-layer GCN in the rumor detection task from the perspectives of spatial and frequency domains, respectively.
1) Spatial Domain
From the spatial perspective of graph signal processing, the adjacency matrix is equivalent to a graph displacement operator. The transformation from Xk-1 to X k requires only the first-order neighbors of all nodes to participate in the calculation. That is to say, each additional layer of GCN is equivalent to aggregating information of the one-order neighbors of nodes additionally. For example, in Fig. 3, V1, V2, V3, V4, V5 are node IDs, x1, x2, x3, x4, x5 are node eigenvalues. For the V1 node, in (a) → (b), only the news of the V2 and V3 nodes is aggregated. In (b) → (c), the V1 node aggregates the information of node V4 additionally, and the same is true for other nodes.
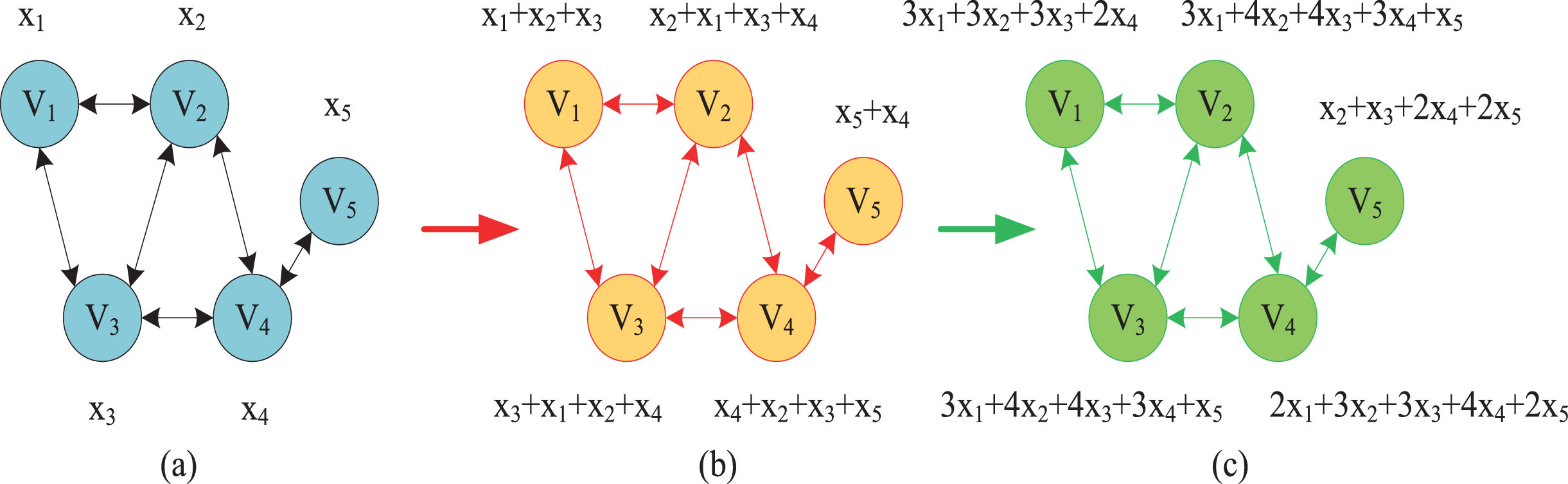
2-layer graph convolution network neighbor information aggregation.
This paper analyzes several commonly used rumor data sets (Weibo, Twitter, BuzzFeed, PolitiFact, etc.) through the Neo4j graph database. We focus on the analysis of the order of the maximum propagation width [30] in the propagation graph of each type of data set. As shown in Tables 1–5, ’Radius’ means the order of the maximum propagation width, and the content of the cell represents the number of events in the data set under the order and the label. Label ’0’ or ’False’ represents false rumors or fake news, and ’1’ Or ’True’ for true rumors or real news, ’Non-rumor’ for non-rumors, and ’Unverified’ is unverified information.
Weibo Dataset [18]
Dataset of Twitter15 and Twitter16 [16]
Dataset of BuzzFeed and PolitiFact
Dataset Statistics
Rumor detection results on the Twitter dataset (Binary Categories)
Remark: 1This paper uses the source node information skip connection to enhance the feature representation ability of the RvNN model, and the same is true for the following experiments.
From Tables 1–3 and Fig. 4, although each dataset differs in propagation depth [30] and width [30], the maximum propagation width of the events of the existing real datasets mainly concentrates in 1-2 order, and the node participation degree (node number) of 1-2 order is far more than other orders. Two-layer GCN can aggregate enough spatial structure information and maintain the local characteristics of the node itself. However, as the node aggregation information spreads to more orders, each node can gradually converge to the whole graph information. The spatial structure covered by each node gradually converges, and the characteristics of the nodes, especially the source node or root node, are Masked by other nodes.
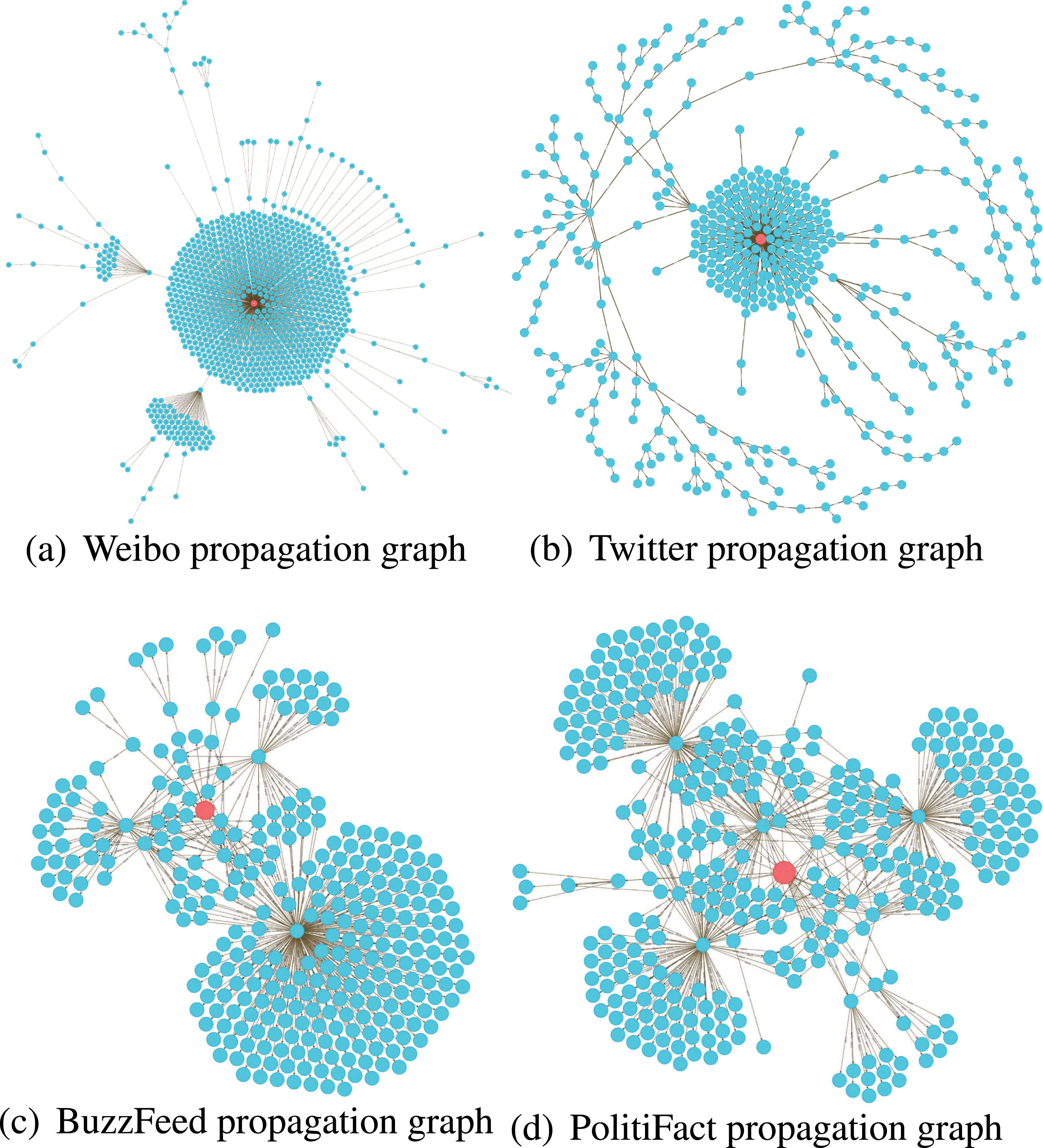
Propagation graphs for several real datasets (red nodes represent source tweets, light blue nodes represent retweets).
2) Frequency Domain
From the frequency domain perspective of graph signal processing, the GCN model (here refers to undirected GCN) can be viewed as a low-pass filter [31], which can perform low-pass filtering on graph signals. The low-frequency signal is retained, the high-frequency signal is filtered, and the graph signal becomes smoother. That is, the signal characteristics of each node are more similar. As shown in Fig. 5, the difference between different colors represents the characteristic difference of the node. With the increase of GCN layers, the GCN has a more muscular scaling function in the low-frequency band, which will form a more effective low-pass filter. This stacked filtering operation will distinguish between nodes worse and worse, and the representation vectors of nodes tend to be consistent. Similarly, the source node information will be masked or weakened by other node information, making the classification task of the lower layer more difficult, which is also the Over-Smooth problem often encountered by multi-layer GCNs.
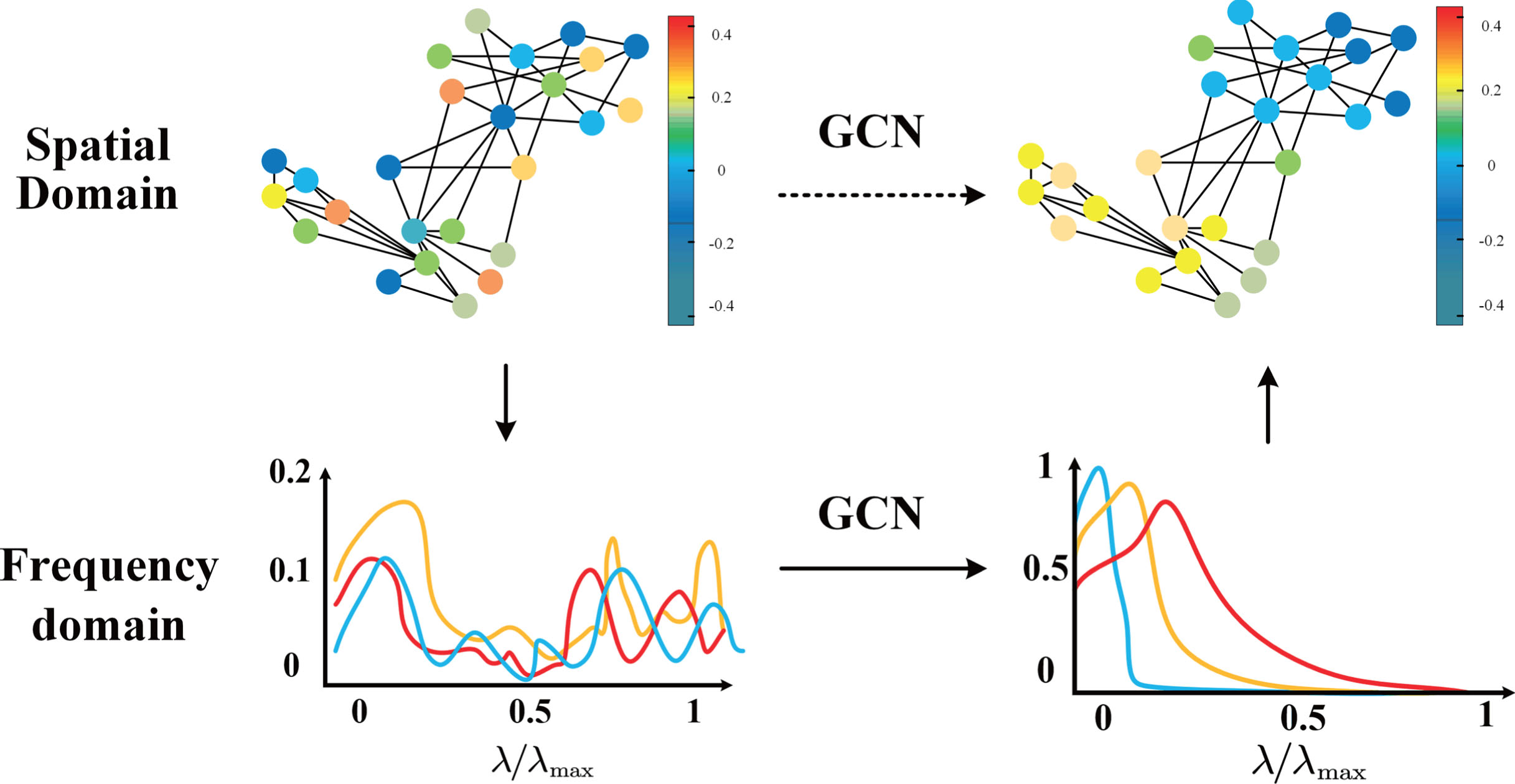
Frequency domain filtering process [32].
In this paper, the GCN module is used to aggregate local information to the source node, and then the source node is classified, which is equivalent to typing the graph. In summary, although the impact that the nodes in the same graph tend to be similar on the classification task between graphs is less, in the process of aggregating more neighbor information of the source node, it’s node information will mask by other node information in the same graph. Between different propagation graphs, the text information of other nodes besides the source node also has different degrees of similarity. And too much aggregation of this similar information is also not conducive to the graph classification task.
Source node information, source tweets are proven to contain rich data to detect rumors, would be masked or weakened by other node information, affecting the lower-level classification task mentioned in Section 4.2.2. Hence, the skip connection is adopted between the source node feature and the output feature of each layer of GCN in this paper to enhance the source node information in the hidden layer to reduce the effect, as shown in Fig. 6.
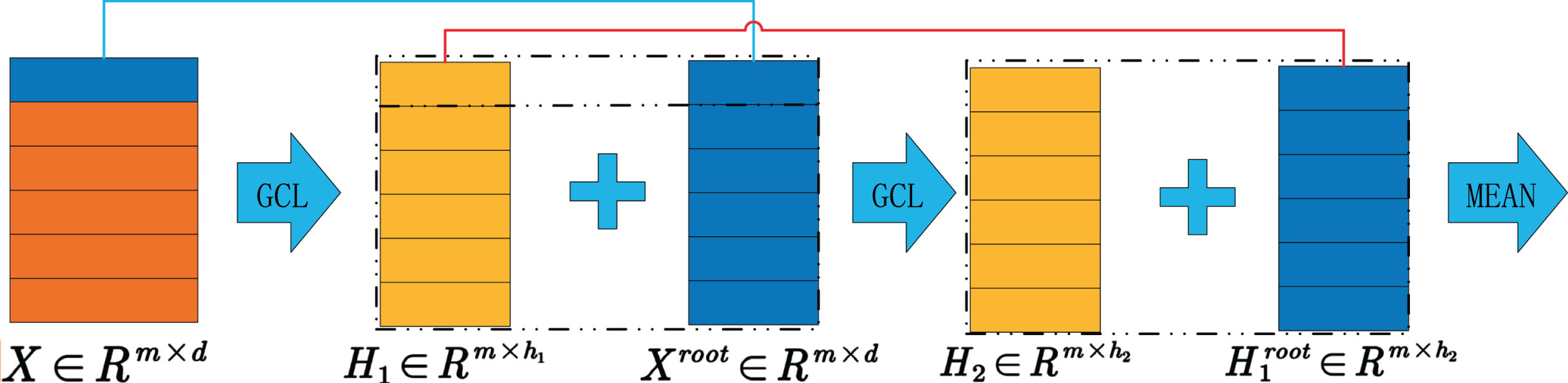
GCN module forward propagation.
From the above, the two-layer GCN forward propagation formula is obtained and shown as follows.
In this paper, the directional time series propagation information of the stand change of the post is extracted through the recurrent neural network. The source node feature is passed through a fully connected layer and then skip-connected to the final time series information representation to avoid the loss and masking of crucial information. This section presents the factual basis for extracting time series information from stance changes in retweeted posts.
Gated Recurrent Unit (GRU)
GRU is a very effective variant of the LSTM network. It has a more straightforward structure than the LSTM network and can also solve the long-term dependency problem in the RNN network. GRU turns the three gate functions of LSTM into two, i.e. Update Gate and Reset Gate. The reduction of parameters makes GRU not only train faster than LSTM but also reduce the risk of overfitting. As shown in Fig. 7, the GRU module is a neural network model formed by stacking multiple layers with GRU units as the main body. The forward propagation of each gated recurrent unit is as follows.

GRU module forward propagation.
There is a stand link between retweeted or replied tweets in the processing of rumor spreading. And stand information has been proven to be a powerful indicator for detecting rumors and other misinformation [33, 34]. Ye et al. [35] and Wu et al. [36] mentioned that rumors are more likely to be questioned than facts or that controversial claims cause suspicion, surprise, etc. Ma et al. [16] found that false rumors often lead to doubts or denials in the process of spreading, while facts often lead to support or affirmation. Even if questioning facts during the spread, questioned tweets will again lead to doubts or denials. As shown in Fig. 8, different colors represent different stands.
Based on this fact, the GRU module is applied to extract the stand changes of tweets. The time series propagation information of tweet stand changes can help us explain the characteristics of rumor propagation from another perspective.
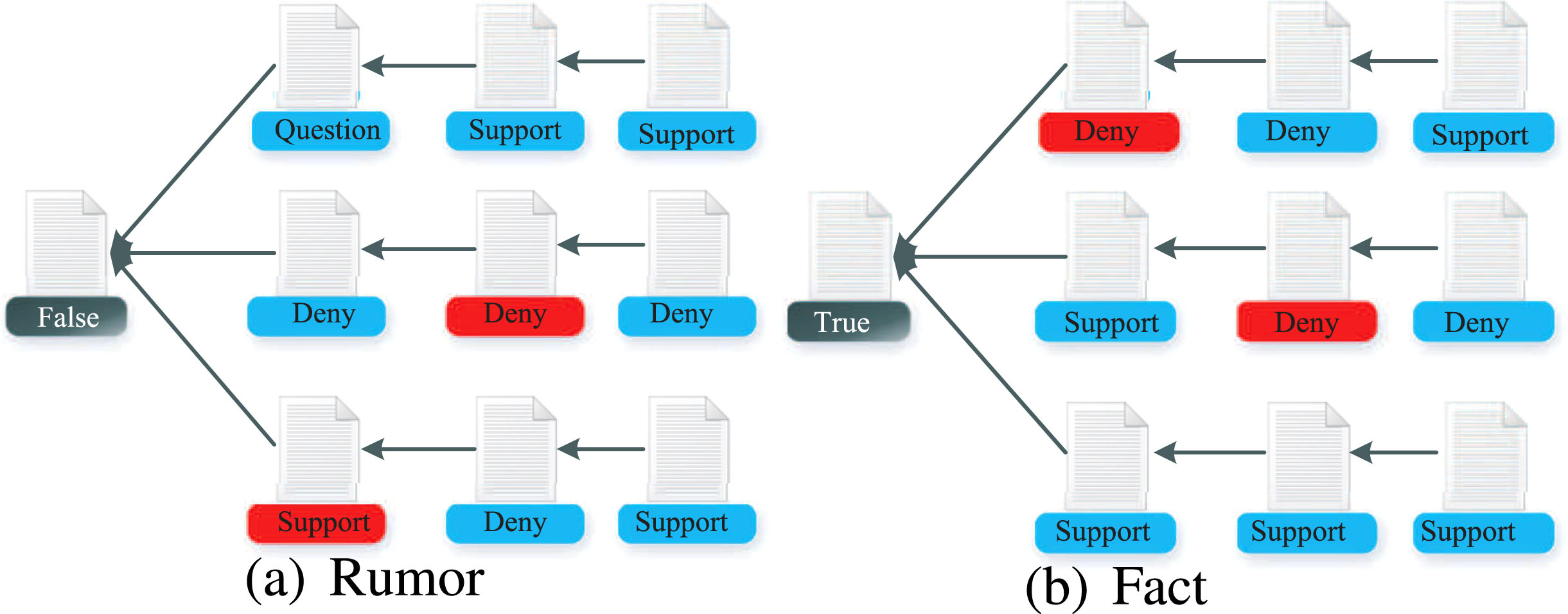
Changes in stand on retweeting or replying to tweets as rumors and facts spread.
The GRU module adopted in this paper starts from the leaf nodes of the propagation graph and aggregates the time-series propagation information upwards. The input is the text feature representation of the node itself. The hidden state of the input is the sum of the hidden states of all child nodes of the node. The initial information of the source node passes through a fully connected layer and then connects with the hidden state obtained by converging. Forward propagation is shown as the Eq.(5).
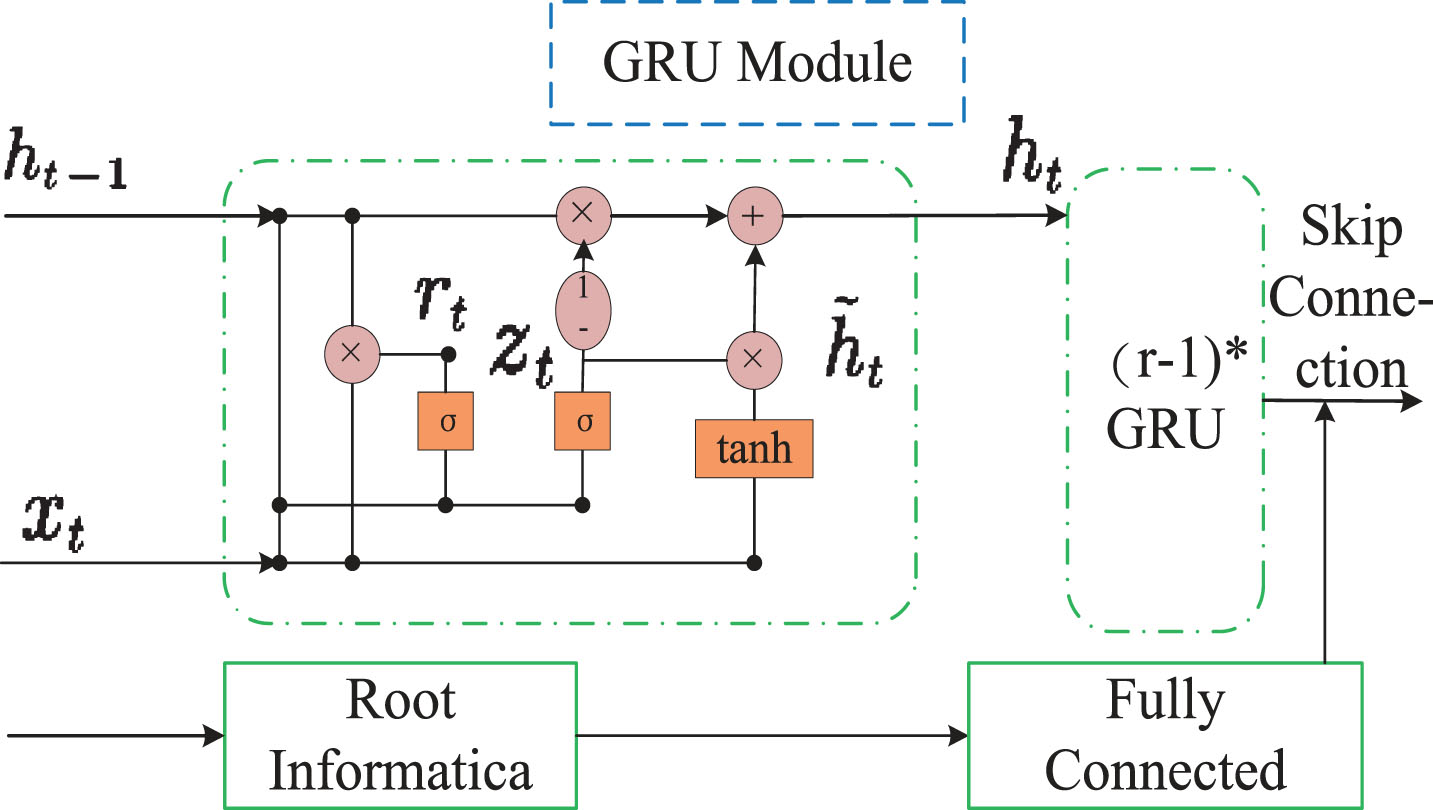
GRU module forward propagation.
The aggregation classification module combines the spatiotemporal information through a weighted connection ensemble, shown as follows.
This paper compares the performance of the SSM model with several state-of-the-art static graph baseline models on Weibo, Twitter, and other datasets, respectively. A new data collection metric for early detection is adopted on the Weibo dataset, and we test the performance of SSM under the new metric.
Datasets
This paper uses the Weibo, Twitter15, Twitter16 datasets provided by Ma et al. [24, 37]. We select the true and false rumors in the Twitter15 and Twitter16 datasets as the facts and rumors of the new Twitter dataset. And we verify the performance of SSM against other baseline models on the Weibo, Twitter, Twitter15, and Twitter16 datasets from two perspectives. The experiments on the Twitter15 and Twitter16 datasets are four-category tasks, while the experiment on the new dataset Twitter constructed in this paper is a two-category task. In particular, this paper does not directly test the performance of SSM on the Weibo dataset but re-collects the events in the Weibo dataset and the nodes in the event through new indicators to obtain the Weibo_burst dataset, and evaluates the early detection performance of the model, see Section 5.4 for details. The statistics of the four datasets are shown in Table 4. Avg. stands for average, Depth represents the depth of the tree (the path distance from the root node to the leaf node), and Size means the width of the tree (the maximum number of nodes in all orders of a tree).
Experimental Setup
The models compared in this article include as follows.
1) RvNN [16]: A rumor detection method based on a tree-structured recurrent neural network, learning the time-series propagation information of rumors to detect rumors. And this paper uses the source node information skip connection to enhance the feature representation.
2) MVAE [38]: A rumor detection model combines a Multimodal Variational Autoencoder and a rumor classifier.
3) VAE-GCN [39]: A GCN-based variational graph autoencoder fake news detection model, using GCN as the encoder and Variational Graph Autoencoder (VGAE) as the decoder.
4) AE-GCN [39]: A GCN-based graph autoencoder fake news detection model, using GCN as encoder and Graph Autoencoder (VAE) as the decoder.
5) GCN [40]: An undirected GCN model, an advanced graph representation learning method, can effectively extract the spatial structure features of rumor propagation.
6) Bi-GCN [18]: A rumor detection model based on bidirectional GCN, which extracts the spatial structure information of rumor propagation through two modes of top-down and bottom-up.
7) EBGCN [41]: A rumor detection model based on Edge-enhanced Bayesian Graph Convolutional Network, which adaptively rethinks the reliability of latent relations by adopting a Bayesian approach.
8) RDEA [42]: A rumor detection model based on social media with Event Augmentations, which integrates three augmentation strategies by modifying both reply attributes and event structure to extract meaningful rumor propagation patterns and to learn intrinsic representations of user engagement.
9) DSSM: The static hybrid model fuses directed GCN and GRU proposed in this paper. The GCN module refers to the bi-directional graph convolution model of Bi-GCN. DSSM is mainly used to verify the heterogeneity and importance of time-series information.
10) UDSSM: The static hybrid model fuses undirected GCN and GRU proposed in this paper.
The experimental environment is PyTorch. In the training process, SSM uses cross-entropy loss function and reverse gradient descent to optimize parameters and uses Early Stopping to prevent overfitting. Five-fold cross-validation is adopted; the training period is 200 rounds; the early stop period (the loss value is lower than the current optimal value for n consecutive times) is ten rounds, and the batch size is 16. A weighted connection ensemble method is adopted to solve the difference in spatiotemporal information representation and classification ability.
Overall Performance
Table 5-7 shows the performance comparison of our model and other baseline models on the four datasets. The baseline models used in this paper are all deep learning methods. From the literature in recent years, We can find a unified conclusion that deep learning methods outperform traditional machine learning methods in performance.
Rumor detection results on Twitter15 dataset (Four Categories)
Rumor detection results on Twitter15 dataset (Four Categories)
Rumor detection results on Twitter16 dataset (Four Categories)
The models’ performance with GCN is generally better shows the effectiveness of the spatial structure features of rumor propagation in rumor detection. The GCN model has excellent advantages in extracting spatial structure features.
DSSM is better than Bi-GCN, indicating that the integration of timing information provides heterogeneous information different from spatial structure information.
Most of the performance indicators of the SSM model on the four datasets are better than RvNN, GCN, and Bi-GCN. It indicates that the fusion spatiotemporal information model provides a better feature representation for lower-level classification tasks than models that only extract time-series information or spatial structure information.
Although the SSM is better in detection effect, the time complexity of model training is higher due to the integration of the time series module. As shown in Table 8, it is about six times slower than Bi-GCN on the three datasets. It’s a problem after the fusion of time series models. For example, the dynamic graph model proposed by Song et al. [27] is about 16 times slower than Bi-GCN. Although AE-GCN and VAE-GCN have low training time complexity per epoch, there are too many training epochs when using the early stop method. The reason is that the continuous decrease of the loss value does not improve accuracy. However, SSM can generally complete each fold training earlier under the early stopping method. In section 5.4, this paper will propose a solution for applying SSM to early detection from data collection to alleviate the problem of excessive training time complexity.
Model training time complexity (min/epoch)
Remark: 2The former time is the comparison self-supervised learning time, and the latter time is the training time of each epoch of the model. The same is true for the following experiments.
Existing problems
The current definition of early detection varies, and the data collection standards are also different. Zhou et al. [21] defined the earliest stage of tweet posting, when rumors have not yet started to spread, as early. Bian et al. [18] and Kwon et al. [22] used time windows to collect early data for rumor detection, which is also a commonly used method in many works of literature. Chen et al. [23] and Ma et al. [16] collected data for early detection according to the proportion or number of samples.
These indicators are insufficient in characterizing early detection, and the Weibo dataset is an analysis example. As shown in Fig. 10, it is a 10,000-nodes level propagation graph. The abscissa represents the n-th addition of 30-users nodes, and the ordinate is the time taken in minutes. If the data is selected according to the time window, for example, two hours, the number of collected nodes can reach more than 2000. From the perspective of rumor spread, the rumors have already had a tremendous impact at this time, and the significance of early detection has become weaker. However, if the time window is 10 minutes, only more than 300 nodes are selected, which seems very suitable. It is a 500-nodes level propagation graph in Fig. 11. Only about 30 nodes are collected, so we can’t extract sufficient dissemination information. In this way, the 10 minutes time window is also inappropriate. If the ratio of nodes or the number of nodes is used to collect data for early detection, it is meaningless for rumor detection because we can’t know what scale a rumored event will develop. And how can it be selected according to the ratio or the number of nodes?
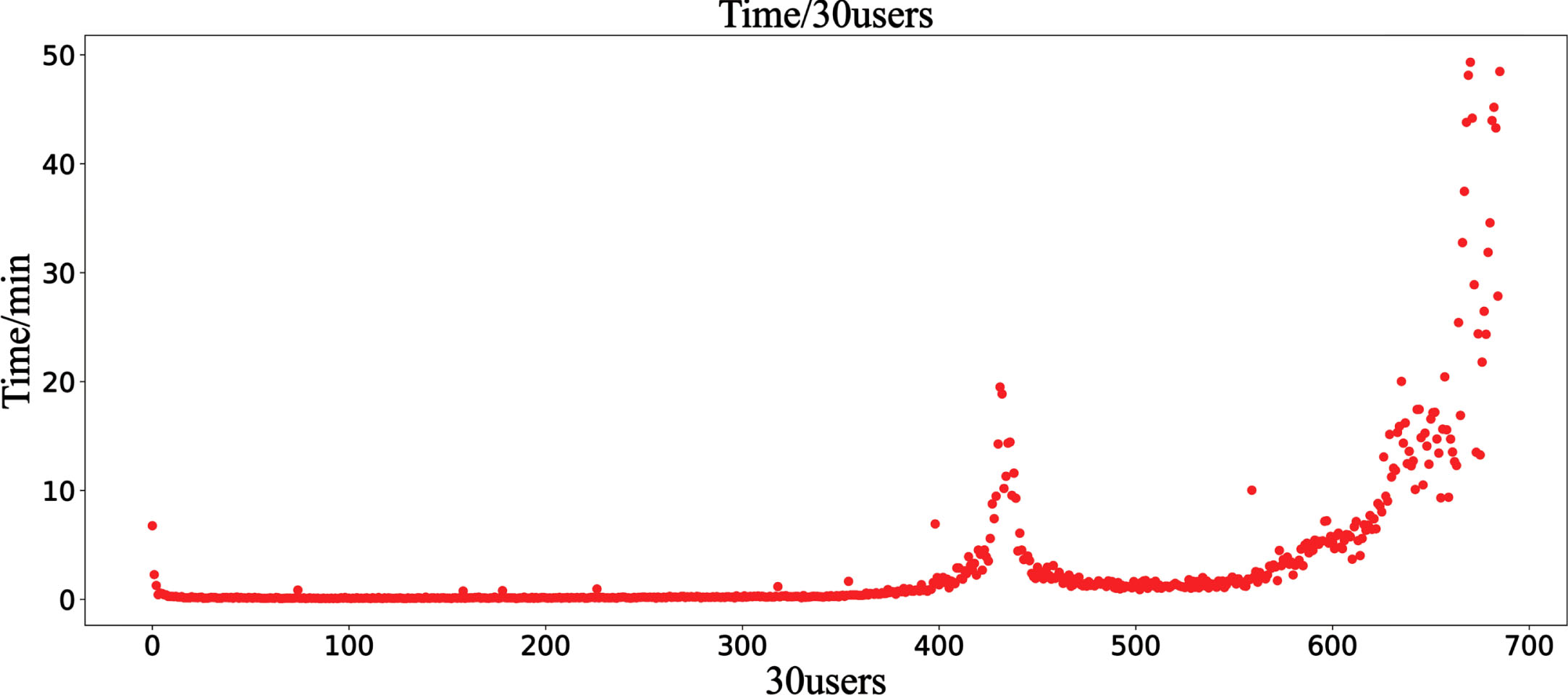
10000-nodes level propagation graph.
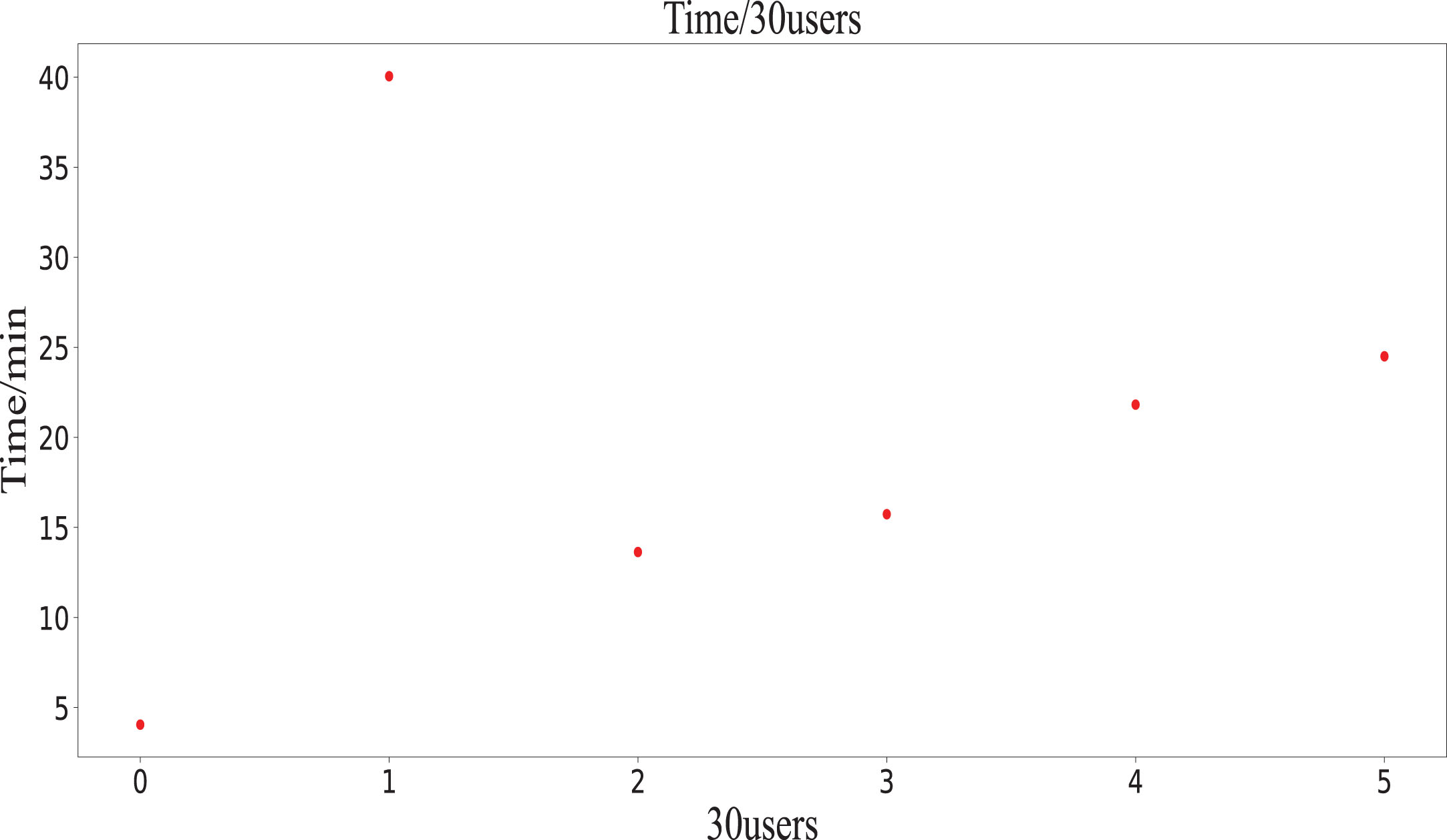
500-nodes level propagation graph.
This paper adopts a new method to select early detection data, called outbreak rumor detection.
Two metrics are first defined: N-users-time window T N and threshold baseline B. T N indicates the time it takes for each N-users participating in (repost, comment, etc.) the spread of rumors. Different types of data sets and different node-level propagation graphs have distinct user growth trends. At this time, threshold baselines can be used to select events at different levels. For example, in the Weibo dataset, measured by a 30-users-time window, compared with the overall growth trend, the period in which the 10,000-nodes propagation graph grows faster is around the 1-min baseline. In contrast, the 1,000-nodes level propagation graph is around 20 minutes.
Therefore, when the number of user nodes participating in the spread of rumors increases rapidly, and the average value of consecutive M times N-users-time window T N is lower than B, the current observation point enters the outbreak period. All nodes before the observation point are selected for early detection. There are three advantages. Firstly, data is selected according to its growing trend, and more finer intervenes in the early stage when rumors spread faster. Secondly, rumors spread fast and have a significant impact, can be found. Thirdly, propagation nodes can be obtained in a controllable manner, as the number of nodes for most collected events is around a fixed value. A smaller number of nodes reduces the training complexity of the model proposed in this paper and makes up for the shortcoming of a long training period. The new indicator is suitable for early detection.
The settings of M, T N , and B are determined in combination with the data type, the real-time detection capability of the device, the impact degree of the event concerned, and the number of nodes that need to aggregate information. As shown in Table 9, Graph Size is the scale of the event (the total number of participating user nodes), Num. is the number of events (or samples) of the scale and the indices, and Mis. represents the missed detection rate of events of the scale and the indices. Different settings of M, T N , and B will affect the collection of nodes in events of different scales. In general, using several indicators in Table 9, events above the 500-nodes level can be well screened, the missed detection rate is low, and different indicators bring slight differences. At the same time, the number of nodes collected through various indicators is different, and most of them are determined according to the value of M and T N .
The settings of M, T
N
, and B
The settings of M, T N , and B
Remark: 1 The left side of ’:’ represents the number of nodes collected from the event, and the right side represents the number of events collected to this node number.
This paper selects indicator T30 ≤ 30 (M = 3) to perform early detection of rumors in the Weibo data set, and the new dataset collected is named Weibo_burst. Some primary conditions of the collected data are in Table 10, and the ratio of the two types of samples is about 1:1.8. The comparison results with each baseline model are in Table 11.
Statistics of Weibo dataset under new data collection metrics
Statistics of Weibo dataset under new data collection metrics
Early detection results on Weibo_burst dataset
As shown in Table 11, UDSSM outperforms several state-of-the-art static graph models in all aspects. We also tested the performance of the UDSSM model on the initial Weibo dataset. But compared with other models, the improvement effect is small, not as good as the Weibo_burst and Twitter data sets. It shows that UDSSM can extract much sufficient information than other models in early detection or events with fewer nodes. Moreover, under the new index, the time complexity of the UDSSM model is reduced from 75.13 minutes to 3.97 minutes. Still, the accuracy has not dropped much, indicating that the UDSSM model has a significant advantage in early detection.
This paper proposes a static graph mixture model that can effectively fuse spatiotemporal information, called SSM. It can simultaneously extract the spatial structure information and time-series information of rumor propagation. And the two kinds of information and textual semantic information are combined effectively to provide better feature representation for lower-level classification tasks. Results on two classification tasks in four datasets show that the proposed model outperforms several state-of-the-art static graph models overall. This paper also analyzes the rationality of using two-layer GCN in the GCN module from the spatial and frequency domains combined with data analysis, which is different from the experimental verification in other literature. In addition, a new data collection index for early detection, called outbreak rumor detection, is also proposed. It can describe early detection in a fine-grained manner, intervene in the evolution of rumor propagation on time, and screen events that spread quickly and have a more significant impact. Besides, our data collection index proposed in this paper makes up for the shortcomings of the model and reduces the time complexity.
Footnotes
Acknowledgments
This work is supported by the National Natural Science Foundation of China under Grant (No.61803384).