
Abstract
Social networks have accelerated the speed and scope of information dissemination. However, the lack of regulation and freedom of speech on social platforms has resulted in the widespread dissemination of the unverified message. Therefore, rapid and effective detection of social network rumors is essential to purify the network environment and maintain public security. Currently, the defects of rumor detection technology are that the detection time is too long and the timeliness is poor. In addition, the differences based on specific regions or specific fields will lead to deviations in the training dataset. In this paper, firstly, the definition of rumor is described, and the current problems and detection process of rumor detection are described; Secondly, introduce different data acquisition methods and analyze their advantages and disadvantages; Thirdly, according to the development of rumor detection technology, the existing rumor detection methods of artificial, machine learning and deep learning are analyzed and compared; Finally, the challenges of social network rumor detection technology are summarized.
Introduction
With the explosive development of social networks, social networks such as microblogging and Twitter have gradually replaced traditional media as an important platform for people to publish and obtain information. According to statistics, social media around the world are generating a lot of new information every second, as shown in Fig. 1. Social networks have greatly accelerated the speed and depth of information exchange and brought great convenience to people’s lives. However, the lack of effective supervision over information on social network platforms has also led to the proliferation of online rumors. The spread of rumors and their constant amplification and distortion in the process of transmission mislead society and individuals, affect people’s daily life and social harmony and stability, and pose a major threat to national security. In the 2016 U.S. presidential election, nearly 529 different rumors about candidates spread through Twitter and Facebook, with a greater impact on voters [22]. Rumor detection is a text classification problem facing massive data. Because the amount of data is very large, the detection process needs the help of the machine. Machine learning refers to training models that can complete certain functions through data. It is one of the most important means to achieve artificial intelligence. The process of machine learning is to learn from the input data sets (called samples or training data), use different algorithms to identify the internal relations in the data and establish a mathematical representation model. Finally, we can use this model to predict or make decisions on the subsequent data sources of the same type, so as to achieve machine intelligence. Machine learning can save a lot of time in rumor detection. Deep learning has a strong feature learning ability. Its model learning features are better and more essentially representative of the original data than the feature data obtained through feature engineering in traditional machine learning algorithms, which can achieve better classification results.
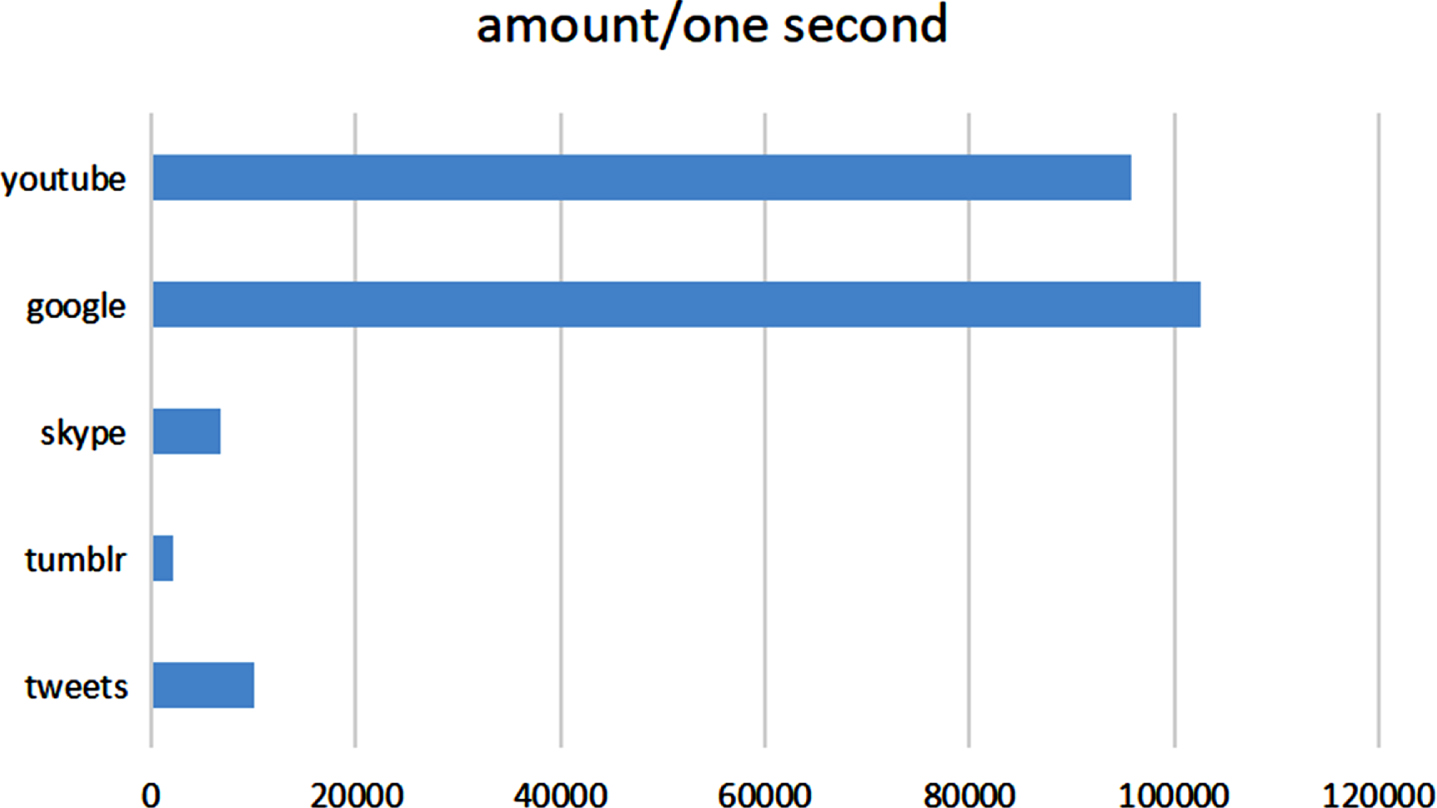
The amount of new information added to social platforms in one second.
Currently, the research on rumors detection in social networks is mainly divided into manual detection methods, detection techniques based on network structure, machine learning (ML) and deep learning (DL). Manual detection methods have high accuracy rates but considerable time and labor costs. Manual detection lags and cannot adapt to social networks’ vast amount of data. Machine learning methods view rumor detection as a binary classification problem in supervised learning, which effectively compensates for the shortcomings of manual methods but relies on manual feature extraction and selection. As the problem of rumor detection has been widely concerned in today’s society, more and more scholars have devoted themselves to the research. The research on various processes of data collection, labelling, model selection and model training in social network rumor detection cannot fully reflect the status of social network rumor detection technology. Meanwhile, there are few descriptions of rumor detection methods based on deep learning, which have developed rapidly over recent years. In summary, the existing review on social network rumor detection technology focuses on the research on the model, ignoring the data collection and rumor relationship in the detection process. Meanwhile, due to the limitation of technical development, the past reviews lack a comprehensive summary of the latest progress of the rumor detection problem, especially the application of deep learning.
This paper first gives the definition of social network and rumor, and summarizes the problems and solutions in the process of rumor detection from three aspects: rumor propagation trend, development of existing technology and rumor detection. The main contributions of this paper are: The dataset open to the public is presented to validate the proposed new approach against the previous model; Analyzes how to collect data from the massive amount of social network data and summarize the possible problems of existing methods; In the part of feature extraction and selection, the features used in the existing research are introduced and compared. They are divided according to content-based features and social environment features, and the impact of features on the model effect is analyzed; This review introduces the new social network rumor detection models in recent years, especially the emerging DL methods, complements and perfects the research status of rumor detection, and compares and evaluates them with previous research methods; Proposing future research interests in deep learning for rumor detection.
Section 2 of this paper summarizes and identifies the basic concepts involved in social network rumor detection research; Section 3 introduces the available datasets and other ways of data acquisition and processing; Section 4 describes various technical tools used for rumor detection based on methods, performance, tools, and architecture; Section 5 then further summarizes the challenges of current social network rumor detection research and provides future research perspectives; finally, Section 6 concludes the paper with a summary statement of the whole article.
Social network
The rise of social networks has continuously changed people’s habits of using the Internet. Its development exceeded people’s expectations. With the rapid growth of mobile Internet users and the rapid rise of mobile apps, humanity has entered the era of information flow, and the information production model has shifted from PGC (Professionally Generated Content) to UGC (User Generated Content) [34]. The essential elements of social networks are Users (everyone who participates in an online social network), Links (link relationships established between each user account), and Groups (groups of users clustered according to specific interests). There may be links between users and users, groups and groups, and users and groups, and this link has bidirectional properties [6]. It provides a service that human beings can participate in anytime, anywhere, and people can openly communicate and talk with others regardless of distance. Social networks have greatly accelerated the speed and depth of information transmission.
Rumor
Rumors have been extensively studied over the past decade and are a special kind of information that has been around for a long time [33]. The researchers provided different explanations for rumors. It refers to information spread in large quantities on the Internet without being confirmed by official teams. In summary, rumors have the following characteristics: (1) they spread among people; (2) they are specific statements of information about something or an issue in society; (3) they often contain more personal and subjective ideas; (4) they may be true, partially accurate, or completely false, because they are always unconfirmed [5]. There are usually several rumors about the same event or topic. Various factors can classify a rumor into different grades, such as its type, value or grade.
Based on the above analysis, this paper defines social network rumors as those generated on the social network platform, whose content has not been verified by the authority or has been officially declared as false, and which have spread in the social network and caused a certain impact on social public opinion. This article defines the composition of social network rumors as shown in Fig. 2.

Composition of social network rumors.
The purpose of rumor detection is to judge the authenticity of a piece of information. The first stage of this process entails mining the salient features in social network information. Table 1 shows the features selected by the researchers for rumor detection. Feature selection is the key to rumor detection and dramatically impacts the detection results. In previous studies, the rumor features selected by researchers have been somewhat differentiated. For example, early researchers focused on textual features. As the form and content of information posted on platforms shifted, they add the study of features in images. Most studies focus on textual and temporal features when researchers began using DL methods for rumor detection. This paper classifies the features currently used for social network rumor detection as shown in Fig. 3.
Common feature types of rumor detection models
Common feature types of rumor detection models
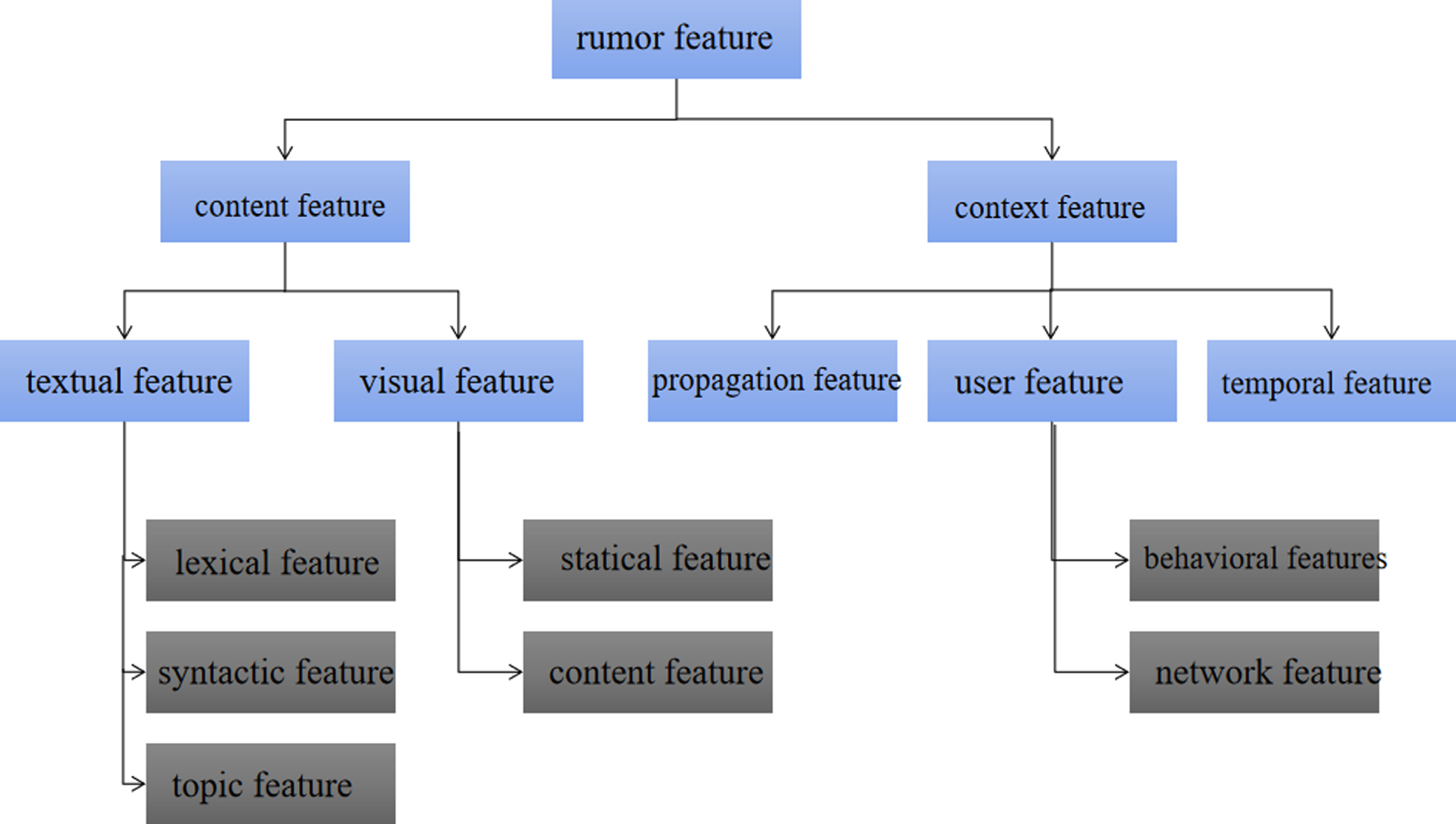
Classification of rumor features.
Social media rumors are rich in variety and have many more differences than traditional rumors. Social network rumors contain a lot of multimedia content such as audio and video. Content features are extracted from images and texts.
-Textual features
Scholars use natural language processing technology to mine and process the text of rumors. Since rumor texts contain words, sentences, and topics, rumor detection using the textual features of rumors can be further refined to utilize its lexical features, syntactic features and topic features. Manan Vohra and Misha- Kakkar in 2018 used the LDA algorithm for topic feature extraction and textual feature extraction for rumor detection [47]. Based on the work of different researchers, this paper collates specific models for the application of these three features.
With word-based extraction, one model uses the total number of words and characters, the total number of unique words, and the average length of words to accomplish the task of rumor detection. Other researchers have taken the sentence dimension and selected the number of keywords in the sentence, sentiment score and lexical annotation [20]. The Bag of Words (BOW) model is the best known of these [31]. Benjamin et al. used two simple BOW representations for text input: term frequency and term frequency inverse document frequency [36]. Topic features are used for rumor detection, focusing more on understanding textual information and its relationships in the corpus. For example, the potential Dirichlet distribution classifier is trained for 18 topics [26].
Rumor detection methods based on textual features are common approaches in early rumor detection, such as the pioneering researcher in rumor detection, Castillo [7]. Refine textual features into string length, number of words, whether it contains punctuation (question marks, exclamation marks, etc.), whether it includes emoticons, personal pronouns (first person, second person, third person), number of capital letters, time of publication, number of positive words, number of negative words, whether it contains tags, whether it contains links.
-Visual features
Pictures or videos may accompany rumors in social networks, and just a video or a picture contains a rumor. Therefore, the visual feature of rumors cannot be ignored entirely in the process of classifying whether the information in social networks is a rumor or not. The visual features of rumors can be divided into visual statistical features and visual content.
A rumor detection study mines time-series features from images to point out that rumor content contains outdated images [44]. Using visual content as a feature, mainly from the perspective of graphics, to explore the information contained in the picture, like the clarity and consistency of an image.
Social context features
-Propagation features
Takahashi et al. [20] studied the spread of Twitter. Rumors have been found to have a characteristic of exploding retweets in a short time, with much higher retweet rates than regular tweets. Most false rumors can be identified not only by the content of the false rumor but also by how people react to it and who those people are. The pattern of dissemination, combined with the subject matter of the thread and the sentiment of the user response, can be a strong indication of whether the original message is true or false. Internet rumors can be traced back to the source of propagation in the network because of their specificity. Some research has used the network features of comments and retweets for rumor detection or proliferation forms.
The pattern of information dissemination in social networks can be modelled as a tree that reflects not only the relationship between retweets and their authors but also the temporal behavior and sentiment of retweets. The most superficial characteristics of propagation in Twitter and Weibo are the number of message retweets and comments. They can be seen as a reaction behavior of users to the message. In addition to the number of retweets and comments, propagation features also include the content and timing features of comments attached to retweets. A recently emerged feature of the propagation process is sentiment consistency, which refers to whether the sentiment tendency of a post is consistent with the sentiment tendency expressed in the comments.
-User features
The most crucial factor that cannot be missing in spreading rumors on social networks is people. User features are mainly about the essential features of users in social networks [4], such as their age, gender, education. Users’ behaviors on social platforms are the behavioral features of users. These behaviors include users’ posting, liking, commenting and other behaviors, reflecting users’ activities and historical behaviors. The longer and more frequently users register on social platforms, the easier it is for them to identify the authenticity of the information. It can be seen that the more messages users post, the less likely they are to post rumors. Users’ network features refer to their relationship networks, which can be used as a basis for determining whether a user is likely to post rumors. A detailed description of the features used for social network rumor detection is shown in Table 2.
Features used in rumor detection models
Features used in rumor detection models
According to the research process of implemented rumor detection technologies in the past decade or so, it is easy to see that the process of rumor dataset formation is crucial. This formation process can be roughly divided into two steps: data collection and processing. Social network rumor data collection and processing is very important as the first step in implementing the technology model. The content and quantitative quality of the dataset play a key role in the subsequent work, and a good dataset can make the model training results twice as good with half the effort. Therefore, this review collates and analyzes existing datasets and other data collection methods, as well as data processing methods that other researchers have used.
Data collection
The following four aspects need to be focused on in data collection: collection platform, collection content, collection quantity, and collection method. Regarding the number of data collected, the main focus needs to be on the number of rumor topics, messages, and the ratio between rumors and non-rumors. Regarding the data collection methods, this review will compile and compare the existing public data sets and data collection methods.
Available public datasets
In the decade of booming rumor detection technology, a large and rich dataset has been generated for researchers to use. This review will present some public datasets from social networks of excellent quality. A description of the publicly available rumor datasets is shown in Table 3.
Publicly available rumor datasets
Publicly available rumor datasets
-CREDBANK
A corpus designed to bridge this gap by systematically combining machine and human computation. CREDBANK contains over 60 million tweets in total [32].
-MULTI dataset
This dataset was published in 2017 and contains message posts collected from Sina Weibo between May 2012 and January 2016. It is a multimedia dataset containing images [13].
-Media Eval
This dataset contains about 9,000 rumor and 6,000 non-rumor tweets from 17 rumor-related events. This dataset can find the text content, additional images or videos, and several social contexts for each tweet [13].
-FakeNews Net
The FakeNews Net [39] is one of the most comprehensive fake news detection benchmarks.It contains 24,000 articles about content in social contexts, including user reactions and comments. It collects fake and factual news articles from fact-checking sites PolitiFact and GossipCop. The real tags of the news articles are provided by experts, ensuring the quality of tags.
-Emergent
Emergent is a new dataset from the Digital News Project for rumor debunking. It contains 300 rumors and 2,595 related news articles, collected and tagged by journalists. Each relevant article is summarized into a headline and labeled to indicate whether its position is supportive, opposing, or neutral. Emergent provides a real-world data source for various natural language processing tasks in a fact-checking context.
In the rumor detection technology research, reasonable and adequate use of existing public data sets will reduce a certain amount of workload. However, if oriented to the latest social events or social news, the existing data sets cannot meet the detection of new fields and new rumors due to the different environment and background. So at the same time, we need to combine other data collection methods to improve and enrich the data used in the training of rumor detection models. From the experience of previous studies, it can be summarized that typical other data collection methods are data collection through Application Program Interfaces (APIs) provided by social platforms and crawlers.
-APIs
In the past part of the research on rumor detection technology, researchers have used Representational State Transfer (REST) APIs provided by social platforms to collect the required web data on social networks. Currently, the main social platforms using APIs for data collection are Twitter and Sina Weibo. However, researchers are more interested in collecting textual data related to rumors on these social platforms. In the face of today’s booming short-video social platforms, no systematic rumor dataset has been generated, but they provide APIs that can collect data.
-Build crawlers to collect data
While it is convenient to use APIs for data collection, sometimes researchers facing special needs and problems also need to build their crawlers to collect data. Using a web packet capture tool, the login protocol, data request process, and the correspondence between each request uniform resource locator (URL). Data are analyzed according to the features of social platforms. Then, the program is implemented to simulate the login process to the web page by obtaining cookies and creating sessions. After the simulated login, the tweet information of the logged-in user is used as the seed set to complete data collection and analysis using the get method via Hyper Text Transfer Protocol (HTTP).
The advantages and disadvantages of different data collection methods are compared as shown in Table 4. Compared with building crawlers to collect data and collecting data through APIs provided by social platforms, the outstanding advantage is that researchers can get the data that best meets their research work. Because sometimes the APIs provided by social platforms have limitations. For example, Sina Weibo’s API can capture 2000 user comments under a tweet at once. And it cannot get the user comments collapsed among the comments, which often results in huge data loss. The crawler method simulates the process of ordinary users browsing information through the program using a client such as a browser. Using this method, researchers can obtain data that meet specific needs, and can define the format and content of the data themselves. This method is not restricted to the official collection method, and can acquire data efficiently and comprehensively. However, building a crawler also has some defects that cannot be ignored. First, the crawler technology is relatively difficult. Second, the use of crawler means to collect data may face legal risks. But the advantage of using the API provided by social platforms to collect data is that it is simple and fast.
Comparison of data acquisition methods
Comparison of data acquisition methods
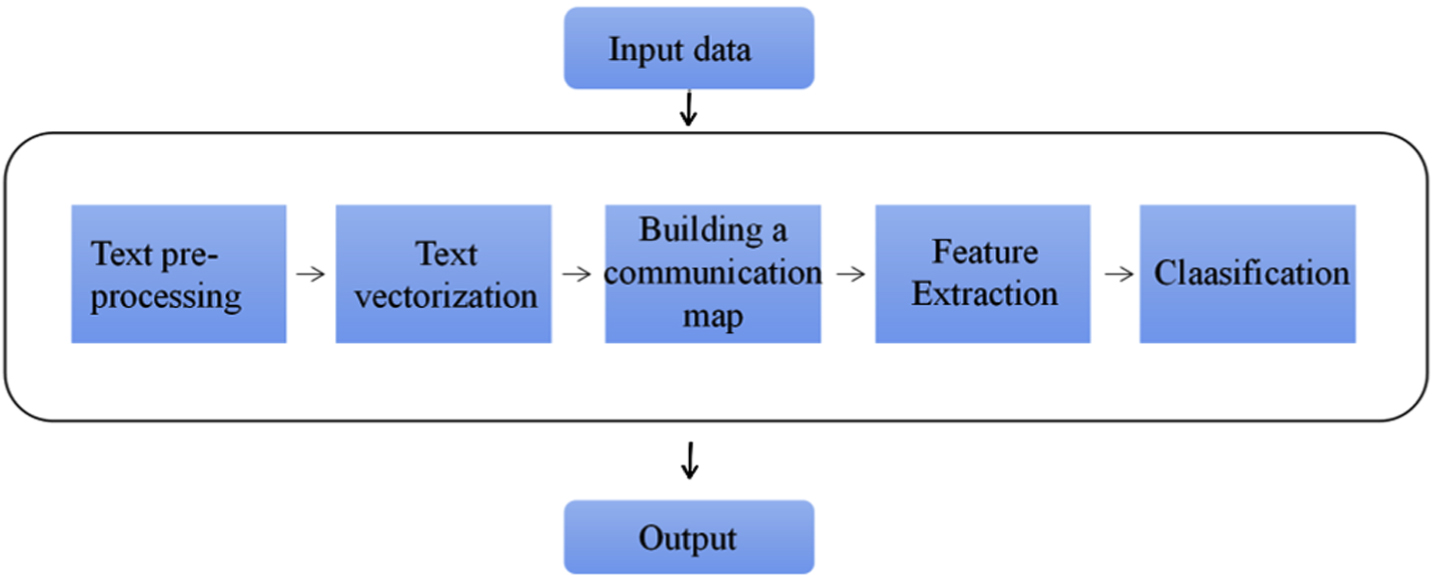
The first-hand data obtained during the experimental process often cannot be used directly, and requires some data processing, including denoising, word separation, feature downscaling and text similarity calculation. Sometimes it is also irreplaceable to represent the text as a vector and other data suitable for processing by ML algorithms.
The data extracted from Twitter or Weibo contains URLs, topic hashtags, @, emojis, special characters. Researchers need to pre-process this data and then use the cleaned data to input the model. The text data is processed by removing URLs, topic tags, @, emojis and punctuation using regular expressions. Another important task that needs to do in the data processing phase is to remove duplicate posts from the dataset.
In the process of binary classification of rumor detection, in order to train a classifier for rumor detection, it is necessary to use labeled data sets for model training. Currently, manual and semi-supervised learning-based annotation are the methods that enable data. Manual labeling is to have some experts label the rumors in social network data, which requires human understanding and judgment of the rumors to avoid cognitive errors, and then given to the machine for learning. The semi-supervised learning-based labeling method introduces a CERT framework under the condition of manually labeling a small amount of data, and achieves classification through machine clustering, feature selection and training of the data.
Rumor detection methods
Most of the current social network platforms use manual rumor detection methods. However, due to the advent of the significant data era, the information in social networks has long exceeded billions. Therefore, many automatic rumor detection methods have been proposed in recent years. ML: Researchers apply manual features to characterize the distribution of rumors in high-dimensional space. Feature extraction and selection is an inevitable step in machine learning. These methods extract features from the textual and visual content of rumors. Network Method: This method uses several heterogeneous structured social network features and a graph-based optimization method to evaluate network credibility. DL: This method automatically learns and fuses multimodal features. The DL method does not require any feature selection because the classifier learns and acquires the required features during the training phase. The method based on DL offers many unexpected effects, including significantly improving performance and eliminating the tedious feature extraction process.
Manual rumor detection method
The concentration platforms of false rumors can be mainly divided into three categories: first, social media, especially social media platforms represented by Sina Weibo, Twitter and Facebook; second, quick video platforms, such as short video media like Jitterbug and Racer; and third, traditional media, which are represented by forums, blogs and posting bars. The manual rumor detection mainly refers to handing over suspicious and uncertain information to experts or other professionals, who will judge and identify the accuracy and authenticity of the data.
The current rumor detection provided by social network platforms are mainly manual methods. Sina Weibo has an official rumor-debunking account, which has been updated daily on the microblogging platform since 2010. It also provides monthly, quarterly and annual summaries of rumors on Weibo, including rumor statistics and rumor posting accounts.
Facebook provides an interface for users to submit suspicious information to the platform, and Facebook screens the information reported by users using traditional media. For example, during the Newcastle pneumonia period, Facebook will put a “Fact-check” tag after the headline of correct information that a third-party professional organization has verified, as shown in Fig. 4. Rumors that have been reposted in large numbers are overlaid with a gray module that says “Certified False Information” as shown in Fig. 5 and allows users to view the official explanation. Similarly, some video platforms offer a script complaint platform where content reviewers review videos as users upload them. Viewers can also file rumor complaints against videos, which professionals then judge.
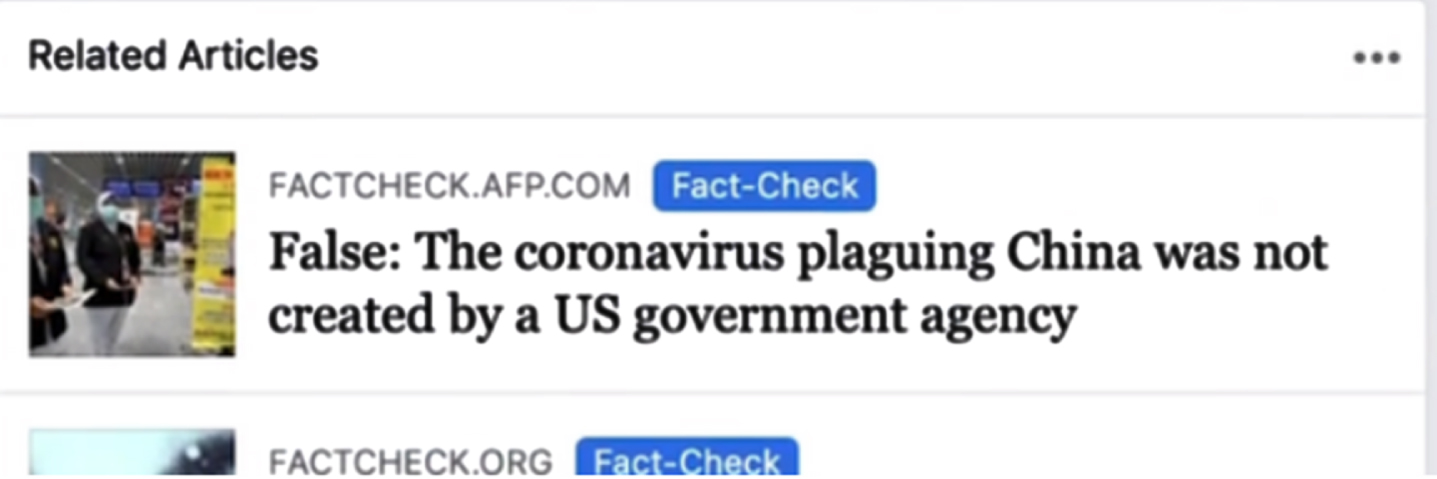
Rumors confirmed by Facebook.
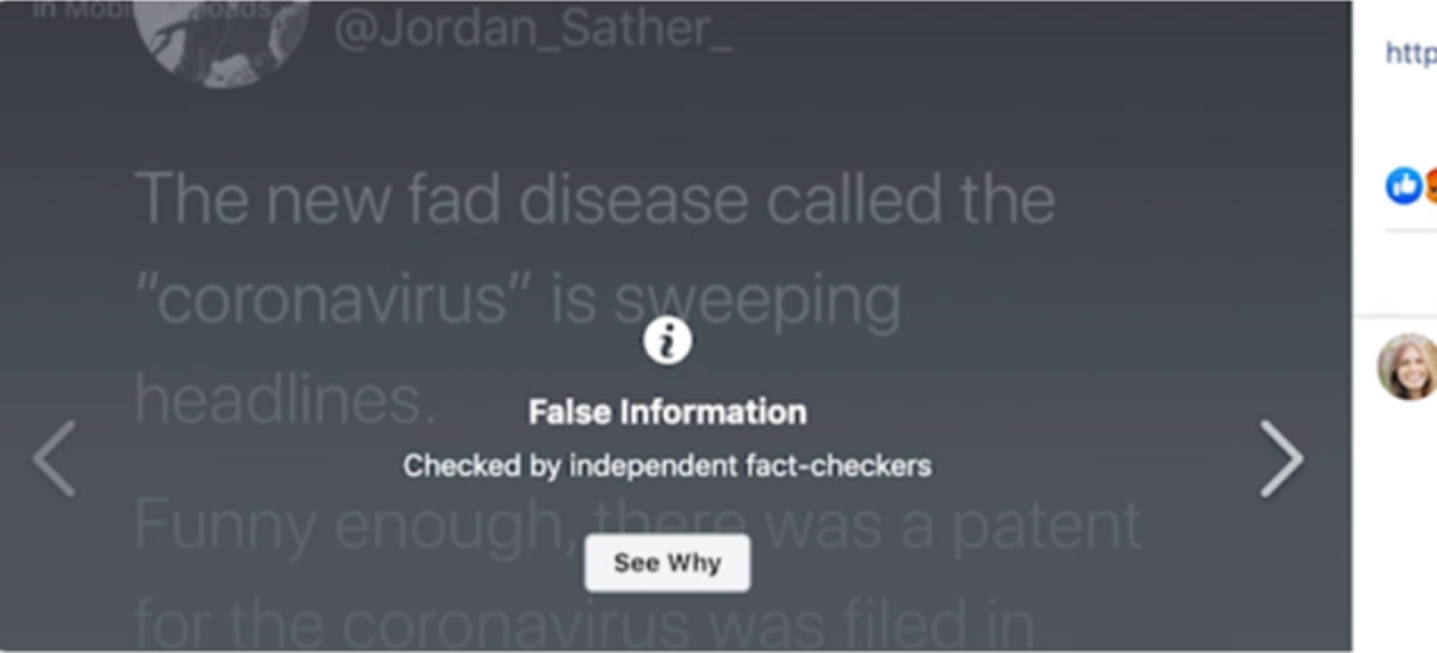
Authentic information certified by third-party institutions.
The advantage of the manual rumor detection method is the high accuracy rate. The probability of misjudging rumors is greatly reduced because it is handed over to professionals for review and screening. However, the disadvantage is also apparent. The manual rumor detection method needs to be initiated by netizens during the rumor spreading process before it can be submitted to the platform, after which time is needed for identification. Therefore, the manual rumor detection method takes much time, and rumor detection has an intense lag. During this delay, rumors can spread to a specific scale and cause more damage. In addition, the manual detection method may have the possibility of missing rumors, and it is impossible to process all network data manually alone.
Currently available rumor detection techniques treat it as a classification task. They extract information features from users, content and propagation features. A classification algorithm is chosen to train the classifier, and the trained classifier is used to determine whether the blog post is a rumor. Early machine learning-based rumor detection methods mainly consisted of the following processes: feature extraction, training a classification model using the extracted features, and using the trained model to make predictions on other data. The general process of rumor detection method based on machine learning as shown in Fig. 6. Through the comparison and analysis of different machine learning methods, it can be found that the selection and extraction of effective features are very important for classification algorithms, and their importance even exceeds the selection of classification models to some extent. The development of rumor detection technology based on machine learning is shown in Table 5. Although the hierarchical structure combined with rumors can make up for some shortcomings based on the features of a single tweet, its essence is to manually select and extract features. Therefore, there are still common problems in feature extraction in machine learning: (1) It is difficult to obtain high-dimensional, complex and abstract feature data. (2) An attempt is made to use a set of general feature sets to represent all the information in different languages on different platforms of the social network. The trained rumor classifier is easy to fall into the “over fitting” state, and the accuracy of the model is not high. (3) All experiments are conducted on the data set selected by the researchers themselves, which cannot effectively reflect the role of the newly proposed features in rumor detection on different platforms and data sets. The comparison of different machine learning models is shown in Table 6.
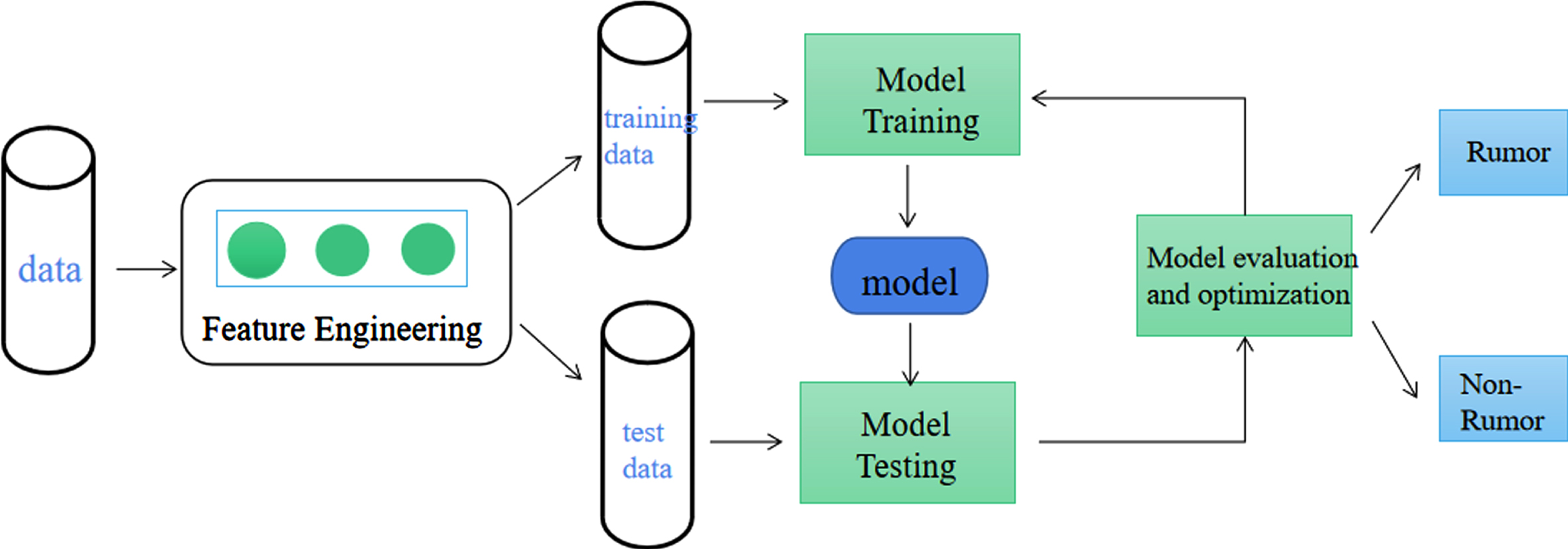
The general process of rumor detection method based on machine learning.
Development of rumor detection technology based on machine learning
Comparison of different machine learning models
The researchers determined the features of rumors by studying the time, structure and language of rumor propagation, and identified key differences between rumor and non-rumor propagation. It was found that random forest results would be better compared to other algorithms, with an accuracy rate of about 90% and a recall rate of about 89% [27]. Other researchers explored the task of automatically classifying rumor positions expressed on the social networks. Using a dataset of more than 4,300 manually coded tweets, they constructed a supervised random forest model for the task, achieving an accuracy of more than 88% across a variety of rumor types [58]. The researchers propose a new set of features specific to the automatic recognition problem for Twitter’s shorter texts. These features significantly improve the accuracy of the classifier and achieve results described above on a recent benchmark dataset. It enables the classification of short texts using a random forest model without known feature extraction [2].
Hidden Markov model
In 2015, Vosoughi S [49] tested various models to detect and verify Twitter rumors. Detecting different rumors is achieved by clustering the asserted arguments about the facts. The researchers trained two HMMs, one with observed data about false rumors and the other with observed data about true rumors.
To predict the truthfulness of rumors, Vosoughi S et al. determined the salient features of rumors by studying three aspects of information dissemination: the linguistic style of the rumor, the features of the people involved in spreading the information, and the characteristics of network transmission [48]. The predictive accuracy of the time series of these features extracted from the Twitter dataset was generated using a Hidden Markov Model (HMM). The model was trained and tested on 209 rumors (113 true, 96 rumors) and the algorithm was able to accurately predict the truthfulness of 75% of the rumors [31]. And they compared the performance of the HMM model relative to four baselines. These baselines are: a majority classifier, a forwarding classifier, an N-gram classifier, and a baseline based on The classifier trained with the features Castillo et al. [17] used, called CAST.
Logistic regression
The researchers used a logistic regression classifier and developed features to check titles and their consistency with statements, achieving an accuracy rate of 73% [16]. Other researchers then developed a classification model using multiclass logistic regression and showed how features other than the usual bag of words used could be helpful. Compared to an RTE system trained on the same data, the accuracy was improved by 26% [16].
SVM
SVM algorithms are widely used for classification and regression tasks. The support vector machine algorithm uses a straight line or a hyperplane to classify statistical data into different classes. Most studies chose Twitter as the premise of the study before 2012. Yang et al. [26] studied the trustworthiness of microblog messages for the first time. The features they chose to extract from microblogs include: content features, user features, location features and two new propagation features. The researchers first considered the first three features, trained the SVM classifier using the RBF kernel function, and then used only the account-based features. They introduced account- and location-based features into each of the three basic features to investigate their effectiveness. Using the same SVM classifier and the same RBF kernel function, the classification accuracy was improved to different degrees. The clear advantages of combining these two newly proposed features into the classification task are shown.
After this, a team of researchers trained the SVM on various content-based features and obtained an F1 score of 87 [37]. Their contribution demonstrates that discourse structure analysis is an essential method for automatic rumor detection and an effective complement to lexical-semantic analysis. In 2015, researchers constructed Radial Basis Function (RBF) kernel vectors by selecting a dataset on Sina Weibo and extracting 23 features from it after building a message propagation tree, with an accuracy of 91% for SVM [26]. But the limitation is that some of these features are specific to the microblogging platform. In 2016 another group of researchers used content-based features for SVM detection with an accuracy of 93% [8].
Decision tree
In 2011, Castillo selected four types of features and used the J48 decision tree classifier to implement the reliable detection of messages on Twitter with an accuracy of 89% [7]. Bodnar et al. used user features to check the trustworthiness of users through a decision tree with an an accuracy of 75% [5]. Other research groups have used six classification methods for rumor detection and found a 96% accuracy rate for rumor accuracy classification using decision trees [17].
LDA
The researchers put forward the features of topic type, user type, average emotion and forwarding time, and extracted the topic of the message through Dirichlet distribution. The probability distribution of the topic in the message can be obtained through Equation 1. β1,k represents all topics from 1 to K, β i represents the distribution of the I th theme word, θ d represents the proportion of topics in the d th message, zd,n represents the subject of the nth word in the d th message, and wd,n represents the nth word in the d th message [47].
Traditional ML methods rely on feature engineering, which requires a lot of human and material to select the appropriate feature vectors. Therefore, researchers have turned to DL-based approaches to overcome the problem of ML classification. DL algorithms belong to the domain of ML, more precisely to the class of artificial neural networks (ANN) with many hidden layers. Deep learning has a robust feature learning capability. The features trained by the deep learning model are closer to the original data, and these features are more representative. This section first highlights the purpose of using DL models and then, taking the development of deep learning-based rumor detection techniques as a clue, details the existing DL models on rumor detection. The representative deep learning rumor detection methods in the past two years are shown in Table 7.
Representative deep learning rumor detection model in recent two years
Representative deep learning rumor detection model in recent two years
Rumor detection methods based on DL are taking shape as researchers begin to consider applying the emerging deep learning techniques to the field of social network rumor detection. More and more scholars are using recurrent neural network (RNN) [24], gate recurrent unit (GRU) [35, 51], long short term memory (LSTM) [13], convolutional neural network (CNN) [12] to conduct rumor detection. Ma et al. [24] proposed a recurrent neural network-based model (RvNN) that uses RNN to capture changes in the contextual information of comments over time. CNN first appeared in the field of computer vision, and later it can be applied to text processing after deformation. The model architecture of early rumor detection using CNN is shown in Fig. 7. Two tree structures, top-down and bottom-up, are built, with each response posting as a tree node. The response relationship between the content and semantics of the postings can be captured by recursive feature learning along the tree structure, enabling fast and accurate rumor detection. The method shows excellent rumor detection capability in the early stage. Wang et al. [52] built a sentiment lexicon and used a two-layer GRU to obtain fine-grained sentiment expressions of tweets. The rumorEval and PHEME datasets were identified by applying LSTM, which detects rumors by collecting datasets related to review users, with an F1 score of 96% [13]. Song et al. [42] treat all forwarded messages as a sequence and achieves credible early detection study by CNN. Wu et al. [26] constructed a hybrid model to detect false information. Their proposed method uses the RCNN model, which is a CNN-based model that uses a recursive structure as the convolutional layer of the CNN model.
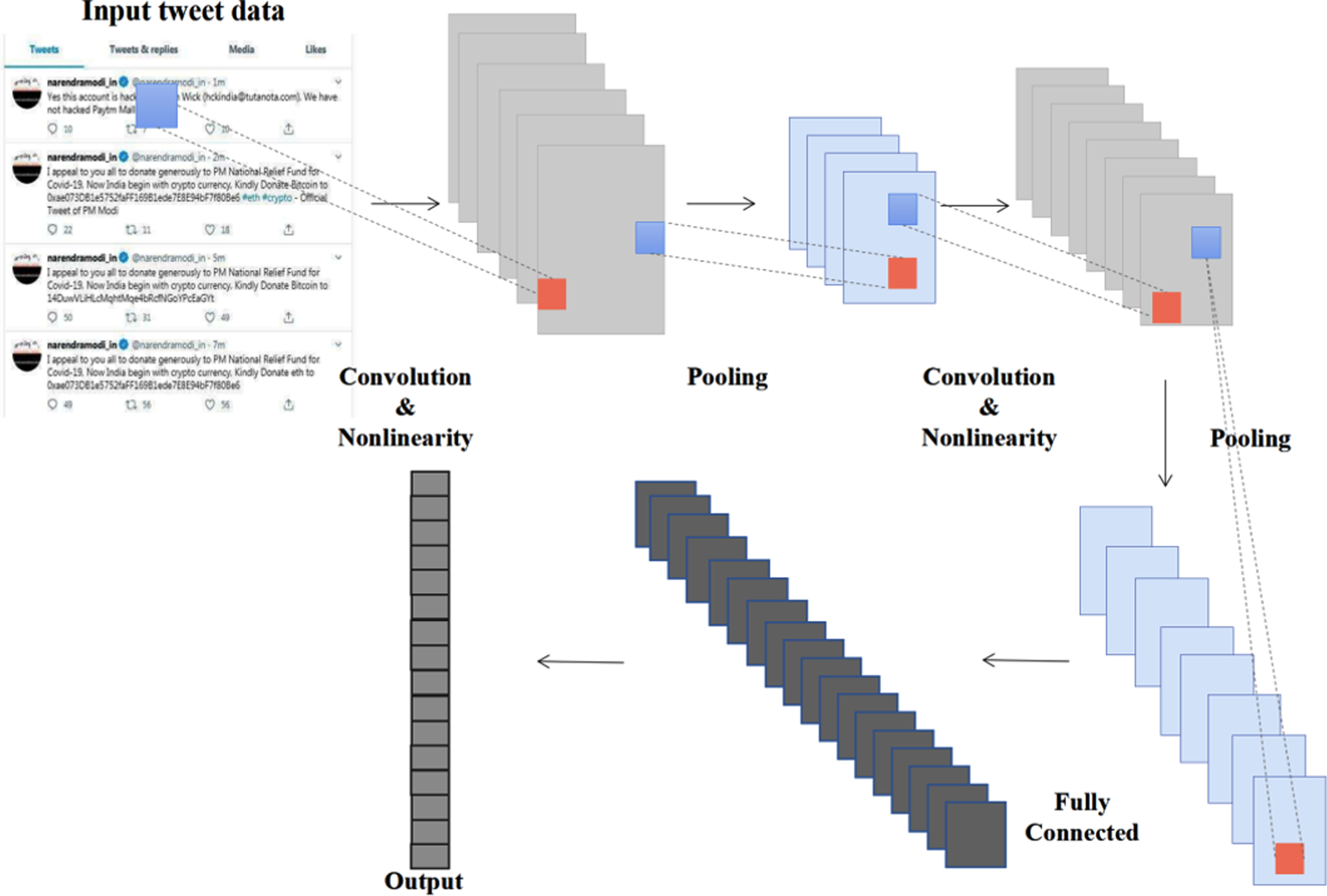
Model Architecture of Early CNN Application in Rumor Detection [12].
Traditional deep learning-based rumor detection methods eliminate the manual construction of feature engineering. However, the natural end-to-end structure makes it difficult to grasp the critical components of rumor information, and the model training lacks controllability, long training time and model complexity. Therefore, introducing attention mechanisms for rumor detection.
Chen et al. [53] proposed a deep RNN-based attention model, called CallAtRumor, which can study the temporal representatipons of consecutive posts and mine the hidden features. CallAtRumor attempts to incorporate attention mechanisms to extract implicit and explicit rumor features from repetitive, ever-changing tweets to detect selected attention-getting messages in social network message sequences. Compared with other models, CallAtRumor can handle redundant data and play a role in improving rumor detection. It achieves 88.63% and 87.10% accuracy on Twitter and Sina Weibo, respectively.
Jin et al. [23] observed that rumors usually consist of images and texts. Therefore, based on Chen’s, attention-Recurrent Neural Network (att-RNN) is proposed to extract the common features of text and social features using LSTM. Then image features are extracted using VGG-19 network. Finally, the image features are fused into the joint features of text and social features for the final rumor classification.
RNN, CNN and autoencoder-based methods have achieved significant improvements over traditional methods. However, most early deep learning-based rumor detection methods process each message independently, ignoring the correlation between notes. Social networks are a common type of graphical data representing social relationships between individuals or organizations. On social networks, there are rich structural associations between different messages. For example, once a user posts a posting, all his followers will receive the posting, while the followers may also re-post or comment on the posting. In addition to the textual information in rumors, recently proposed detection methods have started exploiting the graph structure in propagation networks for rumor detection. Graph neural networks can maintain the form of rumor propagation compared to CNN and RNN. The flow of the rumor detection method based on the propagation structure is shown in Fig. 8.
Flow of rumor detection method based on propagation structure [12].
The spreading features of rumors cannot be ignored. In recent work, in order to extract the structural features of propagation, researchers proposed Graph Convolutional Networks [3, 57]. GCN and GAT have been successfully employed on rumor detection [46]. Since the RvNN model only considers the pattern of propagation and ignores the structural problem of extensive dispersion in rumor detection measurements, yet propagation and dispersion are two important structural features of rumors, and with this purpose, Bian et al. [3] apply bidirectional GCN to learning communication structure features by examining the propagation structure and diffusion structure of rumors. Each layer of GCN involves source-posted information, thus enhancing the root impact of rumors.
Liu et al. [55] construct text graph tensor to describe semantic, syntactic and sequential contextual information, and implement intra- and inter-graph propagation of information through GCN. Yao et al. [56] build graphs based on word co-occurrence and document-word relationships. Then, in order to learn words and documents, they select GCN. Zhang et al. [59] used the model proposed by Li et al. [28] to effectively achieve inductive learning of new words and capture of contextual word relations.
These methods are limited to representing rumor propagation as a static graph and are not ideal for capturing the dynamic information of rumors. Choi et al. [12] proposed a graph convolutional network with an attention mechanism, which became dynamic GCN for rumor detection in 2021. The researchers first represent rumor posts and their response posts as dynamic graphs, and temporal information is used to generate a series of graph snapshots. The attention mechanism is used to learn the representation of graph snapshots and obtain structural and temporal information of rumor propagation. The main components of the Dynamic GCN (DYNGCN) model are snapshot generation, GCN, readout layer, and an attention mechanism. They are responsible for the functions of rumor propagation representation, representation learning on graph snapshots, node embedding aggregation of global graph representations, and sequential learning from a series of graph snapshots, respectively. Upon generating the graph snapshots S = {S(1), S(2), …, S(T)} and their adjacency matrices A = {A(1), A(2), …, A(T)}, researchers conduct representation learning on the graph snapshots with the graph convolutional networks (GCNs). A(t) ∈ RN(t)×N(t), where N(t) is the number of nodes in the snapshot, and feature matrix X ∈ RN(t)×F, the learnable parameters W
k
∈ Rdk-1×d
k
, where k
th
layer produce node embeddings H
k
∈ RN(t)×d
k
. The GCN model used is shown in Equations (2)–(4).
Since social networks often have various images and video messages attached to them in addition to text messages. Image information is more attractive than textual information, and they have rich visual information that can assist in rumor detection. Therefore, extracting multimodal features for multimodal information containing text and image information is also the focus of today’s research. The flow of the rumor detection method based on multi-modal features is shown in Fig. 9.
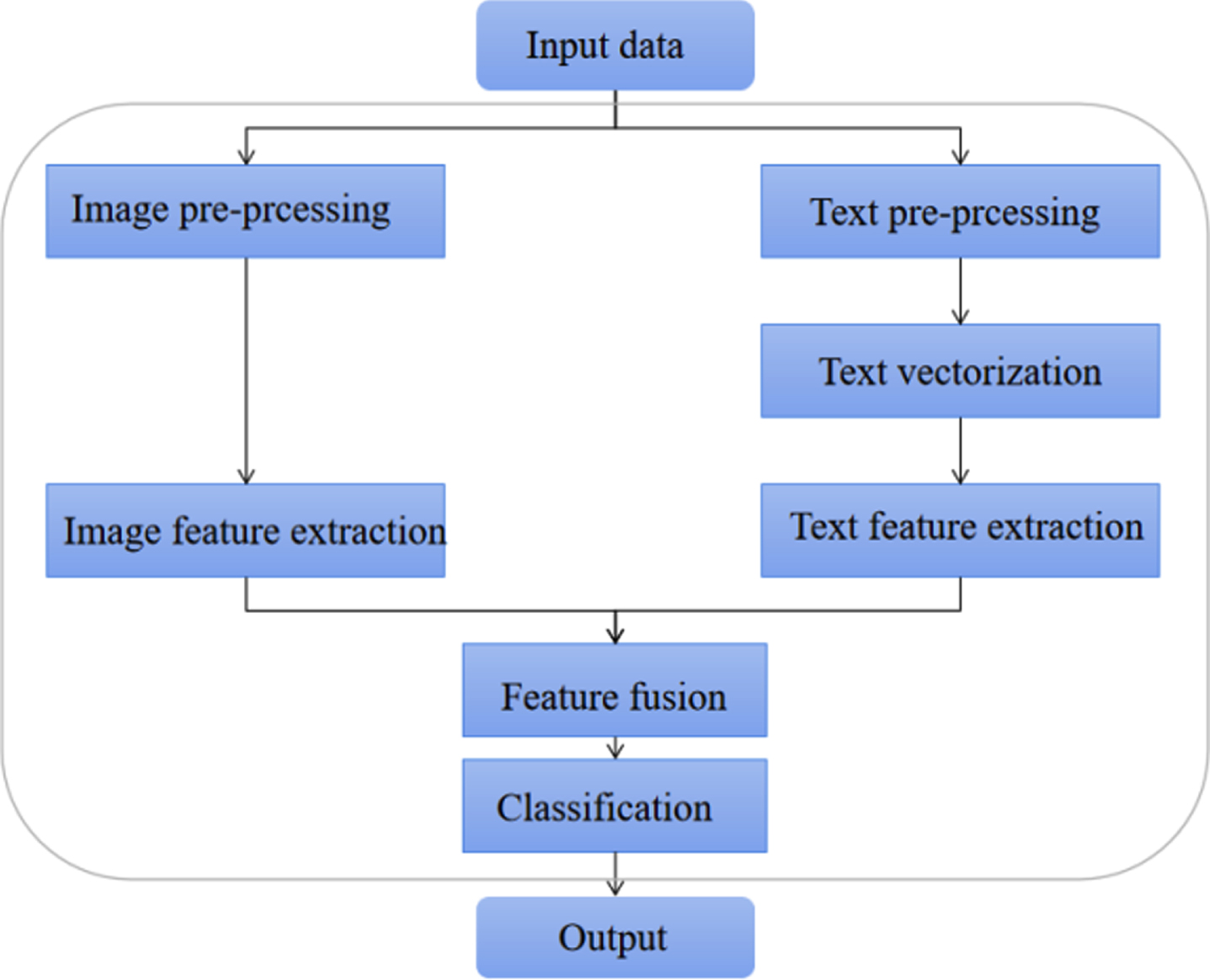
Flow of rumor detection method based on multimodal features.
-Attention-Recurrent neural network
Jin et al. [23] found that with the continuous improvement of social platforms, publishers can not only upload text information, but also upload one or more pictures. Therefore, based on Chen’s work, an attention-Recurrent Neural Network (att-RNN) model is proposed to extract the joint features of text and social features using Long-Short-Term Memory. Then image features are extracted using VGG-19 network, and finally visual features are fused into the joint features of text and propagation features for the final rumor classification.
Researchers defined a tweet instance I = {T, S, V} as a tuple representing three different modalities of contents: the textual content T, the social context S, and the visual content V. The proposed model took features from these modalities (R
T
, R
S
, R
V
), and aimed to learn a reliable representation R
I
as the aggregation of T, S and V for the given tweet I. Their proposed visual-neuron attention mechanism weights the contributions of different neurons for different words. To achieve this goal, they take the output hidden state h
m
of the LSTM at each time step as guidance. h
m
is connected into a fully-connected layer with non-linearity ReLU function and a fully-connected layer with softmax function to obtain the attention vector A
m
∈ R512, which has the same dimension as the visual neurons R
V
.
-Event adversarial neural networks
Since most existing methods have difficulty in identifying rumors of emerging different types of events, they can only mine event-specific features and cannot apply the extracted features to new types of events. To address this shortcoming, researchers proposed an EANN [50] framework for new rumor detection based on multimodal features. The researchers built a new, publicly available dataset for false news detection that is an order of magnitude larger than the previous largest publicly available faulty news dataset of its kind. CNN is used to extract texture features, while the pre-trained VGG19 [41] is used to extract visual features efficiently. After that, the features are stitched together, and finally the stitched features are input to the rumor detection module and the event classification module, respectively. The model learns the invariant event features and can detect the emerging events.
The lack of training data will lead to the inability to truly describe the real social network. Therefore, scholars have proposed transfer learning [38]. Incomplete training data is a problem that can arise during rumor detection, which can lead to the inability to identify features in features deeply and can use migration learning to improve the accuracy of the model by transferring knowledge in the relevant domain.
Yang and Zhang [54] proposed a migration learning algorithm for short text mining called Automatic Transfer Learning (AutoTL). Johnson and Zhang [25] implemented a semi-supervised framework, which can improve the accuracy of text classification. Do and Gaspers [14] greatly improved the accuracy by using additional initialization parameters for the unlabeled dataset. Recently, Guo et al. [18] proposed a deep migration model called TL-CNN, which leverages knowledge of reviews and ratings in the e-commerce domain to achieve accurate rumor detection. The architecture of the TL-CNN model is shown in Fig. 10.
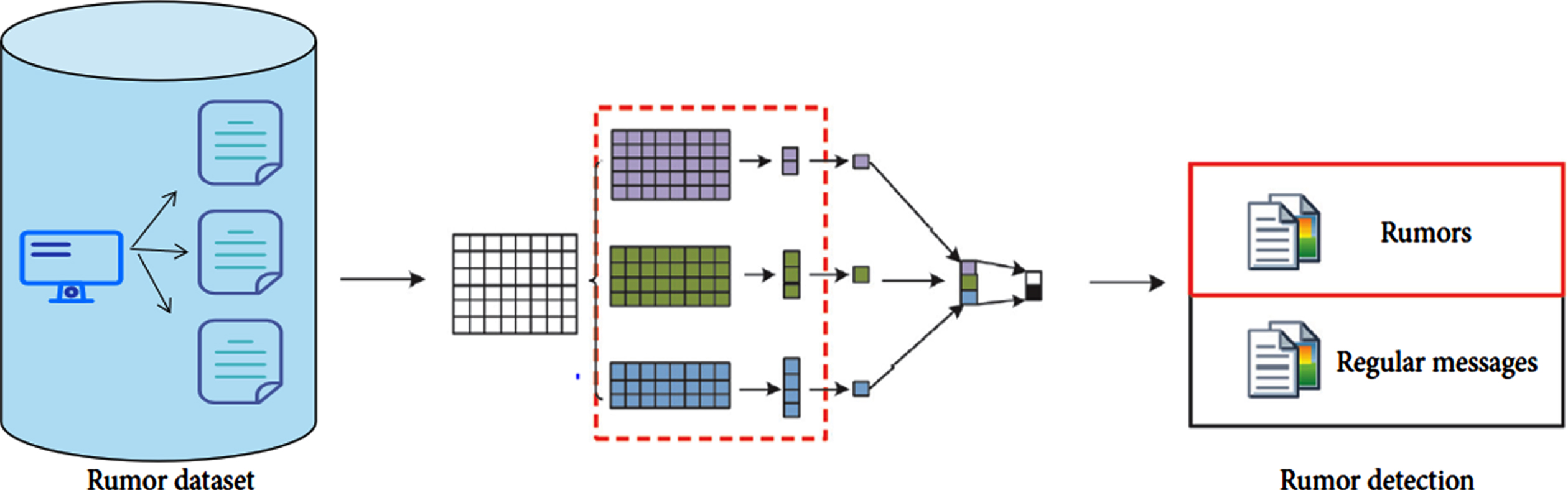
TL-CNN architecture.
Health information, such as food and disease, is closely related to people’s lives, so rumors in the health field account for a large part of all rumors. Especially this year, infectious diseases are spreading all over the world, and social media are full of health rumors. The researchers [40] used the health information data collected from Twitter in their research on the detection of health rumors. For the detection of Chinese health rumors, researchers used 88646 pieces of Chinese health data shared by the true and false information platforms of WeChat and Tencent, including 8972 pieces of rumors. Through the dynamic LSTM model, a stable accuracy of 0.9 can finally be achieved on the evaluation set. It is not difficult to see that for rumor detection technologies in different fields, early data preparation is crucial. In this process, we need the help of experts with knowledge in a certain field.
Evaluation indicators in the study of rumor detection technology
Through the organization and analysis of research on rumor detection techniques, this section will provide statistics and explanations of evaluation metrics that researchers frequently use.
For the evaluation metrics, the researchers used a combination of accuracy(acc), precision(pre), recall(rec) and F1 scores, which are defined in Equations (6)–(9). Accuracy is the most commonly used indicator in the classification problem. It calculates the ratio between the correct prediction number and the total prediction number. However, for unbalanced data sets, Accuracy is not a good indicator. Therefore, we need to introduce precision, recall and F1 score evaluation indicators. Precision rate is calculated as the ratio of all messages correctly classified as rumors (TP) to all messages classified as rumors (TP+FP). Recall is the ratio of all messages correctly classified as rumors (TP) to all messages that should be classified as rumors (TP+FN). F1-measure is the harmonic mean of precision and recall. The confusion matrix summarizes the predicted and actual results, as shown in Fig. 11., where R represents rumors and NR means non-rumors. Accuracy is only a tiny fraction of the overall prediction of correct predictions. Recall is the number of right positive results divided by the number of all relevant samples.
With the continuous development of social networks and the growth of the number of users, the problem of social network rumor detection still has the following challenges. Different challenges require corresponding measures to solve the problem.
(1) Unbalanced rumor data
Existing public datasets or datasets used by other researchers tend to have slightly less non-rumor data than rumor data, and the difference is insignificant. However, in authentic social networks, the actual situation is that the number of rumors is much smaller than the number of non-rumors, which is a typical unbalanced data set classification problem. One study [21] shows that in machine learning problems, significant differences in prior data class probabilities (unbalanced datasets) can hinder the performance of specific classifiers (decision trees, SVMs). It can lead to higher error rates in the detection results of rumor detection models, which cannot be really effectively applied in real social networking platforms. To face this problem, scholars have proposed to adjust the inter-class distribution in the rumor dataset by using SMOTE [9] sampling method or adding the cost information to the traditional classification algorithm, so as to modify the existing classification algorithm into Cost Sensitive Learning (CSL) [15].
(2) Real-time rumor identification
The current rumor detection method is used to screen rumors after the data on social networks reach a specific scale and people find that an event or a topic has become the focus of attention of a group of people in the web. Then they find that there may be a mixture of misinformation and false information. When new data is released, there is a problem of “cold start” [35] detection due to the lack of necessary clues. Therefore, this work mode leads to a lack of timely authenticity judgments of unexpected events, massive social network information, and a considerable delay in rumor detection. It leads to a longer time lag for rumors to spread and a wider spread of rumors, which brings more danger to individuals or society. Therefore, it is urgent to solve the problem of detecting rumors before they cause great harm.
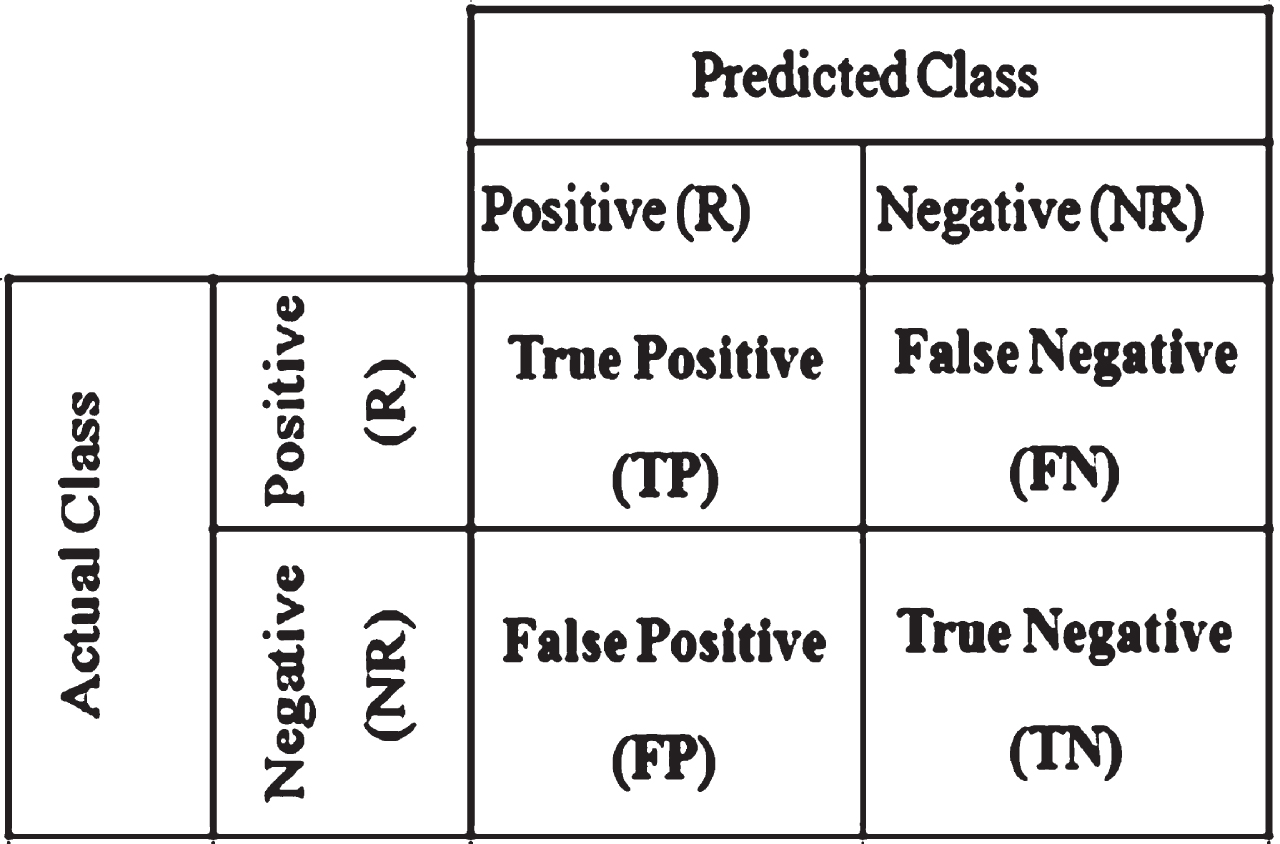
Confusion matrix for rumor detection.
If rumors are detected and stopped from spreading at an early stage, the impact of rumors will be greatly reduced and various losses will be minimized. Currently, there are fewer related studies. In future research, we can try to put the information suspected to be rumors into the candidate set to improve the speed of rumor detection.
(3) Multimedia information rumor detection
Multimedia information (images, videos, audio) has become crucial supplementary information in the process of social network rumor propagation, and has even becomes the main content of rumors. Many rumors come from the PS of images, audio or video editing and synthesis. The current research mainly focuses on rumor text information, and a small number of researchers use tags and external knowledge of images to assist rumor detection. In contrast, the mining of video and audio type information is sporadic. Therefore, the rational application of image, audio and video processing techniques to rumor detection is another trend for future research.
(4) The law of rumor propagation
Many factors influence the spread of rumors. Suppose we want to achieve accurate rumor detection. In that case, it is necessary to search for features and propagation patterns of rumors and non-rumors [29].
(5) Classifying rumors by topic
Different topics, groups, and influences will lead to different rumor rates. The unique laws of rumor propagation are studied according to topic classification, and establish rumor recognition models for different topic types. This approach not only reduces the processing difficulty of rumor identification in real-time but also increases the accuracy of rumor identification and shortens the detection time. For example, some researchers have specifically developed rumor detection under knowledge topics in the health domain [45].
In summary, the existing social network rumor detection methods have new challenges in the face of the changing social network information. Research and development of real-time, accurate and adaptive social network rumor detection technologies are still an urgent need in the field of network security and network public opinion.
Social network rumor detection is a hot issue in social networks and information dissemination. In the era of booming self-media, rumor detection has become urgent. In this review, we summarize the development of rumor detection technology and the detection process and the manual rumor detection methods, machine learning and deep learning-based methods in terms of architecture, data set, and effect evaluation, respectively. This review can help researchers in related fields to understand different rumor detection methods from the perspectives of both social network rumor content and technology, which can be helpful in learning and promoting the development and optimization of social network rumor detection models. Rumor detection timeliness, large untagged real datasets, and coping with changing forms of social network rumors are challenges for future research. Future research work will consider the contribution of different levels of coding features, as well as investigate the relationship between features such as user characteristics and propagation patterns.