
Abstract
Information system (IS) is a significant model in the field of artificial intelligence. Information structure is not only a research direction in the field of granular computing (GrC), but also an important method to study an IS. A multiset-valued information system (MVIS) refers to an IS where information values are multisets. A MVIS can be seen as a model that is the result of information fusion of multiple categorical ISs. This model helps deal with missing values in the dataset. This paper studies information structures in a MVIS on the view of GrC and consider their application for uncertainty measurement (UM). First of all, some notions of multisets and probability distribution sets (PDSs) are proposed. Naturally, relationships between multisets and PDSs are researched. Then, the concept of a MVIS based on the notion of multisets is given, and the internal structure of a MVIS is revealed by an incomplete information system (IIS). Furthermore, tolerance relations in a MVIS are defined by using Hellinger distance, and tolerance classes are obtained to construct the information structures of a MVIS. Considering the association of information structures, relationships between information structures are raised from the two aspects of dependence and separation. Moreover, some properties between information structures are provided by using information distance and inclusion degree. Finally, four UMs as the applications of information structures are investigated, and comprehensive experiments on several datasets demonstrate the feasibility and superiority of the proposed measures. These results will be helpful for establishing a framework of GrC in a MVIS and studying UM.
Introduction
Background and related work
There are always coexisting certain and uncertain phenomenon in the objective world. To understand the objective world, human have spontaneously developed an organized and hierarchical way of mindset of granulation. Granular computing (GrC) is a new discipline that studies mindset of granulation and its methodology. GrC [50] was first proposed by Zadeh in 1996. It can dispose large-scale complex data sets and is an important tool for data mining and knowledge representation [47].
The main goal of GrC is to deal with uncertain information and it is also a significant tool to study information systems. The major methods to study GrC are rough set theory (RST) [35, 36], fuzzy set theory [51], quotient space theory [54] and other artificial intelligence theories [18, 21].
RST [34] was proposed by Polish mathematician Pawlak in 1982, it has been a mathematical theoretical method for processing incomplete, imprecise and inconsistent information. At present, RST is successfully applied to data mining [6], machine learning [7], knowledge discovery [16, 28] and other fields. In RST, an information table is also a way of knowledge representation and that is called an IS. An IS is a database that describes the relationship between objects and attributes. The equivalence relation in an IS can be regarded as a special similarity relation between two objects of data set. Any subset of attributes of an IS can determine an equivalence relationship. This equivalence relation divides the universe into disjoint classes, which are known as equivalence classes. If two objects in the universe belong to the same equivalence class, then we say that the two objects cannot be distinguished under this equivalence class. Therefore, each equivalence class is an information granule composed of indistinguishable objects [19]. The family of all these information granules constitutes a vector, which is called the information structure induced by attribute subset of IS. Obviously, the information structure in an IS is the granularity structure in the sense of GrC. In this regard, many scholars have made contributions. For example, Qian et al. [40] discussed the knowledge structure in the knowledge base; Liang et al. [24] explored the theory of information granule and entropy in an IS; Zhang et al. [52] researched the information structure in a fuzzy IS from the perspective of GrC; Chen et al. [9] investigated the information structure in a lattice valued IS; Xie et al. [32] studied the information structure and UM in an incomplete probability set-valued IS; Yu [48] studied the information structure in an IIS; Xu et al. [33] considered knowledge granulation and knowledge entropy an ordered IS.
UM based on RST is an important basis to describe the classification ability of IS, which has been studied by many scholars. Pawlak [37] proposed the concepts of precision and roughness to measure the uncertainty of IS. Meanwhile, he raised the concepts of approximate precision and approximate roughness to measure the uncertainty of DIS; Some scholars have also studied UM of IS from other different angles. For example, information entropy and knowledge granularity can be effectively used to measure the uncertainty of IS. Yao et al. [49] gave the measurement method of granularity from the perspective of granulation; Liang et al. [23] studied the problem of information granulation in complete ISs and IISs; Dai et al. [11] researched the entropy measure and granularity measure of set-valued ISs; Qian et al. [39] proposed combination entropy and combination granularity to measure uncertainty of ISs; Miao et al. [30] discussed the relationship between knowledge roughness and information entropy, they proved information entropy and mutual information are monotonous under the definition of knowledge roughness. Liu et al. [20] constructed a expanded of rough entropy to describe the uncertainty of type-2 fuzzy information systems; Liao et al. [26] three-level and three-way uncertainty measurements of the interval-valued decision systems are proposed, mainly by systematically constructing vertical-horizontal weighted entropies. At present, UM has been widely used in machine learning [45], pattern recognition [8], image processing [31], medical diagnosis [15], data mining [22], decision analysis [12, 53] and other fields.
Information fusion was first applied in military field. A research institution uses the fusion of multiple independent sonar signals to detect the position of enemy ships [2]. With the advent of big data era, information fusion has become a research hotspot in the field of artificial intelligence. Due to the characteristics of multi-source, heterogeneity and incompleteness of big data, it is necessary to fuse big data. Many complex data come from multiple sources. In order to form a unified result, it is need to combine and merge information from multiple sources, so as to optimize the combination of information and obtain high-quality effective information. The purpose of information fusion mainly has two aspects:
(i) Aiming at the redundancy of multi-source information, it can eliminate the noise and outliers of information;
(ii) Aiming at the complementarity of multi-source information, it can obtain valuable information related to practical application, and maximize the complete information description of the observed object.
The theories commonly used to study multi-source information fusion in big data environment are RST [5], D-S evidence theory [10], cluster analysis theory [13], Bayes theory [38] and fuzzy set theory [42]. Actually, information fusion based on RST has been researched by many scholars. For instance, Khan et al. [27] extended the single source IS to multi-source IS, and proposed the rough set model of fuzzy multi-granularity decision theory in multi-source fuzzy decision IS; Information fusion [44] is the most effective method for processing multi-source IS, which is one of the research hotspots in the field of artificial intelligence; Li et al. [25] proposed an information fusion method based on information entropy; Xu et al. [46] raised the information fusion method from GrC angle; Huang et al. [14] put forward the information fusion method based on trapezoidal fuzzy granular; Ristic et al. [41] proposed a framework for performance assessment of a system for reasoning under uncertainty in high-level information fusion.
Motivation and inspiration
On the one hand, RST can only deal with complete and nonconflict data sets. However, datasets are usually incomplete and redundant in reality. These datasets will seriously affect the data of data mining and become an obstacle to data mining. Therefore, in order to improve the instruction of data mining, we must preprocess the data before analyzing the data in the database. Data cleaning is a part of data preprocessing, and the processing of missing values is an important part of data cleaning. In real life, there are many reasons for the lack of collected datasets. But no matter what kind of reason for the lack, it will cause the deviation of data mining results. So how should we deal with the missing data? It has become an important research topic.
Usually, the missing information value of an attribute is replaced by all information values of the same attribute (i.e., a set) in the existing work. However, it misses the fact that some information values may occur more frequently than others. To consider the frequency of information values, the missing information value of an attribute is replaced by a multiset in this paper. This filling method reflects the rationality of the filling. Based on mutilsets, a mutilset-valued information system (MVIS) is introduced.
On the other hand, a MVIS can be regarded as the result of information fusion of multiple categorical ISs. The relationship between data samples from different data sources implies various knowledge structure information, which expresses the information between data samples from multiple angles. Through information fusion based on RST, it is helpful to further excavate the value of data and enhance the function of information analysis.
For the above reasons, we studied the MVIS induced by an IIS or obtained from multiple classified ISs by information fusion. Considering its information structure from the perspective of GrC and RST. And continuing to study the cross problem method of GrC and RST. It provides an effective rough set method for dealing with knowledge acquisition in an IIS. It not only further enriches the connotation of RST, but also has important practical significance.
This paper studies information structures in a MVIS and applied them to uncertainty measurement. The major contributions of this dissertation are summarized as below:
(i) A multiset can be dealt with a PDS on the basis of the relationships of one-to-one correspondences between multisets and PDSs in a MVIS;
(ii) Based on Hellinger distance, a tolerance relation of any subset in a MVIS is defined and tolerance classes are obtained to construct information structures;
(iii) Considering the association of information structures in a MVIS, relationships between information structures are raised from the two aspects of dependence and separation;
(iv) Four UMs as the applications of information structures are investigated, and comprehensive experiments on several datasets are demonstrated the feasibility and superiority of the proposed measures.
Organization
The specific arrangements of the article is structured as follows. Section 2 introduces binary relations, multisets and probability distribution sets, and researches relationships between multisets and PDSs. Section 3 provides information structures of a MVIS induced by tolerance relations that are obtained from Hellinger distance. Section 4 introduces information distance and inclusion degree between information structures in a MVIS. Section 5 investigates four measurement methods which are seen as the applications of information structure in a MVIS. Section 6 propose numerical experiments and effectiveness analysis to demonstrate the feasibility and superiority of the proposed UMs. Section 7 concludes this paper.
The research framework of this paper is depicted in Figure 1.
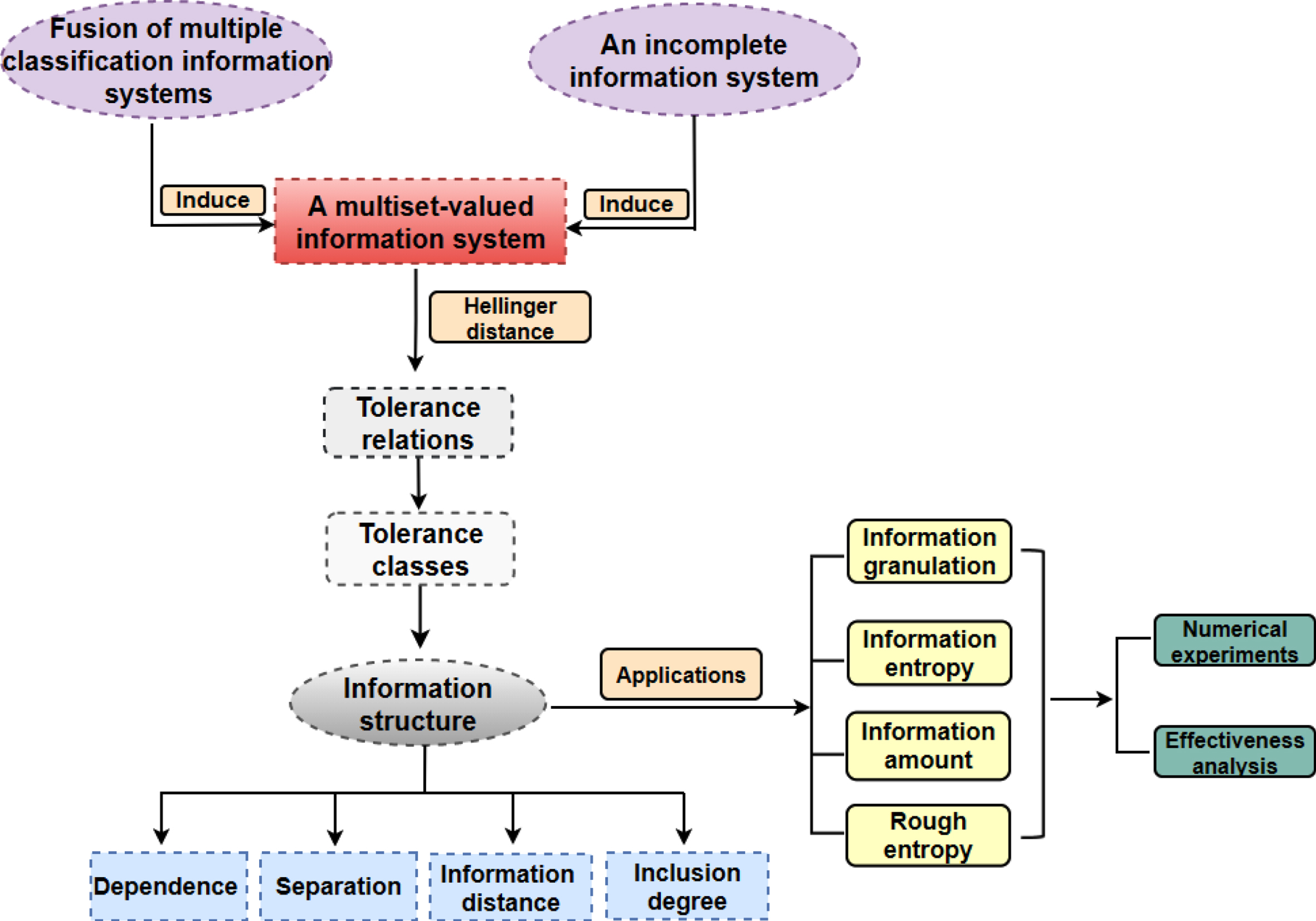
The research framework of this paper.
In this paper, suppose that O is a non-empty finite set of objects, 2
O
expresses the collection that is formed by all subsets of O and |X| indicates the cardinality of X ∈ 2
O
. Put
Binary relations
For R ⊆ O × O, then R is a binary relation on O. If (o, o′) ∈ R, denoted by oRo′. A binary relation R is satisfied the following properties.
(1) reflexive, ∀ o ∈ O ⇒ oRo;
(2) symmetric, ∀ o, o′ ∈ O, oRo′ ⇒ o′Ro;
(3) transitive, ∀ o, o′, o″ ∈ O, oRo′ and o′Ro″ ⇒ oRo″.
Then, R is said to be an equivalence relation on O, if R is reflexive, symmetric and transitive; R is called a tolerance relation on O, if R is reflexive and symmetric.
Multisets
A multiset is a collection of elements in which an element may appear more than once. The number of occurrences of an element in a multiset is referred to as the multiplicity of this element. The cardinality of a multiset is the sum of the multiplicities of its elements [1].
For convenience, ∀ x ∈ U, C M (x) is denoted by M (x) .
If M (x) = m, then it represents that x appears m times in M, we denote it by
For a non-empty finite set X = {x1, x2, …, x
s
}, ∀ x
i
∈ X, M (x
i
) = m
i
, then M is denoted by {m1/x1, m2/x2, ⋯ , m
n
/x
s
}, i.e.,
(1) M1 = M2⇔ M1 (x) = M2 (x) (x ∈ X) ;
(2) M1⊑ M2 ⇔ M1 (x) ≤ M2 (x) (x ∈ X) ;
(3) P = M1⊔ M2 ⇔ P (x) = M1 (x) ∨ M2 (x) (x ∈ X) ;
(4) P = M1 ⊓ M2 ⇔ P (x) = M1 (x) ∧ M2 (x) (x ∈ X) .
(5) P = M1⊕ M2 ⇔ P (x) = M1 (x) + M2 (x) (x ∈ X) ;
(6) P = M1 ⊖ M2 ⇔ P (x) = (M1 (x) - M2 (x)) ∨0 (x ∈ X) .
Probability distribution sets
In the real world, there are many probabilistic data and related models proposed by Barbara et al. from the early 1990s [3, 4]. For example, patients who might have the flu are needed to be diagnosed by five doctors from some symptoms. Each patient has different degrees of symptoms that are headache={yes,no}, musclepain={yes,no} and temperature={normal,high,very high}. Five doctors will give the diagnosis results of patients’ symptoms based on their own experience, such as, for the symptoms of temperature, they diagnosed patient A as normal, normal, high, high and very high. These results can be denoted by a set, i.e., S = {normal, normal, high, high, very high}. Moreover, S = {normal, normal, high, high, very high} is expressed as a multiset S = {normal/2, high/2, very high/1}. In this multiset, the probability of occurrence of normal is 0.4, the probability of occurrence of high is 0.4, the probability of occurrence of very high is 0.2. In order to better express this phenomenon, a probability distribution set be defined as follows.
From the above definition, P can be regarded as a map P : X → [0, 1] , namely,
(1) P and Q are said to be equal, if s = t, for each i, x
i
= y
i
and p
i
= q
i
. We write
(2) P and Q are said to be approximately equal, if s = t and for each i, x
i
= y
i
. We write
clearly, P = Q ⇒ P ≃ Q.
Relationships between multisets and PDSs
In this subsection, we will prove that there exist relationships of one-to-one correspondence between multisets and PDSs. This result will be helpful for understanding why a multiset can been considered as a PDS.
Obviously,
Clearly,
∀ i,
Then ∀ i,
Then ∀ i,
Note that ∀ i,
Then
By Lemmas 2.8 and 2.9, we get
Thus f ∘ g = i Ψ , g ∘ f = i Ω , where i Ψ is the identity mapping on Ψ, i Ω is the identity mapping on Ω, respectively.
Hence, f and g are two one-to-one correspondences. This suggests that there exists a one-to-one correspondence between Ω and Ψ. □
Based on Theorem 2.10, a multiset is able to be considered as a RPDS. Below, we will deal with multisets like RPDSs.
Multiset-valued information systems
In this section, we introduce the concept of multiset-valued information system (MVIS), and define tolerance relations and rough approximations in a MVIS.
The concept of multiset-valued information system
In this subsection a MVIS can be regarded as the result of information fusion of multiple categorical ISs.
Especially, if ∃ o ∈ O and a ∈ A such that a (o) is a missing value, denoted by a (o) =*, then (O, A) is called an incomplete information system (IIS).
Suppose that (O, A) is an IIS. For any a ∈ A, denote
One can see from Table 1 that
An IIS about cars
An IIS about cars
If B ⊆ A, then (O, B) is known as a subsystem of (O, A).
Considering that internal structures of a MVIS are complex. For ease of understanding, we will reveal this internal structure in the following.
Let (O, A) be a MVIS, where O = {o1, o2, ⋯ , o
n
} and A = {a1, a2, ⋯ , a
m
} . For any i, a
i
(o1), a
i
(o2), ⋯ a
i
(o
n
) are multisets drawn from a same set. We denote the same set by X
i
, namely,
Next, we illustrate by an example that a MVIS can be induced by an IIS.
An MVIS (O, A) is induced by an IIS.
The following example illustrates the background of a MVIS. In practical application of evaluating the credit card applicant’s credit rating, a credit card applicant is evaluated by multiple experts, and may have dissimilar evaluation results.
Put X1 = {G, A, P}, X2 = {H, M, L}, X3 = {O, Y} and X4 = {H, M, L}. Then ∀ o ∈ O, a1 (o), a2 (o), a3 (o)and a4 (o) are four multisets drawn from X1, X2, X3 and X4, respectively.
As can be seen from this example, a MVIS (see Table 8) may be the result of information fusion of multi-classified ISs or multi-source IS (see Tables 3-7).
expert-1
expert-2
expert-3
expert-4
expert-1
A MVIS is composed of Tables 3-7
In this subsection, we provide the tolerance relation in each subsystem of a MVIS based on Hellinger distance.
Clearly,
Let
Clearly,
(1) If B1 ⊆ B2, ∀ o ∈ O, then
(2) If 0 ≤ θ1 < θ2 ≤ 1, then
Information structures in a MVIS
In this section, we study information structures in a MVIS.
The concept of information structures in a MVIS
From the perspective of GrC, information structures refer to a mathematical structure of the family of information granules granulated from a data set. Considering that a set vector is better than family of sets in displaying the internal structure of an information structure, a mathematical structure of the family of information granules is showed by a set vector.
Especially, if ∀ i,
(1) S
θ
1
(B1) is said to be dependent on S
θ
2
(B2), if ∀ o ∈ O,
(2) S
θ
1
(B1) is said to be dependent partially on S
θ
2
(B2), if ∃ o ∈ O,
(3) S
θ
1
(B1) is said to be independent on S
θ
2
(B2), if ∀ o ∈ O,
S θ 1 (B1) = ({x1, x4, x6, x9} , {x2, x3, x7} , {x2, x3, x7} , {x1, x4, x6, x9} , {x5, x8} , {x1, x4, x6, x9} , {x2, x3, x7} , {x5, x8} , {x1, x4, x6, x9}) ;∥S θ 2 (B2) = ({x1, x3, x5} , {x2, x4, x8, x9} , {x1, x3, x5} , {x2, x4, x8, x9} , {x1, x3, x5} , {x6, x7} , {x6, x7} , {x2, x4, x8, x9} , {x2, x4, x8, x9}) ;∥S θ 2 (B3) = ({x1, x9} , {x2, x3} , {x2, x3} , {x4} , {x5} , {x6} , {x7} , {x8} , {x1, x9}) .
Thus,
Relationships between information structures in a MVIS
In this subsection, we study relationships between information structures in a MVIS from two aspects of dependence and separation.
Dependence between information structures in a MVIS
(2) S
θ
1
(B1) ⪯ S
θ
2
(B2) implies
The following theorem shows that the relationship between information structures can be quantitatively described by inclusion degree in a MVIS.
“⇐". Denote
Information distance between information structures in a MVIS
In non-deterministic reasoning, the distance between uncertain structures plays an important role in reasoning. Taking into consideration of separation between information structures of a MVIS, we put forward the notion of information distance to differentiate two given information structures in the same MVIS and research some of its properties.
For X, Y ∈ 2
O
, denote
Apparently, ∣X⊕ Y ∣ = ∣ X ∪ Y ∣ - ∣ X ∩ Y ∣.
(1) (Nonnegativity) ∀ m, m′ ∈ M, ρ (m, m′) ≥0 and ρ (m, m) =0;
(2) (Symmetry) ∀ m, m′ ∈ M, ρ (m, m′) = ρ (m′, m);
(3) (Trigonometric inequality) ∀ m, m′, m″ ∈ M, ρ (m, m″) ≤ ρ (m, m′) + ρ (m′, m″).
Under these circumstances, ρ is called a pseudo-metric on M.
Then,
(2) Since S
θ
1
(B1) ⪯ S
θ
2
(B2), ∀ i,
ρ (S
θ
(B) , S
θ
π
(π)) + ρ (S
θ
(B) , S
θ
U
(U))
To illustrate the rationality of the above results, an example is given below.
({x1} , {x2} , {x3} , {x4} , {x5} , {x6} , {x7} , {x8} , {x9}) , S
θ
U
(B4) = (U, U, ⋯ , U) .Denote
This example illustrates the following facts:(1) By Definition 4.13, calculate
(3) It is clear that
ρ (S θ π (π) , S θ 2 (B3)) + ρ (S θ 2 (B3) , S θ 1 (B1)) = ρ (S θ π (π) , S θ 1 (B1)) .
Uncertainty measurement of a MVIS
Measuring uncertainty of an IS were investigated by many scholars. The research tools usually include granulation measure, entropy measure and information amounts. They have become effective mechanisms for evaluating uncertainty of an IS. Inspired by this idea, we propose information granulation, information entropy, information amount and rough entropy to measure uncertainty of a MVIS in the following.
Information granulation of a MVIS
The θ-information granulation is a mapping from an attribute subspace to a real space, i.e. IG : (B, θ) → R+, where R+ is the domain of nonnegative real numbers. With this mapping, the degree of uncertainty of different subsystem can be evaluated.
(1) If B1 ⊆ B2, ∀ θ, IG θ (B2) ≤ IG θ (B1);
(2) If θ1 ≤ θ2, ∀ B, IG θ 1 (B) ≤ IG θ 2 (B).
(1) If S
θ
1
(B1) ⪯ S
θ
2
(B2), then
(2) If S
θ
1
(B1) ≺ S
θ
2
(B2), then
(2) Since S
θ
1
(B1) ≺ S
θ
2
(B2), by Definition 4.4, we have S
θ
1
(B1) ⪯ S
θ
2
(B2) and S
θ
1
(B1) ≠ S
θ
2
(B2). Then, ∀ o ∈ O,
This theorem shows that when available information becomes coarser, IG θ (B) increases. By contrary, when available information becomes finer, IG θ (B) decreases. Therefore, IG θ (B) is presented in Definition 5.1 can be used for uncertainty measurement of a MVIS.
Information entropy of a MVIS
(1) If B1 ⊆ B2, ∀ θ, IE θ (B1) ≤ IE θ (B2);
(2) If θ1 ≤ θ2, ∀ B, IE θ 2 (B) ≤ IE θ 1 (B).
(1) If S
θ
1
(B1) ⪯ S
θ
2
(B2), then
(2) If S
θ
1
(B1) ≺ S
θ
2
(B2), then
(2) Since S
θ
1
(B1) ≺ S
θ
2
(B2), by Definition 4.4, we have S
θ
1
(B1) ⪯ S
θ
2
(B2) and S
θ
1
(B1) ≠ S
θ
2
(B2). Then, ∀ o ∈ O,
Similarly, Definition 5.4 and Theorem 5.6 illustrate that IE θ (B) can be used to evaluate uncertainty of a MVIS.
Information amount of a MVIS
(1) If B1 ⊆ B2, ∀ θ, IA θ (B1) ≤ IA θ (B2);
(2) If θ1 ≤ θ2, ∀ B, IA θ 2 (B) ≤ IA θ 1 (B).
(1) If S
θ
1
(B1) ⪯ S
θ
2
(B2), then
(2) If S
θ
1
(B1) ≺ S
θ
2
(B2), then
(2) Since S
θ
1
(B1) ≺ S
θ
2
(B2), by Definition 4.4, we have S
θ
1
(B1) ⪯ S
θ
2
(B2) and S
θ
1
(B1) ≠ S
θ
2
(B2). Then, ∀ o ∈ O,
Definition 5.7 and Theorem 5.9 explain that IA θ (B) can be used for uncertainty measurement of a MVIS.
Rough entropy of a MVIS
(1) If B1 ⊆ B2, ∀ θ, RE θ (B1) ≤ RE θ (B2);
(2) If θ1 ≤ θ2, ∀ B, RE θ 2 (B) ≤ RE θ 1 (B).
(1) If S
θ
1
(B1) ⪯ S
θ
2
(B2), then
(2) If S
θ
1
(B1) ≺ S
θ
2
(B2), then
(2) Since S
θ
1
(B1) ≺ S
θ
2
(B2), by Definition 4.4, we have S
θ
1
(B1) ⪯ S
θ
2
(B2) and S
θ
1
(B1) ≠ S
θ
2
(B2). Then, ∀ o ∈ O,
Definition 5.10 and Theorem 5.12 indicate that RE θ (B) can be used to evaluate uncertainty of a MVIS.
Numerical experiments and effectiveness analysis
In this section, numerical experiments are researched on ten UCI datasets [43] to evaluate the performance of proposed UMs with MVISs, and the effectiveness of proposed measurement measurements are analyzed from the perspective of statistics.
Numericals experiment
Ten datasets(See Table 9) are selected from the UCI databases for testing the performance of IG, IE, IA and RE.
The description of datasets
The description of datasets
For dataset Br, denote F i = {a1, ⋯ , a2×i} (i = 1, ⋯ , 4). Then, four measurement sets of Br are written as follows:
X IG (Br) = {IG (F1) , ⋯ , IG (F4)} ,
X IE (Br) = {IE (F1) , ⋯ , IE (F4)} ,
X IA (Br) = {IA (F1) , ⋯ , IA (F4)} ,
X RE (Br) = {RE (F1) , ⋯ , RE (F4)} .
For dataset Ca, denote H i = {a1, ⋯ , a i } (i = 1, ⋯ , 6). Then, four measurement sets of Ca are written as follows:
X IG (Ca) = {IG (H1) , ⋯ , IG (H6)} ,
X IE (Ca) = {IE (H1) , ⋯ , IE (H6)} ,
X IA (Ca) = {IA (H1) , ⋯ , IA (H6)} ,
X RE (Ca) = {RE (H1) , ⋯ , RE (H6)} .
For dataset Ch, denote I i = {a1, ⋯ , a3×i} (i = 1, ⋯ , 12). Then, four measurement sets of Ch are written as follows:
X IG (Ch) = {IG (I1) , ⋯ , IG (I12)} ,
X IE (Ch) = {IE (I1) , ⋯ , IE (I12)} ,
X IA (Ch) = {IA (I1) , ⋯ , IA (I12)} ,
X RE (Ch) = {RE (I1) , ⋯ , RE (I12)} .
For dataset Fl, denote J i = {a1, ⋯ , a2×i} (i = 1, ⋯ , 5). Then, four measurement sets of Fl are written as follows:
X IG (Fl) = {IG (J1) , ⋯ , IG (J5)} ,
X IE (Fl) = {IE (J1) , ⋯ , IE (J5)} ,
X IA (Fl) = {IA (J1) , ⋯ , IA (J5)} ,
X RE (Fl) = {RE (J1) , ⋯ , RE (J5)} .
For dataset Ly, denote K i = {a1, ⋯ , a2×i} (i = 1, ⋯ , 9). Then, four measurement sets of Ly are written as follows:
X IG (Ly) = {IG (K1) , ⋯ , IG (K9)} ,
X IE (Ly) = {IE (K1) , ⋯ , IE (K9)} ,
X IA (Ly) = {IA (K1) , ⋯ , IA (K9)} ,
X RE (Ly) = {RE (K1) , ⋯ , RE (K9)} .
For dataset Pr, denote L i = {a1, ⋯ , a i } (i = 1, ⋯ , 17). Then, four measurement sets of Pr are written as follows:
X IG (Pr) = {IG (L1) , ⋯ , IG (L17)} ,
X IE (Pr) = {IE (L1) , ⋯ , IE (L17)} ,
X IA (Pr) = {IA (L1) , ⋯ , IA (L17)} ,
X RE (Pr) = {RE (L1) , ⋯ , RE (L17)} .
For dataset So, denote M i = {a1, ⋯ , a5×i} (i = 1, ⋯ , 7). Then, four measurement sets of So are written as follows:
X IG (So) = {IG (M1) , ⋯ , IG (M7)} ,
X IE (So) = {IE (M1) , ⋯ , IE (M7)} ,
X IA (So) = {IA (M1) , ⋯ , IA (M7)} ,
X RE (So) = {RE (M1) , ⋯ , RE (M7)} .
For dataset Sp, denote N i = {a1, ⋯ , a2×i} (i = 1, ⋯ , 11). Then, four measurement sets of Sp are written as follows:
X IG (Sp) = {IG (N1) , ⋯ , IG (N11)} ,
X IE (Sp) = {IE (N1) , ⋯ , IE (N11)} ,
X IA (Sp) = {IA (N1) , ⋯ , IA (N11)} ,
X RE (Sp) = {RE (N1) , ⋯ , RE (N11)} .
For dataset Tt, denote O i = {a1, ⋯ , a i } (i = 1, ⋯ , 9). Then, four measurement sets of Tt are written as follows:
X IG (Tt) = {IG (O1) , ⋯ , IG (O9)} ,
X IE (Tt) = {IE (O1) , ⋯ , IE (O9)} ,
X IA (Tt) = {IA (O1) , ⋯ , IA (O9)} ,
X RE (Tt) = {RE (O1) , ⋯ , RE (O9)} .
For dataset Vr, denote P i = {a1, ⋯ , a2×i} (i = 1, ⋯ , 8). Then, four measurement sets of Vr are written as follows:
X IG (Vr) = {IG (P1) , ⋯ , IG (P8)} ,
X IE (Vr) = {IE (P1) , ⋯ , IE (P8)} ,
X IA (Vr) = {IA (P1) , ⋯ , IA (P8)} ,
X RE (Vr) = {RE (P1) , ⋯ , RE (P8)} .
For dataset Au, denote P i = {a1, ⋯ , a3×i} (i = 1, ⋯ , 23). Then, four measurement sets of Au are written as follows:
X IG (Au) = {IG (P1) , ⋯ , IG (P23)} ,
X IE (Au) = {IE (P1) , ⋯ , IE (P23)} ,
X IA (Au) = {IA (P1) , ⋯ , IA (P23)} ,
X RE (Au) = {RE (P1) , ⋯ , RE (P23)} .
For dataset Mu, denote P i = {a1, ⋯ , a2×i} (i = 1, ⋯ , 10). Then, four measurement sets of Mu are written as follows:
X IG (Mu) = {IG (P1) , ⋯ , IG (P10)} ,
X IE (Mu) = {IE (P1) , ⋯ , IE (P10)} ,
X IA (Mu) = {IA (P1) , ⋯ , IA (P10)} ,
X RE (Mu) = {RE (P1) , ⋯ , RE (P10)} .
Four UMs on each of 12 datasets are shown in Figs 2-13. The abovementioned results show that the values of IE and IA increase, when the attribute subsets become larger; Nevertheless, the values of IG and RE decrease, when the attribute subsets become larger. We can conclude that the proposed UMs in a MVIS have monotonicity with the growth of the attribute subsets. Therefore, IG, IE, IA and RE can be utilized to measure the uncertainty of a MVIS.
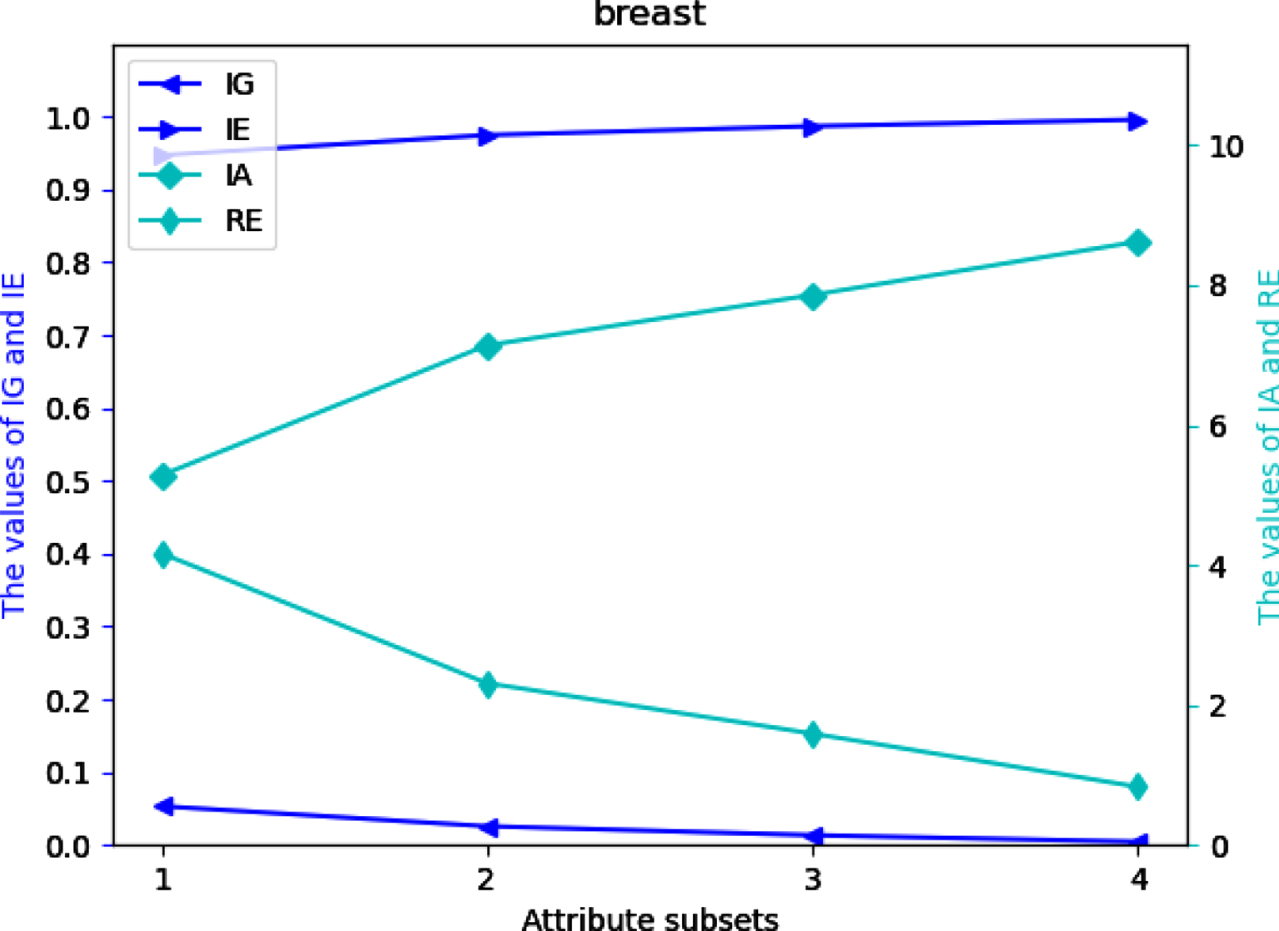
Values of IG, IE, IA and RE on dataset Br.
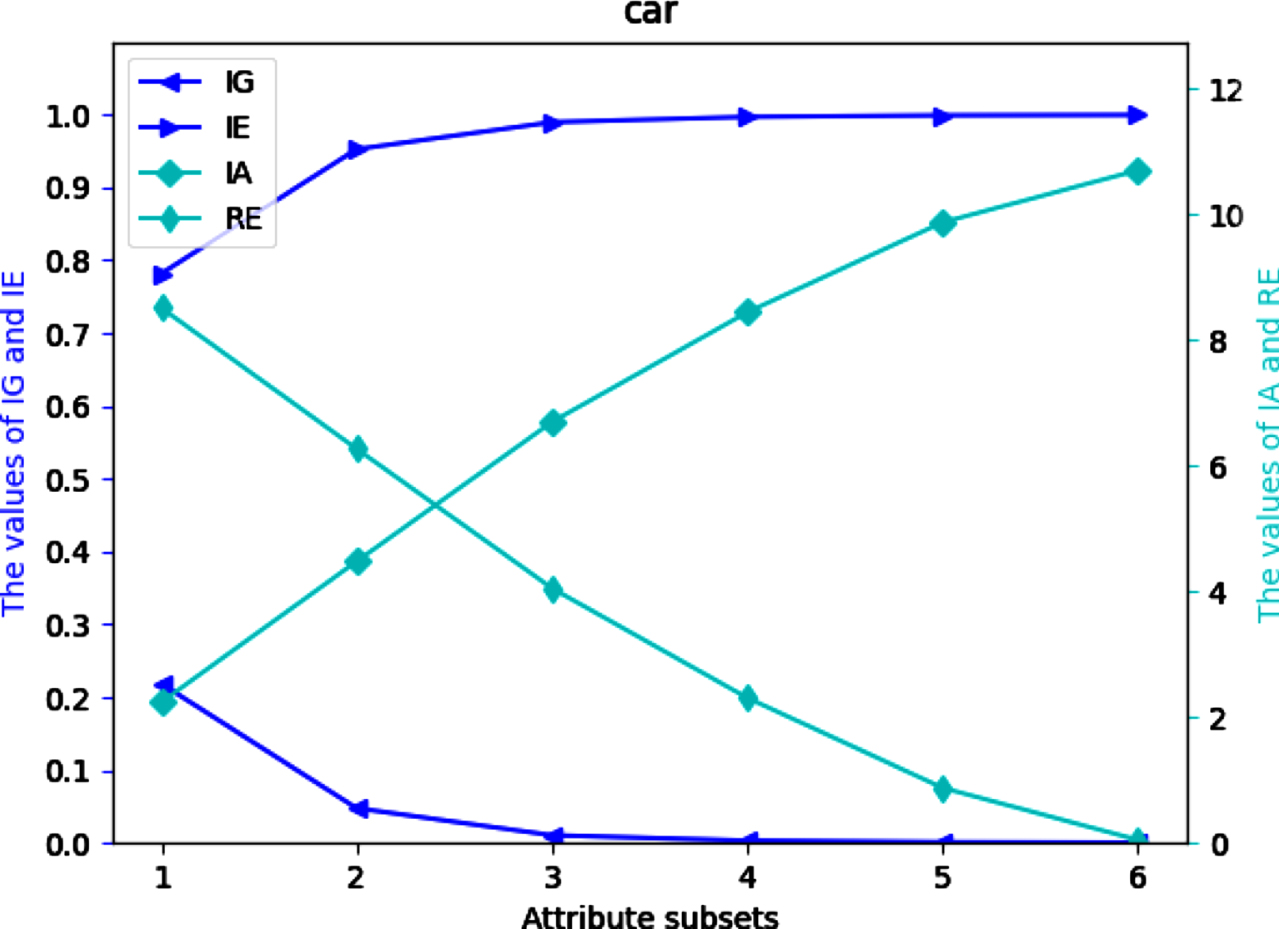
Values of IG, IE, IA and RE on dataset Ca.
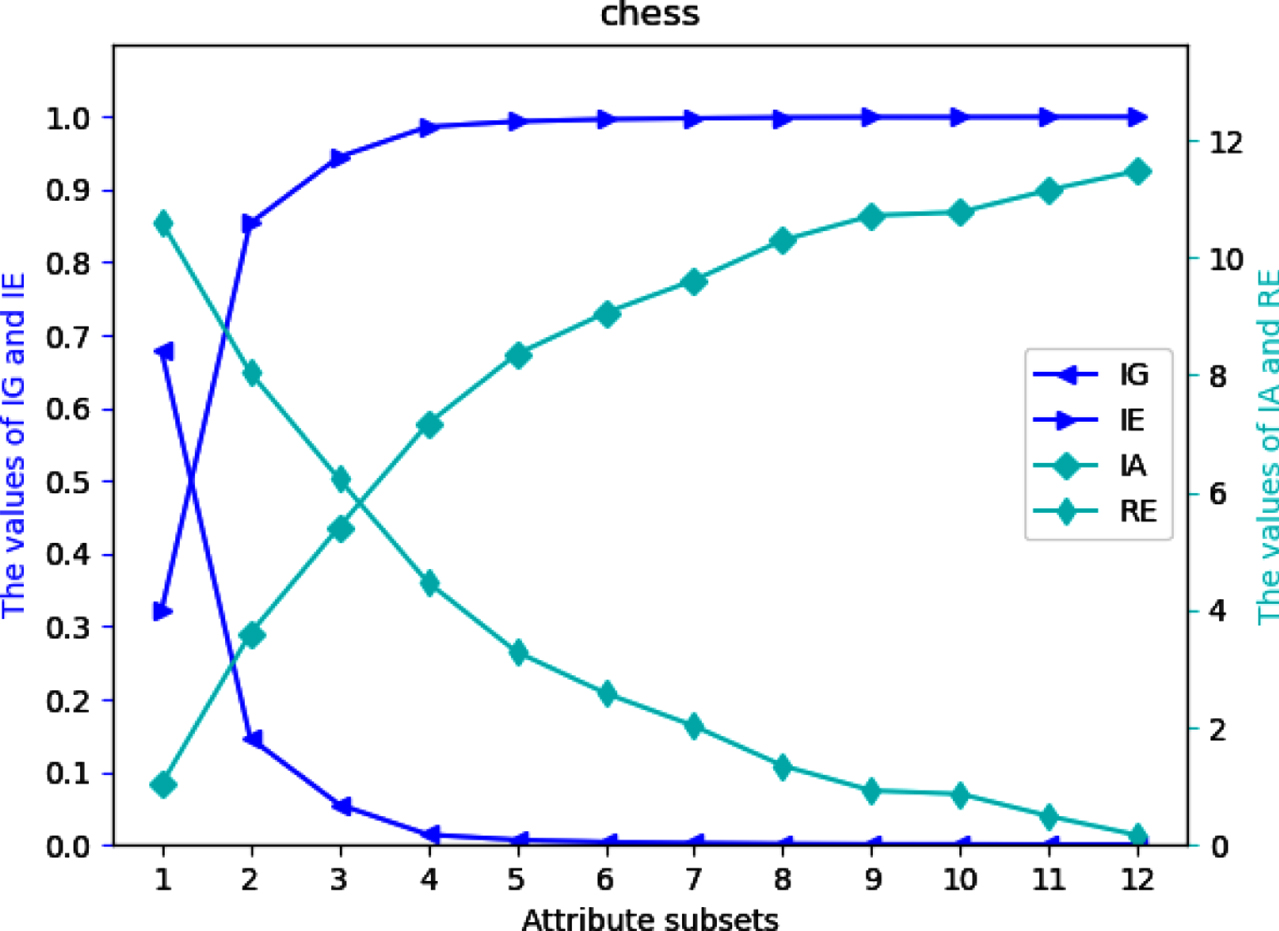
Values of IG, IE, IA and RE on dataset Ch.
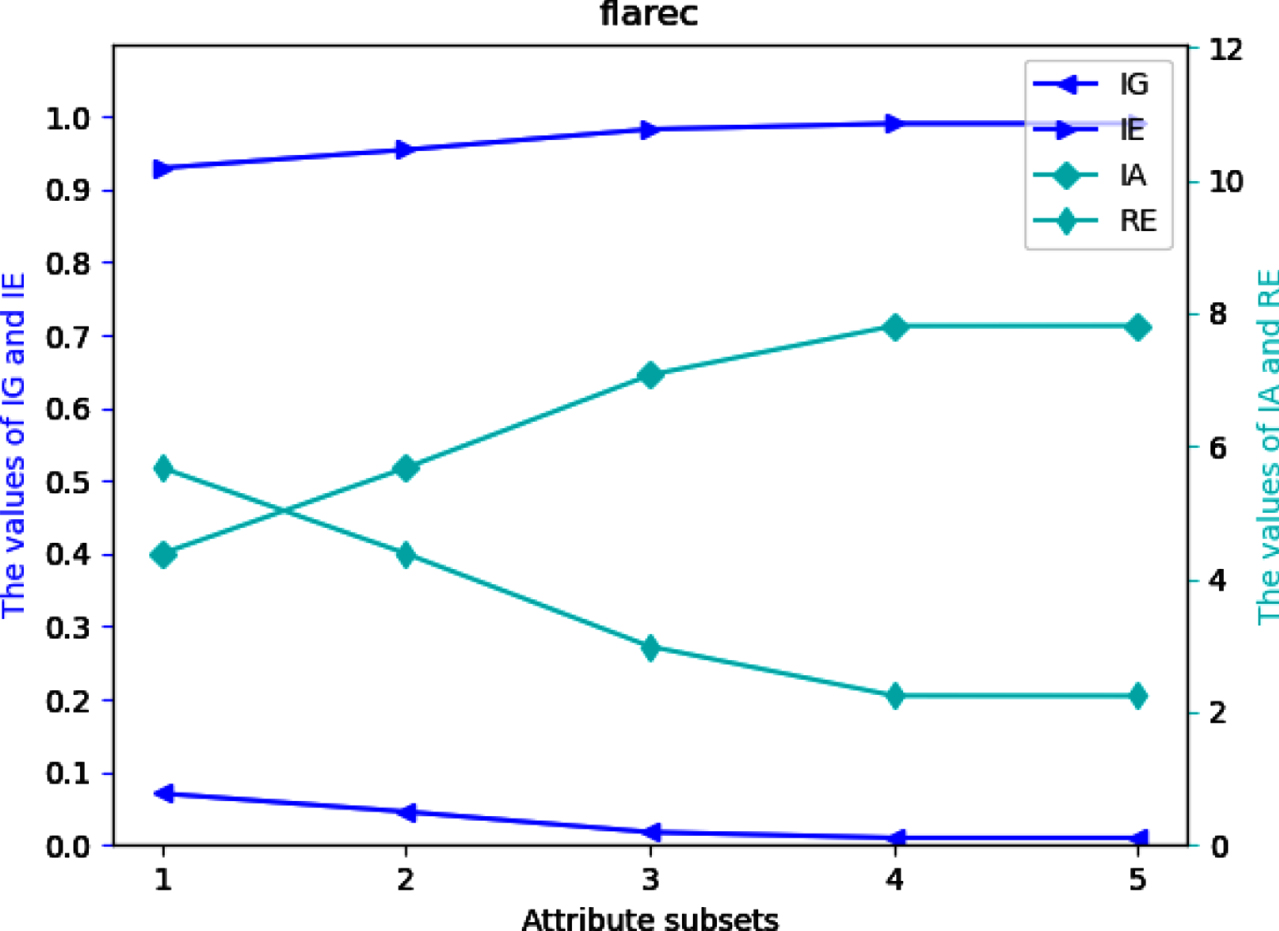
Values of IG, IE, IA and RE on dataset Fl.
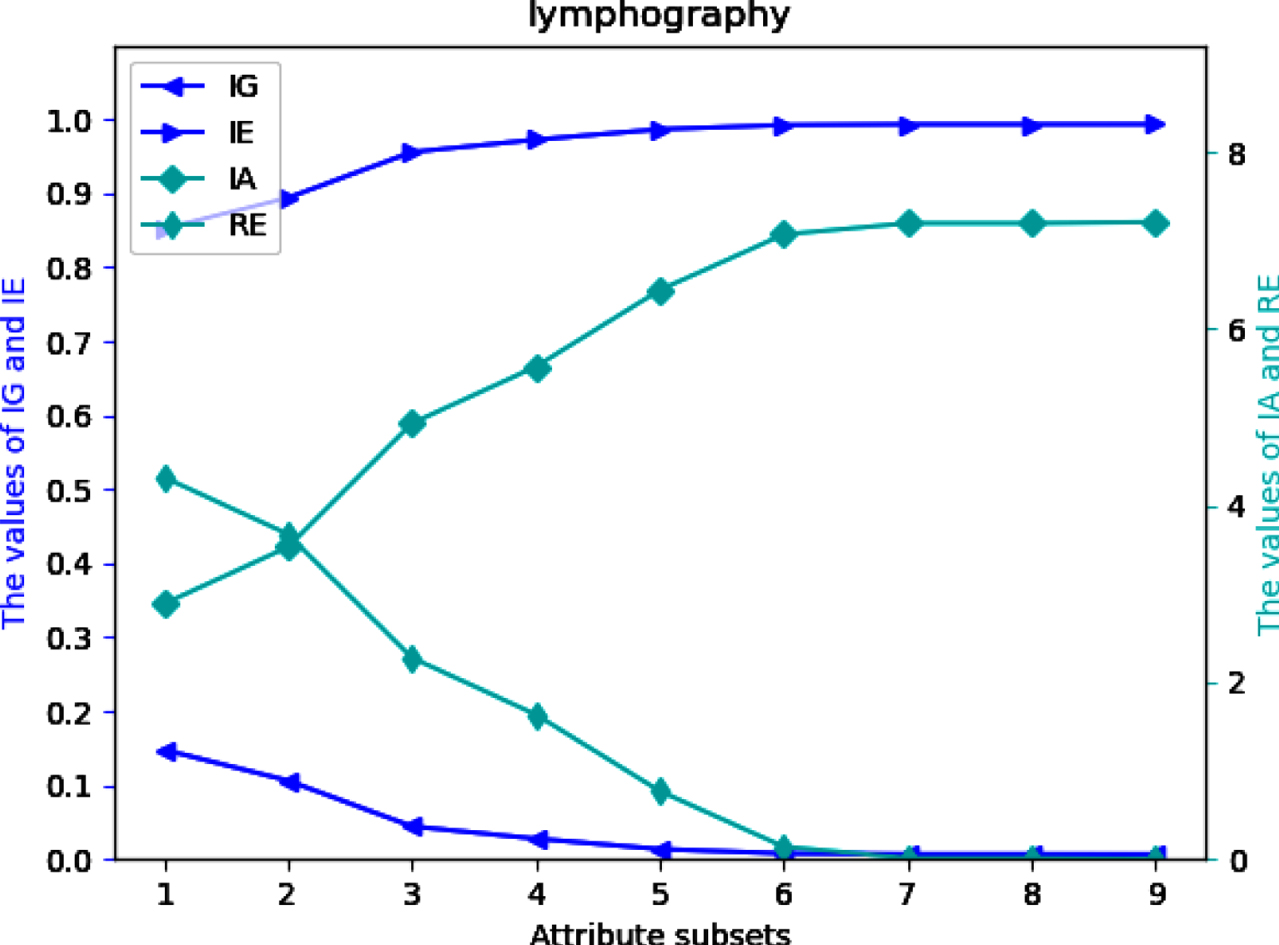
Values of IG, IE, IA and RE on dataset Ly.
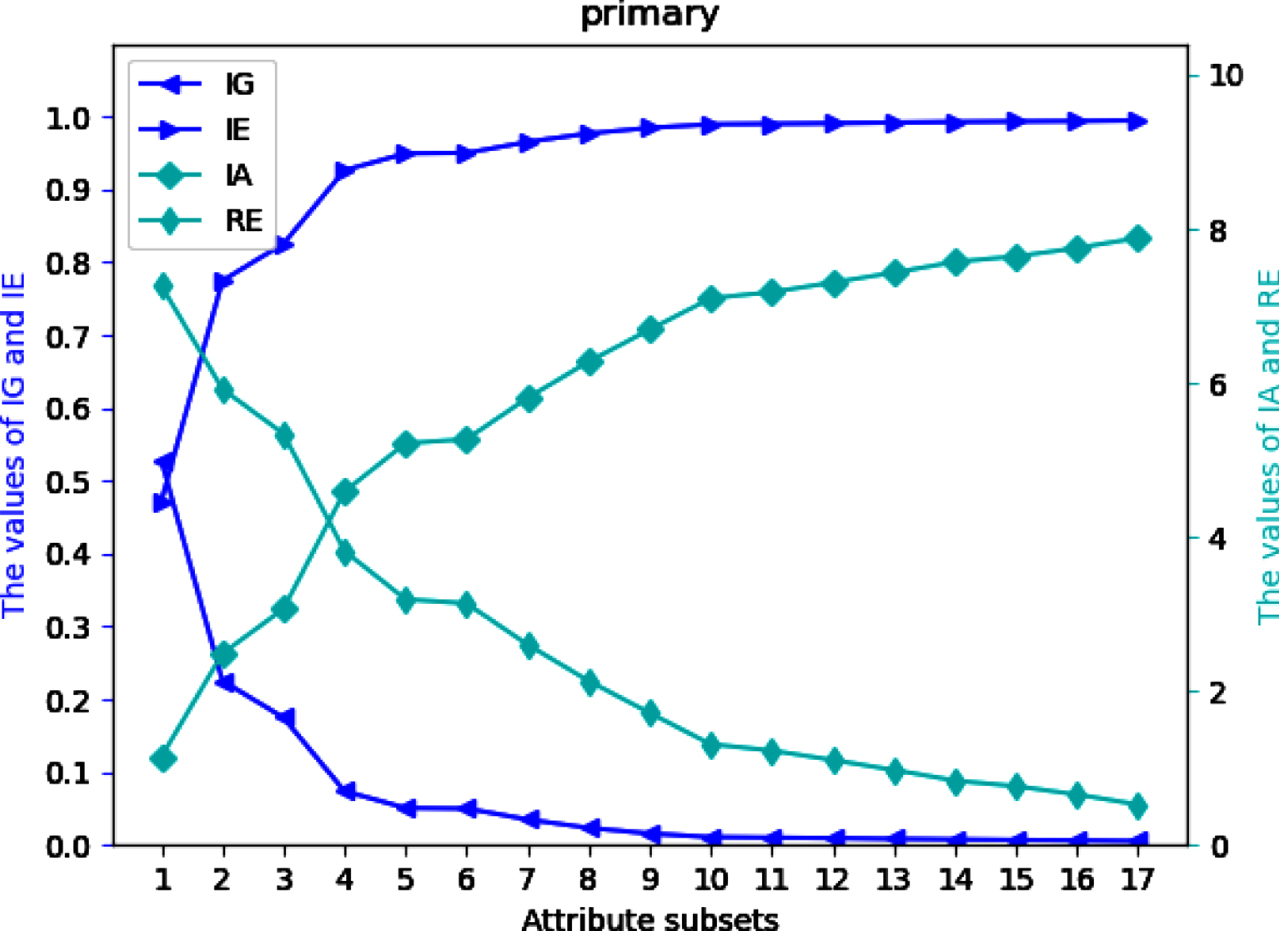
Values of IG, IE, IA and RE on dataset Pr.
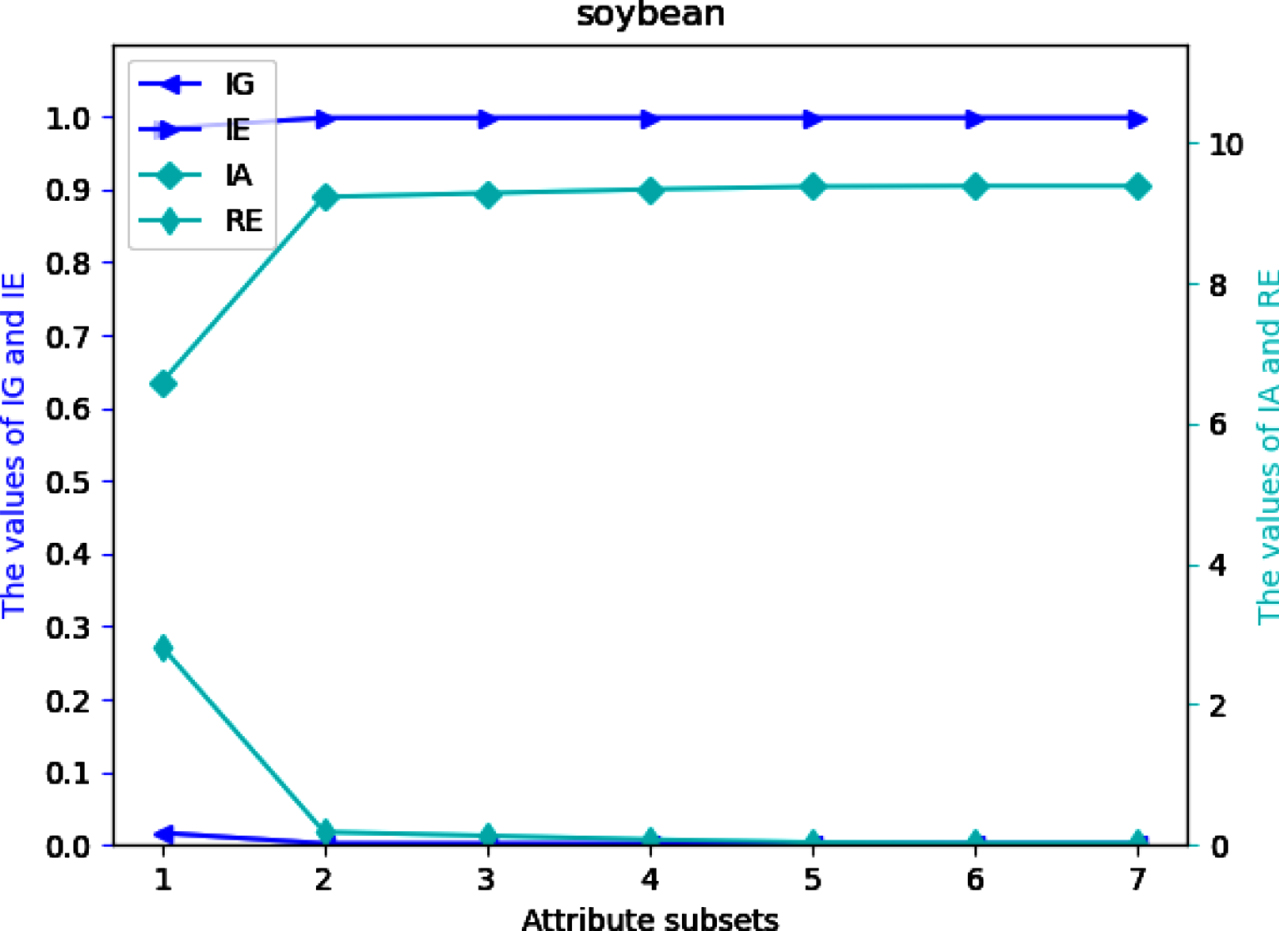
Values of IG, IE, IA and RE on dataset So.
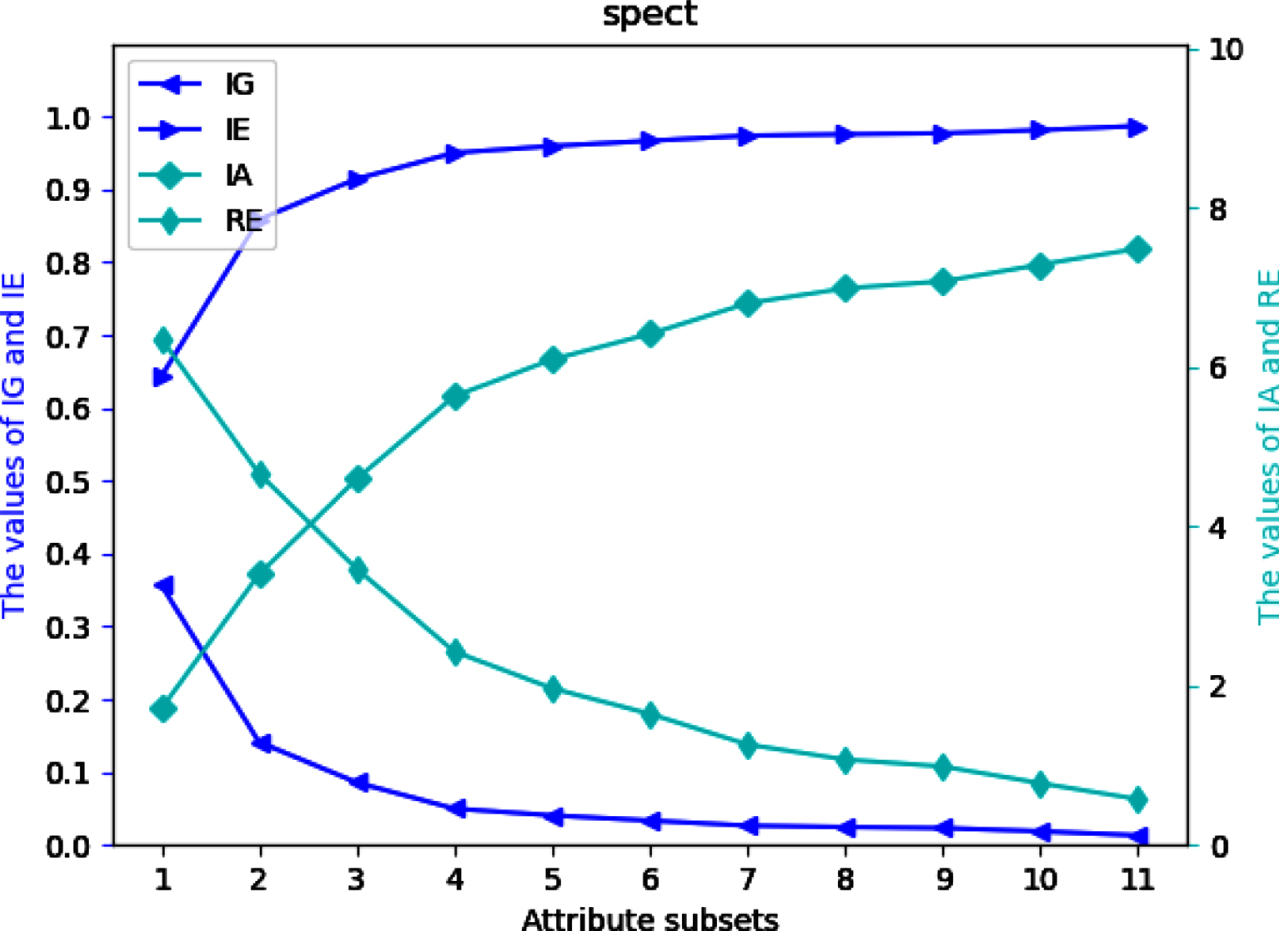
Values of IG, IE, IA and RE on dataset Sp.
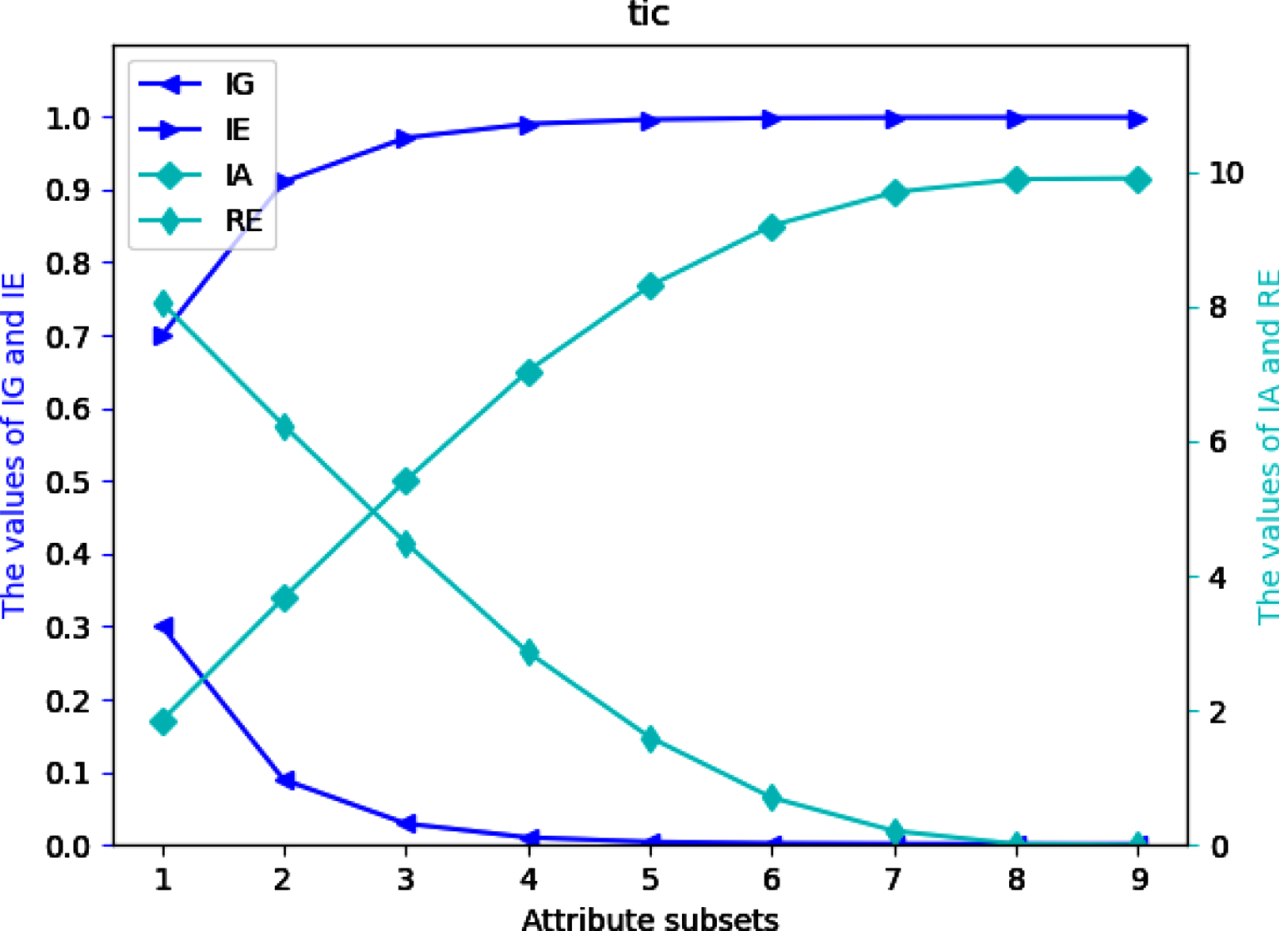
Values of IG, IE, IA and RE on dataset Tt.
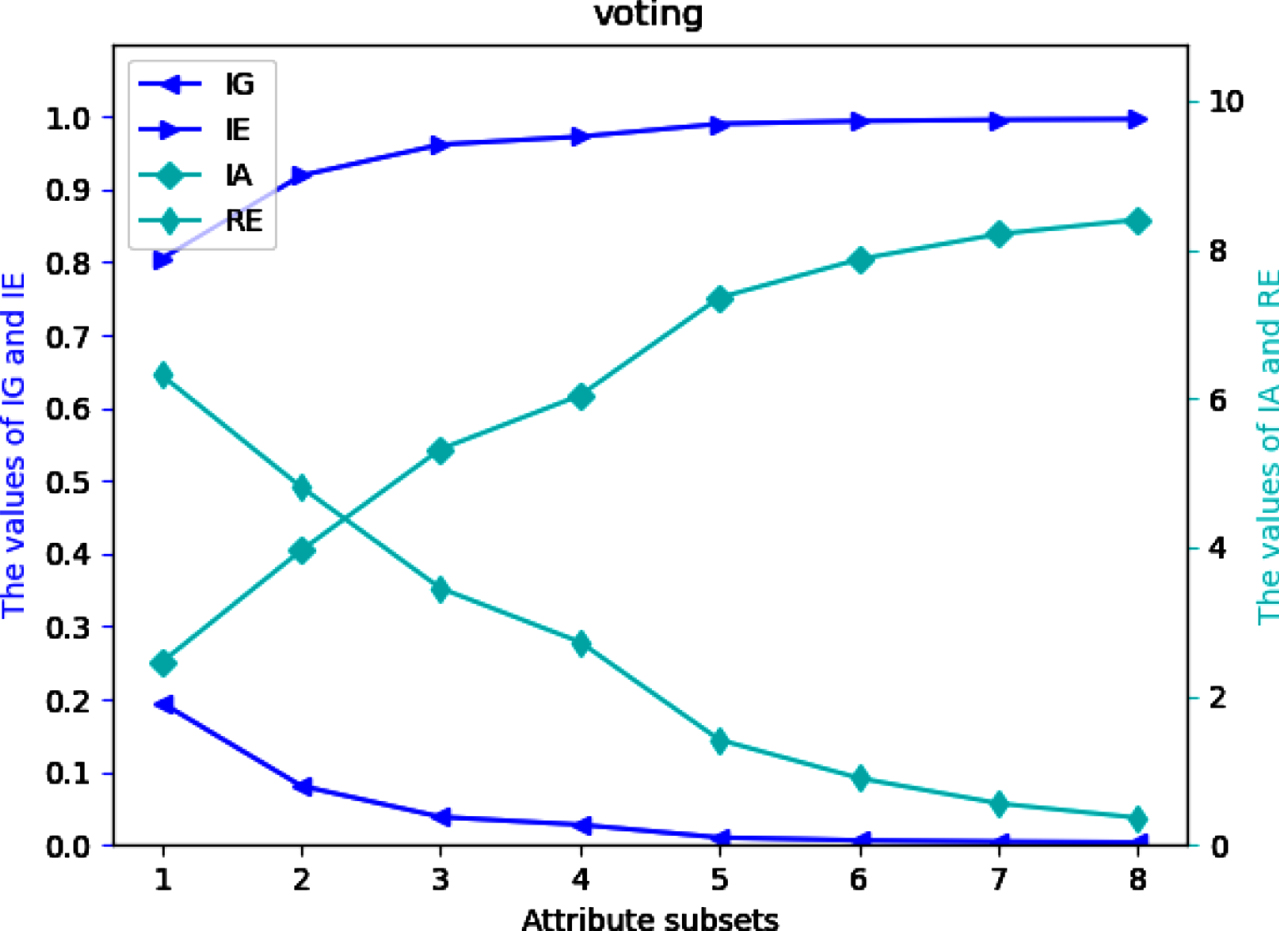
Values of IG, IE, IA and RE on dataset Vr.
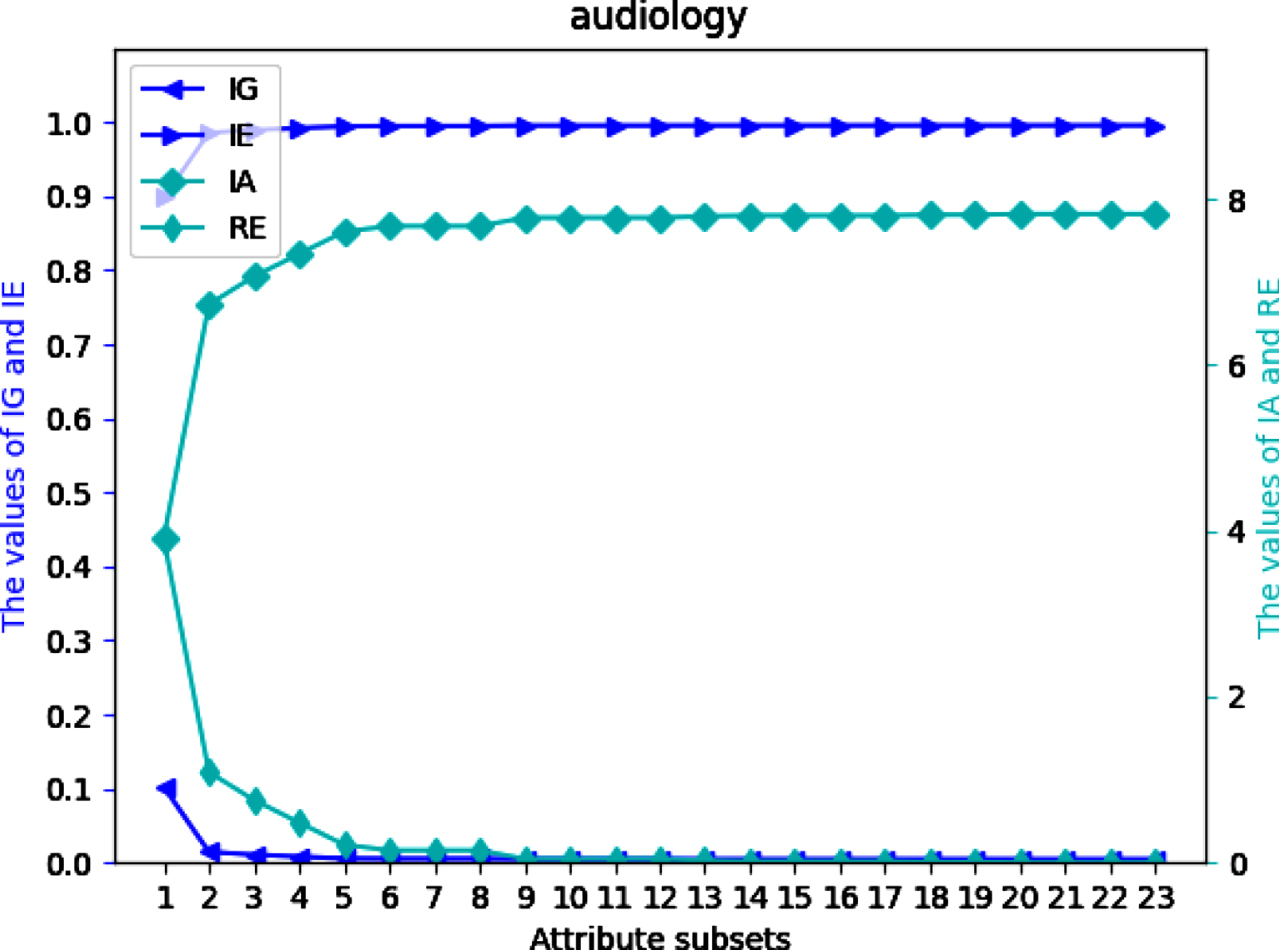
Values of IG, IE, IA and RE on dataset Au.
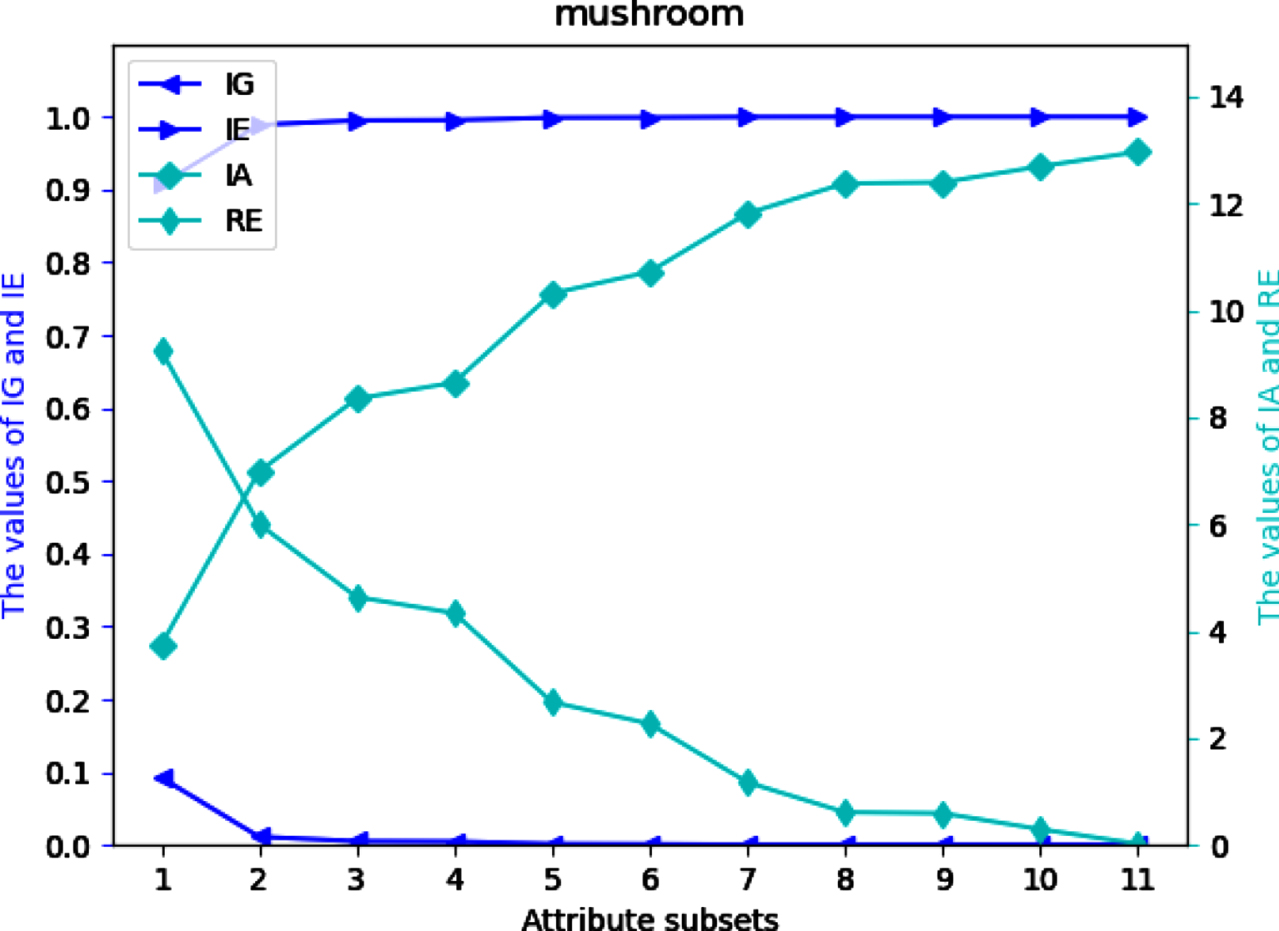
Values of IG, IE, IA and RE on dataset Mu.
In this subsection, we analyze the degree of dispersion of four UMs on the perspective of statistics.
Given a dataset X = {x1, ⋯ , x
n
}, the standard deviation coefficient is defined as
In the following expressions, standard deviation coefficient is referred to as CV-value.
The standard deviation coefficient can represent the degree of dispersion between datasets, the larger standard deviation coefficient is, the higher dispersion is; the smaller standard deviation coefficient is, the lower dispersion is.
With that in mind, we can compute the CV-values of IG, IE, IA and RE on each of twelve datasets are shown in Figs 12-21.
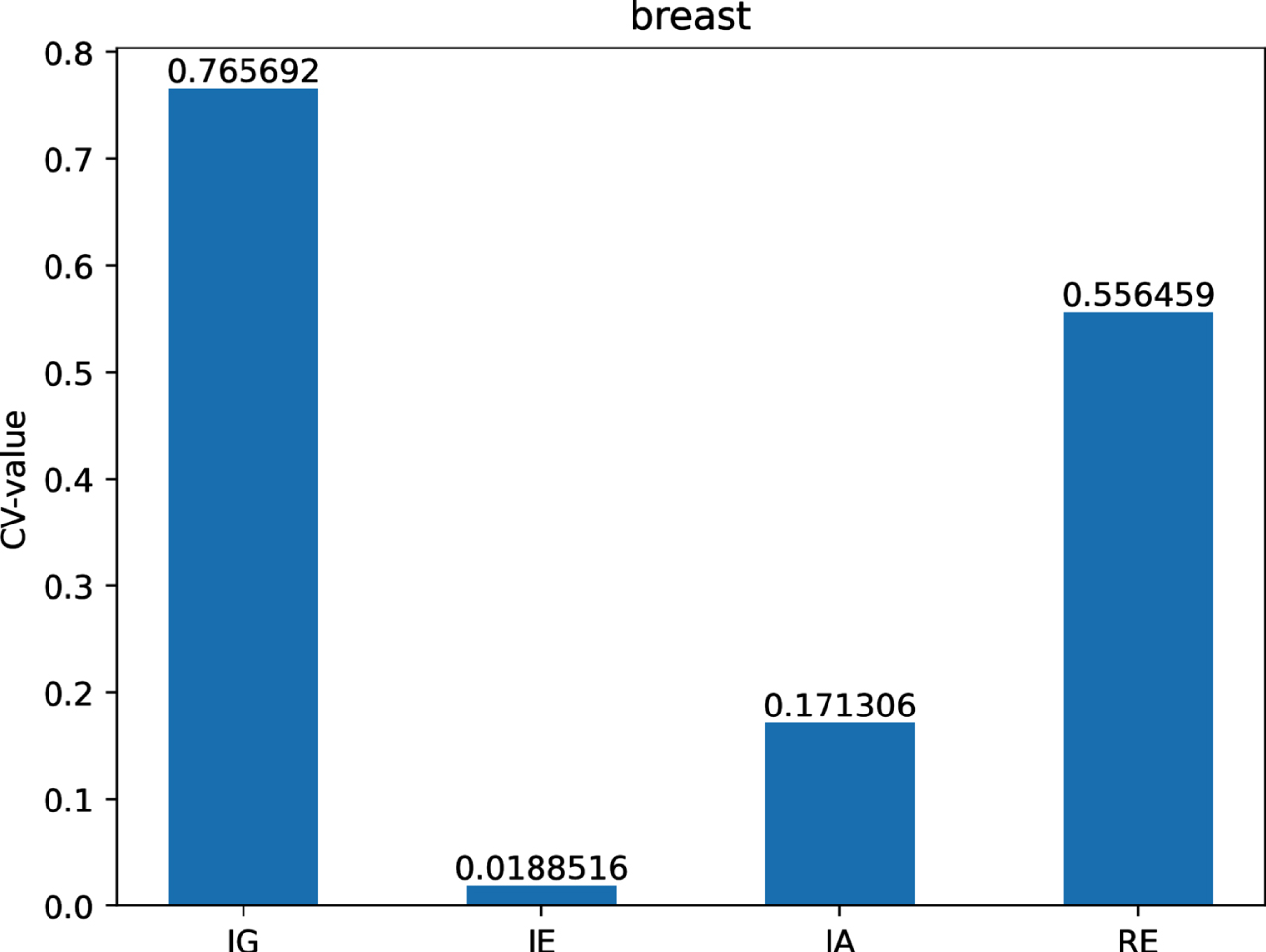
The CV-values of IG, IE, IA and RE on dataset Br.
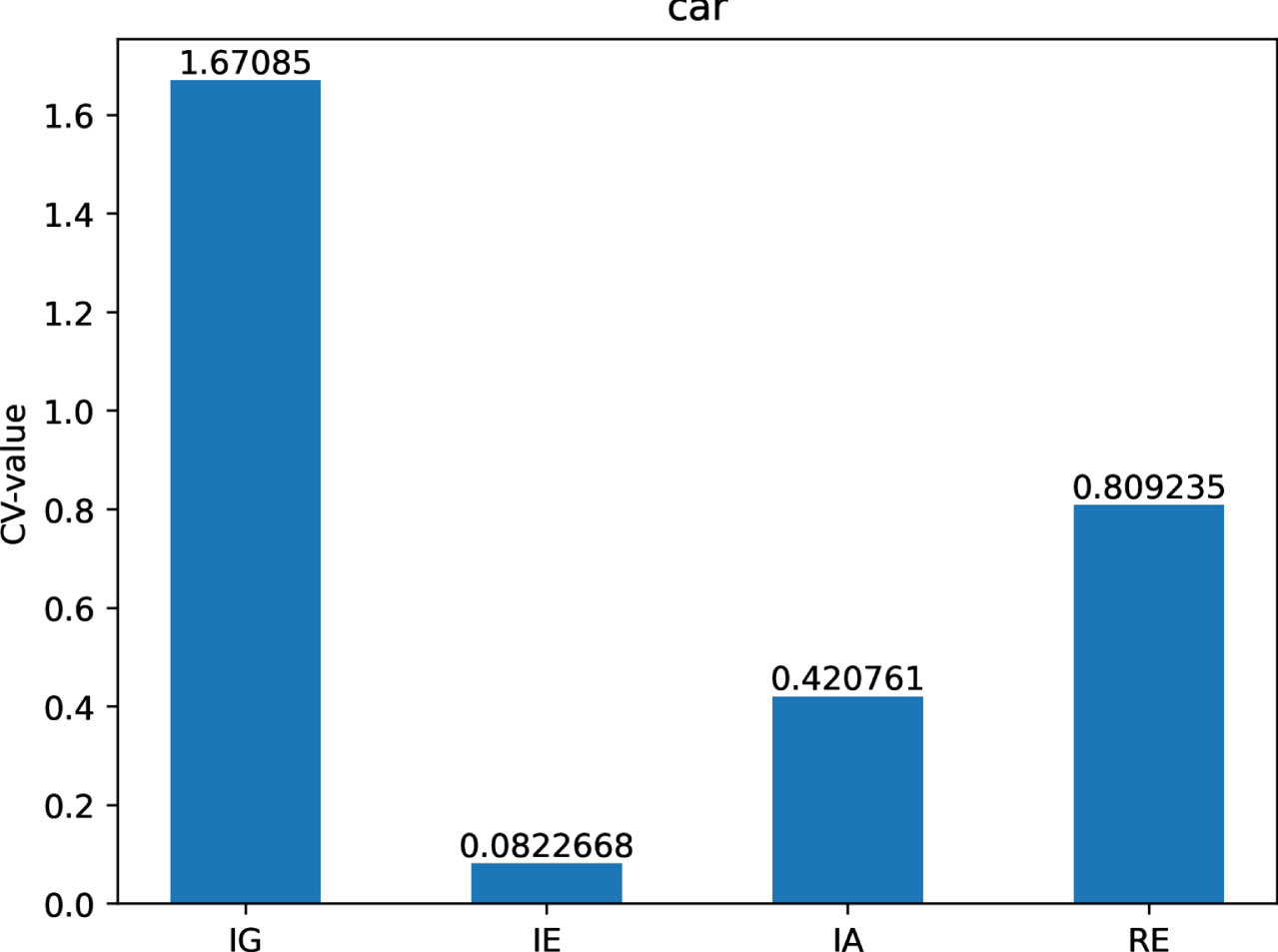
The CV-values of IG, IE, IA and RE on dataset Ca.
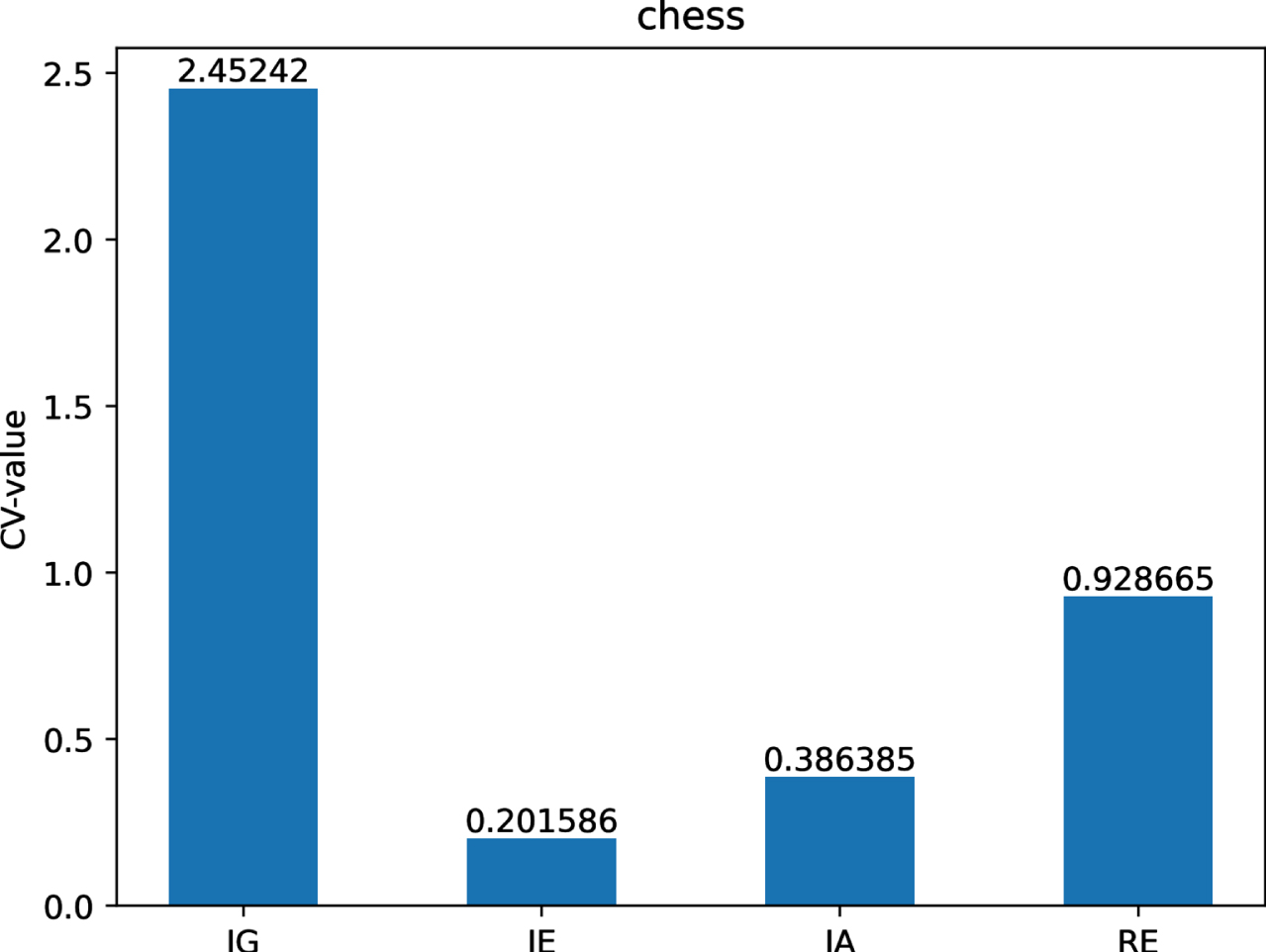
The CV-values of IG, IE, IA and RE on dataset Ch.
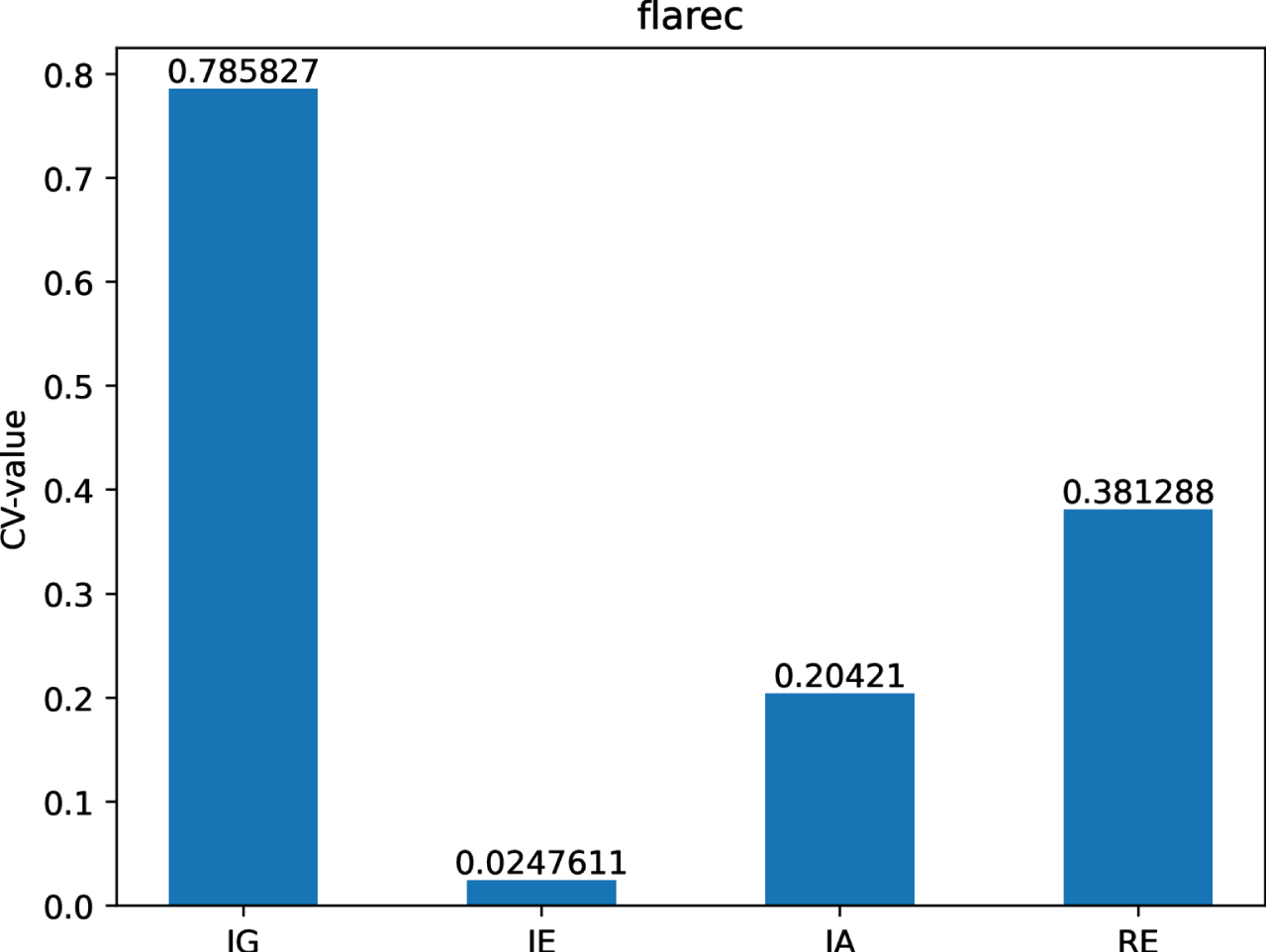
The CV-values of IG, IE, IA and RE on dataset Fl.
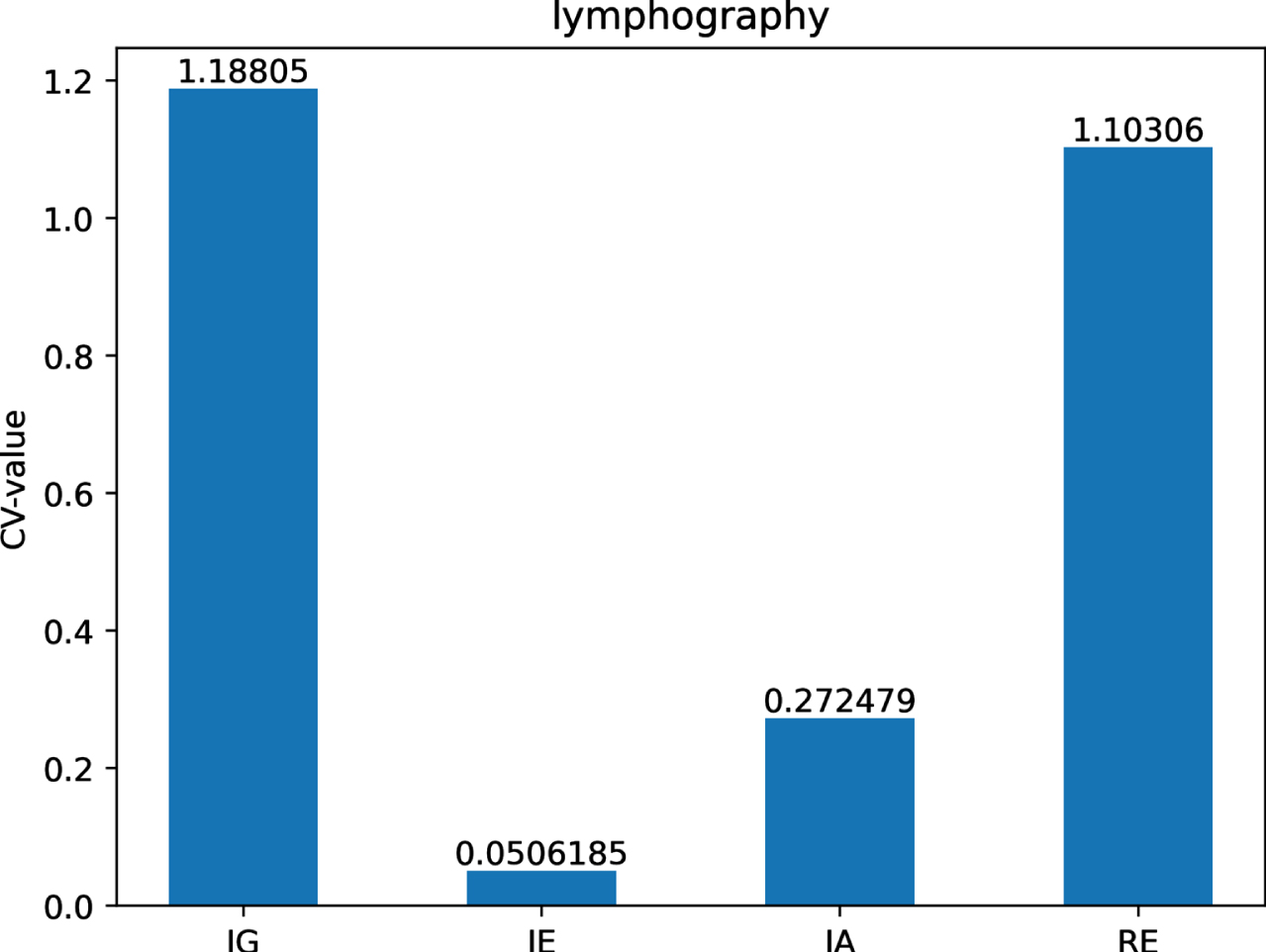
The CV-values of IG, IE, IA and RE on dataset Ly.
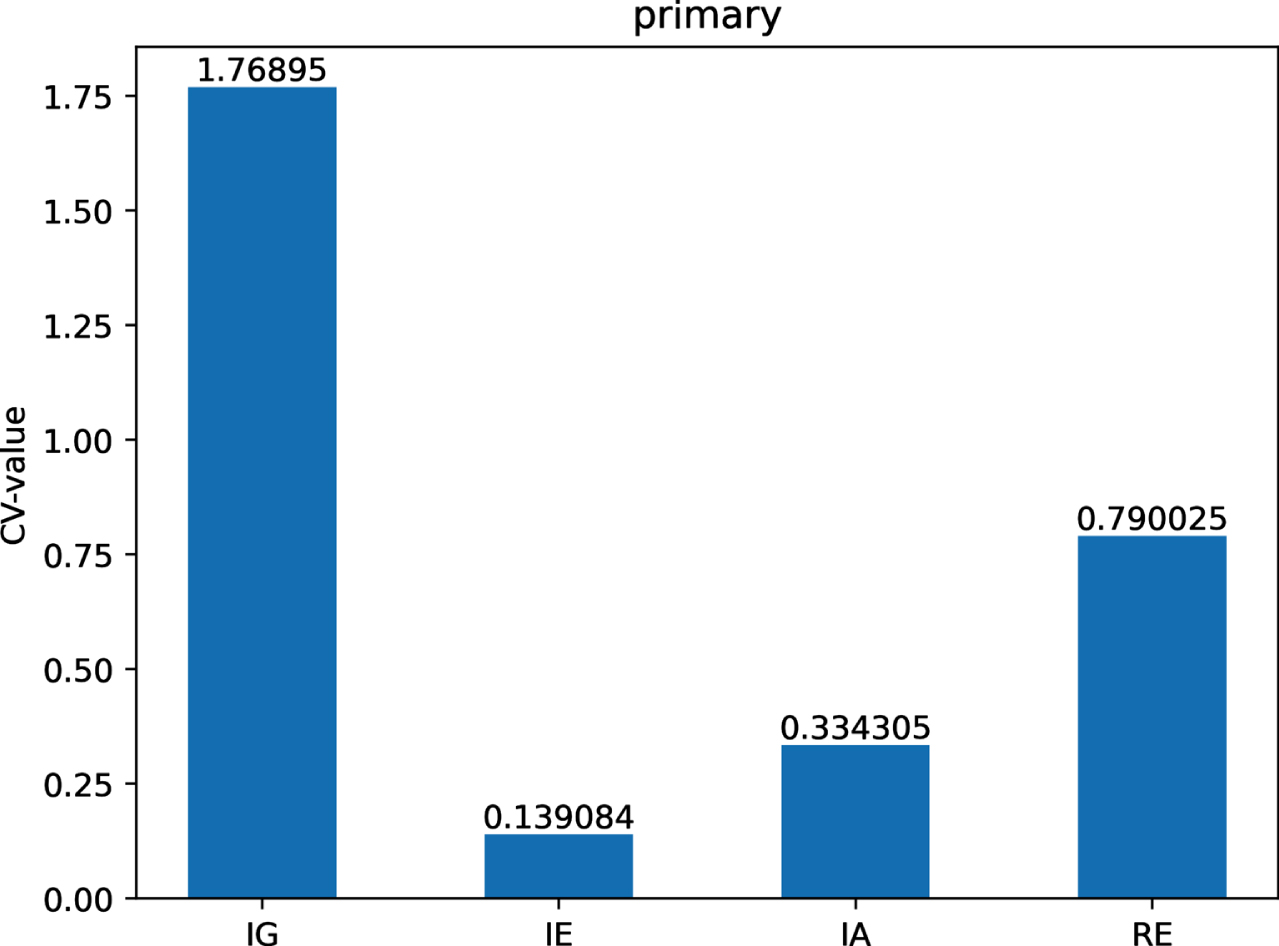
The CV-values of IG, IE, IA and RE on dataset Pr.
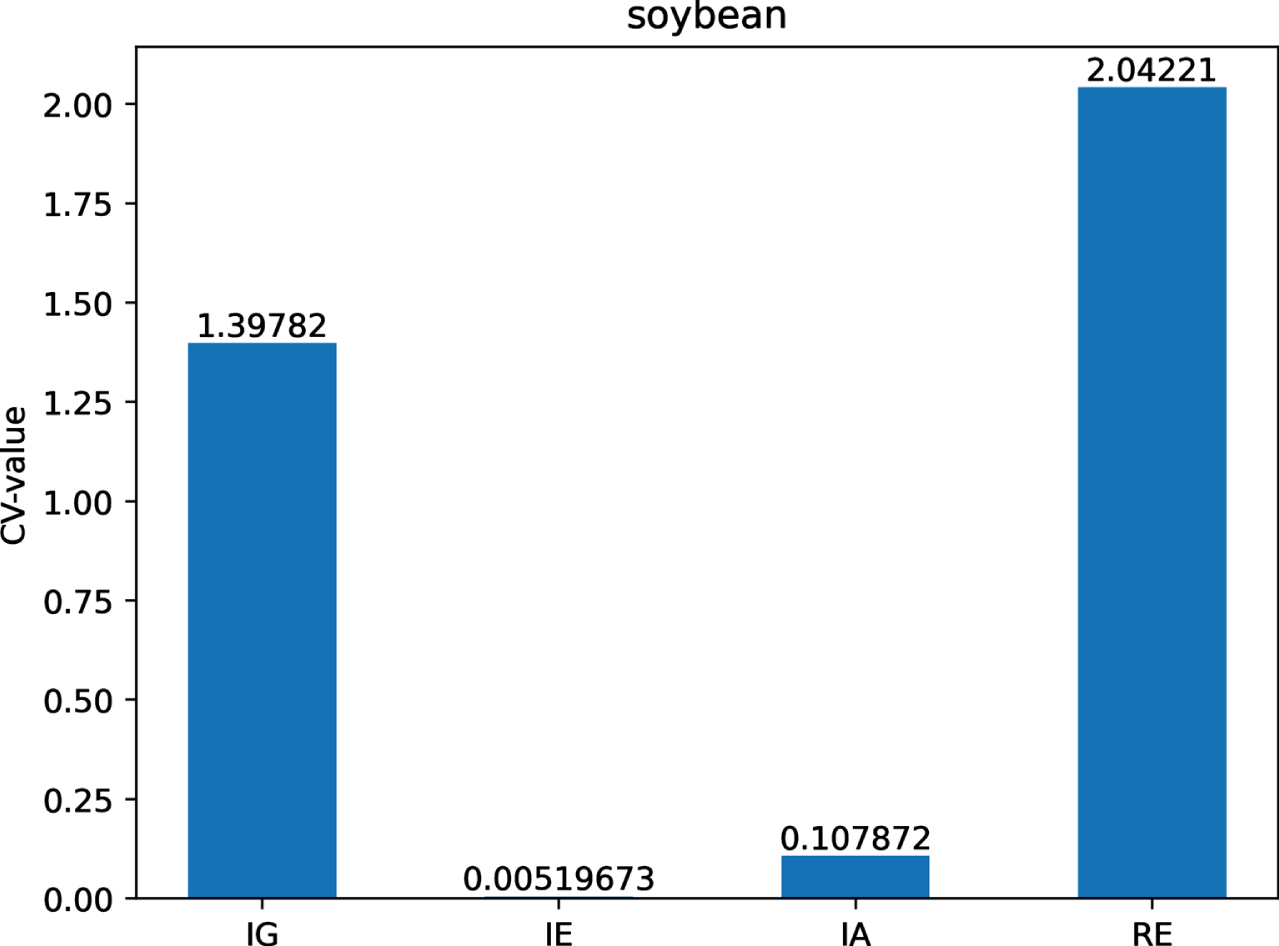
The CV-values of IG, IE, IA and RE on dataset So.
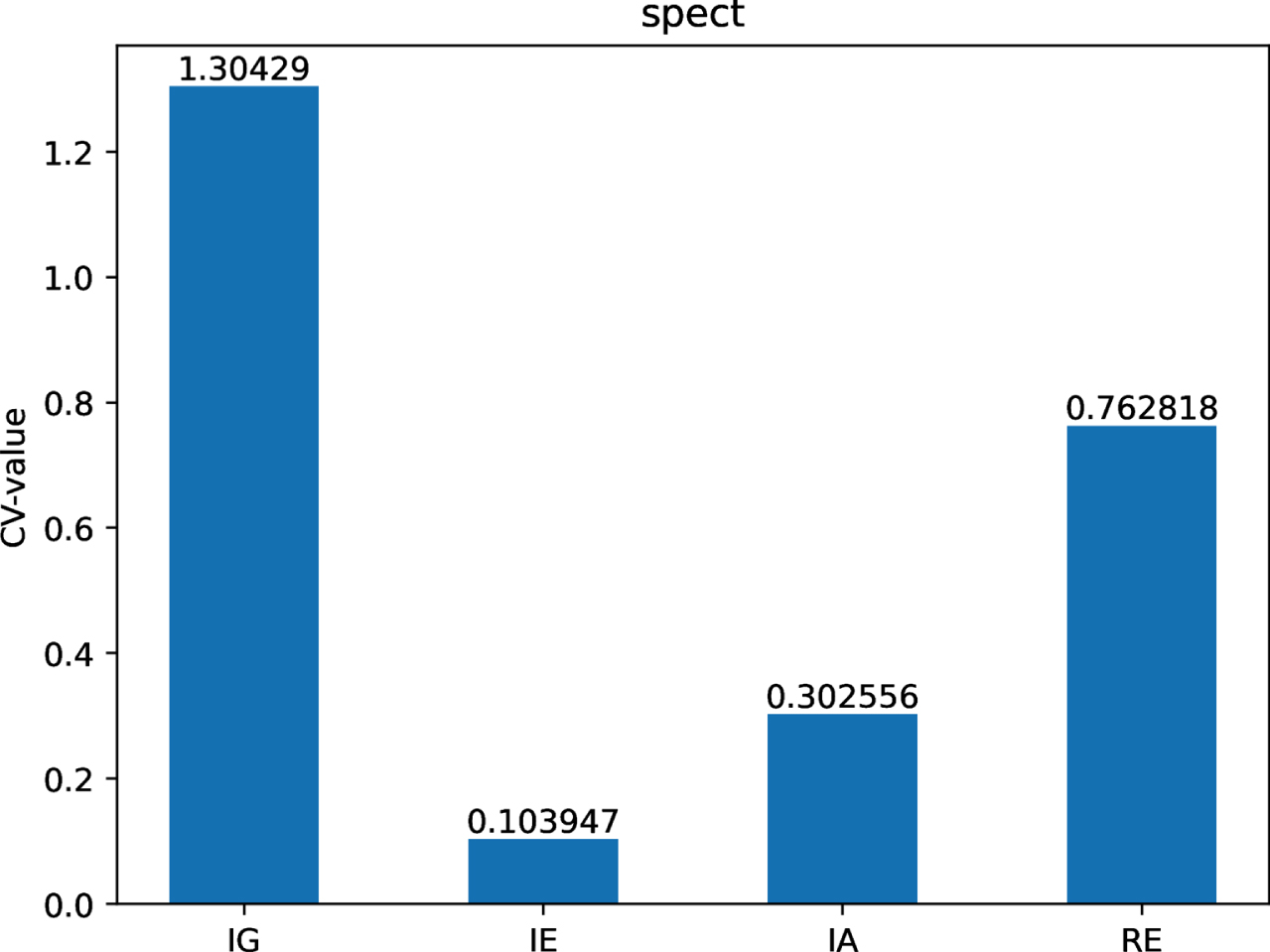
The CV-values of IG, IE, IA and RE on dataset Sp.
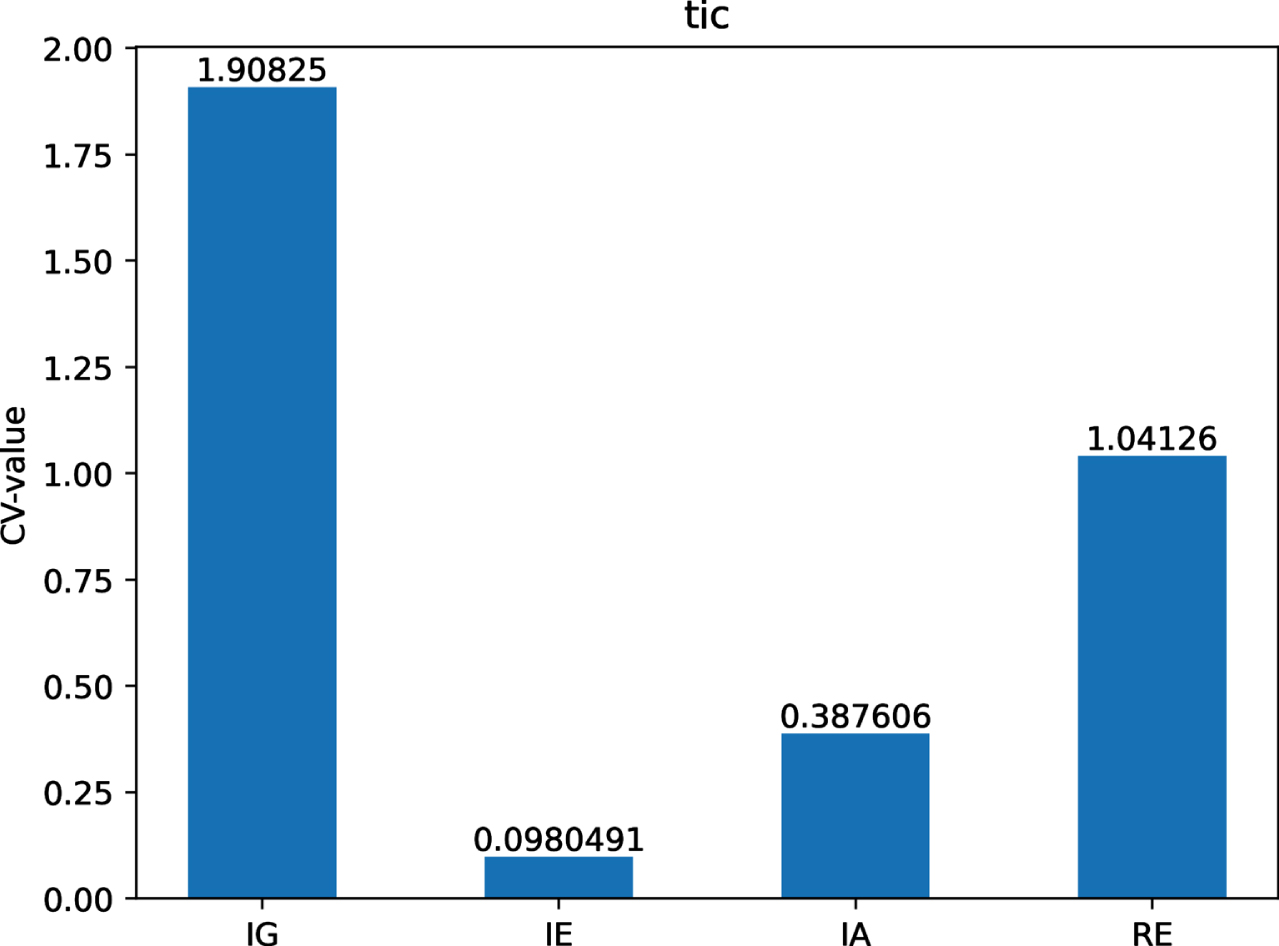
The CV-values of IG, IE, IA and RE on dataset Tt.
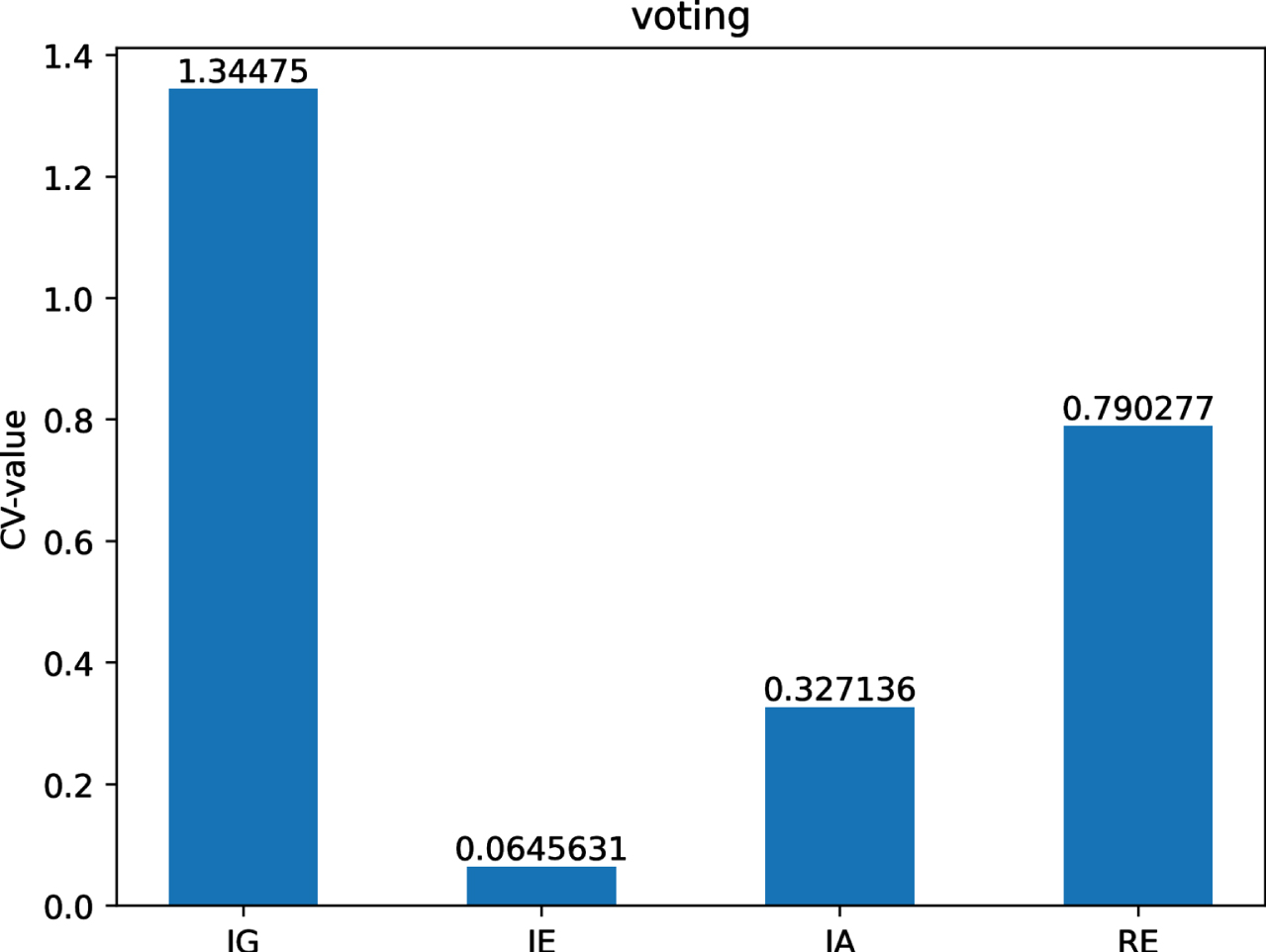
The CV-values of IG, IE, IA and RE on dataset Vr.
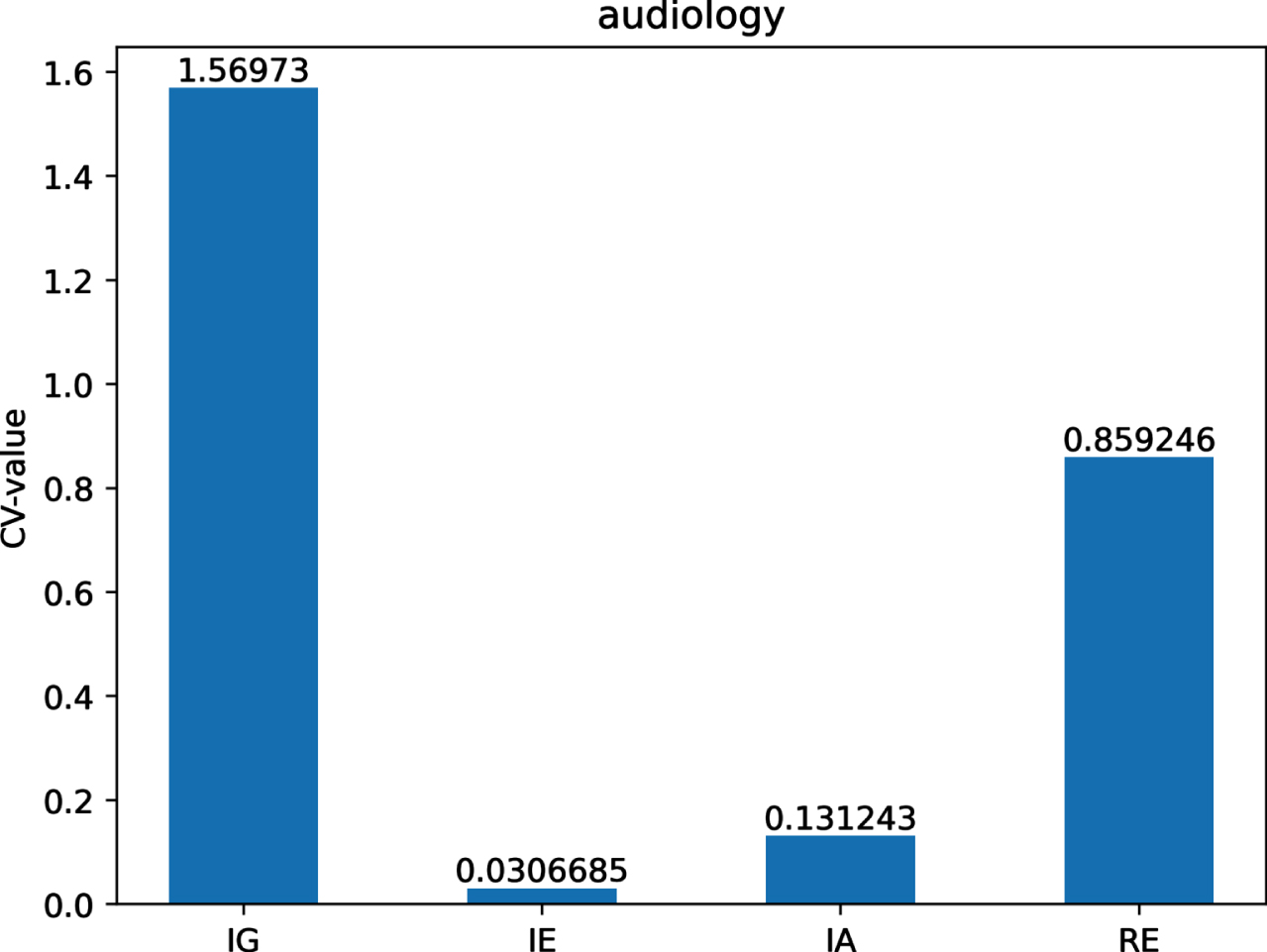
The CV-values of IG, IE, IA and RE on dataset Au.
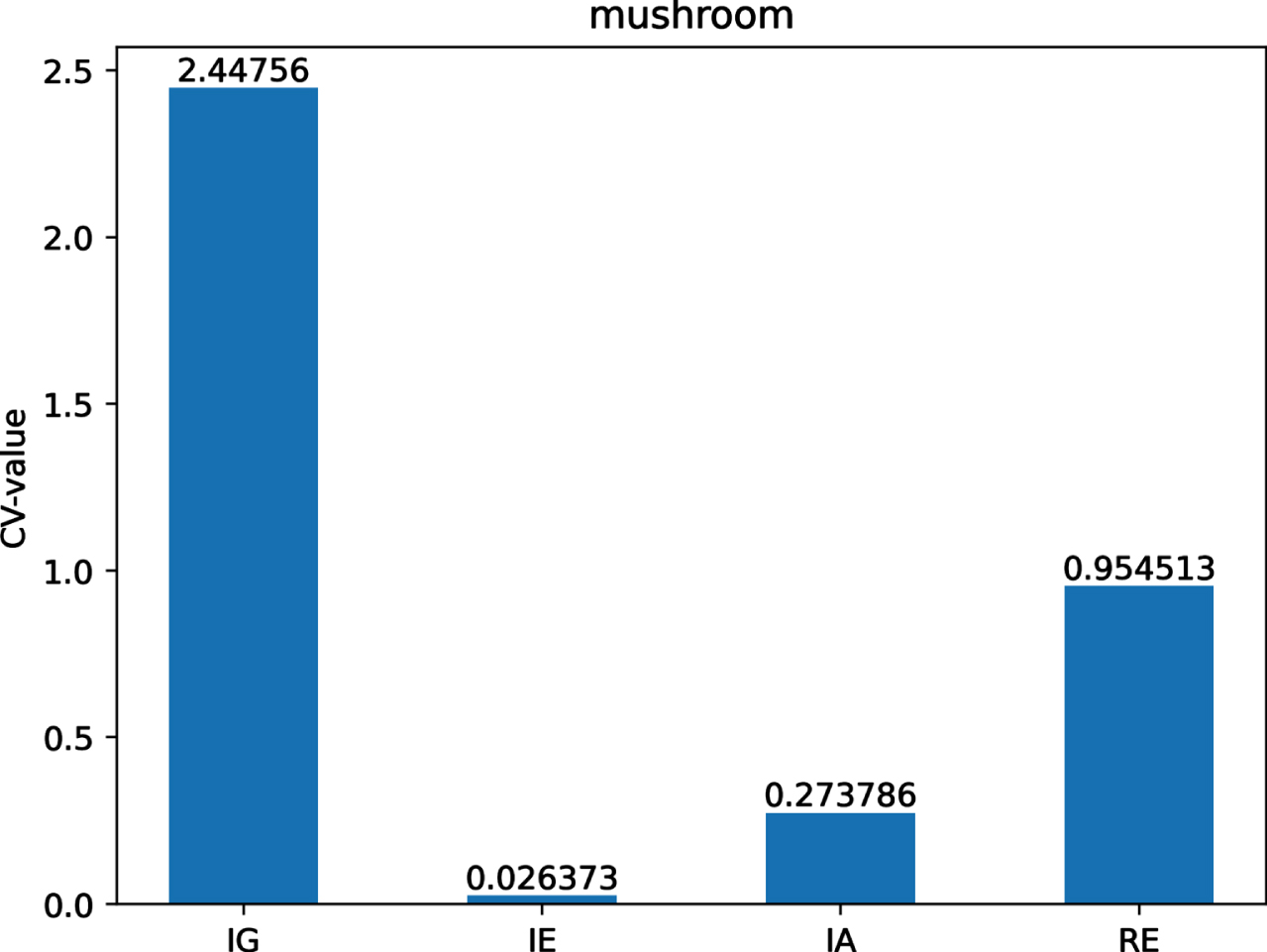
The CV-values of IG, IE, IA and RE on dataset Mu.
Figs 12-21 indicate that the CV-values of IG and RE are much greater than those of IE and IA on each of twelve datasets. Therefore, IE and IA have the best measuring effect on the uncertainty of twelve datasets. In other words, IE and IA are more suitable for measuring the uncertainty of a MVIS from the perspective of dispersion.
Friedman test is a statistical test, which is usually used to compare the overall performance of k algorithms on N datasets. If there were different performances, the Nemenyi test will be applied to distinguish which algorithm is significantly different from other algorithms. In this subsection, we will use Friedman test and Nemenyi test to demonstrate which uncertainty measurement has better performance.
Suppose that N and k are the number of datasets and algorithms, respectively. The Friedman test is defined by
τ F is the F-distribution with k - 1 and (k - 1) (N - 1) degrees of freedom. If the value of τ F is greater than τ α (k - 1, (k - 1) (N - 1)), then null hypothesis is rejected. It indicates that there is a significant difference between algorithms, then we can continue to carry out the Nemenyi test.
The Nemenyi test of critical difference, written as CD
α, is defined by
In subection 6.2, the CV-values of IG, IE, IA and RE on each of twelve datasets are received and showed in Table 10. Four UMs can be regarded as four algorithms and ranked by CV-values on each of twelve datasets. The results of the ranking of CV-values are depicted in Table 11.
The CV-values of IG, IE, IA and RE on each of twelve datasets
The CV-values of IG, IE, IA and RE on each of twelve datasets
The ranking of CV-values of IG, IE, IA and RE on each of twelve datasets
In the following, Friedman test and Nemenyi test will be used to test the performance of four UMs.
(1) For twelve datasets and four UMs, τ F is the F-distribution with 3 and 33 degrees of freedom. We can calculate τ0.05 (3, 33) =2.89, τ F = 294.56. Apparently, τ F is much larger than 2.96. Hence, the null hypothesis is rejected under the significance level α = 0.05, namely, IG, IE, IA and RE have dramatic difference on performance.
(2) To further demonstrate the dramatic difference between any two of IG, IE, IA and RE, the Nemenyi test is carried out. After calculation,
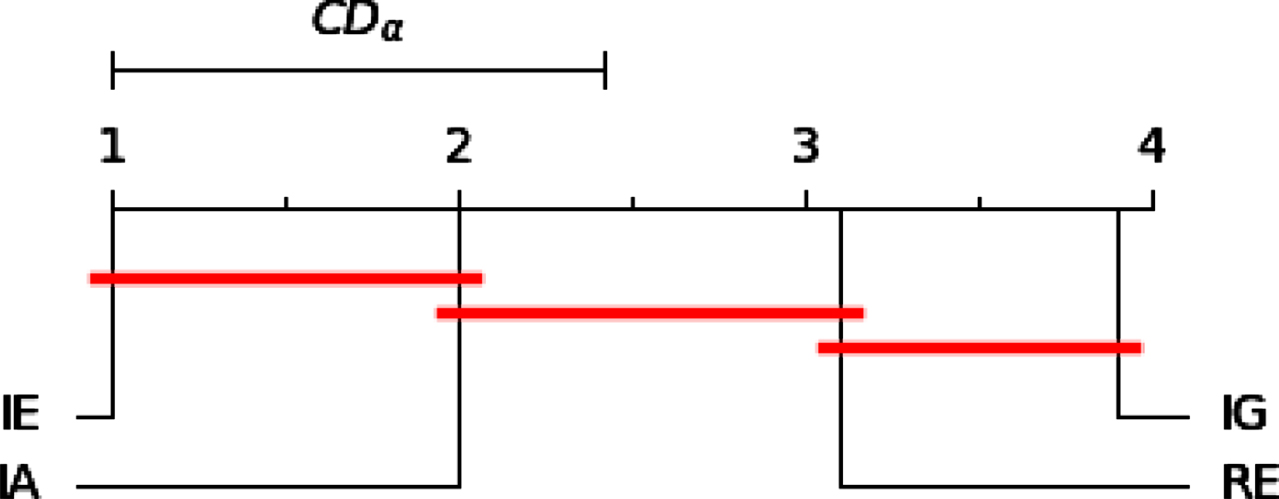
The results of the Nemenyi test for four UMs.
From Fig 26, we can draw the following conclusions:
(i) IE is statistically superior to other UMs, namely, IE has better performance than other UMs.
(ii) There is significant difference between IE and RE, IE and IG, and IA and IG.
(iii) There is no significant difference between IE and IA, IA and RE, IG and RE.
1) In information systems, uncertain data are often presented in fuzzy form. Liu et al. [20] studied measures of uncertainty based on Gaussian kernel for type-2 fuzzy information systems, they are δ-coarse granularity and δ-rough entropy. Through effectiveness analysis, δ-coarse granularity and δ-rough entropy are monotonically decreasing when attribute subset become larger. It means that when the attribute subset becomes larger, the uncertainty of type-2 fuzzy information system is reduced.
2) Considering that relatively less studies for the interval-valued decision systems, Liao et al. [26] proposed three-level and three-way uncertainty measurements by means of three-way weighted entropies of interval-valued decision systems. Through theoretically deduced and experimentally verified three-level and three-way uncertainty measurements are monotonicity and non-monotonicity, respectively.
3) A MVIS can be seen as a model that is the result of information fusion of multiple categorical ISs and helps deal with missing values in the dataset. This paper constructs information structures in a MVIS based on tolerance relations by using set matrices. On the basis of the information structures, granularity measures, entropy measures and information amounts are proposed to measure uncertainty of a MVIS. Through theoretically deduced and experimentally illustrate that the proposed measures are monotonicity.
Conclusions
In this paper, information structures in a MVIS have been proposed and studied. Actually, information structures were composed of information granules from the view of GrC. Information granules have been constructed from tolerance relations by means of Hellinger distance in a MVIS. The family of all these information granules constitutes a vector that is a information structure induced by a given attribute subset. Considering the association of information structures induced by two attribute subsets, relationships between information structures have been researched from two aspects of dependence and separation. In addition, some properties of information structures by using information distance and inclusion degree have been proved. Uncertainty measurements as the applications of information structure have been investigated, numerical experiments and effectiveness analysis on twelve datasets demonstrate the uncertainty measurement of IE that had better performance than others. Nevertheless, the proposed four UMs of a MVIS only are the extension of the previous measurement index and we do not consider how to more effectively choose the parameter θ. In future work, we will study how to more effectively choose parameter θ in practical application and use information structures to deal with decision making problems under uncertainty.
Footnotes
Acknowledgments
The authors would like to thank the editors and the anonymous reviewers for their valuable comments and suggestions which have helped immensely in improving the quality of this paper. This work is supported by Guangxi university middle-aged and young teachers’ basic scientific research ability improvement project(2020KY19012).