
Abstract
In recent years, imbalanced data learning has attracted a lot of attention from academia and industry as a new challenge. In order to solve the problems such as imbalances between and within classes, this paper proposes an adaptive boundary weighted synthetic minority oversampling algorithm (ABWSMO) for unbalanced datasets. ABWSMO calculates the sample space clustering density based on the distribution of the underlying data and the K-Means clustering algorithm, incorporates local weighting strategies and global weighting strategies to improve the SMOTE algorithm to generate data mechanisms that enhance the learning of important samples at the boundary of unbalanced data sets and avoid the traditional oversampling algorithm generate unnecessary noise. The effectiveness of this sampling algorithm in improving data imbalance is verified by experimentally comparing five traditional oversampling algorithms on 16 unbalanced ratio datasets and 3 classifiers in the UCI database.
Introduction
The classification issue is one of the important research topics in the field of machine learning. Traditional classification methods have achieved good results and accuracy in classifying balanced datasets [13, 18]. However, real datasets are often unbalanced. Imbalance in the data is manifested in two main ways, one is imbalance between classes, that is, the difference between the sample size of one class and the sample size of another class. In addition to imbalances between the majority class and the minority sample, imbalances can also occur within a class of samples. For example, in a common dataset in medicine, an unbalanced medical dataset has ‘healthy’ as the majority sample and ‘sick’ as the minority sample. However, in the ‘sick’ category, the number of leukaemia patients is certainly much smaller than the number of flu patients. For example, an unbalanced medical dataset in a medically common dataset has ‘healthy’ as the majority sample and ‘sick’ as the minority sample. However, in the ‘sick’ category, the number of leukaemia patients is certainly much smaller than the number of flu patients. The dataset mentioned above is the unbalanced dataset that contains between-classes and within-classes at the same time.
In general, techniques for improving unbalanced data are divided into algorithm-level methods, data-level methods [26]. At the level of classification algorithm, the commonly used methods include cost-sensitive learning, single classifier method and ensemble learning method [30]. At the data level, some strategies are adopted to change the distribution of samples and transform unbalanced samples into a state of relatively balanced distribution [24]. The sampling of training data can be accomplished by removing majority samples (under-sampling) or adding minority samples (over-sampling). However, under-sampling runs the risk of losing important samples. Random over-sampling randomly repeats the minority samples until a balanced distribution of samples is reached. It is the most commonly used of the over-sampling methods because it is simple and easy to implement [29]. However, since the sample is simply repeated, classifiers trained on random over-sampled data can be overfitted.
Chawla et al. suggested the SMOTE algorithm, which avoids the risk of overfitting faced by random over-sampling [7]. Based on the SMOTE algorithm, many classic algorithms were born. Borderline-SMOTE1 changes the random sample selection strategy of SMOTE and focuses on generating minority samples at the decision boundary. This approach resolves the between class imbalance but not the within class imbalance, and also tends to create the problem of missing important samples [15]. Proposed method in this paper addresses the imbalance problem of between and within class, while avoiding the problem of important samples loss that arises with this approach. Borderline-SMOTE2 extends Borderline-SMOTE1 to allow interpolation between a minority sample and one of its majority samples nearest neighbors by setting the interpolation weight to less than 0.5, thus making the generated sample closer to the minority sample. However, this method also have the problem of missing important samples. Cluster-SMOTE combines an over-sampling algorithm with a clustering algorithm, using K-means to cluster minority samples and then applying SMOTE to the clusters [1]. While this approach solves the problem of within-class imbalance, it does not specify how many samples to generate in each cluster or how to determine the optimal number of samples. Our proposed method solves this problem by determining the number of samples per cluster and boundary through a strategy of determining global sample weights and local sample weights. In recent years, Alejot et al. proposed the neural network method in deep learning to improve the learning of imbalanced data. This algorithm solves the classification of unbalanced data under a large number of data [2]. Compared with the method proposed in this paper, the above method has high complexity and poor classification effect on small data sets. Jz A et al. proposed a weighted hybrid ensemble method to classify unbalanced data, in which each sampling method and each classifier are assigned corresponding weights, addressing only the within-class imbalance. The two weight assignment strategies used in the proposed method address inter-class imbalance and intra-class imbalance more precisely than the method [19]. Aurelio et al. used a weighted cross-entropy function to solve the data imbalance problem of the target dataset. Compared with the method proposed in this paper, the algorithm is more expensive to learn and the efficiency of the algorithm needs to be improved [3]. Jerzy et al, proposed A domain-based feature learning method for local data to change the imbalanced data and improve the classification results, but it is blind to the overlapping class boundaries, so it may lead to noise [6]. The method proposed in this paper can effectively avoid the generation of noisy samples and improve the accuracy of the classifier. Asniar et al. proposed a method to improve the SMOTE algorithm by adding a local outlier factor (LOF), while the ABWSMO algorithm combines the SMOTE algorithm with the K-Means clustering algorithm to generate minority class samples, improving the classification accuracy and the generalisation capability of the algorithm [5]. Ssa B et all. propose a generative adversarial network to enhance the quality of generated minority class samples. The method proposed in this paper has higher classifier accuracy than this approach and is applicable to a wider range of datasets [28].
In this paper, we proposed A Novel Adaptive Boundary Weighted and Synthetic Minority Oversampling Algorithm for Imbalanced Datasets (ABWSMO). ABWSMO proposes two innovative weight determination strategies, an adaptive boundary adjustment strategy and an adaptive oversampling sample size determination strategy. And these two strategies are cleverly combined with the improved SMOTE algorithm and K-means algorithm to effectively overcome the shortcomings of traditional oversampling algorithms. The proposed method eliminates the within-class and between-class imbalance, avoids the generation of noise samples, balances the minority and majority samples, and enhances the learning of boundary samples, thus improving the classification performance of the classifier.
Related theory
SMOTE algorithm
The SMOTE algorithm, which avoids the risk of overfitting faced by random oversampling [16]. As shown in Fig. 1, SMOTE generates a new sample by randomly selecting a minority sample and linearly interpolating among its k nearest minority samples. More precisely, SMOTE executes three steps to generate a new minority class sample [21]. It selects a random minority sample Among its k nearest minority samples neighbors, instance Randomly interpolate between the two samples by
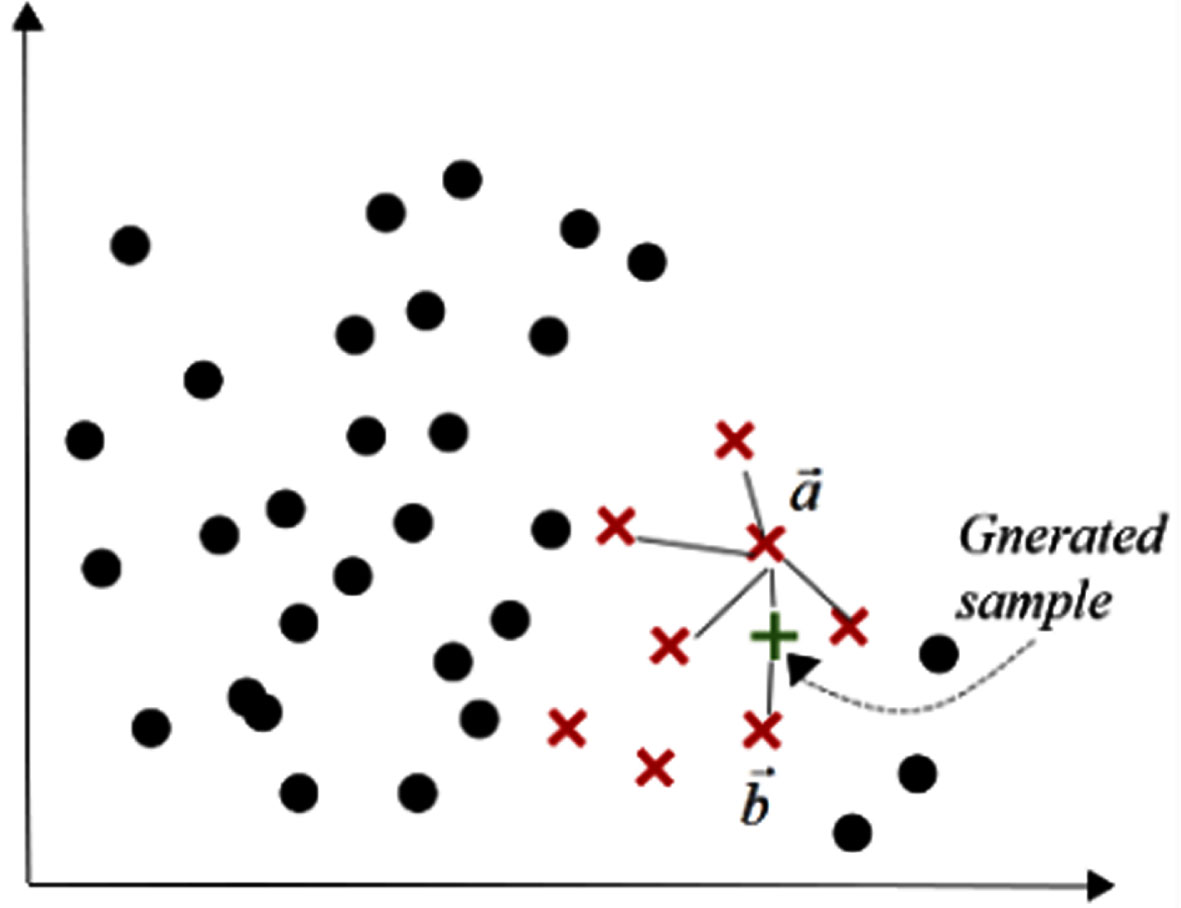
SMOTE randomly selected a minority sample for linear interpolation (k = 4).
However, as illustrated in Fig. 2, the algorithm has some weaknesses. One of them is that it does not address the within-class imbalance [14]. More samples are generated in areas with dense samples, while fewer samples are generated in areas with sparse samples. Another drawback is that SMOTE may further amplify the noise that exists in the data.
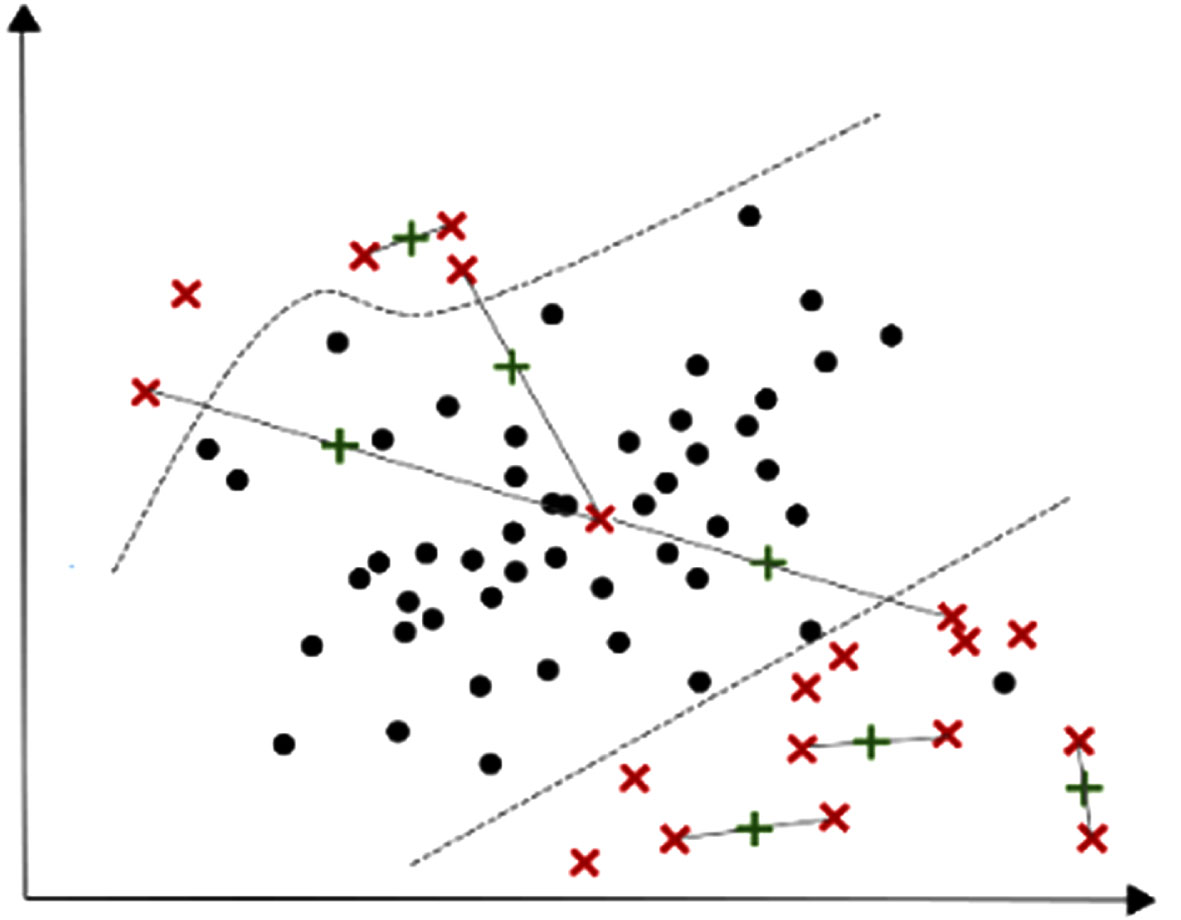
SMOTE may generate minority samples in majority regions (Noise samples). Most non-noise samples are generated in dense minority areas, contributing to within-class imbalance.
There are multiple variations of SMOTE which aim to combat the original algorithm’s weaknesses. Yet, many of these approaches are either very complex or alleviate only a few of SMOTE’s shortcomings. This work proposes combining the K-means clustering algorithm with SMOTE to address some of the drawbacks of previous oversampling algorithms with a simple-to-use technique [10].
K-means is a very important clustering algorithm in cluster analysis. The idea of the K-means algorithm is that, for a given sample set, the sample set is divided into K clusters according to the distance between the samples [23]. Let the points in the cluster be as close together as possible, and let the distance between the clusters be as wide as possible. The K-means can be summarized as: For each training sample {x(1), … x(i) }, x(i) ∈ R
n
. Randomly select cluster centroids points as μ1, … μ
k
, μ
i
∈ R
n
. Assigning each sample i to the nearby cluster centroids. Formula is as follows:
For each cluster j, use Equation (2) to recalculate the centroid of the class.
Repeat steps until the centroid position is no longer updated and the algorithm converges [13]. The algorithm iteration process is shown in Fig. 3. All the parameters of K-means are also parameters of the algorithm in this paper, and the most significant one is the number of clusters K.
The iterative process of K-means algorithm.
The proposed method ABWSMO adopts the popular K-means clustering algorithm, combined with SMOTE oversampling technology, and fuses the idea of boundary weighting to rebalance the dataset. It manages to avoid the generation of noise by oversampling only in safe areas [18]. At the same time, the sampling weight of the sample is determined by the number of majority samples in the k nearest neighbors of the minority boundary point. The regions closer to the boundary in minority samples are given higher sampling weights, so that the samples are generated closer to the boundary in preference. The classification performance of the classifier is improved by increasing the learning of the difficult-to-learn samples at the boundary, resolving the imbalance between and within classes.
Adaptive boundary weight adjustment strategy
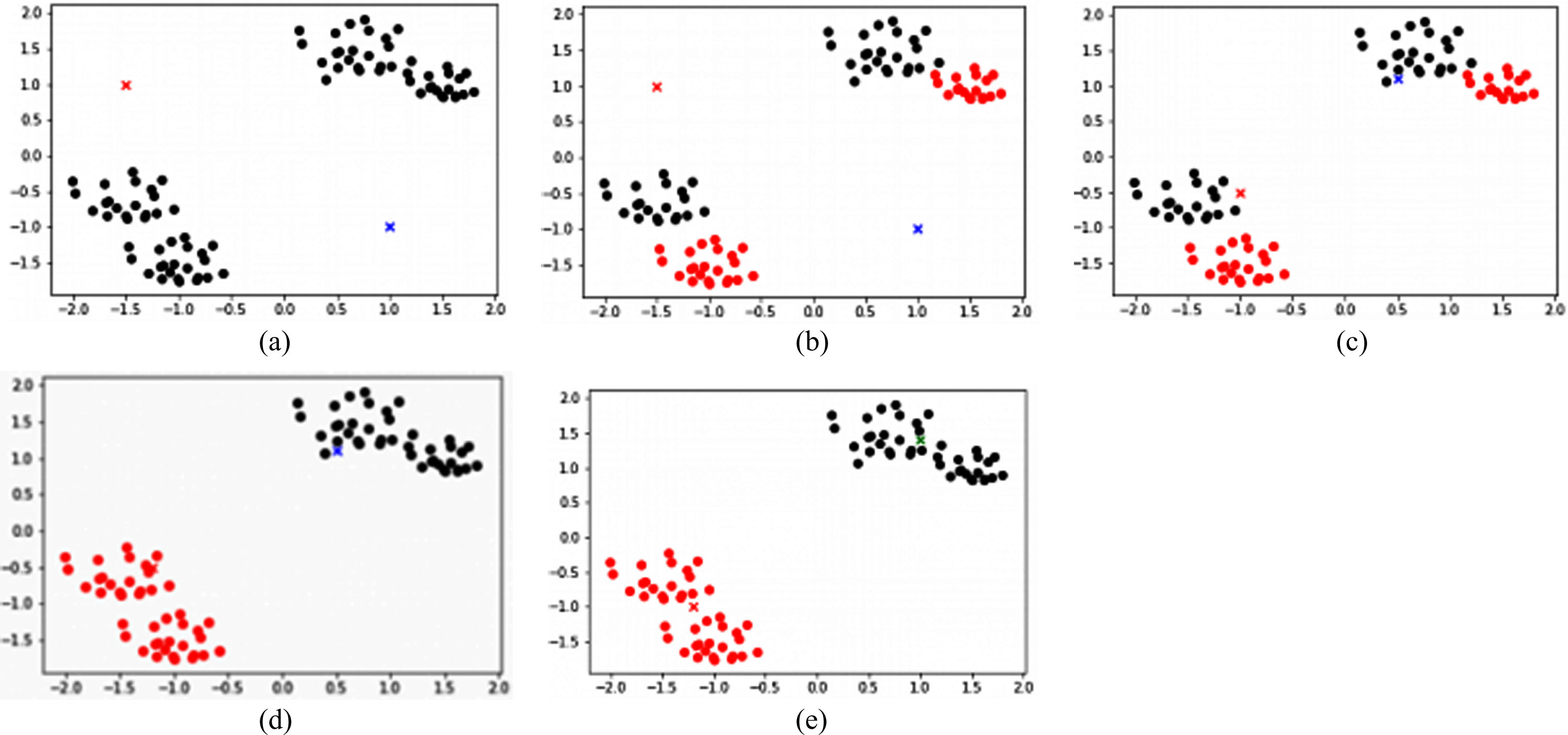
There are various techniques to quantify the importance and learning difficulty of a boundary sample based on the distance between minority and majority samples [9]. First, look for the center of the majority samples. The set of minority samples with the smallest distance within a certain threshold will represent the most informative and important boundary samples. As illustrated in Fig. 4(a), The ‘×’ in the figure represents minority samples, the ‘circle’ represents the majority samples, and the ‘diamond’ represents the center of the majority samples. Calculate the Euclidean distances between minority samples M1, M2, M3, M4, M5 and the center of majority samples. As shown in Fig. 4(b), this method exhibits a critical flaw. If the majority class contains two clusters, each majority class must find its nearest cluster center before the minority sample calculates the distance to the center of the majority class, which increases the computational difficulty and reduces the efficiency of the algorithm. The adaptive boundary weight adjustment strategy of the ABWSMO algorithm does not look for the center of majority samples. The sampling weight is determined by the number of majority samples in the K nearest neighbors of each minority sample, and the value is taken as the local sample sampling weight. As illustrated in Fig. 4(c). The highlighted region surrounded by a dotted circle represents the K nearest neighbors search regions for minority samples M1, M2, M3, M4, M5. Therefore, in the 4 nearest neighbors of M1, M2, M3, M4, M5, accordingly, there are 3, 1, 2, 1, and 0 majority samples. This means that minority sample M1 is more likely to be near the decision boundary. Therefore, more synthetic samples should be generated for M1, assigning higher local boundary sample weights forces the classifier to pay more attention to the difficult-to-learn region of the boundary [11].

(a) A sample that determines the boundary based on Euclidean distance; (b) Shortcomings of the original method; (c) Use K nearest neighbors of each minority samples to calculate the weight.
Local sample weights can be calculated as follows: In the sample of minority, for each minority sample M
i
, its k
i
nearest neighbors are found in the data set according to the Euclidean distance of n-dimensional space, which is defined as:
(δ
i
< k
i
), Where δ
i
is the number of majority samples in the k
i
nearest neighbors. When δ
i
= k
i
, the sample is defined as noise sample. α is the proportionality coefficient, defined as 0.25 [22]. The larger r
i
is, the more likely the sample is to be a boundary sample. Calculate the local sampling weight of each sample, Normalize r
i
according to:
One of the key issues in the oversampling algorithm is how to determine the global sampling weights. In other words, how many samples need to be generated per cluster [17]. In this paper, an adaptive oversampling sample size determination strategy is proposed to oversample only a few clusters with a relatively large proportion of minority samples. This method reduces the effect of noise. In addition, we aim to achieve within-class balance for minority samples. Therefore, the proposed oversampling strategy assigns more generated samples to sparse minority clusters than to dense ones. Whether or not each cluster is oversampled is determined by the proportion of minority and majority samples in the cluster. This can be adjusted by the imbalance rate threshold (or IR), a hyperparameter of ABWSMO which defaults to 1. The imbalance ratio of a cluster is defined as:
A high sampling weight corresponds to minority samples with a low density and generates more samples. The calculation of global sampling weight can be expressed by four sub-calculations: Randomly select cluster centroids points as μ1, … μ
k
, μ
i
∈ R
n
. For each selected cluster, calculate the Euclidean distance matrix between the samples of the minority classes. Calculate the average distance within each cluster, add all the off-diagonal elements of the distance matrix, and divide by the number of off-diagonal elements. To get the density of each cluster, the sample density is defined as:
f is the number of features contained in the sample. Sample sparsity is defined as:
The global sampling weight of each cluster is defined as the sparsity of the cluster divided by the sum of the sparsities of all the clusters.
Therefore, the sum of all global sampling weights is 1. Because of this property, the global sampling weight of the cluster can be multiplied by the total number of samples to be generated, so as to determine the number of global samples to be generated in the cluster. After determining the global and local sampling weights of the samples, SMOTE algorithm is used to over-sample each selected cluster. For each cluster, for each minority sample, execute instruction ∥ samplingweight (p) × n ∥ × r i to generate samples, where n is the total number of samples to be generated.
The method proposed in this work uses the k-means clustering algorithm in combination with SMOTE oversampling. It avoids noise by oversampling only in safe regions. Furthermore, it focuses on between-class imbalances and within-class imbalances. What makes this method unique from related methods is not only its simplicity but also its novel and effective synthetic sample allocation strategy. Sample allocation is based on the density of clusters, producing more samples in sparse minority areas than in dense ones to eliminate within-class imbalance. Finally, overfitting is resisted by generating new samples rather than replicating them.
ABWSMO consists of four steps: marking minority boundary points and assigning local weights; clustering; selecting; and oversampling. The algorithm cleverly incorporates two innovative sample global and local weight determination strategies proposed in sections 3.1 and 3.2. An adaptive boundary weight adjustment strategy is used in the step of marking boundary points and assigning local weights. All majority and minority samples are input into the model, the boundary points are marked, and local sampling weights are assigned to each sample through the adaptive boundary weight adjustment strategy. In the clustering step, K-means clustering is used to cluster the input samples into K clusters.
The selection step selects the clustering for oversampling and retains the clustering with a high sample ratio of minority samples.
An oversampling sample size strategy is applied to assign global sample weights to each cluster, that is, the total number of samples to be generated for each cluster to be oversampled, and allocate more samples to minority clusters with sparse samples. Finally, in the over-sampling step, the SMOTE algorithm is applied to each minority sample in each selected cluster to achieve the target proportion of minority and majority samples. The sampling process of this algorithm is shown in Fig. 5.
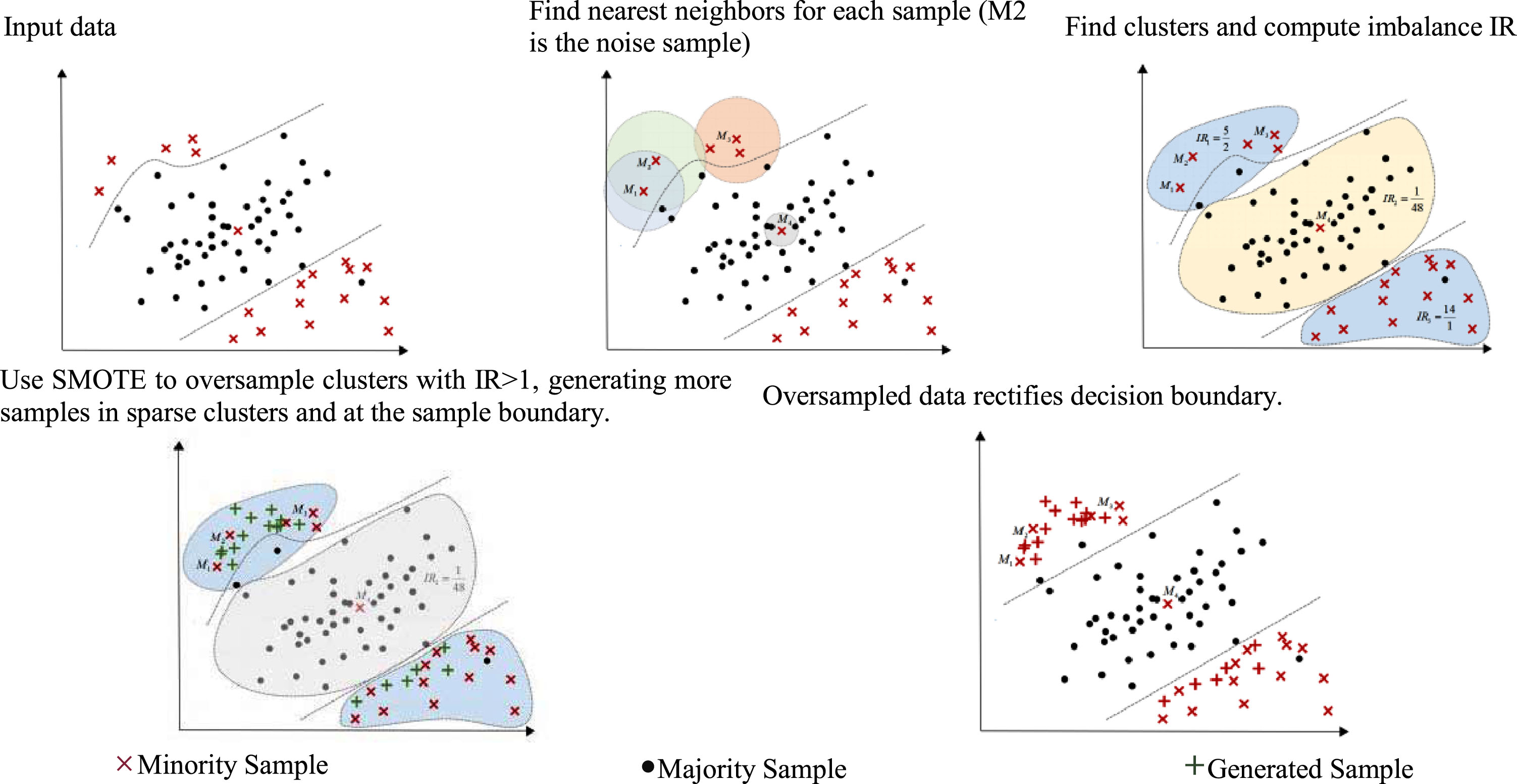
ABWSMO sampling procedure description.
This method is not only simple, but also a new and effective method for synthesizing sample distribution. The sample distribution is based on the clustering density, and more samples are generated in the sparse area of minority samples than in the dense area of minority samples, so as to overcome the within-class imbalance. By assigning a higher local sampling weight to minority class boundary points, the learning intensity of the classifier on boundary samples is increased. In addition, this method clusters without considering the category label so that safe over-sampling areas can be detected. Finally, overfitting is offset by generating minority samples rather than simply copying them.
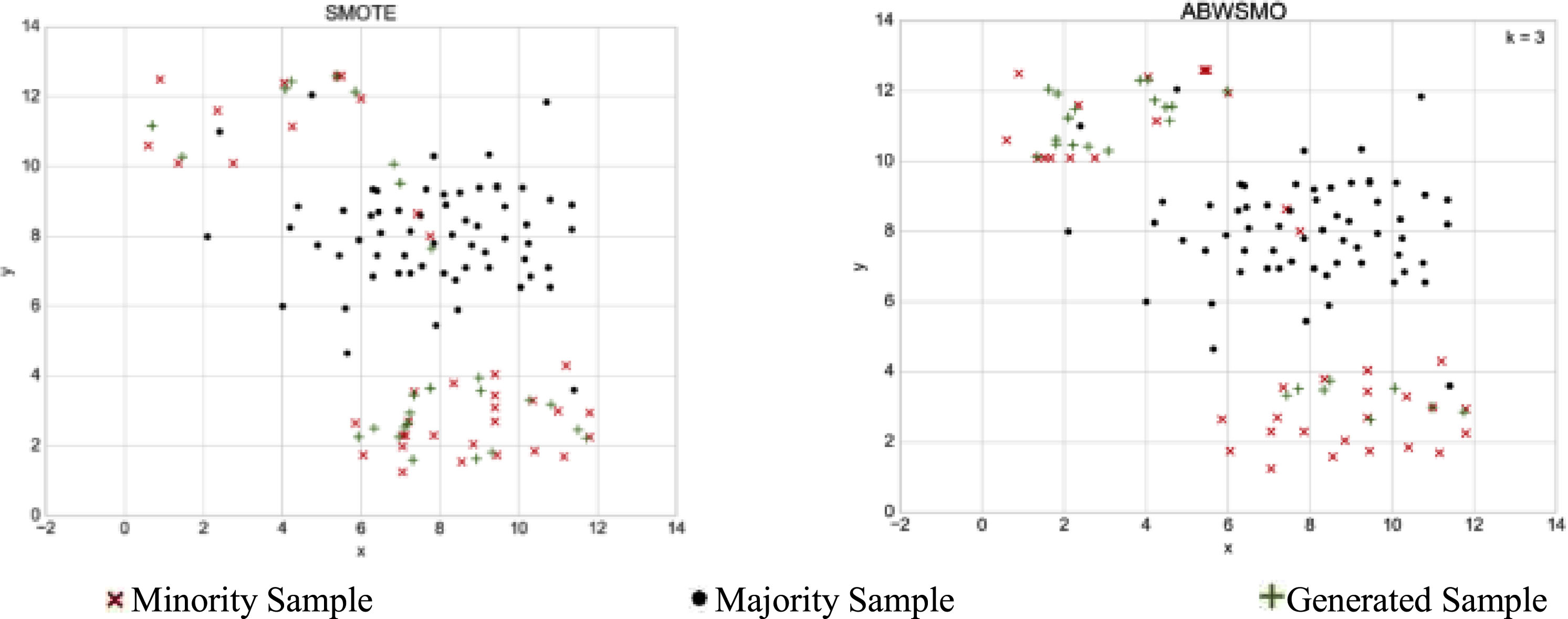
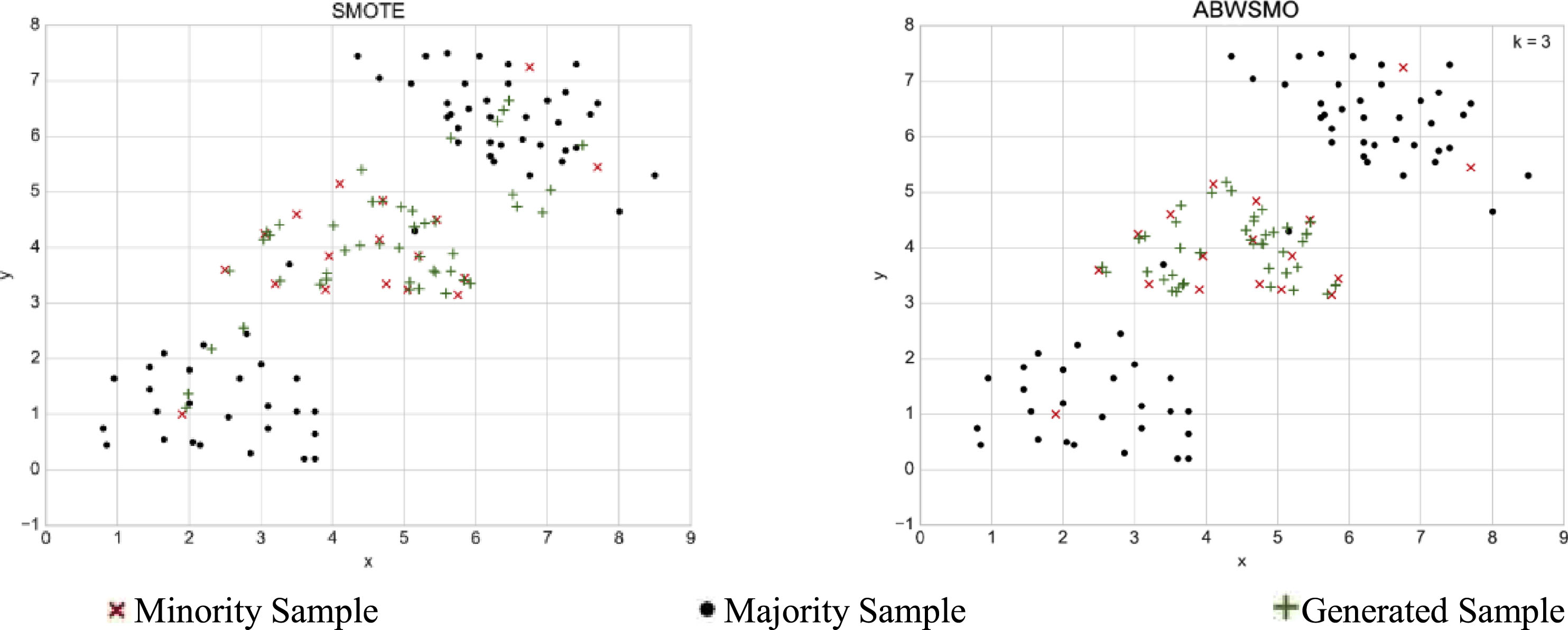
In order to illustrate the effectiveness of the ABWSMO oversampling algorithm, three two-dimensional arrays are used to illustrate. They are created for this work, consist of minority clusters, majority clusters, and noisy clusters. They are referred to as datasets A, B, and C. It can be clearly observed that the application of two innovative local and global sample determination strategies applied to the ABWSMO algorithm effectively avoids noise generation. In contrast to the traditional SMOTE algorithm, the ABWSMO algorithm prioritises the generation of samples near the boundary points. As shown in Figs. 6–8, it is clear that oversampling via the ABWSMO algorithm effectively avoids the generation of noise compared to the traditional oversampling SMOTE algorithm, while generating samples preferentially close to the boundary points. The problem of imbalance within and between classes is solved, while the effect of class overlap on the oversampling algorithm is eliminated.

Samples generated through oversampling dataset A with SMOTE and ABWSO.
Samples generated through oversampling dataset B with SMOTE and ABWSO.
Samples generated through oversampling dataset C with SMOTE and ABWSO.
Dataset description
The performance of ABWSMO is evaluated on 13 datasets from the UCI machine learning repository [4]. These datasets vary in size and class distributions to ensure a thorough assessment of performance. Table 1 summarizes the characteristics of the datasets used in our simulation. To ensure a full evaluation of performance, convert a dataset with two or more classes to a dataset with two classes for a majority class and a minority class. In addition, the Python library scikit-learn was used to generate three variations of the artificial “MADELON” dataset, which poses a difficult binary classification problem.
Imbalance datasets
Imbalance datasets
There are metrics which have been employed or developed specifically to cope with imbalanced data [25]. In this article, the performance measures used to compare the different approaches are: F-measure, G-mean, and Area under Receiving Operator Characteristic Graph (AUC). A confusion matrix (Table 2) can be constructed to illustrate the alignment of predictions with the true distribution. In the confusion matrix, minority instances are referred to as positive (P) and majority instances are referred to as negative (N).
Confusion matrix
Confusion matrix
Precision measures the accuracy of the classifier, which means that a sample that is predicted to be positive is actually positive. Recall measures the completeness of the classifier, that is, the number of samples from minority categories that are correctly classified as positive. Parameter β of F
measure
adjusts the relative importance between Precision and Recall. F
measure
can be calculated by the following formula:
The ultimate goal of any oversampling method is to improve the classification results. In other words, an oversampling algorithm is successful if the oversampled data it produces improves the predictive quality and classification performance of a given classifier. In this paper, the proposed ABWSMO method is evaluated on 13 datasets from the UCI database and compared with the other 5 oversampling methods: Random-OverSampling; SMOTE; Boderline1-SMOTE; Boderline2-SMOTE; Cluster-SMOTE.
In order to determine the mean and standard deviation of the performance measures for the over-sampling methods, 4-fold cross validation was used. Each experiment was repeated 3 times report the average in order to alleviate the randomness effects on the results. The criteria for cross validation are G mean , because it explains all the value indicators in the confusion matrix and provides a more reliable measure for learning from unbalanced data.
In order to evaluate the various oversampling methods, several different classifiers were chosen to ensure that the results obtained could be generalized and not limited by the use of a particular classifier. The choice of classifier was also influenced by the number of hyperparameters: classification algorithms with few or no hyperparameters were preferred. Classification algorithms with few or no hyperparameters are less likely to bias the results due to their specific configuration. With reference to the experience of previous research by experts and scholars, the following classifiers are chosen for this paper. SVM is a common binary classification algorithm that is highly representative for classifying small data sets. For the SVM classifier, the parameter is selected from the values (2-1, 20, 21). For KNN, select the nearest neighbor among the values (4, 5, 6). LR does not need to adjust any parameters [20].
Results discussions
Tables 3–5 shows the results of the mean and standard deviation of our proposed ABWSMO method and the other 5 sampling methods using these 3 classifiers on 16 datasets. The best classification algorithm is shown in bold. ABWSMO obtains the best results according to at least one of the measures in 14 out of the 16 datasets when KNN was used and in 15 out of the 16 datasets when SVM and LR were used. For example, in Table 3, on the dataset “Vehicle”, ABWSMO performs best in all three metrics compared to the other five classification algorithms, reaching 0.937, 0.964, and 0.992. Of the six algorithms tested on the dataset “Pima”, Cluster SMOTE performed best in two evaluation metrics, while ABWSMO performed best in one evaluation metric.
Results for the Sampling methods on the 13 datasets classified using KNN
Results for the Sampling methods on the 13 datasets classified using KNN
Results for the Sampling methods on the 13 datasets classified using SVM
Results for the Sampling methods on the 13 datasets classified using LR
According to DEM’s [8] recommendations for evaluating classifier performance across multiple datasets, the resulting metrics are not compared simply, but rather sorted to produce a ranking. Figure 9 shows the average ranking of each method in terms of F-measure, G-mean, and AUC of all test data sets, with the best performing method ranking at 1 and the worst method ranking at 6. It can be seen that the ranking of ABWSMO is the best under the three evaluation indexes of the three classifiers, while the ranking of other oversampling algorithms is unstable. Combined with the Friedman test [12] and Holm’s method [27] this evaluation method is also used by other authors working on the topic of imbalanced classification.
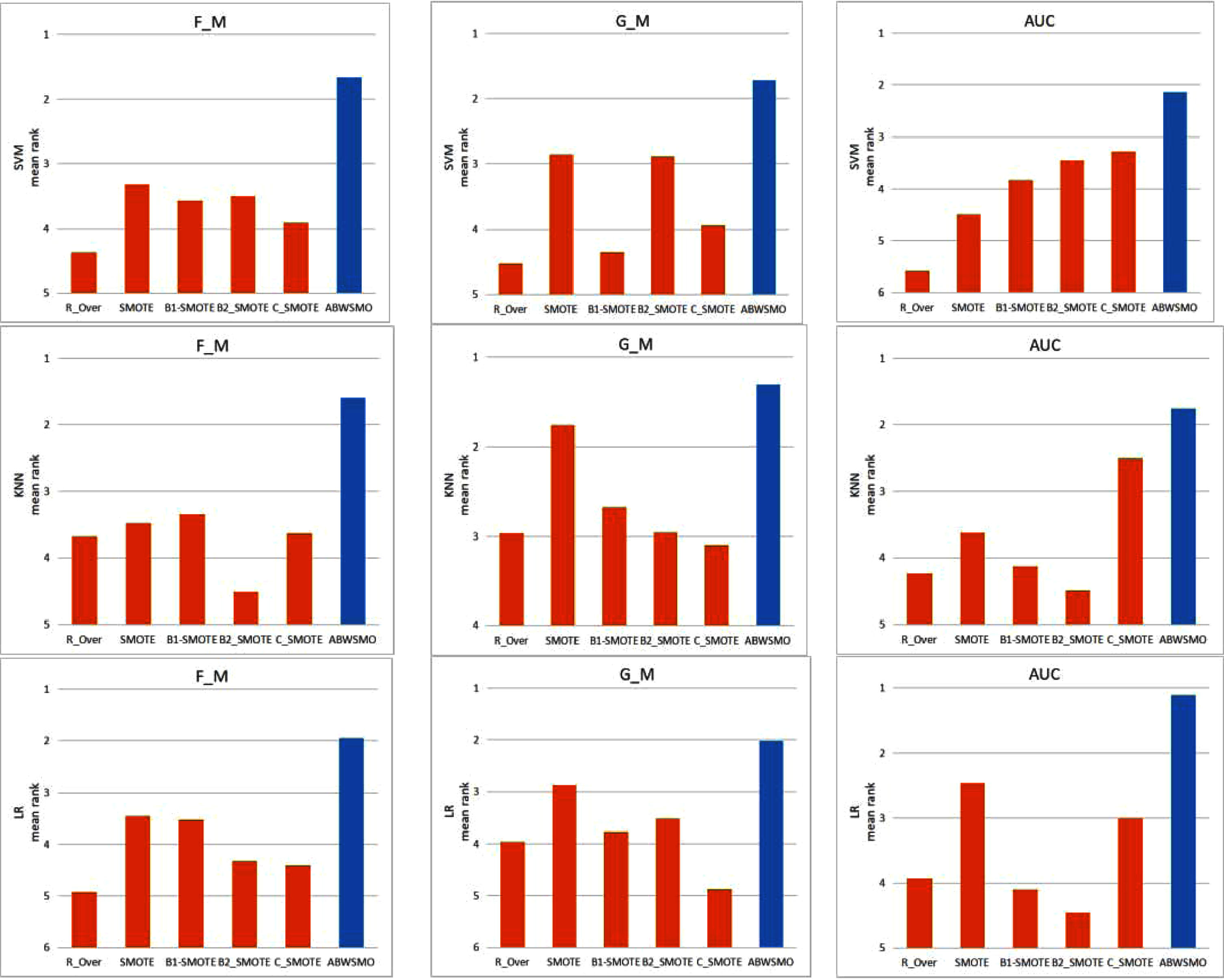
The mean ranking results of the 6 methods on 16 datasets (Best: 1; Worst: 6) Evaluate different classifiers and evaluation indicators.
The Friedman test is a nonparametric equivalent method for repeated measures. The null hypothesis that Friedman tests is whether all classifiers perform similarly in the mean rankings. The Friedman test results are shown in Table 6. From the results, it can be seen that for all three classifiers and for all three measures, there is sufficient evidence at α = 0.05 to reject the null hypothesis, which means that the classifier does not behave similarly.
Fridman test
A post-hoc test is used since all three performance measures reject the null hypothesis. Holm’s test was used where ABWSMO was considered the control method. Holm’s test is the non-parametric analog of the multiple t-test that adjusts α to compensate for multiple comparisons in a step-down procedure. The null hypothesis is whether ABWSMO is superior to other methods as a control algorithm. Table 7 shows the adjusted α and the corresponding p-value for each method. As can be seen from the table, the proposed ABWSMO method outperforms all other methods based on all three measures when SVM is used as the classifier. When KNN, Logistic Regression, and LR were used as the classifier, ABWSMO was significantly better than all other methods in terms of G-mean and F-measure. On the other hand, SMOTE and Cluster SMOTE perform well according to AUC, while B2-SMOTE and B1-SMOTE perform satisfactorily according to F-measure and G-mean. Moreover, it can be observed that methods that perform well in terms of G-mean also perform well in terms of F-measure while they do not perform well in terms of AUC.
Holm’s test
According to the results, compared with the traditional methods, our method is more suitable for data sets with a high unbalance rate, such as GLASS and LEV. In such a dataset, a few samples are highly sparse, and there are multiple sub-clusters of minority samples in the dataset, that is, the degree of imbalance within the class is high. According to our proposed boundary sample weight adjustment strategy and sample number determination strategy, this kind of problem can be well solved.
This paper proposed a new oversampling algorithm, A Novel Adaptive Boundary Weighted and Synthetic Minority Oversampling Algorithm for unbalanced Datasets (ABWSMO). The advantage of ABWSMO is that, according to the distribution of the underlying data, the decision boundary is adaptively transferred to a minority sample whose boundaries are difficult to learn by using the idea of boundary weighting, assigning global weight to sub-clusters and local sampling rights to a single instance. This strengthens the classifier’s learning of the boundary’s important information points. At the same time, the integration of the K-means algorithm avoids the problem of noise easily generated by the traditional oversampling algorithm, and effectively overcomes the imbalance between and within classes. ABWSMO was tested on 16 publicly available datasets with different imbalance ratios and compared with other sampling techniques using different types of classifiers. The evaluation of the experiments conducted shows that the proposed technique effectively reduces noise generation, which is crucial in many applications. The results are statistically robust and apply to various metrics suited for the evaluation of imbalanced data classification. The results show that this method is superior to other sampling methods in most datasets. As the proposed oversampling algorithm can be applied to rebalance any dataset independently of the chosen classifier, its potential impact is substantial. The ABWSWO algorithm is significantly effective on relatively small datasets that are not particularly complex in size, and it has limitations for larger as well as more complex datasets. As future work, we will investigate the application of ABWSMO to multi-class classification problems. In the meantime, future work may consequently focus on applying ABWSWO to various other real-world problems.
Footnotes
Acknowledgment
This work has been supported by National Natural Science Foundation of China (No. 52175379).