
Abstract
In increasingly complex scenes, multi-scale information fusion becomes more and more critical for semantic image segmentation. Various methods are proposed to model multi-scale information, such as local to global, but this is not enough for the scene changes more and more, and the image resolution becomes larger and larger. Cross-Scale Sampling Transformer is proposed in this paper. We first propose that each scale feature is sparsely sampled at one time, and all other features are fused, which is different from all previous methods. Specifically, the Channel Information Augmentation module is first proposed to enhance query feature features, highlight part of the response to sampling points and enhance image features. Next, the Multi-Scale Feature Enhancement module performs a one-time fusion of full-scale features, and each feature can obtain information about other scale features. In addition, the Cross-Scale Fusion module is used for cross-scale fusion of query feature and full-scale feature. Finally, the above three modules constitute our Cross-Scale Sampling Transformer(CSSFormer). We evaluate our CSSFormer on four challenging semantic segmentation benchmarks, including PASCAL Context, ADE20K, COCO-Stuff 10K, and Cityscapes, achieving 59.95%, 55.48%, 50.92%, and 84.72% mIoU, respectively, outperform the state-of-the-art.
Introduction
Image semantic segmentation is a challenging task with many applications in reality, e.g., human-computer interaction [20], augmented reality [1], and driverless technology [18]. It is mainly used for the per-pixel classification of images. Since Long et al. developed Fully Convolutional Networks [42], semantic segmentation has attracted more and more attention.
However, there are usually three difficulties in the per-pixel classification of natural images: (1)There are many categories in the image, leading to confusing similar categories and classification errors. For example, ADE20K [67] has 150 categories, and COCO-Stuff 10k [3] has 182. It requires the global modeling capability of the model. (2) The boundary segmentation is often rough. Because of the high resolution, the boundary part occupies very few pixels and is not easily segmented. It requires the model to be able to deal with the boundary accurately [2, 50]. (3)There will often be large and small objects in the same image. It requires the model to be capable of multi-scale modeling.
In the shallow layer of the network, a feature map usually contains more detailed information. It can distinguish small objects well, but large objects cannot be distinguished well due to the limitation of the receptive field. In the deep layer of the network, it is difficult to distinguish small objects because the feature map is downsampled many times. However, it usually contains rich semantic information and can distinguish large objects well. Therefore, many works [8, 69] are exploring integrating multi-scale features and modeling multi-scale context information. CNN’s excellent ability to extract local information is used to conduct local modeling of a specific scale feature map and fine processing of boundaries.
As shown in Fig. 1(a), the red pixel merges all the information in the small window, but it is often limited by the receptive field and fails to solve problems 1 and 3. DeepLab series [5, 8] use dilated convolution to enlarge the receptive field, valid for question 1. As shown in Fig. 1(b), the red pixel integrates some of the surrounding pixels and expands the receptive field, thus improving the efficiency of calculation. The emergence of Non-local Networks [51] make global modeling a reality. As shown in Fig. 1(c), the red pixel integrates all the information of the whole feature map. However, it is unfriendly to problem 2 and increases the consumption of computing resources. Currently, many works explore how to fuse multi-scale features and demonstrate that modeling multi-scale context is very beneficial for semantic segmentation. Panoptic feature pyramid networks(Semantic-FPN) [29] is a typical representative, which gradually adopts a top-down pathway to inject strong semantics into the bottom layer. As shown in Fig. 1(d), the red pixel is gradually fused from the features in the previous scale window but is limited by a small receptive field. In this way, it is impossible to transfer the rich details of the shallow layer to the deep features in a bottom-up manner (i.e., Gated fully fusion [32] is a particular case). As for Fig. 1(e), it is an excellent solution to problems 1, 2, and 3 at present. Typical representatives include Feature Pyramid Transformer[63] and Asymmetric non-local neural networks [69]. Red pixel integrates features of multiple scales at one time and has a global receptive field. However, they all sample feature maps of different scales to the same size and lose scale-level information. Their processing of boundary details is rough, significantly increasing the amount of computation.
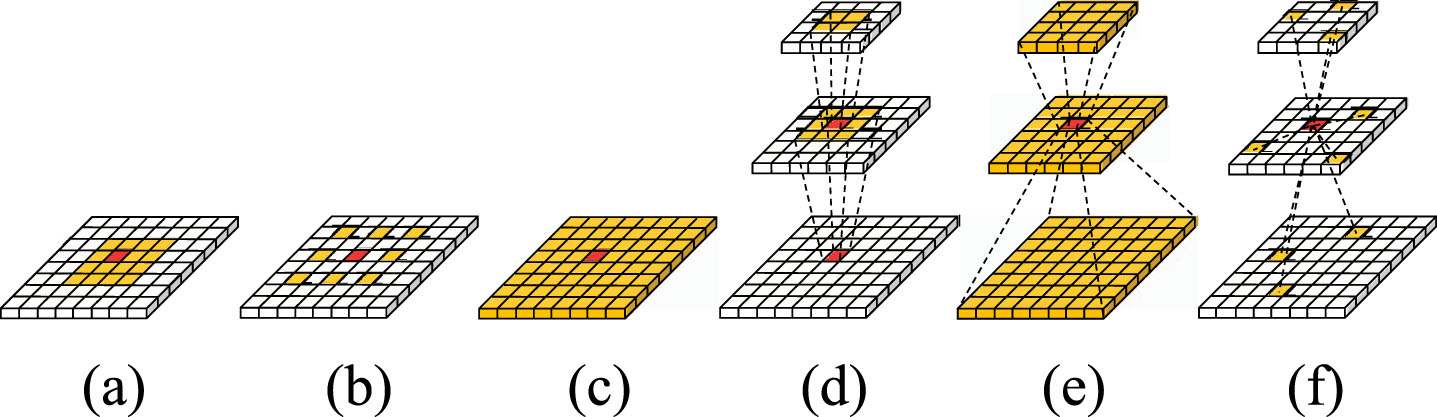
Comparison with the existing methods. The red dot represents the query feature. (a) Single-scale feature fusion only fuses some features around the red dot. (b) Single-scale expansion feature fusion expands the area of local feature fusion. (c) Single-scale global feature fusion fuses global features. (d) Multi-scale local feature fusion fuses multi-scale features layer by layer in only one local area. (e) Multi-scale global feature fusion fuses multi-scale features layer by layer in only one local area. (f) Ours implements a sparse sampling strategy and fuses information of all scales at one time to achieve a global receptive field.
We absorb the previous experience and propose a Cross-Scale Sampling Transformer(CSSFormer) to solve the above problems uniformly. As shown in Fig. 1(f), the red pixel can sample all the scale feature maps at one time to generate global sampling points, and these sampling points can make the red pixel shift to align the boundary. Our approach is computationally friendly and can significantly reduce carbon emissions. Furthermore, we evaluate our CSSFormer on four challenging semantic segmentation benchmarks, including PASCAL Context [44], ADE20K [67], COCO-Stuff 10K [3], and Cityscapes [13], achieving 59.95%, 55.48%, 50.92%, and 84.72% mIoU, respectively, which outperform the SOTA methods. Our main contributions include: We propose a Channel Information Augmentation module to enhance query feature features, highlight the response with sampling points, and assign weights to different channels. We propose a Multi-Scale Feature Enhancement module for sparse sampling and fusion of full-scale features. We propose a Cross-Scale Fusion module for the cross-scale fusion of query feature and full-scale feature to obtain information of all scales at one time. Based on the above three modules, outperforming the state-of-the-art on four challenging benchmarks, including PASCAL Context [44], ADE20K [67], COCO-Stuff 10K [3], and Cityscapes [13].
This section mainly describes related work from three aspects, including Boundary handling, Multi-scale feature fusion, and Transformer in Semantic Segmentation.
Boundary handling
Much of the previous work focuses on exploring semantic boundaries [40, 60]. These methods are often applied to high-resolution images but are ineffective for context modeling and multi-scale fusion. In the case of many categories, it is easy to lead to classification errors. Seman-flow [31] applies optical flow to semantic segmentation and proposes a module of pixel deviation alignment to calibrate the offset pixels. FaPN [25] uses the spatial position alignment module to calibrate the pixel position deviation caused in the upsampling process. Fekri et al. [17] proposes a method for bark texture classification with high accuracy based on the improved local ternary patterns (ILTP). Unlike the previous work, our work can make the pixels in the edge position combine with the context information and carry out effective spatial displacement to achieve the natural effect of the alignment of the boundary position.
Multi-scale Features Fusion
Feature maps of different scales have different information. Shallow features have more details, while in-depth feature semantic information is richer. The advantage of multi-scale feature fusion is that features can fuse information of different scales, enrich semantic features and detail features, and effectively distinguish objects of different sizes in an image. In object detection, Feature Pyramid Networks(FPN) [38] firstly propose a multi-scale fusion strategy to fuse multi-scale features gradually. Semantic-FPN [29] and SETR-MLA [66] extend FPN and adopt top-down fusion mode to fuse multi-scale features. Based on this top-down fusion, ZigZagNet [35] propose top-down and bottom-up propagations to aggregate multi-scale features. Differently, DeepLab series [5, 8] introduces the dilated convolution, which fuses multi-scale features via concatenation at the channel dimension. Zhao et al. [65] introduces the Pyramid Pooling Module for context modeling. Zhu et al. [69] uses a non-local approach to fuse features from two different scales. Lin et al. [36, 37] uses a sparse sampling strategy to fuse multi-scale features. Zhang et al. [63] proposes a Feature Pyramid Transformer for multi-scale feature fusion, which adopts the feature map of all scales to the same scale. Grounding Transformer is used to carry out the fusion of features, abandoning the traditional top-down and bottom-up pathway. Different from the previous methods, we explore how to select the features of all scales at one time for global modeling based on retaining scale-level information (i.e., fusion without sampling to the same size), which is computationally friendly.
Transformer in Semantic Segmentation
Encouraged by Transformer’s great success in the field of natural language processing, Transformer has also made great strides in the field of image recognition. Vision Transformer(ViT) [16] is the first model to apply Transformer to image classification and achieve state-of-the-art. Swin Transformer [41] uses a pyramid structure, proposing a shifted window-based self-attention and performing well in both classified and downstream tasks. Recently, Transformer has received more and more attention on semantic segmentation [11, 66]. Since Transformer naturally has a global receptive field, this is friendly to segmentation tasks. Zheng [66] is the first semantic segmentation model using ViT as the backbone, which uses a Transformer-based encoder and CNN-based decoder. Ranftl et al. [45] also use ViT as the backbone and uses the convolutional progressive fusion feature to get full-resolution predictions. Many works are beginning to apply Transformer to decoder architecture. Xie et al. [57] uses top features extracted from the encoder. K types of learnable Token Embedded are randomly generated for transparent object segmentation. Nevertheless, Transformer is less suited to semantic segmentation when sequences are long. Therefore, SegFormer [58] uses the Transformer-based encoder to extract features and the lightweight MLP-decoder to predict pixel by pixel. FTN [53] and Pale Transformer [54] use grouping strategies to fuse context features. The Transformer is not friendly to sequence length, so Segmenter [48] uses features from the top extracted from the encoder and generates k classes of learnable tokens embedded in the Transformer for segmentation. Cheng et al. [11] build a unified framework for instance and semantic segmentation by introducing mask predictions. Although Transformer has the feature of global modeling, it is limited by the input of large resolution images(i.e., self-attention). So, we use a sparse sampling strategy to sample from multi-scale features with sampling points far smaller than feature-sequence, and then cross-attention is used to conduct cross-scale global modeling.
Method
We first describe our framework, Cross-Scale Sampling Transformer (CSSFormer). We present the Channel Information Augmentation module(CIA), which assigns different weights to different channels according to their importance to motivate importance features and assigns a global receptive field to each channel. Then, we present the Multi-Scale Feature Enhancement module (MSFE), which combines multi-scale features to generate offsets to align each sample point on each scale, and uses a Transformer to fuse multi-scale information. Finally, we introduce the Cross-Scale Fusion module (CSF), which differs from the MSFE module in that it can fuse all scales of information for each query feature at once.
Framework
The overall framework of our CSSFormer is shown in Fig. 2, which consists of a Channel Information Augmentation module(CIA), Multi-Scale Feature Enhancement module (MSFE), and Cross-Scale Fusion module (CSF). Recently, Swin Transformer’s [41] powerful modeling capabilities in downstream tasks are impressive, so we chose it as the backbone of our method. Given an input image
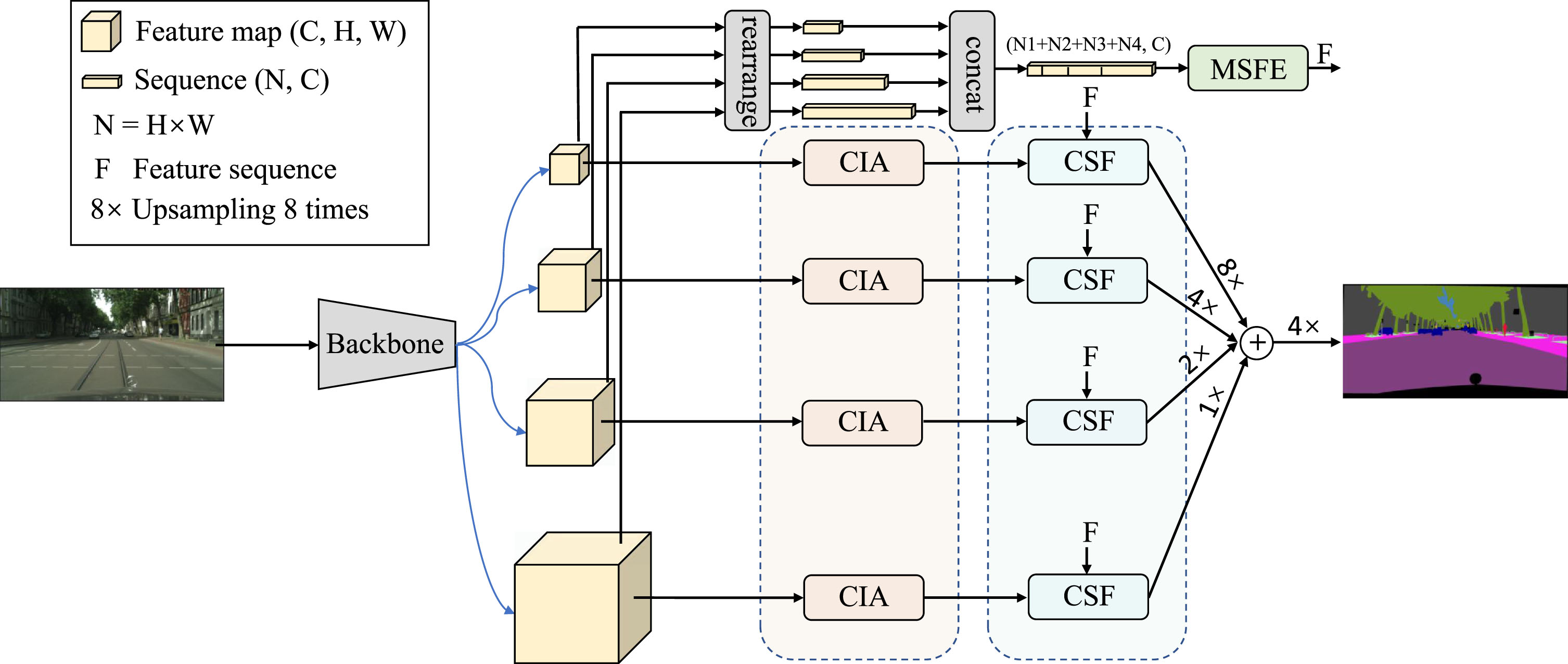
Overall architecture of our Cross-Scale Sampling Transformer(CSSFormer). "CIA," "MSFE," and "CSF" indicate Channel Information Augmentation module, Multi-Scale Feature Enhancement module, and Cross-Scale Fusion module, respectively.
In order to facilitate the subsequent recalibration of query feature sampling points, details of query features are required to be highlighted. We hope to adaptively adjust the importance degree of each channel relative to the global context features so that the calibration can be carried out dynamically with the sampling points. We find that the richer the acceptance field of the feature map is, the more conducive it is to the expansion and contraction of channel weights and the stronger the responsiveness of sampling points. To this end, we design a Channel Information Augmentation module to re-model the query feature.
The data flow diagram of the entire Channel Information Augmentation module is shown in Fig. 3. Specifically, We use adaptive averaging pooling to obtain feature maps of four different sizes for each scale feature
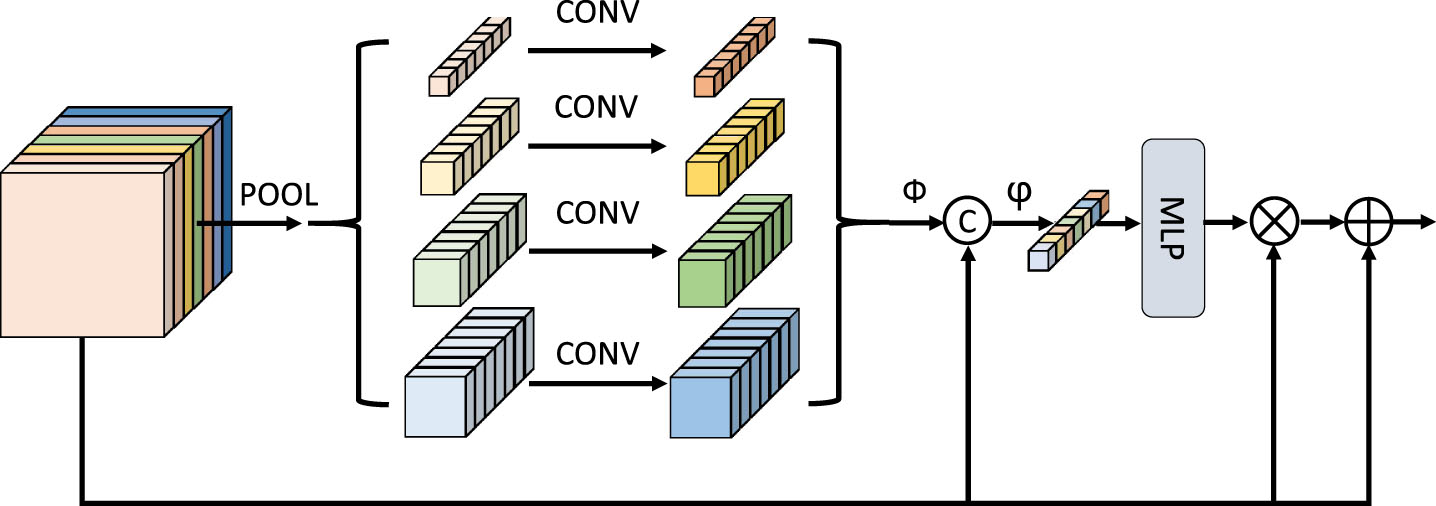
In addition, 1×1 convolution is used to align the number of channels and features with different receptive fields are obtained, and upsampling is performed to the size of the query feature for fusion.
For significance feature
Next, for global feature vector α i , we use an MLP module (i.e. two 1 × 1 conv layers followed by a sigmoid activation function, the input and output dimensions of the two 1 × 1 conv layers change as C->C/2 and C/2 ->C) to predict the importance of each channel. This process is formulated as follows:
To get the importance of each channel on the feature map, we also need to dot and
It is worth mentioning that our Channel Information Augmentation module was inspired by SENet [24] and PSPNet [65]. The difference is that we hope to more effectively scale the channel weights by enhancing the receptive field of the feature map to correspond to the sampling point and feel the farther area and residual connections are used to prevent the channel information from being overly squeezed and excited. In this way, local details will be highlighted more after the CIA Module is used. The query feature will be re-modeled with only a little computation, conducive to the subsequent multi-scale information fusion and adjustment of edge detail features.
We find that simply superimposing multi-scale information is not friendly to the query feature of each scale, and it cannot effectively obtain information gained from it. Therefore, the MSFE module (as shown in Fig. 4) is proposed to enhance multi-scale information, mainly through the interaction of multi-scale features, fine-tuning the spatial position of the pixel in the spatial domain, and one-time fusion of multi-scale information. We find that the one-time integration of all information scales would produce a considerable amount of computation and cause a significant GPU memory overhead, resulting in difficult training. Inspired by Deformable detr [68], we adopt a sparse sampling strategy to solve this problem(as shown in Fig. 5).
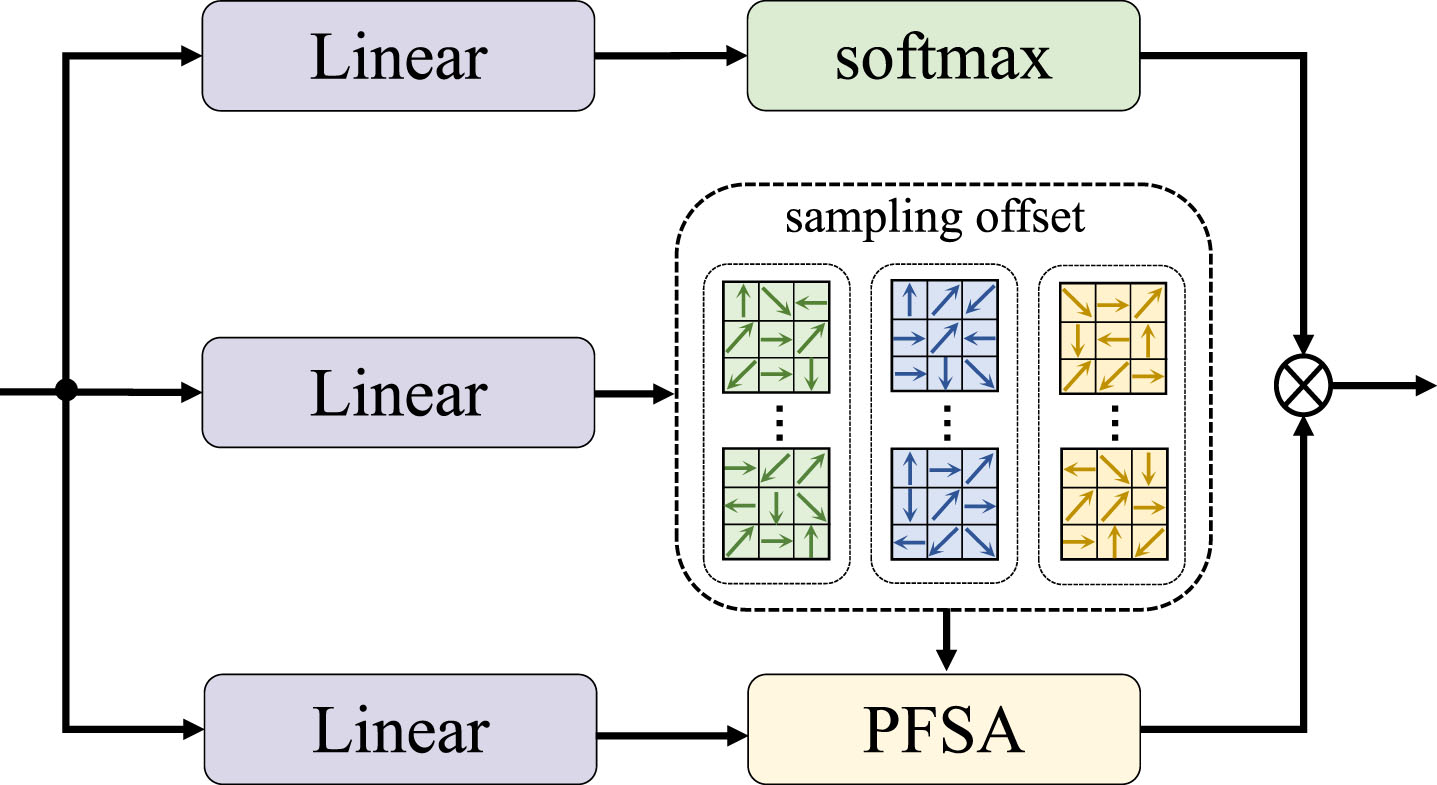
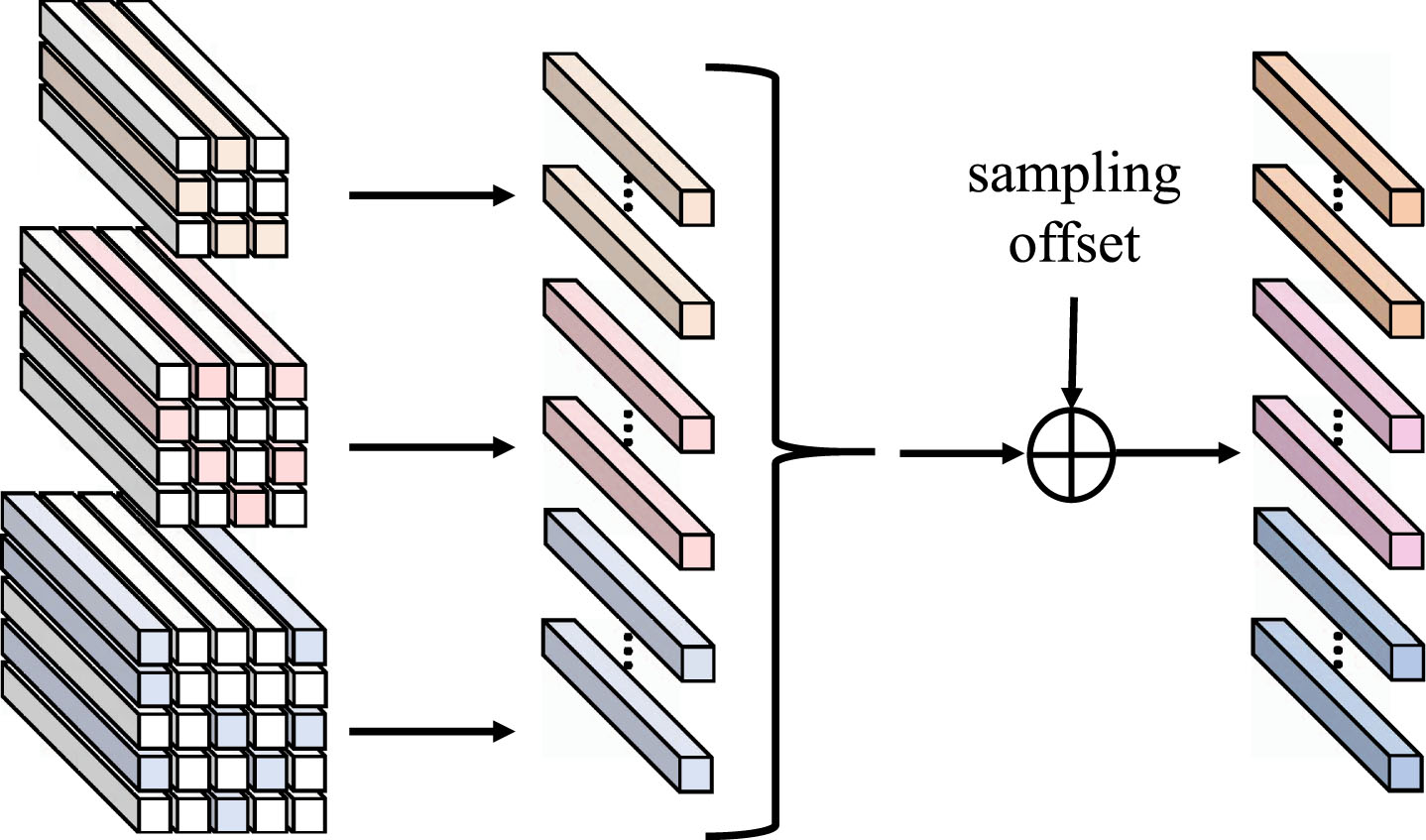
Specifically, we flatten the multi-scale features
The importance of effective modeling of multi-scale information has been demonstrated in [8, 69]. As shown in Fig. 1, we hope to avoid the position offset caused by upsampling in the top-down fusion process [29, 45]. And to be able to merge the full-scale features obtained from the MSFE module at one time. As shown in Fig. 7, we propose our CSF module, which can calibrate the spatial position of pixels and obtain the full-scale information under the action of multi-scale information. For each scale feature, we carry out Multi-Head Self-Attention on


Visual analysis.
A multi-task loss function of AUX and CE is used to optimize the model parameters jointly. In particular, the loss function of AUX is defined as:
Here, we use Swin Transformer as the backbone and use
Here,
Finally, we formulate the multi-task loss function
We first introduce the datasets and implementation details. Then, we compare our method with the recent state-of-the-arts on four challenging semantic segmentation benchmarks, Finally, extensive ablation studies are conducted to evaluate the effectiveness of our approach.
Datasets
Implementation details
Because Vision Transformer has been prominent in the visual field recently, and the community is gradually using Transformer to replace CNN as the backbone. Since Swin Transformer [41] is a pyramid structure with low computation overhead, we choose it as our backbone. The channel C of features
Comparisons with the State-of-the-art Methods
State-of-the-art comparison on the ADE20K dataset. SS: Single-scale inference. MS: Multi-scale inference. † means the resolution of the image is 640 × 640, otherwise 512 × 512.
State-of-the-art comparison on the ADE20K dataset. SS: Single-scale inference. MS: Multi-scale inference. † means the resolution of the image is 640 × 640, otherwise 512 × 512.
Comparison with the state-of-the-art approaches on the PASCAL Context dataset. MS: Multi-scale inference.
Comparison with the state-of-the-art approaches on the COCO-Stuff 10K dataset. MS: Multi-scale inference.
Comparison with the state-of-the-art methods on the Cityscapes validation set. “SS” and “MS” indicate single-scale inference and multi-scale inference, respectively. “†” means the input resolution is 1024 × 1024, otherwise 768 × 768.
Comparisons of different decoders
To remove each method to use different backbone this influence factor, only compare decoder method. We use mmsegmentation as the framework, the same training strategy, and Swin transformer [41] as the backbone of the PASCAL Context dataset to fairly compare various recently popular methods. The results are shown in Table 7. We can see that with Swin-Tiny as the backbone, our CSSFormer is +2.30%mIoU higher than the best of the other methods in the single scale test (50.61 vs. 48.31). When using Swin-Small, Base, and Large as the backbone, CSSFormer is +1.86%, +1.68%, +1.90%mIoU higher than the best of the other methods, respectively (53.78 vs. 51.92, 54.48 vs. 52.80, 58.87 vs. 56.97).
Combinations of different decoders on PASCAL Context validation dataset. We implement all the methods in the table, and all models are trained on PASCAL Context dataset with 80K iterations and batch size 16, and crop size is 480×480. All methods are evaluated using mean IoU (%), single scale test protocol. We’re only testing FLOPs and Params for the Decoder, removing the encoder. We use Swin as the backbone, T-S-B-L represent Tiny-Small-Base-Large models respectively. {2, 2, 6, 2} represents the number of layers of each stage, and
is the number of channels in each stage, the others are similar.
Combinations of different decoders on PASCAL Context validation dataset. We implement all the methods in the table, and all models are trained on PASCAL Context dataset with 80K iterations and batch size 16, and crop size is 480×480. All methods are evaluated using mean IoU (%), single scale test protocol. We’re only testing FLOPs and Params for the Decoder, removing the encoder. We use Swin as the backbone, T-S-B-L represent Tiny-Small-Base-Large models respectively. {2, 2, 6, 2} represents the number of layers of each stage, and
In Table 5, we first evaluate the performance of each module in CSSFormer on the Pascal Context dataset. All ablation experiments are performed at a crop size of (480 × 480). Our CSSFormer with the CIA module and MSFE-CSF module is +3.86%mIoU higher than baseline in single scale test. The amount of computation increases by 42.3 GFLOPs. Our CIA module is +0.91%mIoU higher than baseline. The amount of computation increases by only 2.4 GFLOPs. Our MSFE-CSF module is +2.97%mIoU higher than baseline. The amount of computation increases by only 39.9 GFLOPs.
Ablation study on PASCAL Context testing set. The input size is 480 × 480.
Ablation study on PASCAL Context testing set. The input size is 480 × 480.
We conduct an ablation study on Pascal Context on how many sampling points are used, as shown in Table 6. We can see that performance increases with sampling points and then decreases. The number of sampling points varies from dataset to dataset. However, we use the parameter sampling points=16 on four datasets for convenience.
Compare with different sampling points with Swin-Tiny on PASCAL Context testing set.
Compare with different sampling points with Swin-Tiny on PASCAL Context testing set.
We briefly visualize several of the most popular models, and we can see that our model still has some advantages.
Conclusion
Cross-Scale Sampling Transformer is proposed in this paper. We first propose that each scale feature is sparsely sampled at one time, and all other features are fused, which is different from all previous methods. Specifically, the Channel Information Augmentation module is first proposed to enhance query feature features, highlight part of the response to sampling points and enhance image features. Next, the Multi-Scale Feature Enhancement module performs a one-time fusion of full-scale features, and each feature can obtain information about other scale features. In addition, the Cross-Scale Fusion module is used for cross-scale fusion of query features and full-scale features. Finally, the above three modules constitute our Cross-Scale Sampling Transformer(CSSFormer). A large number of experiments show the effectiveness of our method.
Footnotes
Acknowledgments
The study is partially supported by the National Natural Science Foundation of China under Grant (U2003208) and Key R & D Project of Xinjiang Uygur Autonomous Region(2021B01002).