
Abstract
Generating natural language description for visual content is a technique for describing the content available in the image(s). It requires knowledge of both the domains of computer vision and natural language processing. For this, various models with different approaches are suggested. One of them is encoder-decoder-based description generation. Existing papers used only objects for descriptions, but the relationship between them is equally essential, requiring context information. Which required techniques like Long Short-Term Memory (LSTM). This paper proposes an encoder-decoder-based methodology to generate human-like textual descriptions. Dense-LSTM is presented for better description as a decoder with a modified VGG19 encoder to capture information to describe the scene. Standard datasets Flickr8K and Flickr30k are used for testing and training purposes. BLEU (Bilingual Evaluation Understudy) score is used to evaluate the generated text. For the proposed model, a GUI (Graphical User Interface) is developed, which produces the audio description of the output received and provides an interface for searching the related visual content and query-based search.
Keywords
Introduction
Overview
In daily life, there is a lot of visual content through which we humans go, and as a human, it is a convenient task for us to interpret their meaning and usage. However, detailed descriptions are required for machines to understand the visual content.
Generating textual descriptions to explain the context of visual content is a well-known area of artificial intelligence (AI). Identifying the scene type and objects in it that understand an image and its content requires both syntactic and semantic understanding of visual content as well as language[1, 8].
Textual description for visual content has a wide range of applications. These applications drastically change or improve the way of living when combined with IoT devices. IoTs [2] are the objects or devices combined with either of these, like sensors, processing devices and other technologies to connect or exchange data. The proposed model can be used with any IoT-enabled technology, like embedded systems, wireless sensor networks, or cloud computing, depending on the required task.
In the proposed model, an encoder-decoder-based technique is used. Two neural networks are combined for a suitable description of the given visual content. The model works in two parts; one handles the visual content, and the other deals with the textual part. CNN is used as an encoder to extract features for the given visual content, and a vector is created for processing. VGG19 is an encoder with slight modifications to get the desired dimensions. A novel Dense-LSTM is proposed as a decoder for the textual part. The existing feature extraction model took more time during training and had less promising results than the proposed model.
In [3], descriptions are generated with tolerable efficiency and ResNet50 CNN is used for feature extraction. ResNet50 was among the best performers, but they suffered from the vanishing gradient problem, which is sorted here using VGG19. VGG 19 shows comparatively better performance when time and space are considered during the training process.
The image is first preprocessed to convert into a 224 × 224 × 3 dimension to pass through the encoder. Then, following the encoder-decoder translation method, the features are passed through the Dense-LSTM network. Paper [4] lacked on text generation part, for which the LSTM network is used for enhancement. Using LSTM, better descriptions are generated as it can handle long-time information. In [43], Dense-LSTM is used to solve degradation problems and efficiently use the information in speech-emotion recognition. Therefore to upgrade the generated text quality, Dense-LSTM is used instead of simple LSTM or RNN in the proposed work. Here, beam-search is used to opt for the better description generated by the decoder.
The basic concept is taken from the paper[9], which addresses that the textual descriptions could be improved using VGG19 as an encoder and LSTM at the decoder part of the model. In [9] author showed promising outcomes on non-standard data. The proposed model further extends the same concept with changes using Dense-LSTM with a modified VGG19 model on a standard data set. The descriptions are preprocessed separately in the training set to develop a dictionary. For training purposes, the Flickr8k and Flickr30k datasets are used. A significant portion of such models is task-related to classifying images, which includes considerable complications in execution. More than identifying the content of visuals and objects is required for such a task. Identifying their relationship is equally important to generate a suitable human-like textual description. The main objective is efficiently producing textual descriptions in human-like language to get the semantics in the visual content for which Dense-LSTM is used.
Motivation
Many applications like image indexing, image editing and virtual assistance in computers and phones are where text generation for visual content is used. While generating text for visual content, existing approaches use objects in an image, whereas the relation between them is equally important. Therefore, a novel Dense-LSTM is proposed to get the semantics in the visual content. When an image is posted on social media, the suggested tool helps predict the text for the content and offers emoticons according to the sentiment in the description. This tool can also generate descriptions in audio form so that it can help visually impaired/incapable people in their daily activities. It can help them understand the surroundings by taking video frames as input and generating descriptions of that frame when used with an IoT-enabled device, which can be directly transferable in audio form to that person. Children are more attentive to the visuals and audio than the text. It helps in child education by providing the facility with an audio and textual description of the visual content to grasp more attention. Search engines like Google are also used for such purposes. Still, Google API is combined with the proposed model to give a more relevant description of the visual content, which is not available in a simple search. In the same way, when the proposed model is combined with an IoT-enabled device, the applications will get broader aspects and areas.
Related work
Much work has been done, and active research is going on in this area of textual description for visual content. There is still much scope for enhancement and addition, like using the same concept for IoT-enable visual content. In 1999, Ashton K[10] first proposed the Internet of Things". Elias et al.[11], and Kapoor A et al.[12] used deep learning and image processing with IoT technology in their work for wildlife and plant growth evaluation, respectively. Similarly, various application areas are still left untouched.
Conversely, various models are used to create visual content descriptions. Here, the encoder-decoder-based approach is considered. In this approach, CNN, a Convolutional Neural Network, is taken as encoder and RNN, that is, Recurrent Neural Network as decoder, are combined to address the textual description generation. As RNN lacks in storing information for longer, alternatives like LSTM and GRU can be used. LSTM is a particular type of RNN with feedback connections. GRU (Gated Recurrent Unit), like LSTM with forgetting gate, and TNN (Temporal Neural Network), which works on low-level and high-level features, are existing alternatives to RNN. A good number of models like VGG, ResNet, Xception and AlexNet with their variations are available for encoding. Similarly, a good number of standard datasets like Flickr8K, which has 8k images; Flickr30K, with 30k pictures; MSCOCO, with 80 object categories; and SUN dataset, are available for description generation tasks.
Many researchers support the encoder-decoder model using CNN with LSTM. The proposed model follows the same approach. Two widely used models from the Visual Geometry Group(VGG) OxfordNet with 16-layer (VGG16) and 19-layer (VGG19) are used for feature extraction and are compared by Aung, San Pa, Win nwe, tin[9]. As per their results, in terms of accuracy, VGG19 performs better. However, as it has more layers than VGG16, it took more memory space. In [3], Chu, Yan Yue et al. show that ResNet50 and LSTM with a soft attention layer give considerably good results. Although, the problem faced in ResNet was Vanishing Gradient.
LSTM is getting more attention among computer vision enthusiasts in the image-to-text generation field. In the LSTM model, some contextual cell states are there. Based on the requirement, these states behave like long-term or short-term memory cells. The possibility of better description generation using LSTM than RNN in understandable natural language is addressed by A Karpathy[14] in their research. They used an image dataset with their descriptions in natural language and checked for various correspondence of words with their description and information related to visual content. In this approach, the CNN model is used for feature extraction, and these features are used as raw data of an image. Words connectivity is done using contextual cells in LSTM to generate the description. Beam-search is used to select the most suitable description. An integrated model (CNN-LSTM) is developed in the paper[5] to automatically view an image with appropriate description generation in English.
As per the previous work shown in Table 1, most of the approaches used VGGNet, giving comparatively better results. Considering the same, VGGNet is used on the encoder part of the model with slight modification as per the required dimension for feature extraction.
Related work in the same area
Related work in the same area
This work mainly focuses on the decoder part responsible for description generation. A novel Dense-LSTM is proposed as a decoder that is more suitable for utilizing information efficiently and as a solution to degradation[43]. In [42], the encoder is modified to get better features and description generation in terms of semantics. The proposed work uses the same basic architecture with Dense-LSTM as a decoder to provide a more suitable description of semantics and the implicit relationship between objects with context information. Work in the same problem area is presented in [47] with a different approach. A GUI is developed to use the model. Audio for the resulting textual description of visual content is generated. One can search similar images for a given image and generate text using GUI. Some previous models [46, 48] also used the Dense-LSTM with different architectures in different application areas. In [46], the authors use Wifi signals to recognize the human activity. In [48], action recognition is performed using frames and Bi-directional LSTM. Table 2 provides a detailed comparison of similar approaches regarding the dataset and methodology with evaluation metrics used.
Detailed comparison of similar approaches
An encoder-decoder-based architecture with a novel Dense-LSTM is proposed for generating semantically correct textual descriptions with context information. The LSTM is widely used for semantic extraction [47]. In the proposed work, densely-connected LSTM is used to provide a more accurate description based on semantics. Encoding is done using a modified VGG19 CNN model, and Dense-LSTM is used for decoding. The probability distribution for each word in the vocabulary is considered for each word in the generated description. Then it is given to the decoder to transform them into a final description considered as the final output. The encoder uses one neuron for each word in the output vocabulary and a softmax activation function. VGG 19 is one of the variants of VGGNet. It has nineteen layers, sixteen convolution layers, and three fully connected layers with five MaxPool and one SoftMax layer
The encoder does the task of image encoding to create feature vectors which are further given as input to the model to generate descriptions using Dense-LSTM. The Dense-LSTM is a densely connected network of LSTM, and LSTM is one of the variants of RNN forms [13, 40]. In the proposed architecture of Dense-LSTM (presented in Fig. 1), four layers of LSTM are connected, followed by two dense layers to enhance the resultant text. As the name "Dense" suggests, each layer is connected with every other three layers [53]. At each layer, five descriptions are generated, out of which the best is selected using beam search. Beam search is a popular heuristic search that returns the list of the most related sequences. That best output is further given as input to the subsequent and successive layers, which improves the description semantically. The final generated description is passed to the two dense layers to get the final output. In the encoder part of the proposed model, the last fully-connected layer is omitted to get the required dimensions.
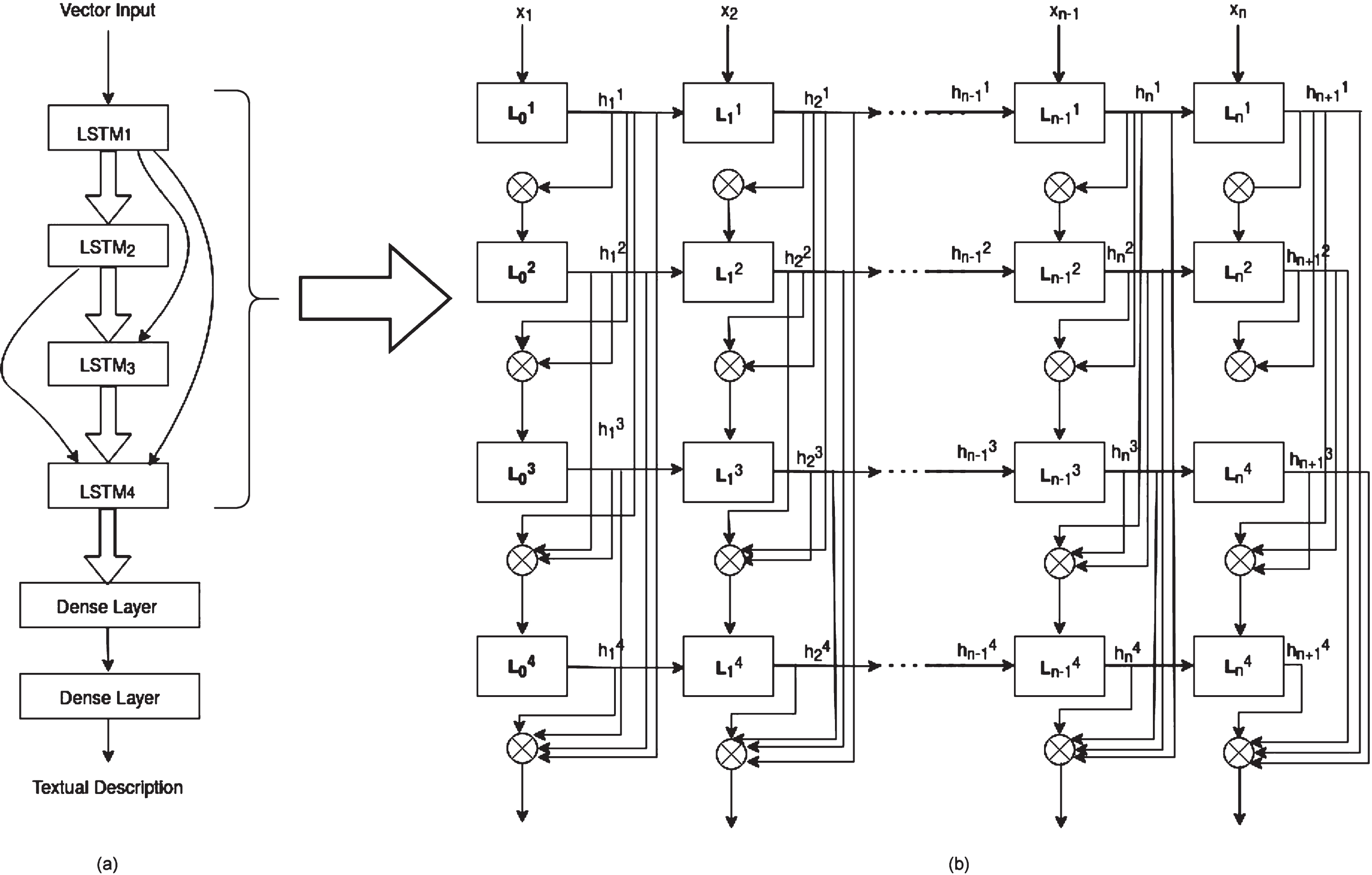
(a) Complete proposed architecture of Dense-LSTM as decoder; (b) Details of densely connected LSTM layers.
In LSTM, the sigmoid gates group controls the reading and writing process. For different inputs, the updation of gates in LSTM takes place as follows:
In the proposed architecture of Dense-LSTM, all gates are updated according to the equations given from 2 to 7. The hidden state of each LSTM unit is passed to the next unit and updated using the output gate and hyperbolic tangent of the memory gate. Then, the output of each unit is given as an input with a different weightage to other units, and the output from the last unit is further passed to the two dense layers to get the desired description.
Initially, visual content is used from the standard dataset for training purposes. Visual content is passed through the encoder to get the features in vector form. A 224 × 224 × 3 image is passed to get output in 4096 × 1 dimensions. The last layer of the CNN model is removed to get the output in the desired shape. Feature vectors are generated in 4096 × 1 size through this process. All these vectors are saved in a separate file for feature extraction of each image during the training, testing, and validation process. Then, description pre-processing is done by eliminating the punctuation, single-letter, and alphanumeric words. With the vocabulary and word embeddings generated in the dataset, the maximum length of the description is obtained. In the case of Flickr8k and Flickr30k, the maximum description length are 34 and 75, respectively. Then word embedding with feature vectors is concatenated and passed through the densely connected LSTMs to get the enhanced description. The block diagram and detailed architecture for the model are shown in Figs. 2 3 respectively.

Block Diagram for Proposed Model.
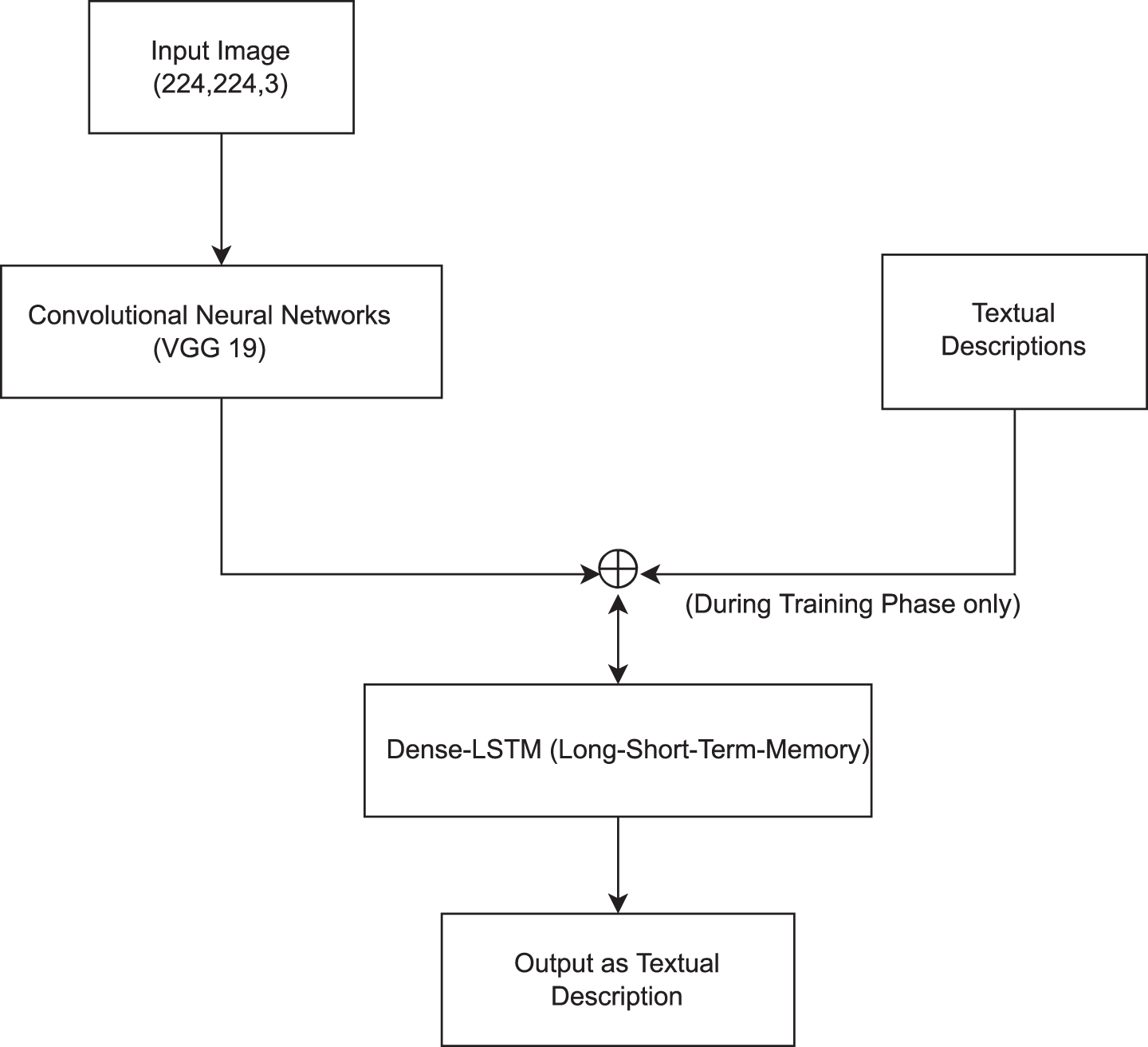
Architecture for Proposed Model.
LSTM is a particular type of RNN with the capability of remembering, forgetting and information updating in long-term dependencies. Hence, the LSTM is preferred here for language modelling. The architecture of the proposed Dense-LSTM is shown in Fig. 1. In the architecture of Dense-LSTM, the used dimension for embedding is 256, and the number of LSTM layers is four with the following two dense layers. The encoder is shown in figure 4, and the detailed architecture with dimension details are given in Fig. 5.
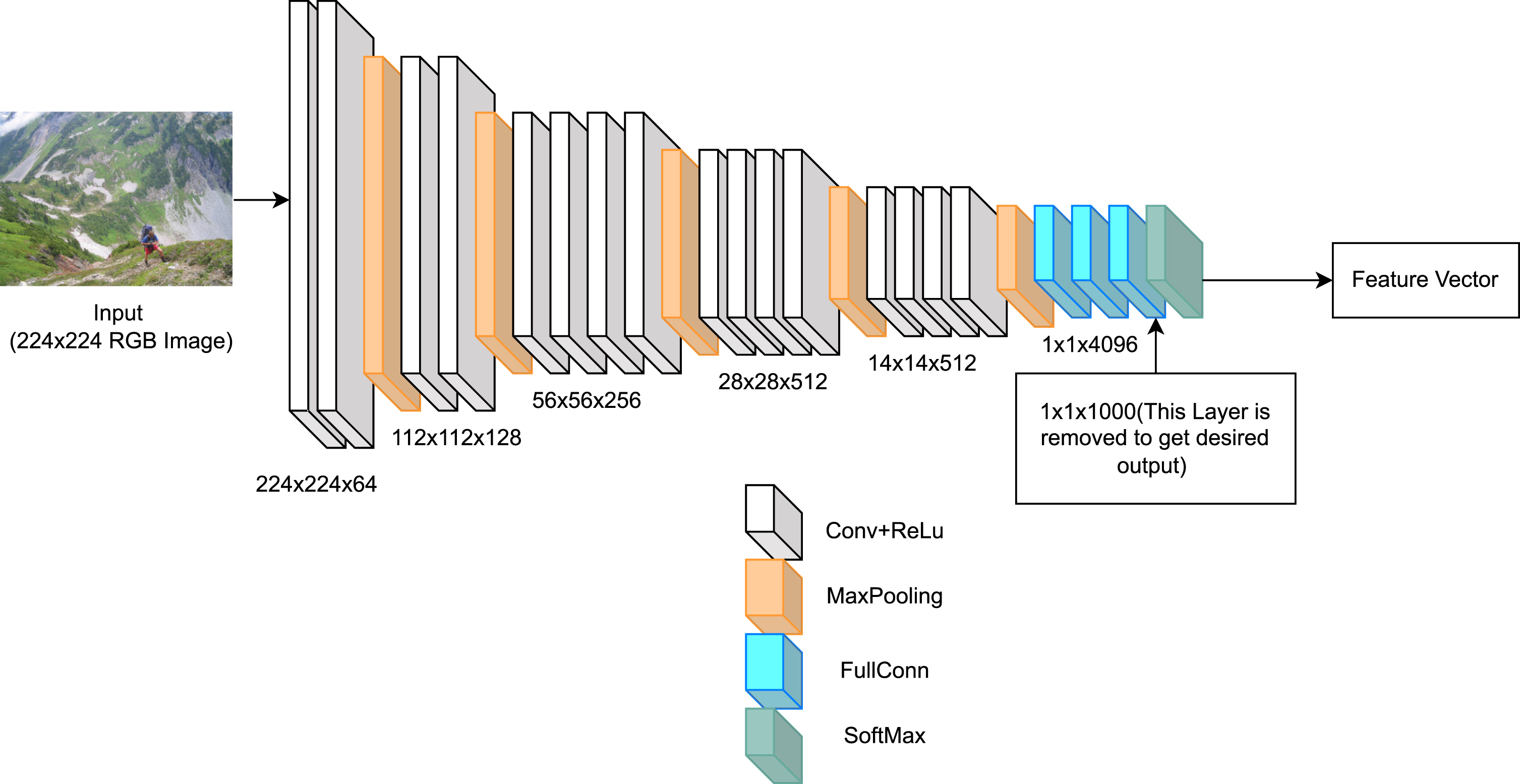
A Descriptive Representation of VGG19 encoder for desired output.
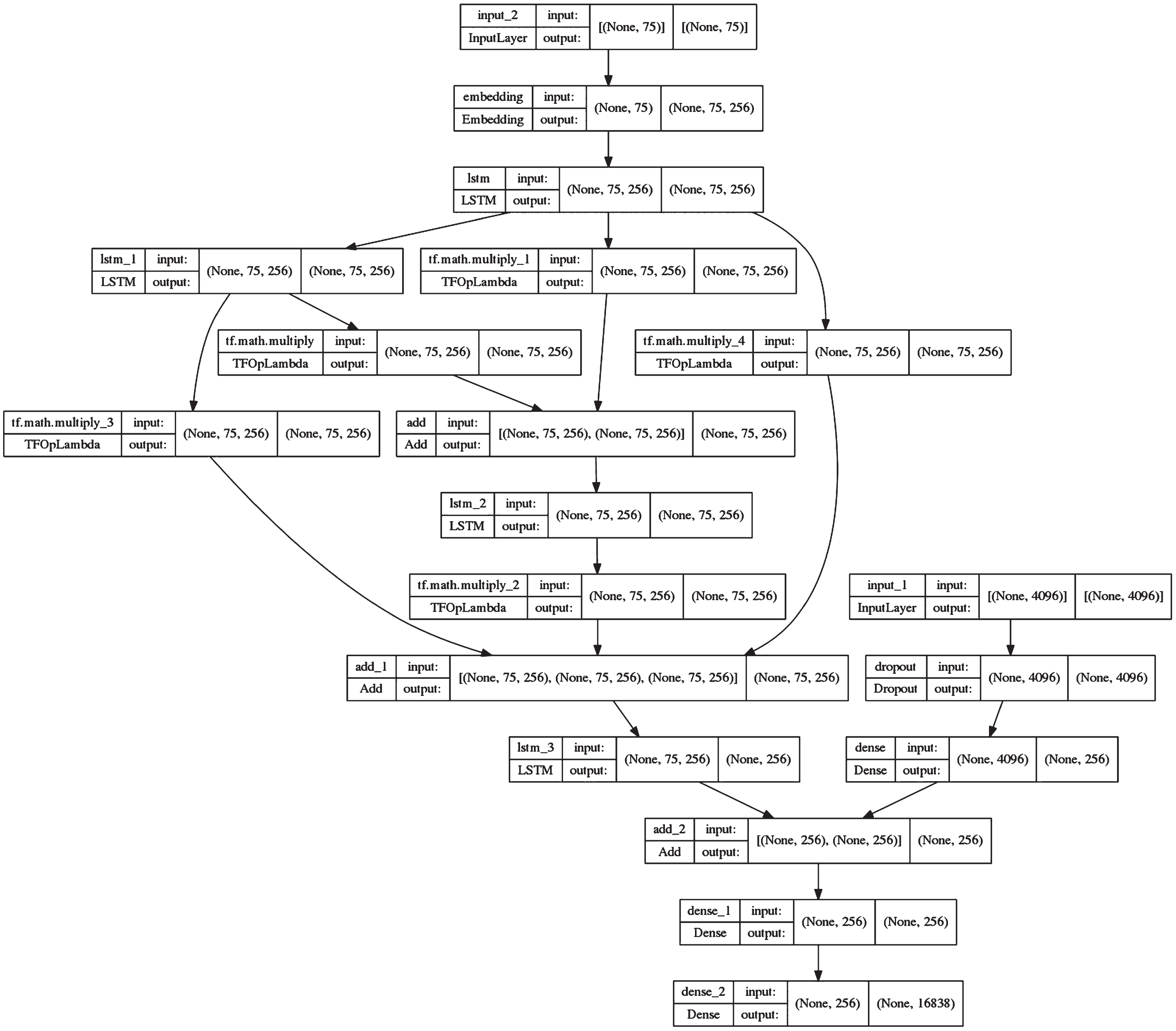
A Descriptive Representation of Complete model with dimension details.
Figure 1 shows that text embedding as input is processed through the densely connected LSTM layers. Output from these layers is given as input to the two dense layers connected sequentially. The output of LSTM1 is given to the LSTM2, LSTM3, and LSTM4 with weights 1, 0.25 and 0.1, respectively. Similarly, the output of LSTM2 is given as input to LSTM3 and LSTM4 with weights of 0.75 and 0.1, respectively. In the same way, the output of LSTM3 with weight 0.8 is passed to LSTM4. Then the output of LSTM4 is given as input to the first dense layer, which is further passed through the second dense layer to get the desired output. As LSTM sequentially introduces the short-term dependencies between the source (image features) and target sentence (required description) [44]. Higher weightage is given to the most recent output considering prior output again improves the model’s performance.
The proposed model is trained for 20 epochs on Flickr8k and Flickr30k datasets for an automatic text generation task on a training set of 6000 and 25426 images, respectively. The loss used is categorical cross-entropy for multi-class classification.
An optimizer is used through this loss function for all the parameters for tuning the learning rate. The learning rate of the parameter aid the optimizer in weight updating in the direction opposite of the gradient. For which a 0.2 learning rate is used. The minimum validation loss model is saved to use further for testing purposes. The configuration used during training is Intel(R) Xeon(R) CPU @ 2.30GHz and 12GB NVIDIA Tesla K80 GPU. Once the system is learned, it could be used for security, content analysis, and IoT-based applications.
For the performance evaluation of the model, some metric is required. Several evaluation matrices are available for the quality evaluation of textual data. The metric for assessment depends on the task for which it is needed. In the same field, several types of models are used. The proposed model is based on the CNN-RNN model, and as per the finding given in [20], the BLEU metric gives better results for such models in evaluation. BLEU stood for Bilingual Evaluation Understudy and was used to determine the quality of text which has been translated. The BLEU score measures quality by calculating the difference between machine-translated text and human-translated text. The formula to calculate the BLEU score is given below:
Datasets
Flickr8K [21] and Flickr30k [45] are the datasets used for this work. In Flickr8K, a total of 8k images are there. Each image has five sentences as a description. Pictures are selected from six groups of the Flickr8k dataset and are not intended to contain any individuals or areas. The Flickr30k dataset consists of 31783 images with 158915 descriptions, i.e. five descriptions for each image. However, Flickr30k contains Flickr8k with extended images. In the Flickr8k and Flickr30k datasets, images and descriptions are kept separately in two folders. A unique ID is used for each image, and five different descriptions for that image with that same unique ID are listed in the file. The dataset contains all images in RGB format. Preprocessing is done before passing them to the model.
Fig. 7 represents the sample images from the dataset with their respective descriptions. Fig. 6 represents the images with their unique ID and size in the Flickr8k and Flickr30k datasets. Dataset splits used for Flickr8k and Flickr30k are as follows: In Flickr8k, 6k, 1k, and 1k images are used for training, testing and validation purposes, respectively. Flickr30k contains 25k, 3k and 2k images for training, testing and validation purposes.

Example images and descriptions from Flickr8K dataset

Sample images in the Flickr8K and Flickr30k datasets
In the proposed model, translation is from visual content to natural language. Therefore it is used to identify the model’s accuracy in terms of the quality of generated text for a given image. It makes the comparison in n-gram where ’n’ could be 1 to 4. Accordingly, scores are named BLEU-1 for n=1, BLEU-2 for n=2, and so on. These scores give the accuracy of the description generated.
In [20], different metrics comparison for the CNN-RNN model is discussed, which indicates that BLEU gives more accurate results than the other evaluation metrics for similar model types.
In these datasets, a thousand images for Flickr8k and 3k for Flickr30k are used for testing purposes. For each image, a description is generated to give 1000 descriptions for Flickr8k and 3k for Flickr30k. BLEU score is calculated for the generated text based on the illustrations available in the dataset. Performance evaluation of the model using the BLEU score is shown in Table 3 in the case of different CNN models with LSTM on the Flickr8k dataset.
Performance evaluation of CNN models with LSTM on BLEU-score
Performance evaluation of CNN models with LSTM on BLEU-score
The detailed review shows that VGGNet is the most preferred network over other networks for such tasks. It is a deep convolutional neural network with 16 layers in VGG16 and 19 in VGG19. As VGG19 is deeper than VGG16, three additional layers should give a better result supported as per the results in table 3. Because of this, it creates better feature vectors than VGG16. VGG19-the pre-trained model used, is trained on a vast data set, ’ImageNet,’ having around a million images with thousand object categories and therefore, rich features vector representation is learned. Compared with different models in table 3, all four scores, BLEU-1 to BLEU-4, are better for VGG19. This model is further trained on the Flickr8k and Flickr30k training datasets. Features given by this model are passed through the Dense-LSTM for sentence formation.
Results are shown in Table 4, which also supports that in the CNN-RNN model, using VGG19 as CNN and Dense-LSTM as RNN gives considerably good results compared to similar approaches while using Flickr8k and Flickr30k datasets. Model performance can be more promising on larger datasets like MSCOCO. As evaluation for the proposed model is done on Flickr30k comes out better in just ten epochs than on flickr8k in around twenty epochs.
Performance evaluation on Flickr8K and Flickr30k Dataset using BLEU score (B1)
The proposed model performs significantly on some of the images of Flickr30k testing data. Observations are listed in table 5. The number of images for which the BLEU score is less than 0.40 are 331, 1956, 2582 and 3039 for BLEU-1, BLEU-2, BLEU-3, and BLEU-4, respectively. This shows that model is not performing well as per BLEU-1 only in the case of 1% of the images. That is, for 99% of data achieved percentile is more than 60%.
BLEU scores B1, B2, and B3 for more than 60 percentile for the proposed model
In some cases, the generated descriptions are not as accurate as those given by humans in areas like colour or context. This can be resolved by training the model on a large data set or preprocessing the dataset at the description level. Descriptions generated by the proposed model having mixed results are shown in Fig. 8.

Results of textual descriptions generated using the proposed method.
Text generation for visual content has a wide range of applications like image editing tools, video summarizing, aid for visually impaired people etc. A GUI (Graphical User Interface) is developed in the proposed work, which could be used for child education. The image-based question-answering system is also one of the applications. The developed interface is shown in Fig. 9. The interactive study, which includes visuals and sounds, was found more attractive, interesting, involving and easy for children. This tool provides more relevant information in text form about the content given as input, as this model uses both foreground and background details while generating the output. Due to this, it provides almost all the details that a human can tell, and the most suitable textual description is generated about the content given as input. It also provides the generated text in audio form. Using this proves to be useful for the visually impaired/ incapable people by fixing the camera in an individual’s walking cane to guide them about the path, scene or object obstacles. In addition, a user can search for similar images and google queries using GUI buttons.
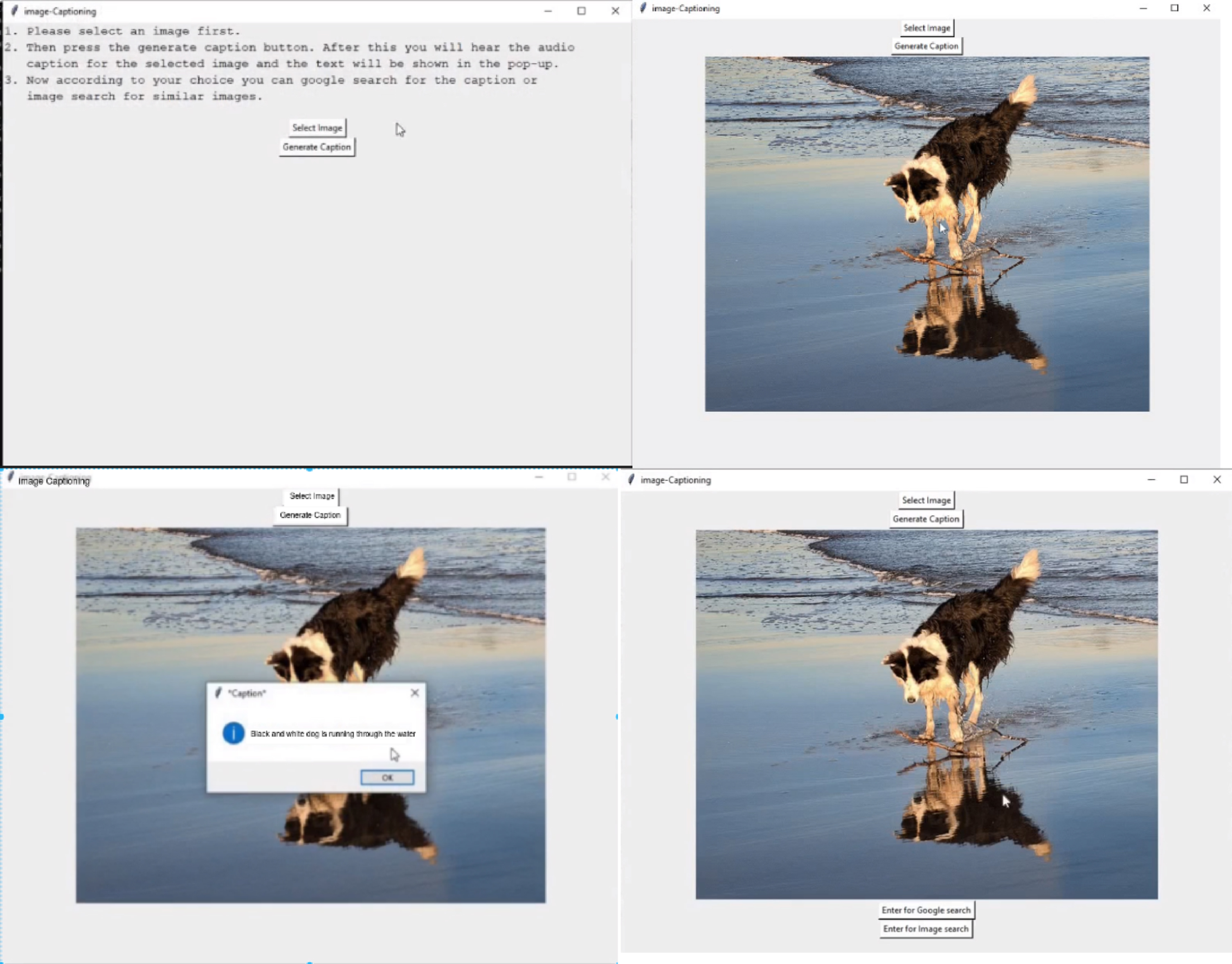
Step-wise screenshots of GUI from top left to bottom right: (a) User is required to select an image using the select image button, (b) selected image will be displayed, (c) by pressing generate caption button, a caption is generated in a pop-up window and audio form, (d) Two more option will be displayed: enter for a google search for generated cation and enter for an image search for the selected image.
An encoder-decoder-based framework with novel Dense-LSTM architecture is proposed that provides natural language descriptions for scene descriptions with context information. Two neural networks are used, one as an encoder and one as a decoder. A CNN is used as an encoder for object identification in given input and to find the in-between relationship between objects by creating a feature vector for the given content. Dense-LSTM is used as a decoder for description generation as it provides better results than LSTM, one of the RNN variants, when used with CNN. Evaluation is done using the BLEU score on the Flickr8k and Flickr30k datasets. The model is suitable and could be used for IoT-enabled visual content to generate a more relevant description in practical applications.
The proposed model generates comparatively good descriptions and audio for the visual content given as input. In general, the descriptions generated are good enough to consider. Still, the wrong object in terms of colour or context identification is done, which will be considered in future work. Comprehensively model can generate considerably good results and be used in similar applications. A GUI is developed to provide usability ease.
Future Work
Textual descriptions for visual content can proven to be helpful in day-to-day activities. Suitable descriptions for the visual content received from the IoT device can be used for surveillance applications. The proposed model addresses the context information for the scene using Dense-LSTM. Still, the scope of improvement is there to address in future work. The model deals with time optimization with increased accuracy for text generation tasks for visual content by fine-tuning the model.
In Flickr30k, some of the images’ original descriptions are not as per the content of the picture. The diversion between visual content and their descriptions is quite significant. This kind of training data also affects the model performance. Therefore, if the training data provided (Flickr30k) is processed further to overcome this issue, results may improve further.
Model is implemented to deal with real-world problems to solve related issues like summarizing videos, guiding path and providing information, etc. An application using IoT devices could be developed to take advantage of descriptions for visual content. The model’s accuracy can be enhanced; if trained on larger datasets, it could generate more general descriptions for new images. Similarly, more applications are there for which this model can be used.