
Abstract
Examining the properties of High-Performance Concrete (HPC) has been a big challenge due to the highly heterogeneous relationships and coherence among several constituents. The employment of silica fume and fly ash as eco-friendly components in mixtures benefits the concrete to improve its physical features. Although machine learning approaches are utilized broadly in many studies solitarily to estimate the mechanical features of concrete, causing to reduce accuracy and lift the cost and complexities of computational networks. Consequently, current research aims to develop a Radial Basis Function Neural Network (RBFNN) integrating with optimization algorithms in order to precisely model the mechanical characteristics of HPC mixtures including compressive strength (CS) and slump (SL). Feeding the dataset of HPC samples to hybrid models will result to reproduce the given CS and SL factors simultaneously. The results of the models showed that the maximum rate of correlation between estimated values and measured ones was obtained at 98.3% while the minimum rate of RMSE was calculated at 3.684 mm (and MPa) in the testing phase. Employing such soft-oriented approaches has been benefiting us to reduce costs and increase the result accuracy.
Keywords
Introduction
High performance concrete (HPC) ingredients are employed widely in long bridges, skyscrapers, dams, etc. These materials often contain other additives such as, fly ash (FA), silica fume, blast furnace slag and superplasticizer as supplementary substance [1, 2]. The dosage of each ingredient can be adjusted to achieve the imposed performance and target intensity [3]. Since the requirement for cement as a major building material, having high price compared with different kind of concrete components, the problems related to greenhouse gas emissions during manufacturing, there is great interest in replacing it with pozzolan material. A lot of waste has been used, as mineral additives in HPC to protect environment [4]. However, utilization of the pozzolan mineral mixture improves the stability and mechanical properties of the concrete. Moreover, it can also be used to reduce cement consumption and carbon dioxide emissions, which can lead to global warming and raw material waste. The green concrete term concrete can be applied for this concrete type [5]. On the other hand, HPC generally has a low w/b ratio and requires a larger amount of cement than conventional concrete [6].
For example, instead of cement, more binders such as FA, lime powder, silica fume, and blast furnace slag can be mixed to prevent uneven distribution of larger particles in fresh concrete. Also, passing ability, flowability, and resistance of HPC is enhanced through adding superplasticizer admixtures and modifiers of viscosity, but it will increase the overall cost of the concrete [7, 8]. Whereas, concerns have been expressed around the world about reducing the use of natural resources in concrete manufacturing and replacing them with alternative waste components. Thus, sustainable high-strength HPCs are manufactured by lowering cement contents by replacing them with mineral wastes such as fly-ash.
It is difficult to predict the compressive strength (CS) and slump (SL) of concrete after choosing the mixing ratio because the mixtures are so heterogeneous. Employing machine learning approaches or statistical ways for appraising the mechanical features by declining errors among estimated outcomes and experiment data (as targets) has received a lot of attention in researches [9–12]. Recently, many machine learning algorithms are developed to model the special features of HPC effectively and accurately. Regarding several ways, the most popular ones are related to single and multi-layer of Neural Networks [13–15] plus the coupling with Monte Carlo stochastic sampling [16].
As well as using Artificial Neural Networks (ANN) in the companion with modified firefly algorithm [17] and fuzzy-ARTMAP [18–20]. Also, ensemble computational techniques such as random forest (RF) [21], support vector regression (SVR) [11, 22], adaptive boosting [23], data-mining [24] and gradient boosting (GB) [25] and boosting smooth transition regression trees (BSTRT) [26] are also different models that have been conducted the predicting concrete physical features. Young et al. [26] did research with the aid of neural networks, gradient boosting, random forest, and SVR models to estimate the CCS of more than 10,000 samples based on measured components of mixtures and industrial considerations with desirable results of correlation higher than 90 percent [27, 28]. Yeh and Lien [29] in another article developed a genetic tree operational model, in combination with the genetic algorithm and operation tree to calculate the some concrete features. Tsai and Lin [31], Gandomi and Alavi [30], Mousavi et al. [31, 32], and Lim et al. [29] used gene expression programmings (GEP) to derive various models for the modeling concrete CCS. Besides mentioned examples, there are numerous applications of AI-based models to estimate key dependent parameters affected by decision variables such as evaluating structural and thermal response of reinforced concrete (RC) beams and columns; at a specific point in time or through tracing time–temperature/deformation history, for up to four hours of fire exposure [33], analyzing the efficiency of biochar in soils with varying particle size distribution for increasing soil–water characteristic curves [34] or developing models for predicting residual tensile strength of Glass fiber reinforced polymer (GFRP) bars aged in the alkaline concrete environment [35].
On the other hand, due to the advantages of Radial Basis Function Neural Network (RBFNN), a powerful branch of ANN, many researchers have used it for prediction purposes [36–39]. It should be noted that applying such estimating models solely to solve equations, can be accompanied by inaccuracy and errors, especially when assigning arbitrary variables. Some authors, interestingly, have developed integrated models of ANN and fuzzy logic [40, 41], regression analyses [42], SVM, and even linear regression [43, 44] with some optimization algorithms to optimize model weights and biases. In this regard, as the novelty of present research, optimization algorithms have been employed to assist the base model to find its arbitrary values at the optimal level for producing outputs with desirable accuracy and unbiased. In fact, modeling the hardness features of HPC including CS and SL will be fulfilled. For this purpose, employing the coupled RBFNN with two matheuristic algorithms is considered for optimizing the prediction process. In this regard, Whale Optimization Algorithm (WOA) and Salp Swarm Algorithm (SSA) have been utilized to minimize the complexity and cost of the computational network and then, finally, to improve the model precision simultaneously. There are several papers using mentioned algorithms with successful results [45–50]. Generally, the developed RBFNN models called WORBF and SSRBF are supposed to decline the costs and uncertainties involved in experimental ways to appraise the compressive strength and slump of concrete mixtures composed of certain ingredients. In the next section, the samples’ components will be introduced as well as the hybrid models mechanism.
Materials and methods
Radial basis function neural network
Introduced by Broomhead and Lowe [38], a Radial basis function neural network (RBFNN) is defined as a feedforward type of network trained with an algorithm trained as supervised. As shown using Fig. 1, the RBF contains 3 main layers: the input, hidden, and output layers.
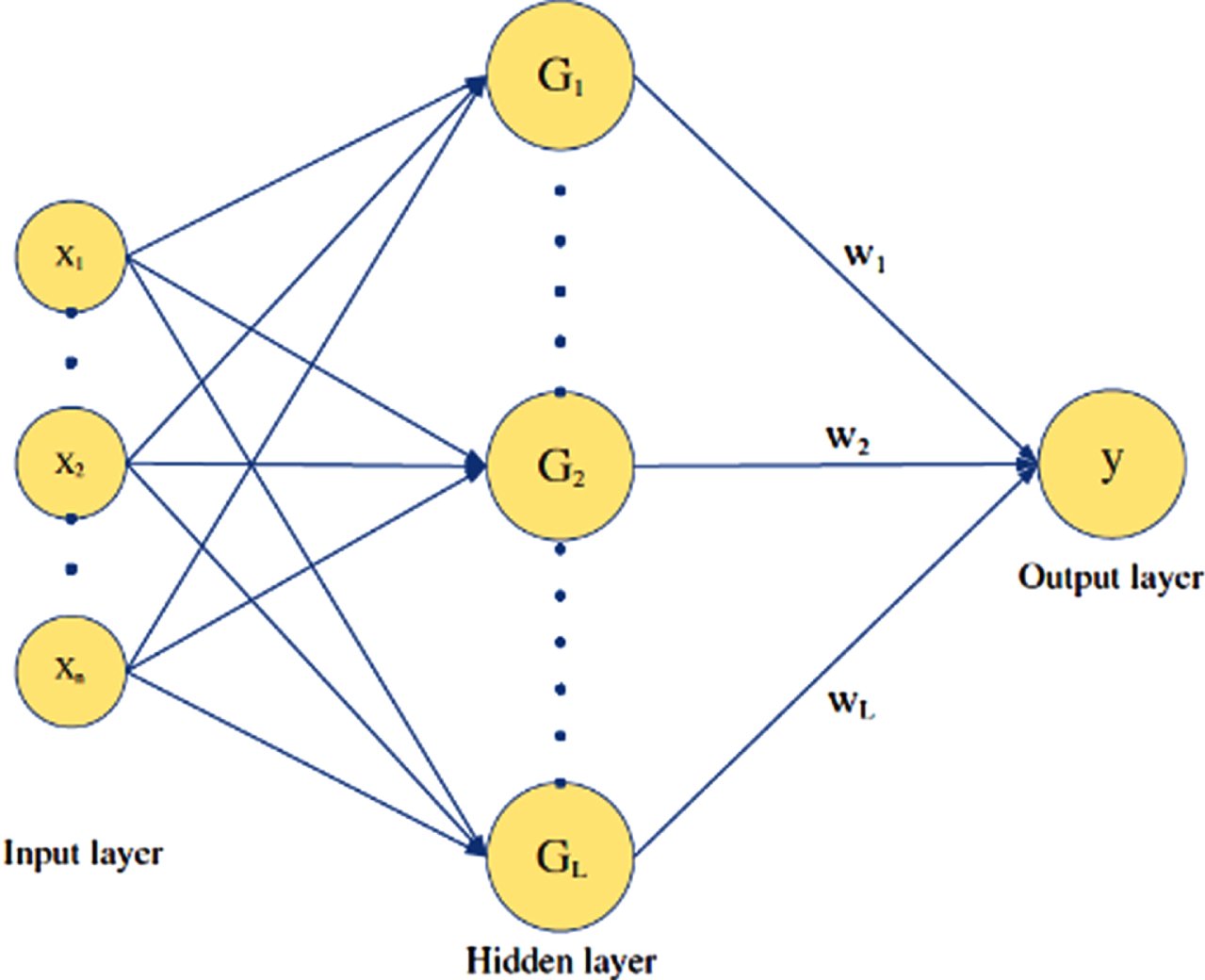
The radial basis function neural network structure.
There are several types of RBFs, such as Gaussian, hardly multiquadric, Inverse multi-quadratic, and Sigmoid functions. The Gaussian RBF is one of the most well-known functions characterized by a center and a spread.
The input layer is a simple part of a network where a node does not run the process. In addition, the node number in the input layer is the same as the variable number [51]. The second layer named hidden seems as the calculator layer, containing radial basis function (RBF) with circular type to find answers. This layer receives the dataset from the first one (input) that uses the RBF to perform a non-linear mapping to the input value. The symmetric function used in RBFNN calculates the distance of a particular input value from a center point. However, there are various types of RBF, including hardly multiquadric, Gaussian, Sigmoid functions, and Inverse multi-quadratic. Gauss RBF has been a well-known function elaborated by spread rate and center [52].
Utilizing the RBF on input vectors, the hidden layer output nodes can be transferred to the output layer with the aggregation of data produced by hidden layer in the simple regression process within the output layer. The RBFNN process can be listed as: 1) determining the radial distance (d i ) between the center (c i ) and input vector (x) for the ith node of RBF in the hidden layer, and, the outcomes (h i ) will be computed by the network (G) with relations presented in following:
The whale optimization algorithm (WOA) was designed based on the hunting prey by creating bubble-net by humpback whales shown in Fig. 2 [53]. In fact, it has been an intelligent swarm-based approach considered to solve the complex optimization problems having continuous domain [54–56]. Seeking prey within multi-dimensional spaces in the swarm, whales will be located as the decision variables, while the objective function is designed to have the minimum distance between whales concerning the position of prey. The time constraint function as locations for a whale is evaluated by the operation steps written as follows [53–57]: (i) shrinkage circling hunt, (ii) exploit phase (as the attack in bubble-net), and (iii) Explore phase (as finding preys). As shown in Fig. 2, when recognizing the prey position, the whale goes to encircle it by moving in 9 steps. This algorithm defines the prey as the most suitable potential solution (target near the best answer) due to having no information on the optimal position of preys in the searching area. For finding the best search candidate every possible attempt is taken into consideration.

The bubble net created by humpback whale.
Interestingly, other agents try to update their locations adjacent to the best answer that is shown through Fig. 3 [52].

The spiral updating process [52].
For the Exploitation phase, the hunting bubble net is defined using Fig. 4 [52]. The same space among the whale positions and preys will be defined by applying a mathematical method that is helix. The hunter positions (in a spiral shape) is tunned after moving [55]:
Exploitation phase [52].
For exploration phase as shown by Fig. 5 [52], if A< –1 or A > 1, the agent of the search will be dated via a randomly selected whale at elite agent location:

Exploration phase [52].

The pseudocode of the WOA algorithm.
The Salp swarm algorithm (SSA), as an intelligent optimizer swarm basis, was inspired by the foraging process of salp swarms [46]. In the struggle for more food sources, these creatures are linked by salp chains, allowing them to quickly communicate and locate food sources [47]. In the Salp School, different salps play different roles: followers and leaders. Followers follow the leader’s instructions and leaders lead the entire population. The final goal of salp is to find the best source of food, indicated as F in the searching space. As with other group basis algorithms, the initial population, consisting of the numbers and location of individuals, will be predefined. Every individual is a prospective solution for the best answer. All solutions’ space has been denoted by U
i
that is a two-dimensional matrix.
Continuously, the initialized swarm of salps will be updated by processing mathematic operations within the model, in which followers and leaders track the various equations. However, a leader plays a main role in searching food and navigation, as updated in Eq. (10):
Modeling the mechanical properties of HPC mixtures via RBFNN would be accompanied with metaheuristic algorithms to generate WORBF and SSRBF hybrid models. Actually, this study examined a dataset containing 181 HPC samples [56] including fine/coarse aggregates, water/binder ratio, air agent, fly-ash, and superplasticizer. Notably, the CS and SL measurements were performed on the 28th day of the concrete age. Table 1 provides a summary of relevant data from a statistical point of view in which CS shows the compressive strength, SL is slump, W/B is the ratio of water to binder, W is water, S/A shows ratio of the weight of fine aggregate to that of all aggregate, SF silica-fume, FA fly-ash, AE content of air-entraining agent, SP shows the superplasticizer. Mentioned dataset can be divided into two types: i) independent variables, which are the components mixed to create the HPC blend ii) dependent variables of mechanical properties: compressive strength and slump features affected by the introduced independent data i. Therefore, all data is fed in hybrid WORBF and SSRBF models as a training and validation phases and then tested. In this regard, the above three stages are performed as subphases of the training phase, too. Specifically, 70% of the mixtures’ data are chosen in the train phase and another 30% is used in the same proportion in the test and validation phases. Fig. 7 shows the whole data used to train models. The coupling mechanism of optimizers SSA and WOA with RBF to generate holistic frameworks of SSRBF and WORBF has been revealed through Fig. 8.
Summary statistical report of model inputs
Summary statistical report of model inputs

Input data used to train models including: a) air entraining, b) fly-ash, c) ratio of the weight of fine aggregate to the weight of all aggregate, d) superplasticizer, e) water, f) water to binder ratio, g) compressive strength, and h) slump flow.
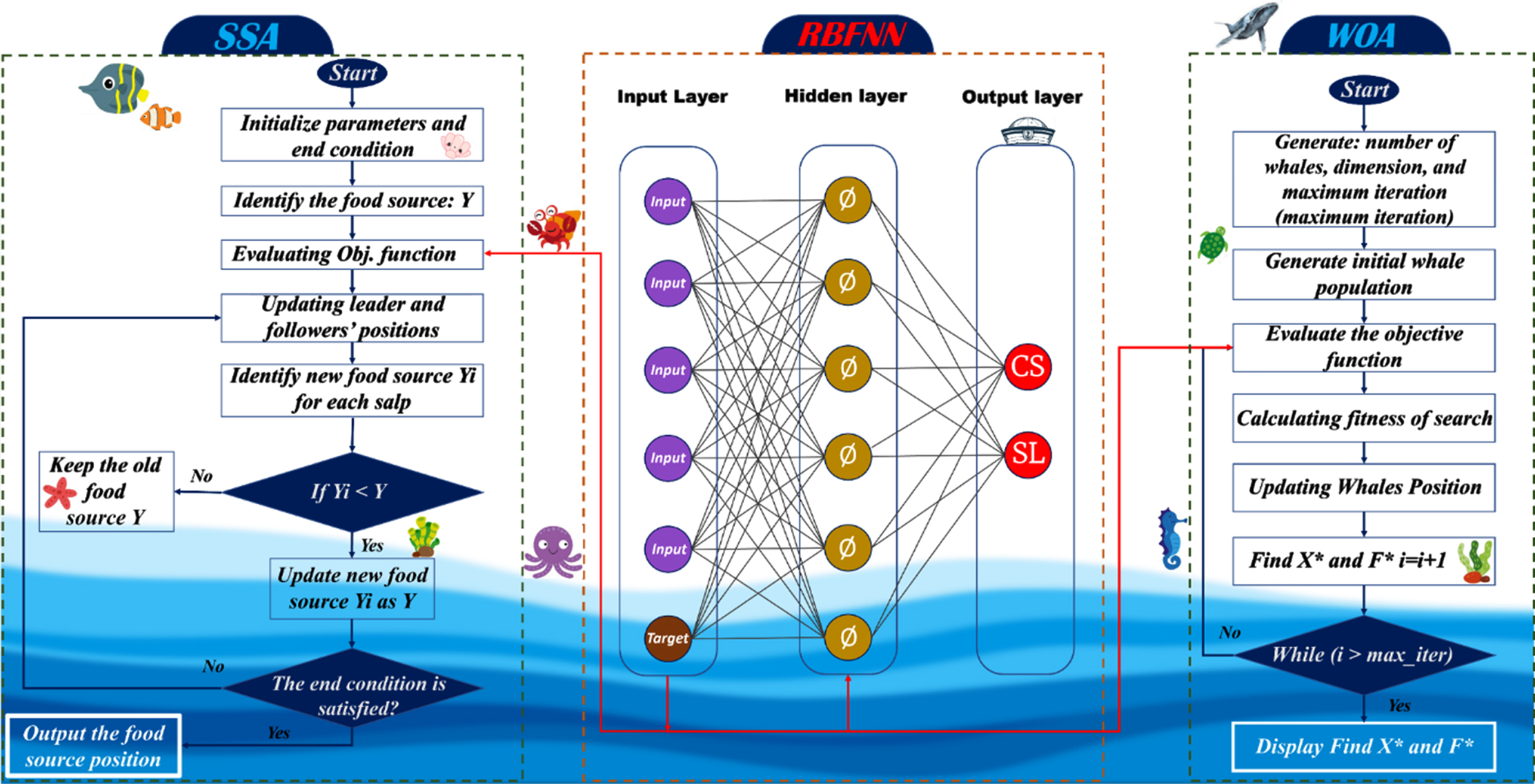
Flowchart of developed hybrid models: WORBF and SSRBF.
For assessing the performance of WORBF and SSRBF in the prediction of compressive strength and slump rate of high-performance concrete (HPC) samples, various types of evaluation indicators are shown through Table 2. In Table 2, t
n
represents the measured numbers of CS and SL and the averages are indicated via
Evaluating indices for analyzing the proposed frameworks
Evaluating indices for analyzing the proposed frameworks
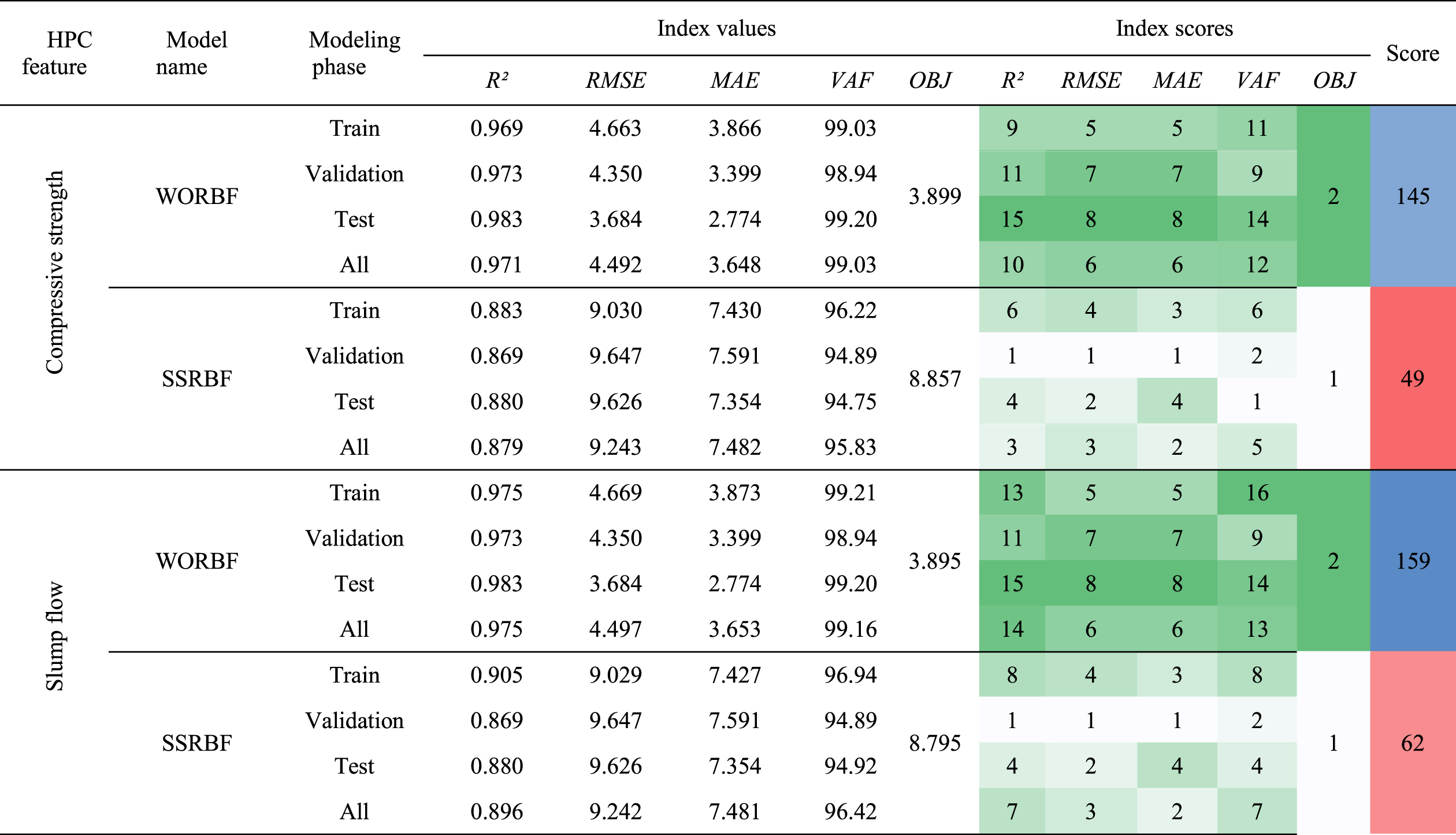
The modeling process was conducted for the developed frameworks WORBF and SSRBF. In fact, by feeding the input data of HPC ingredients as well as the compressive strength and slump flow rates as targets to models, training operation was done to predict the mentioned target numbers with similar inputs. Actually, the hardness properties of samples were surveyed in four different conditions as brought in Table 3. The indices aforementioned assessed the results of models in four stages of training, validation, testing, and considering all of the data. In addition, in the score part of the table, the mentioned results of indicators were ranked and then summed to generate the final scores for each defined condition. As shown in Table 3, modeling the slump flow of HPC samples was done with better results. However, in the training phase of modeling CS by WOA optimizer, the correlation index of R2 was calculated at 96.9 percent that was 11% more than that of SSRBF. The high-accuracy modeling based on the RMSE index was done by WORBF with 3.684 mm (and MPa) for both concrete aspects. On the other hand, the WOA optimizer could tune the RBFNN to reach the prediction of CS and SL according to the MAE index. In testing phase the minimum rate of MAE is diagnosed for all of models between various stages that 2.77 mm (and MPa) was the minimum rate of error seen in simulations. Assessment of the models using VAF proved the fact that WORBF was successful in prediction. With this respect, in the modeling the slump rate of HPC samples, the training phase could receive a 99.21 rate that was 3.52% more than the SSRBF result. Despite the fact that referred four indicators had four stages of modeling, the OBJ index is calculated based on the results of other criteria, so can show a comprehensive view of the models’ ability to appraise the target features of HPC. Regarding the results, the SSA was not prosperous compared to WOA. For estimating the SL factor WORBF could do a better job with the rate of 3.89 that was 139% more than that of SSRBF. While for estimation of CS the difference was calculated at 140% that SSRBF had an 8.79 mm error. Relied on the evaluative results of five assessment criteria, the ranking of each index was done and they were summed to show the total scores in the last column. Based on the total scores of the models, WOA has been efficient in tunning RBFNN with 66% and 61% discrepancies to appraise the CS and SL properties of HPC samples respectively.
The results of evaluation criteria and scoring models
The results of evaluation criteria and scoring models
Nevertheless, WORBF and SSRBF models to estimate the target values of compressive strength and slump flow used same data inputs as ingredients and measured CS and SL. To survey the interaction of them rather to each other, Fig. 9 has indicated the correlation index of R2 between mentioned parameters and also the target values of CS and SL. Regarding the correlation rates seen in Fig. 9, the highest R2 can be found among compressive strength with water to binder ratio (W/B) in negative direction, superplasticizer and silica-fume in positive way which are dedicated with red and blue box, respectively. On the other side, for slump as expected, the water to binder ratio (W/B) plays the main role then fine aggregate to total aggregates ratio. According to the ingredient used in HPC compounds, the roles of each additive is clear with the aid of Fig. 9. For example, except for silica-fume and superplasticizer, other remaining materials have reduced the stability and cohesion of concrete then led to decreasing compressive strength Correlation of inputs and targets used in models. Counter map of: a) water, superplasticizer, CS, b) water, superplasticizer, SL, c) water/binder, fine aggregate/total aggregate, SL.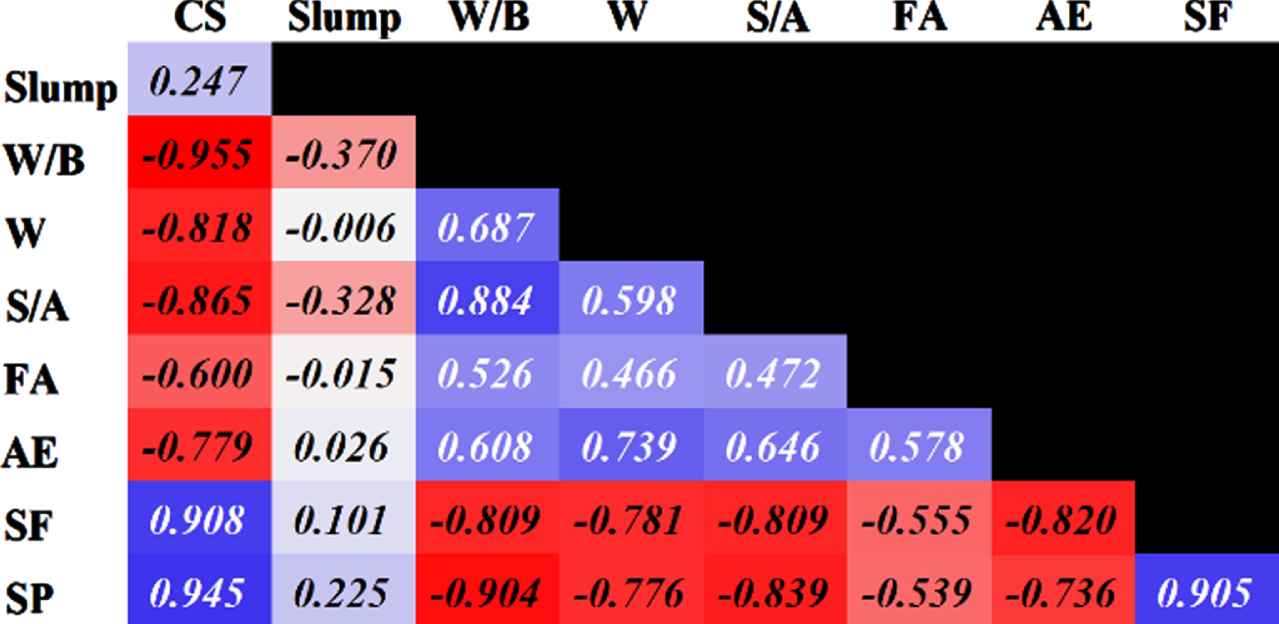
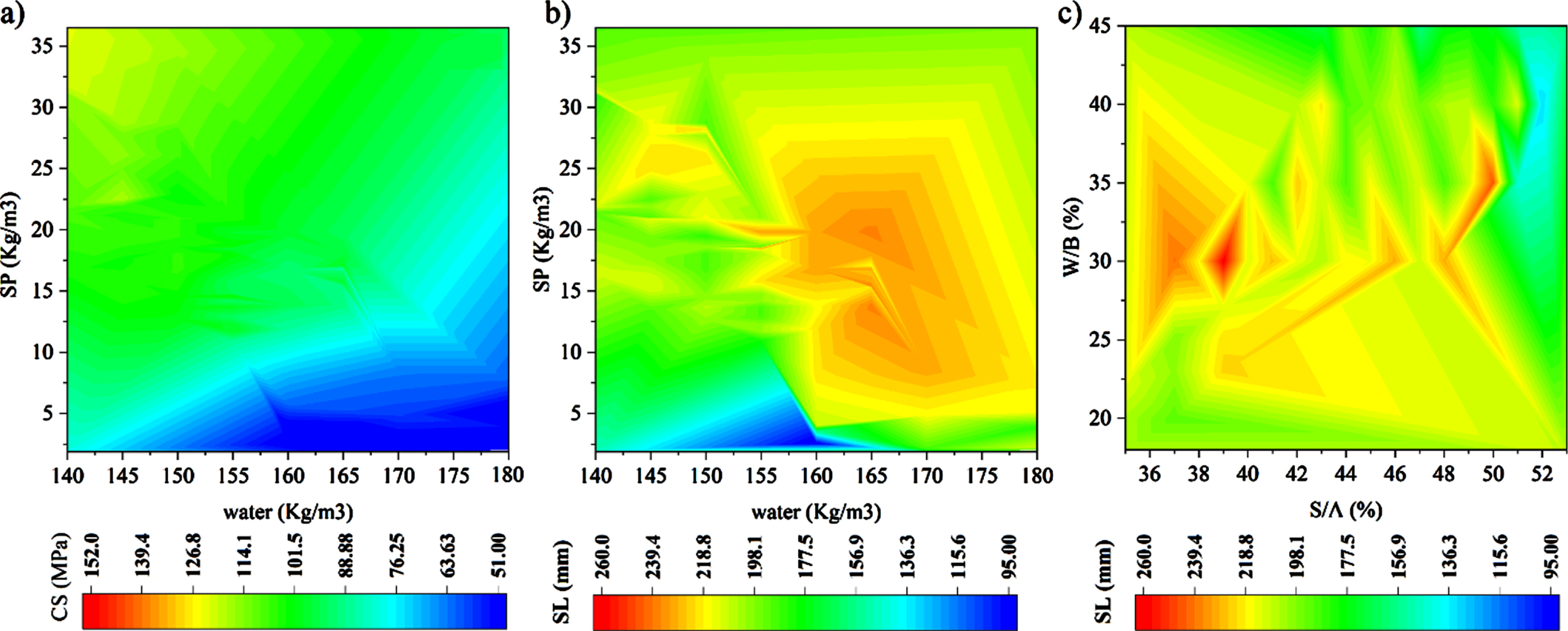
Based on Fig. 10 for compressive strength (a), the roles of superplasticizer and water is clearly obvious that by increasing water and decreasing SP, the CS would decline. Despite the reduction of CS with water increasing, the covering role of SP could enhance the CS rate. Moreover, considering SL with the effects of same materials (b), the lowest SL has been happened at the lowest rate of SP. In Fig. 10 (c), the impacts of W/B and S/A on SL simultaneously, cannot prove a same pattern but in a certain zone of W/B (25% –37.5%), the SL has been topped to its highest rate. Nevertheless, by increasing S/A and W/B linearly, the S/A could prevail the effects of water and has reduced the slump of HPC.
Modeling the geomechanical features of HPC samples is important to survey in terms of error rates that are defined the difference between predicted and measured value. To this end, Fig. 11 has shown the performance of each models to estimate the CS and SL factors. Based on Fig. 11, the modeling by WOA optimizer has been prospering compared to SSA that the points of plots can confirm this fact. In estimation of CS by WORBF (a) gathering points around the fitting line is more than SSRBF (b). To better understand the modeling process, also the equations of fitting line can assist to know how the CS points were modeled. In this regard, the slope of fitting line relevant to WORBF is 0.97 while that of SSRBF has been calculated 0.88, with 9.3% difference. In addition, a near distance between bisector line of Y = X and fitting line in WORBF shows a better simulation of compressive strength rates rather to SSRBF. Besides, the distribution of CS points in SSRBF is more broad than WORBF. On the other side, modeling SL was done at the similar condition and the WOA could tune the RBFNN better than SSA. In estimating slump rates, WORBF by reducing the errors better than SSRBF, gathered the SL points at better conditions and more closer to the fitting line that the RMSE of earlier model was calculated about 106 percent more than latter one. The slope of fitting line equation, also, was a computed 0.91 for WORBF while 0.88 for another model, with 3.3 percent difference.
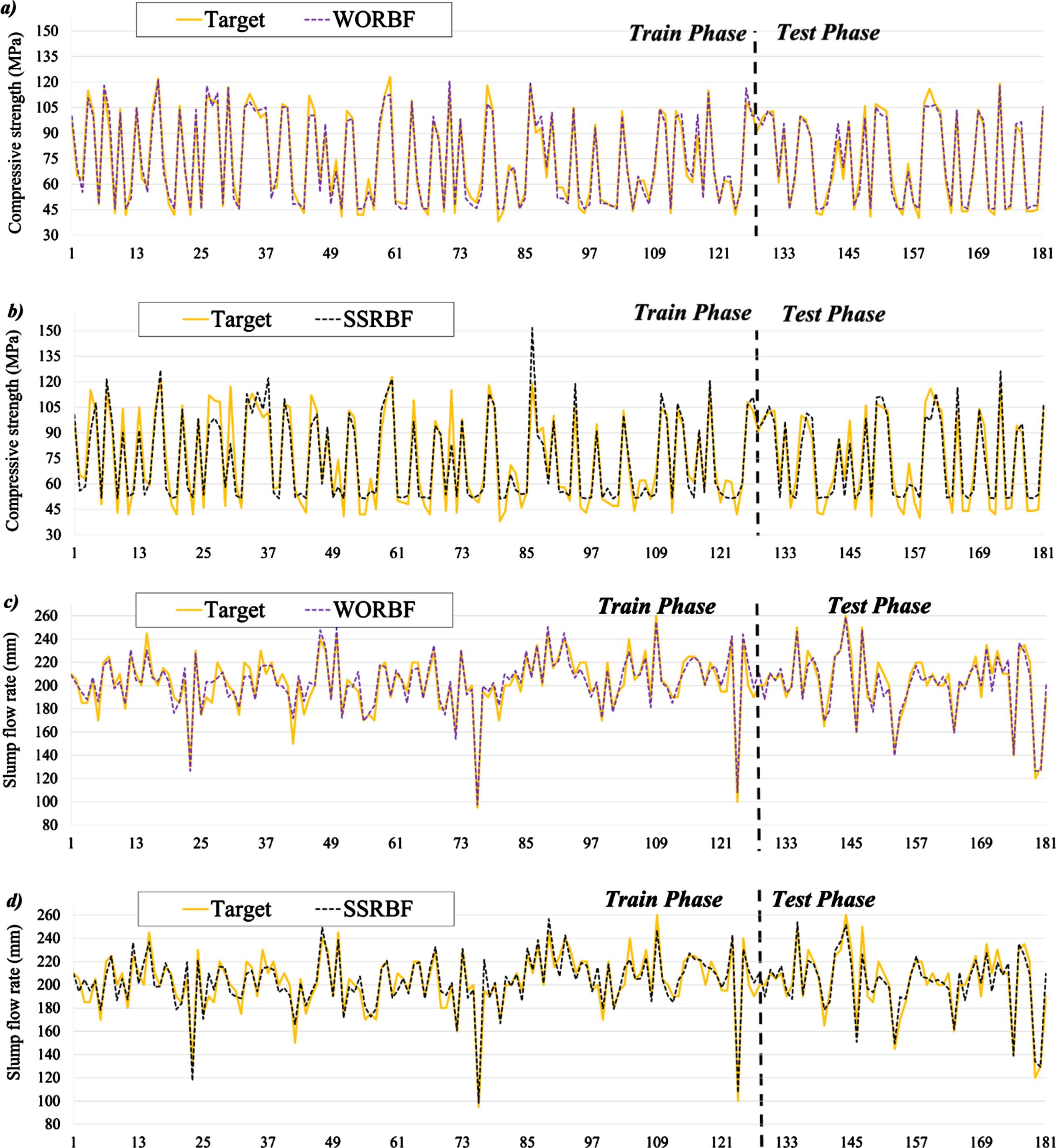
Measured (target) values against the predicted values modeled by: a) WORBF (estimating CS), b) SSRBF (estimating CS), c) WORBF (estimating SL), and d) SSRBF (estimating SL).
To bolding the the differences of modeling rates with measured (as targets), Fig. 12 has attempted to show the gaps for each HPC samples. As shown in Fig. 12, the coincidence of model lines with measured lines are at acceptable conditions, while there are some mismatch between them. The main gaps can found in modeling CS by SSRBF (b) that in testing phase most of errors has been cured while in estimation of SL there are cases of overestimation and underestimation. For CS modeling, the highest errors can be found in SSRBF especially for mixture #86 that in WORBF (a) it is placed on the target line. Generally, the modeling results in testing phase has been improved by considering the gaps among dashed line of model and target lines. Also the SL of samples were modeled with gaps but in this case, the gaps are rarely found to be large. With this respect, there can be found positions in SSRBF that have exceeded the target line. For example, in sample #54 that is leaved in the training stage, the SL has been estimated higher than target line. But generally, the modeling of slump flow with to developed models of WORBF and SSRBF has been simulated better than compressive strength factor.
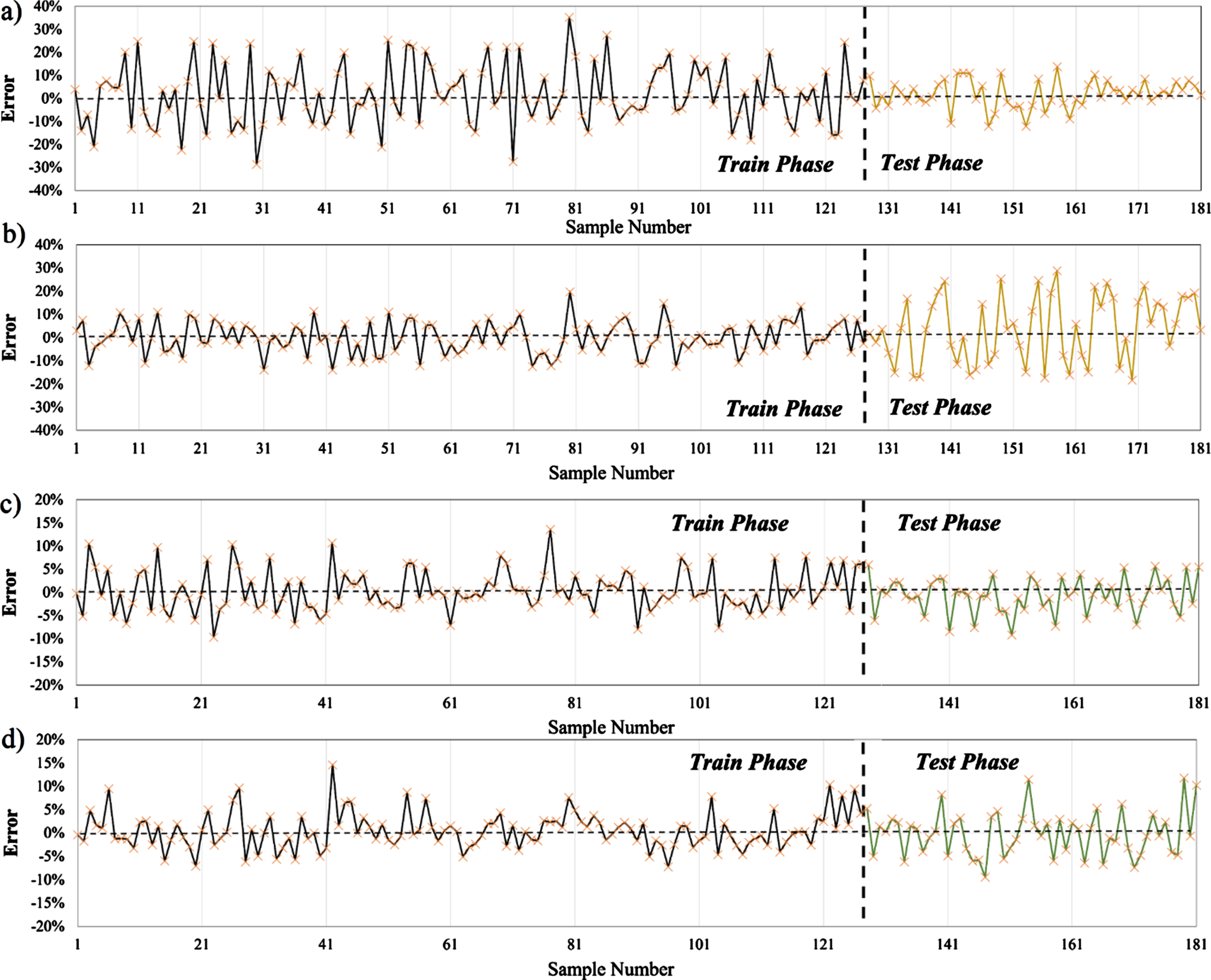
Error percentage rates embedded in CS and SL modeled by: a) WORBF (estimating CS), b) SSRBF (estimating CS), c) WORBF (estimating SL) and d) SSRBF (estimating SL).
For enlarging the mentioned gaps between measured and modeled target values, the errors should be provided to give us a detailed view of modeling process for each sample. In this regard, Fig. 13, indicates the capability of models in overcoming errors in modeling operation. In light of analyzing performance of models in removing errors, considering the error threshold of similar concrete characteristic would help us. With considering this fact in Fig. 13, the CS charts has the error range of –40% to+40% and for SL –20% to+20%. This fact can prove that the error limit of CS is twice SL.
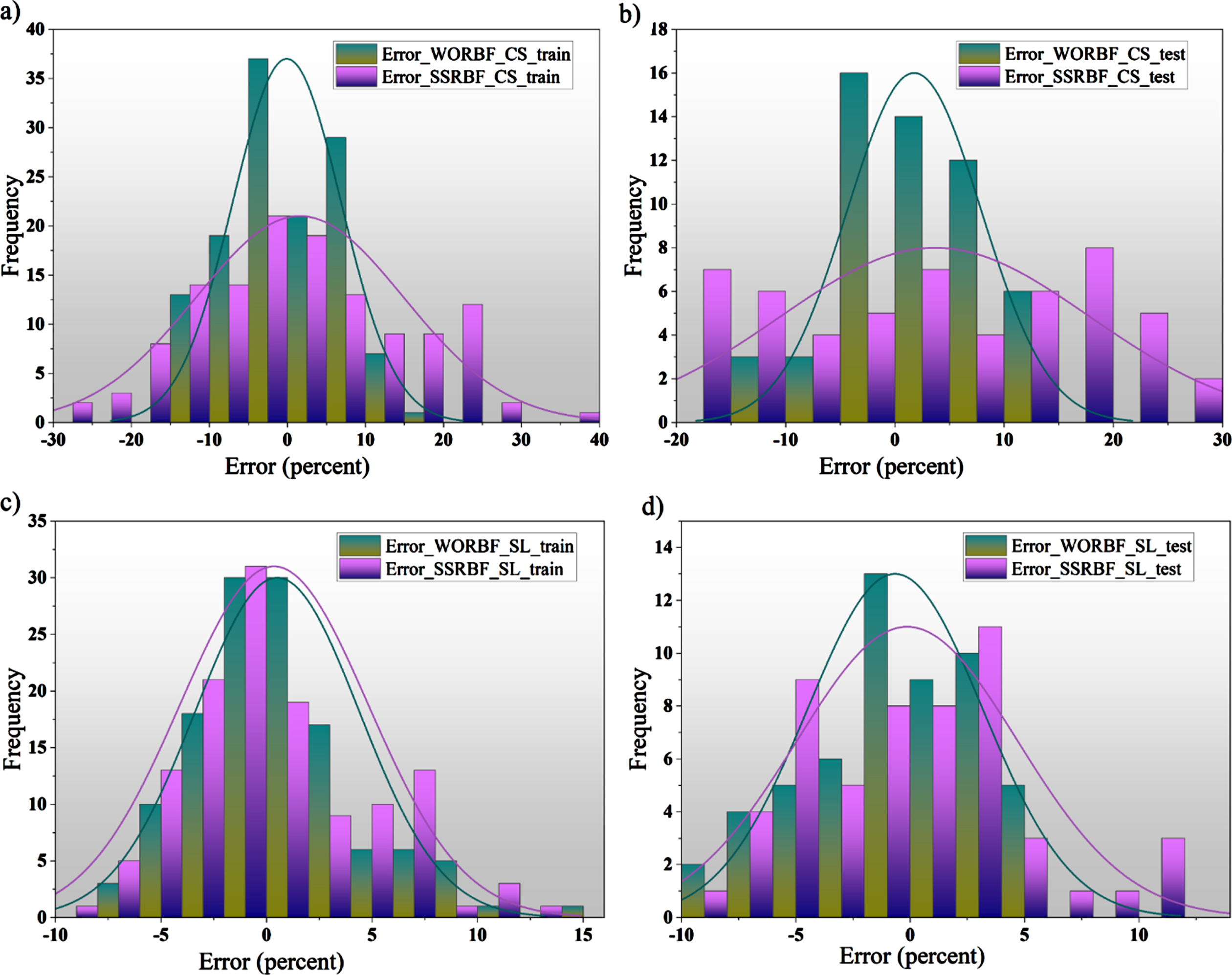
Error histogram plus the normal distribution curves for: a) Training phase in estimating CS, b) Testing phase in estimating CS, c) Training phase in estimating SL, and d) Testing phase in estimating SL.
According to Fig. 13 in estimation of CS, two various trend in data distribution can be found. Firstly, for WORBF, the training phase has led to reduce the errors in testing phase, showing the appreciable training process. While the inverse circumstances can be seen for SSRBF in which the error domain of testing phase is lower than training phase. The high-error HPC samples modeled by WORBF are seen in mixtures #95 with 14.70% error, #117 with 13.4% error, #158 with 13.74% error while similar samples in SSRBF was modeled with 13.17%, 2.94%, 28.89% error. Similar event can be seen in estimation of slump flow diagrams.
Based on Fig. 13(c), the WOA has been successful to train the model RBFNN to generate the SL rates. Because of results that in testing phase the error rates are diminished outstandingly from averagely 2.97% to 3.59%. SSA optimizer also could do better job but in testing phase the error rates went up for the samples that in WORBF had better results.
Distribution of errors are so important that in Fig. 14 using the normal distribution curve of errors for each models can give us the ability of models in dealing with errors. As can be seen from the Figs. 14-a and 14-b, to appraise the CS values, the WOA has minimized the errors near to the zero level in training stage while SSA optimizer has distributed the errors among broadly leading to flattening the normal distribution curve of errors. In opposite state, the normal distribution curve of errors for WORBF is sharpened and resembles to bell. For testing phases, however this story runs true and error distribution of SSRBF do not follow the normal distribution. Nonetheless, in estimation of SL, both models have worked alike compared to CS and even in training phase, the SSA could manage the errors better than WOA. But in testing phase WORBF appears to play better role in controlling errors.
Examining the properties of High-Performance Concrete (HPC) has been a big challenge due to the highly heterogeneous relationships and coherence among several constituents. The employment of some specific additives such as superplasticizer, silica-fume and fly-ash as eco-friendly components in mixtures benefits the concrete to improve its physical features. Although machine learning approaches are utilized broadly to solve problems, employing models solitarily to estimate the mechanical features of concrete in similar researches has caused in reducing the accuracy and lift the cost and complexities of computational networks. Therefore, in this study a Radial Basis Function Neural Network (RBFNN) was developed with two optimization algorithms of Whale Optimization Algorithm (WOA) and Salp Swarm Algorithm (SSA) in order to precisely model the mechanical characteristics of HPC mixtures including compressive strength (CS) and slump (SL). The hybrid models of WORBF and SSRBF could reproduce the SL and CS rates of 181 HPC compounds based on the data of ingredients feeding the models. By generating results in the training phase of modeling CS using WORBF, the correlation index of R2 was calculated 96.9 percent that was 11% more than that of SSRBF. The high-accuracy modeling based on RMSE index was done by WORBF with 3.684 mm (and MPa) for both concrete aspects. On the other hand, the WOA optimizer could tune the RBFNN to reach prediction of CS and SL according to MAE index. In testing phase the minimum rate of MAE was diagnosed for all of models between various stages that 2.77 mm (and MPa) was the minimum rate of error seen in simulations. In addition, based on OBJ indicator encompassing various types of indicators, the SSA was not prosperous compared to WOA. For estimating SL factor WORBF could do better job with the rate of 3.89 that was 139% more than that of SSRBF. Moreover, the WOA minimized the errors near to the zero level in training stage while SSA optimizer distributed the errors among broadly leading to flattening the normal distribution curve of errors. In opposite state, the normal distribution curve of errors for WORBF was sharpened and resembled to the shape of a bell. For testing phases, however error distribution of SSRBF did not follow the normal distribution. Nonetheless, in estimation of SL, both models worked alike compared to CS and even in training phase, the SSA could manage the errors better than WOA. But in testing phase, WORBF appeared to play better role in controlling errors.
To sum up, most of results affirmed that both models were capable to generate the acceptable outcomes while in some cases the WORBF appeared better than SSRBF. Generally, using such methods instead of experimental ways can increase the profitability of researches when using the physical appliances seems costly; especially, using high-accuracy models has enhanced the applicability of smart models in reducing the costs and energy loss and definitely increasing the accuracy of estimation. However, some limitations can be happened for other predictions when employing various dosages of concrete components, or using experimental data having probable error in gauging each constituent to develop a predictive framework with an aim of modeling mechanical features of other concrete mixtures.