
Abstract
The aim of this study is to improve randomized methods for designing a Takagi-Sugeno-Kang (TSK) fuzzy system. A novel adaptive incremental TSK fuzzy system based on stochastic configuration, named stochastic configuration fuzzy system (SCFS), is proposed in this paper. The proposed SCFS determines the appropriate number of fuzzy rules in TSK fuzzy system by incremental learning approach. From the initial system, new fuzzy rules are added incrementally to improve the system performance until the specified performance is achieved. In the process of generation of fuzzy rules, the stochastic configuration supervision mechanism is applied to ensure that the addition of fuzzy rules can continuously improve the performance. The premise parameters of new adding fuzzy rules are randomly assigned adaptively under the supervisory mechanism, and the consequent parameters are evaluated by Moore-Penrose generalized inverse. It has been proved theoretically that the supervisory mechanism can help to ensure the universal approximation of SCFS. The proposed SCFS can reach any predetermined tolerance level when there are enough fuzzy rules, and the training process is finite. A series of synthetic data and benchmark datasets are used to verify SCFS’s performance. According to the experimental results, SCFS achieves satisfactory prediction accuracy compared to other models.
Introduction
In the past few decades, Takagi-Sugeno-Kang (TSK) fuzzy system [1], as one of the most important and popular fuzzy systems, has received more and more attention and has been successfully applied in many different fields, such as data modeling [2], pattern recognition [3], model approximation [4], adaptive control [5], etc. However, as the dimension and scale of the dataset increase, the rule base and the parameters of TSK fuzzy system increase exponentially. How to determine a TSK fuzzy system with appropriate architecture and good learning and generalization performance is a significant research problem.
The task of designing a TSK fuzzy system includes structure recognition and parameters optimization of both fuzzy antecedents and functional consequents. Fuzzy clustering methods [6, 7] have been widely applied for structure recognition, optimization techniques [8, 9], feature selection [10] and back propagation (BP) algorithm are used for parameters optimization.
In the process of using fuzzy clustering methods to determine the system structure, it is a crucial problem to determine an appropriate number of clustering in advance, which determines the number of rules. The performance of fuzzy systems with few rules is poor, while large rules may cause overfitting.
The parameters learning of TSK fuzzy systems can be realized by data-driven techniques similar to artificial neural network training method. Randomized approaches which have great potential in developing fast training algorithms become popular as a result of their good modeling performance and training speed. In [11], The ELM method is applied to optimize the fuzzy system parameters. In [12], a regularization ELM is introduced to randomly select fuzzy layer parameters and to determine neural layer parameters by solving optimization problems in regularization framework. The scope of random parameters is important to the training process of randomized approaches. In [13], IRVFLN’s universal approximation capacity is found to be affected by the scope of random parameters. In [14], stochastic configuration network (SCN) is presented to solve the problem. It ensures universal approximation by assigning random parameters under a supervisory mechanism. Various SCN models [15–17] have been proposed for data modeling to obtain universal approximation. In [18], a complex multidimensional numerical integration method based on SCN is proposed to deal with engineering problems. Deep stacked SCN is presented for data streams modeling in [19]. In [20], SCN’s structural parameters are improved by incorporating the driving amount.
According to current results, determining an appropriate number of fuzzy rules is a critical step in improving fuzzy system approximation. The traditional learning methods of fuzzy system are to set the number of rules in advance. This may affect the approximation ability and generalization ability of fuzzy system. In addition, although the randomized approaches have been used to optimize the parameters of fuzzy system, how to ensure the universal approximation of randomly generated fuzzy systems is still a problem.
Motivated by these facts, in this study an adaptive incremental TSK fuzzy system based on stochastic configuration (SCFS) is proposed. We determine the architecture by an adaptive incremental learning approach and randomly assign the premise parameters with inequality constraints so as to establish a TSK fuzzy system with appropriate fuzzy rules and good approximation capability. The incremental learning approach of SCFS starts with an initial structure and then gradually adds fuzzy rules until predefined termination criteria are met. Obtaining a compact fuzzy system and an appropriate number of fuzzy rules are straightforward. Fuzzy rules are added randomly using a supervisory mechanism which ensures universal approximation. The proposed SCFS is evaluated by a number of popular regression benchmarks and compared with some start-of-the-art approaches. It appears that SCFS is capable of achieving satisfactory performance based on numerical examples.
The rest of paper starts with some preliminaries for TSK Fuzzy system in section 2. The construction of SCFS is introduced in section 3. Section 4 investigates approximation properties of SCFS and section 5 proposes the parameters learning algorithm of SCFS. In section 6, a series of synthetic data and benchmarks datasets are carried out to illustrate the performance of SCFS. Section 7 gives some conclusions.
Preliminaries
TSK fuzzy system is the most popular fuzzy system, and its fuzzy rules have the following form:
The rule R
k
of TSK fuzzy system maps antecedent fuzzy sets (Ak1, ⋯ , A
km
) to consequent function f
k
(x). By sum-product inference, the defuzzified output is written as follows:
Centralized TSK fuzzy system which omit the denominator in (2) is suggested in [21–23] and the output can be simplified into
The consequent function f
k
(x) usually is a polynomial of the input variables. The zeros-order and first-order TSK fuzzy systems are two popular TSK fuzzy system, in which constant and first order polynomial are chosen as consequent function respectively. However, the consequent function can also be other function. In [24], Chebyshev polynomial is used to improve the nonlinear expression ability of the consequent function, which is employed in this study and has the following form:
The construction of SCFS is elaborated in this section. SCFS retains the form (3) of a centralized TSK fuzzy system, but adopts the idea of stochastic configuration to gradually add rules until specified condition is met.
Given a target function
Hence, the output of S
L
0
can be represented as
If ∥e
L
0
∥ fails to reach the tolerance level ɛ, a new fuzzy rule RL0+1 will be added based on a supervisory mechanism
Hence, the output of SL0+1 can be represented as
The incremental learning approach of SCFS, which repeats the above incremental process and gradually adds new rules until the predefined tolerance level ɛ is met, is illustrated in Fig. 1.

The incremental learning approach of SCFS.
The initial system S L 0 with L0 fuzzy rules can either be generated by traditional methods or is a null system. For given target function f, new rules are produced incrementally under a supervisory mechanism for improving the performance of the SCFS until specified performance ɛ is met.
It can be found that different form the traditional fuzzy system which requires a given number of fuzzy rules in advance, SCFS increases rules gradually by incremental learning to obtain a suitable number of rules. And the supervision mechanism of SCFS can ensure universal approximation which is proved in the next section.
In this section, the approximation capability of SCFS will be analyzed theoretically.
Given dataset with inputs
If eL-1 (X) ≥ ɛ, new fuzzy rule R
L
is generated and added to the old SCFS SL-1 to get the new SCFS S
L
with L fuzzy rules. The output and the residual error of the S
L
on dataset {X, Y} can be represented as
The premise parameters c L and σ L of new added rule R L are randomly assigned under inequality constraint.
Then, we will give the first theorem of SCFS and analyze the convergence of the approximation error as the number of rules increases.
where
Since
So, ∥e
L
(X) ∥ 2
Then, the next question is the existence of c L and σ L satisfying the supervisory mechanism (9), which is studied in the following theorem 2.
Thus, we have
On the other hand,
Hence, we have
We notice that
The consequent parameters a L in Theorem 1 are given and remain fixed. This may lead a slow convergence of incremental learning. In fact, there is a recalculation scheme. The consequent parameters are determining by minimizing global residual and recalculating as rule increases. Theorem 3 gives the convergence when the consequent parameters a L are updated by the recalculation scheme.
It is obvious that
Theorem 1 and Theorem 3 have proved the convergence of two kind of parameters learning approach of SCFS. The two approach evaluate consequent parameters by constructing and optimizing schemes, respectively. Note that the performance of the latter is superior to that of the former. Hence, we only give the parameters learning algorithm associated with Theorem 3 here. Generally, the proposed algorithm is composed of the following components. Configuration of premise parameters: Premise parameters c
L
and σ
L
are randomly assigned under the supervisory mechanism. Evaluation of consequent parameters: Evaluating and recalculating the consequent parameters
In the process of configuring the premise parameters, the value ranges of random parameters c
L
and σ
L
are designed as
The supervisory mechanism can be represented as
In the process of evaluating the consequent parameters, the consequent parameters
Thus, the new fuzzy rule R
L
is generated and added to old system SL-1 form a new system S
L
. the residual error of new system S
L
is
As that, the new fuzzy rules are generated gradually under a supervisory mechanism and added to the system until specified performance ɛ is met. In the parameters training algorithm, in order to avoid too long training process and facilitate the control of training process, we set a maximum rules number L max .
The parameters training algorithm for SCFS is summarized as follows:
Parameters training algorithm for SCFS
Given dataset {X, Y}; Set the error tolerance ɛ, the maximum configuration times T, a set of positive numbers ϒ ={ K min : ΔK, : K max } and the maximum number of rules L max .
1. Initial e = Y, L = 0, two null sets P and W.
2. While L < L max and e > ɛ, Do
Stage 1: Premise parameters configuration
3. For K ∈ ϒ
4. For t = 1, ⋯ , T
5. Randomly allocate c L and σ L ;
6. Calculate H L based on Equation (11);
7. If
8. save c L and σ L in W, H L in P;
9. End If
10. End For
11. If W is not empty
12. Find
13. Break and go to step 16;
14. End If
15. End For
Stage 2: Consequent parameters evaluation
16. Compute a(L) based on Equation (13);
17. Compute e based on Equation (14);
18. End while
Return c i , σ i , a i , i = 1, 2, ⋯ , L.
Thus, the proposed parameters training algorithm has completed the designing of SCFS.
We investigate the performance of the proposed SCFS in this section. Compared with the proposed SCFS, MQ [25], ELM [26], IRVFLN [13], SCN [14], ISCN [27], CSSA-SCN [28], BLS [29], FBLS [30], HPFNN [31] and other models are performed. Root mean squares error (RMSE) is adopted to evaluate the prediction accuracy of the proposed SCFS and the selected comparison models. The statistic measure is denoted by
Synthetic data (Syn_1D)
A one-dimensional nonlinear function f1 (x) is considered.
As in [14], training data set consists of 1000 samples uniformly distributed in the interval [0,1], and testing dataset is 300 samples produced from an equally spaced grid on [0, 1].
The parameters are set as follows. Let the degree of Chebyshev polynomial n be 4, the regularization parameter λ be 1e - 10 and the collection of positive constants ϒ be{ 1e3 : 1e3 : 1e4 } in SCFS. Let the predefined maximum configuration times T be 100 in ISCN, SCN, CSSA-SCN and SCFS, the scope of random parameters be [- 1, 1] in IRVFLN and ELM, and the learning rate in MQ be 0.5.
Table 1 compares the training and testing RMSE of the proposed SCFS and other six models, in which L max is maximum rules number or hidden nodes number (from the perspective of neural fuzzy network, each rule corresponds to a hidden node, so we will not distinguish hidden nodes and fuzzy rules below). From the comparison results in Table 1 where the bold items show the best results, it is obvious that the proposed SCFS has the best training performance and testing performance.
RMSE Comparisons on Syn_1D
RMSE Comparisons on Syn_1D
Figure 2 shows the testing performance of the IRVFLN, SCN and SCFS. It can be found that the SCFS has distinctly better generalization ability compared against the IRVFLN and SCN.
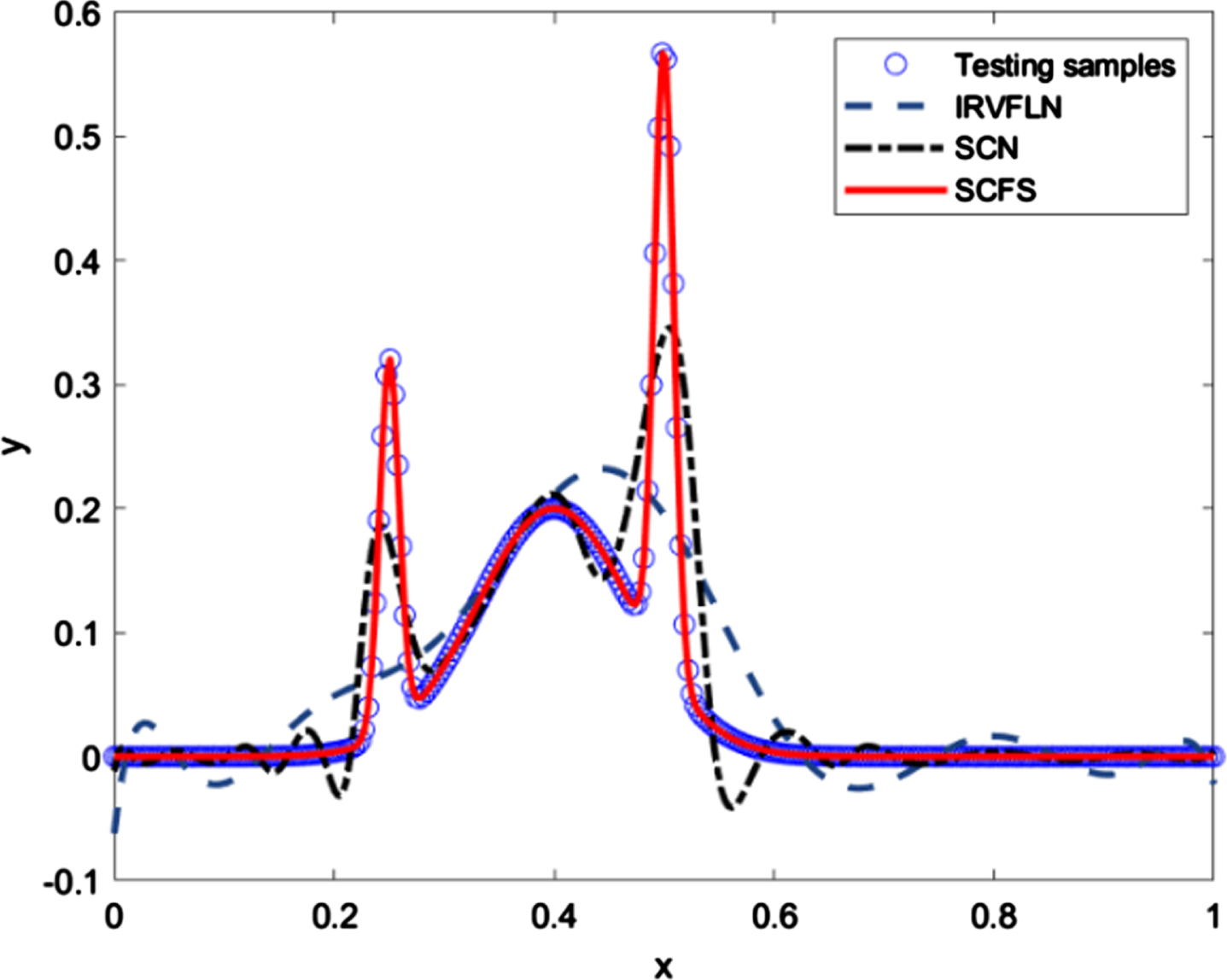
testing performance on Syn_1D when L max = 25.
Table 2 presents the result of efficiency comparisons. It can be found that IRVFL are failed in achieving the expected training tolerances while L max is set as 50 and SCFS requires fewer fuzzy rules than SCN to achieve the expected training tolerances.
Efficiency comparisons under the same error tolerance on Syn_1D
The proposed SCFS uses the incremental learning approach to designing TSK fuzzy system. A common problem with incremental learning process is that it may be very long (maybe infinite if unlucky). In Section 4, we explain this problem from theoretically two aspects: the existence of random parameters and sufficient conditions to achieve a given precision. The supervision mechanism of SCFS ensures that the incremental learning process of SCFS is finite. The results in Table 2 also explain this problem from the perspective of simulation experiments.
Figure 3 shows the comparisons of convergence rates for testing data among the proposed SCFS, SCN and IRVFL. It can be found that SCFS has the best convergence performance. That is, SCFS can achieve satisfactory performance with less fuzzy rules.
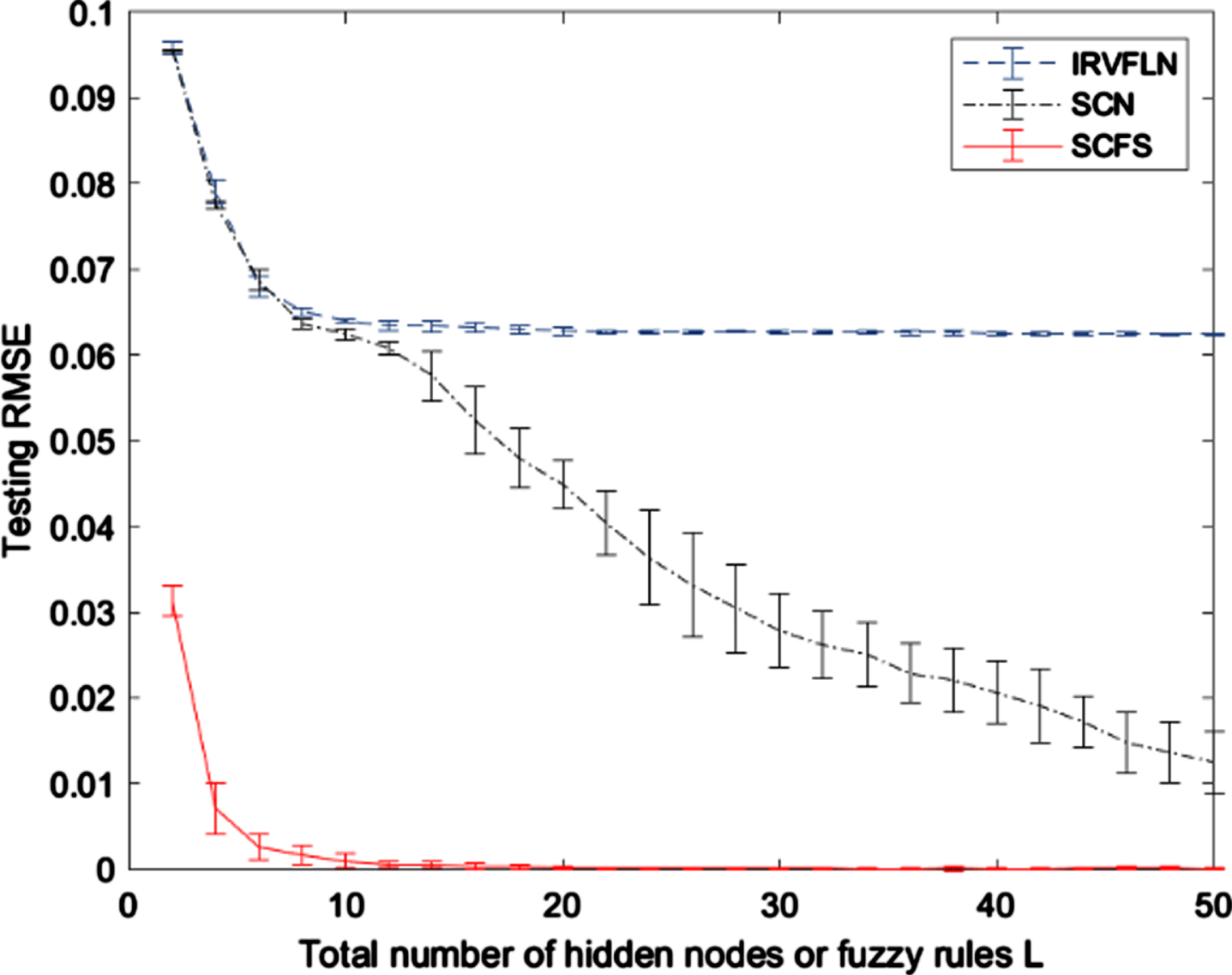
Testing RMSE with 50 additive nodes or rules.
The Stock dataset from the KEEL (http://keel.es/) dataset repository contains 950 daily stock prices of ten aerospace companies. 75% of the samples are randomly chosen as training dataset and the rest as testing dataset.
The parameters are set as follows. Let the degree of Chebyshev polynomial n be 3, the regularization parameter λ be 0.1 and the collection of positive constants ϒ be{ 1, 100, 1e4, 1e6, 1e8 } in SCFS. Let the maximum configuration times T be 100 in ISCN, SCN, CSSA-SCN and SCFS, the scope of random parameters (w, b) be [- 1, 1] in BLS andFBLS.
Table 3 compares the training and testing RMSE of the proposed SCFS and other five models on Stock. In Table 3, the bold items show the best RMSE. It is obvious that SCFS performs best in both training and testing performance. This shows that the proposed SCFS performs well not only on synthetic data, but also on real datasets
RMSE Comparisons on Stock
RMSE Comparisons on Stock
Figure 4–7 shows the performance comparison between SCFS with different values of paraments n and λ. We can see that although a bigger degree of Chebyshev polynomial n and a smaller regularization parameter λ contribute to better training performance, but on testing performance it is not necessarily and it may occur overfitting. The selection of appropriate parameters can improve the performance of the model. Grid search for the parameters in SCFS and other models to get better performance is used in this paper.
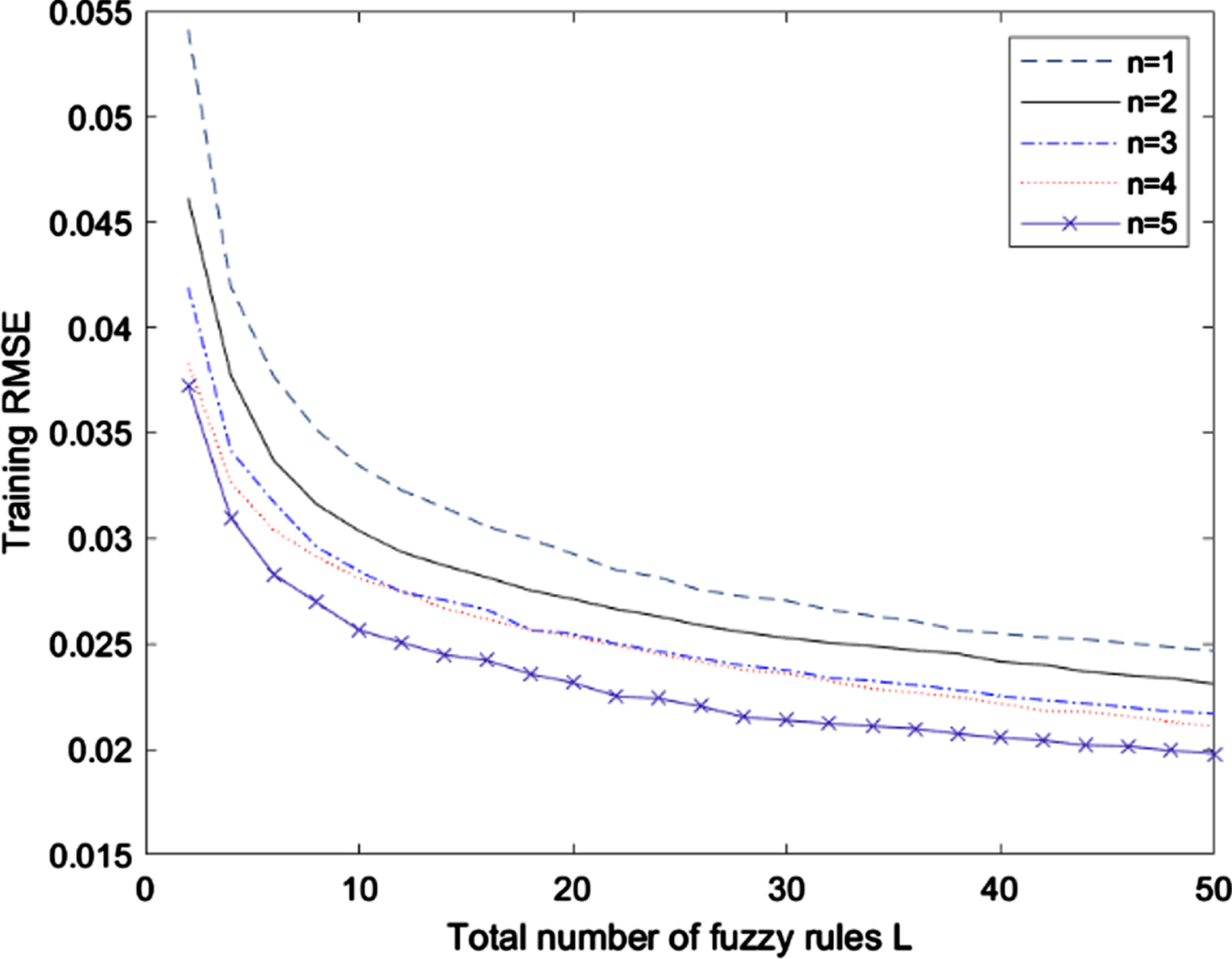
Training RMSE of SCFS with different n.
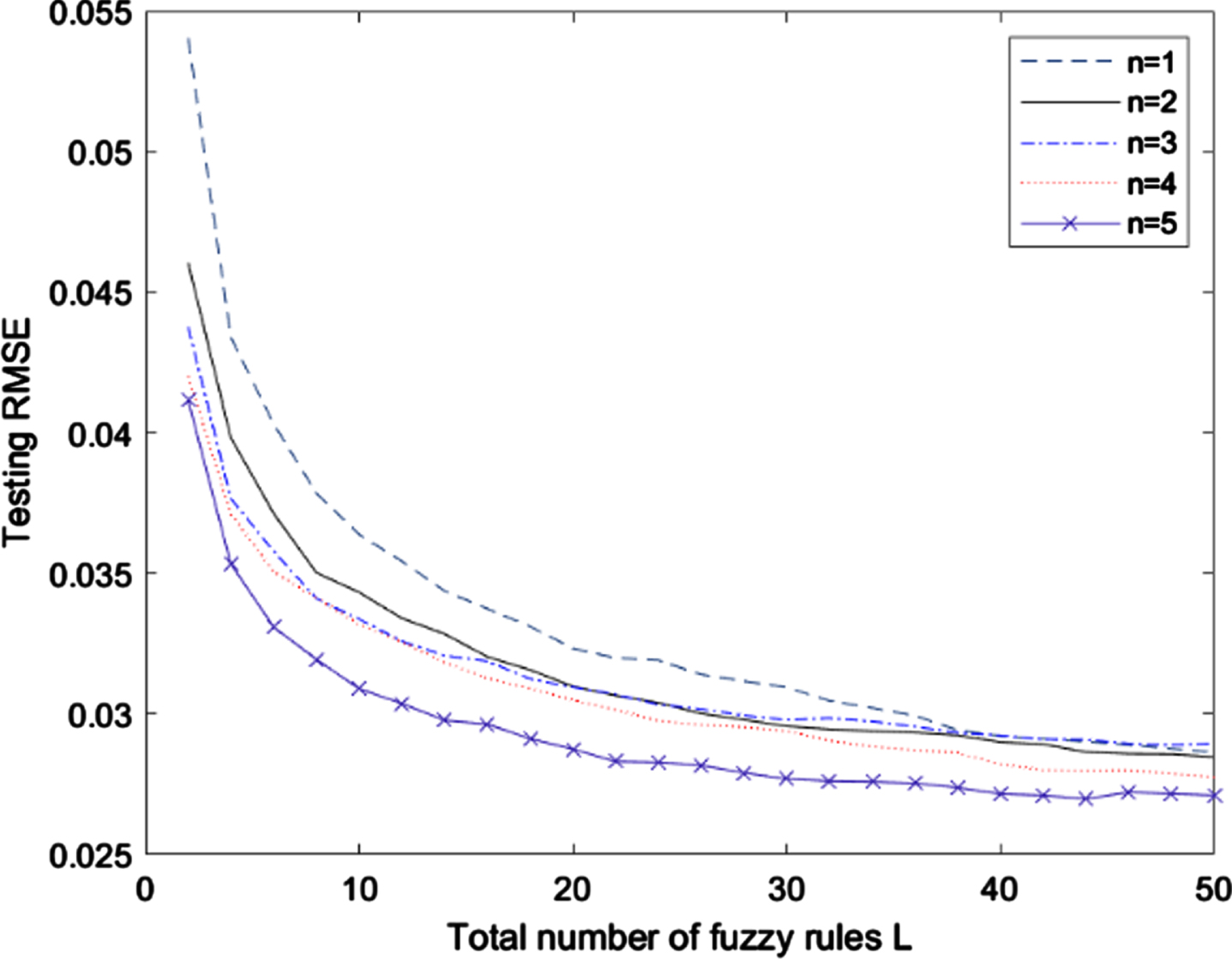
Testing RMSE of SCFS with different n.
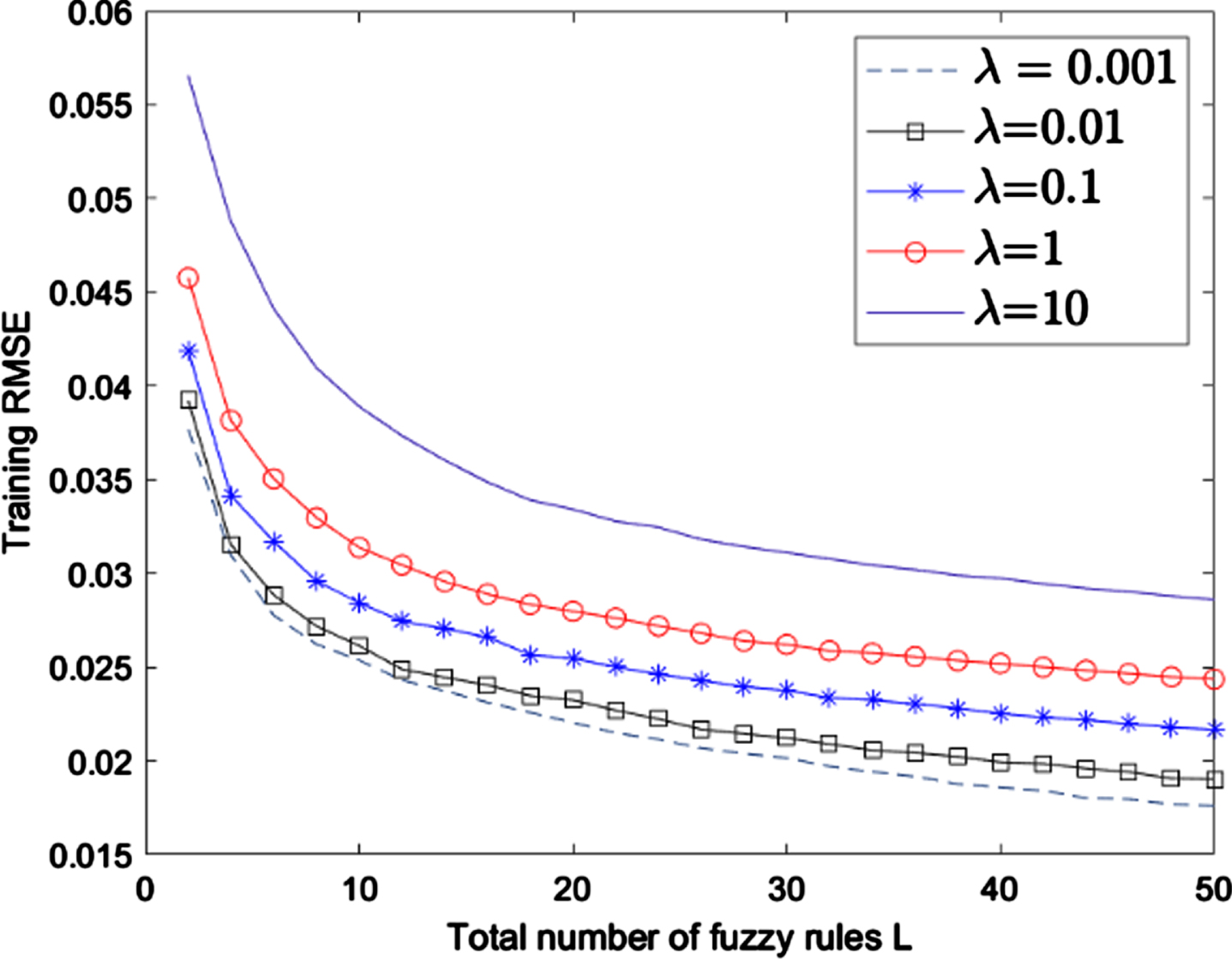
Training RMSE of SCFS with different λ.
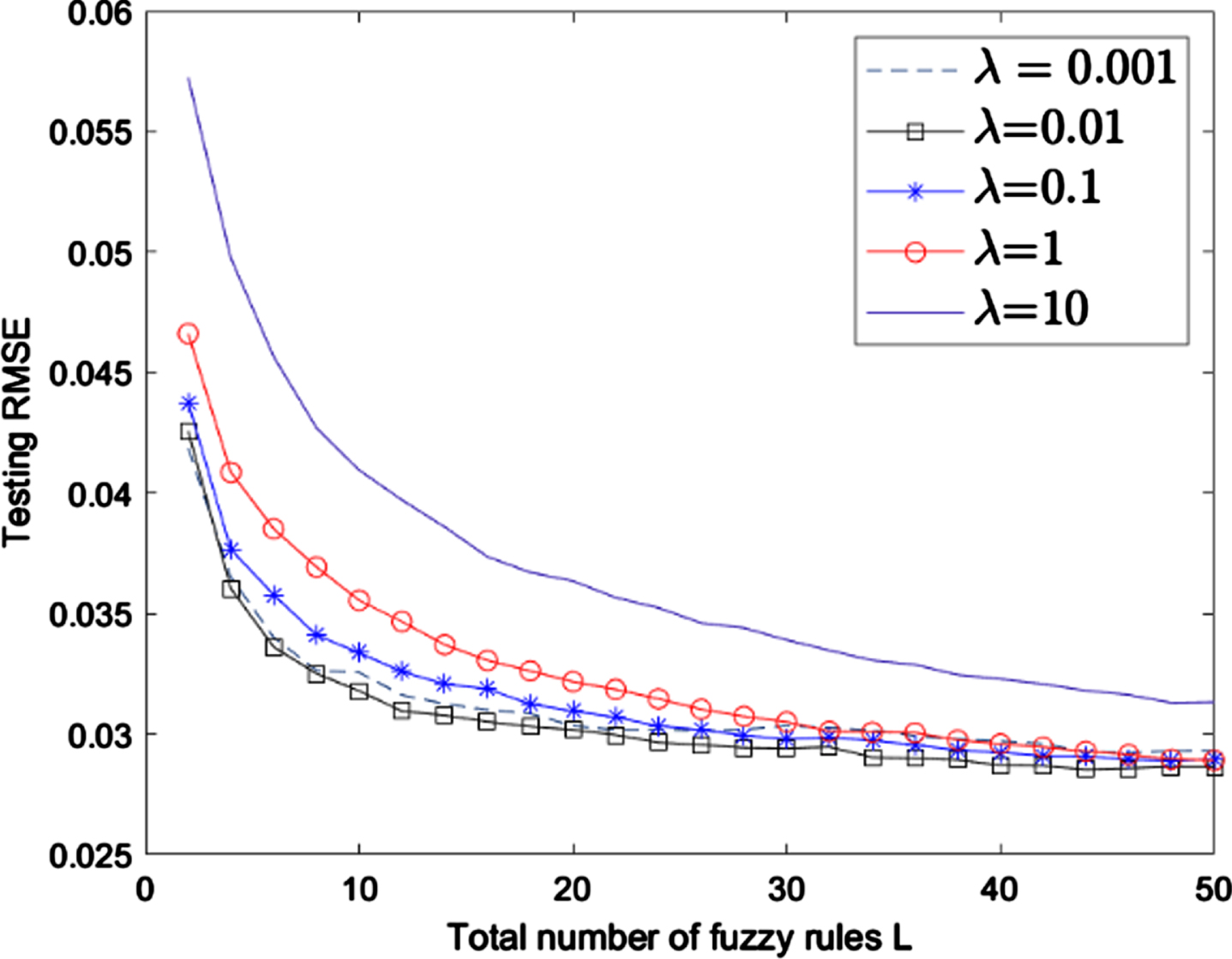
Testing RMSE of SCFS with different λ.
We next train 10 algorithms (including the proposed SCFS) with 20 datasets from UCI and KEEL repositories and perform statistical analysis to further evaluate the proposed SCFS. Table 4 shows the detail of the 20 datasets, including the abbreviation name which will be used in subsequent tables.
Information about the 20 open datasets
Information about the 20 open datasets
The testing RMSE comparisons of the proposed SCFS with other 9 algorithms, such as MLP, SVR, LR, KNN, HPFNN [31], SCN [14], BLS [29], FBLS [30] and SCBLS [32] are listed in Table 5. The results of HPFNN, MLP, SVR, LR, and KNN are borrowed from [31], and the results of FBLS, BLS, SCN, SCBLS are the optimal test RMSE obtained by simulation on the dataset using the source code. The regularization parameter λ and the degree of Chebyshev polynomial n are selected from {1e-3, 1e-2, 1e-1} and {1, 2, 3, 4} respectively. Let the collection of positive constants ϒ be{ 1e3 : 1e3 : 1e4 } and the predefined maximum configuration times T be 100.
Testing RMSE Comparisons of 10 algorithms on 20 open datasets
The bold items in Table 5 are the minimum testing RMSE of the 10 algorithms on each dataset. We can find that our SCFS gets the minimum testing RMSE on the most data sets than the other 9 algorithms. The proposed SCFS has the best generalization ability and gets the minimum on 9 datasets. The second is HPFNN which gets the minimum on 7 datasets, but the difference is small. Hence, we perform statistical tests below to show that the difference between the proposed SCFS and HPFNN is significant.
We divide the 9 comparison models into two groups according to whether they are randomized methods: (1) MLP, SVR, LR, and KNN; and (2) HPFNN, SCBLS, FBLS, BLS and SCN.
First, the Friedman test is adopted to each group for analyzing the ranking of these models. Table 6 and Table 7 display the results of the Friedman test of each group. It can be seen that the rankings of SCFS in two group are both first. What’s more, the two p-values are both less than 0.1, they demonstrate that the ranking are significantly different.
Result of Friedman tests among SCFS, MLP, SVR, LR, and KNN
Result of Friedman tests among SCFS, MLP, SVR, LR, and KNN
Second, the Holm post-hoc test is applied to compare the proposed SCFS with other models by one vs one. The results are listed in Tables 8 and 9. if the significance level α is large than the adjusted p-value, we reject the null hypothesis H0 that the comparative two models have no significant difference. It means there are significant differences. We can find that the proposed SCFS are significantly better than SVR, KNN, LR, MLP, SCBLS, FBLS, BLS and SCN. And from Table 9, we also can see the average rankings of SCFS and HPFNN have significantly differences. Hence, compared with other 9 models, the proposed SCFS has good generalizationperformance.
Result of Holm test for SCFS vs MLP, SVR, LR, and KNN with α = 0.1
Result of Holm test for SCFS vs SCN, BLS, FBLS, SCBLS and HPFNN with α = 0.1
This paper develops SCFS, a kind of adaptive incremental TSK fuzzy system based on stochastic configuration, to improve randomized methods for designing fuzzy system. The proposed SCFS determines the appropriate number of fuzzy rules in TSK fuzzy system by incremental learning approach, which starts from an initial system, and gradually adds randomly generated fuzzy rules to improve the system performance until the specified performance is achieved. The premise parameters of new adding fuzzy rules are randomly assigned under the supervisory mechanism to ensure the continuous improvement of system performance. The universal approximation property and the convergence of approximation error of SCFS have been proved theoretically in Section 4.
Hence, the proposed SCFS has the advantages of adaptive and fast modeling of randomized methods and can guarantee good approximation ability. We compare the performance of the proposed SCFS with the other 14 models on a series of synthetic data and benchmark datasets. The experimental results and statistical analyses show that the proposed SCFS is significantly outperform than other methods in terms of both approximation and generalization performance.
In the future, we can combine broad learning system with SCFS to further improve the approximation performance and training speed of the fuzzy system by referring to the characteristics of broad learning system, such as fast training and strong nonlinear representation ability. In addition, the improvement of the interpretability of fuzzy system and the integration of intelligence optimization algorithm [33–35] are also interesting.
Footnotes
Acknowledgments
This work is supported by the National Key Research and Development Program of China (2018AAA0100300), the Fundamental Research Funds for the Central Universities (DUT22YG227) and the National Natural Science Foundation (NNSF) of China (12071056, 61773088).