
Abstract
The spectrum scarcity problem in today’s wireless communication network is addressed through the use of a cognitive radio network (CRN). Detection in the spectrum is made easier by cooperative spectrum sensing (CSS), which is a tool developed by the military. The fusion centre receives the sensing information from each secondary user and uses it to make a global conclusion about the presence of the principal user. Literature has offered several different methods for decision making that lack scalability and robustness. CSS censoring is inspected in the attendance of faded settings in the current study. Rayleigh fading, which affects reporting channels (R), is examined in detail. Multiple antennae and an energy detector (ED) are used by each secondary user (SU). A selection combiner (SC) combines the ED outputs with signals from the primary user (PU), which are established by several antennas on SU, before the joint signal is utilised to make a local result. SUs are expurgated at the fusion centre (FC) using a hybrid Support Vector Machine (SVM) that significantly improves detection performance and reduces the number of false positives. With a minimum false alarm probability of 0.1, error rate of 0.04, spectrum utilization of 99%, throughput of 2.9kbps and accuracy of 99%, proposed model attains better performance than standard SVM and Artificial Neural Network (ANN) models.
Keywords
Introduction
In order to keep up with the changing demands and needs of people, wireless communication technologies are always evolving and improving. It was necessary to address the issue of spectrum scarcity due to the rise in popularity of wireless applications and services. It has been revealed that licenced bands are not utilised at a rate of up to 90% by the US telecommunications body [1], it is the Federal Communications Commission (FCC) (FCC). Findings were made public in the FCC’s report on spectrum efficiency, “FCC Account of the Spectrum Efficiency Working Group.” Spectrum bands that are currently underutilised or perhaps completely unutilized have been studied extensively in recent years. Mitola’s cognitive radio concept is the most well-known in the field [2].
Secondarily, secondary users (SUs) can only access CR networks through opportunistic usage of unused spectrum slots that are not claimed by main users (PUs). The result is that they need to be able to detect the various spectral bands throughout time [3]. It is then imperative that the SUs be evacuated as soon as the PU reenters the bands in order to minimise unwanted interference. For the SUs, another approach requires that their predefined interference temperature be maintained in order to coexist with the PU in licenced bands [4]. In order to ensure the PU’s QoS, SUs always transmit information at a reduced power level [4]. This dramatically improves spectrum efficiency. Spectrum sensing is an significant aspect of CR [5–7]. Multi-path fading, and the near–far effect all have the potential to compromise spectrum sensing results in a real-world wireless communication environment. Spectrum sensing (CSS) has evolved as an active way to ensure that many SUs work together to detect the various bands of the spectrum. Final decisions are made by the fusion centre (FC) based on the information providing by the SUs [8].
Local information fusion can be separated into two categories. In the first approach, each SU takes a local decision and intelligences the outcomes via 1-bit data, where ’1’ signifies presence and ’0’ denotes absence of the PU [9, 10]. Rules like “OR,” “AND,” and “MAJORITY” are used to come to a conclusion in the final choice. With Soft-decision detection [11, 12], which is more expensive for local transmission bands than 1-bit hard decision detection, each SU sends the sensing data to the FC, It then generates a global test fact by integrating all of the local sensing info together. A compromise between sensing performance and band cost is therefore difficult to find. Hybrid SVMs are employed in this study to evaluate local information fusion (GL-SVM). Four antennas are employed for sensing in the secondary user prediction. For the remainder of the document, the following structure is used: In Section 3, a system model with an explanation of the proposed GL-SVM is mentioned in Section 2, which also includes related research. Section 4 deliberates the testing of the suggested model with an existing technique, and Section 5 concludes the study.
Related works
IEDs in a CSS system can only be evaluated if the S-channel is also a Rayleigh, or Rician faded and R is perfect, as in [13] and [14]. While this is true in [13, 14], it isn’t taken into account in [15–17]. The S- and R-channels are both faded in the current work (Hoyt, Rayleigh, Rician). Using threshold-based filtering, it is possible to halt transmission over severely fading R-channels. For Rayleigh [15] and Hoyt [16] fading, the presentation of CSS with threshold-based editing of CEDs is examined. At FC, IED under the influence of Rayleigh fading is examined in [17], which examines the effects of these logic rules: OR, AND, and majority-logic fusion. When OR-logic rules are used, the overall error probability is higher than the error likelihood with logic fusion for many CR users, according to the findings [18] So we set about creating analytical and simulation frameworks for energy-constrained cognitive radio networks that use censoring with thresholds in Rayleigh, fading channels. Several fading models have been devised contingent on the specific propagation situation and the fundamental communiqué scenario.
Simulating an environment with a lot of reproduced and dispersed waves, Rayleigh distribution is employed. However, the set of reproduced and dispersed waves is conquered by one strong constituent, which is why Nakagami-n is usually used to depict Rayleigh fading channels. [19]. The Nakagami-q distribution, which spans the Gaussian. For strong ionospheric scintillation in satellite links, Hoyt’s distribution is typically utilised [20, 21]. There is an examination of data derived from separate homogeneous Bernoulli likelihood mass functions in [22] for situations where the alternative hypothesis’ success probabilities are unknown. An equation for the pmf for variables is found in [23] and labels the number of successful trials in a series when the individual success probabilities change between trials. Furthermore, its compensations in footings of speed, installation and ease of examination are also covered in this article. A wireless sensor network (WSN) is described in [24–26].
Wanlu Lei et al., [27], proposes an in-depth enhancement study model to realize real-time spectrum assignment using the mathematical terms of mixed integers and nonlinear programming. Rodney Martinez Alonso et al. [28] have proposed a dynamic management algorithm that aims to improve the spectrum utilization of units. Prabhat Thakur et al. [29], advises on potential questions related to random channel perception using the revised and improved electoral approach. Varun et al., [30], call for implementation of an intelligent machine learning system to improve prediction accuracy for channel assortment.
Hurmat Ali Shah et al., [31] an efficient spectrum-sharing approach based on predicted machine learning. This predictive technology learns the current state of the primary user from a spectral context. Sensitivity details are kept in the appropriate categories, and then the current sensitivity level is divided into such categories. According to the classification results, the primary user is recognized as present or absent. The options identified by the FC were combined to implement the final solution using a new decision-making technique that takes into account the reliability of CRN users.
Koushik A.M et al., [32] develop a learning-based transmission spectrum to explore whether a channel with error rate in the datagram is inactive. When learning checks are moved from the Q table to the expert node, the boost takes more time to define the learning channel [20].
Goli Sai Sumith et al [33] projected a decision-making to optimize the optimal channel for delivery, which would be comparable to and superior to the existing multi-attribute decision-making (MADM) methods. This algorithm gives a high effect when the PU power is high when using the plot against static distortion. In both cases, the algorithm selects the same channel.
Dr. Ruby et al., [34] Research primarily focuses on spectrum distribution and migration selection. The problem of interference often occurs in PU and SU. It includes an intelligent method for spectrum allocation and relay selection to increase efficiency and signal-to-noise ratio (SNR). A forward based random paging selection scheme is used to select the best solution, determine the free space, create an efficient SU connection, and combine it with PSO technology. Zahra Beheshti [35] discusses the S-shaped transport function of BPSO, which is used to solve the problem of local. This algorithm increases performance efficiency and speed of collection.
SP Rajamohan and K. Umamageswari [36] influences the hybrid approach of the IPBSO concept and promotes its products based on high demand rating. This process was created to provide a credible advantage subcommittee. Duplicate reviews were identified and classification accuracy was found to be better.
Sha-sha Guo et al. Al., [37] obtainable the binary Search Location 00 and 10. There are some issues with local and global optimism. So the Z-shaped transfer function of BPSO was implemented and tested with several definitions to avoid this problem. The effect of this transmission process is to improve its accuracy and speed.
Shanidul Hoque et al. [38] Comes with M/G/1 sequencing to reduce Total Service Time (TST) for the seasoned user and to provide for Total Delivery Delay (CHD) during a SU transaction. This has been proposed using fixed, variable and random spectrum transmission. Explore PU performance and cache size based on delays.
Anastassia Gharib et al. [39] discussed about multi-band cooperative spectrum sensing to support secondary users to access the spectrum. The presented approach divides the sensing tasks based on the secondary user’s residual energy, capability, and channel conditions. For each channel, a leader has been selected by formulating the scenario into an optimization problem. Also, the presented approach includes new secondary users in the sensing process and assigns multiple channels with minimized energy consumption.
Ahmed et al. [40] presented a cooperative spectrum sensing model for cognitive radio networks based on Maximum A Posteriori estimation. The presented approach considers the secondary users as sensing nodes and gets individual decisions about the primary user occupancy status. The decisions are received by the fusion centre and posteriori estimations makes final decision which defines the primary user occupancy. Minimized interference and improved detection were achieved by the presented model compared to existing approaches.
Shunchao et al. [41] presented a clustering algorithm for cooperative spectrum sensing in cognitive radio networks. The presented approach includes k-medoids and mean shift algorithm to avoid fraudulent sensing data. The sensing status is transferred as a local energy vector to the fusion center where all the energy vectors are fused for further process. The presented clustering-based global decision model enhances the robustness of the sensing process compared to traditional approaches.
Mehran et al. [42] presented a soft decision algorithm for cooperative spectrum sensing in cognitive radio networks. The presented approach initially takes soft decision based on sensor measurements. Further a novel fast soft decision is presented based on machine learning algorithms. The decision boundaries are used to classify the power spectral density measurement vectors. The final decision function includes power spectral density of sensors to obtain faster solutions. Improved detection probability, less training time are attained by the presented model which is better than linear support vector machine based approach.
System model
The proposed model is portrayed in Fig. 1. A secondary FC and a PU round out the setup. PU and FC are expected to have a single transmit/receive antenna, but each SU has M receive antennas, an ED, and a solitary transmit antenna, according to our assumptions. The R-channel is used by all SUs to communicate their sensor data to the FC. Furthermore, each SU gets M antennae’s signal and processes it with M-eds for each of its antennas. SC is used to integrate the energy values at the production of the EDs right before making important decisions.
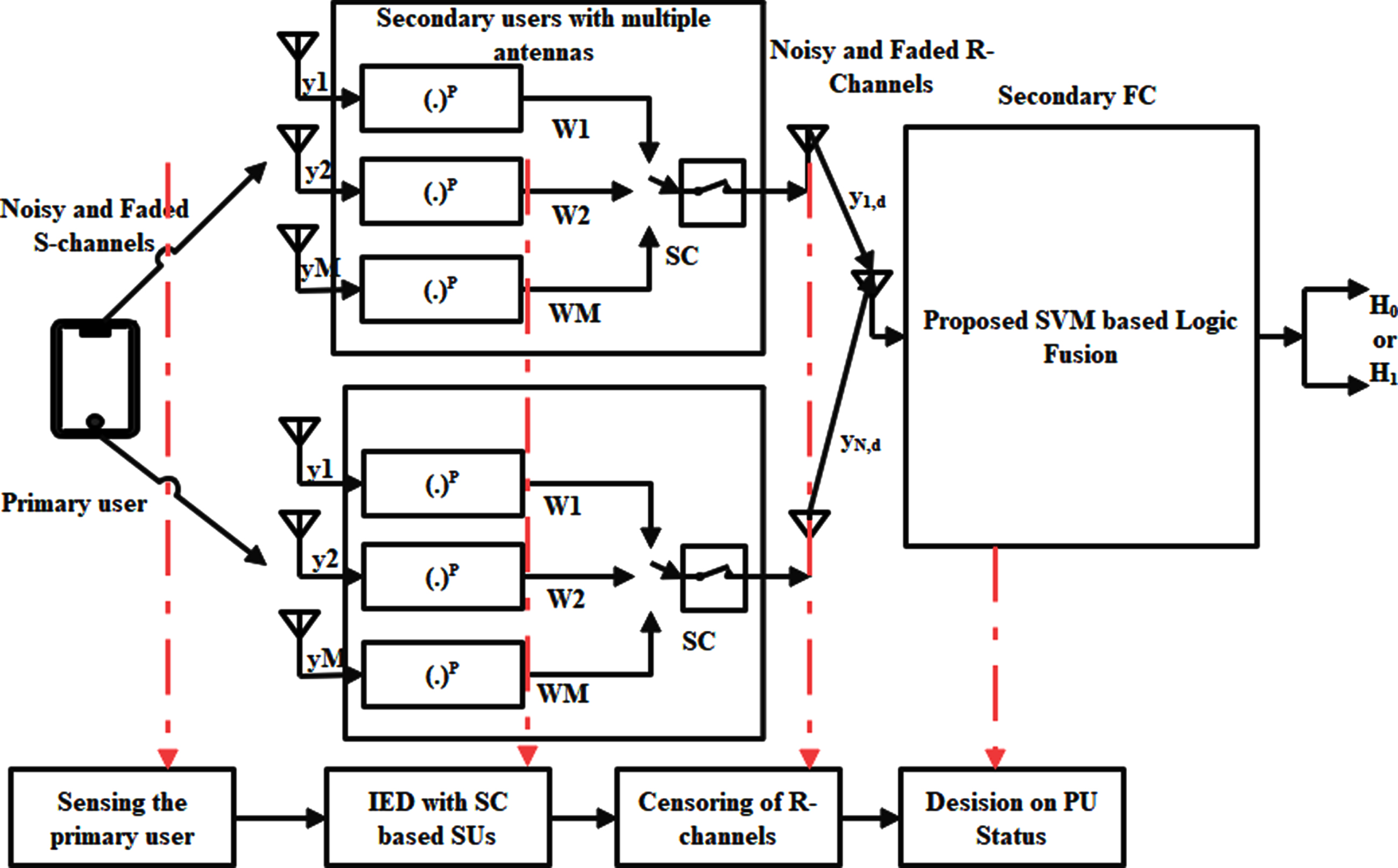
CSS with censoring.
Assuming that all SUs have the same value of (the local detection threshold), the highest is initially designated and associated with a local detection threshold, indicated as, before a hard local judgement on the PU status is made. There are two possibilities for R-channel sound: perfect (no censorship). A noisy-Rayleigh faded censored S- and R-channels are both present in the presence of censoring.
The - i-th antenna (i = 1, … . M) at respectively SU can be uttered as:
The PU is assumed to be the source of a s (n) unidentified signal with energy E s n
i
in this scenario. a complex with a circular symmetry With zero mean symmetric variance, Gaussian random variables can be characterised as complex random variables. Fading considered to be independent and identically distributed [9]. It’s a given that that I and {h
i
} are distinct. The i - th antenna at each SU has a decision variable, W
i
, which is used to decide if the PU is current or not: [43–46]:
For example, the detection threshold
In a fading situation, P f is the same. As a result, it will not be revisited.
In a fading situation, P f is the same because there is no PU signal. As a result, it will not be revisited.
To find λ
opt
, a first order partial derivative of
No prior knowledge of the source signal is required to utilise ED as the most commonly used algorithm. So, these are the major arguments for utilising the single-user technique that we described earlier.
It is possible to represent each SU’s signal as a binary hypothesis problem:
The existence or absenteeism of a PU signal can be detected by each SU. If Z is greater than the threshold, PU exists; else, it does not exist. Chance of Pm, and probability of false alarm (Pfa) are three major performance evaluation factors that can be used to measure system performance (Pf). They can be expressed mathematically as follows:
A cooperative network of M units, where K users engage in the sensing process, is studied. The signal received at FC by kth SU should be referred to as:
When a fusion rule is utilised, the separate local one-bit judgments are merged via FC. To aid in global decision-making, there are many MSUs (k) that have different variations of the fusion rule (). Classification and expression of the most often used fusion rules:
In a cooperative context, the performance evaluation parameters can be expressed as follows:
In this research work, hybrid SVM that consists of Gaussian SVM and Lagrangian SVM (GL-SVM) is used and Fig. 2 shows the flow of projected GL-SVM.
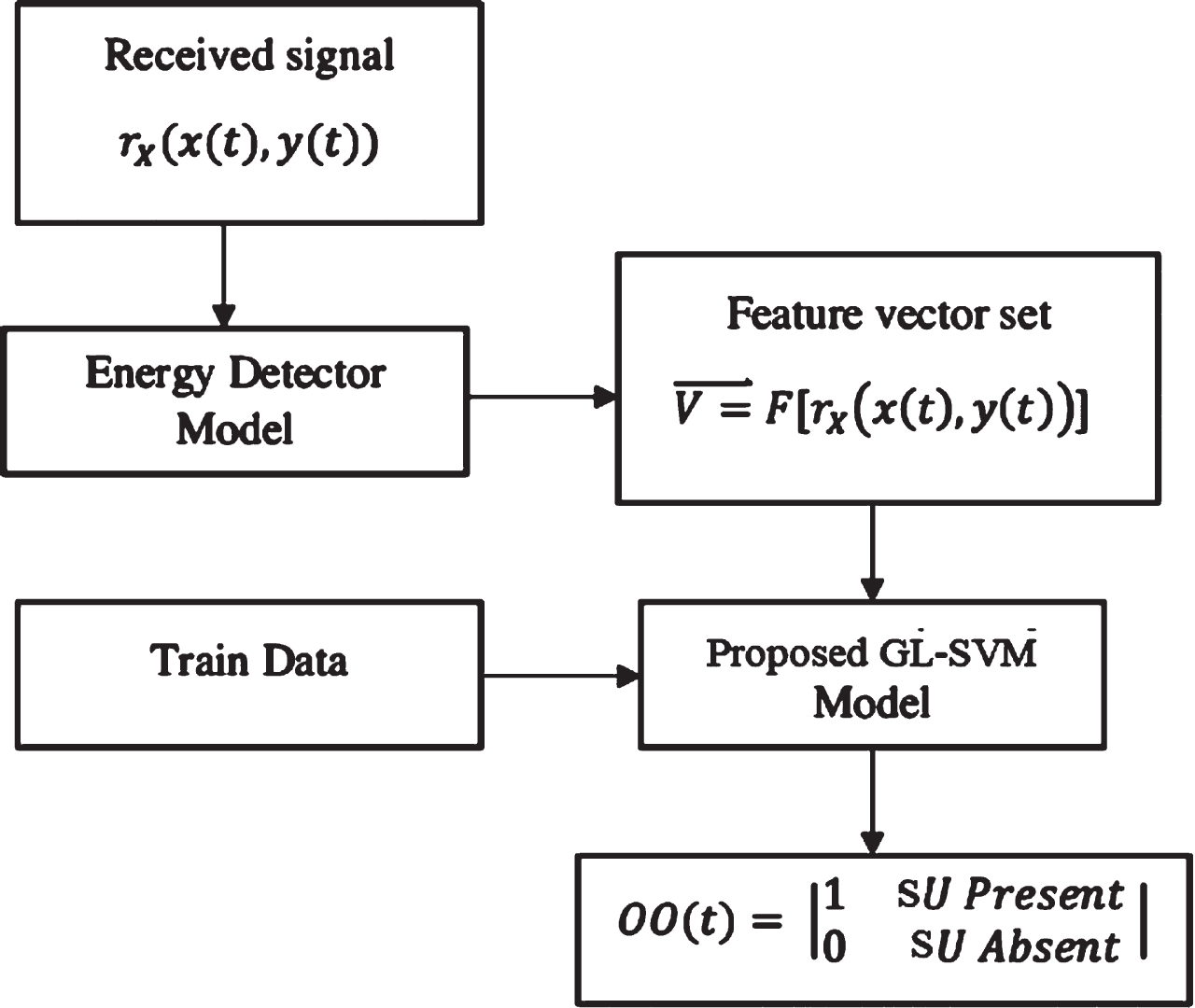
Workflow of proposed GL-SVM.
The features are extracted from the sensing channel by using conventional energy detector model and fed into the proposed GL-SVM model. When compared with cyclo and matched filter, the reason for choosing the energy detector is simplicity in construction and provides accurate classification, while using GL-SVM. In this way, the proposed model differs from the traditional SVM which enhances the detection accuracy. Further to improve the detection accuracy the proposed model uses double phase heterogeneous kernel that yield weights from the investigation of the train and test data.
The train data is derived from the power signal, while test data sequence is used from the received energy signal statistics. OR fusion rule is used in the weight combination process so as to assist in an efficient cooperative sensing strategy. The essence behind the utilization of two kernels is to maximize the hyperplane margin that provides a fine separation between two decisions related to presence or absence of SU in the sensed signal. The maximization function is obtained as:
Where x represents the set of data points on the 2D space. Based on the above Equation, the spectrum sensing hypothesis get transformed into
The Equation (31) represents the optimal hyperplane that needs an ideal classification. Hence, the value taken by hyperplane depends on the preciseness of H
M
which for an ideal condition is formulated as
The objective function for SVM is denoted as O F M , the learning rate is presented as β and error incurred in classification is given as E err . If classification is not accurate or precise, E err ≠ 0. GL-SVM is used to minimize these classification error, where the application of LSVM and GSVM to the proposed spectrum sensing problem, the solution is formulated as:
The support vectors are x
T
. The weights derived from both kernels after processing on that, feature vector are fused using OR rules to identify whether the SU is present or absent as:
Finally, the proposed GL-SVM identify the SU with efficient manner.
In this unit, the projected GL-SVM is tested with standard ANN, SVM and other techniques. The project is mainly focused on secondary users, hence it is higher than primary users. Four antennas are used and remaining simulation parameters are explained in Table 1.
Simulation strictures and its description
Simulation strictures and its description
Initially, the likelihood of false alarm is considered to test the efficiency of proposed model and graphical representation is provided in Fig. 3.
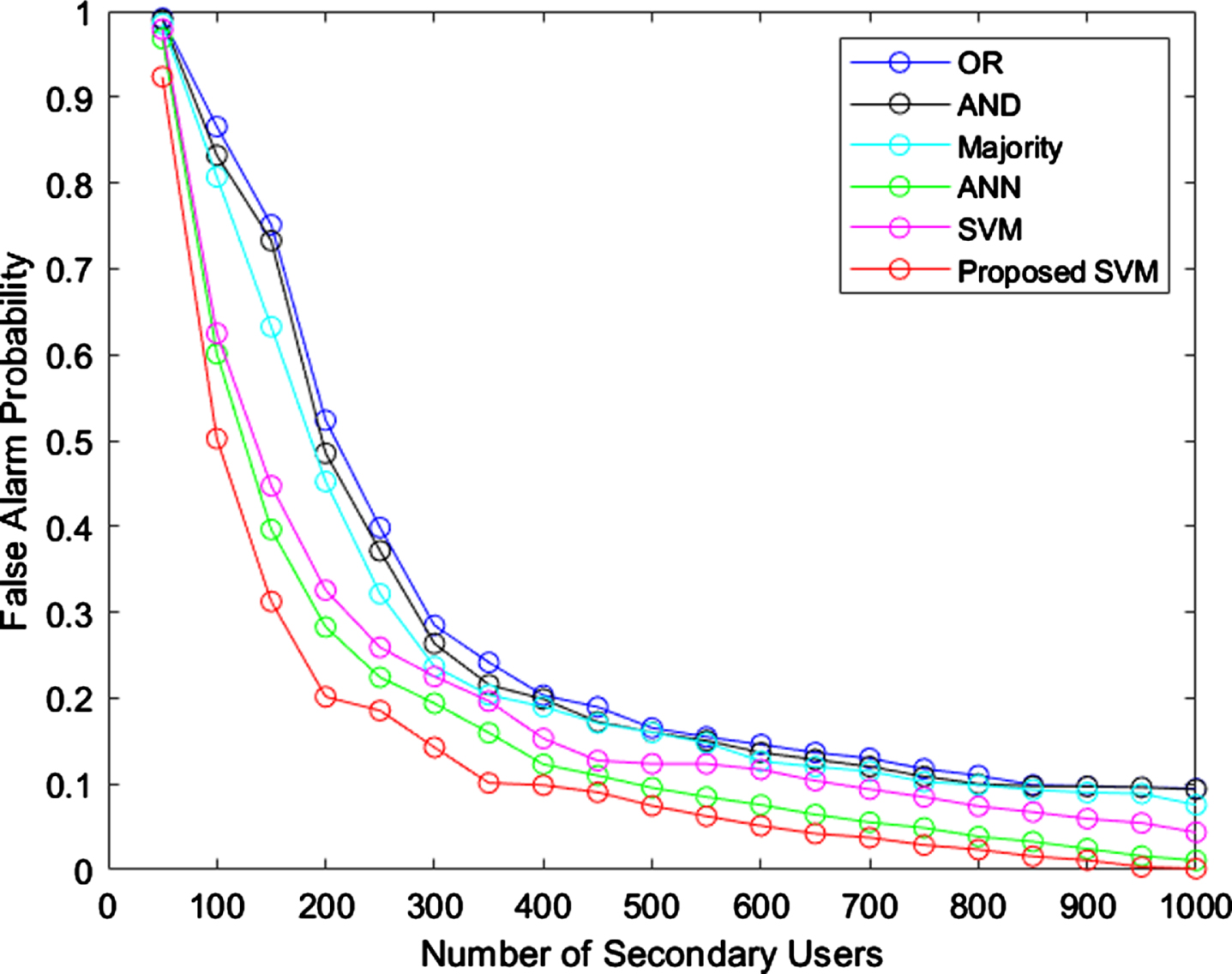
False Alarm Probability (FAP).
From the above figure, it is clearly proved that the proposed SVM has less FAP than various existing rules such as OR, AND, Majority, ANN and standard SVM. When the secondary users are 350, the FAP of proposed model is 0.1 and OR has 0.3FAP. When the number of users upsurges, the FAP of proposed model gets decreased. The graphical representation of proposed model with other rules in terms of error rate is shown in Fig. 4.
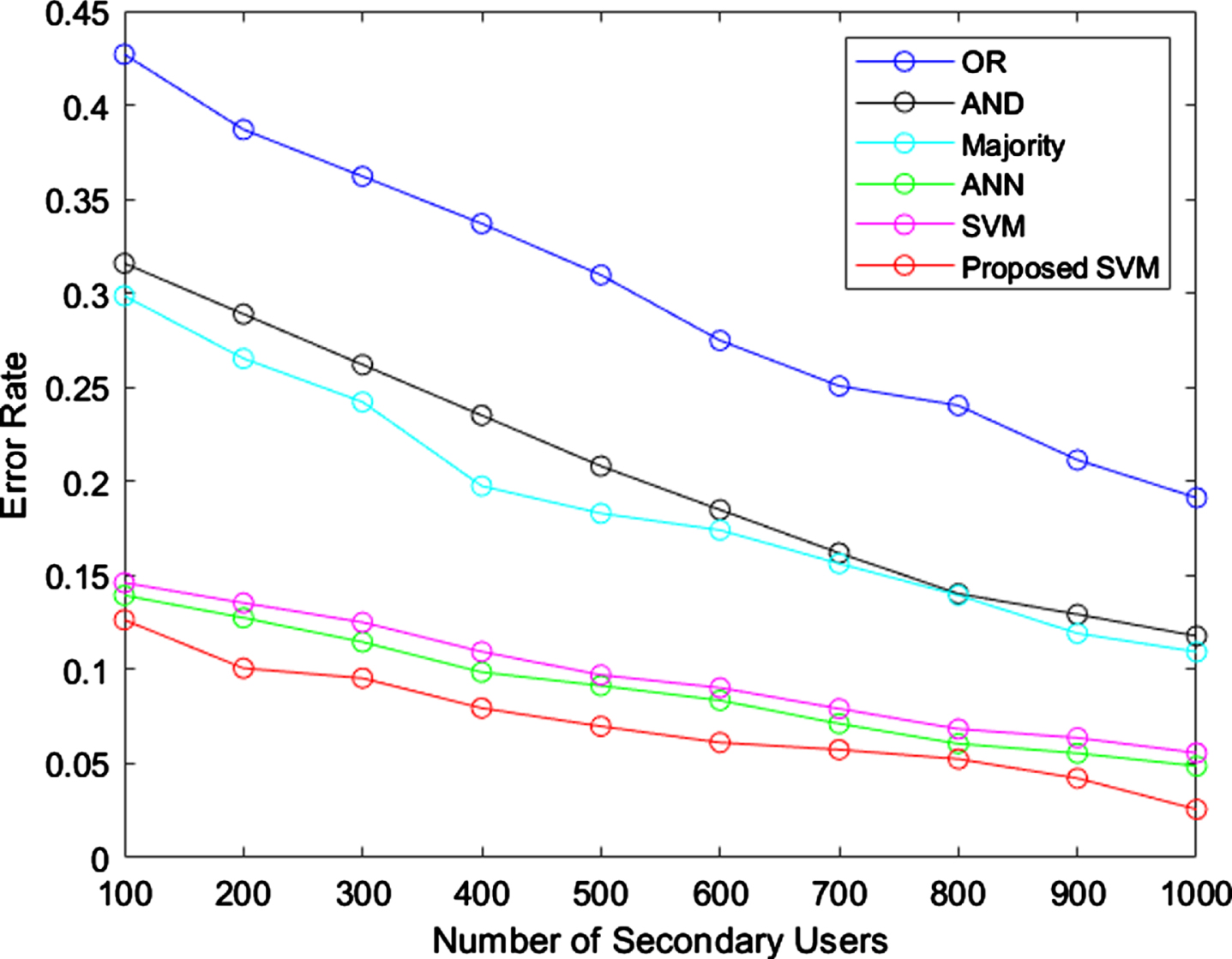
Error Rate (ER).
When the sum of secondary users are 1000, the ER for proposed model is 0.04 and the same model has 0.13 of error rate, while the secondary user is only 100. The existing ANN and SVM has less error rate than majority, AND, OR. When compared with all techniques, OR has high ER, i.e. it has 0.24 of ER when the users are 1000. Figure 5 shows the utilization of spectrum for all techniques.
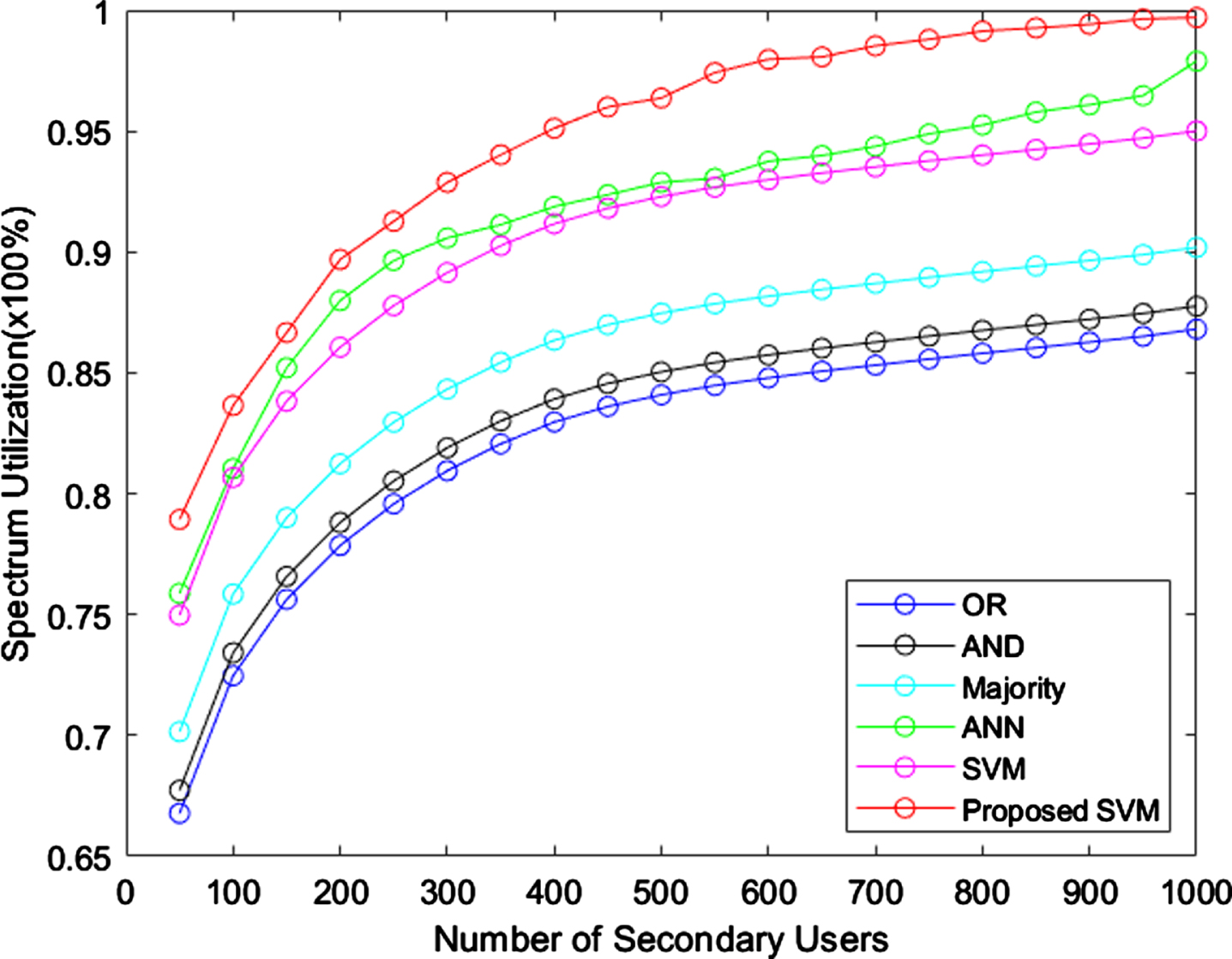
Spectrum utilization.
The utilization of spectrum is high in the proposed model than existing rules and techniques. Next to proposed model, ANN and standard SVM uses average spectrum than OR, AND, majority rules. The OR has less spectrum utilization and provides poor performance, which is proved in the above figure. Figure 6 shows the throughput analysis of proposed model.
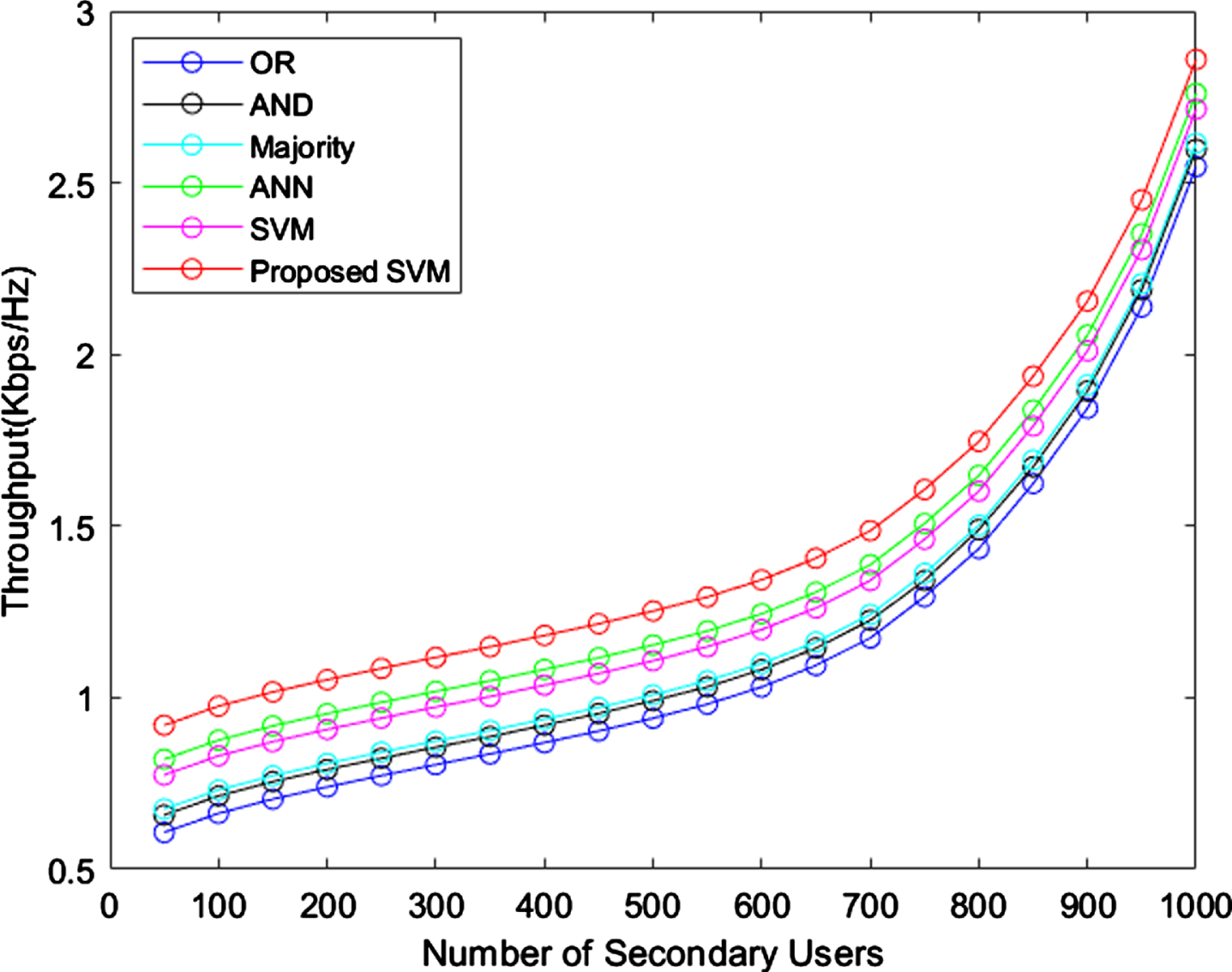
Throughput.
When the user upsurges, the throughput is also augmented for all techniques. The proposed SVM reaches 2.9kbps of throughput and Majority rule obtained 2.5kbps of throughput, when the user are 1000. This analysis shows proposed SVM achieved better performance than existing techniques. The probability for detection is graphically represented in Fig. 7.
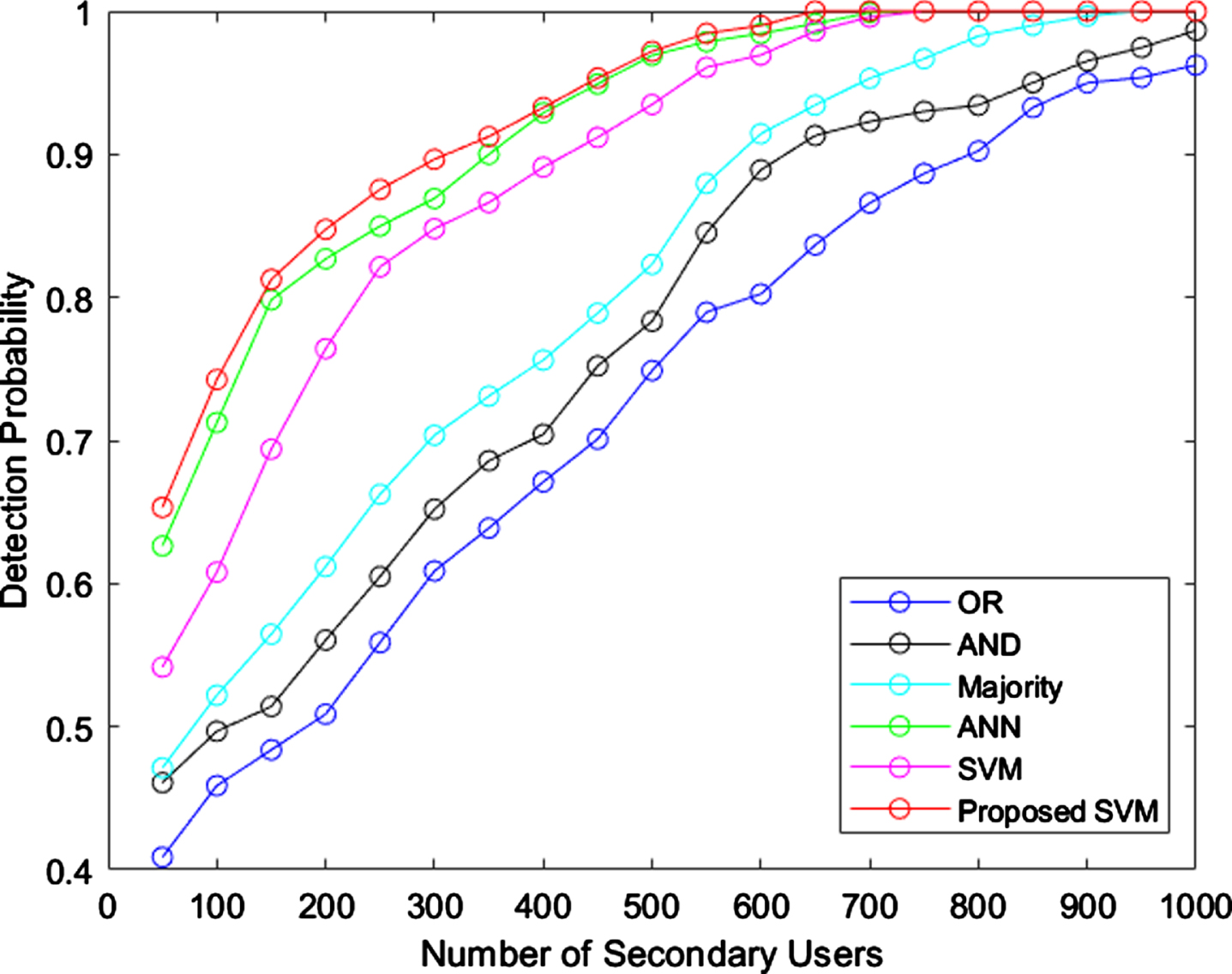
Detection probability.
The probability must be high for better performance, here, ANN and proposed SVM shows better detection probability than other techniques. When the user reaches 650, the detection probability is stable for both proposed model and ANN. However, the majority rules reaches the stable probability only, when the number of users are 800. However, the OR with AND rules didn’t the reach the probability. Figure 8 depicts the misclassification rate.
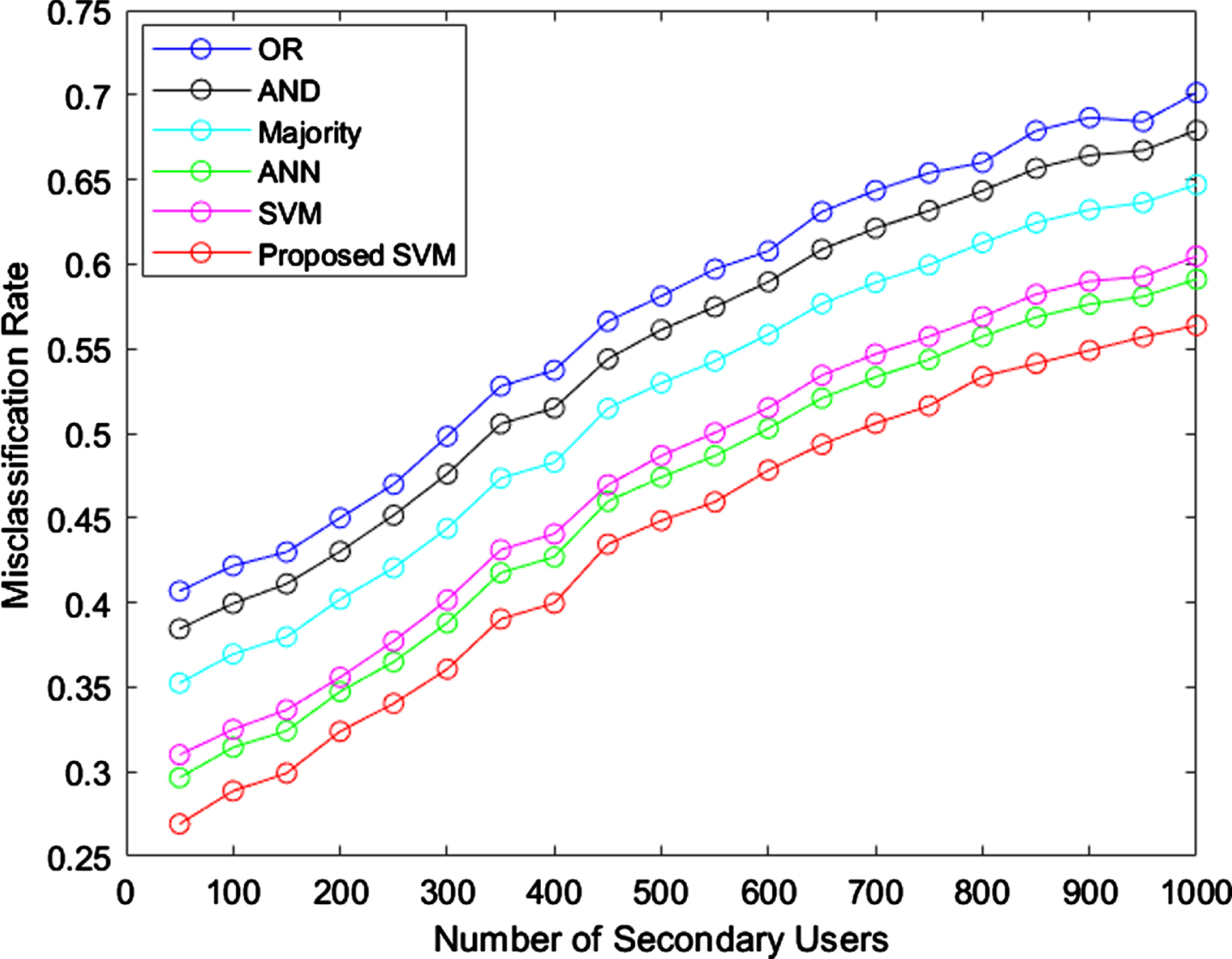
Misclassification rate.
The rate of misclassification must be less for the better performance model. When the users are less, the misclassification rate is very less for proposed model, i.e. 0.26 when the user is 50. But the same proposed model gained the misclassification rate as 0.54, when the users are 1000. Not only proposed model, the OR rules attained high probability rate i.e. 0.71, when the users are 1000. Figure 9 represents the sensing time for all techniques.
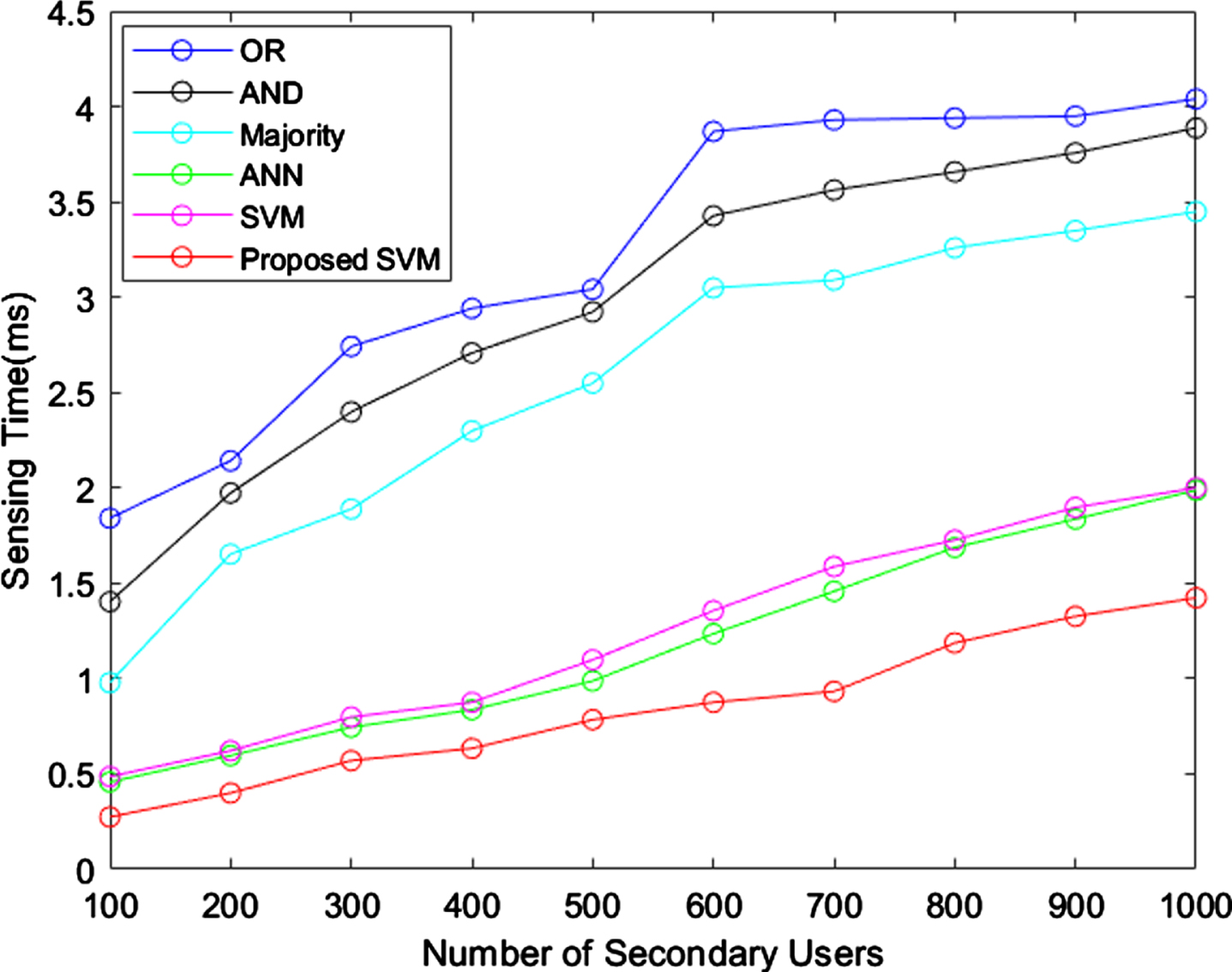
Sensing time.
The good model should take less time for sensing, but the OR takes 4 ms of sensing time, when the users are 600. For the same number of users (i.e.600), the AND takes 3.4 ms, majority rules consumed 3 ms. But, the ANN and standard SVM attained nearly 1 ms to 1.3 ms of sensing time, where the proposed model takes only 0.8 ms for sensing for 600 users. This shows the better performance of proposed model over existing techniques. The graphical representation for energy consumption using different techniques is provided in Fig. 10.
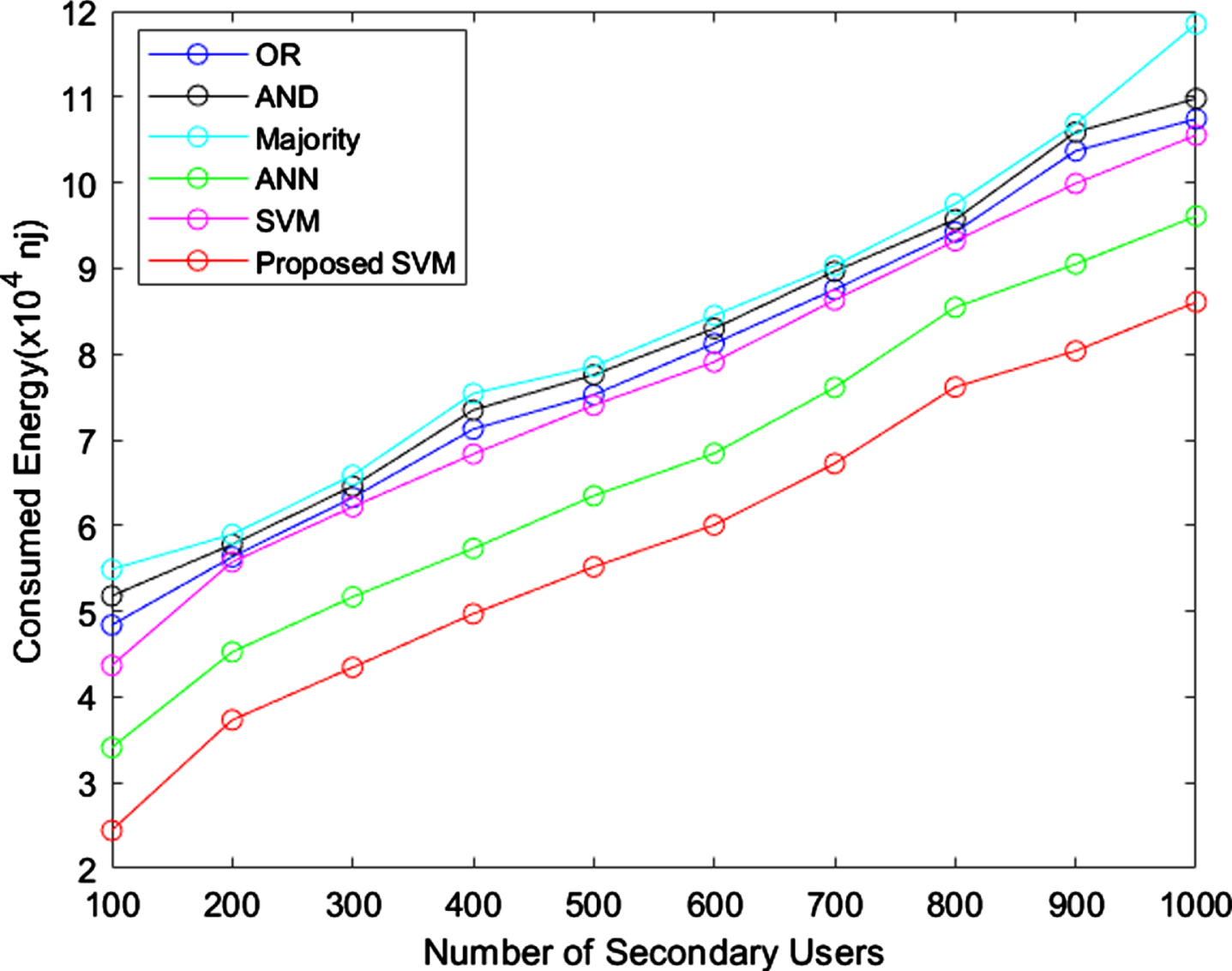
Energy consumption.
The best algorithm should consume less energy even though when the number of secondary users increases. When compared with OR, AND, majority and standard SVM, the ANN consumes less energy, but higher than proposed model. This analysis shows the proposed model achieved good performance. Figures 11 12 provides the graphical representation of probability of detection with false alarms and Signal to Noise Ratio (SNR).
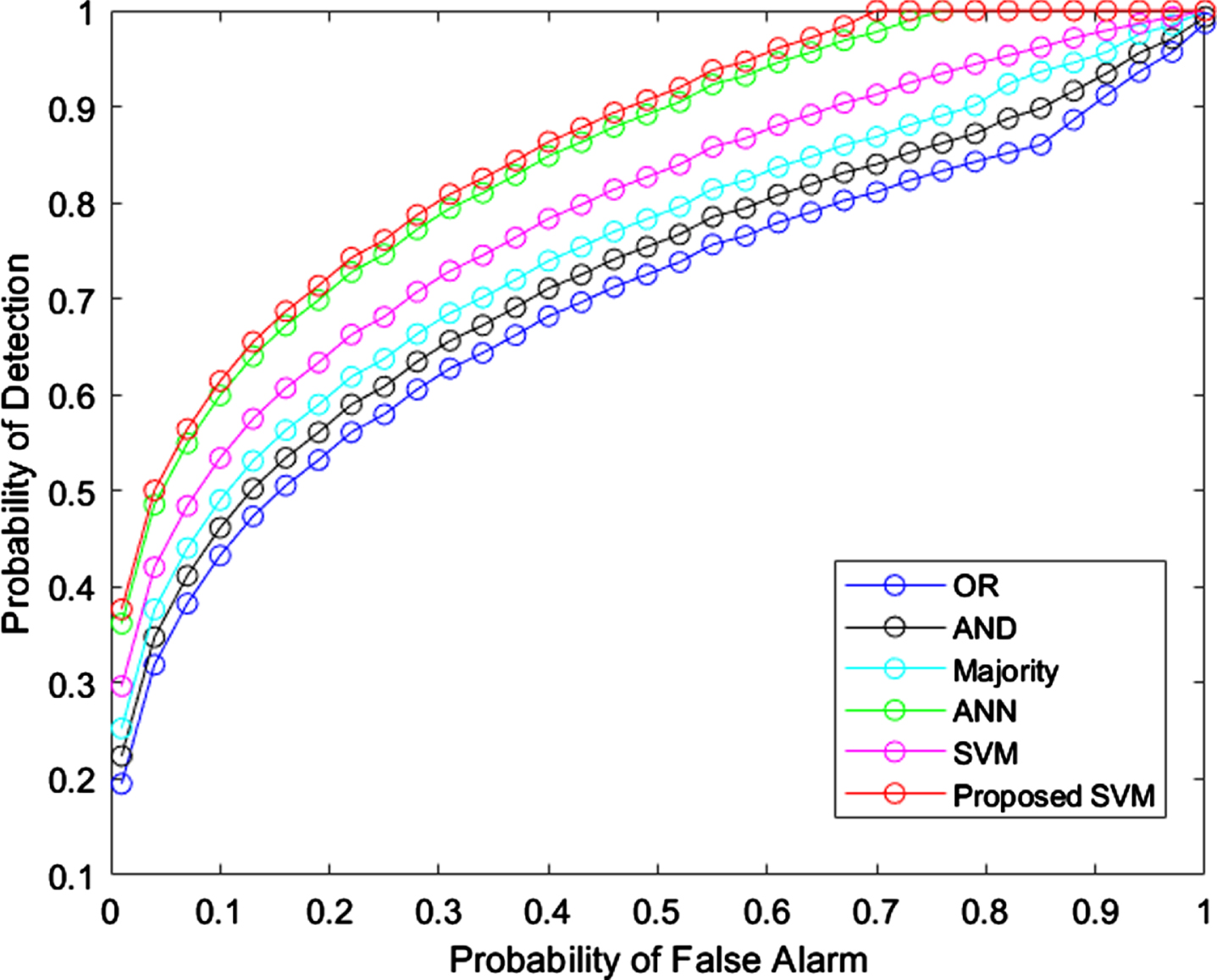
Chance of detection vs false alarm.
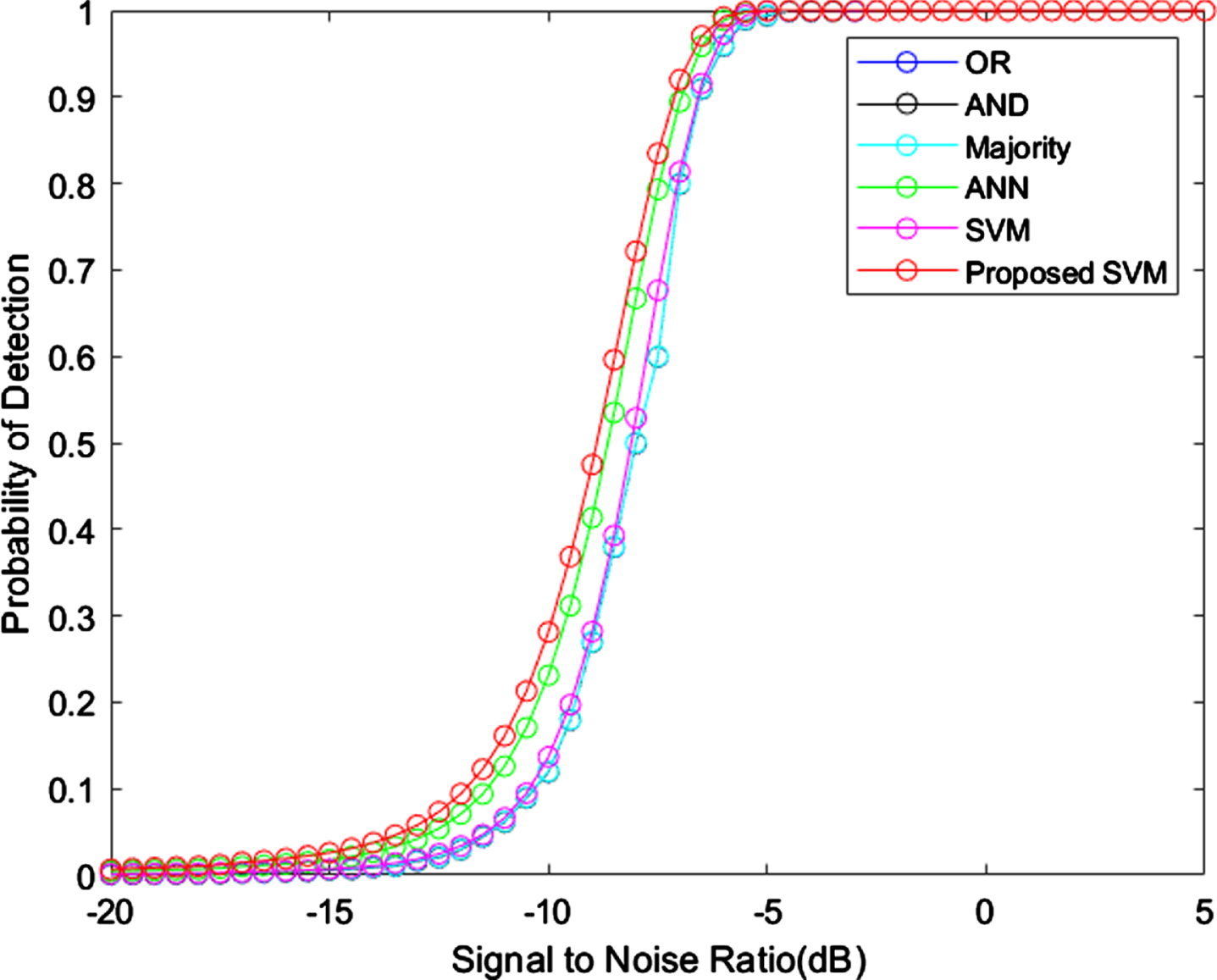
Chance of detection Vs SNR.
The ANN and proposed model provides stable detection probability, when the false alarm reaches 0.7. Comparing with all techniques, OR with AND rules provides less performance. Accuracy comparison for different techniques is given in Fig. 13.
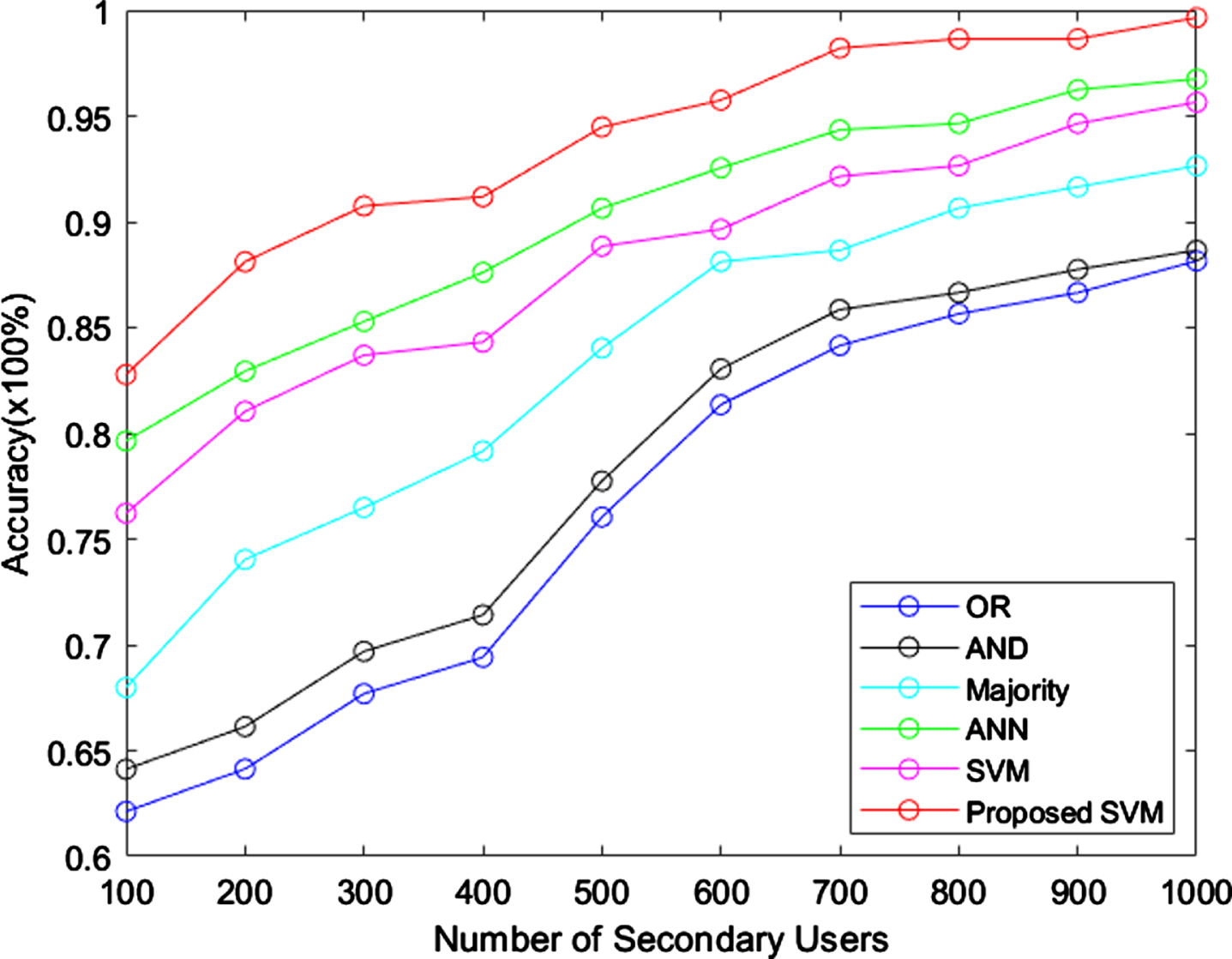
Accuracy.
When the number of users are 900, the accuracy of proposed SVM is 99% and it achieved 83% of accuracy when the user is only 100. The OR achieved only 64% of accuracy when the user is 100 and its maximum accuracy reaches upto 85%, when the user is high (i.e.1000).
Further to validate the performance of proposed work with recent research works a comparative analysis is presented in Table 2. From the comparative analysis it can be observed that the proposed model attains maximum accuracy compared to existing approaches. From this simulation scenario, it is proves that the proposed model achieved better presentation than other existing techniques.
Performance comparative analysis
With SUs censored by R-channel quality, this study examined the presentation of energy detector-based CSS situations. The average miss detection probability is strongly influenced by the SU selection filtering threshold. It has been determined that the performance of both channel approximation has been associated. An optimal censoring threshold can be established based on the values of pertinent network characteristics, such as the restriction of energy detector, the normalised detection threshold, the sum of antennas, the regular S and R-channel SNRs. Increasing the sum of obtainable SUs, the sum of antennas, and the average S and R-channel SNRs. CSS systems for energy cognitive radio, for example, could benefit from these findings. Further this research work can be enhanced by adopting the feature benefits of deep learning techniques to reduce the misclassification rate and error rate in the spectrum sensing process.
Declaration
Funding –The author did not receive support from any organization for the submitted work. Conflicts of Interest - The author has no relevant financial or non-financial interests to disclose. Ethics Approval –The paper is an original contribution of research and is not published elsewhere in any form or language. Consent Statement –All authors mentioned have contributed towards the research work, drafting of the paper as well as have given consent for publishing of this article. Availability of Data & Material –The author hereby declare that no specific data sets are utilized in the proposed work. The have also agree to be accountable for all aspects of the work in ensuring that questions related to the accuracy or integrity of any part of the work are appropriately investigated and resolved. Consent to publication –all authors listed above have consented to get their data and image published. Author’s contribution –Mr.Sivagurunathan P T–Research proposal –construction of the work flow and model –Final Drafting; Dr. N.Sathish Kumar–Survey of Existing works –Improvisation of the proposed model–Formulation of pseudocode. Code Availability –Since, future works are based on the custom codes developed in this work, the code may not be available from the author. The authors have no relevant financial or non-financial interests to disclose. No Humans or Animals were involved in the experimentation.